4.1. ASCE Structure—Phase II
The effectiveness of the proposed method is first assessed against the experimental datasets relevant to the four-story steel structure of the second phase of the ASCE problem [
40]. This structure consists of a 2-bay-by-2-bay steel frame, which is 2.5 × 2.5 m in plan and 3.6 m tall. The members were made of hot-rolled 300 W grade steel, with a nominal yield stress of 300 MPa. In each bay, the bracing system was represented by two threaded steel rods with a diameter of 12.7 mm, placed in parallel along the diagonal.
To obtain a realistic mass distribution, four 1000 kg slabs were placed on the first, second, and third floors, while four 750 kg slabs were placed on the fourth one. On each floor, two of the masses were placed off-center to increase the degree of coupling between the translational motions of the structure. The structure was subjected to a random excitation via an electro-dynamic shaker, placed on the fourth floor. The vibration responses, in terms of acceleration time histories, were acquired with 15 accelerometers (with three of them for each story) and a frequency of data acquisition of 250 Hz.
Table 1 provides the sensor numbering and their locations for this benchmark problem: Sensors #1–3 are not listed in it and are not considered here, since they were mounted on the basement of the structure and did not provide relevant information concerning its dynamics.
During the tests, the damage was simulated by removing several braces from the east, southeast, and north sides of the structure, or by loosening bolts at the beam–column connections. In this work, only the damage patterns caused by removing the bracing systems from the east and southeast sides have been considered, see
Table 2. Response modeling and feature extraction were first performed by time series analysis, via an AR model. The AR residuals at all sensor locations, regarding both the undamaged and damaged states, were then adopted as damage-sensitive features. Additional details about the residual-based feature extraction algorithm based on AR modeling and other time series analyses, can be found in [
19].
The Leybourne–McCabe (LMC) hypothesis test was then adopted to ascertain the stationarity of the vibration signals and also the compatibility with the proposed modeling strategy [
41]. As outputs, the LMC test provides the null (H
0) or alternative (H
1) hypothesis, a probability value (
p-value), a critical value (
c-value) and a test statistic (
Q). The AR model is suitable for a univariate time series if the
p-value is larger than a significance limit (
α), or if the test statistic is smaller than the
c-value. For example, under a customarily adopted 5% significance level (namely, for
α = 0.05),
p-value > 0.05 and/or
Q <
c-value = 0.1460 the mentioned stationarity of the time series is ascertained.
Table 3 lists the LMC test statistics for all the sensor locations of Cases 1–5, based on such 5% significance level: since all the values of
Q are smaller than the
c-value = 0.1460, the measured vibration responses can be considered stationary in all the cases, and conform to an AR model. This model thus appears to be accurate for the current feature extraction purposes.
Next, the AR model order has to be set. The determination of an optimal order is of paramount importance for the process of feature extraction via time series modeling, in order to avoid issues related to a poor goodness-of-fit. In this work, the approach proposed in [
19] has been adopted, to obtain the mentioned model order at each sensor location and for the undamaged Case 1. This algorithm is based on the residual analysis by the Ljung–Box hypothesis test, to assess the correlation between the model residuals. As an appropriate model order should enable the time series representation to generate uncorrelated residuals, their uncorrelatedness was selected as the criterion to set the model order [
19].
If the residual sequences of the time series model are uncorrelated, the
p-value provided by the Ljung–Box Q (LBQ) test becomes larger than the significant limit, while the test statistic remains smaller than the
c-value. The smallest model order to satisfy these selection criteria was chosen as the order to use for feature selection purposes.
Table 4 displays the model orders for sensors #4–15 and Case 1, as well as the obtained
p-values: all the
p-values are shown to be larger than the 5% significance limit, with the H
0 hypothesis satisfied at all sensor locations. By adopting such model orders, the coefficients of all the AR models for the undamaged state have been then estimated by the least-squares technique. Finally, the model residuals for Cases 1–5 have been extracted and handled as the damage-sensitive features by means of the residual-based extraction technique described in [
19].
