
Scene Uyghur Text Detection Based on Fine-Grained Feature Representation


Abstract
:1. Introduction
- (1)
- First of all, aiming at the lack of public Uyghur text image datasets in academia, this paper constructs a Uyghur text image dataset in natural scenes, and annotates it at the word level. The dataset contains 4000 images including store signs, road signs and other street scenes.
- (2)
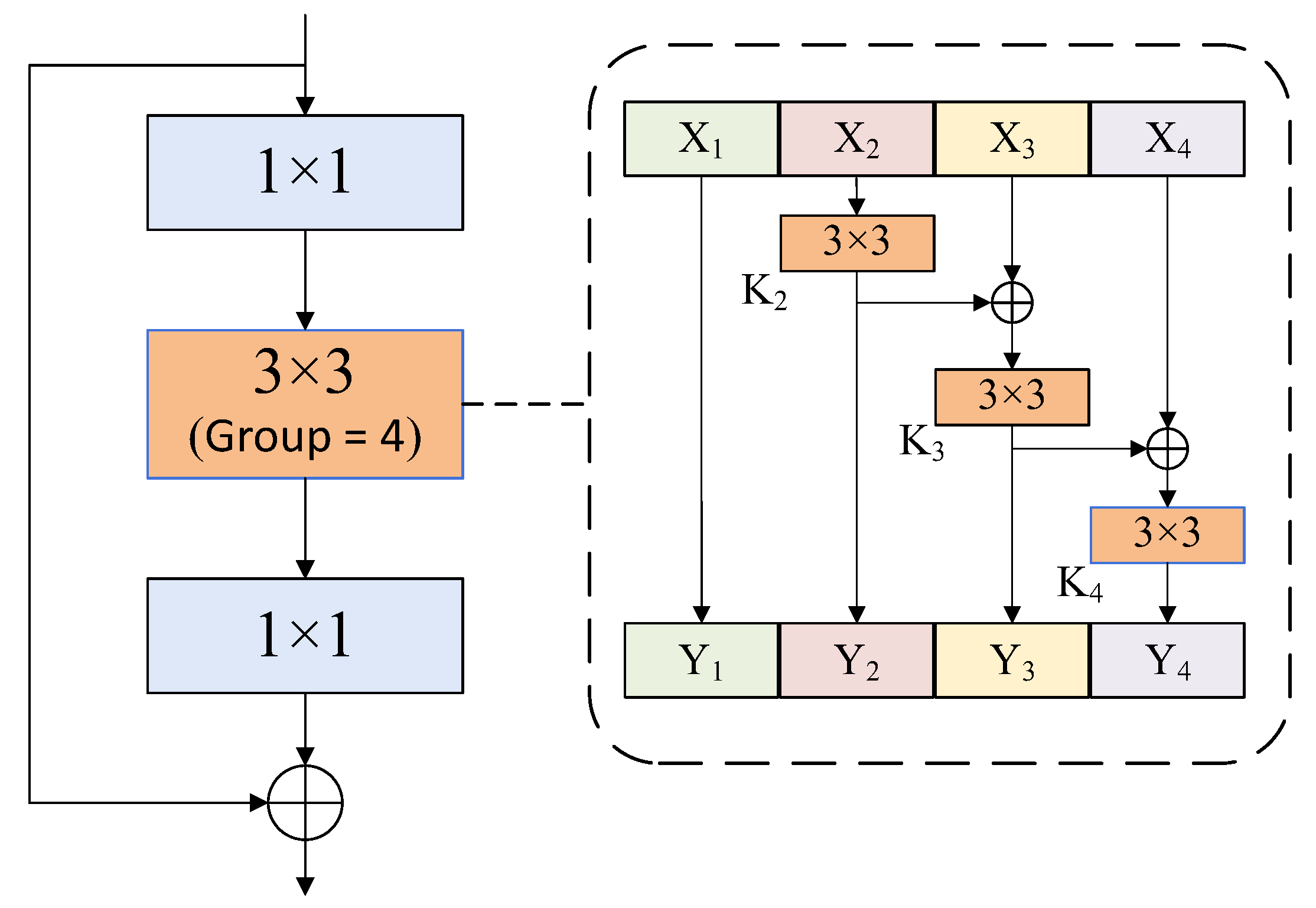
- Since there are texts of extreme sizes in the same scene image, and the text occupies a small proportion of the area in the image, the feature information of multi-scale objects in the perception context is of great help for understanding local text objects. It is beneficial to identify false detections of objects similar to text texture features. In this paper, a text feature extraction network based on fine-grained feature representation is proposed for the multi-scale text and the false positives of text-like objects. The network gradually increases the receptive field by embedding multi-level convolutions in the residual structure, which can increase the number of scales represented by the output feature in a more fine-grained form, acquire the contextual information of the text instance while capturing the features, and thus improve the efficiency of handling Uyghur text instances with extreme scale distribution and effectively suppress the false positives.
