
DNet: Dynamic Neighborhood Feature Learning in Point Cloud

Abstract
:1. Introduction
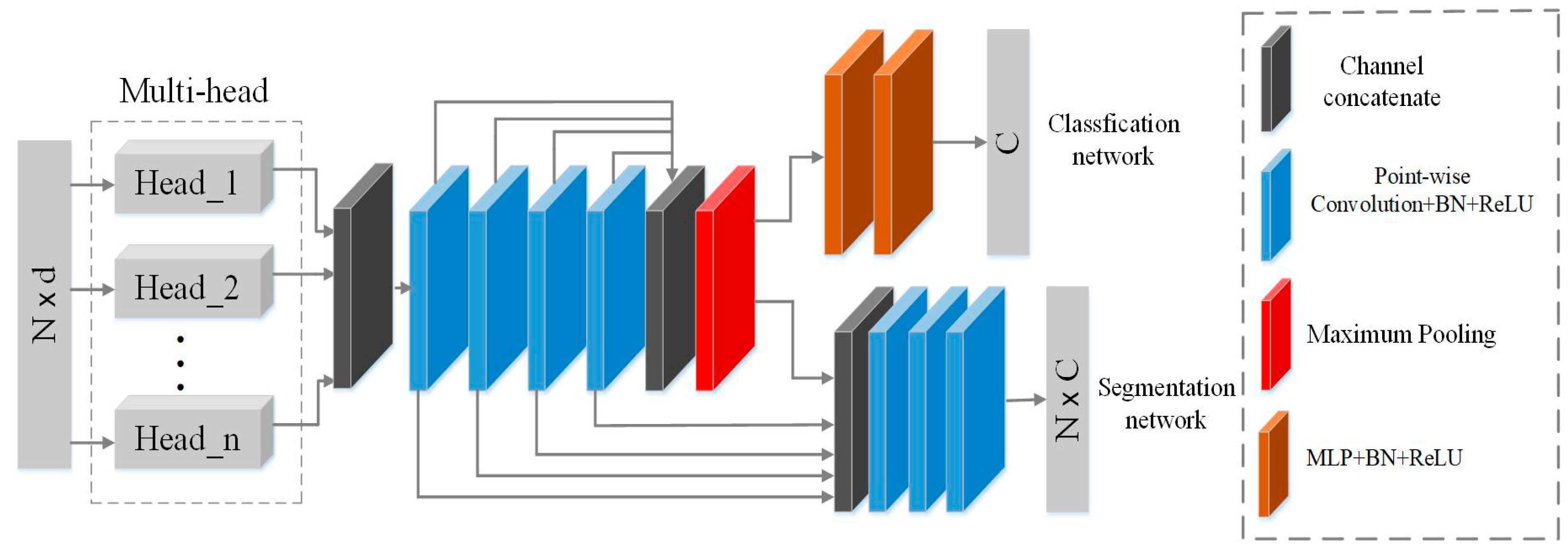
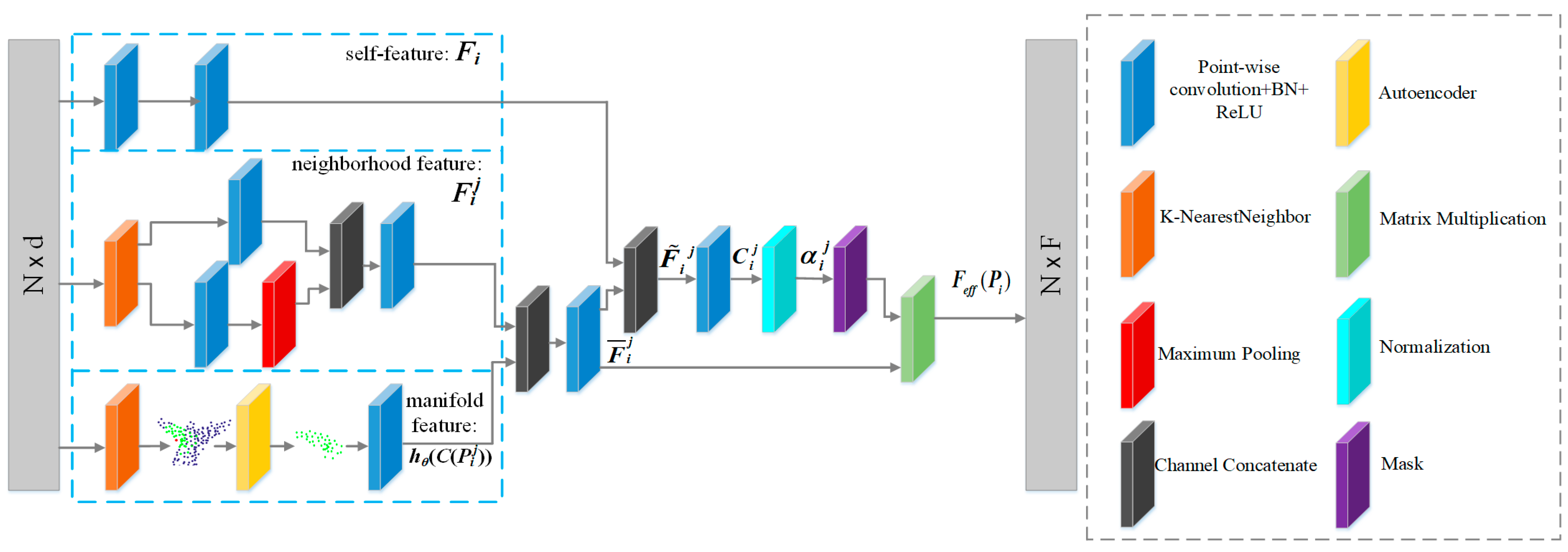
- To learn the features of different scales of a point cloud, a multi-head structure is designed to effectively capture multi-scale features, and the Feature Enhancement Layer (FELayer) inside each head supplements the manifold features of local regions of the point cloud, so that each head can learn enough contextual information;
- An attention mechanism is proposed to obtain the contribution degree of each neighborhood point in a local region through learning the self-features, 2D manifold features and neighborhood features of the local region;
- A masking mechanism is designed to remove the pseudo neighborhood points that may mislead the neighborhood learning but keep the ones which are conducive to network understanding, so that the network can learn neighborhood features more reasonably and effectively.
2. Motivation
- (1)
- How to choose the number of points in a neighborhood, and whether the number of neighborhood points of all points in a point cloud should be equal.
- (2)
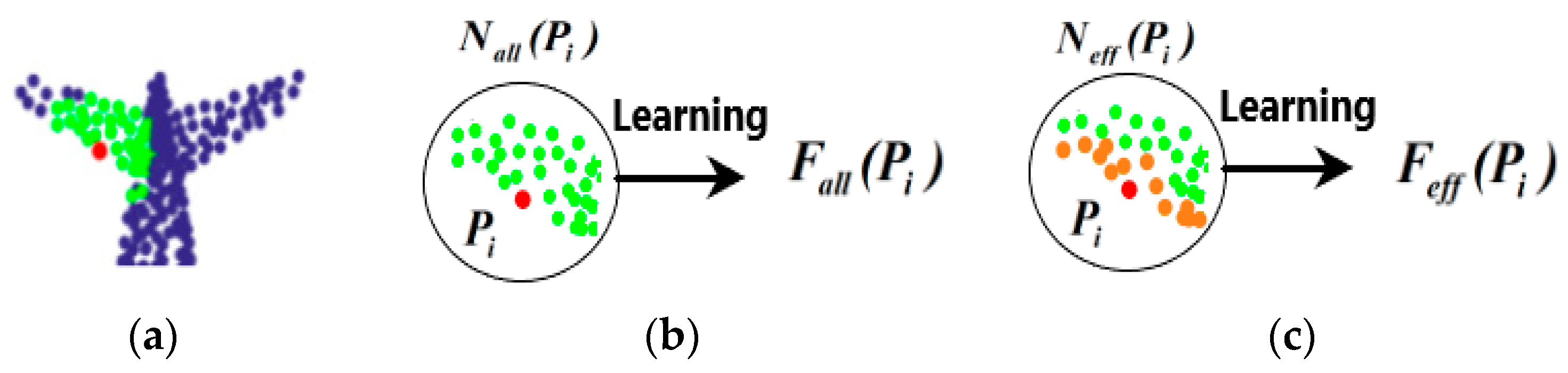
- If the neighborhood is determined, whether all points in the neighborhood help to understand the point cloud.
