
Optimization of PBFT Algorithm Based on QoS-Aware Trust Service Evaluation


Abstract
:1. Introduction
- (1)
- We propose a QoS-aware trust service global evaluation mechanism to achieve reliability ranking of services. Services with higher evaluation values are considered more reliable and secure. The global evaluation is calculated by integrating the performance of static and dynamic QoS, where the static QoS value is the initial state of the service, which is provided by the service provider, and the dynamic QoS value is the real-time performance of the service, which is captured by monitoring the QoS parameters of the service.
- (2)
- We develope an improved PBFT consensus algorithm called QTPBFT that is based on the trust service global evaluation mechanism. The QTPBFT algorithm introduces a mechanism to select nodes participating in the consensus based on their QoS-aware trust value, which reduces the communication cost in the network. Nodes with higher degree of trust are selected to form the main consensus group.
- (3)
- We constructe a practical protocol for the proposed system. Simulation experiments and analysis of the optimization scheme verify its efficacy and efficiency.
2. Related Work
2.1. The Basic PBFT
- Step 1: Request. The client sends a request to the primary (leader) to perform an operation.
- Step 2: Pre-prepare. The primary (leader) node broadcasts the request to each secondary (backup) node.
- Step 3: Prepare. After receiving the preparation message, and after confirming that the information is correct, all nodes (primary and secondary) verify the message, execute the request, and then send a reply to the client.
- Step 4: Commit. When the client receives identical replies from different nodes, the process ends, where f is the maximum number of faulty nodes allowed.
2.2. The Improved PBFT
3. Qos-Aware Trust Service Evaluation
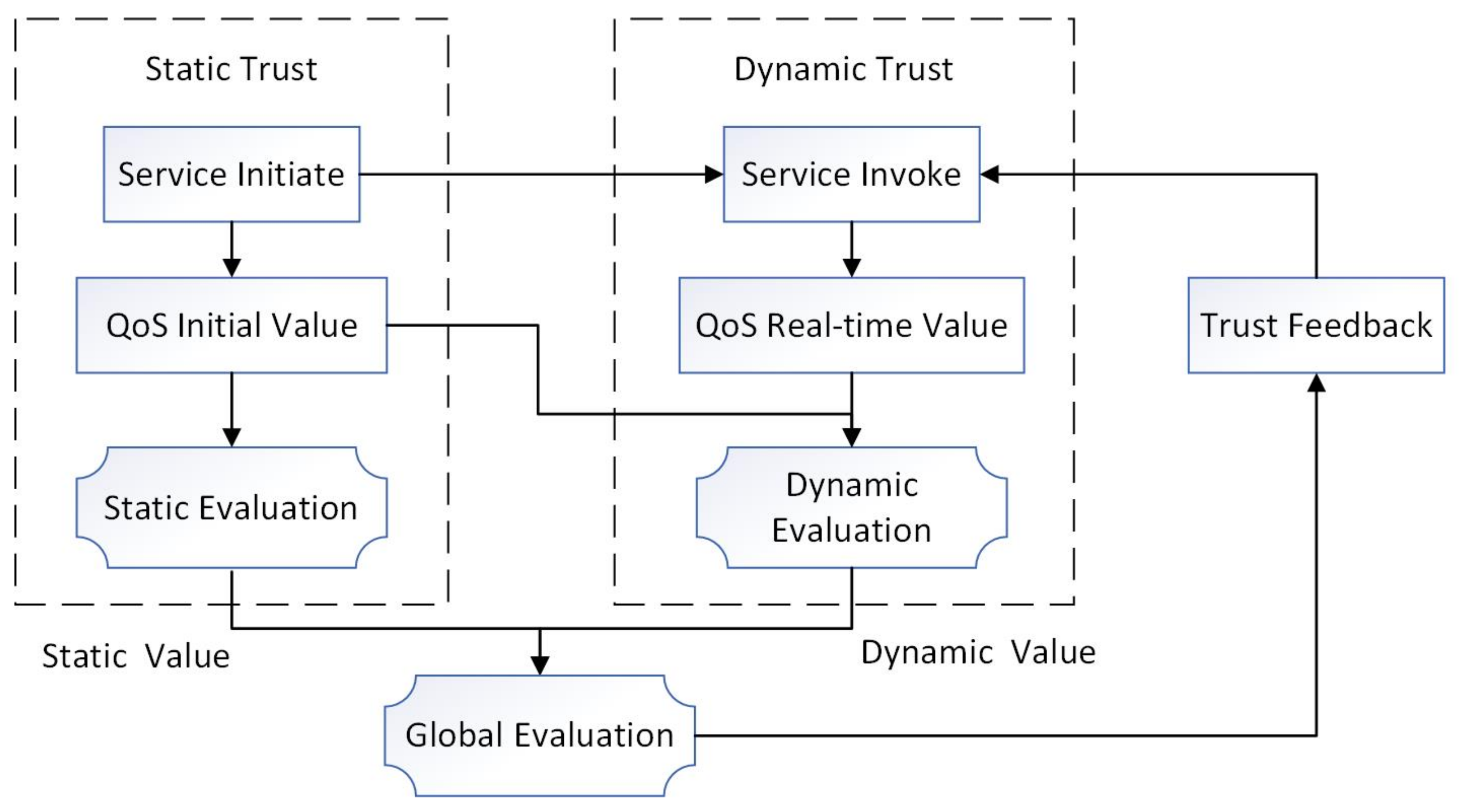
3.1. Overview of Evaluation Strategy
3.2. Detailed Evaluation Process
- Step 1: Set QoS parameters of provider’s service.In this study, QoS parameters are set in the form of intervals. The format is as Equation (3).where a represents a value of a QoS parameter, represents the lower limit interval number, and represents the upper limit interval number. When a provider publishes a service, some QoS parameters will fluctuate owing to network instability. The interval can filter out some fluctuations and ensure the authenticity and objectivity of the parameters.