- (3)
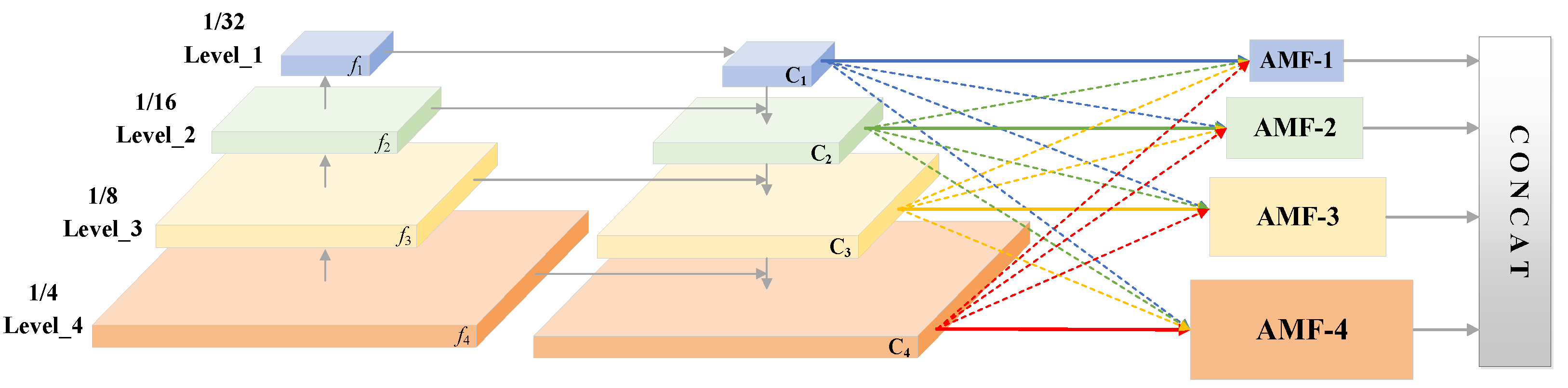
- Considering that the scales of text objects mapped by different levels of feature maps in the Feature Pyramid Network (FPN) are different, and this inconsistency will lead to the conflict of information between different feature scales when the features of