In this section, we conduct experiments to evaluate MrKD on five datasets for image and audio classification: CIFAR100, CIFAR10 [
26], CINIC10 [
27] DCASE’18 ASC [
30] and DCASE’20 Low Complexity [
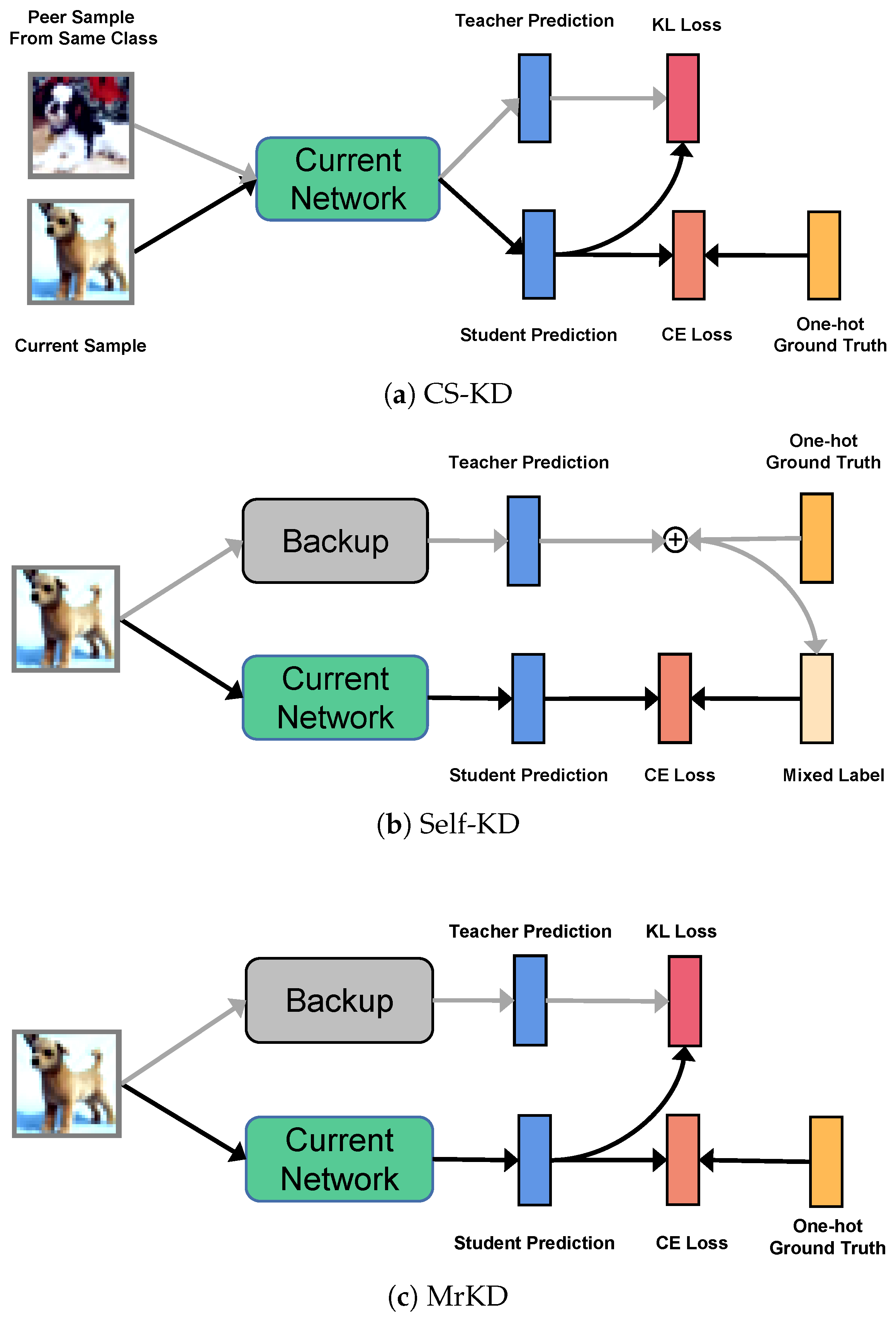
31]. For a fair comparison, all results on the same dataset are obtained with the identical setting. We implement the networks and training procedures in PyTorch and conduct all experiments on a single NVIDIA TITAN RTX GPU. Besides baseline and MrKD, we also provide the results of two peer self-knowledge distillation methods, self-KD [
40] and MSD [
21], that are introduced in
Section 2.
4.1. CIFAR-100
The CIFAR-100 [
26] dataset consisted of 50,000 training images and 10,000 test 32 × 32 color images in 100 classes, with 600 images per class in total. A random horizontal flip and crop with 4 pixels zero-padding weere carried out for data augmentation in the training procedure. The networks used below were implemented as their official papers for 32 × 32 images, including ResNet [
1], WideResNet [
28], ResNeXt [
28]. See
Figure 6.
For all runs, including the baselines, we trained a total epoch of 200, with batch size 128. The initial learning rate of 0.1 decreased to zero with linear annealing. The SGD optimizer was used with a weight decay of 0.0001, and momentum was set to 0.9. We averaged the last epoch results of four runs for all presented results because choosing the best epoch results was prone to benefiting unstable and oscillating configurations.
Experimental results are shown in
Table 2. The best result for every network is in bold. It can be observed in
Table 2 that MrKD improved the baseline consistently. With historical model teachers’ knowledge, MrKD decreased the error rate from 1.03% to 1.96% on the CIFAR100 test set. Although MSD obtained competitive results for some networks, we argue that MSD was a multi-branch method that needed to redesign each of the networks. On the other hand, self-KD, which smoothed the one hot label by a historical teacher, reduced the error rate not as significantly as MSD and MrKD.
