
A Machine Learning Framework for Automated Accident Detection Based on Multimodal Sensors in Cars

 , , , ,
, , , ,  , and
, and
Abstract
:1. Introduction
- This paper is the first study investigating ML-based accident detection on basic in-car network data. Our work is a unique and innovative study on detecting real driving accidents from the most accessible and affordable data sources inside cars.
- This paper presents a detailed ML framework based on the PRC introduced in Figure 1 to perform accident detection using basic in-car network data. In addition, it uses this framework to provide a comparison of state-of-the-art ML feature extraction techniques, applicable on in-car sensor data for accident detection based on SHRP2 NDS crash data set providing gas-pedal position, speed, steering angle and acceleration sensors. Using this framework, we obtain very promising results for automated accident detection based on a naturalistic data set.
2. Related Work
2.1. Driving Behavior Analysis
2.2. Accident Detection
2.2.1. Rule-Based Accident Detection
2.2.2. ML-Based Accident Detection
3. Materials and Methods
3.1. Data Acquisition
SHRP2 Data Set
3.2. Data Pre-Processing and Segmentation
3.3. Feature Extraction
3.3.1. Feature Extraction Based on Handcrafted Features (HC)
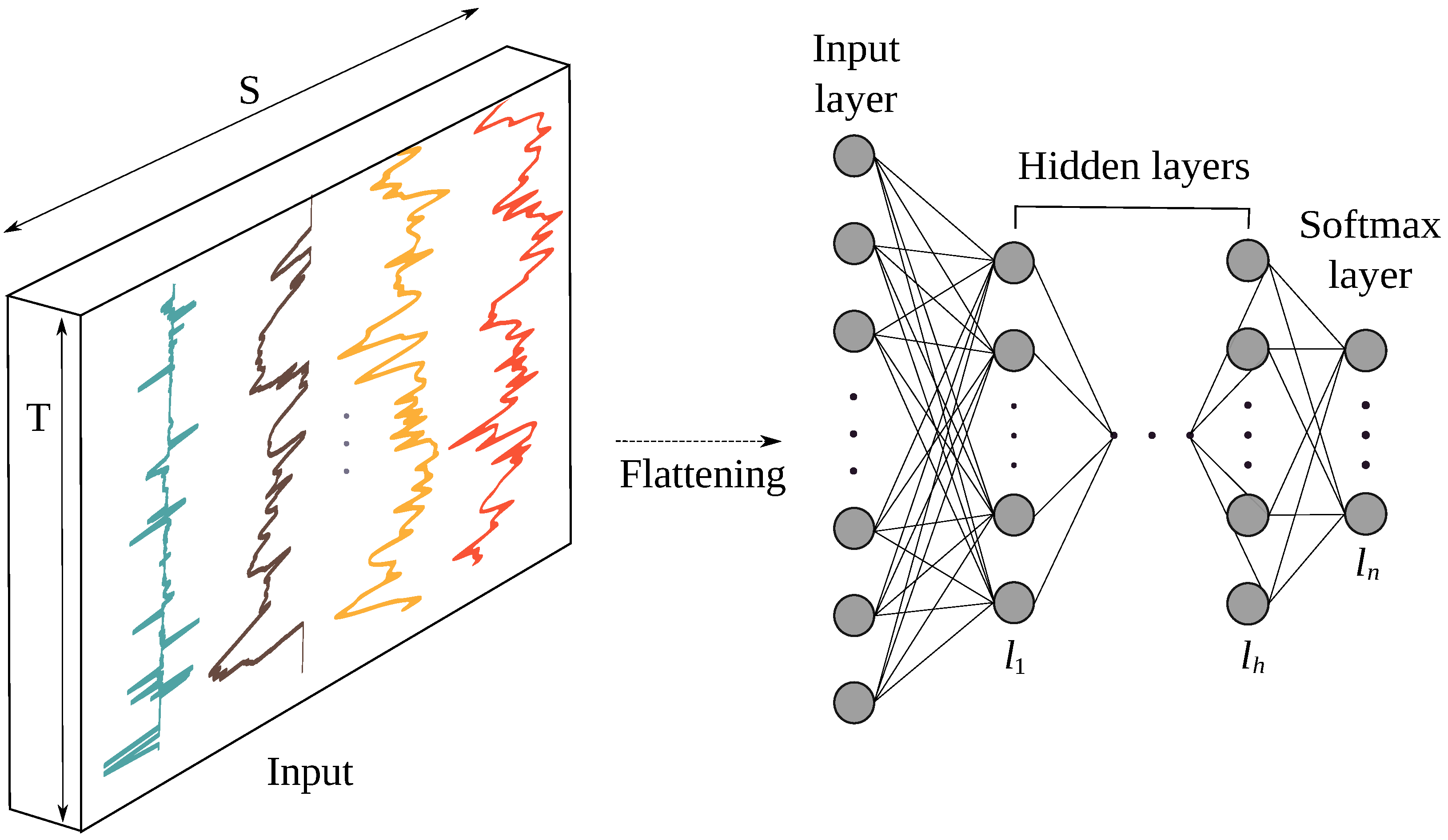
3.3.2. Feature Learning Based on Multi-Layer-Perceptron (MLP)
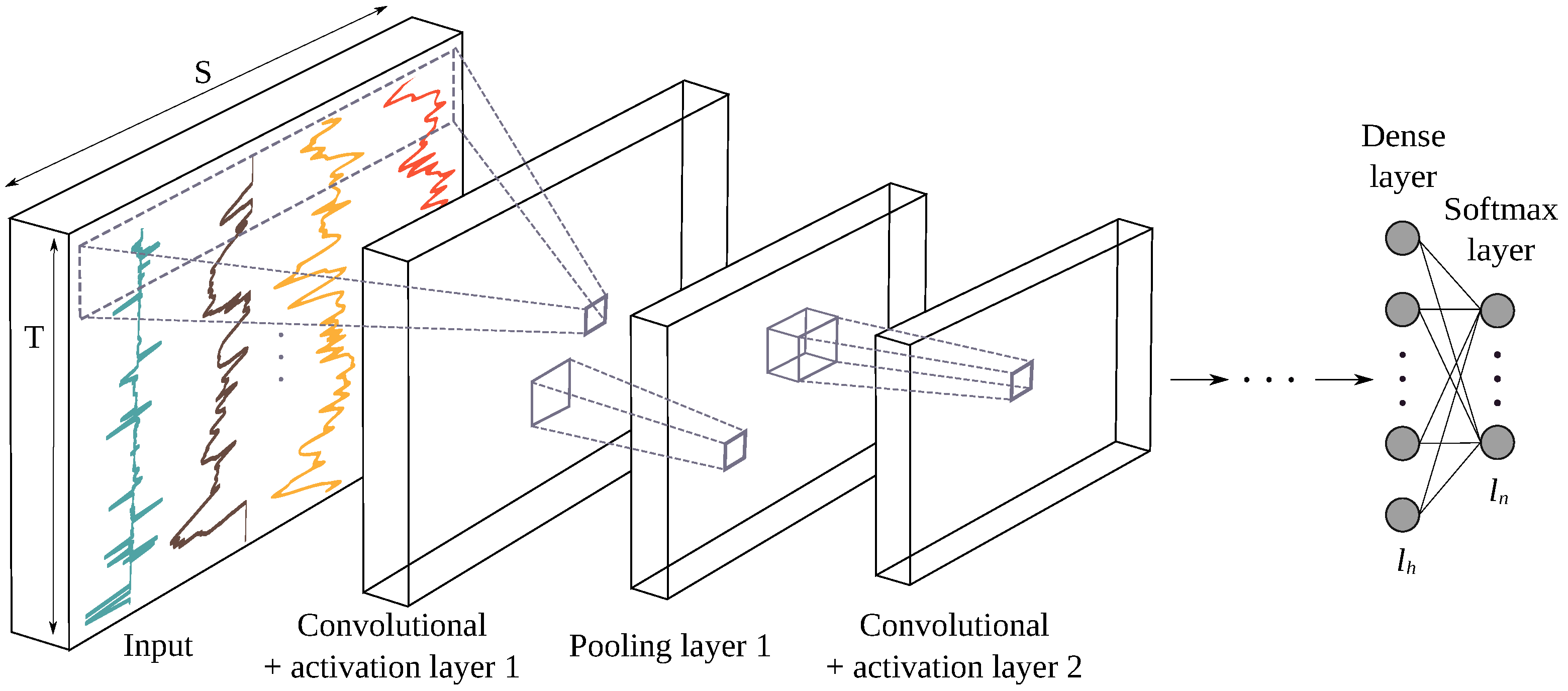
3.3.3. Feature Learning Based on Convolutional Neural Networks (CNN)
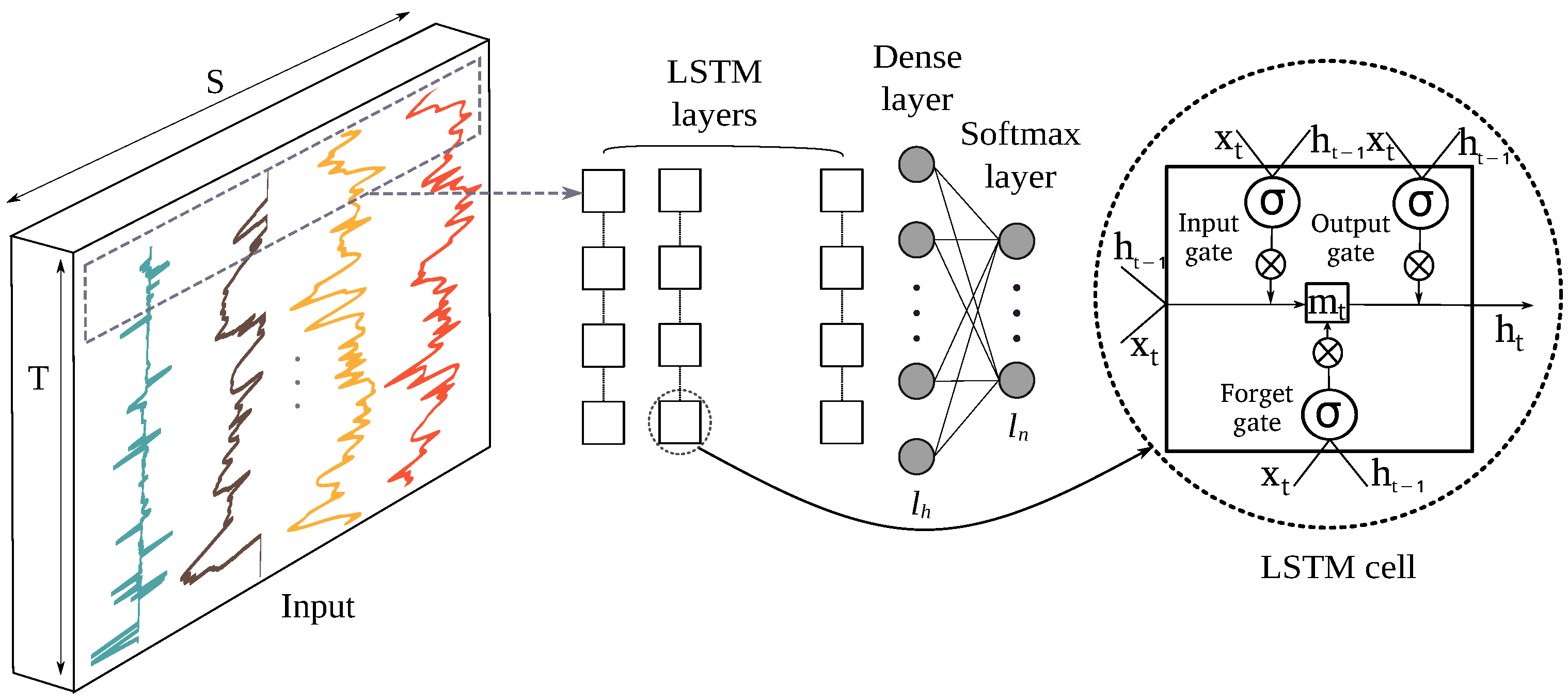
3.3.4. Feature Learning Based on Long Short-Term Memory (LSTM)