each level are fused. In order to reduce the interference of inconsistency on feature learning, this paper proposes a fusion strategy based on multi-level feature weighting, which eliminates the information conflict between positive and negative samples caused by fusion by calculating the spatial weight of multi-level feature maps.
2. Related Works
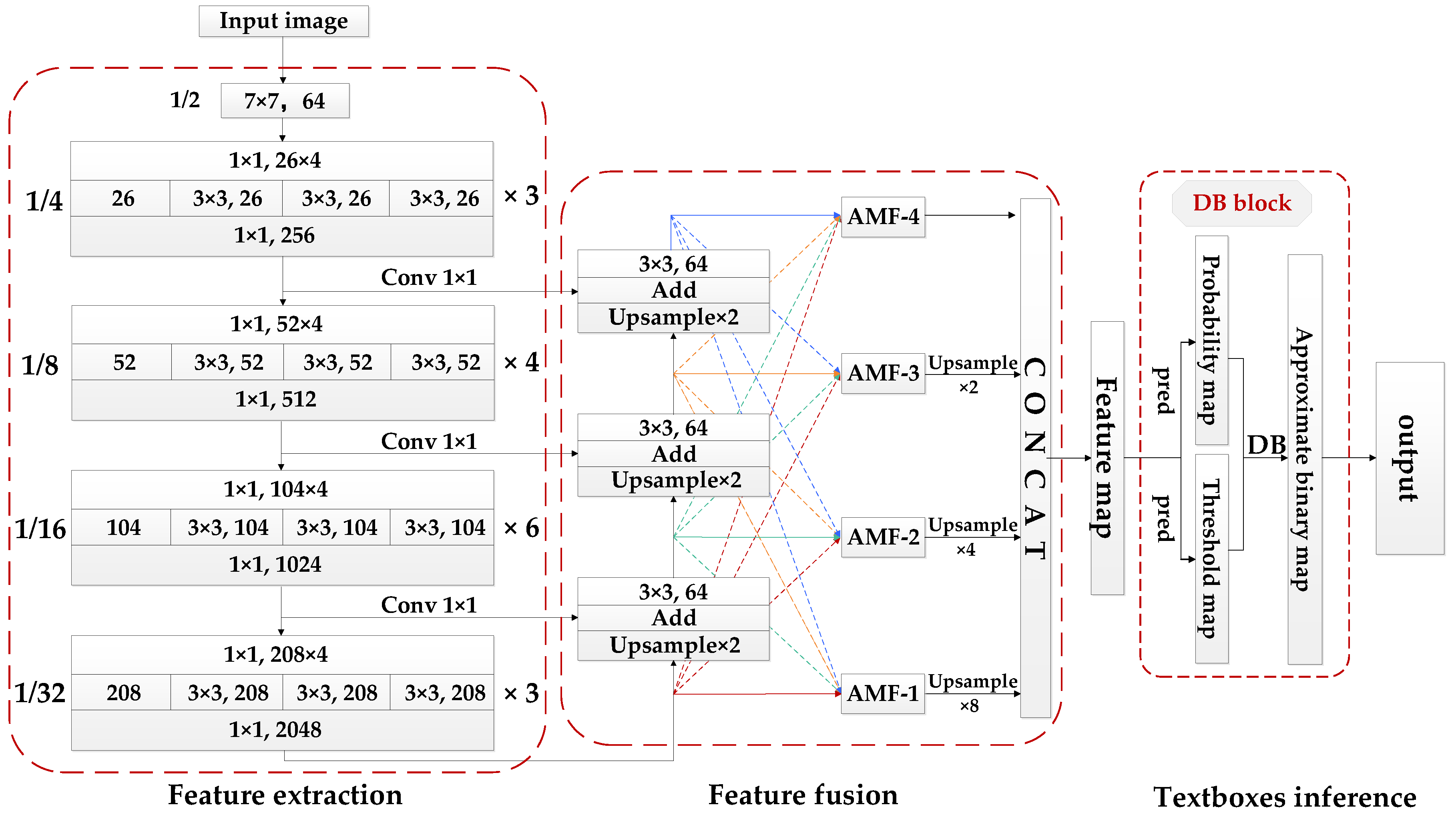
3. Methods
3.1. Fine-Grained Feature Extraction Module
3.2. Adaptive Multi-Level Feature Fusion Module
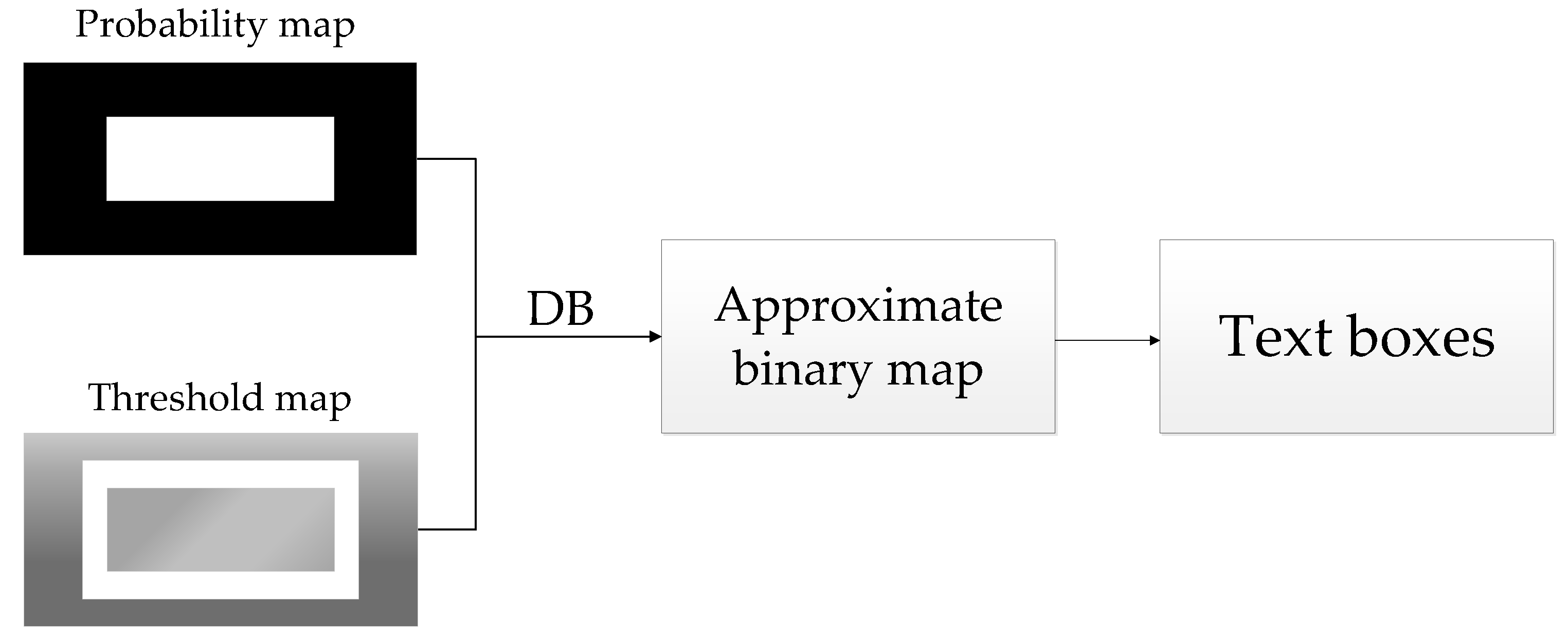
3.3. Text Bounding Boxes Inferencing
4. Results
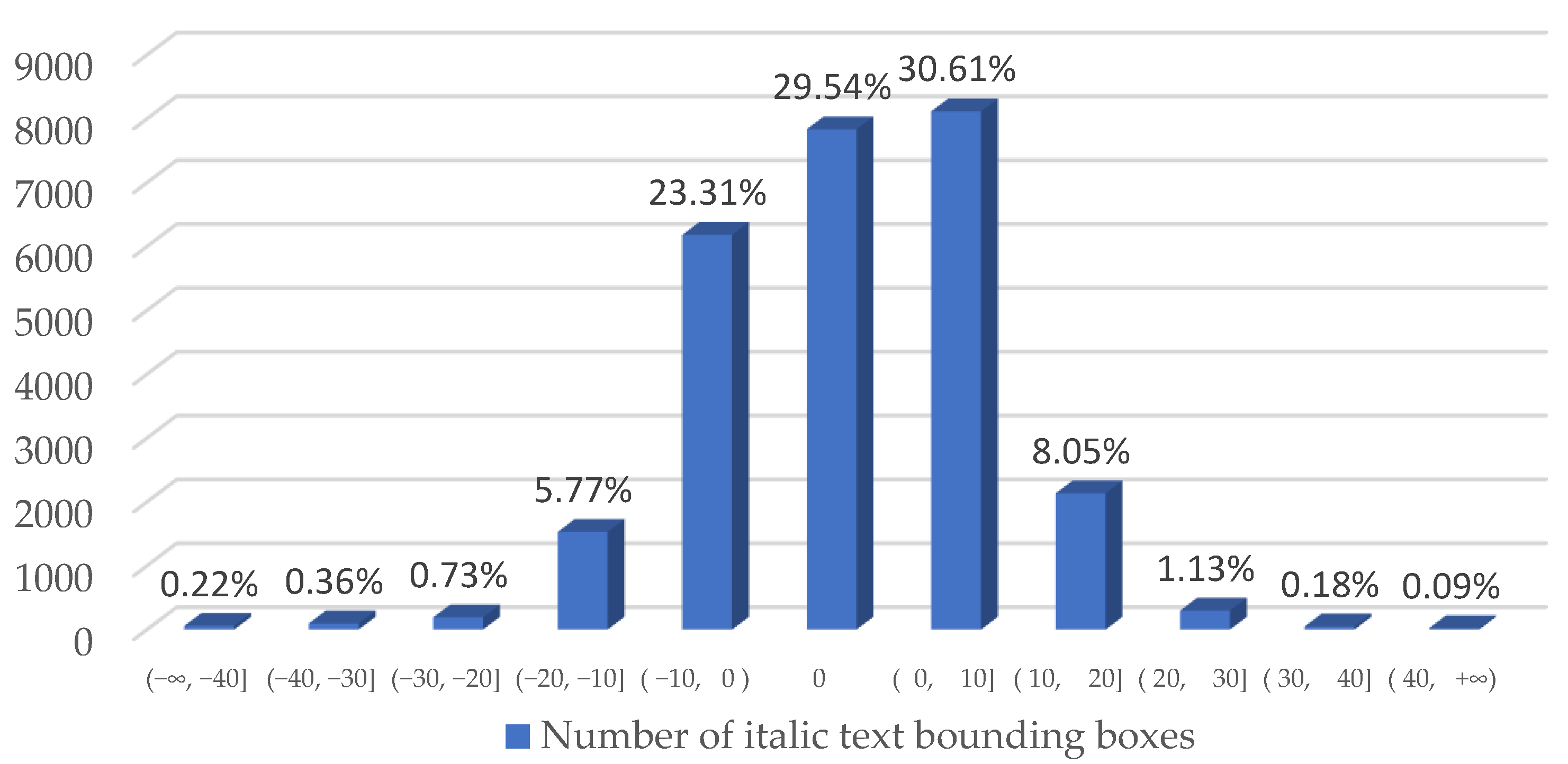
