1. Introduction
Urban mobility and transportation are cornerstones of society. Due to the high socio-economic impact of road accidents, there is a motivation to continuously make improvements with regard to automotive safety. This motivation has derived from the development of the modern road infrastructure, which has brought major advances in terms of road safety and traffic-flow efficiency. Recent European Union (EU) road safety statistics [
1] show, however, that these improvements stagnated in 2019. Specifically, they quantify a decrease in fatal accidents of 23% when compared to 2010 and of 2% when compared to 2018. For this reason, the EU has launched an ambitious initiative called “Vision Zero” [
2], in which it establishes the goal of reducing fatalities caused by traffic accidents to near zero by 2050 and sets the target of halving the number of severe accidents by 2030. To this end, the EU initiative highlights the role that vehicle automation and connectivity play in increasing safety. Given that the majority of accidents (94%) are caused by human error [
3], the ADSs under development are mainly focused on improving safety by assisting drivers with the early recognition and avoidance of dangerous situations, while also considering other aspects such as emissions reduction, driving efficiency, and improved passenger comfort. The deployment of automated driving functions in traffic scenarios in open environments is being carried out progressively. The Society of Automotive Engineers defines six levels of automation from levels 0 to 5 [
4], where level 5 corresponds to full and unsupervized autonomy. A level 5 automated vehicle demands a very high technological complexity, and, to date, the driving functions required for this level of automation do not have the necessary robustness for deployment in traffic scenarios in open environments. According to [
5], the main aspects and systems related to ADSs can be summarized using ten categories: (1) connected systems, (2) end-to-end driving, (3) localisation, (4) perception, (5) assessment and motion prediction, (6) planning, (7) control and dynamic, (8) human machine interface, (9) dataset and software, and (10) implementation. In this work, multidisciplinary research is performed, covering mainly aspects from categories 5 and 9.
A recent line of research [
6,
7,
8,
9,
10,
11,
12] focuses on multi-modal motion prediction. This is based on the consideration that traffic motion is multi-modal in nature, meaning that each traffic participant is not bound to follow a single trajectory in the future, but it can instead choose from a wide variety of possible trajectories. In this way, not just one, but multiple probable motion hypotheses are predicted for each traffic participant, allowing researchers to capture the different options a driver may take, such as turning left, making a U-turn or continuing straight ahead, among others. In the following, the term mode refers to a specific estimation of future motion within a finite set of possibilities, and the likelihood that a given mode will be selected is denoted as mode score or mode probability. One prominent approach to address multi-modal motion predictions makes use of ML methods based on the supervised learning paradigm. For this, a labeled dataset is necessary, i.e., the label associated with each sample is known. In case the dataset is generated from real traffic data, only a single real trajectory per traffic participant can be labeled, namely the one that has been driven. This shows the challenge of (a) predicting multiple motion hypothesis for each traffic participant, out of a single labeled one. In addition, the prediction of multiple motion hypotheses implies the assignment of a probability score to each one with respect to the total number of hypotheses. However, labeled datasets with probabilities for routes are not available, (b) resulting in a lack of ground truth for this probability scores.
These aspects ((a) and (b)) motivate the investigation of a method that addresses the following research questions: (1) how to extract the route (certain sections of the road) that represents each possible mode from real traffic datasets, (2) how to estimate the probability that a vehicle will drive a certain mode, and (3) how to generate an adequate multi-modal labeled dataset so that a ML model can learn from it the intrinsic multi-modal motion of traffic scenarios.
In this regard, this work introduces a novel data-based method named PROMOTING that allows the estimation of multiple routes for each traffic participant and provides a probability score for each of the possible future routes. In this way, PROMOTING can be used as a labeling approach for the generation of a labeled dataset that contains not only single trajectories as its ground truth, but also the multiple estimated routes. Given the fact that the early introduction of smart intersections will be of mixed traffic, i.e., automated and non-automated driving together, the modeling of the traffic flow at such scenarios will be significant. The smart intersection is a concept aimed at improving the safety and traffic flow of intersections. It is based on the use of sensors and communication systems that allow researchers to capture and analyze traffic to support ADSs functions. Thus, PROMOTING focuses on urban traffic scenarios, paying special attention to urban intersections.
Therefore, this work makes a contribution to the improvement of multi-modal motion predictions by introducing the PROMOTING method, highlighting the following. First, the method is able to extract multiple motion hypotheses for each traffic participant. Second, the method is able to estimate the probability that a vehicle will drive following a specific motion hypothesis. Third, the method may be used for the generation of a labeled dataset that provides extra information that is useful for a multi-modal prediction task. Fourth, the method is evaluated using real-world traffic scenarios from a database, which allows us to obtain a realistic representation of the traffic’s behavior in urban traffic scenarios.
The rest of the paper is structured as follows: in
Section 2, related works are presented. In
Section 3, the methodology of PROMOTING is detailed. In
Section 4, the evaluation of PROMOTING is presented, and the associated results are shown and described. In
Section 5, the main findings of the work are discussed. The paper is summarized in
Section 6.