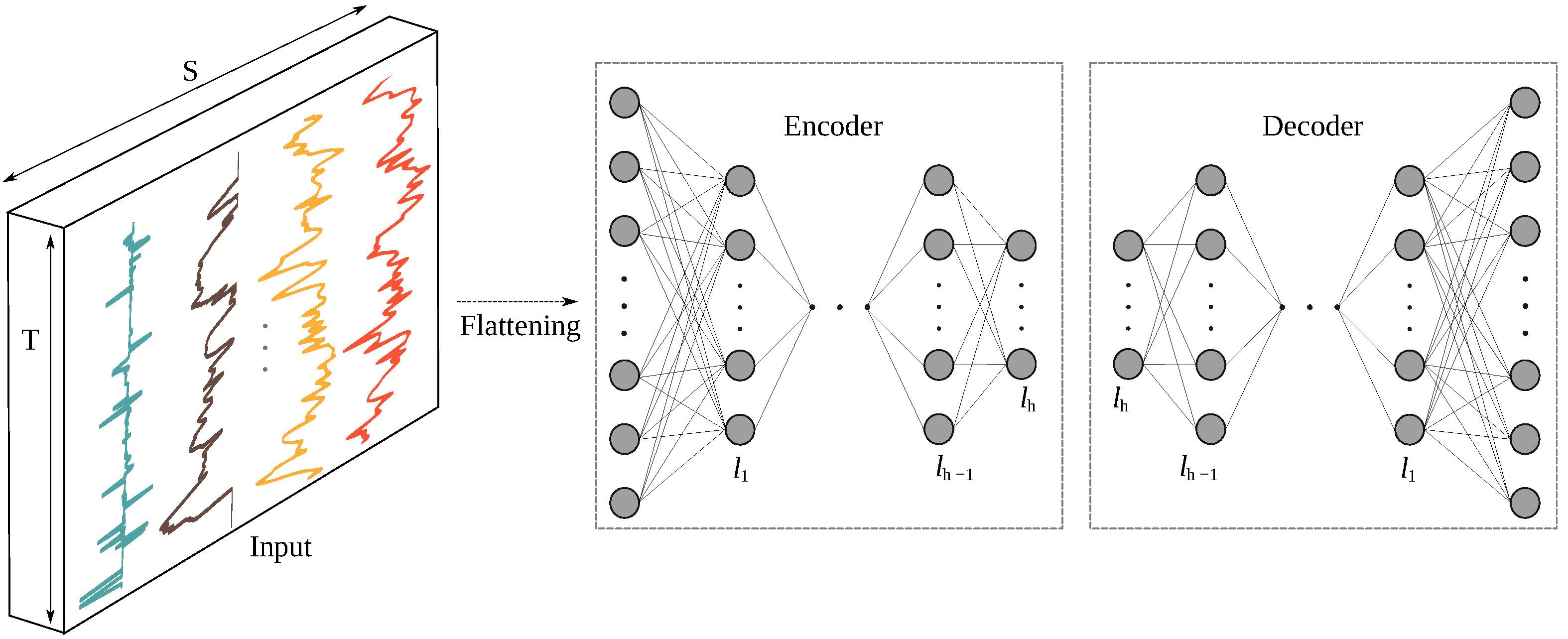
3.3.5. Feature Learning Based on an Autoencoder (AE)
3.4. Classification
4. Experiments and Results
- HC:
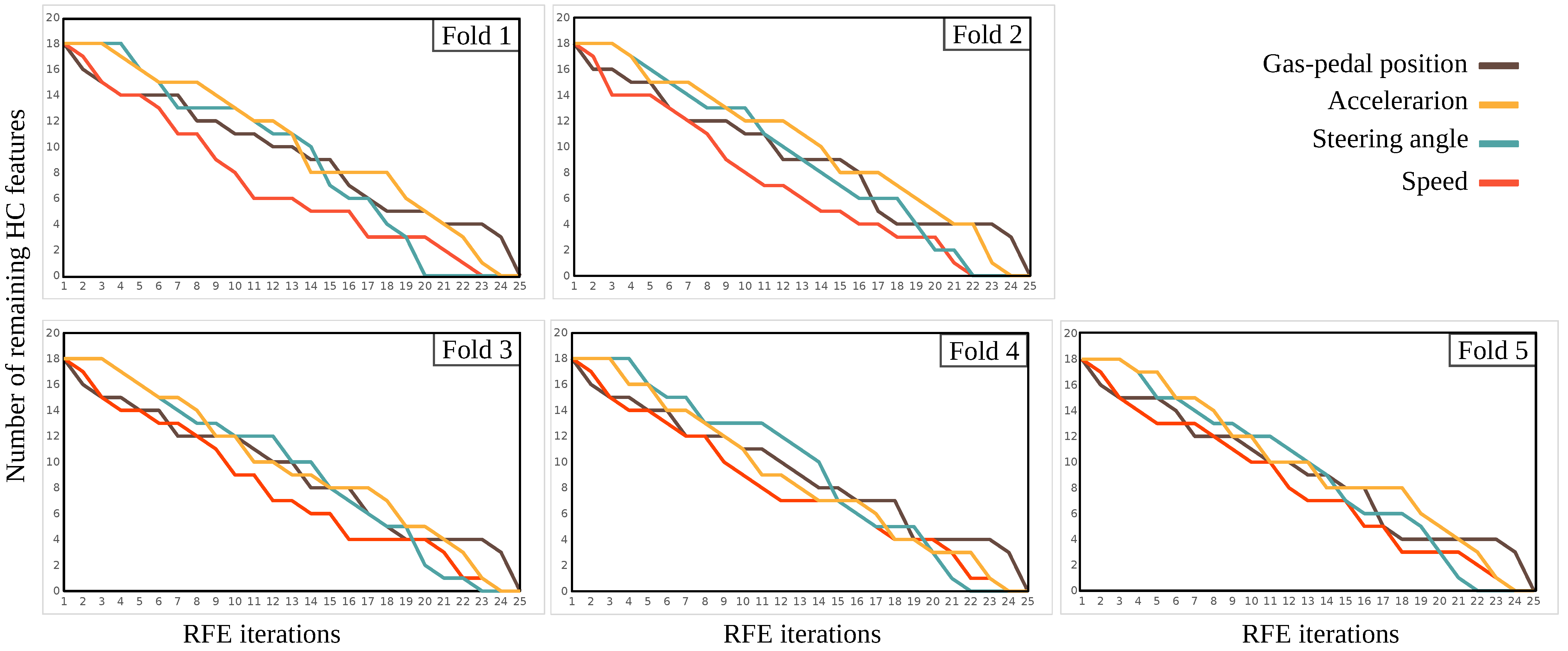
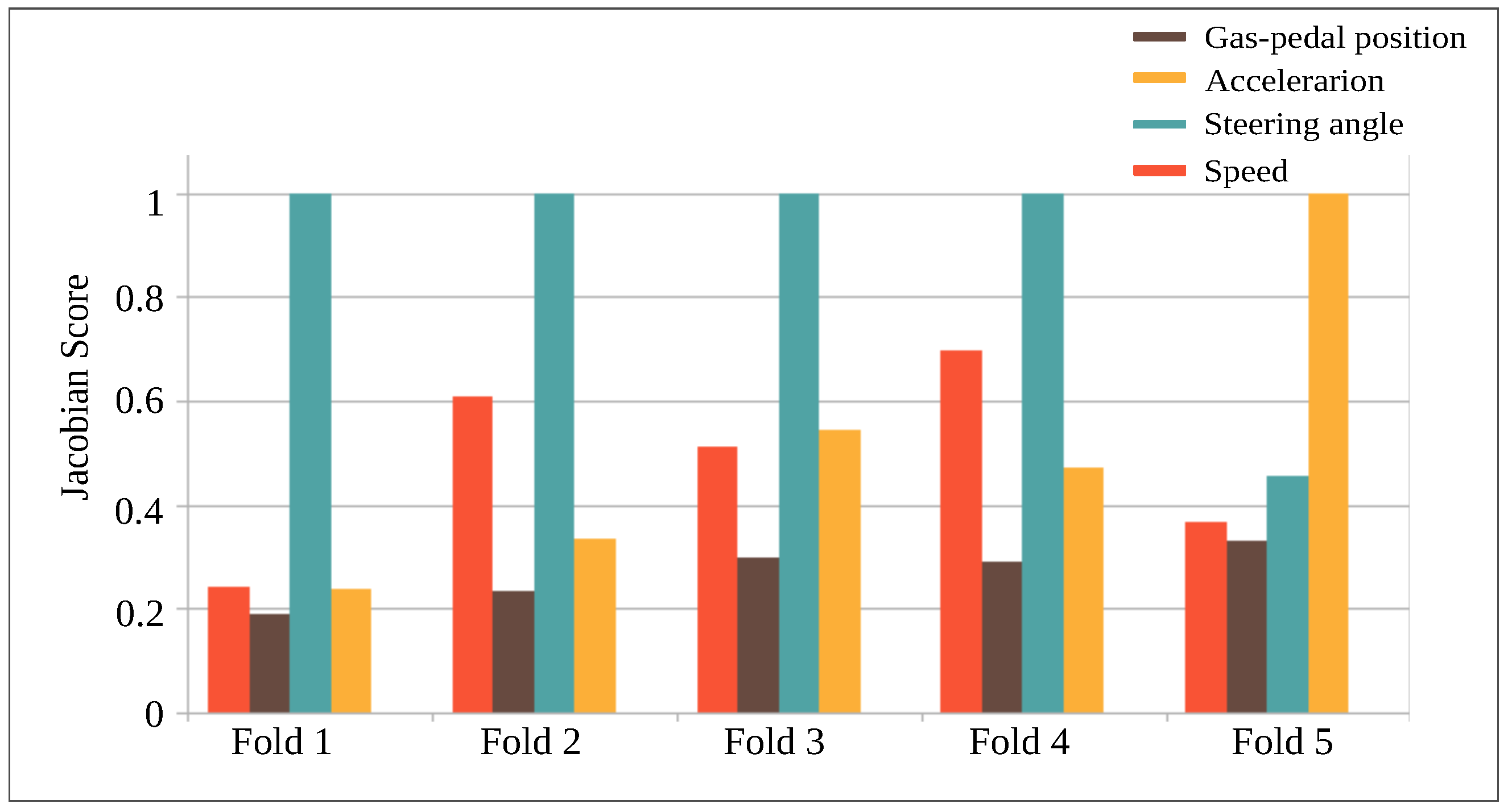
- The HC features consisted of 15 statistical values directly computed on the time series, and 3 frequency-related on their power spectrum were computed on each sensor individually and concatenated together. Then RFE feature selection with an elimination size of three was applied.
