4.2. HLS Accelerator
The HLS accelerator should be able to perform the three convolution operations which consist of the building blocks of the MobileNetV2 model, i.e., standard convolution, depth-wise convolution and point-wise convolution. Generally, there are two types of approaches when designing an application-specific integrated circuit:
Flexible designs. In such scenarios, the design will be able to execute operations with variable operand size (e.g., 6-bit, 12-bit or 32-bit wide) by leveraging a complex interconnection network, which propagates the intermediate results to the corresponding functional units. In our case, a flexible design choice would guarantee that our accelerator could execute all three convolution operations within one hardware module.
Non-flexible designs. Non-flexible designs are implemented to execute a specific task without being able to adapt to support additional operations or variable operand width. In our case, a non-flexible design choice would require three separate modules, each one dedicated to one convolution operation.
In this work, we opt for a non-flexible design due to the high operating cost of flexible accelerators in terms of power consumption. Despite their flexibility, such designs utilize interconnection fabrics which require a significantly larger amount of power to operate. On the contrary, non-flexible designs employ simpler interconnects but they utilize more area, since hardware modules are dedicated to certain execution tasks. In this sense, we opt to trade higher area requirements with smaller power consumption.
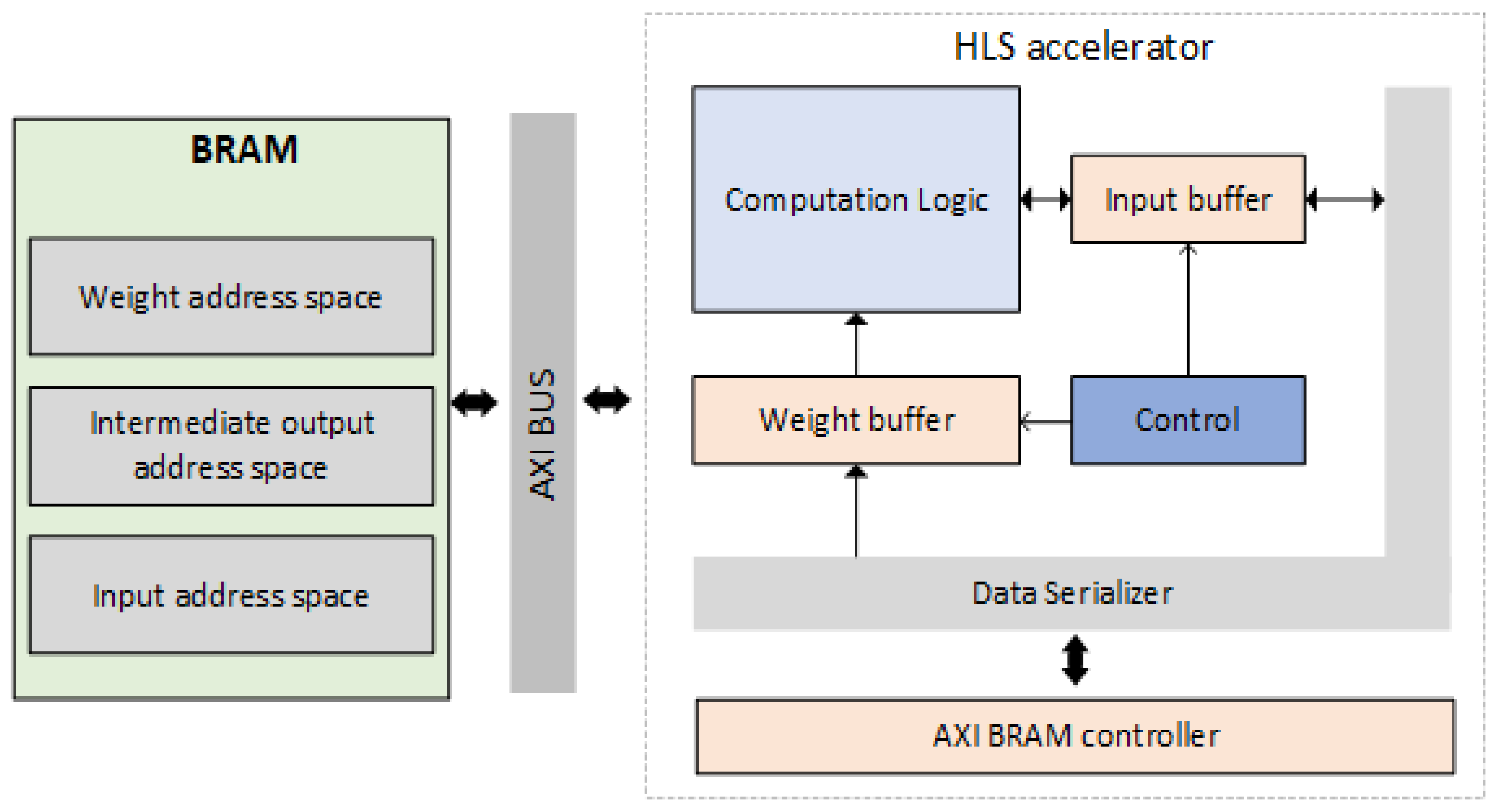
Algorithm 1 depicts the HLS pseudocode of the accelerator module. The
computational logic is charged with the execution of convolution operations and its outputs are either discarded or stored in the
input buffer. Such a decision is taken by the
control unit which manages the write rights of both
weight and
input buffers. The
