
TruthTrust: Truth Inference-Based Trust Management Mechanism on a Crowdsourcing Platform

Abstract
:1. Introduction
- S1: Honest Strategy. Workers with honest strategies always provide good services, and requesters give objective and real evaluations over all workers.
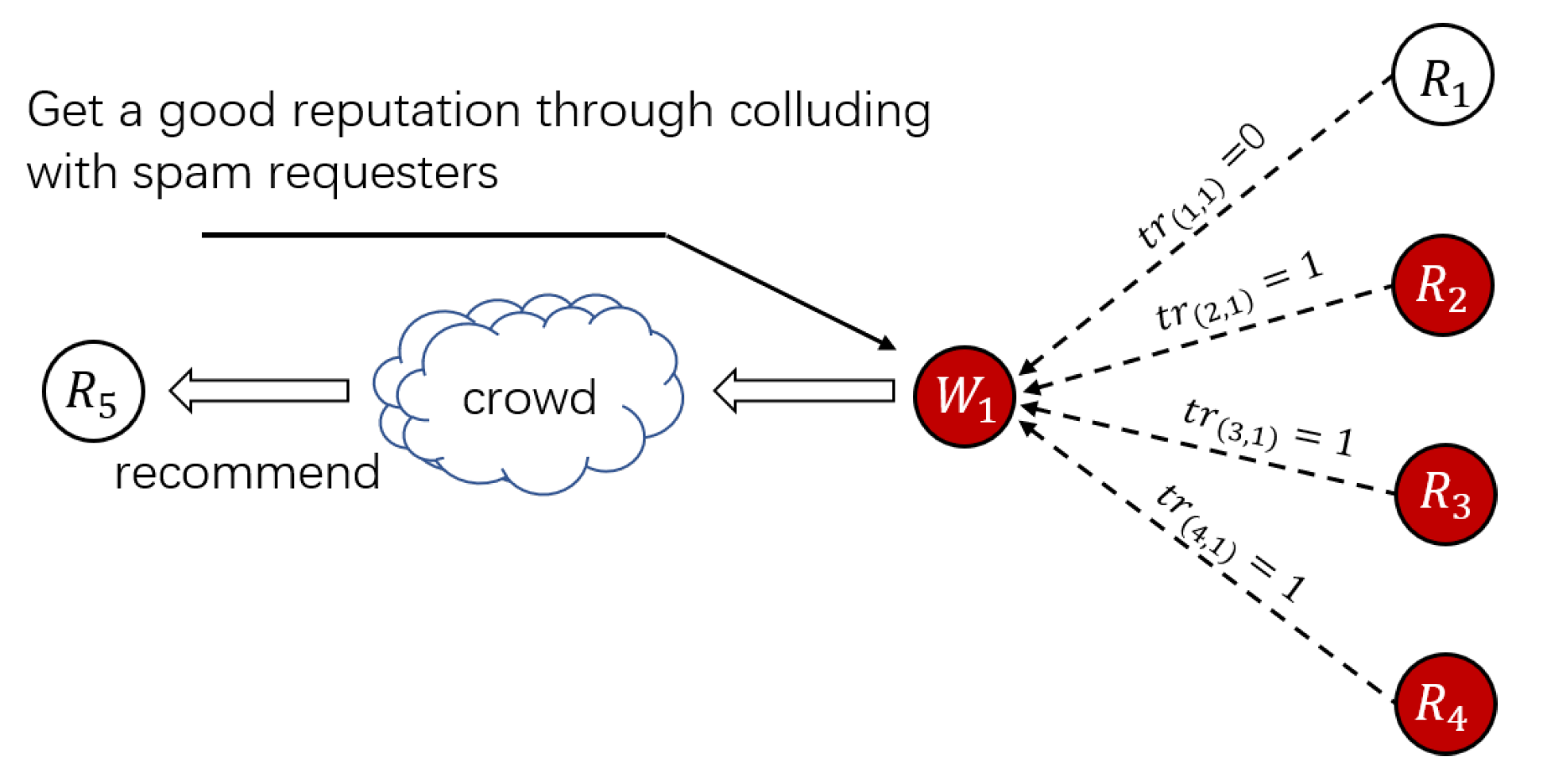
- S2: Collusive Strategy. Spam workers through collusive requesters always get high ratings to make themselves disguised as normal workers. When the collective workers are chosen to complete a HIT published by a normal requester, they always provide invalid services. On the other hand, requesters with a collusive strategy only recruit spam workers.