- (3)
- Do these neighborhood points contribute equally to the correct understanding of point clouds?
- (1)
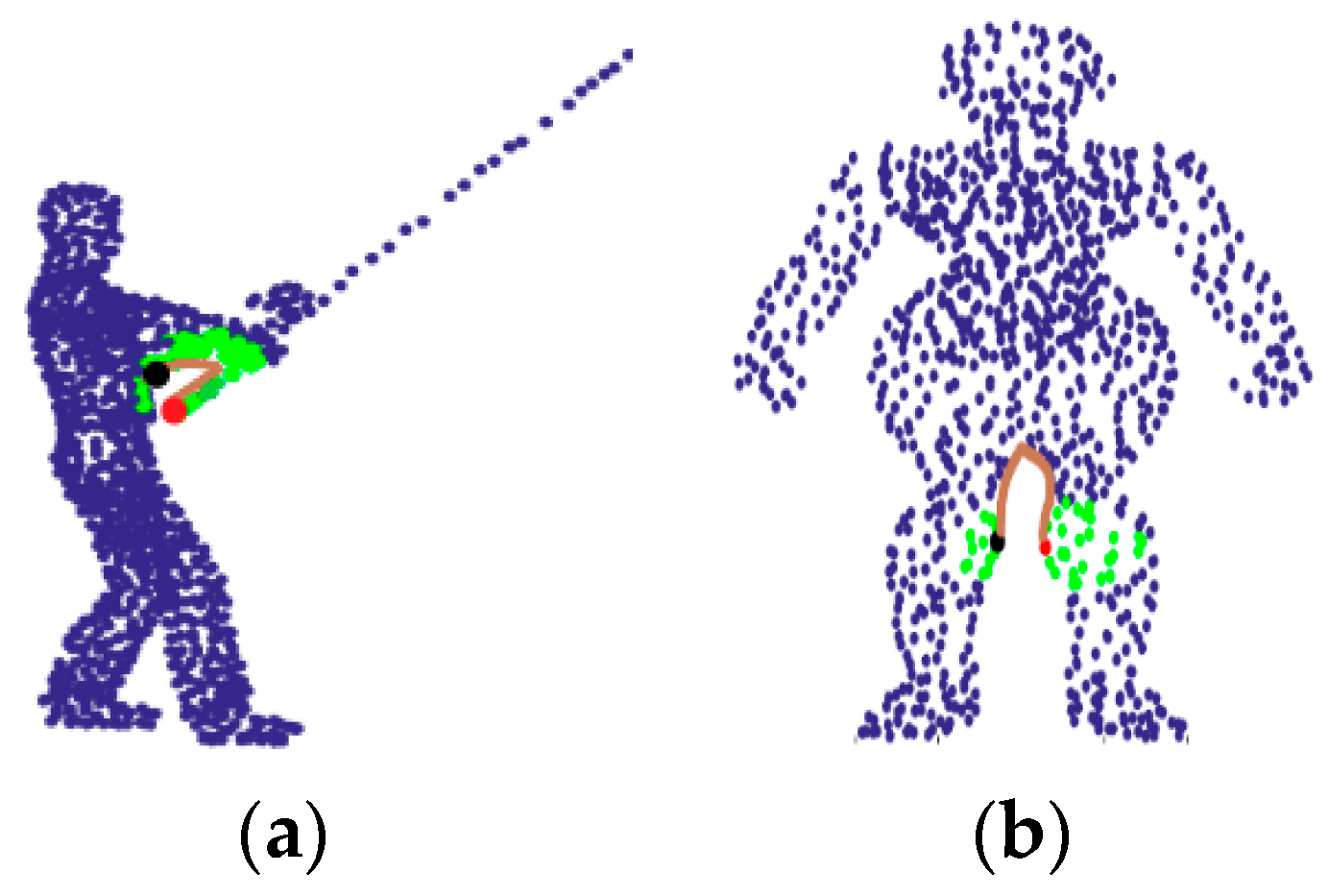
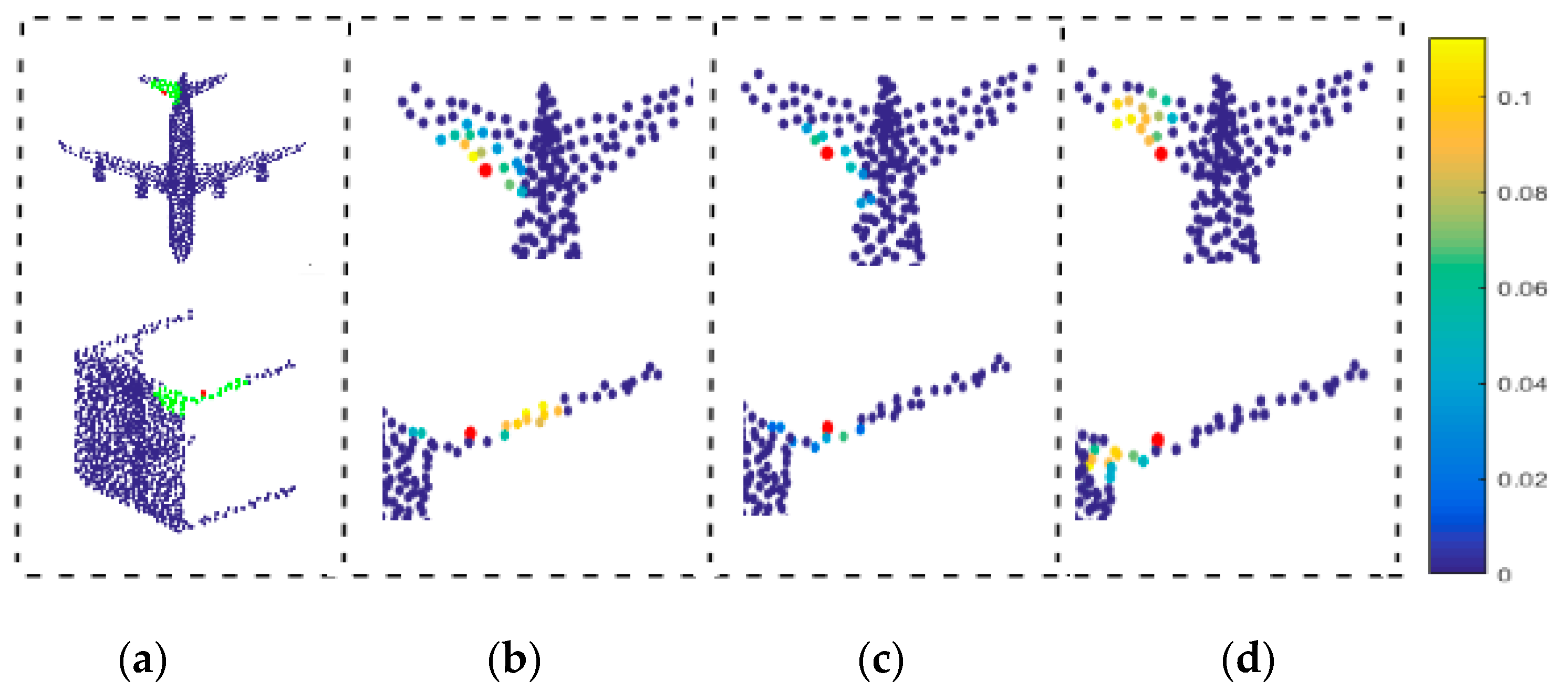
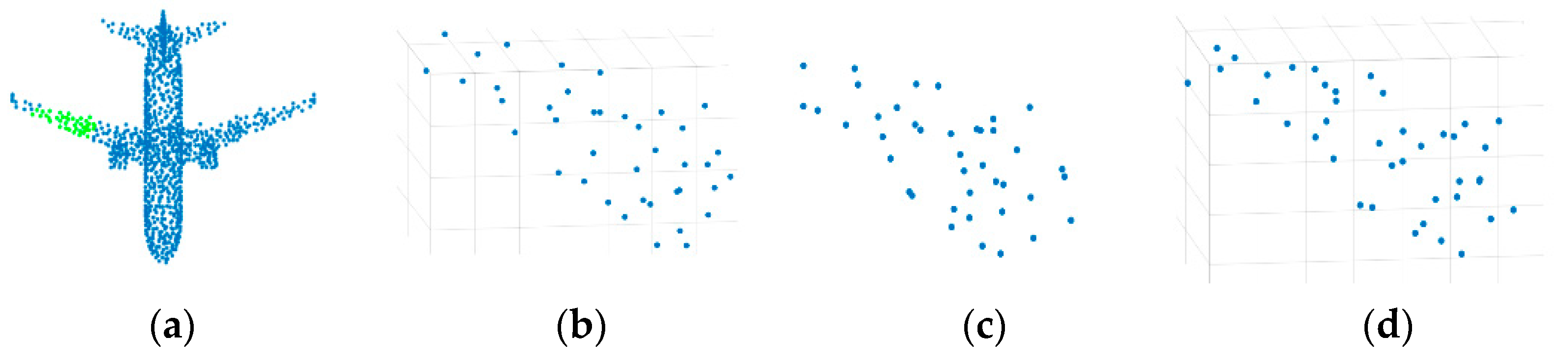
- When the point cloud has pathological neighborhood (as shown in Figure 1), the network is expected