- MLP:
- The MLP architecture used in this study contained three dense layers and REctified Linear Units (RELU) activation. MLP usually takes 1D inputs only, therefore a flattened layer was used to convert the 2D input to 1D. According to the recommendations of [14,56], a batch normalization layer was placed directly after the network input to improve results. Three fully connected dense layers with RELU activation function, containing 2000 neurons each, and a final softmax layer built up the MLP network used for our study (see Table 3). In Table 3, the values for the hyper-parameters used for feature learning approaches in this study are shown. Optimizing the hyper-parameters of DNNs is an important and difficult topic. Optimal parameters for our models were chosen after testing several manually selected configurations. Manual hyper-parameter selection is the default approach in the literature due to the absence of other more elaborated high performing approaches.
- CNN:
- As listed in Table 3, the CNN layout consisted of three blocks of batch normalization and a convolutional layer with RELU activation followed by dense and pooling layers. The CNN design was based on [14] with some modifications, including a reduction in the size of the convolutional kernels and an increase pooling window size, while keeping the amount of kernels the same for each block.
- LSTM:
- The values of all hyper-parameters for the LSTM architecture are provided in Table 3. Like other ANNs used in this paper, a batch normalization layer was added at the beginning and a dense and softmax layers at the end of the network. The gate activation used in the LSTM cells is a sigmond function, and in the dense layers, a tangent activation function was used.
- AE:
- The AE architecture consisted of simple dense layers (three dense layers for the Encoder and then three for the Decoder designed as a mirror), with ReLU for the activation function. Different numbers of dense layers were tested, and the one achieving the best performance is presented in Table 3.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Parameter | Value/ Type |
|---|---|---|
| MLP | . # Dense layers | 3 |
| . # Neurons in each layer | 2000 | |
| . Activation function | ReLU | |
| CNN | . # Conv. blocks | 3 |
| . Conv. kernel size for blocks 1, 2 and 3 | (5, 1), (4, 1), (3, 1) | |
| . # Conv.kernels in each block | 50 | |
| . Pool size for blocks 1, 2 and 3 | (2, 1), (3, 1), (4, 1) | |
| . # Neurons in the dense layer | 1000 | |
| . Activation function for the Conv. blocks | Tanh | |
| . Activation function for the dense layer | ReLU | |
| LSTM | . # LSTM layers | 2 |
| . # Output dimensions for each LSTM cell | 600 | |
| . # Neurons in the dense layer | 512 | |
| . Activation function for the dense layer | ReLU | |
| AE | . # Encoder dense layers | 3 |
| . # Neurons in layers 1, 2 and 3 | 5000, 3000, 1000 | |
| . Activation function | ReLU |
5. Analysis
6. Conclusions
- It is possible to obtain promising results with ML for the detection of accidents using basic in-car sensor data.
- A deep learning feature extraction method performs better in comparison with HC, and unsupervised feature extraction remarkably achieves the second best performance score.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- World Health Organization. Global Status Report on Road Safety 2018: Summary; Technical Report; World Health Organization: Geneva, Switzerland, 2018. [Google Scholar]
- Bergasa, L.M.; Almería, D.; Almazán, J.; Yebes, J.J.; Arroyo, R. Drivesafe: An app for alerting inattentive drivers and scoring driving behaviors. In Proceedings of the 2014 IEEE Intelligent Vehicles Symposium Proceedings, Dearborn, MI, USA, 8–11 June 2014; pp. 240–245. [Google Scholar]
- Donnelly, B.R.; Schabel, D.; Blatt, A.J.; Carter, A. The automated collision notification system. In Proceedings of the Transportation Recording: 2000 and Beyond. International Symposium on Transportation Recorders, Arlington, VA, USA, 3–5 May 1999. [Google Scholar]
- Meiring, G.A.M.; Myburgh, H.C. A review of intelligent driving style analysis systems and related artificial intelligence algorithms. Sensors 2015, 15, 30653–30682. [Google Scholar] [CrossRef] [PubMed]
- Zaldivar, J.; Calafate, C.T.; Cano, J.C.; Manzoni, P. Providing accident detection in vehicular networks through OBD-II devices and Android-based smartphones. In Proceedings of the 2011 IEEE 36th Conference on Local Computer Networks, Washington, DC, USA, 4–7 October 2011; pp. 813–819. [Google Scholar]
- Kusano, K.; Gabler, H.C. Comparison and validation of injury risk classifiers for advanced automated crash notification systems. Traffic Inj. Prev. 2014, 15, S126–S133. [Google Scholar] [CrossRef] [PubMed]
- Nishimoto, T.; Mukaigawa, K.; Tominaga, S.; Lubbe, N.; Kiuchi, T.; Motomura, T.; Matsumoto, H. Serious injury prediction algorithm based on large-scale data and under-triage control. Accid. Anal. Prev. 2017, 98, 266–276. [Google Scholar] [CrossRef] [PubMed]
- Gulino, M.S.; Di Gangi, L.; Sortino, A.; Vangi, D. Injury risk assessment based on pre-crash variables: The role of closing velocity and impact eccentricity. Accid. Anal. Prev. 2021, 150, 105864. [Google Scholar] [CrossRef]
- Available online: www.thyssenkrupp-automotive-technology.com/en/products-and-services/carvaloo (accessed on 16 February 2022).
