
Deep Learning Based Air-Writing Recognition with the Choice of Proper Interpolation Technique



Abstract
:1. Introduction
2. Related Work
3. Materials and Methods
3.1. Dataset Description
3.1.1. Smart-Band Dataset
3.1.2. Six-Dimensional Motion Gesture (6DMG) Datasets
3.1.3. RealSense-Based 3D Trajectory Digit and Character (RTD-RTC) Datasets
3.2. Data Preprocessing
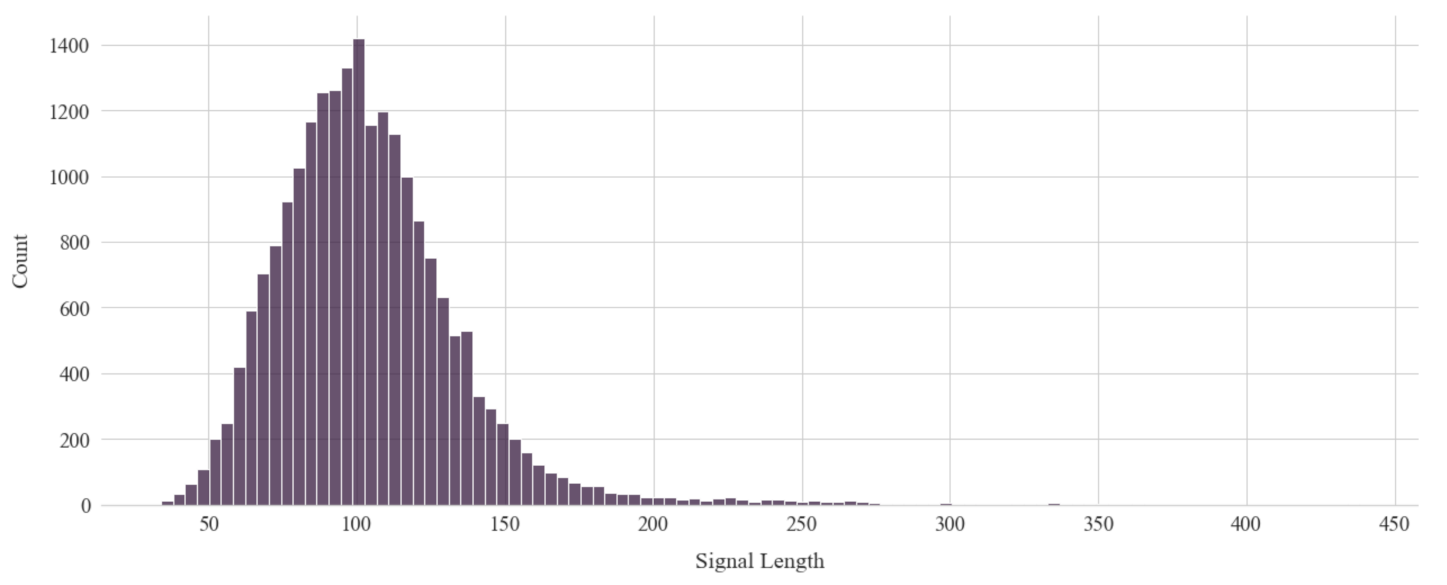
3.2.1. Optimal Signal Length Selection
- We could consider the mean of the signal lengths such that the fixed length nearly split the data in half. Half of the signal length was less than the fixed length, so we had to upsample the data to increase the length. We downsampled the other half of the signals where the length of the signals was greater than the fixed length.
- As loss occurs in downsampling the data, we could consider upsampling the maximum number of signals so that the data loss was kept to a minimum and the signal length was manageable.