to have the ability of learning the correct neighborhood points and discarding the pseudo neighborhood point.
- (2)
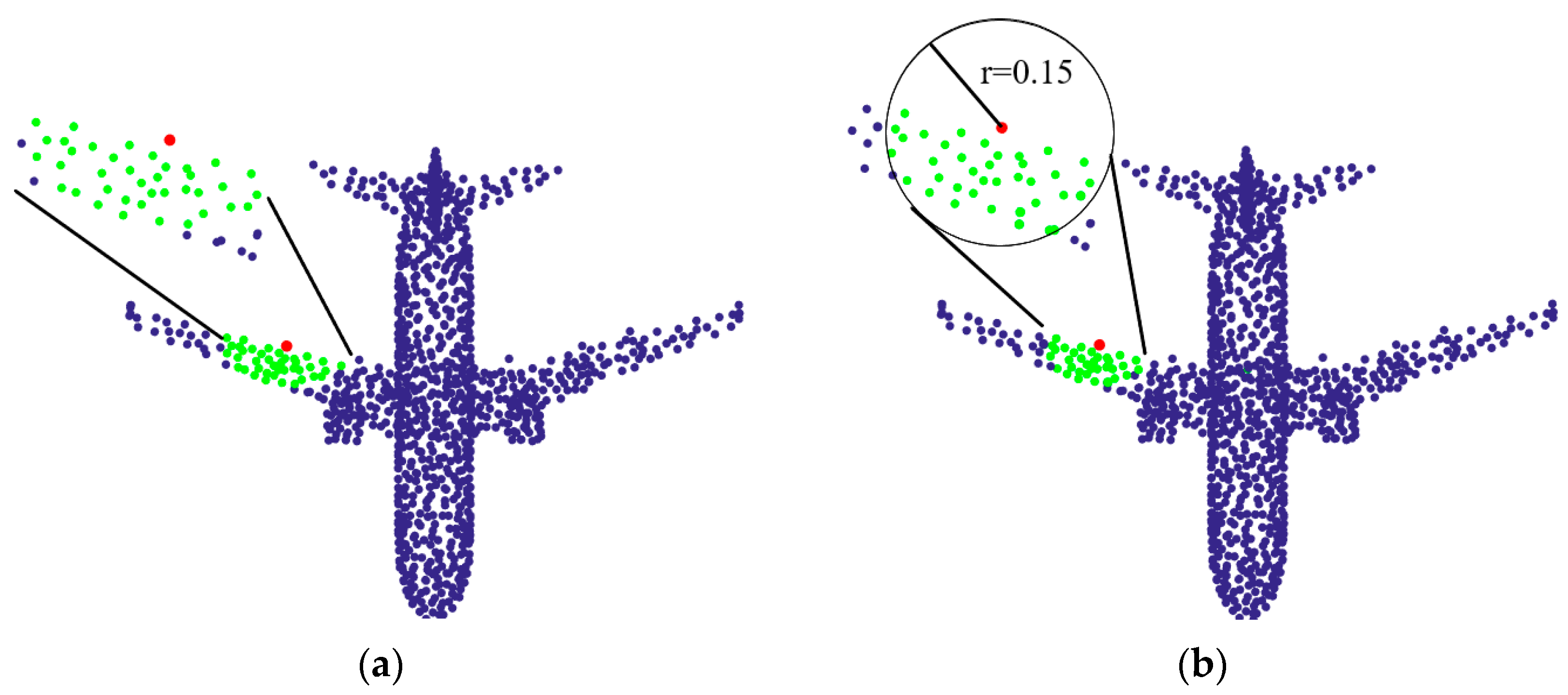
- When the center point is at the edge (as shown in the red point in Figure 2), the network is hoped to learn the edge features of the point cloud instead of the plane features.