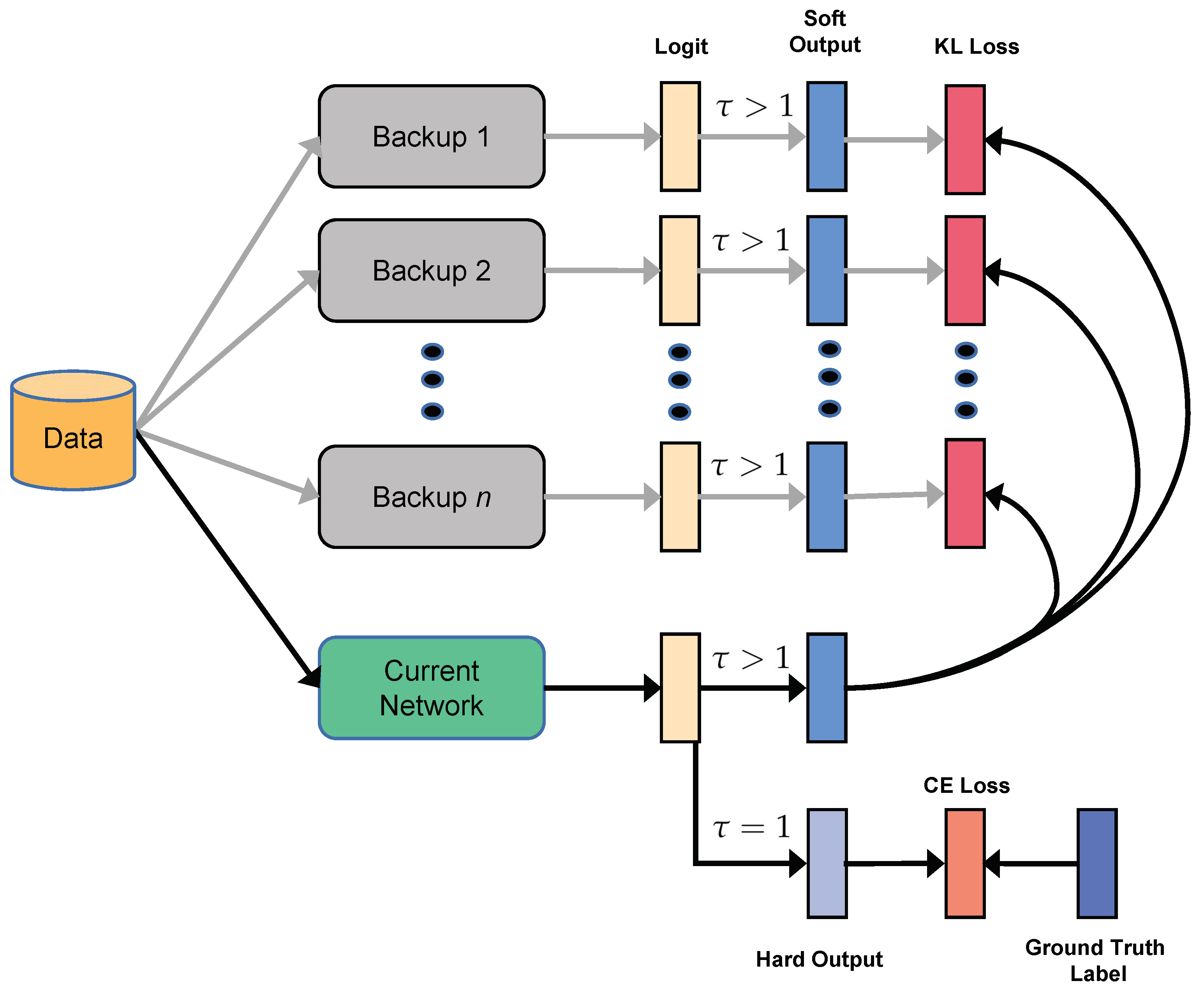
Influence of each component: We empirically demonstrate the influence of MrKD with each component.
Table 3 shows that the plain historical model distillation without FCN ensemble and Knowledge Adjustment could improve the networks from 0.6% to 1.2%. The FCN ensemble could decrease the error rate further by around 0.4–0.7%. Finally, compared to MrKD without KA, the full MrKD method showed more improvement when the networks went deeper. We argue that a deeper network was more sensitive to the correctness of the teacher distribution. Thus ResNet-164 and WRN-28-10 benefited more from KA than their shallower siblings.