2. Related Works
According to [
6], the motion prediction of traffic participants can be grouped into the following categories:
- (1)
an engineering approach or physics-based methods,
- (2)
planning-based methods, and
- (3)
pattern-based methods.
Over the last few years, the research into motion prediction has shifted its focus from the physics-based generation of trajectories to the use of ML methods for the same purpose. The authors of [
13] proposed the Attention mechanism that marked a shift in the way typical neuro-linguistic programming, time-series forecasting, and sequence-to-sequence problems are approached. Along with this Attention mechanism, Transformer Networks are also finding their way into motion prediction tasks. In [
6], Multiple Attention Heads (MAH) are implemented together with a Long–Short Term Memory Encoder–Decoder architecture to predict multiple trajectories, thus addressing the multi-modality of the motion of traffic participants and considering cross-agent interaction modeling. A similar approach is taken in [
14]. The difference between [
6] and [
14] is that the latter adds map-related information that is learned by the Attention mechanism, which assists in modeling the agent–map interaction and improves the system performance. In [
15], an architecture based on an Encoder–Decoder structure is proposed, where both are based exclusively on MAH. This model achieves a better performance than the one proposed in [
14]. Other recent approaches [
9,
16,
17] build on the work of [
13] and use Transformer Networks based on MAH. In [
16], pedestrian trajectory prediction is investigated, where the behavior of the pedestrians is modeled without taking into account any kind of interaction with neither traffic participants nor with the map information. This approach is able to closely predict the motion of pedestrians, highlighting the suitability of using Transformer Networks for motion planning tasks. A similar method is presented in [
17], where the orientation of the traffic participants is considered to be an additional feature to the input vector when compared to [
16]. Furthermore, whereas in [
16] only pedestrians are considered, in [
17] the performance of the ML model is evaluated for different types of traffic scenarios and different types of road users. A more complex ML-architecture than [
16,
17] is used in [
9], consisting on three stacked Transformer Networks: vehicle motion, vehicle–map interaction, and vehicle–vehicle interaction. The networks are trained sequentially for each epoch, where the vehicle–vehicle interaction network receives the output of the vehicle–map interaction network, and the vehicle–map interaction network receives the output of the vehicle motion network. In addition to receiving the output of the previous one, each network receives additional inputs, which allows each network to specialize in a particular task.
In order for a ML model to learn something as complex as urban traffic, a large amount of data captured from real-world driving scenes is necessary. To prevent over-fitting, the data should have a large variability; in this way, the ML model is able to capture as many as possible of the variations of relevant features.
In the case of urban intersections, for example, the behavior of the traffic participants varies depending on the time of day, working/non-working days, and construction sites, among others. All these situations influence the behavior of the traffic participants, and their consideration provides extra knowledge that must be taken into account by ADSs. On the other hand, capturing real traffic data with these characteristics is a major challenge because of the required financial, computational, and time resources. One strategy to overcome this is to constrain the research and development of ADSs to bounded driving environments, such as smart urban corridors [
18]. To this end, it is relevant to use appropriate databases for the training of the ML models.
Current research works [
6,
7,
8,
9,
10,
11,
12] that focus on multi-modal motion prediction evaluate their performance either in terms of the Average Displacement Error (ADE), the Final Displacement Error (FDE), or the Root Mean Square Error (RMSE). That is, they consider a single labeled real trajectory and measure the Euclidean distances between the reference trajectory and each of the predicted ones. The best trajectory is then chosen based one of the minimum ADE, the minimum FDE, or the minimum RMSE. The main problem with using these metrics both to reduce training losses and to evaluate the model during the inference phase is that it forces ML models to generate trajectories close to the reference trajectory. This may result in a subset of the predicted trajectories not being drivable, not following the road infrastructure, or colliding with other traffic participants. Furthermore, the prediction of multiple motion scenarios for each traffic participant entails assigning a probability score that indicates the likelihood of selecting a hypothesis within the set of multiple hypotheses; however, the existent datasets containing real traffic data as [
19,
20,
21,
22,
23,
24,
25] do not provide this score, as there is only a single real trajectory labeled by each traffic participant.
