
Machine Learning Methods for Automatic Silent Speech Recognition Using a Wearable Graphene Strain Gauge Sensor



Abstract
:
1. Introduction
2. Materials and Methods
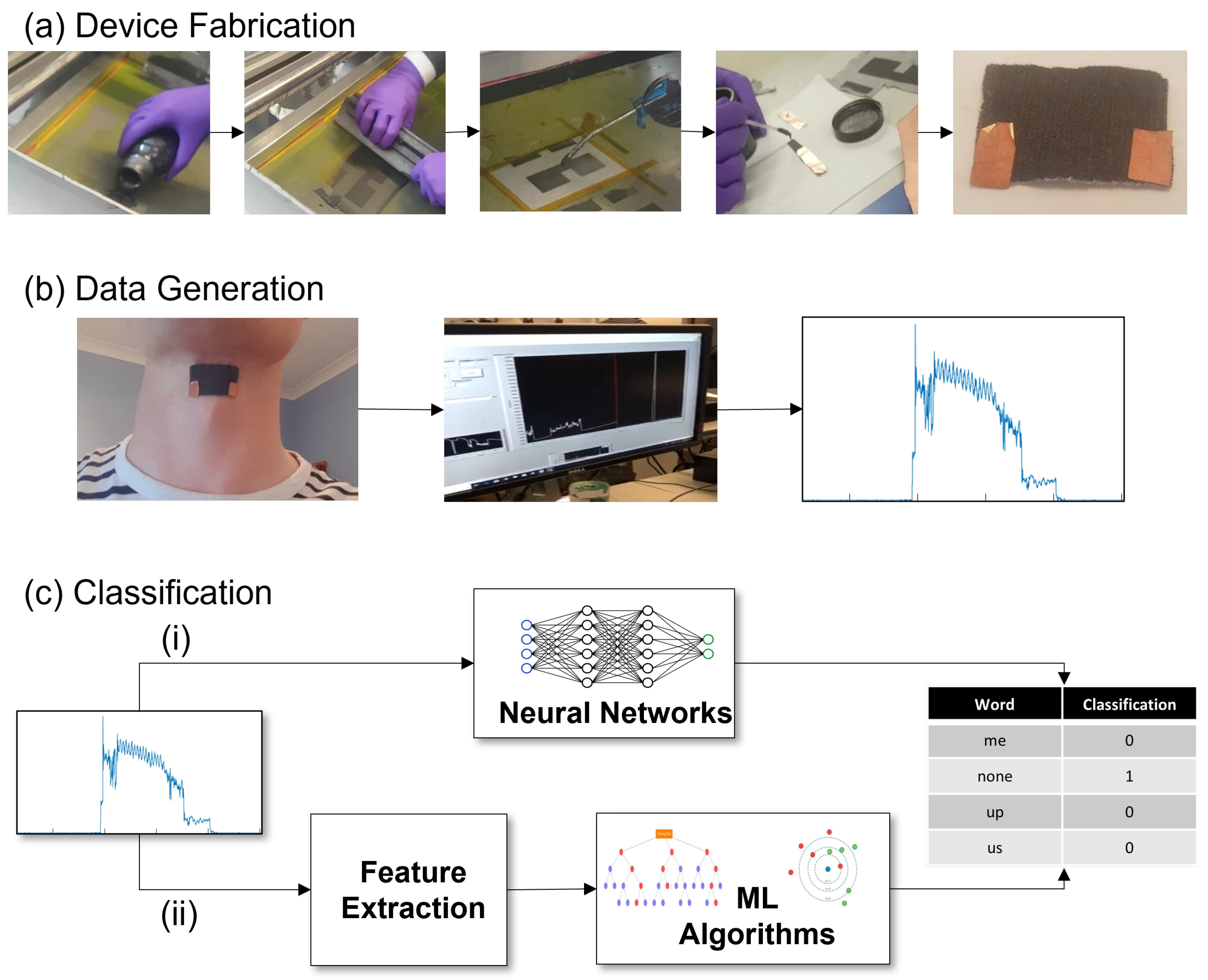
2.1. Device Fabrication