In the next step, the residual samples at all the sensor locations for Case 1 (undamaged state) and Cases 2–5 (current states) have been collected into two different sets, to provide the feature matrices
X and
Z, see
Section 3. These matrices collect
n = m = 24,000 samples (as rows) and
r = 12 variables (as columns). Before classifying Cases 2–5 as damaged states or not, it is necessary to set the optimal number
p of partitions: the ten sample values reported in
Table 5 have been investigated. In the table, results are reported for each of them in terms of number and percentage of Type II errors for Cases 4–5 (
Table 5); results are instead not reported for Cases 2–3, since no errors at all were encountered, independently of
p. As all the distance values relevant to Case 1 have been shown to fall below the threshold limit, without Type I errors, the optimal value of
p has been set accordingly on the basis of the rates of Type II errors only. Focusing on Cases 4 and 5, values
p 20 are shown to yield the best performances: hence,
p = 20 has been adopted in the current analysis. The feature matrices
and
were then subdivided into 20 sub-sets
and
, each of which consisting of 1200 samples (
l =
h = 1200) and, again, 12 variables. The 1200-by-1200 distance matrices
for
, and
for
were computed using the ESD technique.
To visually compare the entries of these distance matrices relevant to the undamaged and damaged states,
Figure 2 and
Figure 3 show the exemplary cases of the first partition in Cases 1, 2, and 5. As reported in
Figure 2, there are clear differences between the distance values gathered by the two matrices for Cases 1 and 2. The damage in the second case led to remarkable increases in the distance values in the matrix
. On the contrary, by comparing the entries of
and
, respectively, related to Cases 1 and 5 and shown in
Figure 3, it is difficult, if not impossible, to ascertain the presence of damage in the latter one due to the very similar values reported. The results have been shown for distances in the first partitions, collected in
and
, but they were very similar when also using the others. This brings us to the conclusion that the direct comparison of the distance values may be neither efficient nor informative, and the proposed data-driven approach for early damage detection therefore appears to be necessary.
Once the distance matrices for all the partitions regarding both the undamaged and the damaged conditions have been determined, the coordinate matrices
U1…
U20 and
Ū1…
Ū20 can be computed according to Equations (3)–(6), each one gathering 1200 samples and 12 variables, where
q =
r = 12 has been automatically set without any hyperparameter optimization tool, as explained in
Section 2. The matrix vectorization technique was adopted next to obtain the vectors
u1…
u20 and
ū1…
ū20, each one accordingly made of
l* =
h* = 14,400 data points. The
l2-norms of these vectors were finally computed to assemble vector
d, featuring 40 distance values for each damage case, among which, the first 20 entries are part of the vector
du and the remaining 20 ones are instead associated with the vector
dc, see Equation (9).
The results of the damage detection procedure are displayed in
Figure 4, where all the damaged states reported in
Table 2 are compared with the undamaged one; in these graphs and similar ones to follow, the horizontal lines refer to the threshold limit computed via the 95% confidence interval of the entries in
du, see Equation (10), resulting in
9.6. Irrespective of the damage case, plots show that there are clear deviations in the distance values gathered by
dc above the threshold, therefore, indicative of damage occurrence; the other way around, the values in
du all fall below the threshold limit, to represent the undamaged state from which
has been computed. Such results clearly prove the capability of the proposed method to accurately distinguish between undamaged and damaged states, and thereby detect damage, while also addressing the usual limitations induced by handling high-dimensional feature samples. In the present case, as all the residuals of the AR models at the 12 sensor locations are adopted, damage detection is carried out via 40 distance samples only, in place of the 24,000 original ones in matrices
X and
Z.
To assess the effects of the number
p of partitions on the damage detection results,
Figure 5 provides the results in the case of
p = 100 partitions used: it can be observed that, again, no values relevant to the first 100 samples (undamaged state) exceed the threshold limit. The distance values relevant to
dc are instead all larger than the threshold in plots 5(a) and 5(b) for the damage in Cases 2 and 3, while some false detections can be observed in plots 5(c) and 5(d) for the damage in Cases 4 and 5. It must be noted that no (Type I) false alarms were encountered; for no partitioning was the undamaged state mistakenly classified as damaged. Additionally, no (Type II) false detections, namely damage states falsely classified by the method as undamaged, were reported for Cases 2 or 3 with any value of
p. On the one hand, it can be thus emphasized that the use of only a few partitions is also preferable in order to reduce classification errors; on the other hand, Type I errors in all the cases turned out to be zero, testifying the great capability of the proposed method to provide no false alarms.