3. The Proposed Network
3.1. Neighborhood Convolution
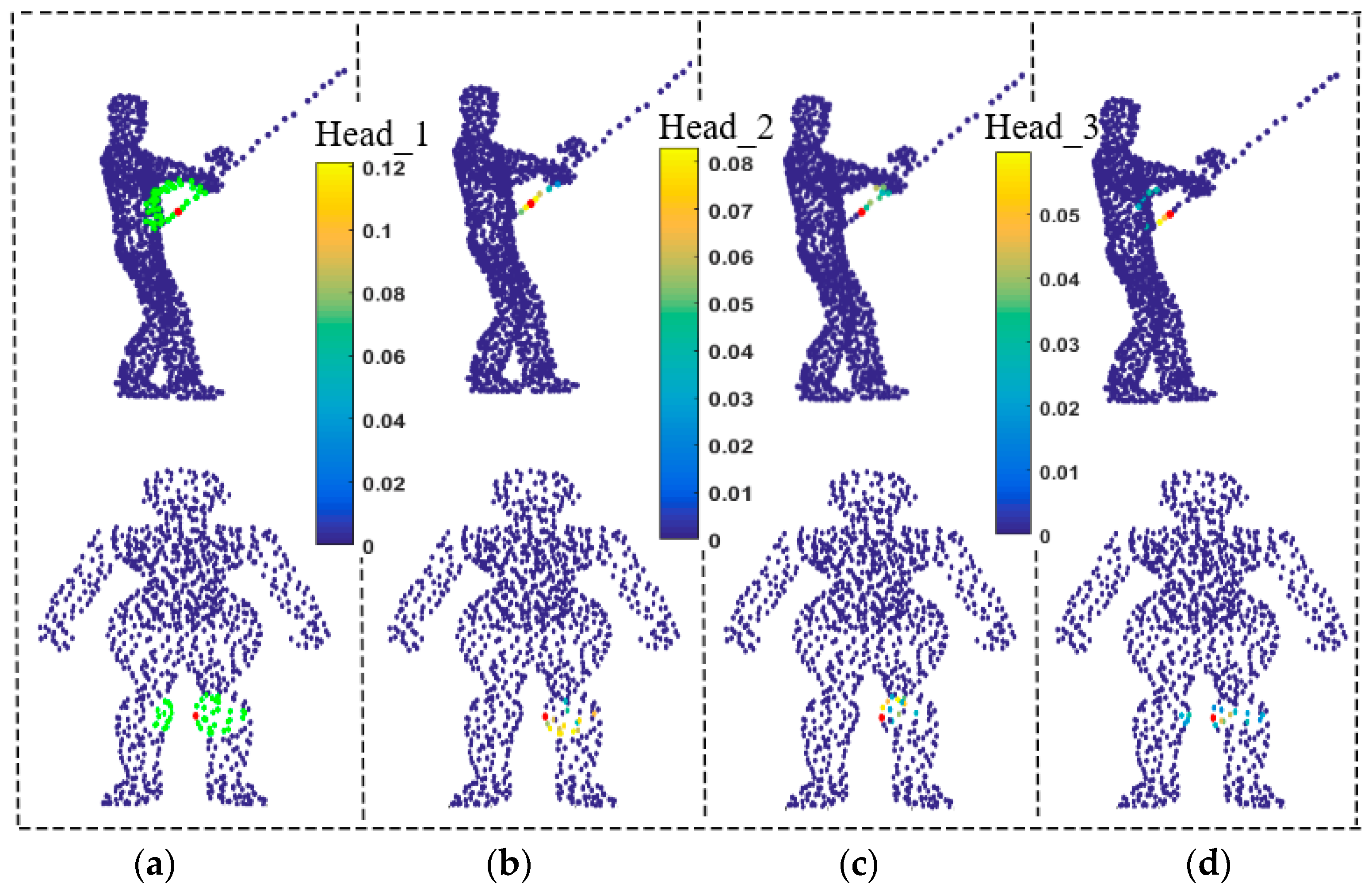
3.2. Multi-Head Structure
3.3. Masking Mechanism
3.4. Learning with DNet
3.5. Loss Function
4. Experimental Results and Discussions
4.1. Network Training
4.2. Point Cloud Classification
4.3. Point Cloud Segmentation
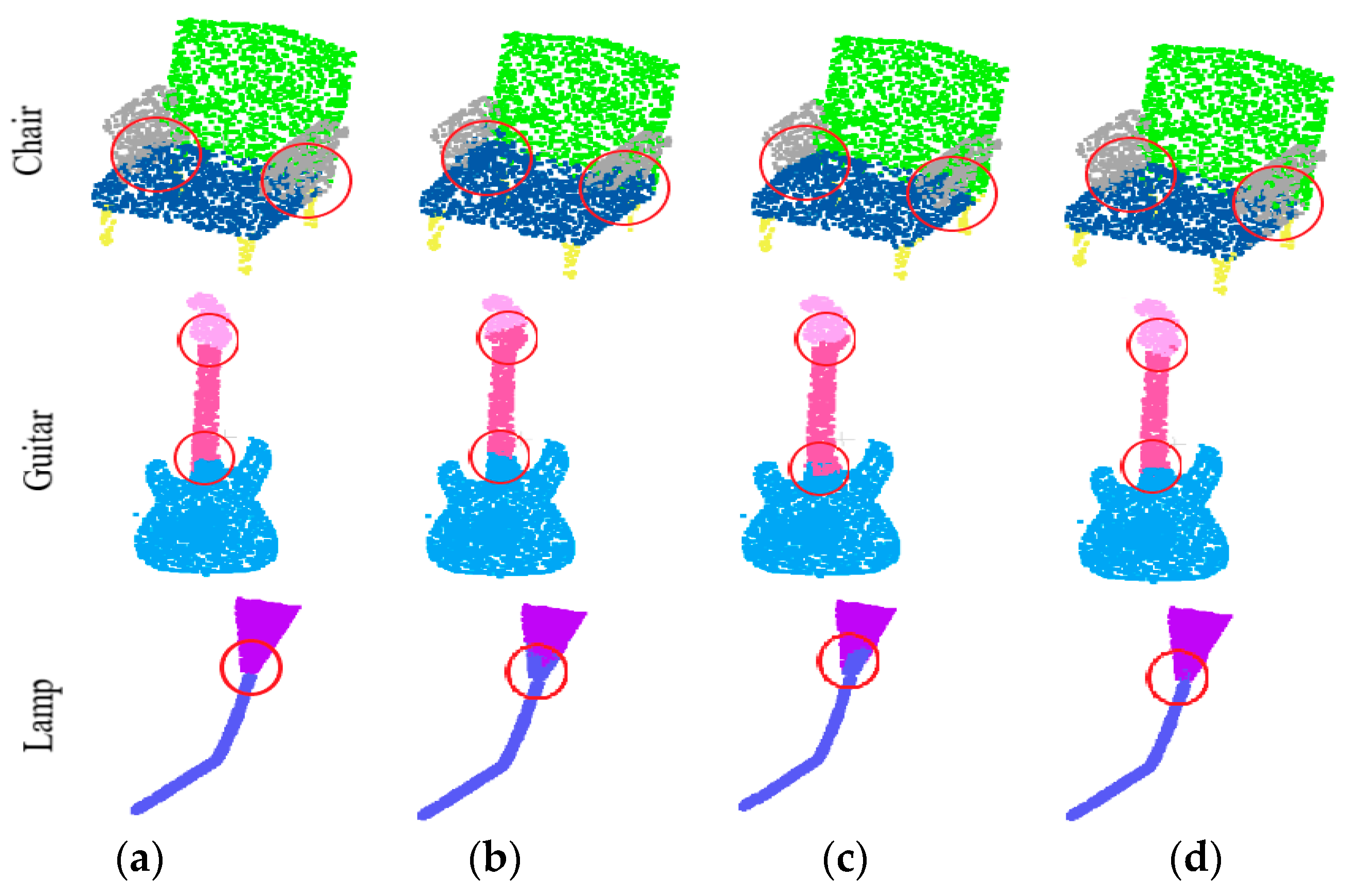
4.3.1. Part Segmentation of Point Cloud
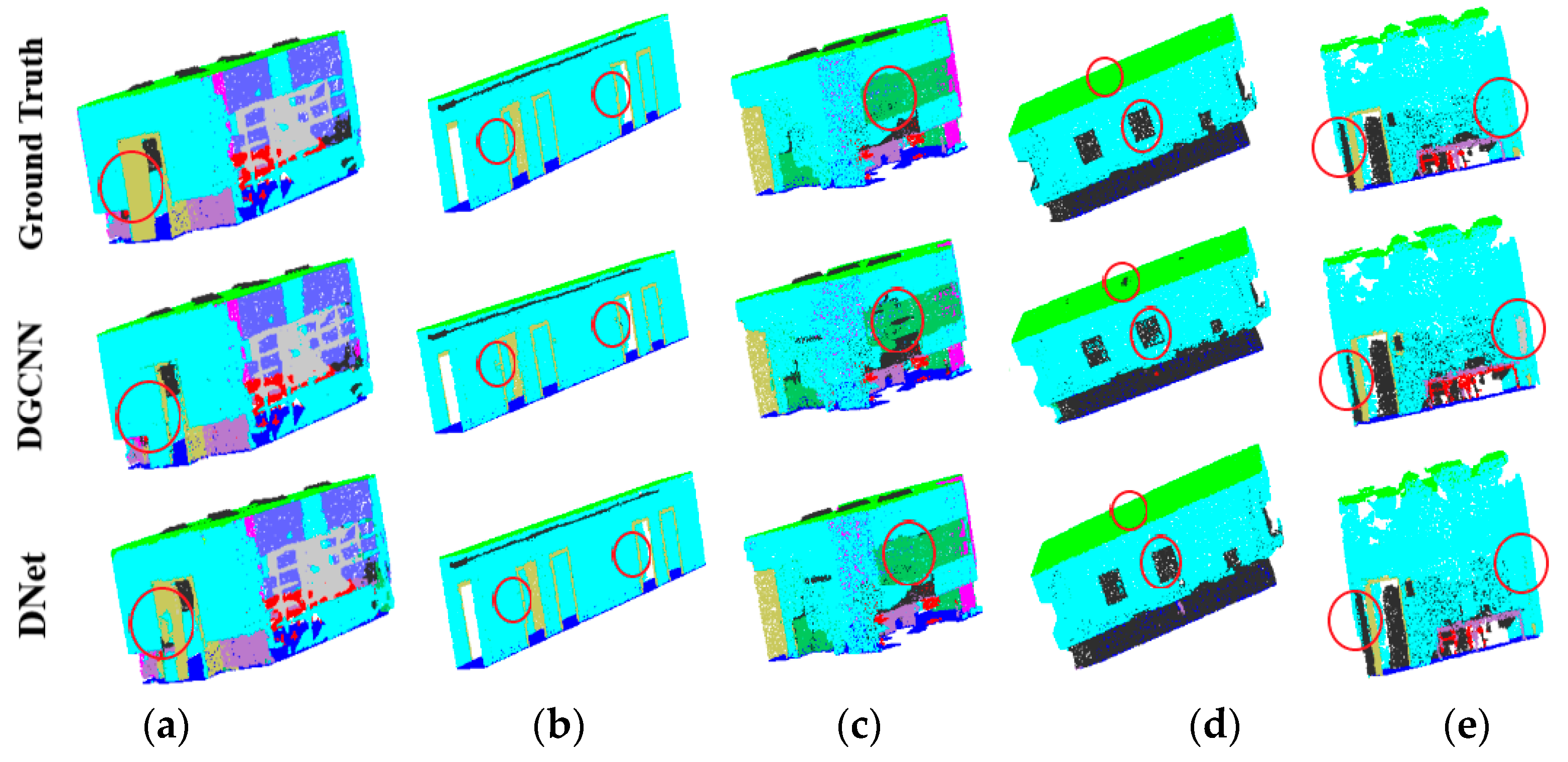
4.3.2. Scene Segmentation of Point Cloud
4.4. Ablation Experiments
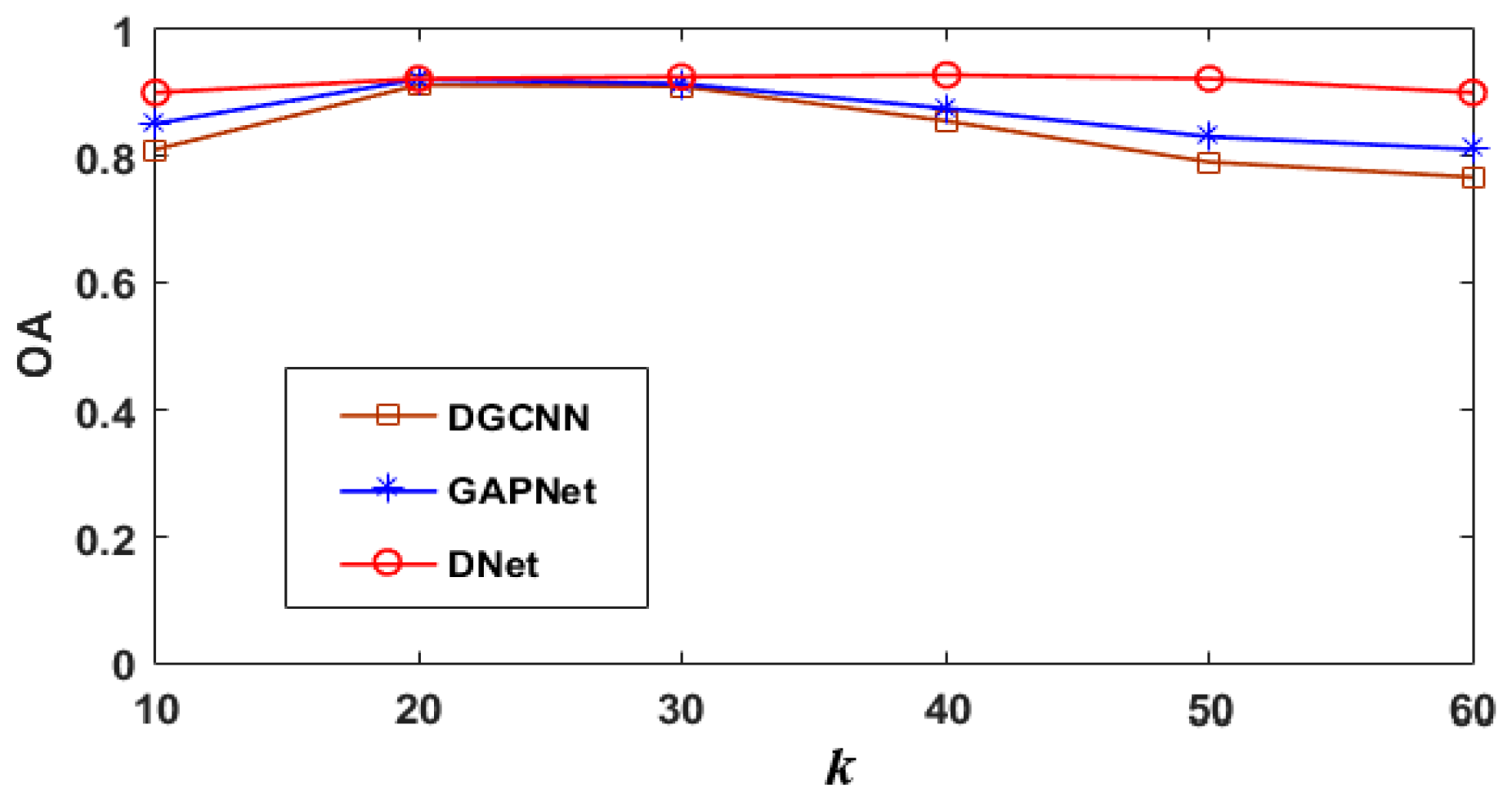
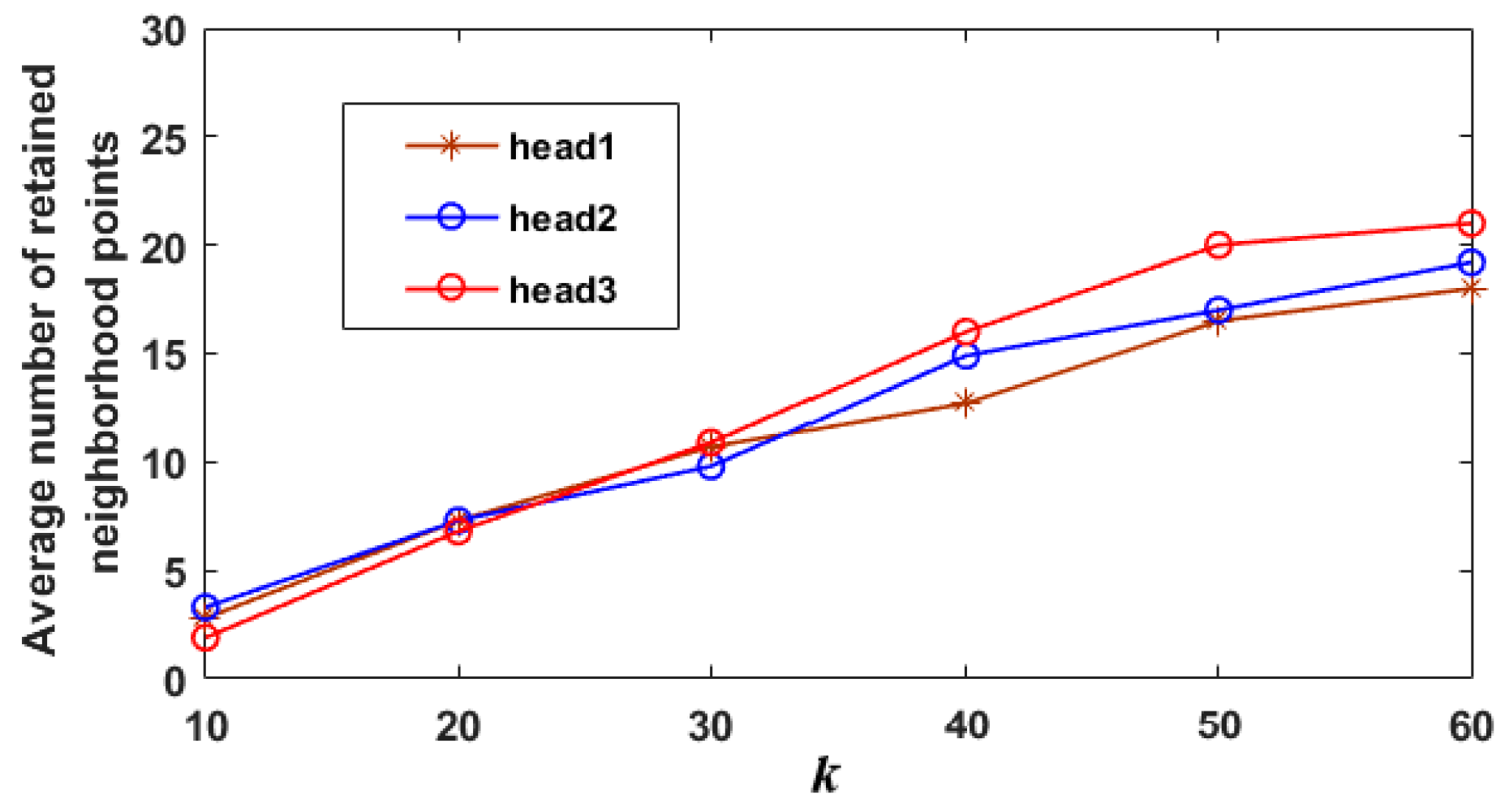
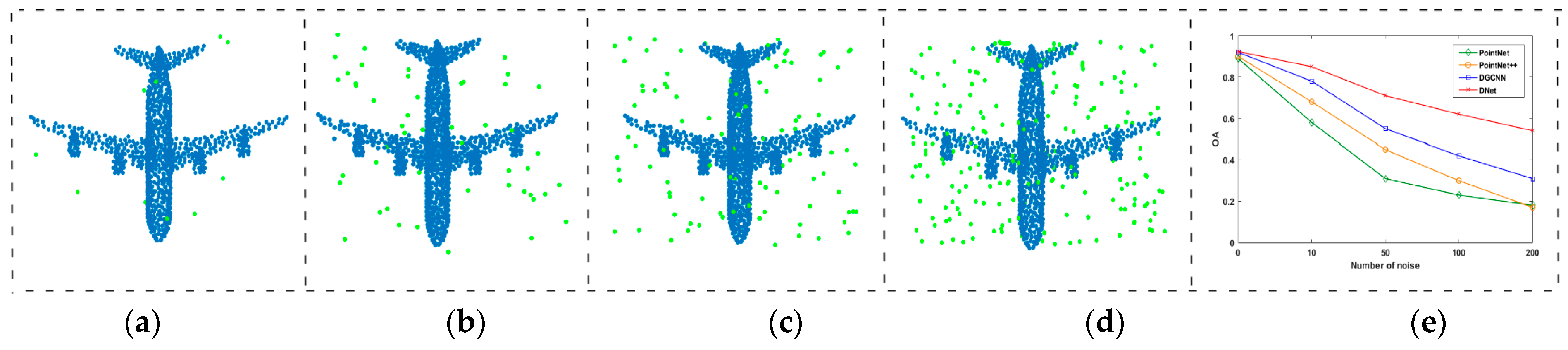
4.5. Robustness Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tsai, C.; Lai, Y.; Sun, Y.; Chung, Y.; Perng, J. Multi-dimensional underwater point cloud detection based on deep learning. Sensors 2021, 21, 884. [Google Scholar] [CrossRef] [PubMed]
- Yang, Y.; Ma, Y.; Zhang, J.; Gao, X.; Xu, M. AttPNet: Attention-based deep neural network for 3D point set analysis. Sensors 2020, 20, 5455. [Google Scholar] [CrossRef] [PubMed]
- Yuan, Y.; Borrmann, D.; Hou, J.; Schwertfeger, S. Self-supervised point set local descriptors for point cloud registration. Sensors 2021, 21, 486. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Fan, B.; Xiang, S.; Pan, C. Relation-shape convolutional neural network for point cloud analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 8895–8904. [Google Scholar]
- Li, F.; Jin, W.; Fan, C.; Zou, L.; Chen, Q.; Li, X.; Jiang, H.; Liu, Y. PSANet: Pyramid splitting and aggregation network for 3D object detection in point cloud. Sensors 2021, 21, 136. [Google Scholar] [CrossRef] [PubMed]
- Wu, W.; Qi, Z.; Fuxin, L. Pointconv: Deep convolutional networks on 3D point clouds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 9621–9630. [Google Scholar]
- Xu, Y.; Fan, T.; Xu, M.; Zeng, L.; Qiao, Y. SpiderCNN: Deep learning on point sets with parameterized convolutional filters. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 87–102. [Google Scholar]
- Su, H.; Maji, S.; Kalogerakis, E.; Learned-Miller, E. Multi-view convolutional neural networks for 3D shaperecognition. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 945–953. [Google Scholar]
- Feng, Y.; Zhang, Z.; Zhao, X.; Ji, R.; Gao, Y. GVCNN: Group-view convolutional neural networks for 3D shape recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 264–272. [Google Scholar]
- Guo, H.; Wang, J.; Li, J.; Lu, H. Multi-view 3D object retrieval with deep embedding network. IEEE Trans. Image Proces. 2016, 25, 5526–5537. [Google Scholar] [CrossRef] [PubMed]
- Maturana, D.; Scherer, S. VoxNet: A 3D Convolutional Neural Network for real-time object recognition. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Hamburg, Germany, 28 September–2 October 2015; pp. 922–928. [Google Scholar]