2.2. Data Generation
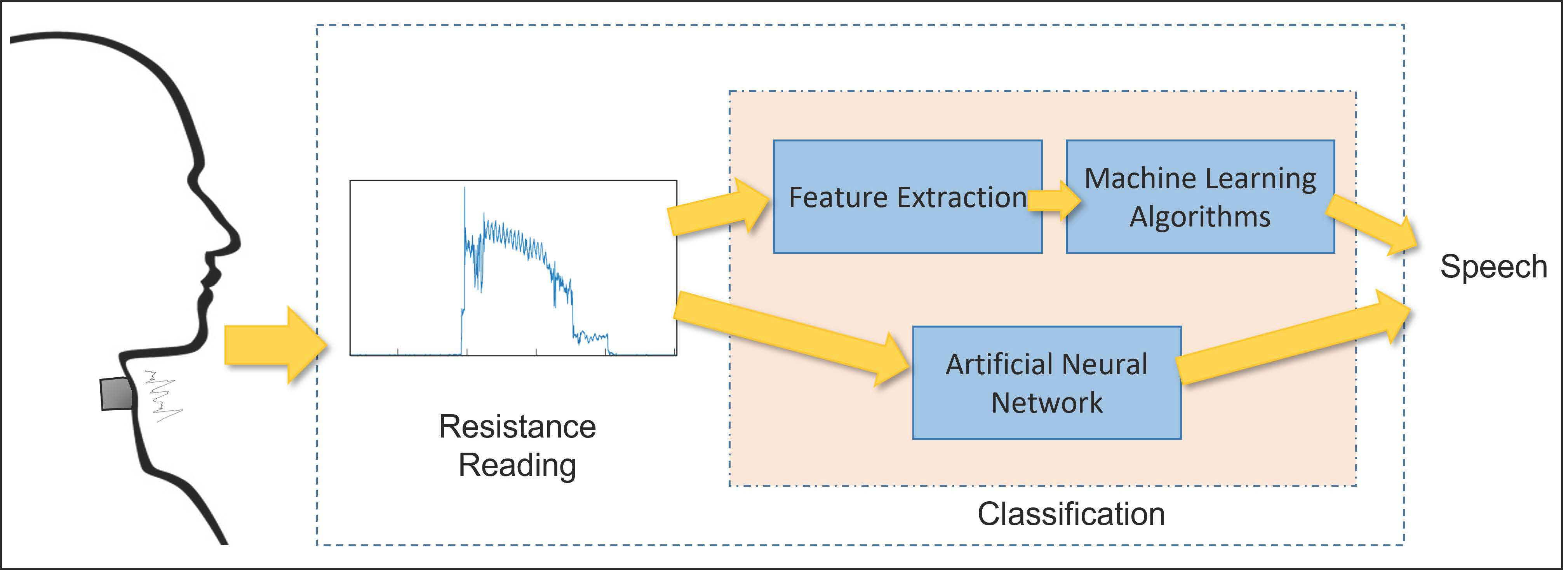
2.3. Classification
2.3.1. Feature Extraction
2.3.2. Machine Learning Algorithms
2.3.3. Neural Networks
3. Results and Discussion
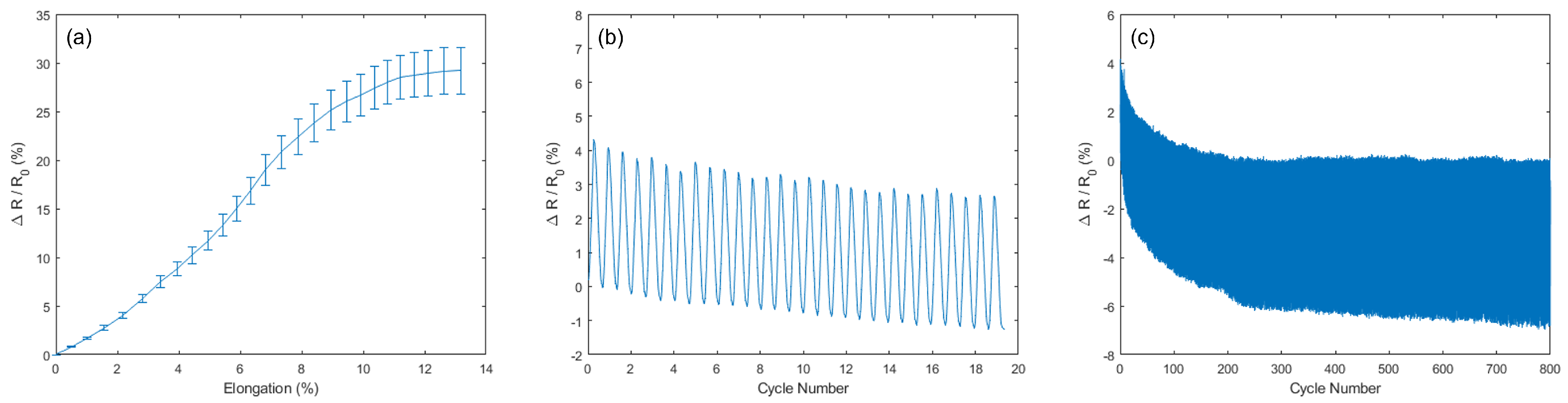
3.1. Device Characterisation