In [
26], the graphs of road topologies are used to identify similar examples through their isomorphism. This is required to shape the latent space for proper novelty detection. Moreover, in [
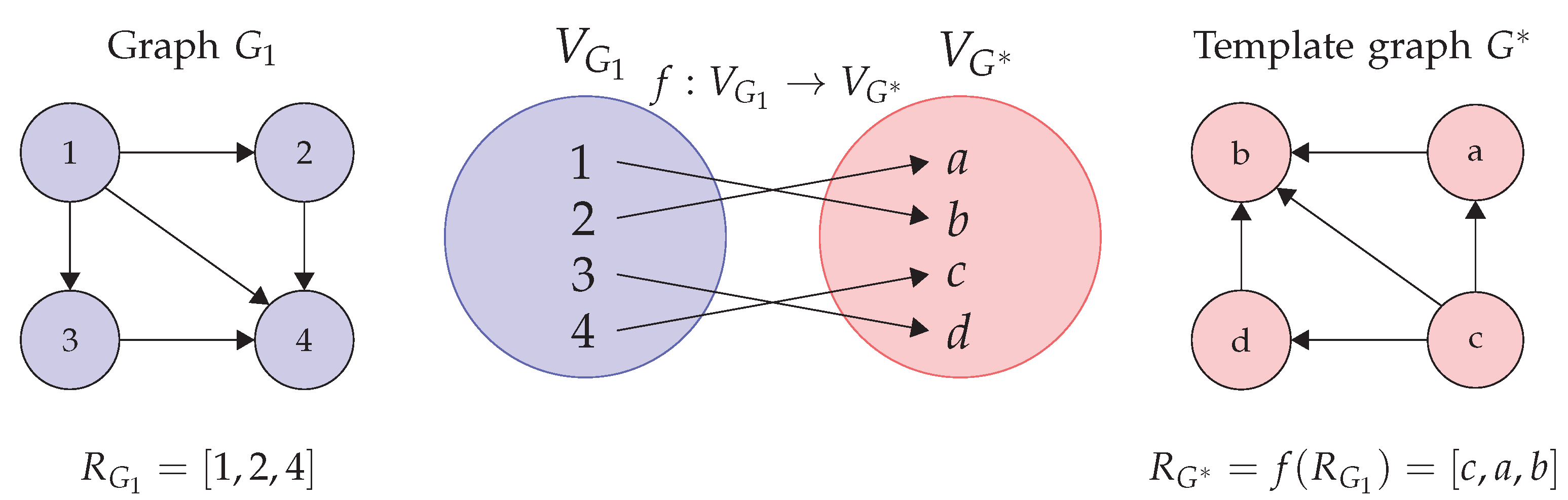
27], the isomorphisms are used to identify similar traffic scenarios, also including the trajectories as paths inside the graphs. As before, this is used for shaping a latent space. However, in the present work, isomorphisms are used to identify similar intersections and routes in the intersections in order to identify similar modes.
Relevant work on the representation of motion hypotheses in traffic scenarios is presented in [
28], with the introduction of the Predicted-Occupancy Grids (POGs). These represent the future traffic scenarios in the form of grid cells, where the confidence about the motion of dynamic agents is represented. This approach considers a spectrum of expected occupancy values beyond the simplistic binary approach, i.e., occupied or not occupied. This type of representation is used for the prediction of complex traffic scenarios in [
29,
30], where different types of machine learning based architectures for POGs estimation are presented. However, there are three notable differences between the work of [
28] and the present work. In [
28], the approach is based on expert knowledge (assumes physical models of vehicles and motion hypothesis), makes use of simulation data, and the method outputs POGs. In contrast, in the present work, a methodology based on a frequentist approach is proposed (recorded traffic data is analyzed without making a motion hypothesis), real-world traffic data is used, and the presented method (PROMOTING) outputs the modes, in the form of routes, and the mode probabilities.
With regard to all the above, the present research work addresses the shortcomings of multi-modal motion prediction research by proposing the novel PROMOTING method. This serves as the methodology for the generation of a labeled dataset that extracts information about the modes of traffic participants based on conditional prior information. The method is able to extract the number and route of the modes, as well as to estimate the probability that a traffic participant will drive a specific mode. To the best of the authors’ knowledge, this is the first work seeking to estimate the modes with their probabilities in a probabilistic way from real-world data for the purpose of the labeling of multi-modal motion hypothesis.
4. Evaluation and Results
In this section, the evaluation procedure and evaluation results are detailed. The proposed methodology is evaluated with respect to its ability to generate similar modes, mode probabilities, route types, graphs, and database trees, given similar datasets as inputs. For this, the Lyft database is used as data source, because it contains map information, as well as data about the motion of traffic participants. The data from the traffic participants are randomly divided into two independent datasets (
and
), where
is the small training dataset provided Lyft for the Kaggle Challenge
https://www.kaggle.com/c/lyft-motion-prediction-autonomous-vehicles (accessed on 11 October 2021), and
is the validation dataset provided by Lyft, while the map information remains the same for both datasets. An overview of the evaluation process is shown in
Figure 13, and each step of the PROMOTING method is detailed in what follows.