- Transportation Research Board of the National Academy of Sciences. The 2nd Strategic Highway Research Program Naturalistic Driving Study Dataset. 2013. Available online: https://insight.shrp2nds.us (accessed on 10 September 2020).
- Leduc, G. Road traffic data: Collection methods and applications. Work. Pap. Energy Transp. Clim. Chang. 2008, 1, 1–55. [Google Scholar]
- Pour, H.H.; Wegmeth, L.; Kordes, A.; Grzegorzek, M.; Wismüller, R. Feature Extraction and Classification of Sensor Signals in Cars Based on a Modified Codebook Approach. In Proceedings of the International Conference on Computer Recognition Systems; Springer: Berlin/Heidelberg, Germany, 2019; pp. 184–194. [Google Scholar]
- Alvi, U.; Khattak, M.A.K.; Shabir, B.; Malik, A.W.; Muhammad, S.R. A Comprehensive Study on IoT Based Accident Detection Systems for Smart Vehicles. IEEE Access 2020, 8, 122480–122497. [Google Scholar] [CrossRef]
- Li, F.; Shirahama, K.; Nisar, M.A.; Köping, L.; Grzegorzek, M. Comparison of feature learning methods for human activity recognition using wearable sensors. Sensors 2018, 18, 679. [Google Scholar] [CrossRef] [Green Version]
- Ali, H.M.; Alwan, Z.S. Car Accident Detection and Notification System Using Smartphone; LAP LAMBERT Academic Publishing: Saarbrucken, Germany, 2017. [Google Scholar]
- Amin, M.S.; Jalil, J.; Reaz, M.B.I. Accident detection and reporting system using GPS, GPRS and GSM technology. In Proceedings of the 2012 International Conference on Informatics, Electronics & Vision (ICIEV), Dhaka, Bangladesh, 18–19 May 2012; pp. 640–643. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 818–833. [Google Scholar]
- Jakobsen, K.; Mouritsen, S.C.; Torp, K. Evaluating eco-driving advice using GPS/CANBus data. In Proceedings of the 21st ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Orlando, FL, USA, 5–8 November 2013; pp. 44–53. [Google Scholar]
- Tefft, B.C. Reducing risk and improving traffic safety: Research on driver behavior and performance. Inst. Transp. Eng. ITE J. 2018, 88, 30–34. [Google Scholar]
- Ferreira, J.; Carvalho, E.; Ferreira, B.V.; de Souza, C.; Suhara, Y.; Pentland, A.; Pessin, G. Driver behavior profiling: An investigation with different smartphone sensors and machine learning. PLoS ONE 2017, 12, e0174959. [Google Scholar]
- Al-Sultan, S.; Al-Bayatti, A.H.; Zedan, H. Context-aware driver behavior detection system in intelligent transportation systems. IEEE Trans. Veh. Technol. 2013, 62, 4264–4275. [Google Scholar] [CrossRef]
- Zinebi, K.; Souissi, N.; Tikito, K. Driver Behavior Analysis Methods: Applications oriented study. In Proceedings of the 3rd International Conference on Big Data, Cloud and Application (BDCA 2018), Kenitra, Morocco, 4–5 April 2018. [Google Scholar]
- Khalid, S.; Khalil, T.; Nasreen, S. A survey of feature selection and feature extraction techniques in machine learning. In Proceedings of the 2014 Science and Information Conference, Shenzhen, China, 26–28 April 2014; pp. 372–378. [Google Scholar]
- Ang, J.S.; Ng, K.W.; Chua, F.F. Modeling Time Series Data with Deep Learning: A Review, Analysis, Evaluation and Future Trend. In Proceedings of the 2020 8th International Conference on Information Technology and Multimedia (ICIMU), Selangor, Malaysia, 24–25 August 2020; pp. 32–37. [Google Scholar] [CrossRef]
- Mori, M.; Miyajima, C.; Angkititrakul, P.; Hirayama, T.; Li, Y.; Kitaoka, N.; Takeda, K. Measuring driver awareness based on correlation between gaze behavior and risks of surrounding vehicles. In Proceedings of the 2012 15th International IEEE Conference on Intelligent Transportation Systems, Anchorage, AK, USA, 16–19 September 2012; pp. 644–647. [Google Scholar]
- Bachoo, S.; Bhagwanjee, A.; Govender, K. The influence of anger, impulsivity, sensation seeking and driver attitudes on risky driving behaviour among post-graduate university students in Durban, South Africa. Accid. Anal. Prev. 2013, 55, 67–76. [Google Scholar] [CrossRef] [PubMed]
- Jahangiri, A.; Rakha, H.A.; Dingus, T.A. Adopting machine learning methods to predict red-light running violations. In Proceedings of the 2015 IEEE 18th International Conference on Intelligent Transportation Systems, Las Palmas, Spain, 15–18 September 2015; pp. 650–655. [Google Scholar]
- Ohn-Bar, E.; Trivedi, M.M. Beyond just keeping hands on the wheel: Towards visual interpretation of driver hand motion patterns. In Proceedings of the 17th International IEEE Conference on Intelligent Transportation Systems (ITSC), Qingdao, China, 8–11 October 2014; pp. 1245–1250. [Google Scholar]