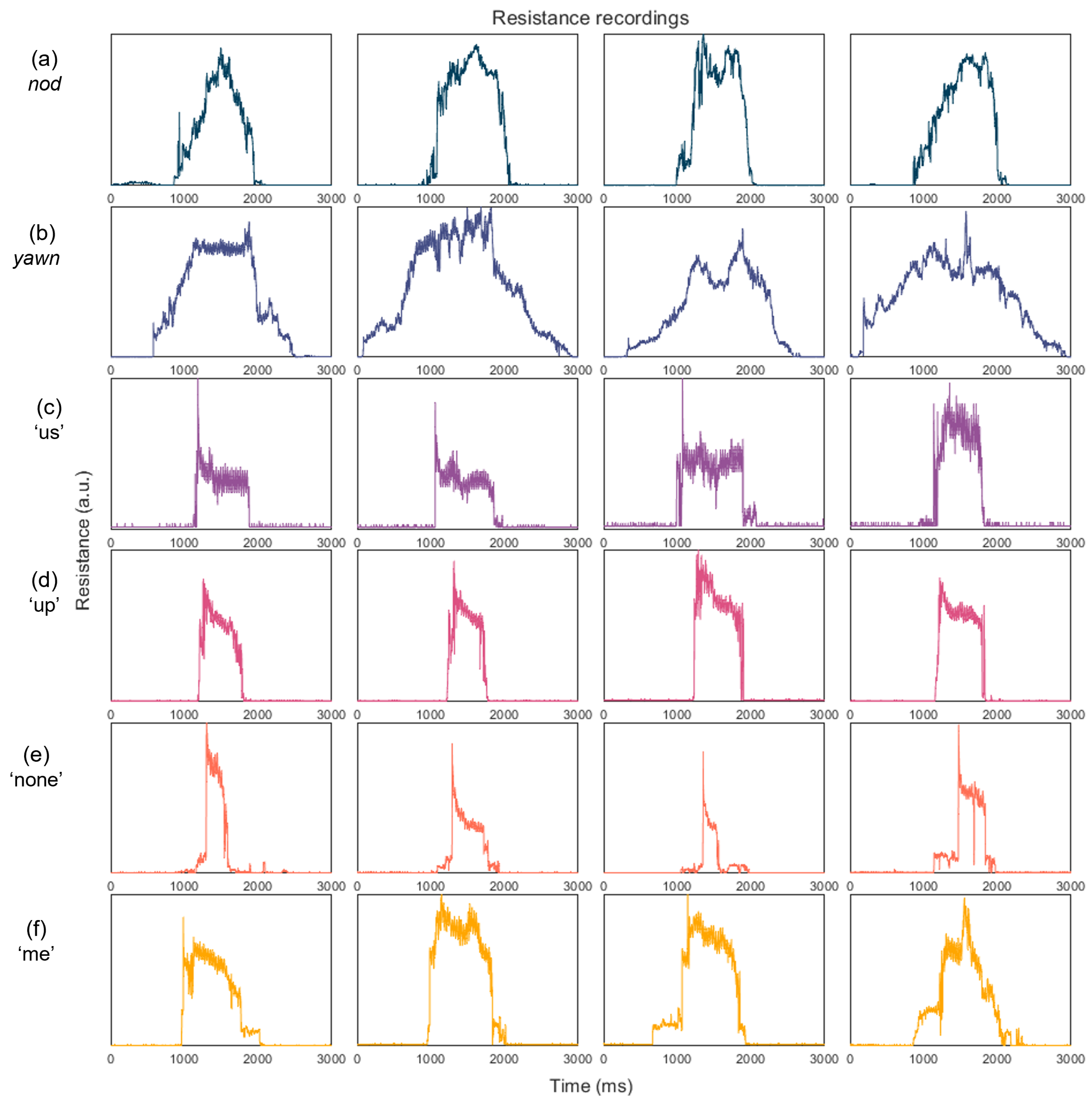
3.2. Dataset and Observations
3.3. Classification
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- World Report on Disability 2011; World Health Organization: Geneva, Switzerland, 2011.