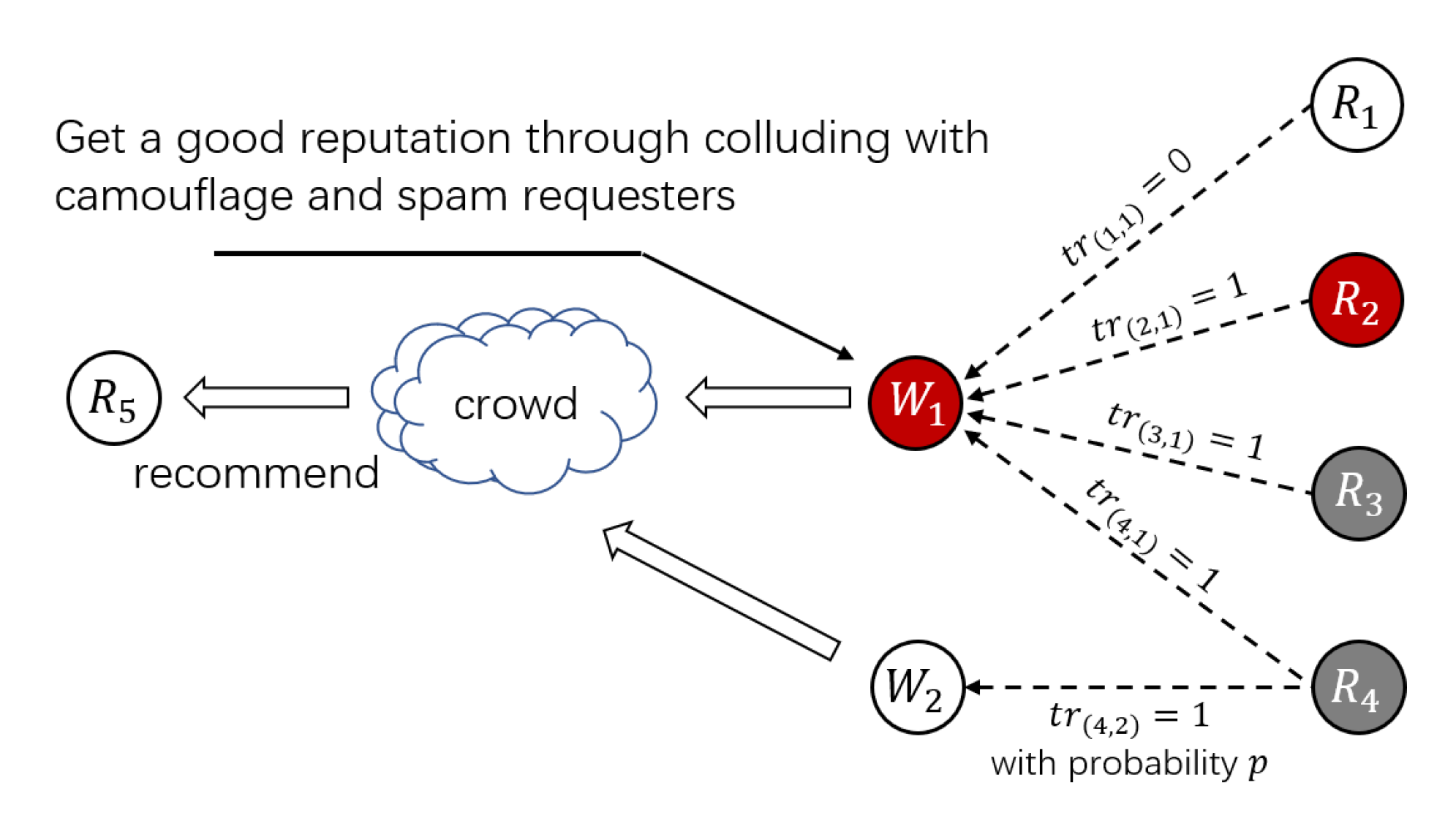
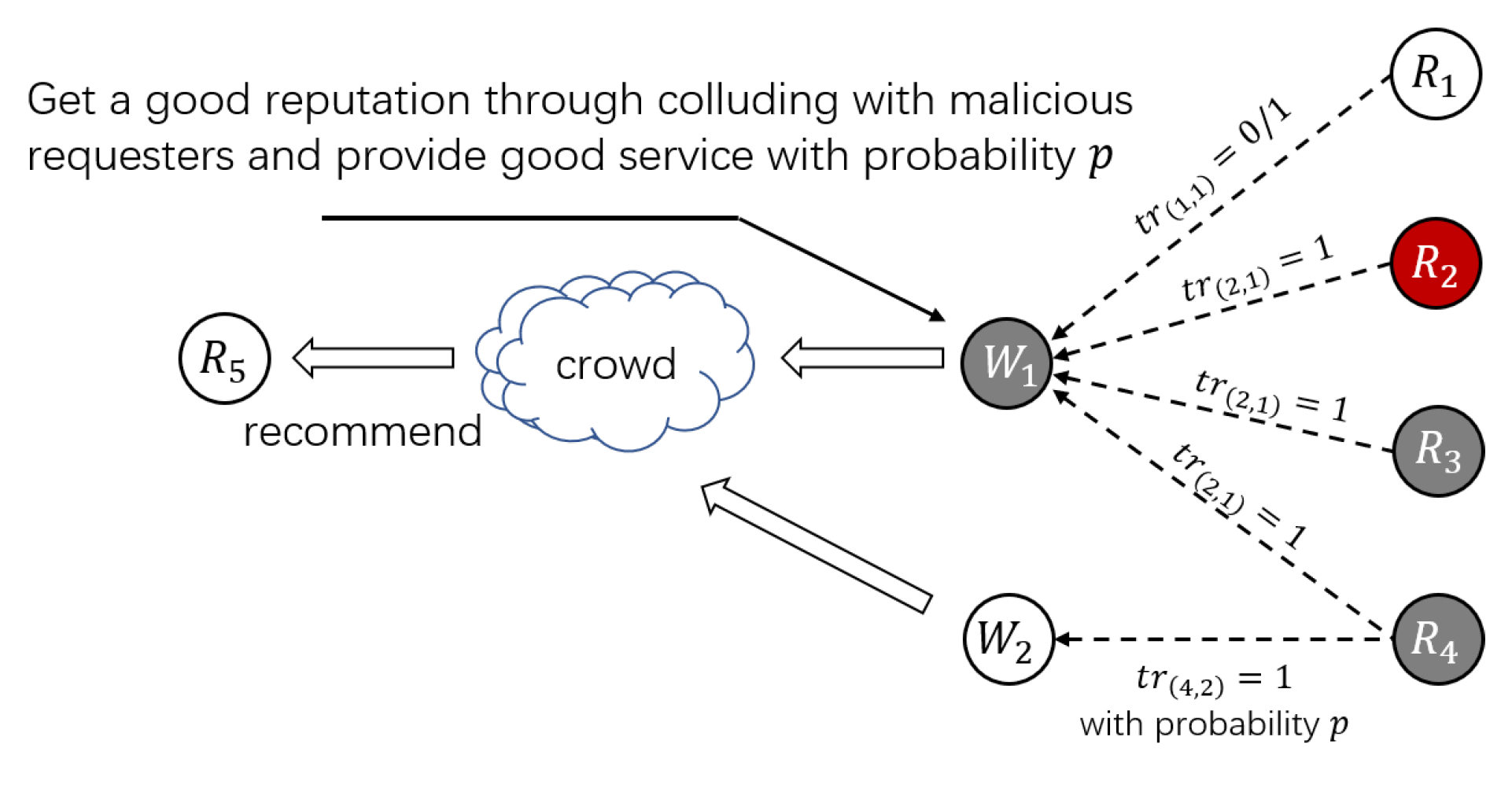
- S3: Camouflage Strategy. When the workers with camouflage strategy are chosen to complete a HIT published by an honest requester, they will provide valid services with a certain probability. On the other hand, the requester with the S3 strategy will also recruit some honest workers to complete HITs and give them real evaluations with a certain probability.