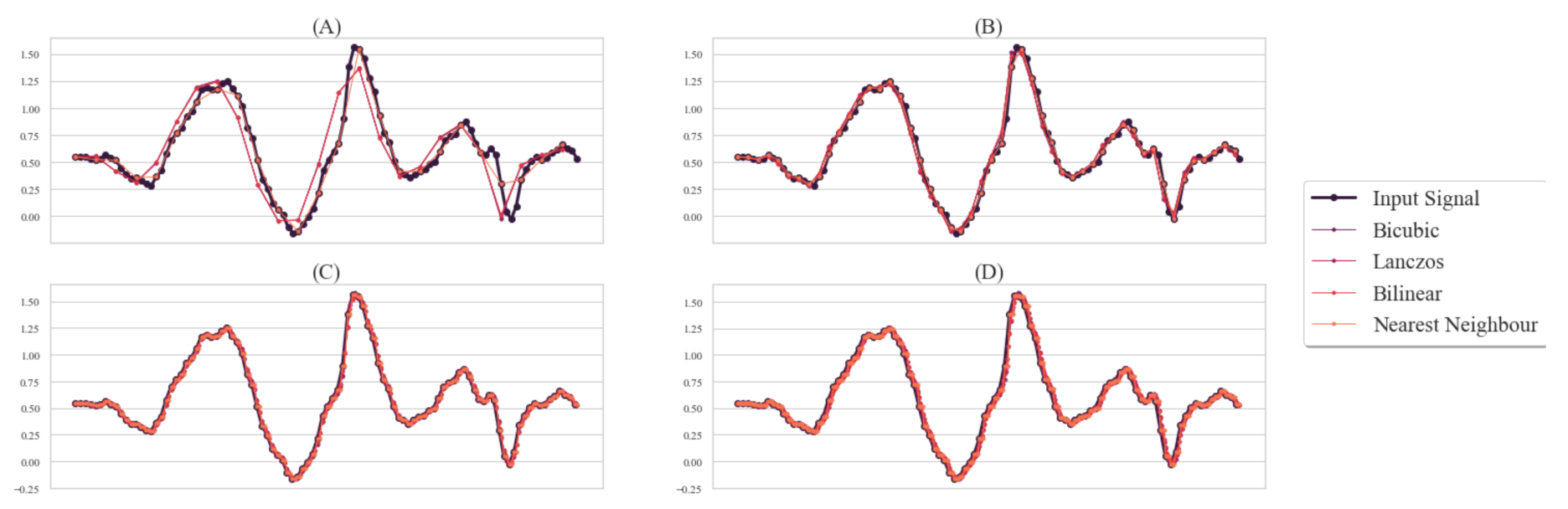
3.2.2. Fixed-Length Signals Using Interpolation Techniques
- A
- Bicubic Interpolation: The Bicubic interpolation is the advanced version of cubic interpolation in a two-dimensional regular grid. The interpolation surface obtained here was smooth. Polynomial, cubic, or cubic convolution algorithm was used here. The cubic convolution determines the gray level value using the 16 closest pixels to the specified input coordinates and assigns the value to the output coordinates. The Bicubic interpolation kernel, [40] is defined as follows,where a is generally or .
- B
- Lanczos Interpolation: To smoothly interpolate the value of a digital signal between samples, the Lanczos filter is employed. Here, each sample of the given signal was mapped to a translated and scaled copy of the Lanczos kernel, . The Lanczos kernel is a normalized function which is windowed by a window. The window used is defined as the central lobe of a horizontally stretched function ) for .Equivalently,where a is a positive integer determining the size of the kernel, generally 2 or 3. The Lanczos kernel contains lobes. Among them, the number of positive lobes at the center is a and the other lobes are situated at each side which are alternating negative and positive lobes. For a one-dimensional signal with samples , the value interpolated at an arbitrary real argument x, is obtained by the discrete convolution of those samples with the Lanczos kernel,where the filter size parameter is defined as a. The sum is bounded in such a way that the kernel is 0 outside of the boundary [41].
- C
- Bilinear Interpolation: The use of linear polynomials to generate new data points within the range of a discrete set of known data points is known as linear interpolation. Bilinear interpolation is accomplished by first performing linear interpolation in one direction and then repeating the process from the opposite direction. In bilinear interpolation, a value for a random position is determined by the weighted average of the four closest values. In the sense of image processing, the four closest values can be regarded as the four closest coordinates to the specified coordinate for which the value is to be determined. In this method, two linear interpolations are performed. One linear interpolation is performed in a direction and the next is performed in the perpendicular direction. The output is smoother than the original input value set. When all distances between the data points are equal, then the interpolated value is their sum divided by four. Here, the interpolation kernel, iswhere x is the distance between two points to be interpolated.