- Step 2: Capture consumer’s requirement.Candidate services are selected based on the functional requirements of the user. Users can set various QoS parameters in the form of intervals according to different requirements and additionally set the maximum tolerance threshold for negative parameters. The format is as Equation (4).where b represents the value of a QoS parameter, represents the lower limit interval number, represents the upper limit interval number, and represents the user-acceptable maximum threshold for negative parameters. Considering that the service is dynamic, the appropriate service is reselected if the current dynamic QoS information exceeds the user threshold.
- Step 3: Select candidate services and construct possible degree matrix.The QoS parameters of the services requested by consumers are compared with the QoS parameters of the services provided by providers, and then the candidate’s services with the same intersection are selected. Assuming that there are two intervals and , and , , the formula’s possible degree is calculated by Equation (5) as follows:where represents the possible degree that a is greater than b. Calculate the possible degrees and then construct the possible degree matrix. The interval is due to the dynamic variability of the service, and the possible degree is a measure of the distance between the current provider’s service and the consumer’s requirement.In this study, TP and SA are positive indicators, whereas RT, BP, and LC are negative indicators; therefore, The Equation (6) is used to express the values corresponding to different indicators.where P represents the possible degree, matrix represents the consumer’s requirement intervals, which is the j-th index of the i-th service, and matrix represents the matrix of the QoS service interval, , . Suppose that the consumer requirement interval matrix is ; that is, there are 13 candidate services and 5 QoS factors. Therefore, the initial static QoS matrix is a matrix. Then, the consumer requirement interval matrix is compared with the static and dynamic QoS parameter matrices of each service, and a static possible degree matrix and a dynamic possible degree matrix are calculated. The static QoS possible degree matrix is set as the initial evaluation when the service is called for the first time.