2. Related Work
2.1. Verification-Based Defense Model
2.2. Data Analysis Solution
2.3. Workers’ Properties Matching Mechanism
2.4. Trust-Based Model
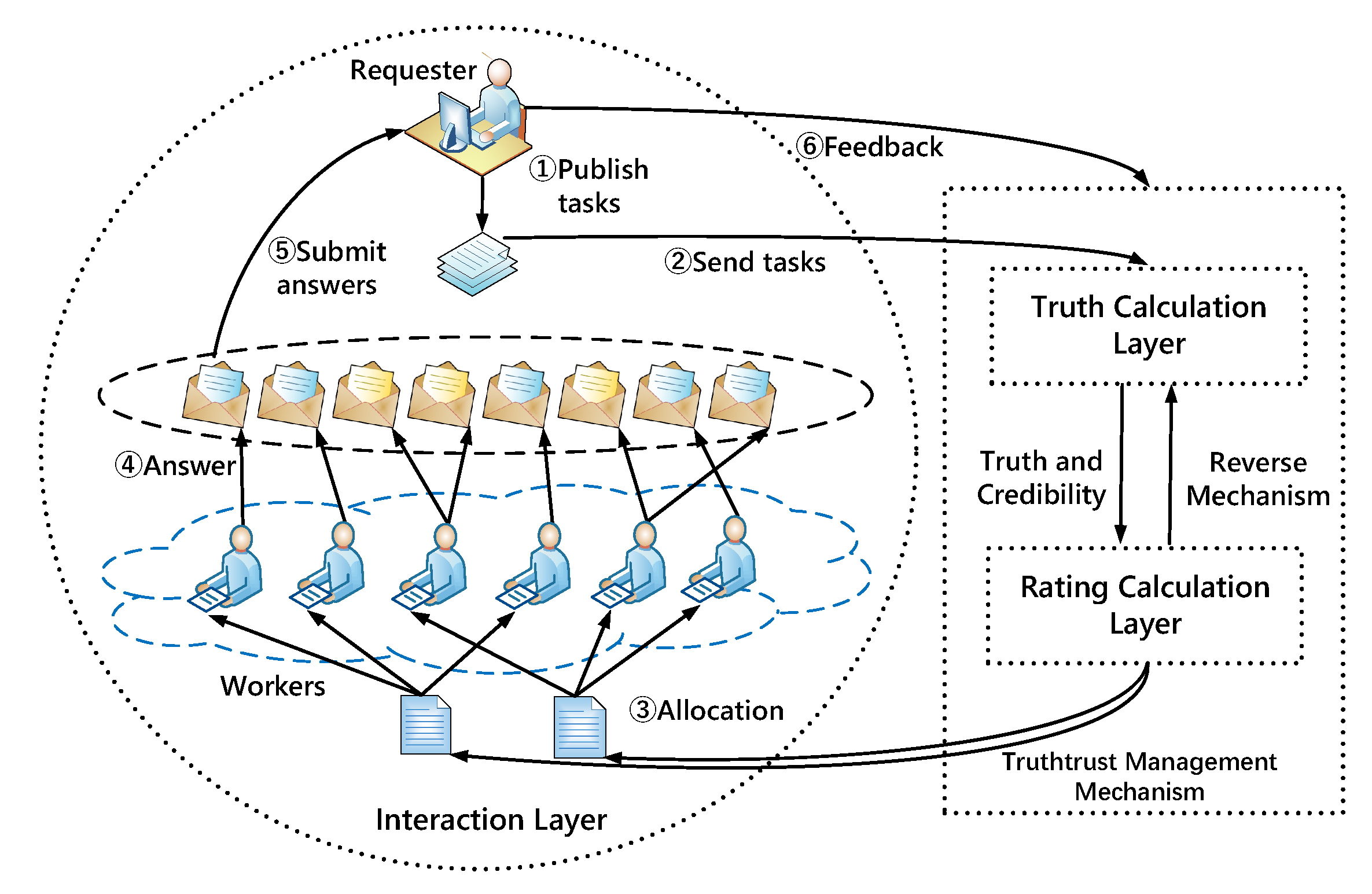
3. TruthTrust Model
3.1. Interaction Layer
3.2. Truth Calculation Layer
- Loss function. d is a loss function defined based on the satisfaction of service. This function measures the difference between the feedback and the identified truth . When the feedback approaches the true value, the loss function should output a low value, and when the feedback deviates from the truth, the loss function should output a high value.
- Regularization function. represents the constraint of the requester’s credibility. If each requester’s credibility is unconstrained, then the can be simply taken as , resulting in the unbounded optimization problem. To constrain the requester credibility into a certain range, we need to specify the regularization function and the domain S that is the entire requester set. For simplicity, we set the value of to be 1.