- Bray, F.; Ferlay, J.; Soerjomataram, I.; Siegel, R.L.; Torre, L.A.; Jemal, A. Global cancer statistics 2018: Globocan estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA Cancer J. Clin. 2018, 68, 394–424. [Google Scholar] [CrossRef] [Green Version]
- Chung, J.S.; Zisserman, A. Lip reading in the wild. In Asian Conference on Computer Vision; Springer: Taipei, Taiwan, 2016; pp. 87–103. [Google Scholar]
- Chung, J.S.; Senior, A.; Vinyals, O.; Zisserman, A. Lip reading sentences in the wild. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3444–3453. [Google Scholar]
- Assael, Y.M.; Shillingford, B.; Whiteson, S.; De Freitas, N. Lipnet: End-to-end sentence-level lipreading. arXiv 2016, arXiv:1611.01599. [Google Scholar]
- Wand, M.; Schultz, T. Session-Independent EMG-Based Speech Recognition; Biosignals: Rome, Italy, 2011; pp. 295–300. [Google Scholar]
- Wand, M.; Janke, M.; Schultz, T. Tackling speaking mode varieties in EMG-based speech recognition. IEEE Trans. Biomed. Eng. 2014, 61, 2515–2526. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Wang, L.; Yang, T.; Li, X.; Zang, X.; Zhu, M.; Wang, K.; Wu, D.; Zhu, H. Wearable and highly sensitive graphene strain sensors for human motion monitoring. Adv. Funct. Mater. 2014, 24, 4666–4670. [Google Scholar] [CrossRef]
- Liu, Q.; Chen, J.; Li, Y.; Shi, G. High-performance strain sensors with fish-scale-like graphene-sensing layers for full-range detection of human motions. ACS Nano 2016, 10, 7901–7906. [Google Scholar] [CrossRef] [PubMed]
- Xu, M.; Qi, J.; Li, F.; Zhang, Y. Highly stretchable strain sensors with reduced graphene oxide sensing liquids for wearable electronics. Nanoscale 2018, 10, 5264–5271. [Google Scholar] [CrossRef]
- Liu, C.; Han, S.; Xu, H.; Wu, J.; Liu, C. Multifunctional Highly Sensitive Multiscale Stretchable Strain Sensor Based on a Graphene/Glycerol–KCl Synergistic Conductive Network. ACS Appl. Mater. Interfaces 2018, 10, 31716–31724. [Google Scholar] [CrossRef]
- Wei, Y.; Qiao, Y.; Jiang, G.; Wang, Y.; Wang, F.; Li, M.; Zhao, Y.; Tian, Y.; Gou, G.; Tan, S.; et al. A Wearable Skinlike Ultra-Sensitive Artificial Graphene Throat. ACS Nano 2019, 13, 8639–8647. [Google Scholar] [CrossRef] [PubMed]
- Wan, S.; Zhu, Z.; Yin, K.; Su, S.; Bi, H.; Xu, T.; Zhang, H.; Shi, Z.; He, L.; Sun, L. A Highly Skin-Conformal and Biodegradable Graphene-Based Strain Sensor. Small Methods 2018, 2, 1700374. [Google Scholar] [CrossRef]
- Yang, Z.; Pang, Y.; Han, X.L.; Yang, Y.; Ling, J.; Jian, M.; Zhang, Y.; Yang, Y.; Ren, T.L. Graphene textile strain sensor with negative resistance variation for human motion detection. ACS Nano 2018, 12, 9134–9141. [Google Scholar] [CrossRef]
- Shinde, P.; Shah, S. A review of machine learning and deep learning applications. In Proceedings of the 2018 Fourth international conference on computing communication control and automation (ICCUBEA), Pune, India, 16–18 August 2018; pp. 1–6. [Google Scholar]