The first step of the PROMOTING method (as per
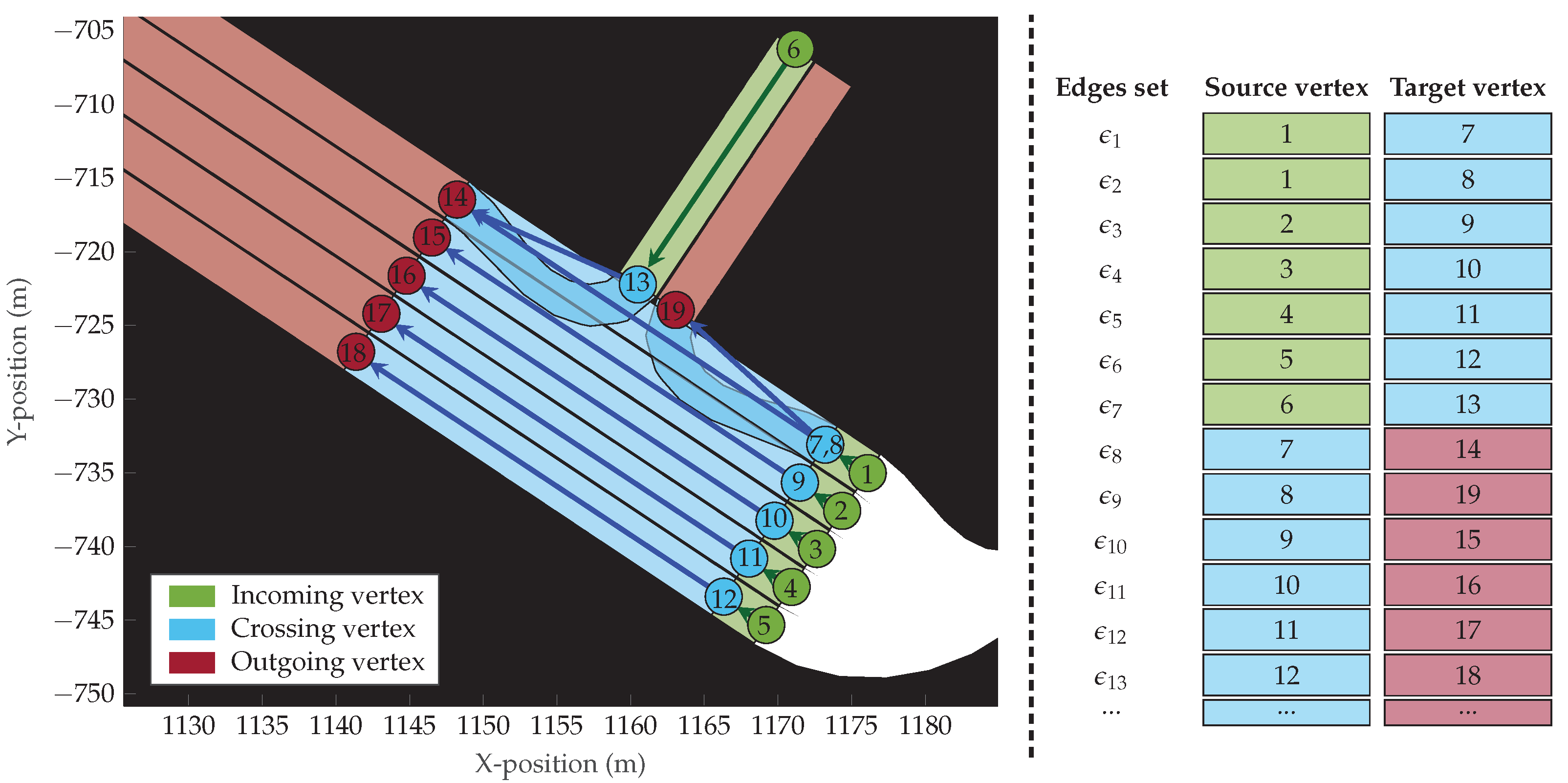
Section 3.1) describes the static traffic information (map vertex set
V and intersection graphs
). Given that this information does not vary over time and is shared among datasets, the outputs of the first step for each given dataset are not compared. A summary of the road infrastructure description of the Lyft database is shown in
Table 1.
The second step of the PROMOTING method (as per
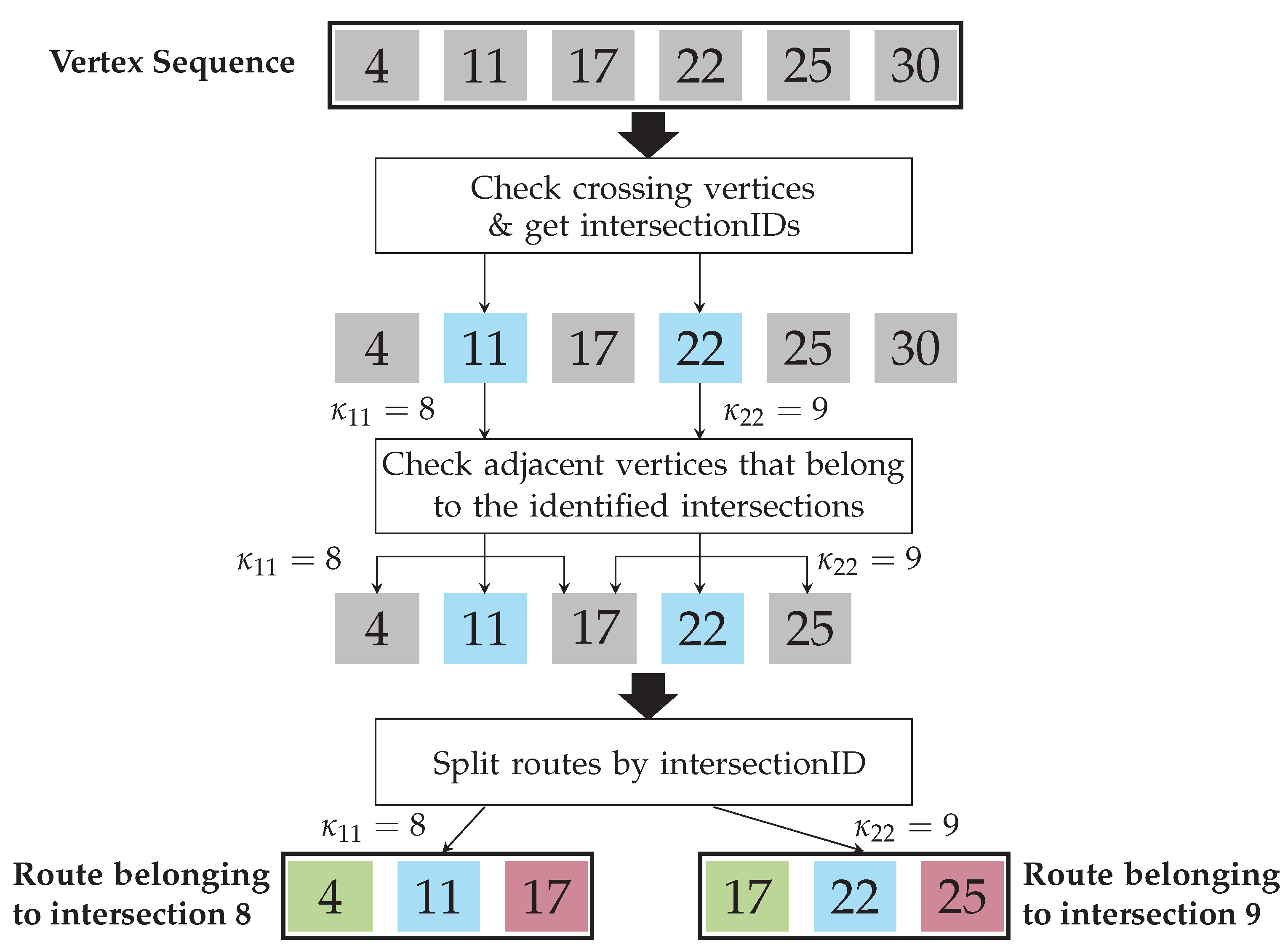
Section 3.2) extracts the VID list
. Given that each
is generated from a unique set of traffic scenes, the VIDs from different datasets are inherently different. In this step, the routes contained in the VIDs from
and
cannot be compared, because the vertices that compose each route have different names and are not yet standardized to a template graph. However, the details of each VID (number of scenes, objects, vehicles, etc.) can be compared, which allows us to corroborate that both
and