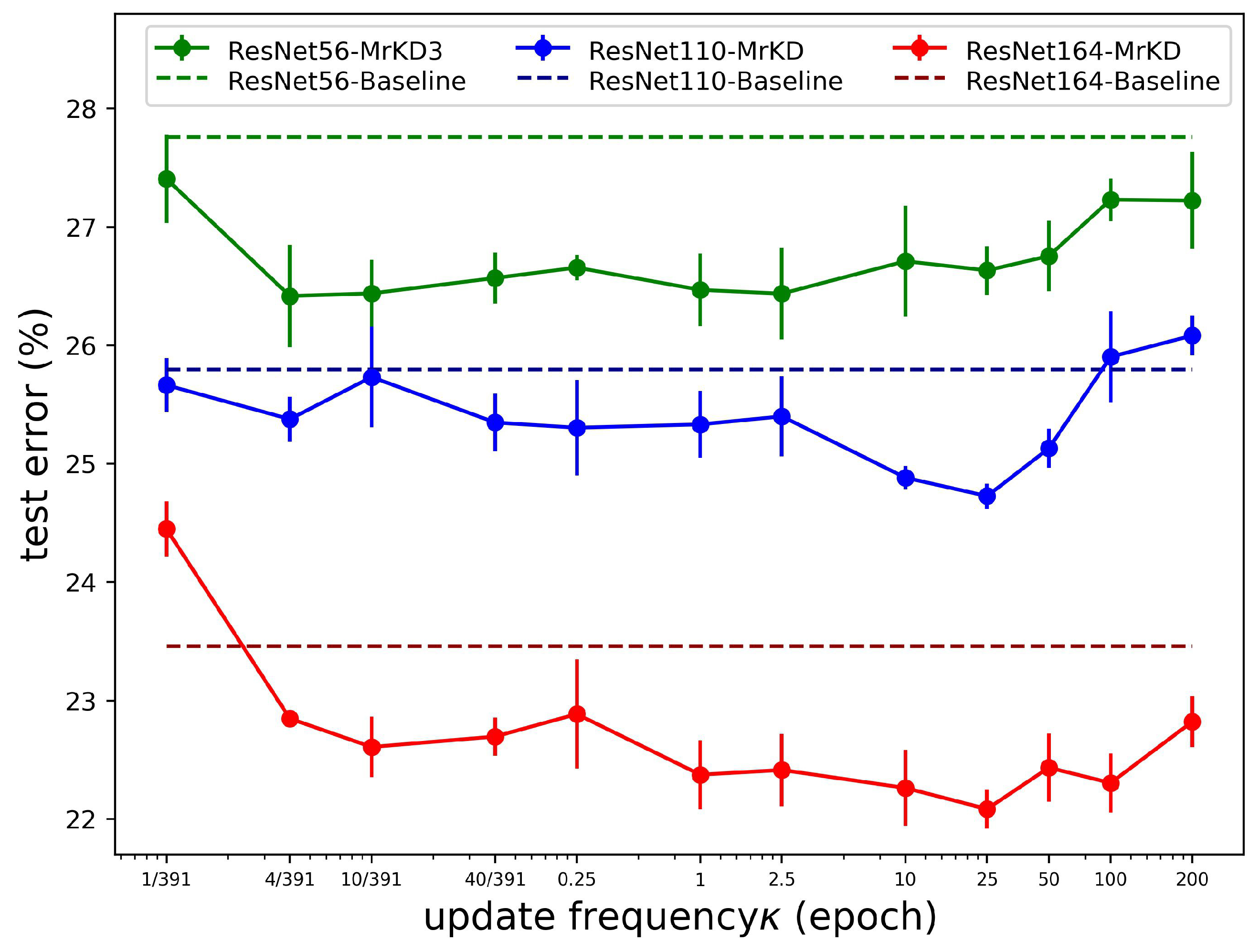
Update frequency
: The critical hyper-parameter for the MrKD method was the model backups’ update frequency
. Following the setting in
Section 3.1, we evaluated MrKD with different
on the CIFAR-100 dataset within the range of {1/391, 4/391, 10/391, 40/391, 0.25, 1, 2.5, 10, 25, 50, 100, 200}. Note that the unit of
was the epoch. As the batch size we set was 128 on CIFAR-100, the total iteration of an epoch was 391; thus, the
= 10/391 meant we updated the copies every 10 steps, and
= 200 means that we never updated the copies during the 200 epochs training. Overall, the range selected above covered the frequency from updating in each step to never renewing the copies during the whole training procedure. The widest range allowed us to observe the influence of update frequency
thoroughly. The control variates method was used below to show the result, which meant that we set other hyper-parameters to the optimal value except for the one we wanted to evaluate.
In
Figure 7, we can see that if the step interval of the model backups was quite small, the error rate rose because the copy was too similar to the current model, then the regularization would not be helpful and may stumble the current model from learning. On the other hand, if the step was too large, the copies would be worse and lagging, then MrKD would also mislead and destabilize the learning. In conclusion, two ambivalent factors influenced the performance of MrKD while
was changing: accuracy and diversity. For high accuracy, we needed to be updated the copies frequently, while for diversity, the copies needed to be far from the current model.
The shallower model (ResNet56) was relatively insensitive to
. On ResNet110 and ResNet164, we can see clearly in
Figure 7 that the optimum value of
was 25. The short standard deviation bars indicated that the optimal values were very stable. These optimal values of
were out of our expectation because updating copies every 25 epochs meant more than a 10% rise of training error than the current model. The large update step interval indicated that diversity was more important than accuracy.