| Algorithm 1: Truth Inference Framework |
 |
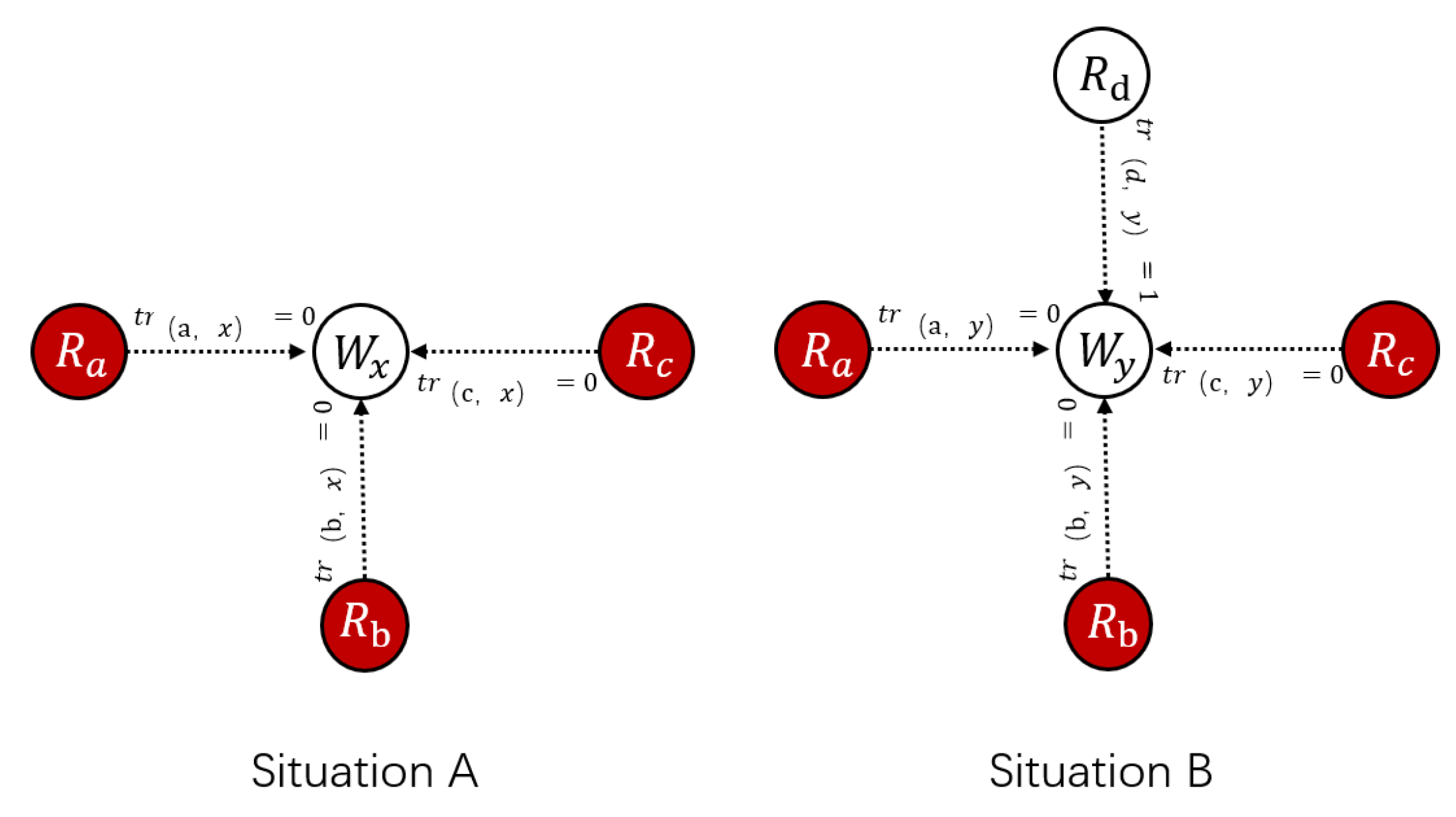
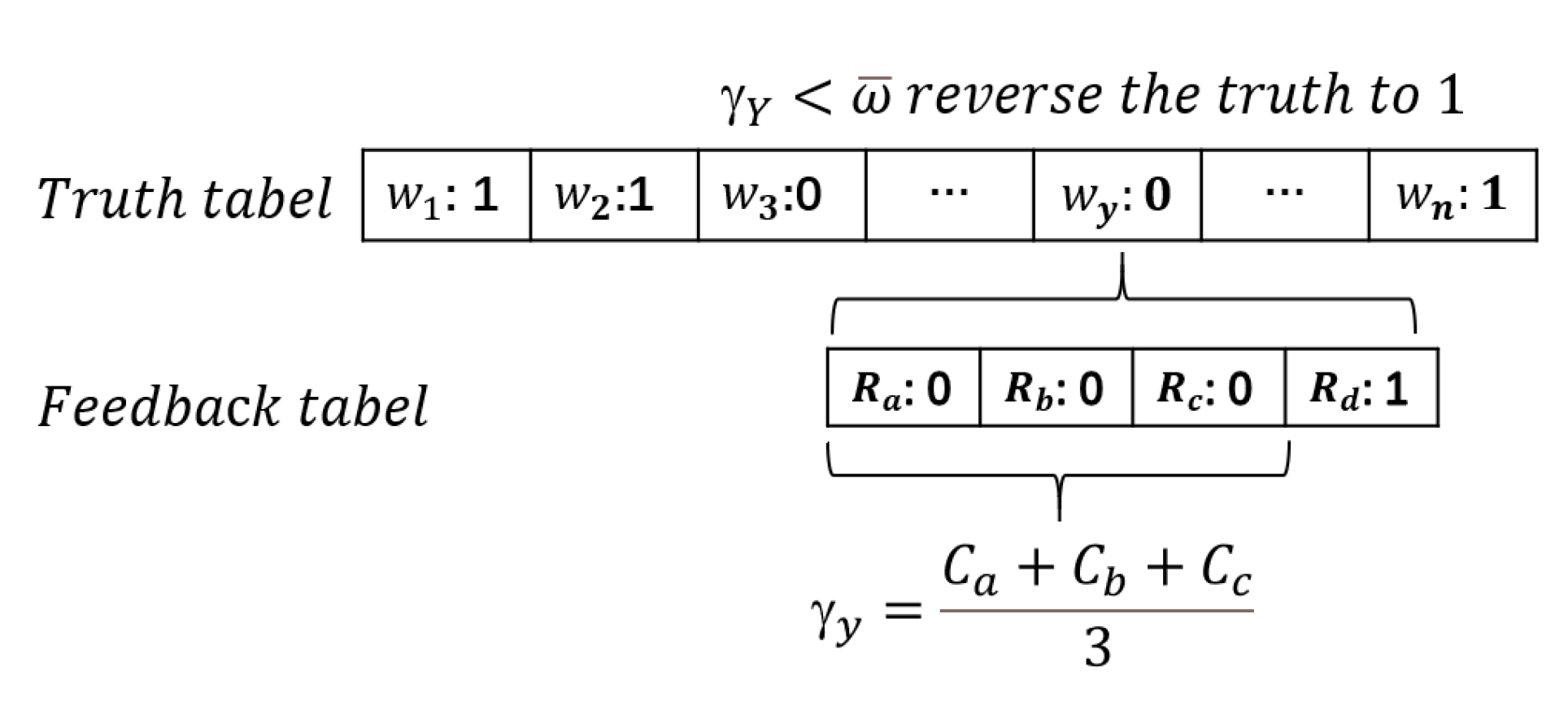
3.2.1. Reverse Mechanism
3.3. Rating Calculation Layer
| Algorithm 2: TruthTrust Algorithm |
 |
4. Experiments and Analysis
4.1. Experimental Setup
- CRH: The unimproved truth discovery and source reliability framework, which directly calculates the truth from the feedback data to the select appropriate workers.