- Qi, C.R.; Su, H.; Nießner, M.; Dai, A.; Yan, M.; Guibas, L.J. Volumetric and multi-view cnns for object classification on 3D data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5648–5656. [Google Scholar]
- Riegler, G.; Osman Ulusoy, A.; Geiger, A. Octnet: Learning deep 3D representations at high resolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3577–3586. [Google Scholar]
- Klokov, R.; Lempitsky, V. Escape from cells: Deep Kd-networks for the recognition of 3D point cloud models. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 863–872. [Google Scholar]
- Wang, C.; Samari, B.; Siddiqi, K. Local spectral graph convolution for point set feature learning. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 52–66. [Google Scholar]
- Wang, L.; Huang, Y.; Hou, Y.; Zhang, S.; Shan, J. Graph Attention Convolution for Point Cloud Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 10296–10305. [Google Scholar]
- Chen, C.; Fragonara, L.Z.; Tsourdos, A. GAPNet: Graph attention based point neural network for exploiting local feature of point cloud. arXiv 2019, arXiv:1905.08705. [Google Scholar]
- Simonovsky, M.; Komodakis, N. Dynamic edge-conditioned filters in convolutional neural networks on graphs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3693–3702. [Google Scholar]
- Landrieu, L.; Simonovsky, M. Large-scale point cloud semantic segmentation with superpoint graphs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4558–4567. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3D classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In Proceedings of the Advances in Neural Information Processing Systems, Curran Associates, Long Beach, CA, USA, 4–9 December 2017; pp. 5099–5108. [Google Scholar]
- Graham, B.; van der Maaten, L. Submanifold sparse convolutional networks. arXiv 2017, arXiv:1706.01307. [Google Scholar]
- Hua, B.; Tran, M.; Yeung, S.-K. Pointwise convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 984–993. [Google Scholar]
- Su, H.; Jampani, V.; Sun, D.; Maji, S.; Kalogerakis, E.; Yang, M.H.; Kautz, J. Splatnet: Sparse lattice networks for point cloud processing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2530–2539. [Google Scholar]
- Li, Y.; Bu, R.; Sun, M.; Wu, W.; Di, X.; Chen, B. Pointcnn: Convolution on x-transformed points. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018; pp. 820–830. [Google Scholar]
- Huang, Q.; Wang, W.; Neumann, U. Recurrent slice networks for 3D segmentation of point clouds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2626–2635. [Google Scholar]
