
An Occupancy Mapping Method Based on K-Nearest Neighbours


Abstract
:1. Introduction
- a k-NN method for occupancy mapping using the context of neighbouring points to update nodes containing points;
- definition of the relationship between the average distance and the change in occupancy probability, potentially decreasing the probability of a node despite the points being present in the node;
- the proposed k-NN method is verified by the point clouds derived by the StereoSGBM algorithm [21] implemented on the images produced from a stereo camera, and can be potentially extended to other point-cloud-based mapping systems.
2. Background
3. Method
3.1. K-NN-Based Inverse Sensor Model
- is the upper clamping threshold, which is the upper bound on the probability.
- is the threshold. A node will be marked as occupied when the threshold is reached.
- is the probability of a “miss”. A node will be updated with if it is traversed by rays and corresponding endpoints are within range .
- is the probability of a “miss”. A node will be updated with if it is traversed by rays and corresponding endpoints are outside range .
- is the lower clamping threshold, which is the lower bound on the probability.
- is the upper bound on the probability derived by the average distance from a point to its k-NN.
- is the lower bound on the probability derived by the average distance from a point to its k-NN.
- k is the number of nearest neighbouring points.
3.2. Distribution of Average Distances
3.3. Map Update
| Algorithm 1: Map Update |
 |
3.4. Parameter Space Considerations
3.5. Parameter Reduction and Optimisation
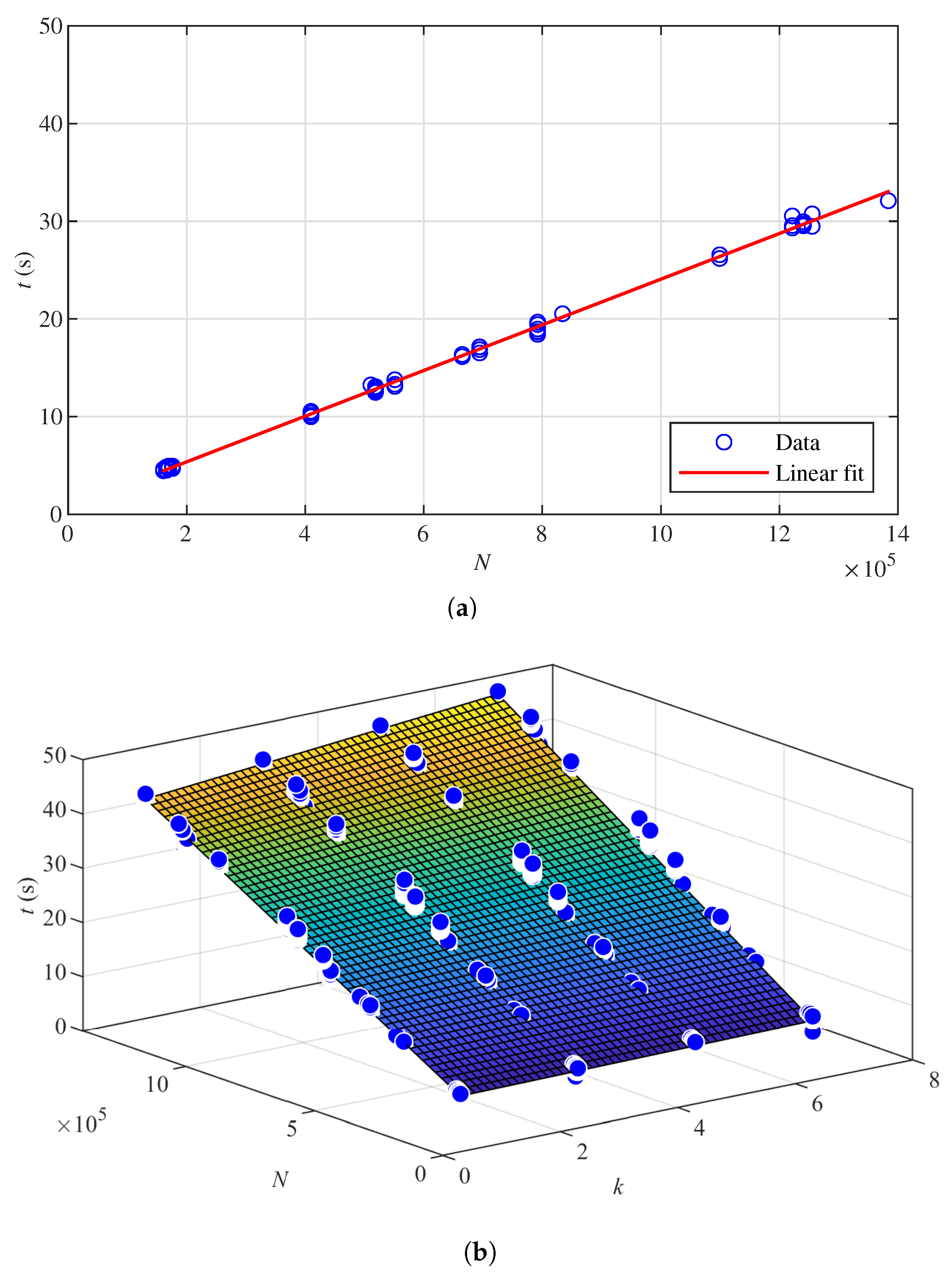
3.6. Run Time
4. Experiments
4.1. Overview of Data Sets
4.2. Map Generation and Node Classification
4.3. Parameter Space for Analysis
4.4. Results
4.5. Discussion
5. Conclusions
- The k-NN model is nonsensitive to different types of distributions.