- TSR: A trust-aware and resemblance based collaborative filtering recommendation model. In the TSR model, we select workers according to the similarity between workers and between requesters.
- AMT: An answer overall approval rate based trust model that is applied in the Amazon Mechanical Turk where requesters choose workers with a higher approval rate as the service provider.
4.2. Experiment 1: Effectiveness Analysis
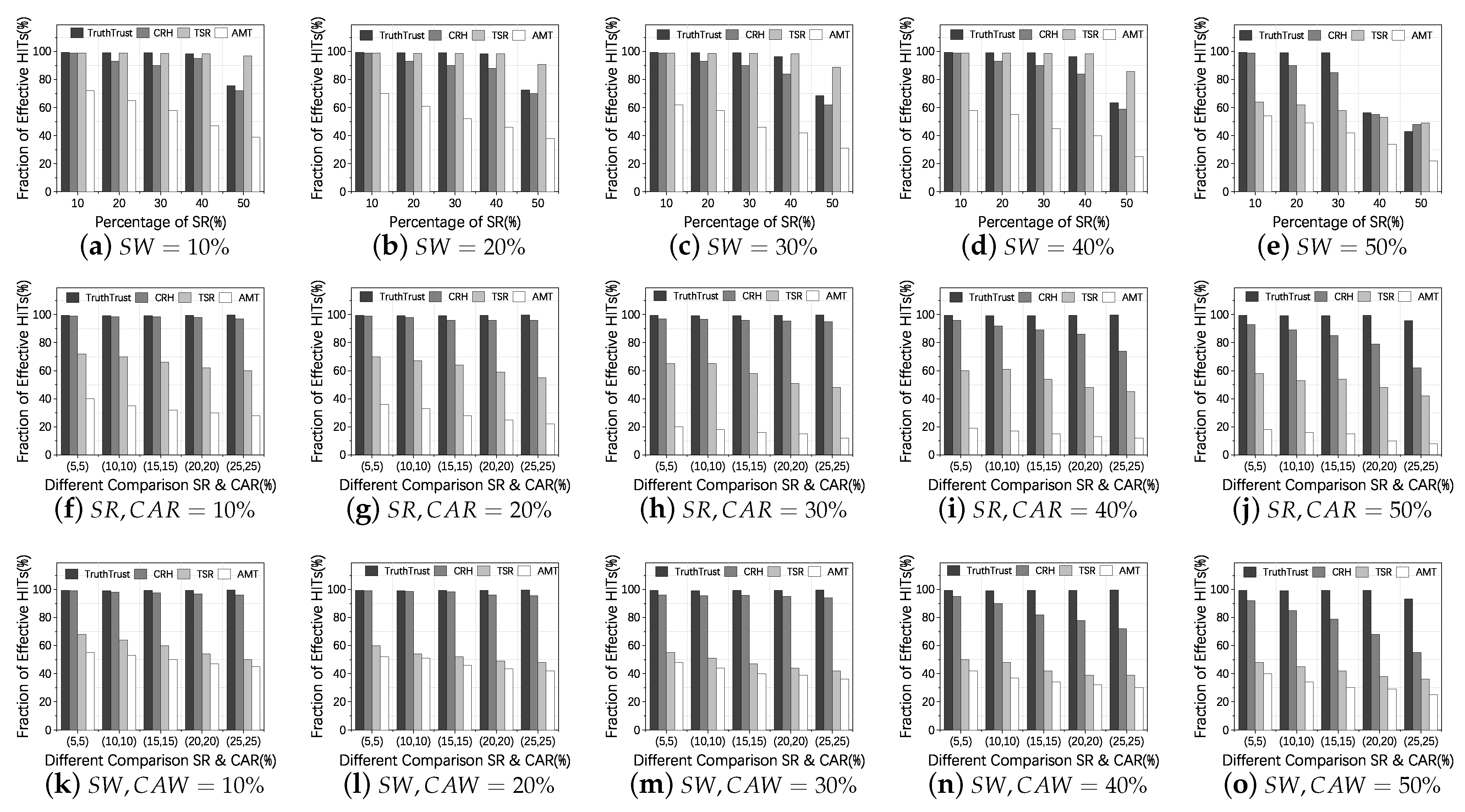
4.3. Experiment 2: Comparative Experiment
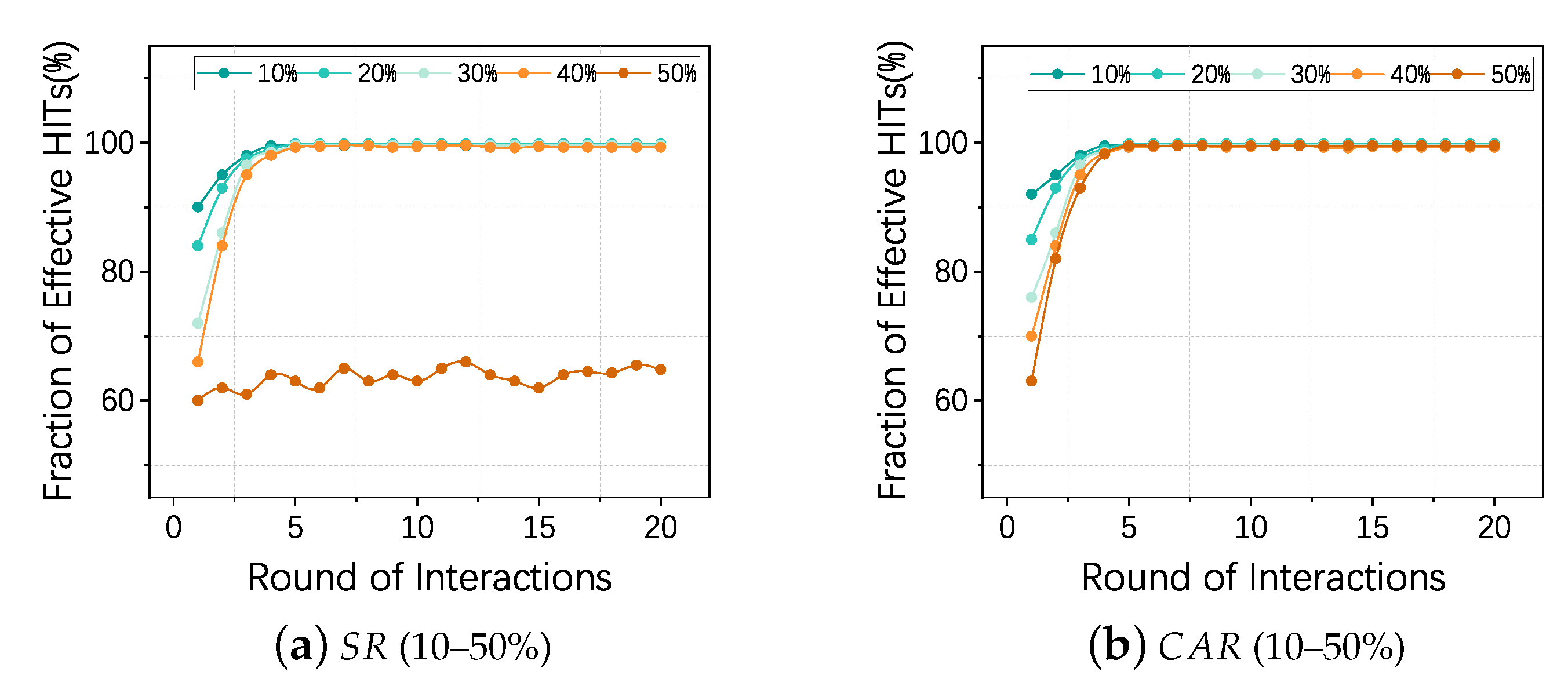
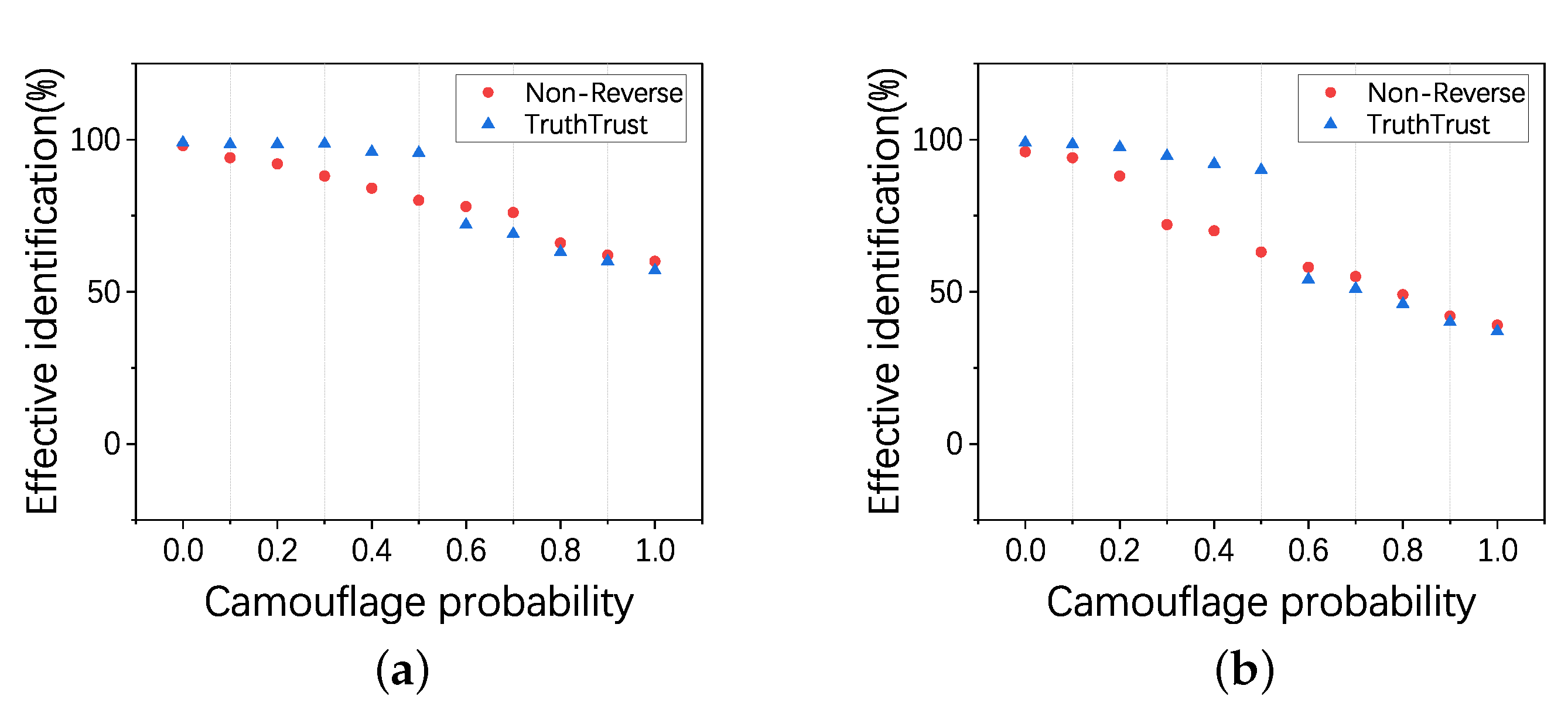
4.4. Experiment 3: Validity of the Reverse Mechanism
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, Q.; Gao, J.; Lin, W.; Li, X. NWPU-crowd: A large-scale benchmark for crowd counting and localization. arXiv 2020, arXiv:2001.03360. [Google Scholar] [CrossRef] [PubMed]
- Duan, Y.; Fu, G.; Zhou, N.; Sun, X.; Narendra, N.C.; Hu, B. Everything as a service (XaaS) on the cloud: Origins, current and future trends. In Proceedings of the 2015 IEEE 8th International Conference on Cloud Computing, New York, NY, USA, 27 June–2 July 2015; pp. 621–628. [Google Scholar]
- Wang, Q.; Gao, J.; Lin, W.; Yuan, Y. Learning from synthetic data for crowd counting in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8198–8207. [Google Scholar]
- Ye, B.; Wang, Y. Crowdrec: Trust-aware worker recommendation in crowdsourcing environments. In Proceedings of the 2016 IEEE International Conference on Web Services (ICWS), San Francisco, CA, USA, 27 June–2 July 2015; IEEE: New York, NY, USA, 2016; pp. 1–8. [Google Scholar]
- Mao, K.; Capra, L.; Harman, M.; Jia, Y. A survey of the use of crowdsourcing in software engineering. J. Syst. Softw. 2017, 126, 57–84. [Google Scholar] [CrossRef] [Green Version]
- Yuen, M.C.; King, I.; Leung, K.S. A survey of crowdsourcing systems. In Proceedings of the 2011 IEEE Third International Conference on Privacy, Security, Risk and Trust and 2011 IEEE Third International Conference on Social Computing, Boston, MA, USA, 9–11 October 2011; IEEE: New York, NY, USA, 2011; pp. 766–773. [Google Scholar]
- Xu, J.; Li, H. Adarank: A boosting algorithm for information retrieval. In Proceedings of the 30th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Amsterdam, The Netherlands, 23–27 July 2007; pp. 391–398. [Google Scholar]
- Miao, C.; Li, Q.; Xiao, H.; Jiang, W.; Huai, M.; Su, L. Towards data poisoning attacks in crowd sensing systems. In Proceedings of the Eighteenth ACM International Symposium on Mobile Ad Hoc Networking and Computing, Los Angeles, CA, USA, 25–28 June 2018; pp. 111–120. [Google Scholar]
- Hirth, M.; Hoßfeld, T.; Tran-Gia, P. Cheat-Detection Mechanisms for Crowdsourcing; Tech. Rep; University of Würzburg: Würzburg, Germany, 2010; Volume 4. [Google Scholar]