control unit identifies data dependencies between consecutive convolution operations and exploits data re-usability if it is detected. In any other case, it generates the necessary control signals to reroute data from the
Data serializer to the
buffer structures.
The Data serializer is responsible for translating compressed data to a format that is usable by the
computational logic. Such data are fed to the
Data serializer by the
AXI BRAM controller, which manages the HLS-BRAM communication.
| Algorithm 1 HLS pseudocode of the accelerator. |
| FloatBuffer WeightBuf [WBUF_SIZE] |
FloatBuffer InputBuf [IBUF_SIZE]
|
| for each convolution do |
output = computation_logic(WeightBuf, InputBuf)
|
| raw_data[weights] = BramCntrl(weight_addr, mem_out) |
raw_data[inputs] = BramCntrl(input_addr, mem_out)
|
| if compression_type == CSC then |
| serialized_data = Data_Serializer(raw_data, CSC) |
| else if compression_type == CSR then |
| serialized_data = Data_Serializer(raw_data, CSR) |
| else |
| serialized_data = raw_data |
end if
|
| WeightBuf_write_enable = controller(WeightBuf); |
InputBuf_write_enable = controller(InputBuf);
|
| if WeightBuf_write_enable == True then |
| for i=0; i<WBUF_SIZE; i++ do |
| WeightBuf[i] = serialized_data[weights][i] |
| end for |
| else |
| WeightBuf[i] = WeightBuf[i] |
end if
|
| if InputBuf_write_enable == True then |
| for i=0; i<IBUF_SIZE; i++ do |
| InputBuf[i] = output[i] |
| end for |
| else |
| InputBuf[i] =serialized_data[Inputs] |
| end if |
| end for |
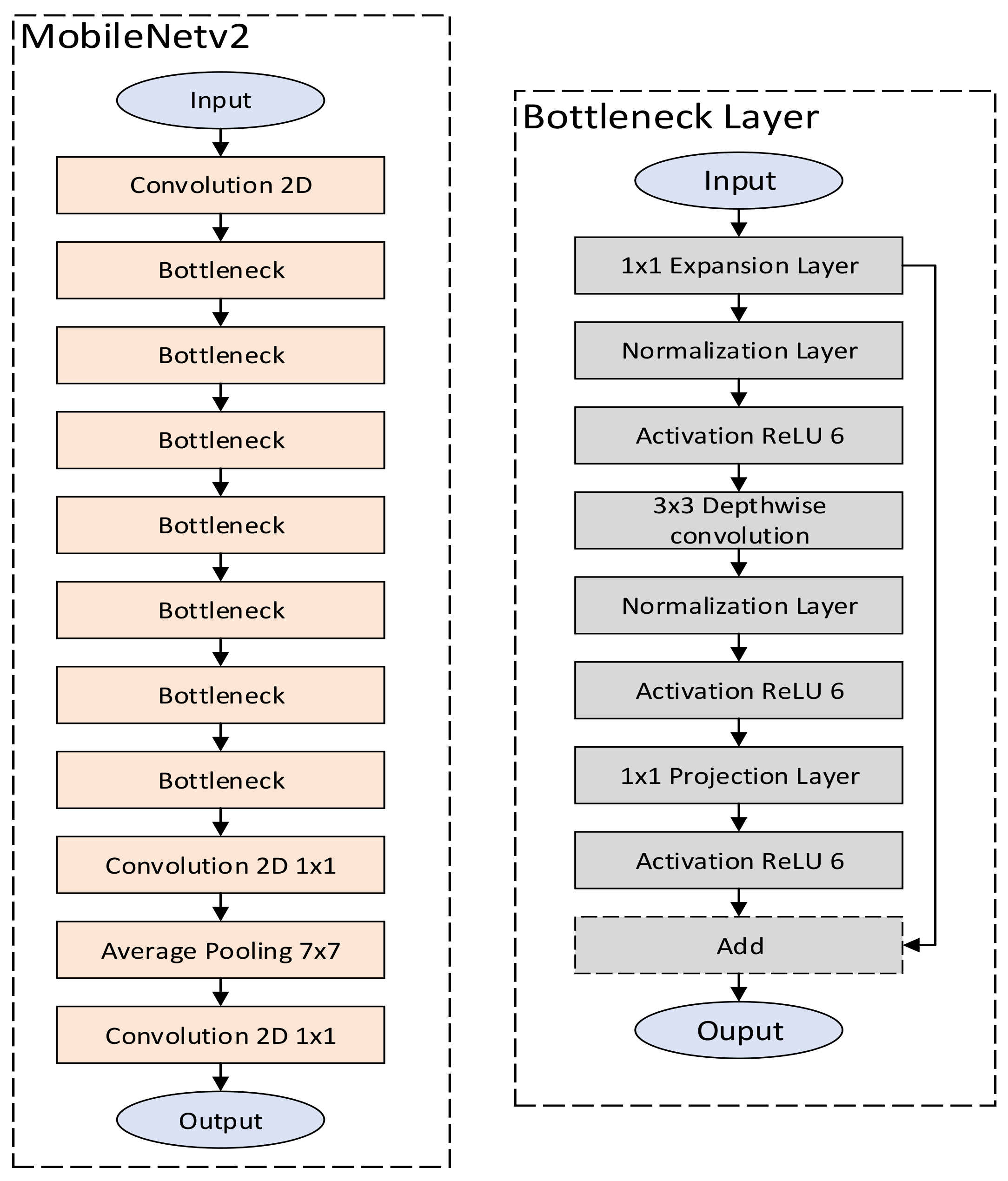
Regarding the implementation of the computational logic, we deploy separate HLS accelerators for each MobileNetV2 layer type, i.e., standard, depth-wise and point-wise convolution. Each accelerator is specialized in accelerating one convolution type only and utilizes the weight, input and output buffers for I/O operations. Below, we discuss the details of each layer type, and we provide the implementation strategy for the corresponding accelerators.