are similar in size. This is important, because datasets of different sizes would imply different numbers of clusters, types of clusters, modes, and so on. Specifically, a total of ≈1.6 millions routes of vehicles crossing intersections are extracted from the Lyft database [
25]. Approximately 50.5% of the routes belong to
, while the remaining ≈49.5% belong to
. The route distribution according to
Section 3.2 is shown in
Figure 14, and a summary of the details of the VID of each dataset is shown in
Table 2.
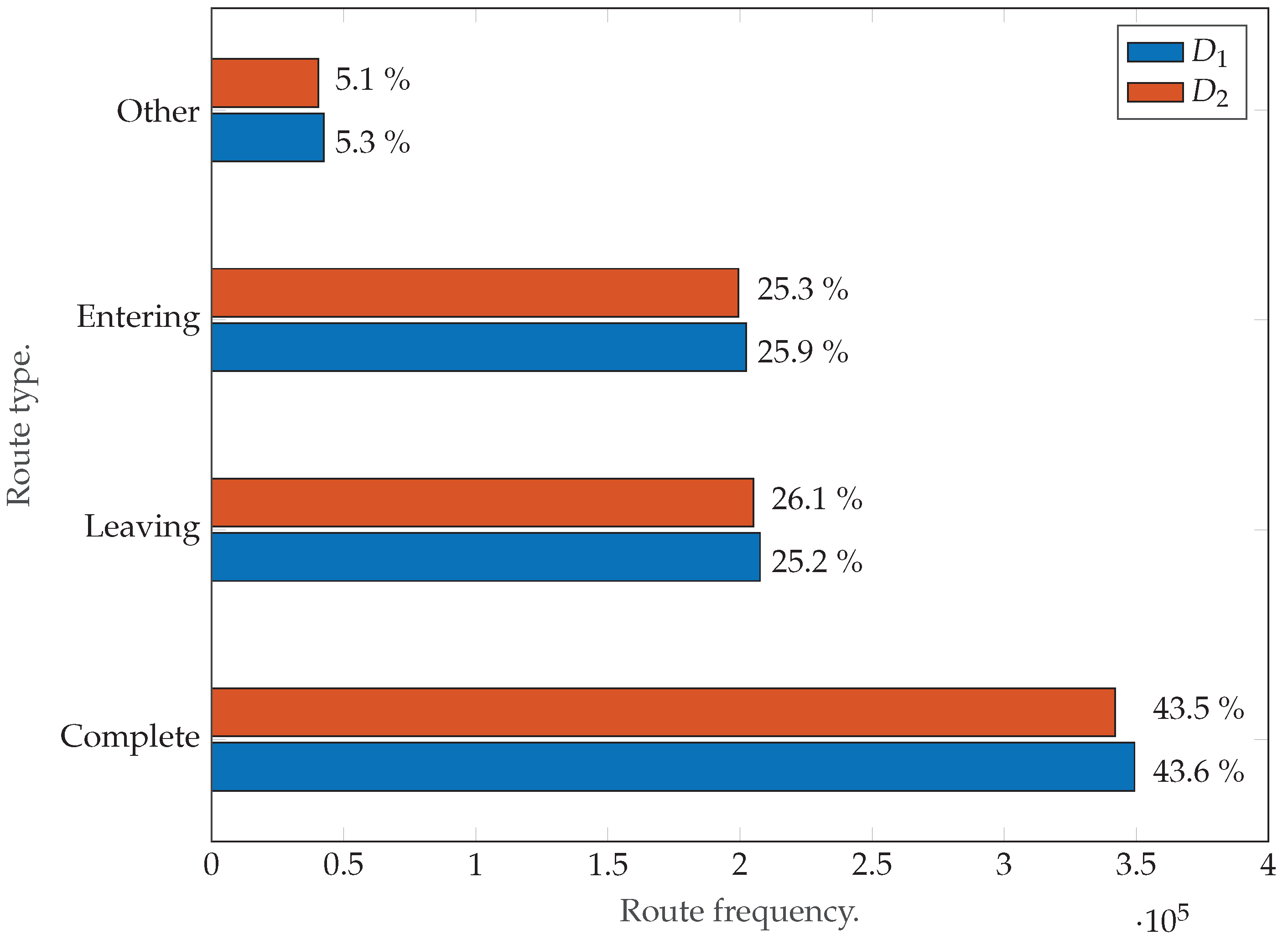
As can be inferred from
Figure 14 and
Table 2, both datasets,
and
, are similar in size, thus aiding in a fair evaluation of the method. Further, as mentioned in
Section 3.2, only “complete” routes have been selected in the output of the second step of PROMOTING. The reason for this is that these routes are the only type that contain a full description of the intersection crossing from the entrance to the exit.
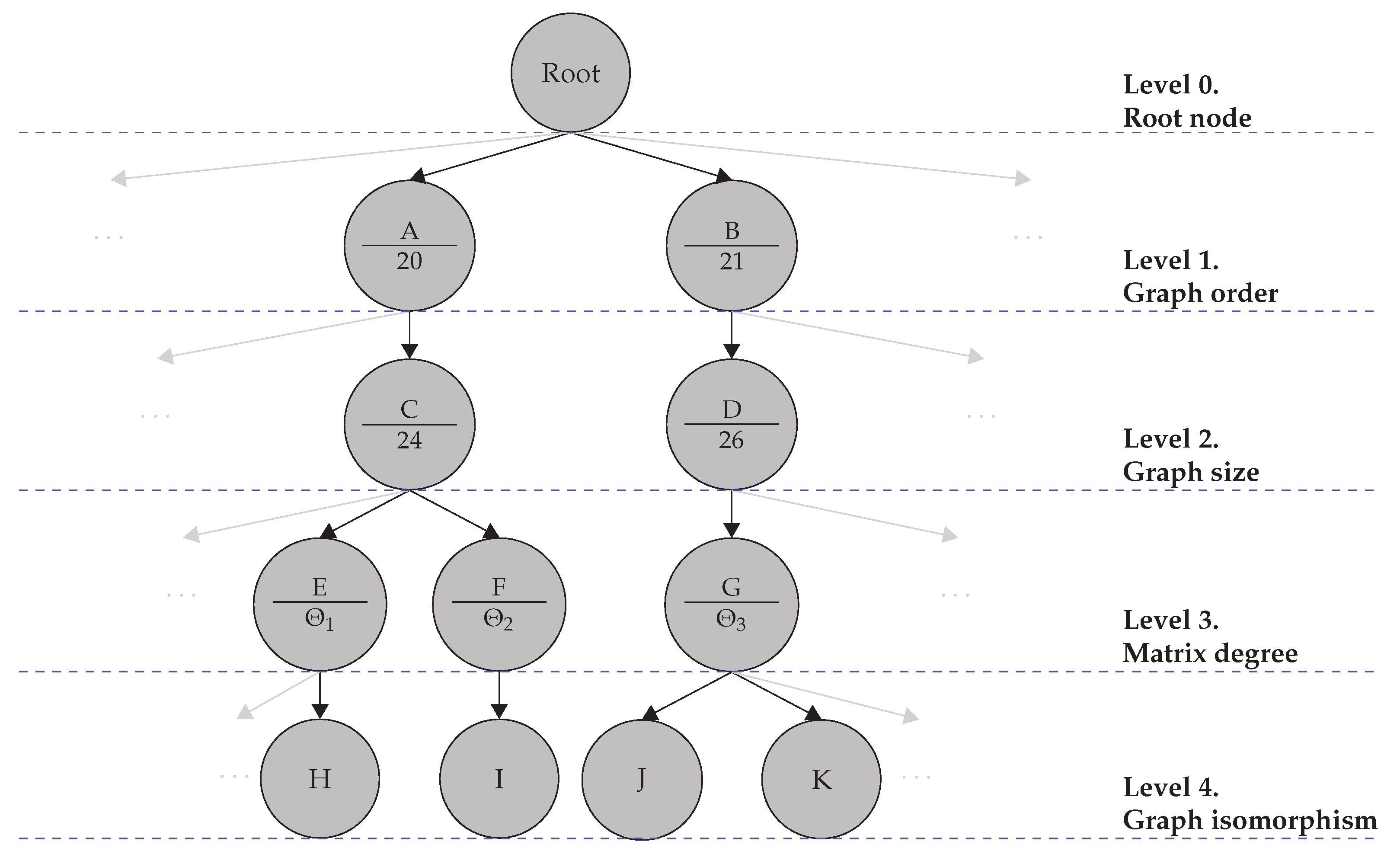