- Wang, G.; Wang, B.; Wang, T.; Nika, A.; Zheng, H.; Zhao, B.Y. Defending against sybil devices in crowdsourced mapping services. In Proceedings of the 14th Annual International Conference on Mobile Systems, Applications, and Services, Singapore, 25–30 June 2016; pp. 179–191. [Google Scholar]
- Sanchez, L.; Rosas, E.; Hidalgo, N. Crowdsourcing under attack: Detecting malicious behaviors in Waze. In Proceedings of the IFIP International Conference on Trust Management, Toronto, ON, Canada, 9–13 July 2018; Springer: Toronto, ON, Canada, 2018; pp. 91–106. [Google Scholar]
- Wang, G.; Wang, B.; Wang, T.; Nika, A.; Zheng, H.; Zhao, B.Y. Ghost riders: Sybil attacks on crowdsourced mobile mapping services. IEEE/ACM Trans. Netw. 2018, 26, 1123–1136. [Google Scholar] [CrossRef]
- Raykar, V.C.; Yu, S. Eliminating spammers and ranking annotators for crowdsourced labeling tasks. J. Mach. Learn. Res. 2012, 13, 491–518. [Google Scholar]
- Wang, J.; Ni, S.; Shen, S.; Li, S. Empirical study of crowd dynamic in public gathering places during a terrorist attack event. Phys. A Stat. Mech. Its Appl. 2019, 523, 1–9. [Google Scholar] [CrossRef]
- Kittur, A.; Chi, E.H.; Suh, B. Crowdsourcing user studies with Mechanical Turk. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Florence, Italy, 5–10 April 2008; pp. 453–456. [Google Scholar]
- Chen, K.T.; Chang, C.J.; Wu, C.C.; Chang, Y.C.; Lei, C.L. Quadrant of euphoria: A crowdsourcing platform for QoE assessment. IEEE Netw. 2010, 24, 28–35. [Google Scholar] [CrossRef]
- Hirth, M.; Hoßfeld, T.; Tran-Gia, P. Cost-optimal validation mechanisms and cheat-detection for crowdsourcing platforms. In Proceedings of the 2011 Fifth International Conference on Innovative Mobile and Internet Services in Ubiquitous Computing, Seoul, Korea, 30 June–2 July 2011; IEEE: New York, NY, USA, 2011; pp. 316–321. [Google Scholar]
- Du, Y.; Sun, Y.E.; Huang, H.; Huang, L.; Xu, H.; Bao, Y.; Guo, H. Bayesian co-clustering truth discovery for mobile crowd sensing systems. IEEE Trans. Ind. Inform. 2019, 16, 1045–1057. [Google Scholar] [CrossRef]
- Liu, X.; Baras, J.S. Crowdsourcing with multi-dimensional trust and active learning. In Proceedings of the 2017 IEEE 56th Annual Conference on Decision and Control (CDC), Melbourne, Australia, 12–15 December 2017; pp. 3224–3231. [Google Scholar]
- Lin, J.; Yang, D.; Wu, K.; Tang, J.; Xue, G. A sybil-resistant truth discovery framework for mobile crowdsensing. In Proceedings of the 2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS), Richardson, TX, USA, 7–9 July 2019; pp. 871–880. [Google Scholar]
- Huang, Z.; Pan, M.; Gong, Y. Robust truth discovery against data poisoning in mobile crowdsensing. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Waikoloa, HI, USA, 9–13 December 2019; pp. 1–6. [Google Scholar]