- Lee, C.; Saccomanno, F.; Hellinga, B. Analysis of crash precursors on instrumented freeways. Transp. Res. Rec. 2002, 1784, 1–8. [Google Scholar] [CrossRef]
- Bagdadi, O. Assessing safety critical braking events in naturalistic driving studies. Transp. Res. Part F Traffic Psychol. Behav. 2013, 16, 117–126. [Google Scholar] [CrossRef]
- Bagdadi, O.; Várhelyi, A. Development of a method for detecting jerks in safety critical events. Accid. Anal. Prev. 2013, 50, 83–91. [Google Scholar] [CrossRef] [PubMed]
- Harlow, C.; Wang, Y. Automated accident detection system. Transp. Res. Rec. 2001, 1746, 90–93. [Google Scholar] [CrossRef]
- Kamijo, S.; Matsushita, Y.; Ikeuchi, K.; Sakauchi, M. Traffic monitoring and accident detection at intersections. IEEE Trans. Intell. Transp. Syst. 2000, 1, 108–118. [Google Scholar] [CrossRef] [Green Version]
- Bacon, J.; Bejan, A.I.; Beresford, A.R.; Evans, D.; Gibbens, R.J.; Moody, K. Using real-time road traffic data to evaluate congestion. In Dependable and Historic Computing; Springer: Berlin/Heidelberg, Germany, 2011; pp. 93–117. [Google Scholar]
- White, J.; Thompson, C.; Turner, H.; Dougherty, B.; Schmidt, D.C. Wreckwatch: Automatic traffic accident detection and notification with smartphones. Mob. Netw. Appl. 2011, 16, 285–303. [Google Scholar] [CrossRef]
- Chuan-zhi, L.; Ru-fu, H.; Ye, H.w. Method of freeway incident detection using wireless positioning. In Proceedings of the 2008 IEEE International Conference on Automation and Logistics, Qingdao, China, 1–3 September 2008; pp. 2801–2804. [Google Scholar]
- Sheu, J.B. A sequential detection approach to real-time freeway incident detection and characterization. Eur. J. Oper. Res. 2004, 157, 471–485. [Google Scholar] [CrossRef]
- Faiz, A.B.; Imteaj, A.; Chowdhury, M. Smart vehicle accident detection and alarming system using a smartphone. In Proceedings of the 2015 International Conference on Computer and Information Engineering (ICCIE), Rajshahi, Bangladesh, 26–27 November 2015; pp. 66–69. [Google Scholar]
- Ahmed, V.; Jawarkar, N.P. Design of low cost versatile microcontroller based system using cell phone for accident detection and prevention. In Proceedings of the 2013 6th International Conference on Emerging Trends in Engineering and Technology, Nagpur, India, 16–18 December 2013; pp. 73–77. [Google Scholar]
- Stisen, A.; Blunck, H.; Bhattacharya, S.; Prentow, T.S.; Kjærgaard, M.B.; Dey, A.; Sonne, T.; Jensen, M.M. Smart devices are different: Assessing and mitigatingmobile sensing heterogeneities for activity recognition. In Proceedings of the 13th ACM Conference on Embedded Networked Sensor Systems, Seoul, Korea, 1–4 November 2015; pp. 127–140. [Google Scholar]
- Ozbayoglu, M.; Kucukayan, G.; Dogdu, E. A real-time autonomous highway accident detection model based on big data processing and computational intelligence. In Proceedings of the 2016 IEEE International Conference on Big Data (Big Data), Washington, DC, USA, 5–8 December 2016; pp. 1807–1813. [Google Scholar]
- Pan, B.; Wu, H. Urban traffic incident detection with mobile sensors based on SVM. In Proceedings of the 2017 XXXIInd General Assembly and Scientific Symposium of the International Union of Radio Science (URSI GASS), Montreal, QC, Canada, 19–26 August 2017; pp. 1–4. [Google Scholar]
- Ghosh, S.; Sunny, S.J.; Roney, R. Accident detection using convolutional neural networks. In Proceedings of the 2019 International Conference on Data Science and Communication (IconDSC), Bangalore, India, 1–2 March 2019; pp. 1–6. [Google Scholar]
- Osman, O.A.; Hajij, M.; Bakhit, P.R.; Ishak, S. Prediction of near-crashes from observed vehicle kinematics using machine learning. Transp. Res. Rec. 2019, 2673, 463–473. [Google Scholar] [CrossRef]
- Hankey, J.M.; Perez, M.A.; McClafferty, J.A. Description of the SHRP2 Naturalistic Database and the Crash, Near-Crash, and Baseline Data Sets; Technical Report; Virginia Tech Transportation Institute: Blacksburg, VA, USA, 2016. [Google Scholar]
- Cook, D.J.; Krishnan, N.C. Activity Learning: Discovering, Recognizing, and Predicting Human Behavior from Sensor Data; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Duda, R.O.; Hart, P.E. Pattern Classification; John Wiley & Sons: Hoboken, NJ, USA, 2006. [Google Scholar]
- Tang, J.; Alelyani, S.; Liu, H. Feature selection for classification: A review. Data Classification: Algorithms and Applications. 2014, p. 37. Available online: www.cvs.edu.in/upload/feature_selection_for_classification.pdf (accessed on 10 February 2022).