The third step of the PROMOTING method (as per
Section 3.3) focuses on the clustering of the VIDs according to their graph isomorphism. The comparison metric is the structure of the database trees
and
that are generated when the datasets
and
are used as inputs. The node generation of both trees is analyzed, that is, how was the database tree was generated for each input dataset. If the trees are similar, it is an indication that the method is able to cluster similar routes, even when they come from different datasets. The common tree
is defined as one with a lineage such as the one that is present in both
and
, i.e., each node of
within each level of the tree has a counterpart in both
and
.
can be expressed as follows
The comparison of the structure of the database tree of both
and
with
is shown in
Table 3.
Given that both datasets
and
are similar in size, from the results shown in
Table 3, it can be inferred that the method is able to comparably cluster the dynamic data from different datasets.
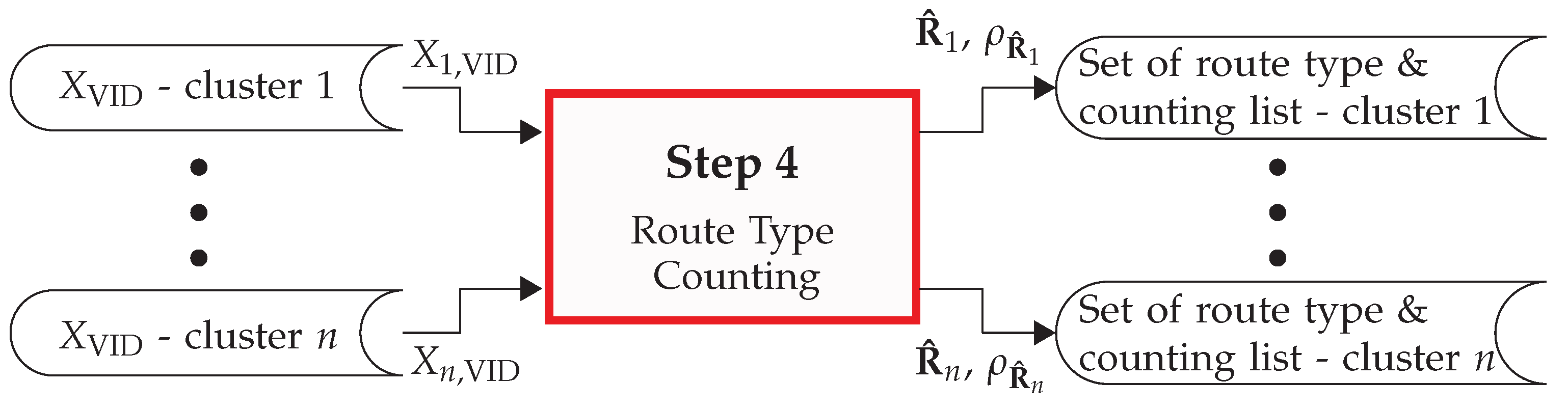
The fourth step of the PROMOTING method (as per
Section 3.4) consists of the counting of route types within each cluster. Given a cluster
a from
, its equivalent cluster
b from
is the one with the similar template graph. The comparison metric is computed by the number of routes in cluster
a that have an equivalence (same route type) in cluster
b, normalized by the overall number of routes in cluster
a. For this, let
be the number of routes of the
cth cluster of
and
be the number of similar routes, given the
cth cluster of
and its equivalent cluster in
. Then, the comparison metric is given by
Then, the metric
that represents the average of the ratio of equivalent routes between all common
cth clusters from
and
is estimated as follows
For this comparison, was achieved. This indicates that common cth clusters from and contain mostly the same route types. This indicates that the method is able to cluster the routes of traffic participants from different datasets in a similar manner.