- Parameter k is of lower impact than other k-NN parameters.
- Through grid search optimisation, the optimal performance of OctoMap can be improved by the k-NN method.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ramasubramanian, S.; Muthukumaraswamy, S.A. On the enhancement of firefighting robots using path-planning algorithms. SN Comput. Sci. 2021, 2, 1–11. [Google Scholar] [CrossRef]
- Sangeetha, V.; Krishankumar, R.; Ravichandran, K.S.; Cavallaro, F.; Kar, S.; Pamucar, D.; Mardani, A. A fuzzy gain-based dynamic ant colony optimization for path planning in dynamic environments. Symmetry 2021, 13, 280. [Google Scholar] [CrossRef]
- Duong, T.; Das, N.; Yip, M.; Atanasov, N. Autonomous navigation in unknown environments using sparse kernel-based occupancy mapping. In Proceedings of the International Conference on Robotics and Automation, Paris, France, 31 May–4 June 2020; pp. 9666–9672. [Google Scholar]
- Lee, J.W.; Lee, W.; Kim, K.D. An algorithm for local dynamic map generation for safe UAV navigation. Drones 2021, 5, 88. [Google Scholar] [CrossRef]
- Hoermann, S.; Bach, M.; Dietmayer, K. Dynamic occupancy grid prediction for urban autonomous driving: A deep learning approach with fully automatic labeling. In Proceedings of the International Conference on Robotics and Automation, Brisbane, Australia, 21–25 May 2018; pp. 2056–2063. [Google Scholar]
- Grigorescu, S.; Trasnea, B.; Cocias, T.; Macesanu, G. A survey of deep learning techniques for autonomous driving. J. Field Robot. 2020, 37, 362–386. [Google Scholar] [CrossRef]
- Rusu, R.B.; Cousins, S. 3d is here: Point cloud library (pcl). In Proceedings of the International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 1–4. [Google Scholar]
- Neuville, R.; Bates, J.S.; Jonard, F. Estimating forest structure from UAV-mounted LiDAR point cloud using machine learning. Remote Sens. 2021, 13, 352. [Google Scholar] [CrossRef]
- Teng, X.; Zhou, G.; Wu, Y.; Huang, C.; Dong, W.; Xu, S. Three-dimensional reconstruction method of rapeseed plants in the whole growth period using RGB-D camera. Sensors 2021, 21, 4628. [Google Scholar] [CrossRef] [PubMed]
- Zhang, C.; Zhang, K.; Ge, L.; Zou, K.; Wang, S.; Zhang, J.; Li, W. A method for organs classification and fruit counting on pomegranate trees based on multi-features fusion and support vector machine by 3D point cloud. Sci. Hortic. 2021, 278, 109791. [Google Scholar] [CrossRef]
- Lin, X.; Wang, F.; Yang, B.; Zhang, W. Autonomous vehicle localization with prior visual point cloud map constraints in GNSS-challenged environments. Remote Sens. 2021, 13, 506. [Google Scholar] [CrossRef]
- da Silva Vieira, G.; de Lima, J.C.; de Sousa, N.M.; Soares, F. A three-Layer architecture to support disparity map construction in stereo vision systems. Intell. Syst. Appl. 2021, 12, 200054. [Google Scholar] [CrossRef]
- Hornung, A.; Wurm, K.M.; Bennewitz, M.; Stachniss, C.; Burgard, W. OctoMap: An efficient probabilistic 3d mapping framework based on octrees. Auton. Robot. 2013, 34, 189–206. [Google Scholar] [CrossRef] [Green Version]
- Meagher, D.J.R. Octree Encoding: A New Technique for the Representation, Manipulation and Display of Arbitrary 3-d Objects by Computer; Technical Report IPL-TR-80-111; Rensselaer Polytechnic Institute: New York, NY, USA, 1980. [Google Scholar]
- Nehring-Wirxel, J.; Trettner, P.; Kobbelt, L. Fast exact booleans for iterated CSG using octree-embedded BSPs. Comput.-Aided Des. 2021, 135, 103015. [Google Scholar] [CrossRef]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Sun, L.; Yan, Z.; Zaganidis, A.; Zhao, C.; Duckett, T. Recurrent-Octomap: Learning state-based map refinement for long-term semantic mapping with 3-d-Lidar data. IEEE Robot. Autom. Lett. 2018, 3, 3749–3756. [Google Scholar] [CrossRef] [Green Version]