- D
- Nearest Neighbor Interpolation: Nearest neighbor interpolation is the most simple interpolation technique [42,43]. In this method, each interpolated output value is generated with the closest sample point in the input. This method produces discontinuous interpolated data [44]. The interpolated point is determined bywhere a and b are the indexes of and and .
3.3. Convolutional Neural Network Architecture
3.4. Experimental Settings and Evaluation Metrics
4. Experimental Analysis
4.1. Searching Optimal Signal Length
4.2. Effects of Various Interpolation Techniques
4.3. Results and Discussions
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| RTD | RealSense Trajectory Digit |
| RTC | RealSense Trajectory Character |
| 6DMG | 6-Dimentional Motion Gesture |
| CNN | Convolutional Neural Network |
| KNN | K-Nearest Neighbors |
| DTW | Dynamic-Time-Warping |
| UDA | Unsupervised Domain Adaptation |
| CRF | Conditional Random Fields |
| HMM | Hidden Markov Model |
| CHMM | Continuous Hidden Markov Model |
| LSTM | Long Short-term Memory |
| BiLSTM | Bidirectional Long Short-term Memory |
References
- Amma, C.; Schultz, T. Airwriting: Bringing text entry to wearable computers. XRDS 2013, 20, 50–55. [Google Scholar] [CrossRef]
- Yanay, T.; Shmueli, E. Air-writing recognition using smart-bands. Pervasive Mob. Comput. 2020, 66, 101183. [Google Scholar] [CrossRef]
- Zabulis, X.; Baltzakis, H.; Argyros, A.A. Vision-Based Hand Gesture Recognition for Human–Computer Interaction. Univers. Access Handb. 2009, 34, 30. [Google Scholar]
- Chen, M.; AlRegib, G.; Juang, B.H. Air-Writing Recognition—Part I: Modeling and Recognition of Characters, Words, and Connecting Motions. IEEE Trans. Hum. Mach. Syst. 2016, 46, 403–413. [Google Scholar] [CrossRef]
- Alam, M.; Kwon, K.C.; Abbass, M.Y.; Imtiaz, S.M.; Kim, N. Trajectory-based air-writing recognition using deep neural network and depth sensor. Sensors 2020, 20, 376. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.; Zhong, L.; Wickramasuriya, J.; Vasudevan, V. uWave: Accelerometer-based personalized gesture recognition and its applications. Pervasive Mob. Comput. 2009, 5, 657–675. [Google Scholar] [CrossRef]
- Dwarampudi, M.; Reddy, N. Effects of padding on LSTMs and CNNs. arXiv 2019, arXiv:1903.07288. [Google Scholar]
- Davis, P.J. Interpolation and Approximation; Courier Corporation: Chelmsford, MA, USA, 1975. [Google Scholar]
- Aly, H.A.; Dubois, E. Image up-sampling using total-variation regularization with a new observation model. IEEE Trans. Image Process. 2005, 14, 1647–1659. [Google Scholar] [CrossRef]
- Roy, R.; Pal, M.; Gulati, T. Zooming digital images using interpolation techniques. Int. J. Appl. Innov. Eng. Manag. 2013, 2, 34–45. [Google Scholar]
- Kim, J.; He, J.; Lyons, K.; Starner, T. The gesture watch: A wireless contact-free gesture based wrist interface. In Proceedings of the 2007 11th IEEE International Symposium on Wearable Computers, Boston, MA, USA, 11–13 October 2007; pp. 15–22. [Google Scholar]
- Ye, R.; Dai, Q. Implementing transfer learning across different datasets for time series forecasting. Pattern Recognit. 2021, 109, 107617. [Google Scholar] [CrossRef]
- Luo, Y.; Liu, J.; Shimamoto, S. Wearable Air-Writing Recognition System employing Dynamic Time Warping. In Proceedings of the 2021 IEEE 18th Annual Consumer Communications & Networking Conference (CCNC), Las Vegas, NV, USA, 9–12 January 2021; pp. 1–6. [Google Scholar]