- Tchapmi, L.; Choy, C.; Armeni, I.; Gwak, J.; Savarese, S. Segcloud: Semantic segmentation of 3D point clouds. In Proceedings of the International Conference on 3D Vision, Qingdao, China, 10–12 October 2017; pp. 537–547. [Google Scholar]
- Li, J.; Chen, B.M.; Hee Lee, G. So-net: Self-organizing network for point cloud analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 9397–9406. [Google Scholar]
- Huang, R.; Xu, Y.; Hong, D.; Yao, W.; Ghamisi, P.; Stilla, U. Deep point embedding for urban classification using ALS point clouds: A new perspective from local to global. ISPRS J. Photogramm. Remote Sens. 2020, 163, 62–81. [Google Scholar] [CrossRef]
- Groh, F.; Wieschollek, P.; Lensch, H.P. Flex-Convolution. In Proceedings of the Asian Conference on Computer Vision, Perth, Australia, 2–6 December 2018; pp. 105–122. [Google Scholar]
- Verma, N.; Boyer, E.; Verbeek, J. Feastnet: Feature-steered graph convolutions for 3D shape analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2598–2606. [Google Scholar]
- Wang, S.; Suo, S.; Ma, W.-C.; Pokrovsky, A.; Urtasun, R. Deep parametric continuous convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2589–2597. [Google Scholar]
- Hermosilla, P.; Ritschel, T.; Vázquez, P.-P.; Vinacua, À.; Ropinski, T. Monte Carlo convolution for learning on non-uniformly sampled point clouds. ACM Tran. Graph. 2019, 37, 6. [Google Scholar] [CrossRef] [Green Version]
- Shen, Y.; Feng, C.; Yang, Y.; Tian, D. Mining Point Cloud Local Structures by Kernel Correlation and Graph Pooling. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4548–4557. [Google Scholar]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic Graph CNN for Learning on Point Clouds. ACM Tran. Graph. 2019, 38, 5. [Google Scholar] [CrossRef] [Green Version]
- Thomas, H.; Deschaud, J.-E.; Marcotegui, B. Semantic classification of 3D point clouds with multiscale spherical neighborhoods. In Proceedings of the International Conference on 3D Vision, Verona, Italy, 5–8 September 2018; pp. 390–398. [Google Scholar]
- Weinmann, M.; Jutzi, B.; Hinz, S.; Mallet, C. Semantic point cloud interpretation based on optimal neighborhoods, relevant features and efficient classifiers. ISPRS J. Photogramm. Remote Sens. 2015, 105, 286–304. [Google Scholar] [CrossRef]
- He, T.; Huang, H.; Yi, L. GeoNet: Deep geodesic networks for point cloud analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 6888–6897. [Google Scholar]
- Xie, S.; Liu, S.; Chen, Z.; Tu, Z. Attentional ShapeContextNet for Point Cloud Recognition. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4606–4615. [Google Scholar]
- Feng, M.; Zhang, L.; Lin, X.; Gilani, S.Z.; Mian, A. Point Attention Network for Semantic Segmentation of 3D Point Clouds. Pat. Recog. 2020, 107, 107446. [Google Scholar] [CrossRef]