- Doherty, K.; Shan, T.; Wang, J.; Englot, B. Learning-aided 3-D occupancy mapping with Bayesian generalized kernel inference. IEEE Trans. Robot. 2019, 35, 953–966. [Google Scholar] [CrossRef]
- Chen, J.; Shen, S. Improving octree-based occupancy maps using environment sparsity with application to aerial robot navigation. In Proceedings of the International Conference on Robotics and Automation, Singapore, 29 May–3 June 2017; pp. 3656–3663. [Google Scholar]
- Zhang, L.; Wei, L.; Shen, P.; Wei, W.; Zhu, G.; Song, J. Semantic SLAM based on object detection and improved Octomap. IEEE Access 2018, 6, 75545–75559. [Google Scholar] [CrossRef]
- Brahmbhatt, S. Practical OpenCV, 1st ed.; Apress: New York, NY, USA, 2013. [Google Scholar]
- Miao, Y.; Hunter, A.; Georgilas, I. Parameter reduction and optimisation for point cloud and occupancy mapping algorithms. Sensors 2021, 21, 7004. [Google Scholar] [CrossRef] [PubMed]
- Yang, W.; Wang, K.; Zuo, W. Neighborhood component feature selection for high-dimensional data. J. Comput. 2012, 7, 161–168. [Google Scholar] [CrossRef]
- Moravec, H.; Elfes, A. High resolution maps from wide angle sonar. In Proceedings of the International Conference on Robotics and Automation, Saint Louis, MO, USA, 25–28 March 1985; Volume 2, pp. 116–121. [Google Scholar]
- Yguel, M.; Aycard, O.; Laugier, C. Update policy of dense maps: Efficient algorithms and sparse representation. In Proceedings of the International Conference Field and Service Robotics, Chamonix, France, 9–12 July 2007; pp. 23–33. [Google Scholar]
- Miao, Y.; Georgilas, I.; Hunter, A.J. A k-nearest neighbours based inverse sensor model for occupancy mapping. In Proceedings of the Annual Conference Towards Autonomous Robotic Systems, London, UK, 3–5 July 2019; pp. 75–86. [Google Scholar]
- Welford, B.P. Note on a method for calculating corrected sums of squares and products. Technometrics 1962, 4, 419–420. [Google Scholar] [CrossRef]
- Preparata, F.P.; Shamos, M.I. Computational Geometry: An Introduction, 1st ed.; Springer: New York, NY, USA, 1985. [Google Scholar]
- Barnes, B.C.; Siderius, D.W.; Gelb, L.D. Structure, thermodynamics, and solubility in tetromino fluids. Langmuir 2009, 25, 6702–6716. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Golomb, S.W. Polyominoes: Puzzles, Patterns, Problems, and Packings, 2nd ed.; Princeton University Press: Princeton, NJ, USA, 1994. [Google Scholar]
- Mur-Artal, R.; Montiel, J.M.M.; Tardos, J.D. ORB-SLAM: A versatile and accurate monocular SLAM system. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Minimum | Maximum | Step | Method |
|---|---|---|---|---|
| a | 0.5 | 0.98 | 0.12 | k-NN |
| b | 0.98 | 0.98 | N/A | Both |
| 0.5 | 0.98 | 0.12 | OctoMap | |
| 0.02 | 0.38 | 0.12 | Both | |
| 0.02 | 0.38 | 0.12 | k-NN | |
| a | 0.02 | 0.38 | 0.12 | k-NN |
| b | 0.02 | 0.02 | N/A | Both |
| 0.12 | Both | |||
| 0.02 | 0.98 | 0.12 | k-NN | |
| 0.02 | 0.98 | 0.12 | k-NN | |
| ka | 1 | 7 | 2 | k-NN |
| kb | 1 | 1 | N/A | k-NN |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Miao, Y.; Hunter, A.; Georgilas, I. An Occupancy Mapping Method Based on K-Nearest Neighbours. Sensors 2022, 22, 139. https://doi.org/10.3390/s22010139
Miao Y, Hunter A, Georgilas I. An Occupancy Mapping Method Based on K-Nearest Neighbours. Sensors. 2022; 22(1):139. https://doi.org/10.3390/s22010139
Chicago/Turabian StyleMiao, Yu, Alan Hunter, and Ioannis Georgilas. 2022. "An Occupancy Mapping Method Based on K-Nearest Neighbours" Sensors 22, no. 1: 139. https://doi.org/10.3390/s22010139