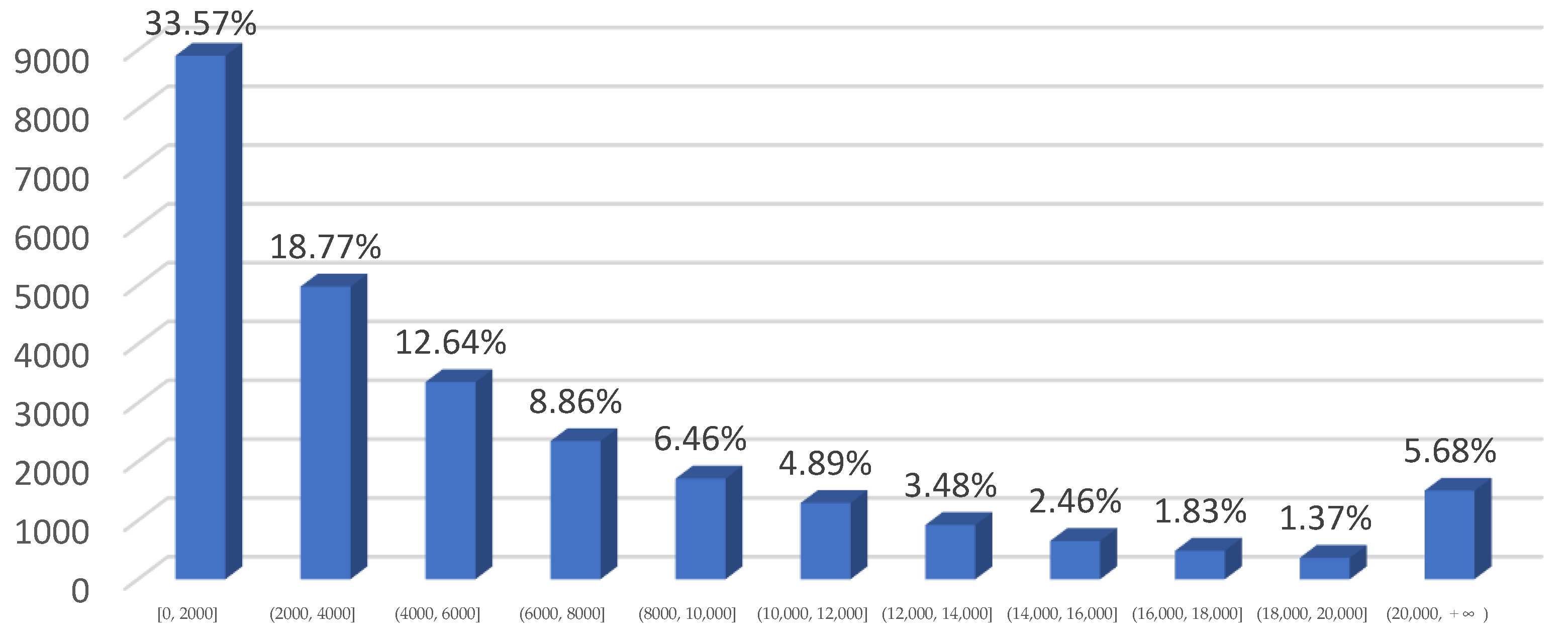
4.1. Datasets
4.2. Evaluation Criteria and Implementation Details
4.3. Selection Strategy of Hierarchical Scale “s” of Residual Block and Ablation Study
4.3.1. Selection Strategy of Hierarchical Scale “s” of Residual Block
4.3.2. Ablation Study
- 1.