The fifth step of the PROMOTING method (as per
Section 3.5) performs the mode estimation. Therefore, the comparison metric is based on the generated modes and their estimated probabilities. For this, let
be the probability that a vehicle will drive the
mth mode given the
cth cluster and the
sth observed sub-route, considering the dataset
. Similarly, let
be the probability that a vehicle will drive the
th mode given the
th cluster and the
th observed sub-route, considering the dataset
. Here, the subscript
indicates that the corresponding equivalence is used, i.e., the
th mode is the equivalence of the
mth mode. Therefore, only equivalent modes in equivalent clusters are considered.
Then, the relative difference
between the probabilities of equivalent modes of both trees with respect to the probability
is given by
Equation (
35) is then estimated for all equivalent modes given all equivalent observations in all equivalent clusters. Then, the metric
that represents the average of
of all equivalent modes for all observations in all common clusters from
and
is computed as follows:
where
indicates the total number of equivalent modes between
and
. For the used datasets,
. This shows that the mode probabilities, when estimated from two different datasets, are similar to each other. This indicates that the mode probability, when calculated using a large dataset, can estimate mode probabilities for similar datasets from same distributions. Even when PROMOTING uses different datasets, it is able to estimate the modes and the probability of each mode in a similar fashion for equivalent sub-route observations in equivalent intersections.
The main results of the evaluation of steps 4 and 5 of PROMOTING are summarized in
Table 4.
A representative graphical example of the extraction of modes and the estimation of the mode probabilities is shown in
Figure 15.
5. Discussion
A common challenge of multi-modal motion prediction, is to determine the “optimal” number of modes to predict, that is, how many trajectories per traffic participant should be predicted in order to comprehensively model a given traffic scene. This question has to take into consideration the amount of computational resources available, the time constraints, and the number of traffic participants, among others. Not only the number of trajectories is important, but also what they should look like. The PROMOTING method serves as a reference that shows both what the modes in a given intersection look like and what the probability is that a traffic participant will drive a specific mode. That is, the proposed method aids in the trajectory-prediction task. The method has the potential to be highly valuable for both the training and inference phases of ML methods for multi-modal motion prediction.
Along with the trajectory prediction that each traffic participant performs, the PROMOTING method could also prove to be useful at smart intersections with Vehicle-to-everything (V2X) capabilities. In that scenario, an automated vehicle could receive the information of the crossing (graphs, modes, etc.) from the infrastructure, so that the traffic participant could perform a better prediction of their own motion according to different parameters, such as efficiency or traffic load. This can be extended to all traffic participants, where each one knows where all the other traffic participants are and can predict the motion of the others with the help of the crossing information. This is relevant in the case of mixed traffic, where automated and human-driven vehicles coexist at the same intersection. Even when no V2X is present, the PROMOTING method could still be on board the EGO-vehicle, and, together with the information from exteroceptive sensors, the relationship between the surrounding traffic participants and their possible routes can be generated.
The PROMOTING method was evaluated in this work using the Lyft database. However, the method is not dependent on this database; instead, it can be used together with other map representations, as long as the required map properties are present, that is, the method is not limited to certain types of intersections but can instead generate the information from many different sources.
The method can be extended using real-time traffic information, as already provided by many navigation tools. The constant update of the traffic conditions (flow, weather, construction works, etc.) can provide an extra benefit for traffic analysis, as well as for the trajectory planning of traffic participants. This real-time traffic information does not necessarily have to come from navigation tools or infrastructure but could also be transmitted by other vehicles in the vicinity that have already crossed the intersection.
It should be noted that the mode probability estimation presented in this work does not take into account the interaction between traffic participants. In this paper, only the past sub-route, not the state of the other objects, are considered in the condition. This is a point for future research, with a special focus on the exchange of intentions between traffic participants via V2X. In addition, the investigation of abnormal behavior of traffic participants is also envisaged.
6. Conclusions
In this research work, a novel method named PROMOTING is proposed that is able to generate the modes (probable routes) of traffic participants, as well as estimate the probability that a traffic participant will drive a specific mode. This is done with the aim of supporting ADSs in their task of multi-modal motion prediction.
Mode generation is performed by clustering intersections based on the isomorphisms of their road topology. This allows us to cluster together equivalent intersections and, as a consequence, the equivalent routes of vehicles that crossed the isomorphic intersections. The probability of each mode is estimated based on the frequency with which each route is driven and a given observation (sub-route within the intersection).
The method is evaluated using the Lyft database. The results confirm that the method is able to cluster equivalent intersections and modes. The estimated probabilities of equivalent modes are almost identical, which also corroborates that the method estimates similar probabilities for similar crossings given similar observations. Therefore, PROMOTING provides a methodology that makes it possible to generate a labeled dataset that allows researchers to estimate multiple routes for each traffic participant and provides a probability score for each of the estimated routes. This labeled dataset has the potential to be highly valuable for ML models aimed at the task of motion prediction.
The method could be improved with the inclusion of real-time traffic information that can be sent via V2X communication, including information about the road infrastructure, cellular networks, or other traffic participants. The method is not limited to the used dataset but could also be implemented for other map sources.
Interested readers are referred to the repository [
31], where the code that implements the methodology proposed in PROMOTING is made publicly available.


 ,
, 















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}