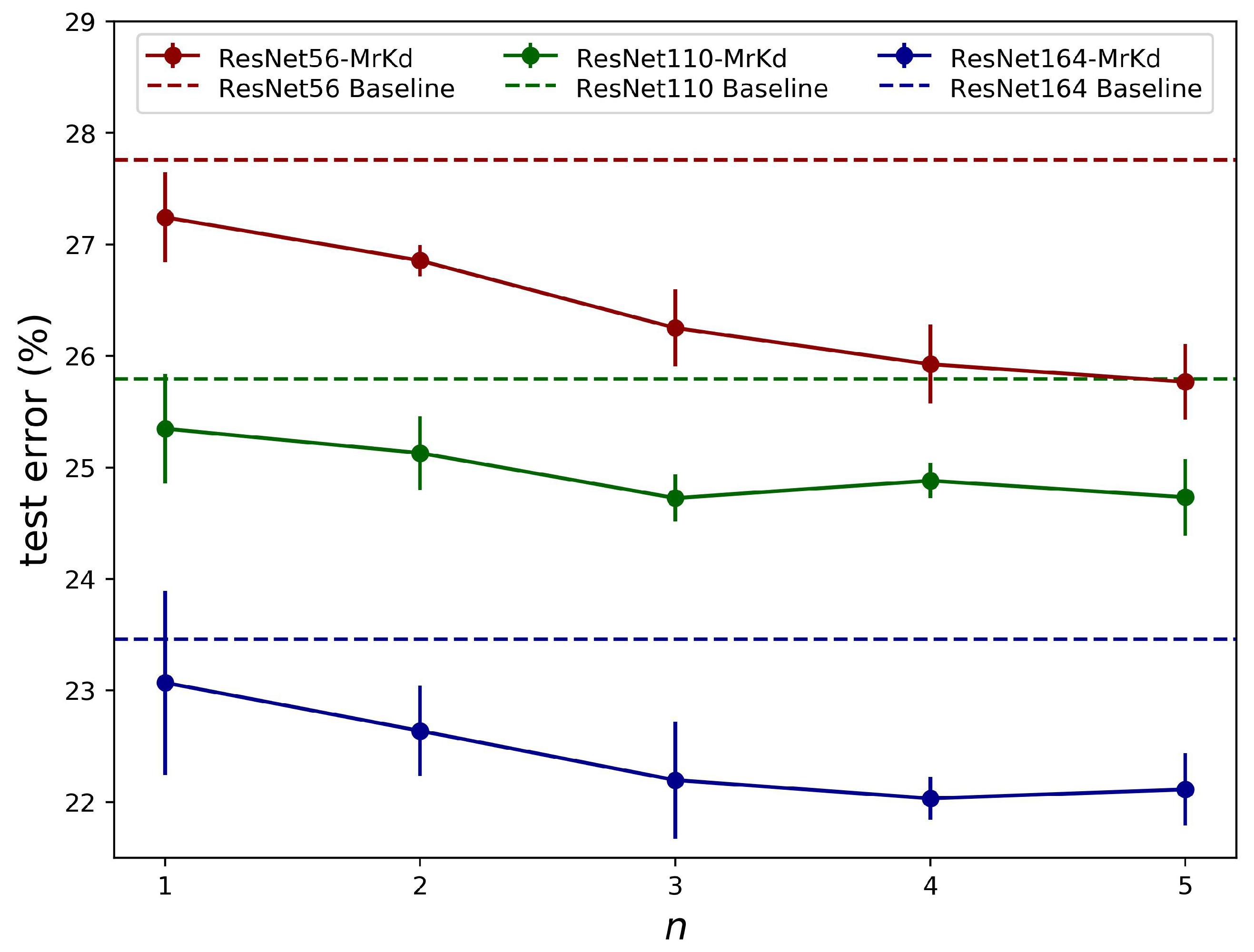
Copy amount
n:
Figure 8 demonstrates the influence of more model backups being available. For ResNet-110 and ResNet-164, the performance gain was saturated with around three historical models. However, on shallower networks ResNet-56, more improvement was obtained with five copies. A similar trend could be found from multiple model distillation methods [
15,
16,
17]. As our experiments showed in