The SC can be described under the following equation:
where
y is the output matrix of the convolutional layer,
f is the activation function of each neuron,
C is the amount of weight channels,
is the height of the weight matrix,
is the width of the weight matrix,
X is the matrix of the layer input,
W is the matrix of the weight values and
B is the layer bias. Generally, the SC can be viewed as a dot product of input matrix and the weight matrix adjusted by an activation function, which normalizes the output within a numerical range limit. In our approach, we employ the
Wbuf and
Ibuf structures to temporarily store the weight and input data correspondingly, and we proceed in calculating their dot product. The output is stored on the local buffer
Obuf in order to reduce memory load/store operations, since it is used as input for the next layer.
The PW can be described using the following equation:
PW convolutions can be considered as a special case of SC where the weight (W) size is 1 (1 × 1 × 1 dimensions), and thus, the computational complexity of the PW is significantly reduced. Thus, a PW convolution utilizes a scalar weight value (referred to as a “point”) to perform the convolution operation with the whole sequence of input data. As a result, PW is used to combine the outputs created by previous layers without expanding the dimensions of the input matrix. Similarly to SC, we utilize the Wbuf, Ibuf and Obuf buffers to minimize BRAM access operations.
The equation that describes the DW operation for each weight channel can be written as follows:
DW, also called depth-wise separable convolution, separates the weights’ depth dimensions by performing a standard convolution operation for each channel separately. Country to the SC approach where weight channels are included in the SC operation, DW performs a SC for each channel and then concatenates the outputs into one multi-dimensional matrix.