- In the first group of experiments, as shown in the second row of the table, only the Res2Net module is used for feature extraction in the text detection algorithm based on DBNet. Res2Net module improves the multi-scale representation ability at the fine-grained level, and gradually expands the receptive field in multiple convolutions to capture the details and global features on the feature map. It can be seen from Table 1, the Res2Net module significantly improves the performance of the text detection model. It improves the recall and F-measure on the ICDAR2015 dataset by 1.41% and 0.87%, respectively, and improves the precision and F-measure on the Uyghur dataset by 0.42% and 0.38%, respectively.
- 2.
- In the second group of experiments, as shown in the third row of the table, after only adding the adaptive multi-level feature fusion module, it can be seen from the experimental results that the performance gains of 0.88% and 0.26% are brought on the F values of the two data sets, respectively. Therefore, it can be seen that the AMF module can learn the method of filtering positive and negative sample conflicts in the spatial dimension during the training process, and suppress the inconsistency of multi-scale targets on the feature maps of different network levels.
- 3.
- In the third group of experiments, this paper adopts the network model of DBNet + Res2 + AMF according to the characteristics of text boxes in two datasets. Compared with using a single module, its comprehensive performance has been improved to a certain extent. In addition, compared with the baseline method, the recall and F-measure of the DBNet + Res2 + AMF model on the ICDAR2015 dataset increased by 3.24% and 1.09%. On the Uyghur dataset, its precision and F-measure are improved by 0.84% and 0.52%. It can be seen that using two improved modules at the same time is more conducive to improving the text detection performance.
4.4. Comparison with Classical Method
4.4.1. Text Detection on ICDAR2015 Dataset
4.4.2. Text Detection on Uyghur Dataset
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Liu, X.; Meng, G.; Pan, C. Scene Text Detection and Recognition with Advances in Deep Learning: A Survey. Int. J. Doc. Anal. Recognit. 2019, 22, 143–162. [Google Scholar] [CrossRef]
- Rani, N.; Pruthvi, T.; Rao, A.; Bipin, N. Automated Text Line Segmentation and Table Detection for Pre-Printed Document Image Analysis Systems. In Proceedings of the 3rd International Conference on Signal Processing and Communication, Singapore, 11–12 January 2021. [Google Scholar]
- Zhao, J.; Wang, Y.; Xiao, B.; Shi, C.; Jia, F.; Wang, C. Detect GAN: GAN-Based Text Detector for Camera-Captured Document Images. Int. J. Doc. Anal. Recognit. 2020, 23, 267–277. [Google Scholar] [CrossRef]
- Bulatov, K.; Fedotova, N.; Arlazarov, V. An Approach to Road Scene Text Recognition with Per-Frame Accumulation and Dynamic Stopping Decision. In Proceedings of the Thirteenth International Conference on Machine Vision, Rome, Italy, 2–6 November 2020. [Google Scholar]
- Sun, W.; Du, Y.; Zhang, X.; Zhang, G. Detection and Recognition of Text Traffic Signs above the Road. Int. J. Sens. Netw. 2021, 35, 69–78. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26–30 June 2016; pp. 770–778. [Google Scholar]
- Long, S.; He, X.; Yao, C. Scene Text Detection and Recognition: The Deep Learning Era. Int. J. Comput. Vis. 2021, 129, 161–184. [Google Scholar] [CrossRef]
- Zhong, Z.; Sun, L.; Huo, Q. Improved Localization Accuracy by LocNet for Faster R-CNN Based text Detection. In Proceedings of the 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; pp. 923–928. [Google Scholar]