- Ye, B.; Wang, Y.; Liu, L. Crowd trust: A context-aware trust model for worker selection in crowdsourcing environments. In Proceedings of the 2015 IEEE International Conference on Web Services, New York, NY, USA, 27 June–2 July 2015; pp. 121–128. [Google Scholar]
- Yuen, M.C.; King, I.; Leung, K.S. Task matching in crowdsourcing. In Proceedings of the 2011 International Conference on Internet of Things and 4th International Conference on Cyber, Physical and Social Computing, Dalian, China, 19–22 October 2011; IEEE: New York, NY, USA, 2011; pp. 409–412. [Google Scholar]
- Jiang, J.; An, B.; Jiang, Y.; Lin, D. Context-aware reliable crowdsourcing in social networks. IEEE Trans. Syst. Man Cybern. Syst. 2017, 50, 617–632. [Google Scholar] [CrossRef]
- Karger, D.; Oh, S.; Shah, D. Iterative learning for reliable crowdsourcing systems. Adv. Neural Inf. Process. Syst. 2011, 24, 1953–1961. [Google Scholar]
- Yu, H.; Shen, Z.; Miao, C.; An, B. Challenges and opportunities for trust management in crowdsourcing. In Proceedings of the 2012 IEEE/WIC/ACM International Conferences on Web Intelligence and Intelligent Agent Technology, Macau, China, 4–7 December 2012; IEEE: New York, NY, USA, 2012; Volume 2, pp. 486–493. [Google Scholar]
- Kantarci, B.; Glasser, P.M.; Foschini, L. Crowdsensing with social network-aided collaborative trust scores. In Proceedings of the 2015 IEEE Global Communications Conference (GLOBECOM), San Diego, CA, USA, 6–10 December 2015; IEEE: New York, NY, USA, 2015; pp. 1–6. [Google Scholar]
- Ye, B.; Wang, Y.; Liu, L. CrowdDefense: A trust vector-based threat defense model in crowdsourcing environments. In Proceedings of the 2017 IEEE International Conference on Web Services (ICWS), Honolulu, HI, USA, 25–30 June 2017; IEEE: New York, NY, USA, 2017; pp. 245–252. [Google Scholar]
- Zheng, Y.; Li, G.; Li, Y.; Shan, C.; Cheng, R. Truth inference in crowdsourcing: Is the problem solved? Proc. VLDB Endow. 2017, 10, 541–552. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Gao, J.; Meng, C.; Li, Q.; Su, L.; Zhao, B.; Fan, W.; Han, J. A survey on truth discovery. ACM Sigkdd Explor. Newsl. 2016, 17, 1–16. [Google Scholar] [CrossRef]
- Li, Y.; Li, Q.; Gao, J.; Su, L.; Zhao, B.; Fan, W.; Han, J. On the discovery of evolving truth. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, NSW, Australia, 10–13 August 2015; pp. 675–684. [Google Scholar]
- Kucherbaev, P.; Daniel, F.; Tranquillini, S.; Marchese, M. Crowdsourcing processes: A survey of approaches and opportunities. IEEE Internet Comput. 2015, 20, 50–56. [Google Scholar] [CrossRef] [Green Version]
- Ghezzi, A.; Gabelloni, D.; Martini, A.; Natalicchio, A. Crowdsourcing: A review and suggestions for future research. Int. J. Manag. Rev. 2018, 20, 343–363. [Google Scholar] [CrossRef]