- Step 4: Set weight.Weight is an important parameter for evaluating multi-attribute decision-making problems. Among the commonly used weight determination methods, the entropy weight method [19] is significantly affected by sample data, which may cause inconsistency with actual cognition, and the analytic hierarchy process [20,21] relies excessively on subjective emotions. In this study, we integrate these two weight determination methods; specifically, the analytic hierarchy process is used to set the subjective weights of the five factors, and the entropy weight method is used to determine the objective weights. Saaty [20] uses a 1–9 scale pairwise comparison method to establish the judgment matrix for QoS parameters and then verifies the consistency of the matrix according to Equations (7) and (8).where represents the consistence index, m is the order of the matrix, and is the maximum eigenvalue of the matrix. When , it means complete consistency, and the larger , the worse the consistency. represents the random index, and the corresponding value of can be obtained in Table 1. represents the consistency ratio. When , the matrix is considered to be valid.After verification, the subjective weight is calculated by Equation (9) as follows:where represents the subjective weight and represents the judgment matrix, , . The objective weight is adjusted according to the change in static or dynamic QoS parameters, whereas the subjective weight is not. Equation (10), which is used to calculate the entropy of the j-th index according to the possible degree matrix obtained in Step 3, compares and normalizes the possible degree of each QoS parameter vertically and finally obtains a matrix. Equation (11) then calculates the objective weights.where represents the entropy of the j-th index and P is the possible degree matrix.where represents the objective weight, . Finally, the mixing weight is calculated Equation (12) as follows:where represents the mixing weight, represents the subjective weight, represents the objective weight, and represents weight ratio, . Using the static possible degree matrix and the dynamic possible degree matrix mentioned above, the static mixing weight and dynamic mixing weight are calculated, respectively.
- Step 5: Calculate global evaluation.Finally, we employ the technique for order preference similarity to ideal solutions (TOPSIS) [22,23] to evaluate the service. TOPSIS is a method used to calculate the distance between the candidate service with the best service and the worst service, and then evaluate the service.First, build a possible degree evaluation matrix according to the possible degree interval in Step 3. If there are 13 candidate services and 5 indicators, it is a matrix. Then, build a weight matrix according to the corresponding mixing weight in Step 4 and rewrite it in diagonal form. There are 5 indicators; therefore, it is a matrix. Then, the static or dynamic evaluation matrix is , where is a matrix to obtain the score of each index of each service. Consequently, the maximum value of each index constitutes a positive ideal solution , and the minimum value of each index constitutes a negative ideal solution . Finally, according to the calculation of the possible degree of each candidate service, a global evaluation is performed. The service that is closest to the positive ideal solution and farthest from the negative ideal solution is the optimal service. These formulas are shown as Equation (13).where represents the distance of the positive ideal solution, represents the distance of the negative ideal solution, and represents the evaluation value of the i-th service. When a service is initialized, it is evaluated according to the static QoS data provided by the service provider. As the number of times the service is invoked increases, the static weight will gradually decrease, and the global evaluation of the service will be more focused on the dynamic evaluation data of the current service. The global evaluation value format is shown as Equation (14).where represents the initial value of global evaluation, represents the static evaluation value, represents the dynamic evaluation value, is the number of times the service has been invoked, and is the global evaluation value after times.
4. Improved PBFT Consensus Mechanism
4.1. Consensus Mechanism
4.1.1. Consensus Group
4.1.2. Candidate Group
4.1.3. Promote–Exclude Mechanism
| Algorithm 1 conConsensusGroup |
| Input: Global trust T, Nodes N, d |
| Output: ConsensusGroup, CandidateGroup |
| 1: ConsensusGroup = ⊘ |
| 2: Sort N by T; |
| 3: for do |
| 4: if is in the top of d then |
| 5: Add into ConsensusGroup; |
| 6: else |
| 7: Add into CandidateGroup; |
| 8: end if |
| 9: end for |
| 10: Return ConsensusGroup, CandidateGroup |
4.2. Consensus Process
- (1)
- Request phase. In this phase, a client sends a request message to the primary node in the network. The format of the request message is shown as Equation (16).where contains message details m and message digest , o represents the requested operation, t represents the timestamp, and c represents the client ID.
- (2)
- Pre-prepare phase. When the primary node receives the request, it enters the pre-prepare phase, and announces the next record that the consensus group should agree to, which is realized by sending a pre-prepare message. The primary node sorts the transaction requests, assigns a number n, and generates a pre-prepare message, which is broadcast to other replica nodes. The format of a pre-prepare message is shown as Equation (17).where v represents the view number, d represents the message digest of the client, m represents the message details, g is the global trust value of node, and h is the result of hash calculation on g.