- Urbanowicz, R.J.; Meeker, M.; La Cava, W.; Olson, R.S.; Moore, J.H. Relief-based feature selection: Introduction and review. J. Biomed. Inf. 2018, 85, 189–203. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Zaremba, W.; Sutskever, I.; Vinyals, O. Recurrent neural network regularization. arXiv 2014, arXiv:1409.2329. [Google Scholar]
- Luong, M.T.; Sutskever, I.; Le, Q.V.; Vinyals, O.; Zaremba, W. Addressing the rare word problem in neural machine translation. arXiv 2014, arXiv:1410.8206. [Google Scholar]
- Gamboa, J.C.B. Deep learning for time-series analysis. arXiv 2017, arXiv:1701.01887. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Instance normalization: The missing ingredient for fast stylization. arXiv 2016, arXiv:1607.08022. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Pal, M. Random forest classifier for remote sensing classification. Int. J. Remote Sens. 2005, 26, 217–222. [Google Scholar] [CrossRef]
- Kramer, O. K-nearest neighbors. In Dimensionality Reduction with Unsupervised Nearest Neighbors; Springer: Berlin/Heidelberg, Germany, 2013; pp. 13–23. [Google Scholar]
- Myles, A.J.; Feudale, R.N.; Liu, Y.; Woody, N.A.; Brown, S.D. An introduction to decision tree modeling. J. Chemom. A J. Chemom. Soc. 2004, 18, 275–285. [Google Scholar] [CrossRef]
- Cutler, D.R.; Edwards Jr, T.C.; Beard, K.H.; Cutler, A.; Hess, K.T.; Gibson, J.; Lawler, J.J. Random forests for classification in ecology. Ecology 2007, 88, 2783–2792. [Google Scholar] [PubMed]
- Gouverneur, P.; Li, F.; Adamczyk, W.M.; Szikszay, T.M.; Luedtke, K.; Grzegorzek, M. Comparison of Feature Extraction Methods for Physiological Signals for Heat-Based Pain Recognition. Sensors 2021, 21, 4838. [Google Scholar] [CrossRef] [PubMed]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. Tensorflow: A system for large-scale machine learning. In Proceedings of the 12th {USENIX} Symposium on Operating Systems Design and Implementation ({OSDI} 16), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Zeiler, M.D. Adadelta: An adaptive learning rate method. arXiv 2012, arXiv:1212.5701. [Google Scholar]
- Browne, M.W. Cross-validation methods. J. Math. Psychol. 2000, 44, 108–132. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, J.; Nguyen, M.N.; San, P.P.; Li, X.; Krishnaswamy, S. Deep convolutional neural networks on multichannel time series for human activity recognition. In Proceedings of the Ijcai, Buenos Aires, Argentina, 25–31 July 2015; Volume 15, pp. 3995–4001. [Google Scholar]
- Zhao, B.; Lu, H.; Chen, S.; Liu, J.; Wu, D. Convolutional neural networks for time series classification. J. Syst. Eng. Electron. 2017, 28, 162–169. [Google Scholar]
- Sadouk, L. CNN approaches for time series classification. In Time Series Analysis-Data, Methods, and Applications; IntechOpen: London, UK, 2019; pp. 1–23. [Google Scholar]
- Li, F.; Shirahama, K.; Nisar, M.A.; Huang, X.; Grzegorzek, M. Deep Transfer Learning for Time Series Data Based on Sensor Modality Classification. Sensors 2020, 20, 4271. [Google Scholar] [CrossRef]
- Liu, H.; Zhou, M.; Liu, Q. An embedded feature selection method for imbalanced data classification. IEEE/CAA J. Autom. Sin. 2019, 6, 703–715. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]








| Variable Name | Unit | Description |
|---|---|---|
| Time stamp | millisecond | Time since beginning of trip, in milliseconds |
| Gas pedal position | none | Position of the accelerator pedal |
| collected from the vehicle network | ||
| and normalized using manufacturer specs | ||
| Speed network | km/h | Vehicle speed indicated on |
| speedometer collected from network | ||
| Steering wheel position | degree | Angular position and direction of |
| the steering wheel from neutral position |
| Handcrafted Features | ||
|---|---|---|
| Maximum | Average | Auto-correlation |
| Minimum | Skewness | First-order mean |
| Percentile 20 | Kurtosis | Second-order mean |
| Percentile 50 | Interquartile | Standard-deviation |
| Percentile 80 | Zero-crossing | Norm of the first-order mean |
| Spectral entropy | Spectral energy | Norm of the second-order mean |
| Methods | Accuracy | Weighted Score | Average Score |
|---|---|---|---|
| HC | 94.34 | 92.99 | 66.56 |
| MLP | 83.60 | 82.30 | 75.00 |
| CNN | 85.72 | 84.9 | 79.10 |
| LSTM | 76.81 | 72.01 | 57.90 |
| AE | 83.40 | 82.40 | 75.50 |
| Methods | Accuracy | Weighted Score | Average Score |
|---|---|---|---|
| HC | 94.97 | 93.95 | 71.78 |
| MLP | 84.06 | 83.57 | 77.47 |
| CNN | 85.72 | 84.19 | 78.39 |
| LSTM | 78.00 | 76.61 | 67.22 |
| AE | 84.22 | 83.74 | 77.67 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hozhabr Pour, H.; Li, F.; Wegmeth, L.; Trense, C.; Doniec, R.; Grzegorzek, M.; Wismüller, R. A Machine Learning Framework for Automated Accident Detection Based on Multimodal Sensors in Cars. Sensors 2022, 22, 3634. https://doi.org/10.3390/s22103634
Hozhabr Pour H, Li F, Wegmeth L, Trense C, Doniec R, Grzegorzek M, Wismüller R. A Machine Learning Framework for Automated Accident Detection Based on Multimodal Sensors in Cars. Sensors. 2022; 22(10):3634. https://doi.org/10.3390/s22103634
Chicago/Turabian StyleHozhabr Pour, Hawzhin, Frédéric Li, Lukas Wegmeth, Christian Trense, Rafał Doniec, Marcin Grzegorzek, and Roland Wismüller. 2022. "A Machine Learning Framework for Automated Accident Detection Based on Multimodal Sensors in Cars" Sensors 22, no. 10: 3634. https://doi.org/10.3390/s22103634