The other important aspect of our dimensionality reduction procedure is its efficiency in terms of computing time.
Figure 6 shows this computing time related to the iterative loops of the procedure, at varying values of
p. Results reported here were obtained with a computer featuring an Intel Core i5-5200@2.20 GHz CPU and 8 GB RAM. It can be observed that the smaller the value of
p, the longer the time to run over the loops due to the higher number of samples to handle, and for which, pairwise distances must be computed. It is worth mentioning that, despite the rather limited performance of the computer used to run the analyses, the computing time was always constrained to a few seconds; only for
p = 10 did the entire procedure last around 3 min. Hence, even if the current procedure is proposed in an online fashion, it can be considered performative enough to be re-implemented in the future within an online damage detection approach.
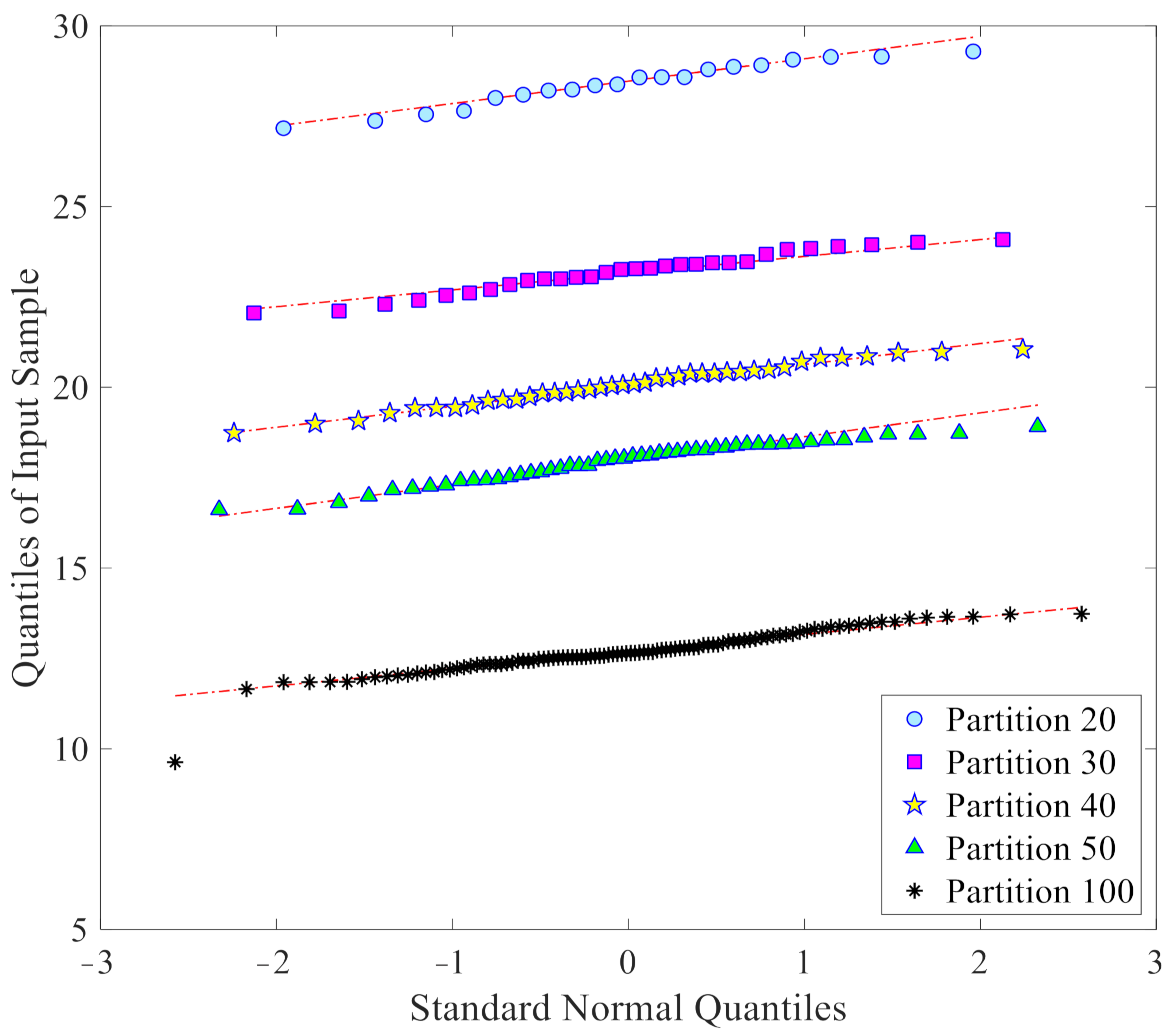
As already mentioned, one of the further advantages of the proposed data-driven approach is to provide samples with a normal or nearly normal distribution, which is best suited for the threshold limit determination via the confidence interval.