Section 4.1–
Section 4.3, setting copies to three was a reasonable choice that could achieve significant improvement, yet, for shallower networks, more than three copies were worth trying for further improvement if computation resources were sufficient.
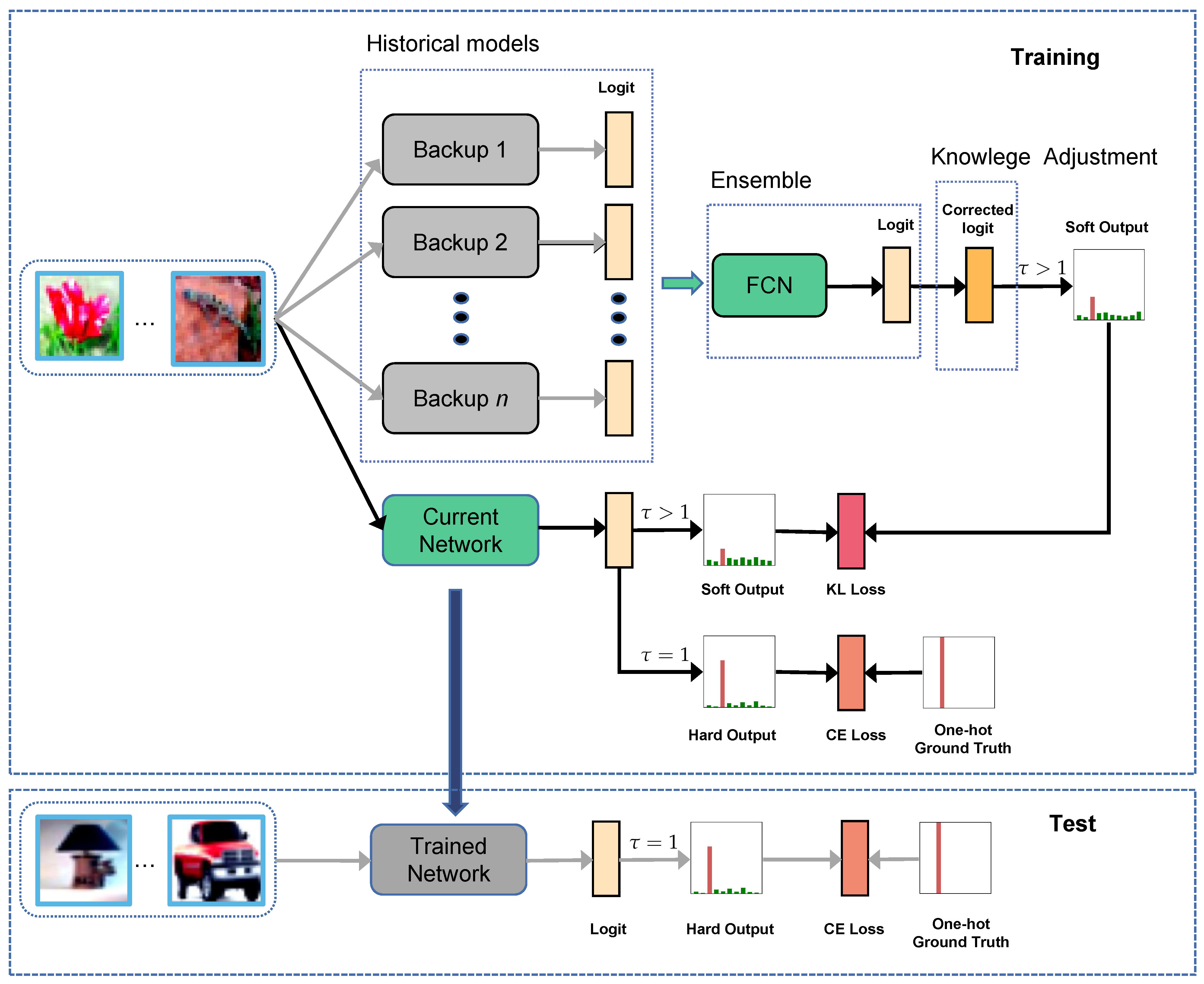
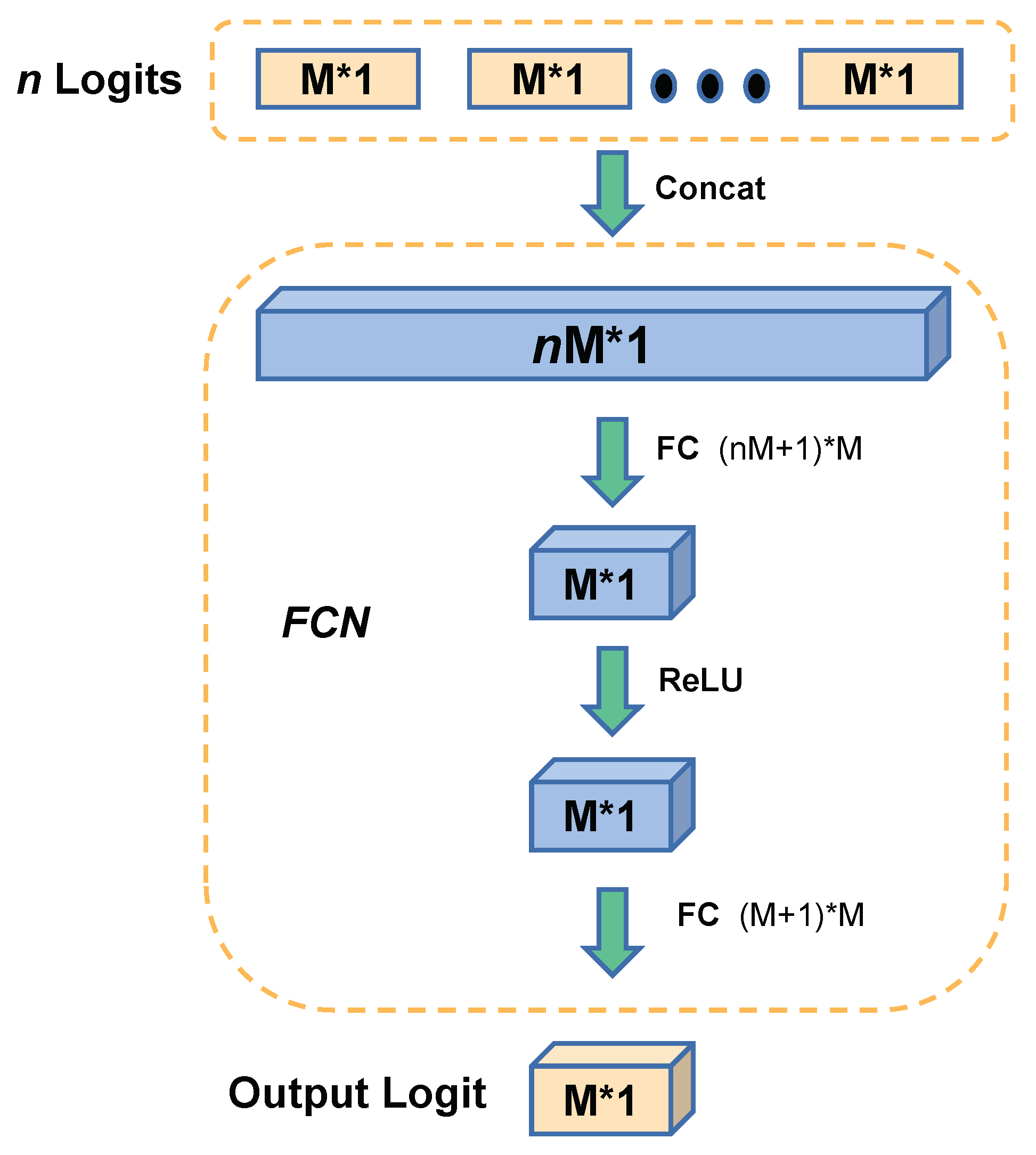
Fully Connected Network: For the Fully Connected Network, we only used the KL loss to update the parameters.