- Wang, Y.; Xie, H.; Zha, Z.; Xing, M.; Fu, Z.; Zhang, Y. Contournet: Taking a Further Step Toward Accurate Arbitrary-Shaped Scene Text Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11753–11762. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ma, J.; Shao, W.; Ye, H.; Wang, L.; Wang, H.; Zheng, Y.; Xue, X. Arbitrary-Oriented Scene Text Detection Via Rotation Proposals. IEEE Trans. Multimed. 2018, 20, 3111–3122. [Google Scholar] [CrossRef] [Green Version]
- Tang, J.; Yang, Z.; Wang, Y.; Zheng, Q.; Xu, Y.; Bai, X. Seglink++: Detecting Dense and Arbitrary-Shaped Scene Text by Instance-Aware Component Grouping. Pattern Recognit. 2019, 96, 106954. [Google Scholar] [CrossRef]
- Long, S.; Ruan, J.; Zhang, W.; He, X.; Wu, W.; Yao, C. TextSnake: A Flexible Representation for Detecting Text of Arbitrary Shapes. In Proceedings of the 15th European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 19–35. [Google Scholar]
- Zhou, X.; Yao, C.; Wen, H.; Wang, Y.; Zhou, S.; He, W.; Liang, J. EAST: An Efficient and Accurate Scene Text Detector. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5551–5560. [Google Scholar]
- He, M.; Liao, M.; Yang, Z.; Zhong, H.; Tang, J.; Cheng, W.; Bai, X. MOST: A Multi-Oriented Scene Text Detector with Localization Refinement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Web Meeting, 19–25 June 2021; pp. 8813–8822. [Google Scholar]
- Xiao, L.; Zhou, P.; Xu, K.; Zhao, X. Multi-Directional Scene Text Detection Based on Improved YOLOv3. Sensors 2021, 21, 4870. [Google Scholar] [CrossRef]
- Zhu, Y.; Chen, J.; Liang, L.; Kuang, Z.; Jin, L.; Zhang, W. Fourier Contour Embedding for Arbitrary-Shaped Text Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Web Meeting, 19–25 June 2021; pp. 3123–3131. [Google Scholar]
- Zhao, F.; Shao, S.; Zhang, L.; Wen, Z. A Straightforward and Efficient Instance-Aware Curved Text Detector. Sensors 2021, 21, 1945. [Google Scholar] [CrossRef]
- Wang, W.; Xie, E.; Song, X.; Zang, Y.; Wang, W.; Lu, T.; Shen, C. Efficient and Accurate Arbitrary-Shaped Text Detection with Pixel Aggregation Network. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 8440–8449. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Hou, W.; Lu, T.; Yu, G.; Shao, S. Shape Robust Text Detection with Progressive scale Expansion Network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 9336–9345. [Google Scholar]
- Deng, D.; Liu, H.; Li, X.; Cai, D. PixelLink: Detecting Scene Text Via Instance Segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Li, S.; Cao, W. SEMPANet: A Modified Path Aggregation Network with Squeeze-Excitation for Scene Text Detection. Sensors 2021, 21, 2657. [Google Scholar] [CrossRef] [PubMed]
- Xu, Y.; Wang, Y.; Zhou, W.; Wang, Y.; Yang, Z.; Bai, X. Textfield: Learning a Deep Direction Field for Irregular Scene Text Detection. IEEE Trans. Image Process. 2019, 18, 5566–5579. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Qin, X.; Zhou, Y.; Guo, Y.; Wu, D.; Tian, Z.; Jiang, N.; Wang, H.; Wang, W. Mask Is All You Need: Rethinking Mask R-CNN for Dense and Arbitrary-Shaped Scene Text Detection. In Proceedings of the 29th ACM International Conference on Multimedia, Lisbon, Portugal, 20–24 October 2021; pp. 414–423. [Google Scholar]
- Zhang, S.; Zhu, X.; Yang, C.; Wang, H.; Yin, X. Adaptive Boundary Proposal Network for Arbitrary Shape Text Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Web Meeting, 11–17 October 2021; pp. 1305–1314. [Google Scholar]
- Liao, M.; Wan, Z.; Yao, C.; Chen, K.; Bai, X. Real-Time Scene Text Detection with Differentiable Binarization. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 11474–11481. [Google Scholar]
