
A Reinforcement Learning Approach to View Planning for Automated Inspection Tasks


Abstract
:1. Introduction
1.1. Motivation
1.2. Related Work
1.3. Contribution
1.4. Structure
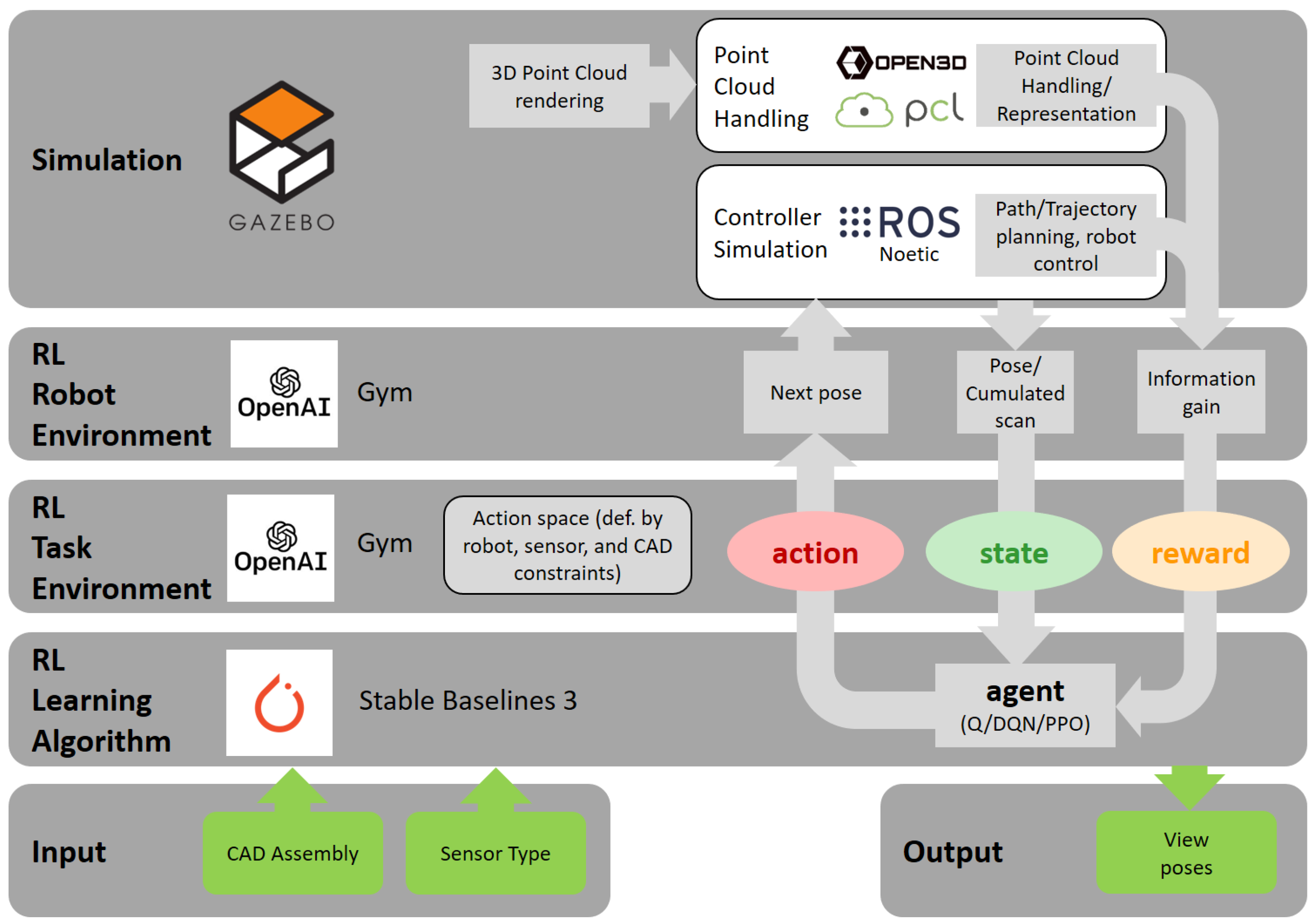
2. Proposed Architecture (Methods)
2.1. Hardware Setup
2.2. Simulation
2.2.1. Controller Simulation
2.2.2. Pointcloud Handling
2.3. Reinforcement Learning
2.3.1. Robot Environment
2.3.2. Task Environment
Theoretical Background
Action and State
Reward
2.3.3. Learning Algorithm
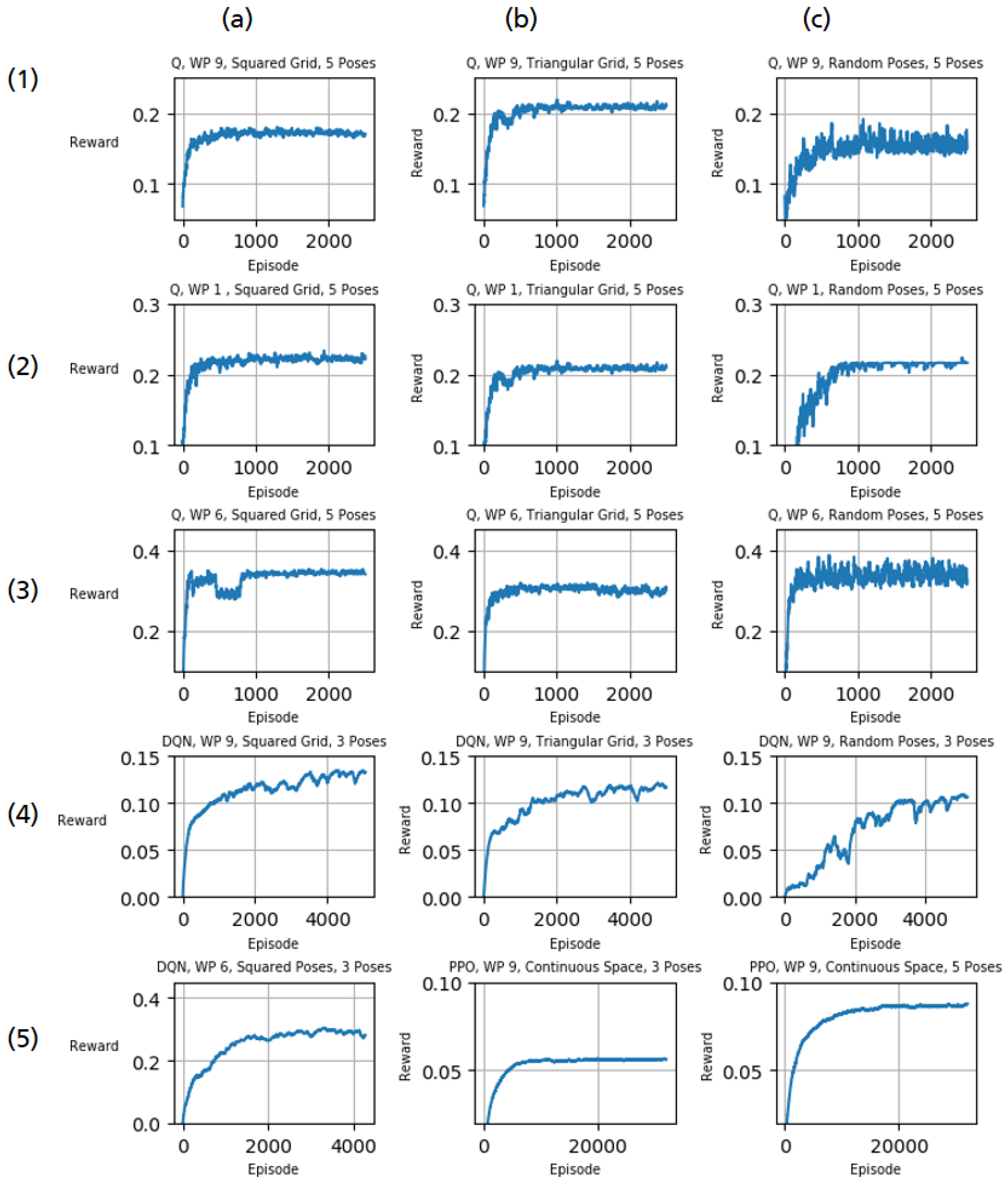
3. Experiments and Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AAE | Adversarial Autoencoder |
| CAD | Computer-Aided Design |
| CD | Clearing Distance |
| CPP | Coverage Planning Problem |
| DQN | Deep Q-Networks |
| MDP | Markov Decision Process |
| MDPI | Multidisciplinary Digital Publishing Institute |
| OLP | Offline Programming |
| PCL | Point Cloud Library |
| POMDP | Partially Observable Markov Decision Process |
| PPO | Proximal Policy Optimization |
| RL | Reinforcement Learning |
| SARSA | State-Action Reward State-Action |
| TD | Temporal Difference |
| SCP | Set Cover Problem |
| TSP | Traveling Salesman Problem |
| VPP | View Planning Problem |
| WD | Working Distance |
References
- Hägele, M.; Nilsson, K.; Pires, J.N.; Bischoff, R. Industrial Robotics. In Springer Handbook of Robotics; Siciliano, B., Khatib, O., Eds.; Springer: Berlin/Heidelberg, Germany, 2016; pp. 1385–1422. [Google Scholar] [CrossRef]
- International Federation of Robotics. 2020. Available online: https://ifr.org/free-downloads (accessed on 12 March 2021).