Table 4 shows the loss options. Compared to the baseline, the plain CE loss improved the least. The KL loss between the FCN output and the model output decreased the error rate by 0.3% to 0.5%. The combination of CE and KL loss obtained similar results as KL loss only. We used the KL loss for ensembling only as of the online KD methods [
41,
42].
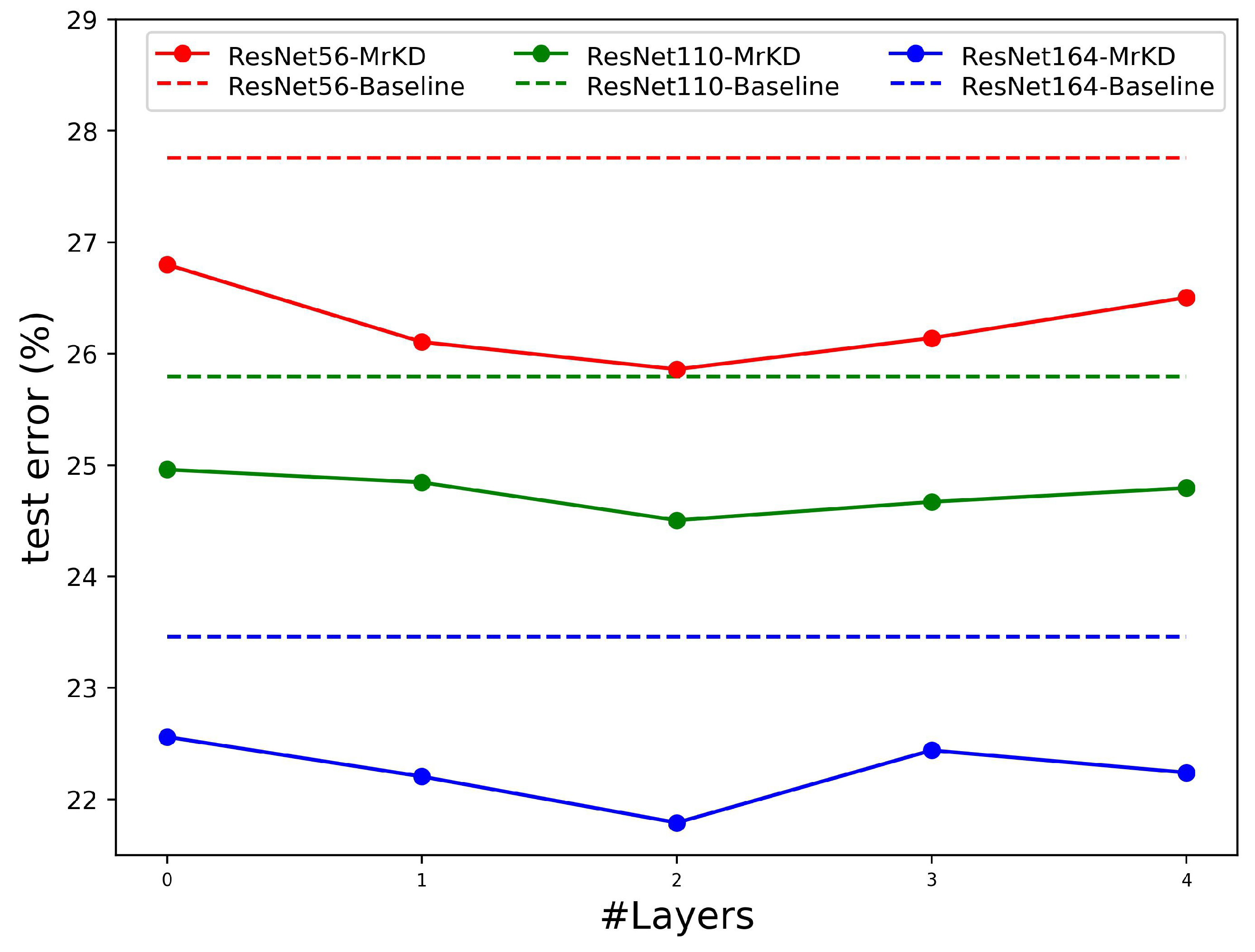
To determine the depth of FCN, we evaluated different layers for CIFAR-100 classification. Note that layers = 0 indicates the logits were averaged evenly with no parameter in FCN. As illustrated in
Figure 9, MrKD achieved the optimal improvement when layer number equals two. With fewer layers, the FCN was be too simple to conduct the model copy logits. With the network going too deep, the FCN was prone to overfit the training set and impair the performance of MrKD.
4.3. DCASE Datasets
Acoustic scene classification (ASC) is a regular task in the Detection and Classification of Acoustic Scene and Event (DCASE) challenge. The objective of ASC is to categorize the short audio samples into predefined acoustic scene classes using the supervised learning method. In this section, the proposed MrKD is evaluated on two ASC datasets. The results presented are obtained by the official development dataset train/test split in which 70% of the data for each class is included for training, 30% for testing.