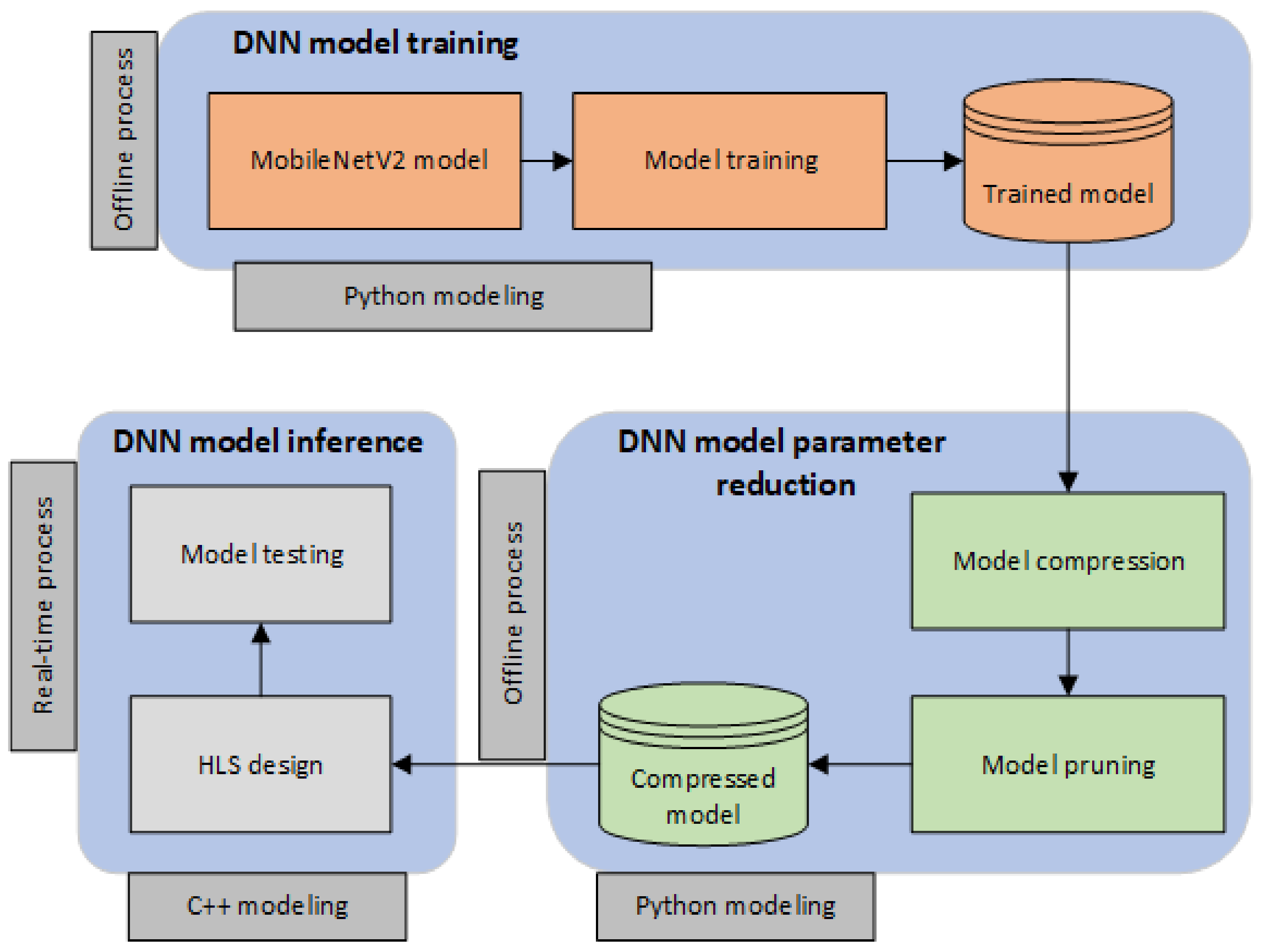
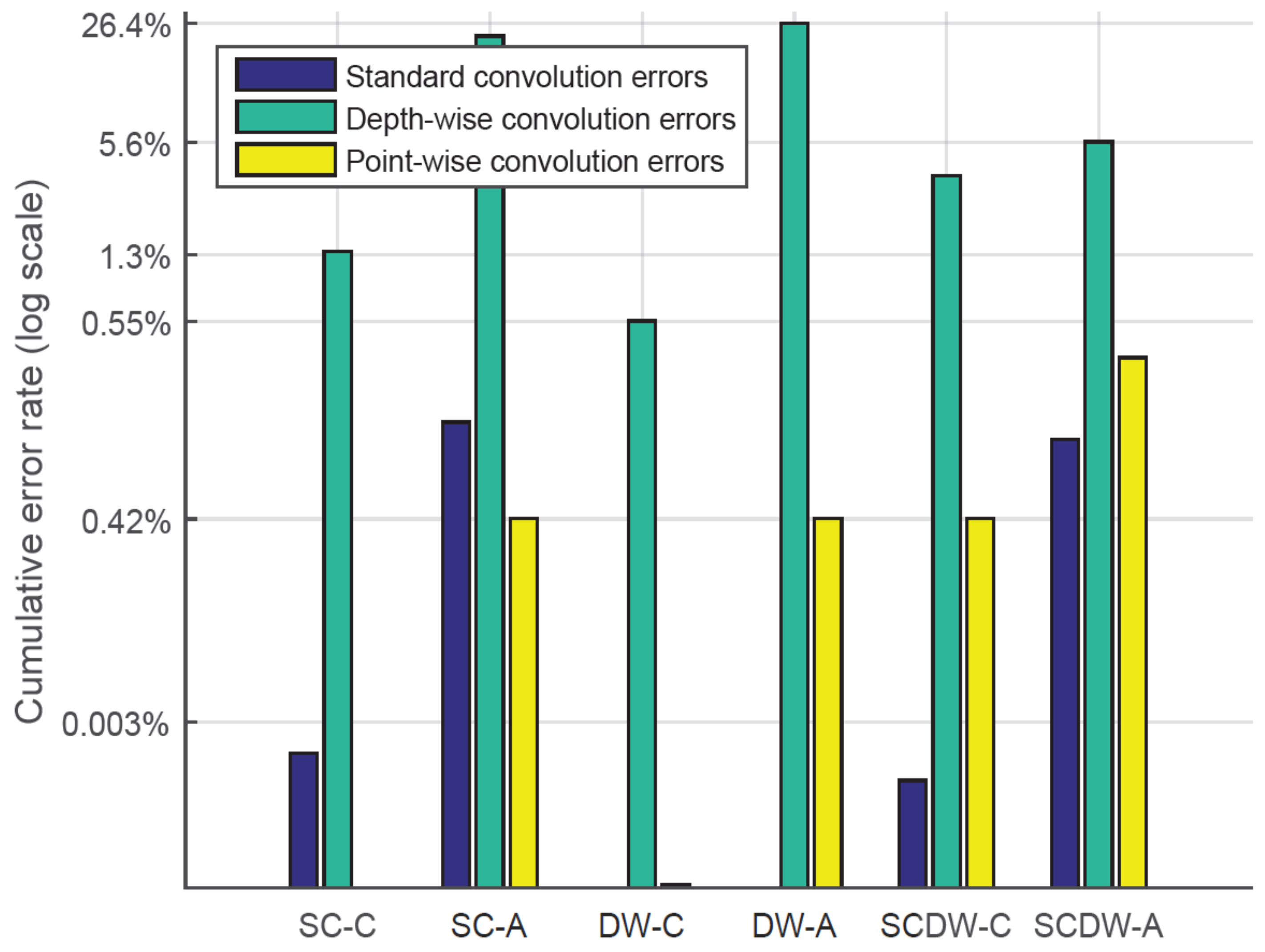
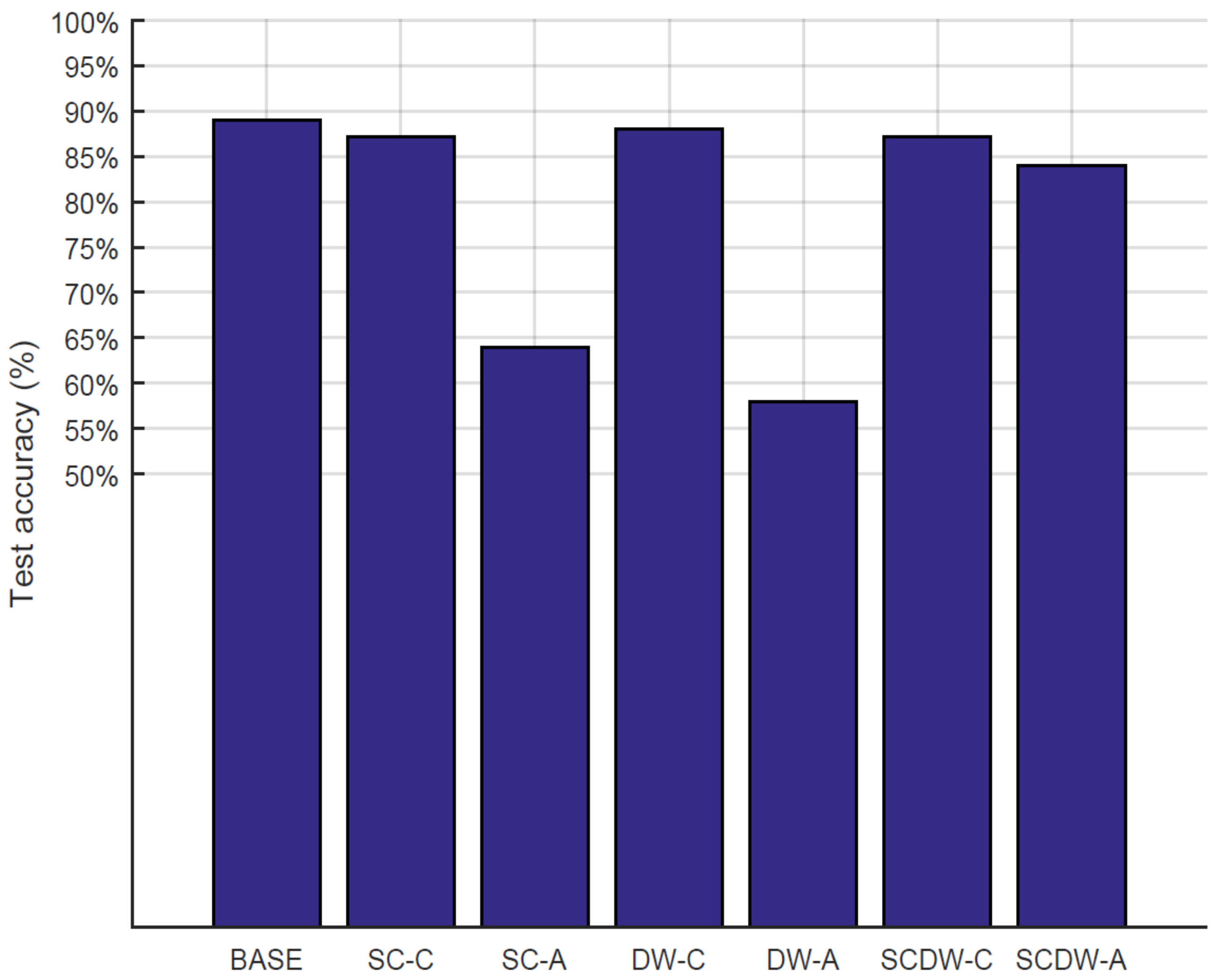
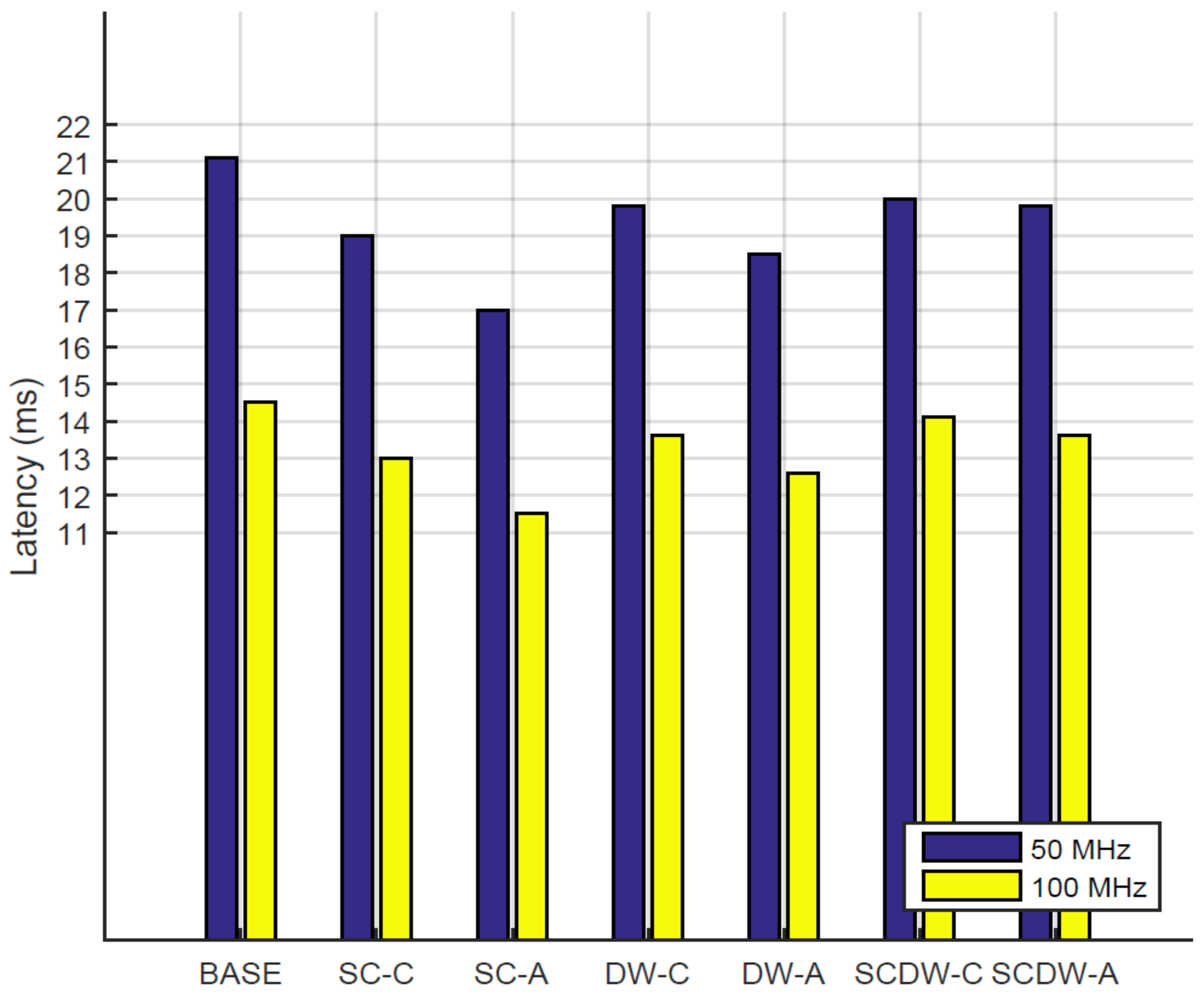
In this work, we explore how the parameter space affects the system performance in terms of inference (test) accuracy, layer errors, model size, inference latency, area and power requirements. Our approach is focused on such aspects since we are considering the real-time performance of a DNN in real-world applications. More specifically, we provide insights regarding the following parameter space.
Architectural support. We provide a simple yet effective hardware architecture to accelerate the three convolution types that reside within the MobileNetV2 model. We also deploy data buffers to reduce the BRAM–accelerator communication overhead. By employing such an approach, we attempt to explore whether hardware accelerators (in HLS) are capable of supporting real-time DNN applications.
Model compression. We utilize a well-established model compression scheme to analyze its efficacy in DNN model size and inference latency.