- (3)
- Prepare phase. After each node in the consensus group receives the pre-prepare message, it verifies the correctness and validity of the record, and determines whether the h value in the pre-prepare message is the same as the local h value. If they are different, the local global trust value will be updated to g. Then a prepare message is multicast to all the other nodes. The format of the prepare message is shown as Equation (18).where i represents the current replica node ID. The prepare phase is complete when a replica node obtains valid prepared messages from different replica nodes, where f is the number of Byzantine nodes in the system.
- (4)
- Commit phase. If replica node i receives verified PREPARE messages, it will send commit messages to other nodes, including the primary node. After receiving the prepare messages from the majority, the primary node multicasts a commit message to both the consensus group and the candidate group. The format of the commit message is shown as Equation (19).At this stage, the primary node will receive feedback messages from all consensus nodes and verify the validity of the messages. Once the transaction information m is tampered with, its hash value d will be changed accordingly. If the value of d is different, it means that the transaction message has been tampered with, so it is determined that the node sending the feedback message is a Byzantine node. When a Byzantine node is identified, the node will be penalized, i.e., the QoS global trust value will drop by 50%. Finally, each node waits for more than of commit messages from the consensus group to ensure that a sufficient number of nodes agree with the record proposed by the leader.
- (5)
- Reply phase. In this phase, the client waits for replies from different nodes in the consensus group. The results of these replies should be the same, where f represents the maximum number of potentially faulty nodes. The format of the commit message is shown as Equation (20).where r represents the result of the request. If the client receives identical reply messages, it means that the request has reached a consensus on the entire network.
5. Analysis and Evaluation
5.1. Qos-Aware Trust Service Validation
5.1.1. Dataset and Selected Services
5.1.2. Results of Global Value
5.1.3. Effects of Parameter Adjustment
5.2. Efficiency Evaluation
5.2.1. Communication Complexity
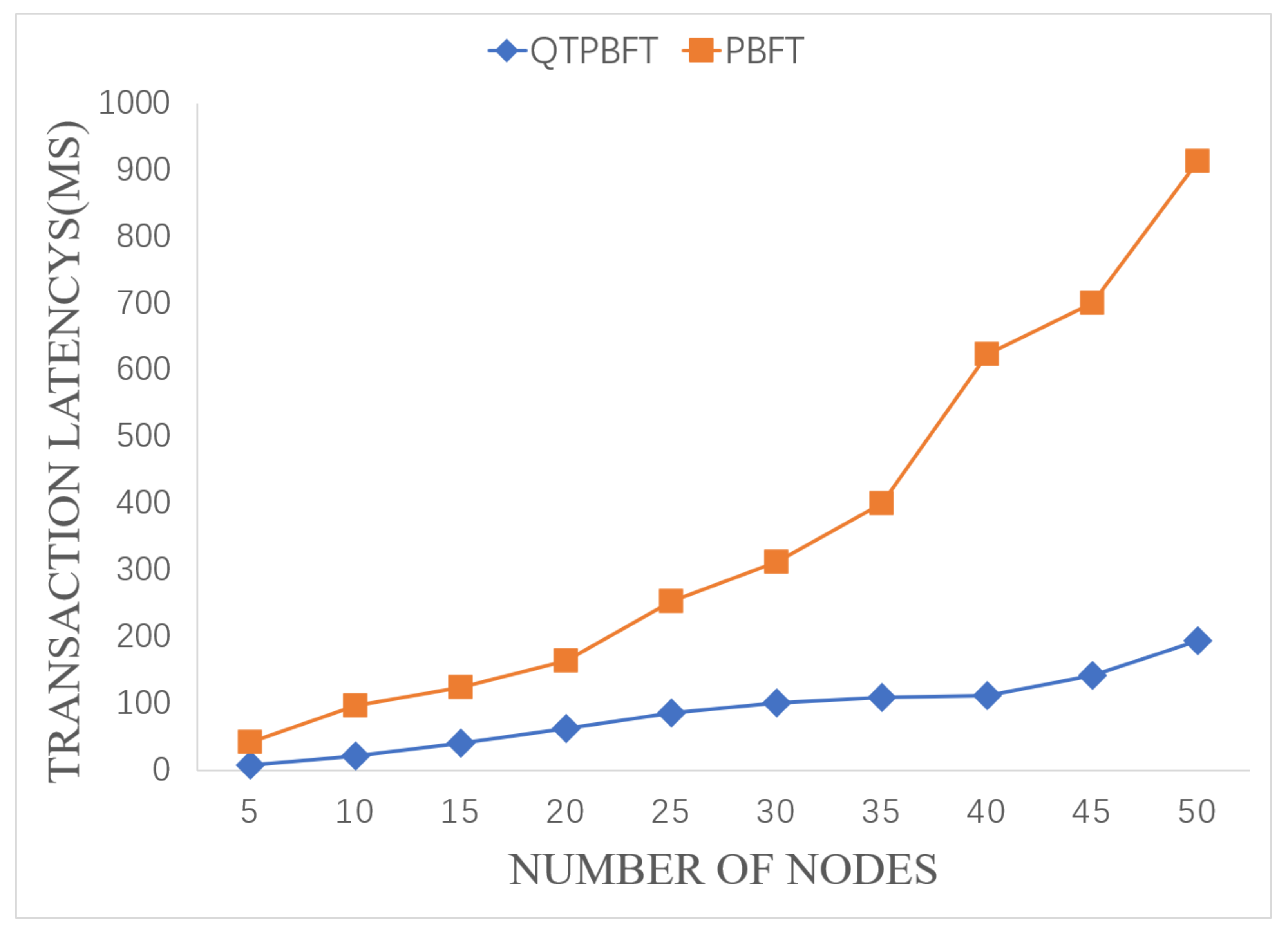
5.2.2. Transaction Latency
5.2.3. Transaction Throughput
5.3. Comparison with Other Optimization Mechanisms