DCASE’18 ASC [
30]: The dataset contained 8640 audio segments of 10-s length, where 6122 clips were included in the training set and 2518 clips in the test subset. The 10 acoustic scenes were airport, shopping mall, metro station, pedestrian street, public square, street, traveling by tram, bus and underground, and urban park. As
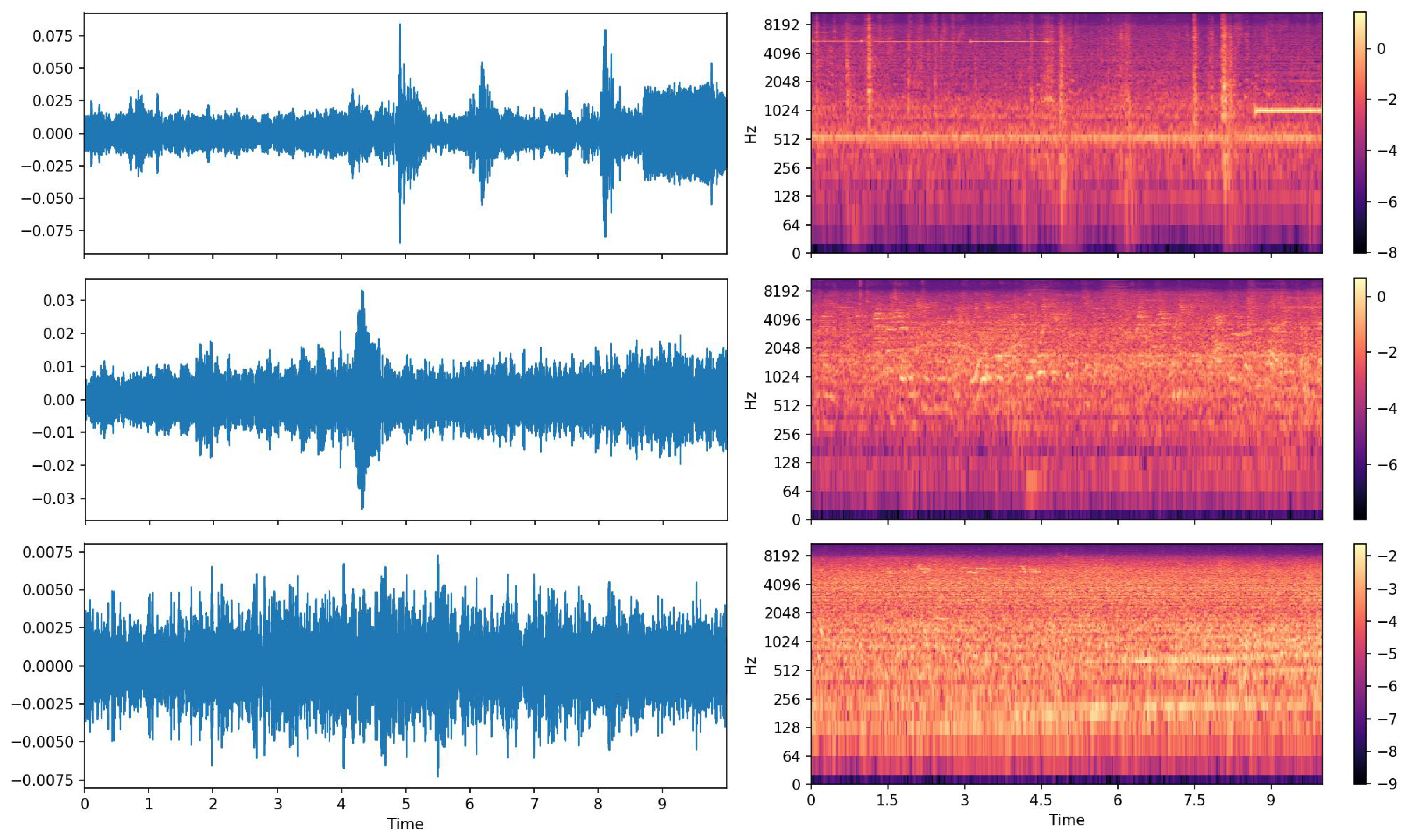
Figure 11 shows, the 10-s audio clips were down-sampled to 22.05 kHz. For feature extraction, the perceptually weighted Mel spectrograms were computed similar to Koutini et al. [
43]. The result was a 256 × 431 tensor with 256 Mel frequency bins and 431 frames.
DCASE’20 Low Complexity ASC [
31] was a three-class supervised learning dataset that comprised 14,400 segments of 10-s length. The data were recorded from 10 acoustic scenes as with DCASE’18 ASC and summarized into three categories, indoor, outdoor, and transportation. As
Figure 12 shows, the feature extraction procedure was the same as the DCASE’18 ASC experiment. We chose this dataset because it was a low complexity three-class classification task and required the model parameter less than the 500 KB size limit.
For both datasets, the presented baselines are the corresponding model trained with only regular classification cross-entropy loss. For DCASE’18 ASC, the network CP-ResNet from Koutini et al. [
44] was used as the baseline to evaluate the methods proposed in this paper. We ran a total epoch of 200, with batch size 10. The learning rate was set to 0.0001 and decreased to zero with linear decay. The SGD optimizer was used with a momentum of 0.9 and zero weight decay. The classification accuracy was used as the measure of the performance, and all the results reported below were averaged over four runs. We also report the result of CP-ResNet combined with Mixup [
45], which is a widely used augmentation method in ASC tasks. For DCASE’20 Low Complexity ASC, the baseline of self-KD methods was frequency damping [
44]. A similar training setup was used as for DCASE’18 ASC.