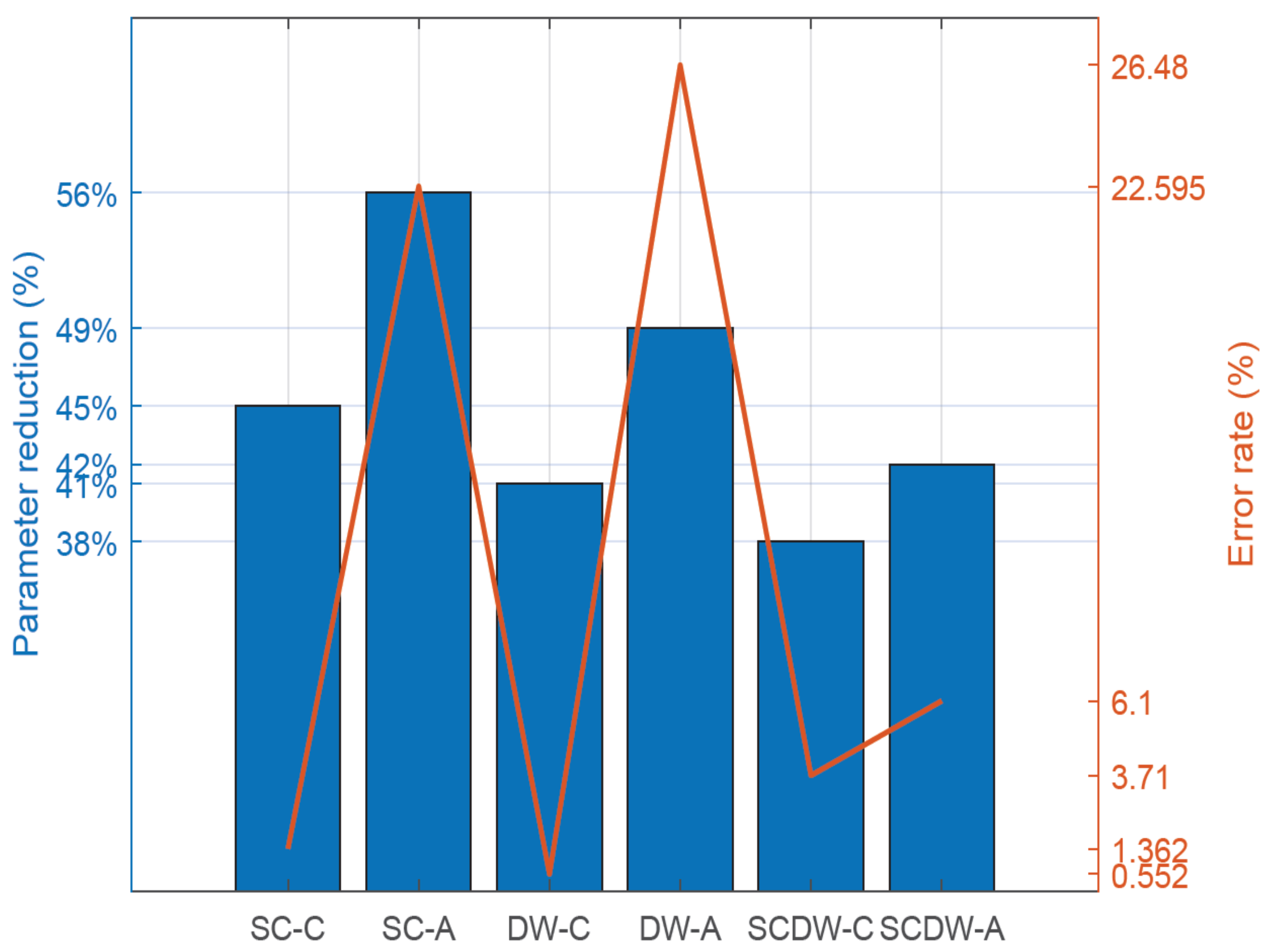
Pruning approach. We implement a conservative and an aggressive pruning mechanism to study their effects on the model performance.
Sparse data storage. For the efficient storage of the sparse MobileNetV2, we deployed representations that exploit the sparsity of the matrices. As a result, we perform all data storage using sparse data structures, i.e., Compressed Sparse Row and Compressed Sparse Column (CSR/C). More particularly, these two approaches leverage the high amount of zero entries and eliminate them by replacing the matrix with a three-vector representation scheme. For example, the CSR approach scans the non-zero elements of the initial matrix in row-major order and stores them in a vector. In parallel, it creates two additional vectors, where the first stores the respective column indices and the second one stores pointers that designate where the new row begins.
Clock frequency. We deploy designs with two different clock frequencies to examine their effects in the inference latency and power consumption of the system.



 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}