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Nakamoto, S. Bitcoin: A peer-to-peer electronic cash system. Decent. Bus. Rev. 2008, 21260. Available online: https://bitcoin.org/bitcoin.pdf (accessed on 20 April 2022).
- Chen, Y.; Bellavitis, C. Blockchain disruption and decentralized finance: The rise of decentralized business models. J. Bus. Ventur. Insights 2020, 13, e00151. [Google Scholar] [CrossRef]
- Sternberg, H.S.; Hofmann, E.; Roeck, D. The struggle is real: Insights from a supply chain blockchain case. J. Bus. Logist. 2021, 42, 71–87. [Google Scholar] [CrossRef] [Green Version]
- Esmat, A.; de Vos, M.; Ghiassi-Farrokhfal, Y.; Palensky, P.; Epema, D. A novel decentralized platform for peer-to-peer energy trading market with blockchain technology. Appl. Energy 2021, 282, 116123. [Google Scholar] [CrossRef]
- Tanwar, S.; Parekh, K.; Evans, R. Blockchain-based electronic healthcare record system for healthcare 4.0 applications. J. Inf. Secur. Appl. 2020, 50, 102407. [Google Scholar] [CrossRef]
- Tseng, L.; Wong, L.; Otoum, S.; Aloqaily, M.; Othman, J.B. Blockchain for managing heterogeneous internet of things: A perspective architecture. IEEE Netw. 2020, 34, 16–23. [Google Scholar] [CrossRef]
- Xu, Y.; Zhang, C.; Zeng, Q.; Wang, G.; Ren, J.; Zhang, Y. Blockchain-enabled accountability mechanism against information leakage in vertical industry services. IEEE Trans. Netw. Sci. Eng. 2021, 8, 1201–1213. [Google Scholar] [CrossRef]
- Xu, Y.; Zhang, C.; Wang, G.; Qin, Z.; Zeng, Q. A blockchain-enabled deduplicatable data auditing mechanism for network storage services. IEEE Trans. Emerg. Top. Comput. 2021, 9, 1421–1432. [Google Scholar] [CrossRef]
- Castro, M.; Liskov, B. Practical byzantine fault tolerance. OsDI 1999, 99, 173–186. [Google Scholar]
- Kotla, R.; Alvisi, L.; Dahlin, M.; Clement, A.; Wong, E. Zyzzyva: Speculative byzantine fault tolerance. ACM Trans. Comput. Syst. 2010, 27, 1–39. [Google Scholar] [CrossRef]
- Gueta, G.G.; Abraham, I.; Grossman, S.; Malkhi, D.; Pinkas, B.; Reiter, M.; Seredinschi, D.A.; Tamir, O.; Tomescu, A. Sbft: A scalable and decentralized trust infrastructure. In Proceedings of the 2019 49th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN), Portland, OR, USA, 14–27 June 2019; pp. 568–580. [Google Scholar]
- Crain, T.; Gramoli, V.; Larrea, M.; Raynal, M. DBFT: Efficient leaderless Byzantine consensus and its application to blockchains. In Proceedings of the 2018 IEEE 17th International Symposium on Network Computing and Applications (NCA), Cambridge, MA, USA, 1–3 November 2018; pp. 1–8. [Google Scholar]
- Kiayias, A.; Russell, A. Ouroboros-BFT: A Simple Byzantine Fault Tolerant Consensus Protocol. IACR Cryptol. ePrint Arch. 2018, 2018, 1049. [Google Scholar]