- Caesarendra, W.; Tjahjowidodo, T. A review of feature extraction methods in vibration-based condition monitoring and its application for degradation trend estimation of low-speed slew bearing. Machines 2017, 5, 21. [Google Scholar] [CrossRef]
- Li, F.; Liu, M.; Zhao, Y.; Kong, L.; Dong, L.; Liu, X.; Hui, M. Feature extraction and classification of heart sound using 1D convolutional neural networks. Eur. J. Adv. Signal Process. 2019, 2019. [Google Scholar] [CrossRef] [Green Version]
- Maesa, A.; Garzia, F.; Scarpiniti, M.; Cusani, R. Text Independent Automatic Speaker Recognition System Using. Mel-Frequency Cepstrum Coefficient and Gaussian Mixture Models. J. Inf. Secur. 2012, 3, 335–340. [Google Scholar] [CrossRef] [Green Version]
- Thorpe, B.; Dussard, T. Classification of speech using MATLAB and K-nearest neighbour model: Aid to the hearing impaired. In Proceedings of the IEEE SoutheastCon, St. Petersburg, FL, USA, 19–22 April 2018; pp. 1–8. [Google Scholar]
- Lanjewar, R.B.; Mathurkar, S.; Patel, N. Implementation and comparison of speech emotion recognition system using Gaussian Mixture Model (GMM) and K-Nearest Neighbor (K-NN) techniques. Procedia Comput. Sci. 2015, 47, 50–57. [Google Scholar] [CrossRef] [Green Version]
- Noroozi, F.; Sapiński, T.; Kamińska, D.; Anbarjafari, G. Vocal-based emotion recognition using random forests and decision tree. Int. J. Speech Technol. 2017, 20, 239–246. [Google Scholar] [CrossRef]
- Terissi, L.D.; Parodi, M.; Gómez, J.C. Lip reading using wavelet-based features and random forests classification. In Proceedings of the 2014 22nd International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014; pp. 791–796. [Google Scholar]
- Grama, L.; Rusu, C. Audio signal classification using linear predictive coding and random forests. In Proceedings of the International Conference on Speech Technology and Human-Computer Dialogue (SpeD), Bucharest, Romania, 6–9 July 2017; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Yasmin, M.; Sharif, M.; Mohsin, S. Neural networks in medical imaging applications: A survey. World Appl. Sci. J. 2013, 22, 85–96. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 3104–3112. [Google Scholar]
- Oord, A.V.D.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. Wavenet: A generative model for raw audio. arXiv 2016, arXiv:1609.03499. [Google Scholar]
- Ravenscroft, D.; Prattis, I.; Kandukuri, T.; Samad, Y.A.; Occhipinti, L.G. A Wearable Graphene Strain Gauge Sensor with Haptic Feedback for Silent Communications. In Proceedings of the 2021 IEEE International Conference on Flexible and Printable Sensors and Systems (FLEPS), Manchester, UK, 20–23 June 2021; pp. 1–4. [Google Scholar]
- Qiao, Y.; Wang, Y.; Tian, H.; Li, M.; Jian, J.; Wei, Y.; Tian, Y.; Wang, D.Y.; Pang, Y.; Geng, X.; et al. Multilayer graphene epidermal electronic skin. ACS Nano 2018, 12, 8839–8846. [Google Scholar] [CrossRef]
- Marcano, D.C.; Kosynkin, D.V.; Berlin, J.M.; Sinitskii, A.; Sun, Z.; Slesarev, A.; Alemany, L.B.; Lu, W.; Tour, J.M. Improved synthesis of graphene oxide. ACS Nano 2010, 4, 4806–4814. [Google Scholar] [CrossRef]