Figure 7 collects the Q-Q plots of the
l2-norm values in
du, that are used for threshold determination, again at a varying number of partitions: it clearly emerges that all the sets of the
l2-norms have distributions rather close to the normal one. This capability thus clearly demonstrates the reliability of the obtained threshold limits for damage detection.
Besides damage detection, the performance of the proposed data-driven method in estimating the level of damage severity was investigated, using—once more—a varying number of partitions.
Figure 8 focuses on the
p samples of the vector
dc relevant to Cases 2–5. In the charts, the dashed circles highlight (minor) errors in estimating the level of damage severity. More precisely, the
l2-norm values concerning the damage Case 2 are almost always larger than the corresponding values relevant to the other cases; this means that Case 2 features the highest level of damage severity. According to the description of the damaged states in
Table 2, this looks reasonable because Case 2 was characterized by the elimination of more bracing systems than damage Cases 3–5. In contrast, the
l2-norm values associated with Case 5 are the smallest and therefore point to the lowest level of damage severity.
It can thus be concluded, that the l2-norm values increase by increasing the level of damage severity, from Case 5 to Case 2. Therefore, the proposed data-driven method based on the CMDS algorithm was not only able to detect damage accurately, but was also capable of estimating the level of damage severity properly. It was also shown that some erroneous estimates of the damage level have been obtained for analyses featuring p = 30, 40 and 50: accordingly, as the best performance was obtained with p 20, a few partitions only should be used if possible. Furthermore, it must be kept in mind that, although the use of few partitions reduces the error rates, it also provides a small, or even too small set of damage indices to be handled at the decision-making stage, and therefore, may not provide adequate outputs. In spite of the similarity in the error rates relevant to solutions linked to p = 10 and p = 20, the latter solution furnishes more damage indices than the former and, thus, enables a more robust decision to be made about damage occurrence. Therefore, a tradeoff between conflicting outcomes in terms of classification errors and output adequacy represents the criterion to adopt for setting the number of partitions in the proposed CMDS-based method.
4.2. Z24 Bridge
The Z24 Bridge is a well-known benchmark for long-term SHM [
42]. The structure was a post-tensioned box-girder concrete bridge, composed of a main span of 30 m and two side-spans of 14 m, as shown in
Figure 9. The bridge was demolished in 1998 to build a new one with a larger side span; before being demolished, it was instrumented and, through a long-term continuous monitoring program, the effects of the environmental variability on damage detection were assessed. Every hour, environmental effects in terms of temperature, wind characteristics, humidity, etc. were measured at several locations with an array of sensors. Acceleration time histories were also acquired with 16 accelerometers located along the bridge with different spatial orientations. Progressive damage tests, including settlement, concrete spalling, landslides, concrete hinge failure, anchor head failure, and the rupture of tendons were carried out to mimic realistic damage scenarios in a controlled way, with the monitoring system always running.