- Aublin, P.L.; Mokhtar, S.B.; Quéma, V. Rbft: Redundant byzantine fault tolerance. In Proceedings of the 2013 IEEE 33rd International Conference on Distributed Computing Systems, Philadelphia, PA, USA, 8–11 July 2013; pp. 297–306. [Google Scholar]
- Lev-Ari, K.; Spiegelman, A.; Keidar, I.; Malkhi, D. Fairledger: A fair blockchain protocol for financial institutions. arXiv 2019, arXiv:1906.03819. [Google Scholar]
- Gao, S.; Yu, T.; Zhu, J.; Cai, W. T-PBFT: An EigenTrust-based practical Byzantine fault tolerance consensus algorithm. China Commun. 2019, 16, 111–123. [Google Scholar] [CrossRef]
- Li, W.; Feng, C.; Zhang, L.; Xu, H.; Cao, B.; Imran, M.A. A Scalable Multi-Layer PBFT Consensus for Blockchain. IEEE Trans. Parallel Distrib. Syst. 2021, 32, 1146–1160. [Google Scholar] [CrossRef]
- Zheng, X.; Feng, W. Research on Practical Byzantine Fault Tolerant Consensus Algorithm Based on Blockchain. J. Phys. Conf. Ser. 2021, 1802, 32022. [Google Scholar] [CrossRef]
- Dai, C.; Wang, W. Multi-attribute spatial node selection algorithm based on subjective and objective weighting. J. Comput. Appl. 2018, 38, 1089–1094. [Google Scholar]
- Saaty, R.W. The analytic hierarchy process—What it is and how it is used. Math. Model. 1987, 9, 161–176. [Google Scholar] [CrossRef] [Green Version]
- Li, F.; Yang, S.; Zhu, J. Improved network security situational assessment method based on FAHP. J. Comput. Appl. 2014, 34, 2622–2626. [Google Scholar]
- Yilmaz, A.K.; Malagas, K.; Jawad, M.; Nikitakos, N. Aircraft selection process with technique for order preference by similarity to ideal solution and AHP integration. Int. J. Sustain. Aviat. 2020, 6, 220–235. [Google Scholar] [CrossRef]
- Pan, X.; Wang, Y. An enhanced technique for order preference by similarity to ideal solutions and its application to renewable energy resources selection problem. Int. J. Fuzzy Syst. 2021, 23, 1087–1101. [Google Scholar] [CrossRef]
- Al-Masri, E.; Mahmoud, Q.H. Investigating web services on the world wide web. In Proceedings of the 17th International Vonference on World Wide Web, Beijing, China, 21–25 April 2008; pp. 795–804. [Google Scholar]
- The QWS Dataset. Available online: https://qwsdata.github.io/ (accessed on 20 April 2022).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Order of Matrix | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| RI | 0 | 0 | 0.58 | 0.90 | 1.12 | 1.24 | 1.32 | 1.41 | 1.45 | 1.49 |
| Service ID | Service Name | RT | TP | SA | BP | LC |
|---|---|---|---|---|---|---|
| CSP1 | GoogleSearchService | 133 | 7.7 | 95 | 84 | 10.67 |
| CSP2 | DiscoveryService | 134.07 | 12.2 | 85 | 69 | 8.21 |