- Runge, C.A.; Hosford-Dunn, H. Word recognition performance with modified CID W-22 word lists. J. Speech Lang. Hear. Res. 1985, 28, 355–362. [Google Scholar] [CrossRef] [PubMed]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Peterson, L.E. K-nearest neighbor. Scholarpedia 2009, 4, 1883. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| RF | k-NN | NN | |
|---|---|---|---|
| Words | 50 | 46 | 55 |
| Noises | 82 | 81 | 85 |
| Cough | Nod | Swallow | Yawn | Avg. | |
|---|---|---|---|---|---|
| cough | 88.5 | 14.8 | 11.6 | 2.1 | 84.5 |
| nod | 5.5 | 72.8 | 1.7 | 0.3 | |
| swallow | 5.5 | 10.7 | 81.8 | 2.8 | |
| yawn | 0.5 | 1.6 | 5 | 94.8 |
| As | Dad | Felt | Give | Hum | It | Low | Me | None | Or | Poor | There | True | Up | Us | Avg. | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| as | 66.6 | 2.4 | 0 | 5.7 | 2.9 | 2.4 | 0 | 0 | 4.8 | 1.6 | 3.4 | 0 | 3.4 | 0.7 | 0 | 54.6 |
| dad | 21.9 | 86.8 | 25.2 | 13.3 | 11.6 | 2.4 | 0 | 0.7 | 6.4 | 12.5 | 0 | 0 | 0 | 0 | 2.4 | |
| felt | 1.20 | 0.6 | 17.4 | 11.4 | 1.5 | 6.1 | 5.3 | 1.4 | 3.2 | 1.6 | 3.4 | 3.3 | 1.7 | 0 | 3.6 | |
| give | 0 | 0 | 1.8 | 2.9 | 0 | 0 | 0 | 0 | 0 | 1.6 | 0 | 2.2 | 0 | 0 | 0 | |
| hum | 5.8 | 0.6 | 16.2 | 7.6 | 49.2 | 0 | 3.9 | 3.6 | 3.2 | 0 | 8.5 | 3.3 | 0 | 0 | 6.1 | |
| it | 1.2 | 0.6 | 3.6 | 1.9 | 1.5 | 63.7 | 2.6 | 0.7 | 8 | 3.1 | 5.1 | 0 | 5.1 | 1.4 | 1.2 | |
| low | 1.2 | 3 | 1.8 | 13.3 | 0 | 2.4 | 57.9 | 0 | 4.8 | 11 | 3.4 | 3.3 | 3.4 | 0 | 1.2 | |
| me | 1.2 | 0.6 | 9 | 1.9 | 10.2 | 2.4 | 0 | 90 | 4.8 | 1.6 | 6.8 | 2.2 | 3.4 | 0.2 | 4.8 | |
| none | 1.2 | 0.6 | 3.6 | 11.4 | 2.9 | 2.4 | 7.9 | 0 | 37.6 | 1.6 | 8.5 | 3.3 | 6.8 | 0 | 3.6 | |
| or | 0 | 0.6 | 1.8 | 7.6 | 2.9 | 3.6 | 10.5 | 0 | 6.4 | 40.5 | 8.5 | 4.4 | 5.1 | 0.2 | 2.4 | |
| poor | 0 | 0 | 1.8 | 0 | 0 | 2.4 | 0 | 0 | 0 | 0 | 28.9 | 1.1 | 3.4 | 0 | 0 | |
| there | 0 | 0 | 7.2 | 9.5 | 4.4 | 1.2 | 3.9 | 0.7 | 4.8 | 9.4 | 16.9 | 69.5 | 11.8 | 0.7 | 2.4 | |
| true | 0 | 0.6 | 1.8 | 1.9 | 1.5 | 0 | 1.3 | 0 | 4.8 | 3.1 | 5.1 | 2.2 | 28.9 | 0.7 | 1.2 | |
| up | 0 | 3 | 5.4 | 5.7 | 2.9 | 3.6 | 5.3 | 0 | 6.4 | 3.1 | 0 | 2.2 | 16.9 | 95.5 | 7.3 | |
| us | 0 | 0.6 | 3.6 | 5.7 | 8.7 | 7.3 | 1.3 | 2.8 | 4.8 | 9.4 | 1.7 | 3.3 | 10.2 | 0.5 | 63.7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ravenscroft, D.; Prattis, I.; Kandukuri, T.; Samad, Y.A.; Mallia, G.; Occhipinti, L.G. Machine Learning Methods for Automatic Silent Speech Recognition Using a Wearable Graphene Strain Gauge Sensor. Sensors 2022, 22, 299. https://doi.org/10.3390/s22010299
Ravenscroft D, Prattis I, Kandukuri T, Samad YA, Mallia G, Occhipinti LG. Machine Learning Methods for Automatic Silent Speech Recognition Using a Wearable Graphene Strain Gauge Sensor. Sensors. 2022; 22(1):299. https://doi.org/10.3390/s22010299
Chicago/Turabian StyleRavenscroft, Dafydd, Ioannis Prattis, Tharun Kandukuri, Yarjan Abdul Samad, Giorgio Mallia, and Luigi G. Occhipinti. 2022. "Machine Learning Methods for Automatic Silent Speech Recognition Using a Wearable Graphene Strain Gauge Sensor" Sensors 22, no. 1: 299. https://doi.org/10.3390/s22010299