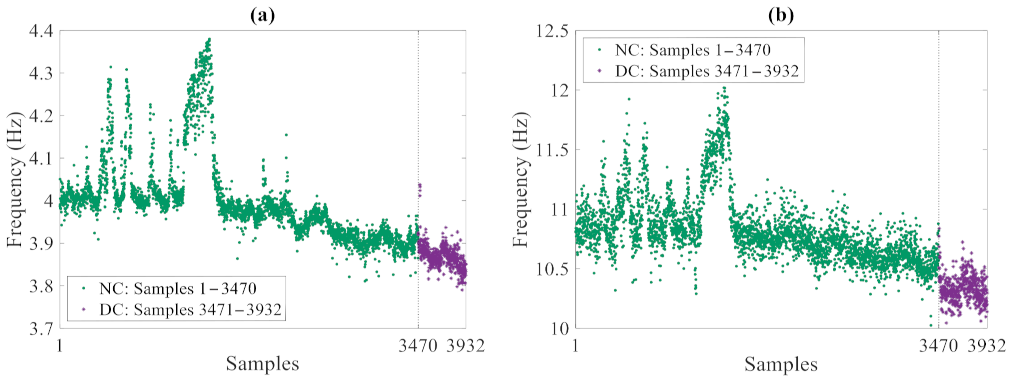
Starting from the raw data, a modal analysis based on the frequency domain decomposition (FDD) technique was carried out to extract the frequencies of the four fundamental vibration modes and assess their variations due to the environmental conditions. The resulting set of data consists of 3932 measurements, out of which the first 3470 refer to the undamaged, normal condition, and the last 462 ones are associated with the damaged state.
Figure 10 collects the exemplary time histories of the modal frequencies relevant to the first and fourth modes: in the plots, the oscillations in the values related to the normal condition were induced by temperature fluctuations in cold periods; these results have clearly testified the high sensitivity of the natural frequencies to the environmental variability. A data normalization procedure based on an auto-associative artificial neural network (AANN) [
43] was then adopted to remove such environmental variability from the variation in time of the vibration frequencies and obtain feature samples linked to the damage state only. In compliance with standard approaches in machine learning, 90% of the frequency data regarding the normal condition were handled as the training set, thus including 3123 samples of the four variables (that are the modal frequencies). The last remaining 10% of the frequency values regarding the normal condition, as well as all the values linked to the damaged state were instead handled as the testing set, consisting of 809 samples of the four variables.
The adopted feed-forward AANN architecture consists of three hidden layers representing the mapping, bottleneck, and de-mapping stages, with network outputs that aim at reproducing the corresponding inputs. In the mapping layer, a nonlinear transfer function (namely a sigmoidal one) was used at the neuron level to map the input data onto the bottleneck layer. While the bottleneck layer plays an important role in the functionality of multilayer feedforward networks, as it enforces an internal encoding and a compression of the input data, the relevant type of transfer function does not greatly affect the generality of the network. In the de-mapping layer, again, a non-linear transfer function has been used to decode or de-map the bottleneck compressed data and extract the output data. As the aim of the AANN is to reconstruct the input data, which emerge at the output layer featuring the same size of the input, it provides a filtered version of them. The AANN, thus, represents a smart algorithm for filtering out noise, outliers, and any type of variations in the data due to environmental and/or operational variability [
43]. As far as the network hyperparameters are concerned, the number of neurons in each hidden layer was set according to the approach described in [
44] and based on the final prediction error. It has turned out that the said number of neurons for the mapping, bottleneck and de-mapping layers has to be, respectively, set to 22, 3, and 22. Finally, as far as the training of the AANN is concerned, the Levenberg–Marquardt back-propagation algorithm was adopted.
To attain data normalization, the AANN was trained to learn the correlations among the features in the training dataset. Once the network was trained to filter out the environmental variability, the residuals between coupled input and output sets were handled as damage-sensitive features for the normal condition. The feature matrix
X for the undamaged state was, thus, built and consisted of
n = 3123 residual samples, each one made of the aforementioned
r = 4 variables. The same procedure was adopted to extract the residuals for the testing set; in this case, the AANN already trained for the normal condition was used to manage the feature set
Z, consisting of
m = 809 samples of the same
r = 4 variables, where
q =
r = 4 was again automatically set according to the discussion provided in
Section 2.