- Xie, Z.; Chen, J.; Peng, B. Point clouds learning with attention-based graph convolution networks. Neurocomputing 2020, 402, 245–255. [Google Scholar] [CrossRef] [Green Version]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3D ShapeNets: A deep representation for volumetric shapes. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1912–1920. [Google Scholar]
- Yi, L.; Kim, V.G.; Ceylan, D.; Shen, I.-C.; Yan, M.; Su, H.; Lu, C.; Huang, Q.; Sheffer, A.; Guibas, L. A scalable active framework for region annotation in 3D shape collections. ACM Tran. Graph. 2019, 35, 6. [Google Scholar] [CrossRef]
- Armeni, I.; Sener, O.; Zamir, A.R.; Jiang, H.; Brilakis, I.; Fischer, M.; Savarese, S. 3D semantic parsing of large-scale indoor spaces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1534–1543. [Google Scholar]
- Mel, B.W.; Omohundro, S.M. How receptive field parameters affect neural learning. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 2–5 December 1991; pp. 757–763. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Input | Points | mA | OA |
|---|---|---|---|---|
| Pointwise-CNN [23] | xyz | 1k | 81.4 | 86.1 |
| ECC [18] | xyz | 1k | - | 87.4 |
| PointNet [20] | xyz | 1k | 86.2 | 89.2 |
| SCN [39] | xyz | 1k | 87.6 | 90.0 |
| Kd-Net [14] | xyz | 1k | 86.3 | 90.6 |
| PointNet++ [21] | xyz | 1k | - | 90.7 |
| KCNet [34] | xyz | 1k | - | 91.0 |
| Spec-GCN [15] | xyz | 1k | - | 91.5 |
| PointCNN [25] | xyz | 1k | 88.1 | 92.2 |
| DGCNN [35] | xyz | 1k | 90.2 | 92.2 |
| GAPNet [17] | xyz | 1k | 89.7 | 92.4 |
| Spec-GCN [15] | xyz+normal | 1k | - | 91.8 |
| Pointconv [6] AGCN [41] | xyz+normal xyz+normal | 1k 1k | - 90.7 | 92.5 92.6 |
| PointNet++ [21] | xyz+normal | 5k | - | 91.9 |
| SpiderCNN [7] | xyz+normal | 5k | - | 92.4 |
| SO-Net [28] | xyz+normal | 5k | 90.8 | 93.4 |
| DNet | xyz | 1k | 90.9 | 93.6 |
| Method | Model Size (MB) | Time (ms) | Accuracy (%) |
|---|---|---|---|
| PointNet [20] | 40 | 6.7 | 89.2 |
| PointNet++ [21] | 12 | 21.3 | 90.7 |
| DGCNN [35] | 21 | 24.6 | 92.2 |
| Proposed DNet | 17 | 19.2 | 93.6 |
| Mask | mA | OA |
|---|---|---|
| No mask | 92.9 | 89.2 |
| Median mask | 93.3 | 90.1 |
| Mean mask | 93.6 | 90.9 |
| Method | mcIoU | mIoU | cIoU | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Air Plane | Bag | Cap | Car | Chair | Ear Phone | Guitar | Knife | Lamp | Laptop | Motor Bike | Mug | Pistol | Rocket | Skate Ball | Table | |||
| Kd-Net [14] | 77.4 | 82.3 | 80.1 | 74.6 | 74.3 | 70.3 | 88.6 | 73.5 | 90.2 | 87.2 | 81.0 | 94.9 | 57.4 | 86.7 | 78.1 | 51.8 | 69.9 | 80.3 |
| PointNet [20] | 80.4 | 83.7 | 83.4 | 78.7 | 82.5 | 74.9 | 89.6 | 73.0 | 91.5 | 85.9 | 80.8 | 95.3 | 65.2 | 93.0 | 81.2 | 57.9 | 72.8 | 80.6 |
| SPLATNet [24] | 82.0 | 84.6 | 81.9 | 83.9 | 88.6 | 79.5 | 90.1 | 73.5 | 91.3 | 84.7 | 84.5 | 96.3 | 69.7 | 95.0 | 81.7 | 59.2 | 70.4 | 81.3 |