- Yan, C.; Xie, H.; Chen, J.; Zha, Z.; Hao, X.; Zhang, Y.; Dai, Q. A fast Uyghur Text Detector for Complex Background Images. IEEE Trans. Multimed. 2018, 20, 3389–3398. [Google Scholar] [CrossRef]
- Fang, S.; Xie, H.; Chen, Z.; Zhu, S.; Gu, X.; Gao, X. Detecting Uyghur Text in Complex Background Images with Convolutional Neural Network. Multimed. Tools Appl. 2017, 76, 15083–15103. [Google Scholar] [CrossRef]
- Gao, S.; Cheng, M.; Zhao, K.; Zhang, X.; Yang, M.; Torr, P. Res2net: A New Multi-Scale Backbone Architecture. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 652–662. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, S.; Huang, D.; Wang, Y. Learning Spatial Fusion for Single-Shot Object Detection. arXiv 2019, arXiv:1911.09516. [Google Scholar]
- Lin, T.; Piotr, D.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Karatzas, D.; Gomez-Bigorda, L.; Nicolaou, A.; Ghosh, S.; Bagdanov, A.; Iwamura, M.; Valveny, E. ICDAR 2015 Competition on Robust Reading. In Proceedings of the 13th International Conference on Document Analysis and Recognition (ICDAR), Nancy, France, 23–26 August 2015; pp. 1156–1160. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | ICDAR2015 | Uyghur Dataset | ||||||
|---|---|---|---|---|---|---|---|---|
| P | R | F | FPS | P | R | F | FPS | |
| DBNet + Res2 + AMF-4s | 88.25 | 81.84 | 84.92 | 18.91 | 96.55 | 91.47 | 93.94 | 22.81 |
| DBNet + Res2 + AMF-6s | 89.51 | 81.02 | 85.05 | 16.03 | 96.20 | 91.90 | 94.01 | 18.23 |
| DBNet + Res2 + AMF-8s | 90.12 | 82.18 | 85.97 | 12.75 | 96.87 | 92.42 | 94.59 | 12.71 |
| Method | ICDAR2015 | Uyghur Dataset | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Res2Net | AMF | P | R | F | FPS | P | R | F | FPS |
| × | × | 89.82 | 78.60 | 83.83 | 22.32 | 95.71 | 91.23 | 93.42 | 26.35 |
| √ | × | 89.98 | 80.00 | 84.70 | 20.42 | 96.13 | 91.59 | 93.80 | 24.55 |
| × | √ | 89.89 | 80.10 | 84.71 | 21.29 | 96.04 | 91.43 | 93.68 | 24.77 |
| √ | √ | 88.25 | 81.84 | 84.92 | 18.91 | 96.55 | 91.47 | 93.94 | 22.81 |
| Method | P | R | F | FPS |
|---|---|---|---|---|
| EAST(VGG16 + RBOX) [15] | 80.46 | 72.75 | 76.41 | 6.52 |
| RRPN [12] | 82.17 | 73.23 | 77.44 | - |
| SegLink++ [13] | 86.30 | 73.70 | 79.50 | 9.50 |
| TextSnake [14] | 84.90 | 80.40 | 82.60 | 1.10 |
| PixelLink [22] | 85.50 | 82.00 | 83.87 | 3.00 |
| TextField [24] | 84.30 | 83.90 | 84.10 | 1.80 |
| FCENet [18] | 84.20 | 85.10 | 84.60 | - |
| DBNet + ResNet18 | 88.03 | 78.01 | 82.72 | 38.93 |
| DBNet + ResNet50 | 89.82 | 78.59 | 83.83 | 22.32 |
| DBNet + Res2 | 89.98 | 80.00 | 84.70 | 20.42 |
| DBNet + Res2 + AMF | 88.25 | 81.84 | 84.92 | 18.91 |
| Method | P | R | F | FPS |
|---|---|---|---|---|
| EAST(VGG16 + RBOX) | 82.68 | 88.44 | 85.46 | 1.16 |
| DBNet + ResNet18 | 94.38 | 88.52 | 91.36 | 45.16 |
| DBNet + ResNet50 | 95.71 | 91.23 | 93.42 | 26.35 |
| DBNet + Res2 | 96.13 | 91.59 | 93.80 | 25.36 |
| DBNet + Res2 + AMF | 96.55 | 91.47 | 93.94 | 22.81 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Mamat, H.; Xu, X.; Aysa, A.; Ubul, K. Scene Uyghur Text Detection Based on Fine-Grained Feature Representation. Sensors 2022, 22, 4372. https://doi.org/10.3390/s22124372
Wang Y, Mamat H, Xu X, Aysa A, Ubul K. Scene Uyghur Text Detection Based on Fine-Grained Feature Representation. Sensors. 2022; 22(12):4372. https://doi.org/10.3390/s22124372
Chicago/Turabian StyleWang, Yiwen, Hornisa Mamat, Xuebin Xu, Alimjan Aysa, and Kurban Ubul. 2022. "Scene Uyghur Text Detection Based on Fine-Grained Feature Representation" Sensors 22, no. 12: 4372. https://doi.org/10.3390/s22124372