The proposed data-driven method was then adopted to detect damage. Based on the conclusions drawn for the previous case study regarding the effects of the number of partitions, feature matrices
X and
Z were subdivided into
p = 20, 30, 50, 75, 100, 120, 150, and 200 partitions. Next, to next set the optimal partitioning, the iterative loops of the procedure were run at the varying value of
p and the rates of Type I, Type II and total errors were obtained as reported in
Table 6. Accordingly, the best performance is shown by the solution featuring
p = 20, with just one error in the entire dataset classification. It can be also seen that the error rates increase by increasing the number of partitions. As already pointed out, smaller values of
p lead to fewer damage indices to deal with at the decision-making stage, and therefore, reduce the error rates. This outcome turns out to be linked to the handling of smaller sets of damage indices, leading to an easier decision-making process by interpreting and comparing the outputs with each other and with respect to the threshold, distinguishing damaged from undamaged states. For this reason and within certain limits, one can conclude that the use of a small number of partitions provides more reliable results. Though not shown, it must be mentioned that Type I and total error percentages obtained with
p = 10 turned out to be larger than those reported for
p = 20, as the relevant damage index dataset does not prove adequate for decision-making. Hence, for this specific case study relevant to the Z24 Bridge,
p = 20 was targeted as the best choice for damage detection.
For the case
p = 20,
Figure 11 compares the values of entries of the distance matrices of the 10th partition (namely of
and
), regarding the normal and damaged conditions. It can be seen that there is a clear variation between the values corresponding to the two conditions. The proposed methodology was then adopted to ease and speed up the comparison of the two states. After having obtained the distance matrices for all the partitions, the coordinate matrices
U1…
Up and
Ū1…
Ūp and their vector forms
u1…
up and
ū1…
ūp were computed, to finally obtain the
l2-norm values and assemble the vector
d associated with each partition.
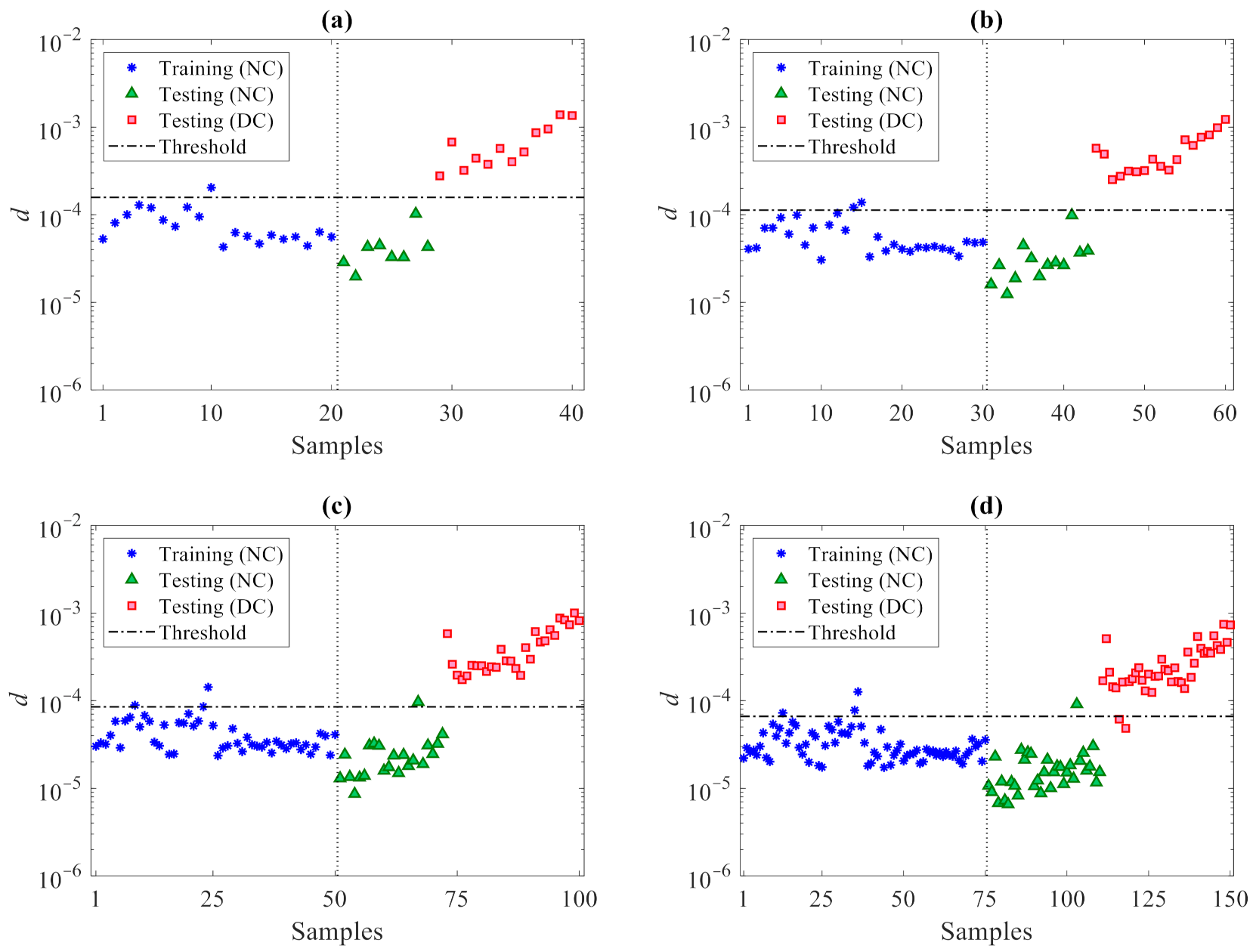
The results for varying the number of partitions are shown in
Figure 12, where the horizontal lines refer, again, to the threshold limits
related to the confidence interval of the entries in
du. It can be seen that the majority of the training samples for the normal condition in