- Scott, W.R. Model-based view planning. Mach. Vis. Appl. 2009, 20, 47–69. [Google Scholar] [CrossRef] [Green Version]
- Engin, S.; Mitchell, E.; Lee, D.; Isler, V.; Lee, D.D. Higher Order Function Networks for View Planning and Multi-View Reconstruction. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 11486–11492. [Google Scholar] [CrossRef]
- Scott, W.R.; Roth, G.; Rivest, J.F. View planning for automated three-dimensional object reconstruction and inspection. ACM Comput. Surv. (CSUR) 2003, 35, 64–96. [Google Scholar] [CrossRef]
- Chen, S.; Li, Y.; Kwok, N.M. Active vision in robotic systems: A survey of recent developments. Int. J. Robot. Res. 2011, 30, 1343–1377. [Google Scholar] [CrossRef]
- Feige, U. A threshold of ln n for approximating set cover. J. ACM 1998, 45, 634–652. [Google Scholar] [CrossRef]
- Tarbox, G.H.; Gottschlich, S.N. Planning for Complete Sensor Coverage in Inspection. Comput. Vis. Image Underst. 1995, 61, 84–111. [Google Scholar] [CrossRef]
- Martin, R.; Rojas, I.; Franke, K.; Hedengren, J. Evolutionary View Planning for Optimized UAV Terrain Modeling in a Simulated Environment. Remote Sens. 2016, 8, 26. [Google Scholar] [CrossRef] [Green Version]
- Englot, B.; Hover, F. Planning Complex Inspection Tasks Using Redundant Roadmaps. In Robotics Research; Christensen, H.I., Khatib, O., Eds.; Springer: Cham, Switzerland, 2017; Volume 100, pp. 327–343. [Google Scholar] [CrossRef]
- Kaba, M.D.; Uzunbas, M.G.; Lim, S.N. A Reinforcement Learning Approach to the View Planning Problem. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5094–5102. [Google Scholar] [CrossRef] [Green Version]
- Sutton, R.S.; Barto, A. Reinforcement Learning: An Introduction, 2nd ed.; Adaptive Computation and Machine Learning; The MIT Press: Cambridge, MA, USA; London, UK, 2018. [Google Scholar]
- Jing, W.; Goh, C.F.; Rajaraman, M.; Gao, F.; Park, S.; Liu, Y.; Shimada, K. A Computational Framework for Automatic Online Path Generation of Robotic Inspection Tasks via Coverage Planning and Reinforcement Learning. IEEE Access 2018, 6, 54854–54864. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing Atari with Deep Reinforcement Learning. arXiv 2013, arXiv:cs.LG/1312.5602. [Google Scholar]
- van Hasselt, H.; Guez, A.; Silver, D. Deep reinforcement learning with double Q-Learning. In Proceedings of the 30th AAAI Conference on Artificial Intelligence, AAAI 2016, Phoenix, AZ, USA, 12–17 February 2016; pp. 2094–2100. [Google Scholar]
- Schaul, T.; Quan, J.; Antonoglou, I.; Silver, D. Prioritized Experience Replay. arXiv 2016, arXiv:cs.LG/1511.05952. [Google Scholar]
- Williams, R.J. Simple Statistical Gradient-Following Algorithms for Connectionist Reinforcement Learning. In Reinforcement Learning; Sutton, R.S., Ed.; Springer: Boston, MA, USA, 1992; pp. 5–32. [Google Scholar] [CrossRef]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.P.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. In Proceedings of the 33rd International Conference on Machine Learning, ICML 2016, New York, NY, USA, 19–24 June 2016; pp. 2850–2869. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:cs.LG/1707.06347. [Google Scholar]
- Lucchi, M.; Zindler, F.; Mühlbacher-Karrer, S.; Pichler, H. robo-gym—An Open Source Toolkit for Distributed Deep Reinforcement Learning on Real and Simulated Robots. arXiv 2020, arXiv:cs.RO/2007.02753. [Google Scholar]
- Sucan, I.A.; Moll, M.; Kavraki, L.E. The Open Motion Planning Library. IEEE Robot. Autom. Mag. 2012, 19, 72–82. [Google Scholar] [CrossRef] [Green Version]
- Koch, S.; Matveev, A.; Jiang, Z.; Williams, F.; Artemov, A.; Burnaev, E.; Alexa, M.; Zorin, D.; Panozzo, D. ABC: A Big CAD Model Dataset For Geometric Deep Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–19 June 2019; pp. 9601–9611. [Google Scholar]
- Zamora, I.; Lopez, N.G.; Vilches, V.M.; Cordero, A.H. Extending the OpenAI Gym for robotics: A toolkit for reinforcement learning using ROS and Gazebo. arXiv 2017, arXiv:cs.RO/1608.05742. [Google Scholar]