| KCNet [34] | 82.2 | 84.7 | 82.8 | 81.5 | 86.4 | 77.6 | 90.3 | 76.8 | 91.0 | 87.2 | 84.5 | 95.5 | 69.2 | 94.4 | 81.6 | 60.1 | 75.2 | 81.3 |
| GAPNet [17] | 82.0 | 84.7 | 84.2 | 84.1 | 88.8 | 78.1 | 90.7 | 70.1 | 91.0 | 87.3 | 83.1 | 96.2 | 65.9 | 95.0 | 81.7 | 60.7 | 74.9 | 80.8 |
| RSNet [26] | 81.4 | 84.9 | 82.7 | 86.4 | 84.1 | 78.2 | 90.4 | 69.3 | 91.4 | 87.0 | 83.5 | 95.4 | 66.0 | 92.6 | 81.8 | 56.1 | 75.8 | 82.2 |
| SpiderCNN [7] | 82.4 | 85.3 | 83.5 | 81.0 | 87.2 | 77.5 | 90.7 | 76.8 | 91.1 | 87.3 | 83.3 | 95.8 | 70.2 | 93.5 | 82.7 | 59.7 | 75.8 | 82.8 |
| AGCN [41] | 82.6 | 85.4 | 83.3 | 79.3 | 87.5 | 78.5 | 90.7 | 76.5 | 91.7 | 87.8 | 84.7 | 95.7 | 72.4 | 93.2 | 84.0 | 63.7 | 76.4 | 82.5 |
| SCN [39] | - | 84.6 | 83.8 | 80.8 | 83.5 | 79.3 | 90.5 | 69.8 | 91.7 | 86.5 | 82.9 | 96.0 | 69.2 | 93.8 | 82.5 | 62.9 | 74.4 | 80.8 |
| PointCNN [25] | 84.6 | 86.1 | 84.1 | 86.5 | 86.0 | 80.8 | 90.6 | 79.7 | 92.3 | 88.4 | 85.3 | 96.1 | 77.2 | 95.3 | 84.2 | 64.2 | 80.0 | 83.0 |
| PointNet++ [21] | 81.9 | 85.1 | 82.4 | 79.0 | 87.7 | 77.3 | 90.8 | 71.8 | 91.0 | 85.9 | 83.7 | 95.3 | 71.6 | 94.1 | 81.3 | 58.7 | 76.4 | 82.6 |
| DGCNN [35] | 82.3 | 85.2 | 84.0 | 83.4 | 86.7 | 77.8 | 90.6 | 74.7 | 91.2 | 87.5 | 82.8 | 95.7 | 66.3 | 94.9 | 81.1 | 63.5 | 74.5 | 82.6 |
| DNet | 83.8 | 86.1 | 84.5 | 85.2 | 88.6 | 79.3 | 91.7 | 77.8 | 91.5 | 88.7 | 84.7 | 95.7 | 73.4 | 95.3 | 82.3 | 62.8 | 76.8 | 82.1 |
| Method | OA | mA | mIOU |
|---|---|---|---|
| PointNet [20] SCN [39] | 78.5 81.6 | 66.2 - | 47.6 52.7 |
| DGCNN [35] | 84.1 | - | 56.1 |
| RSNet [26] | - | 66.4 | 56.4 |
| AGCN [41] SPGraph [19] | 84.1 85.5 | - 73.0 | 56.6 62.1 |
| PointCNN [25] | 88.1 | 75.6 | 65.3 |
| DNet | 86.3 | 75.3 | 66.7 |
| Method | OA | mA | mIOU |
|---|---|---|---|
| PointNet [20] | - | 49.0 | 41.1 |
| SegCloud [27] | - | 57.4 | 48.9 |
| PointCNN [25] | 85.9 | 63.9 | 57.3 |
| SPGraph [19] | 86.4 | 66.5 | 58.0 |
| PCCN [32] | - | 67.0 | 58.3 |
| DNet | 86.5 | 66.3 | 59.7 |
| DNet Using Different Features | OA |
|---|---|
| without self-features | 93.0 |
| without manifold features | 92.3 |
| without neighborhood features | 90.2 |
| all features | 93.6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tian, F.; Jiang, Z.; Jiang, G. DNet: Dynamic Neighborhood Feature Learning in Point Cloud. Sensors 2021, 21, 2327. https://doi.org/10.3390/s21072327
Tian F, Jiang Z, Jiang G. DNet: Dynamic Neighborhood Feature Learning in Point Cloud. Sensors. 2021; 21(7):2327. https://doi.org/10.3390/s21072327
Chicago/Turabian StyleTian, Fujing, Zhidi Jiang, and Gangyi Jiang. 2021. "DNet: Dynamic Neighborhood Feature Learning in Point Cloud" Sensors 21, no. 7: 2327. https://doi.org/10.3390/s21072327