d (marked by the blue stars) fall below the threshold limits. Additionally, the values associated with the validation data, namely the testing samples for the normal condition (marked in the charts by the green triangles) do not exceed the thresholds and behave in a way similar to the training data. Conversely, most of the values related to the damaged state—namely, the testing data for the damaged condition (marked by the red squares)—are larger than the threshold limits. This outcome clearly, again, proves the great capability of the proposed data-driven method, ruled by the partitioning strategy and by the CMDS algorithm, to provide an accurate damage detection and, thus, robustly distinguish the damaged state of the structure from the normal condition, even under a strong environmental variability.
The computing time required to perform the iterative loops of the method is shown against the number of partitions in
Figure 13. As discussed with reference to the previous case, the cost of the procedure decreases by increasing the number of partitions, due to the reduction in the number of samples in each partition used for the pairwise distance calculation. Even more than in the other case, independently of
p, the cost is shown to be extremely limited, if not negligible.
Finally, a comparison is reported between the results of the proposed CMDS-based method and those of the PCA technique [
45], to prove the superior performance of the former. As discussed in
Section 2, PCA is a parametric approach and the number of principle components to be retained in the analysis must be set. This number was determined with the aim to attain 90% of the variance in the training data; accordingly, the principal components retained in the analysis are linked to the eigenvectors, whose eigenvalues overall allow one to attain the mentioned critical threshold of 90% of the variance [
46]. The corresponding results of damage detection are depicted in
Figure 14. This outcome has been arrived at by handling the same normalized features exploited by the CMDS-based method, after normalization via the AANN, and used as training and testing data samples. Moreover, the outputs of the PCA-based method are based on the Euclidean norms of the residuals between the original normalized features and the reconstructed features obtained via the PCA [
45]. It can be observed that a rather large number of outputs (termed
dPCA in the figure) regarding the normal condition exceed the threshold, thereby leading to false alarm or Type I errors. Conversely, some outputs associated with the damaged state fall below the threshold limit, leading—in those cases—to false detection or Type II errors. The comparison between the results relevant to damage detection and those collected in
Figure 12 and
Figure 14, proves that the proposed CMDS-based method is superior to the PCA-based one, not only because it does not require procedure to set any hyperparameter during the analysis, but also in terms of the smaller error rates obtained.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}