- Koenig, N.; Howard, A. Design and use paradigms for gazebo, an open-source multi-robot simulator. In Proceedings of the 2004 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Sendai, Japan, September 2004; pp. 2149–2154. [Google Scholar] [CrossRef] [Green Version]
- Chitta, S.; Marder-Eppstein, E.; Meeussen, W.; Pradeep, V.; Tsouroukdissian, A.R.; Bohren, J.; Coleman, D.; Magyar, B.; Raiola, G.; Lüdtke, M. ros_control: A generic and simple control framework for ROS. J. Open Source Softw. 2017, 2, 456. [Google Scholar] [CrossRef]
- Rusu, R.B.; Cousins, S. 3D is here: Point Cloud Library (PCL). In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 1–4. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Q.Y.; Park, J.; Koltun, V. Open3D: A Modern Library for 3D Data Processing. arXiv 2018, arXiv:cs.CV/1801.09847. [Google Scholar]
- Coleman, D.; Sucan, I.; Chitta, S.; Correll, N. Reducing the Barrier to Entry of Complex Robotic Software: A MoveIt! Case Study. arXiv 2014, arXiv:cs.RO/1404.3785. [Google Scholar]
- Brockman, G.; Cheung, V.; Pettersson, L.; Schneider, J.; Schulman, J.; Tang, J.; Zaremba, W. OpenAI Gym. arXiv 2016, arXiv:cs.LG/1606.01540. [Google Scholar]
- Raffin, A.; Hill, A.; Ernestus, M.; Gleave, A.; Kanervisto, A.; Dormann, N. Stable Baselines3. GitHub. 2019. Available online: https://github.com/DLR-RM/stable-baselines3 (accessed on 12 March 2021).
- Watkins, C.J.C.H.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Wong, C.; Mineo, C.; Yang, E.; Yan, X.T.; Gu, D. A novel clustering-based algorithm for solving spatially-constrained robotic task sequencing problems. IEEE/ASME Trans. Mechatron. 2020, 1. [Google Scholar] [CrossRef]
- Gumhold, S.; Wang, X.; Macleod, R. Feature Extraction from Point Clouds. In Proceedings of the 10th International Meshing Roundtable, Newport Beach, CA, USA, 7–10 October 2001; pp. 293–305. [Google Scholar]
- Guo, Y.; Wang, H.; Hu, Q.; Liu, H.; Liu, L.; Bennamoun, M. Deep Learning for 3D Point Clouds: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020. [Google Scholar] [CrossRef]
- Makhzani, A.; Shlens, J.; Jaitly, N.; Goodfellow, I.; Frey, B. Adversarial Autoencoders. arXiv 2016, arXiv:cs.LG/1511.05644. [Google Scholar]
- Zamorski, M.; Zięba, M.; Klukowski, P.; Nowak, R.; Kurach, K.; Stokowiec, W.; Trzciński, T. Adversarial autoencoders for compact representations of 3D point clouds. Comput. Vis. Image Underst. 2020, 193, 102921. [Google Scholar] [CrossRef] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| (a) | |
|---|---|
| Parameter | Value |
| Learning Rate () | 0.1 |
| Discount Factor () | 0.7 |
| Initial Exploration Rate () | 0.9 |
| Exploration Discount Factor | 0.999 |
| Number of Episodes | 2500 |
| (b) | |
| Parameter | Value |
| Policy | Multi-Layer Perceptron |
| (2 layers with 64 neurons) | |
| Learning Rate () | 0.0001 |
| Discount Factor () | 0.99 |
| Initial Exploration Rate () | 0.9 |
| Minimal Exploration Rate | 0.05 |
| Number of Episodes () | 20,000 |
| Exploration Fraction of Training | 0.2 (4000 episodes) |
| (c) | |
| Parameter | Value |
| Policy and Value Network | Multi-Layer Perceptron |
| (2 layers with 64 neurons) | |
| Learning Rate () | 0.0001 |
| Batch Size | 4 |
| Discount Factor () | 0.7 |
| Clipping Range () | 0.2 |
| Loss Entropy Coefficient () | 0.1 |
| Loss Value Function Coefficient () | 0.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Landgraf, C.; Meese, B.; Pabst, M.; Martius, G.; Huber, M.F. A Reinforcement Learning Approach to View Planning for Automated Inspection Tasks. Sensors 2021, 21, 2030. https://doi.org/10.3390/s21062030
Landgraf C, Meese B, Pabst M, Martius G, Huber MF. A Reinforcement Learning Approach to View Planning for Automated Inspection Tasks. Sensors. 2021; 21(6):2030. https://doi.org/10.3390/s21062030
Chicago/Turabian StyleLandgraf, Christian, Bernd Meese, Michael Pabst, Georg Martius, and Marco F. Huber. 2021. "A Reinforcement Learning Approach to View Planning for Automated Inspection Tasks" Sensors 21, no. 6: 2030. https://doi.org/10.3390/s21062030