As
Table 7 shows, MrKD improved both CP-ResNet and the combination with Mixup by 1.06% and 0.53%, respectively. Although our method improved the baseline performance, no significant improvement was shown comparing to the second-best results of other self-KD methods in
Table 7. Note that MSD obtained similar result as our method on CP-ResNet but failed to get improvement when combining with Mixup. We argue that Mixup was a strong augmentation method. In this case, the knowledge offered by standalone peers was no longer helpful, while the similarity of the student and historical model in MrKD made our method effective. Self-KD obtained less improvement on CP-ResNet, both with or without Mixup, than ours. To make this conclusion more concrete, we performed the t-test of the equality of means hypothesis between the results of self-KD and ours. The level of confidence of rejection without and with Mixup was 98.9% and 91.5%, respectively.
The evaluation on DCASE’20 Low Complexity ASC is shown in
Table 8. The accuracy drop of baseline with Mixup indicated that as a strong label-mixing augmentation method, Mixup was not effective when the accuracy gap between training set and test set was small. Similar to DCASE’18 ASC, although MSD obtained similar improvement as MrKD on Freq-damp, it failed to improve the combination with Mixup. Self-KD and MrKD obtained improvement consistently on DCASE’20 Low Complexity ASC, while MrKD had higher means. The rejection confidence of the equality of means hypothesis was 97.7% and 98.9%, without and with Mixup, respectively. Particularly, MrKD achieved better performance on DCASE’20 Low Complexity ASC when combined with Mixup augmentation. As illustrated in
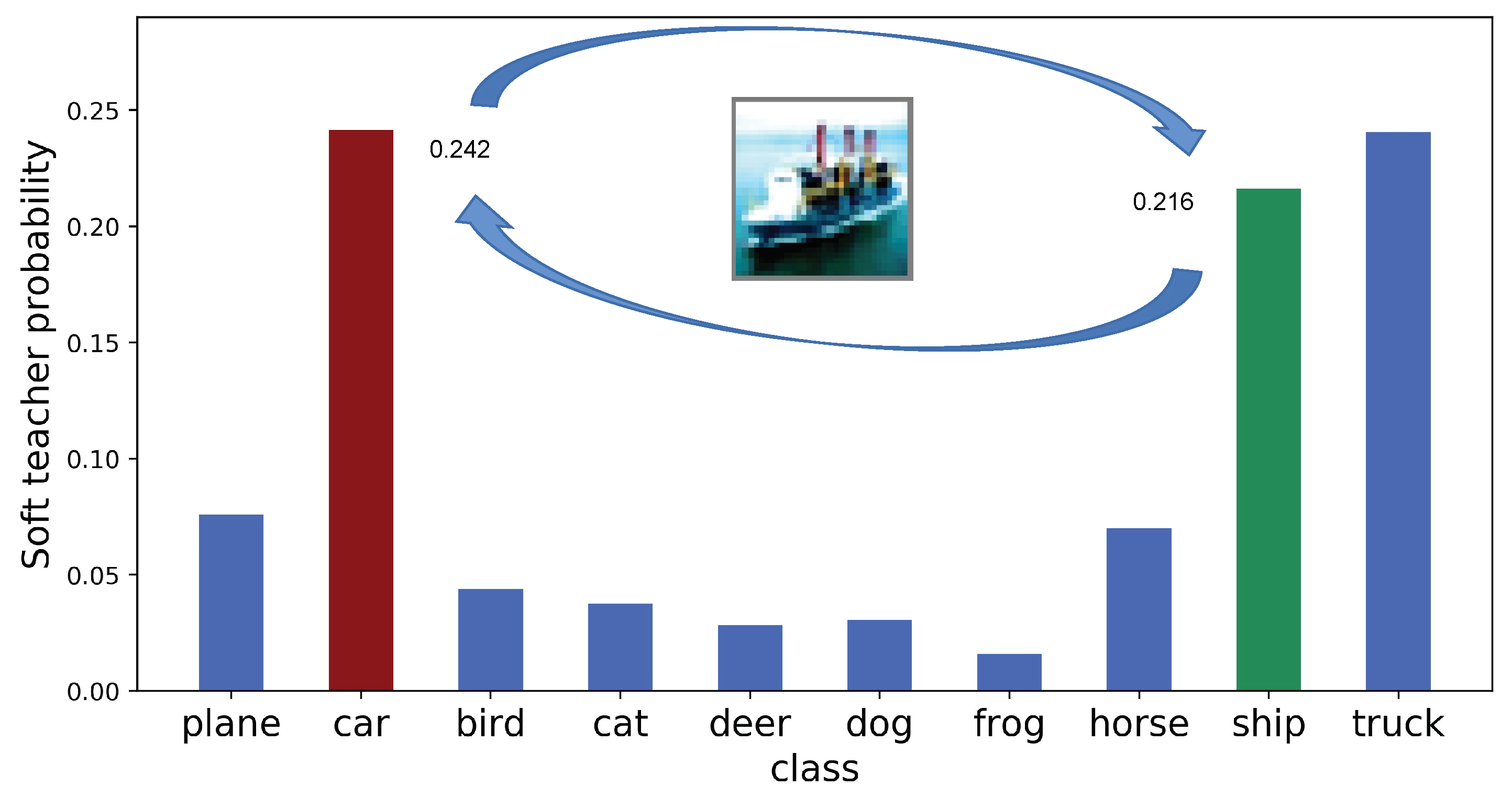
Figure 1, since our method MrKD redesigned the training procedure and did not modify the final student network, the 500 KB size limit of DCASE’20 Low Complexity ASC was still satisfied.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}