| CSP3 | CSearch | 184.67 | 2.7 | 74 | 80 | 40.84 |
| CSP4 | AddressLookup | 141.77 | 7.5 | 56 | 77 | 88.31 |
| CSP5 | SearchService | 151.33 | 6.9 | 99 | 84 | 8.66 |
| CSP6 | AmazonSearchService | 47.27 | 20.3 | 62 | 82 | 2 |
| CSP7 | AddressFinder | 203.57 | 1.2 | 59 | 72 | 110.5 |
| CSP8 | redataService | 383.2 | 2.1 | 100 | 84 | 6.2 |
| CSP9 | SearchCuroCustomerService | 171 | 18.6 | 84 | 87 | 5 |
| CSP10 | search | 58 | 16 | 98 | 80 | 1 |
| CSP11 | findkmService | 204.6 | 1.9 | 99 | 75 | 7.8 |
| CSP12 | LookingForStrategyServices | 149.67 | 11.2 | 95 | 84 | 82 |
| CSP13 | GoogleSearchServiceTwo | 121 | 7.9 | 97 | 84 | 10 |
| RT | TP | SA | BP | LC | |
|---|---|---|---|---|---|
| Threshold | 200 | — | — | 100 | 100 |
| Requirement | [100, 150] | [5, 20] | [80, 100] | [50, 80] | [5, 50] |
| Name | RT | TP | SA | BP | LC |
|---|---|---|---|---|---|
| Subjective weight | 0.09 | 0.05 | 0.42 | 0.23 | 0.21 |
| Static QoS objective weight | 0.24 | 0.11 | 0.27 | 0.13 | 0.25 |
| Dynamic QoS objective weight | 0.24 | 0.17 | 0.21 | 0.22 | 0.16 |
| Static QoS mixing weight | 0.17 | 0.08 | 0.34 | 0.18 | 0.23 |
| Dynamic QoS mixing weight | 0.17 | 0.11 | 0.32 | 0.22 | 0.18 |
| Service ID | Static Value | Dynamic Value | Global Value |
|---|---|---|---|
| CSP1 | 0.78 | 0.63 | 0.7 |
| CSP2 | 0.7 | 0.61 | 0.65 |
| CSP3 | 0.28 | 0.15 | 0.21 |
| CSP4 | 0.28 | 0.18 | 0.23 |
| CSP5 | 0.74 | 0.6 | 0.67 |
| CSP6 | 0.53 | 0.55 | 0.54 |
| CSP9 | 0.38 | 0.53 | 0.45 |
| CSP10 | 0.77 | 0.85 | 0.81 |
| CSP12 | 0.47 | 0.44 | 0.46 |
| CSP13 | 0.66 | 0.67 | 0.66 |
| Consensus | Byzantine Fault Tolerance | Communication Complexity | Node | View Change Probability |
|---|---|---|---|---|
| Original PBFT [9] | Yes | Single | High | |
| Zyzzyva [10] | Yes | Single | High | |
| SBFT [11] | Yes | Single | High | |
| RBFT [14] | No | Single | High | |
| T-PBFT [16] | Yes | Group | Low | |
| X-layer PBFT [17] | Yes | Multi-Layer | High | |
| Proposed method | Yes | Group | Low |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, W.; Zhang, X.; Feng, W.; Huang, M.; Xu, Y. Optimization of PBFT Algorithm Based on QoS-Aware Trust Service Evaluation. Sensors 2022, 22, 4590. https://doi.org/10.3390/s22124590
Liu W, Zhang X, Feng W, Huang M, Xu Y. Optimization of PBFT Algorithm Based on QoS-Aware Trust Service Evaluation. Sensors. 2022; 22(12):4590. https://doi.org/10.3390/s22124590
Chicago/Turabian StyleLiu, Wei, Xuhao Zhang, Wenlong Feng, Mengxing Huang, and Yun Xu. 2022. "Optimization of PBFT Algorithm Based on QoS-Aware Trust Service Evaluation" Sensors 22, no. 12: 4590. https://doi.org/10.3390/s22124590