- Bruneau, N.; Carlet, C.; Guilley, S.; Heuser, A.; Prouff, E.; Rioul, O. Stochastic collision attack. IEEE Trans. Inf. Forensics Secur. 2017, 12, 2090–2104. [Google Scholar] [CrossRef]
- Deng, S.G.; Huang, L.T.; Wu, J.; Wu, Z.H. Trust-based personalized service recommendation: A network perspective. J. Comput. Sci. Technol. 2014, 29, 69–80. [Google Scholar] [CrossRef]
- Vakharia, D.; Lease, M. Beyond AMT: An analysis of crowd work platforms. arXiv 2013, arXiv:1310.1672. [Google Scholar]
- Fahad, A.; Alshatri, N.; Tari, Z.; Alamri, A.; Khalil, I.; Zomaya, A.Y.; Foufou, S.; Bouras, A. A survey of clustering algorithms for big data: Taxonomy and empirical analysis. IEEE Trans. Emerg. Top. Comput. 2014, 2, 267–279. [Google Scholar] [CrossRef]
- Aljalbout, E.; Golkov, V.; Siddiqui, Y.; Strobel, M.; Cremers, D. Clustering with deep learning: Taxonomy and new methods. arXiv 2018, arXiv:1801.07648. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Items | Entries | Descriptions |
|---|---|---|
| Platform | Workers Kind of Tasks # of skills of each worker # of requesters # of HITs for training # of HITs for each round # of simulation cycles in one experiment # of experiments results are averaged HIT’s distribution | 1000 30 5 80 5000 3000 20 5 Normal distribution |
| Identities | Descriptions |
|---|---|
| Spam Worker (SW) Camouflage Worker (CAW) Honest Worker (HW) | Always provide malicious service Provide a effective service with the probability p Always provide effective services |
| Spam Requester (SR) Camouflage Requester (CAR) Honester Requester (HR) | Always provide fake feedback Provide real feedback with the probability p Provide real feedback with 95% probability |
| Threat Pattern | (SW%, CAW%) | (SR%, CAR%) |
|---|---|---|
| Threat Pattern A | (10,0), (20,0), ..., (50,0) | (10,0), (20,0), ..., (50,0) |
| Threat Pattern B | (10,0), (20,0), ..., (50,0) | (5,5), (10,10), (15,15), (20,20), (25,25) |
| Threat Pattern C | ((5,5), (10,10), (15,15), (20,20), (25,25) | (5,5), (10,10), (15,15), (20,20), (25,25) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, J.; Jin, X.; Yu, L.; Xue, L.; Ren, Y. TruthTrust: Truth Inference-Based Trust Management Mechanism on a Crowdsourcing Platform. Sensors 2021, 21, 2578. https://doi.org/10.3390/s21082578
Zhou J, Jin X, Yu L, Xue L, Ren Y. TruthTrust: Truth Inference-Based Trust Management Mechanism on a Crowdsourcing Platform. Sensors. 2021; 21(8):2578. https://doi.org/10.3390/s21082578
Chicago/Turabian StyleZhou, Jiyuan, Xing Jin, Lanping Yu, Limin Xue, and Yizhi Ren. 2021. "TruthTrust: Truth Inference-Based Trust Management Mechanism on a Crowdsourcing Platform" Sensors 21, no. 8: 2578. https://doi.org/10.3390/s21082578