- MerlinLivingston, L.; Deepika, P.; Benisha, M. An Inertial Pen with Dynamic Time Warping Recognizer for Handwriting and Gesture Recognition. Int. J. Eng. Trends Technol. 2016, 35, 154–163. [Google Scholar]
- Chen, M.; AlRegib, G.; Juang, B.H. Air-Writing Recognition—Part II: Detection and Recognition of Writing Activity in Continuous Stream of Motion Data. IEEE Trans. Hum. Mach. Syst. 2016, 46, 436–444. [Google Scholar] [CrossRef]
- Xu, S.; Xue, Y. Air-writing characters modelling and recognition on modified CHMM. In Proceedings of the 2016 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Budapest, Hungary, 9–12 October 2016; pp. 001510–001513. [Google Scholar]
- Li, C.; Xie, C.; Zhang, B.; Chen, C.; Han, J. Deep Fisher discriminant learning for mobile hand gesture recognition. Pattern Recognit. 2018, 77, 276–288. [Google Scholar] [CrossRef] [Green Version]
- Wen, H.; Ramos Rojas, J.; Dey, A.K. Serendipity: Finger gesture recognition using an off-the-shelf smartwatch. In Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems, San Jose, CA, USA, 7–12 May 2016; pp. 3847–3851. [Google Scholar]
- Levy, A.; Nassi, B.; Elovici, Y.; Shmueli, E. Handwritten signature verification using wrist-worn devices. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2018, 2, 1–26. [Google Scholar] [CrossRef]
- Amma, C.; Georgi, M.; Schultz, T. Airwriting: A wearable handwriting recognition system. Pers. Ubiquitous Comput. 2014, 18, 191–203. [Google Scholar] [CrossRef]
- Xu, C.; Pathak, P.H.; Mohapatra, P. Finger-writing with smartwatch: A case for finger and hand gesture recognition using smartwatch. In Proceedings of the 16th International Workshop on Mobile Computing Systems and Applications, Santa Fe, NM, USA, 12–13 February 2015; pp. 9–14. [Google Scholar]
- Lin, X.; Chen, Y.; Chang, X.W.; Liu, X.; Wang, X. Show: Smart handwriting on watches. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2018, 1, 1–23. [Google Scholar] [CrossRef]
- Chen, Y.H.; Huang, C.H.; Syu, S.W.; Kuo, T.Y.; Su, P.C. Egocentric-View Fingertip Detection for Air Writing Based on Convolutional Neural Networks. Sensors 2021, 21, 4382. [Google Scholar] [CrossRef] [PubMed]
- Kim, U.H.; Hwang, Y.; Lee, S.K.; Kim, J.H. Writing in The Air: Unconstrained Text Recognition from Finger Movement Using Spatio-Temporal Convolution. arXiv 2021, arXiv:2104.09021. [Google Scholar]
- Bastas, G.; Kritsis, K.; Katsouros, V. Air-Writing Recognition using Deep Convolutional and Recurrent Neural Network Architectures. In Proceedings of the 2020 17th International Conference on Frontiers in Handwriting Recognition (ICFHR), Dortmund, Germany, 8–10 September 2020; pp. 7–12. [Google Scholar]
- Tsai, T.H.; Hsieh, J.W.; Chang, C.W.; Lay, C.R.; Fan, K.C. Air-writing recognition using reverse time ordered stroke context. J. Vis. Commun. Image Represent. 2021, 78, 103065. [Google Scholar] [CrossRef]
- Arsalan, M.; Santra, A.; Bierzynski, K.; Issakov, V. Air-Writing with Sparse Network of Radars using Spatio-Temporal Learning. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 8877–8884. [Google Scholar]
- Moazen, D.; Sajjadi, S.A.; Nahapetian, A. AirDraw: Leveraging smart watch motion sensors for mobile human computer interactions. In Proceedings of the 2016 13th IEEE Annual Consumer Communications & Networking Conference (CCNC), Las Vegas, NV, USA, 9–12 January 2016; pp. 442–446. [Google Scholar]
- Uysal, C.; Filik, T. RF-Wri: An Efficient Framework for RF-Based Device-Free Air-Writing Recognition. IEEE Sens. J. 2021, 21, 17906–17916. [Google Scholar] [CrossRef]
- Hsieh, C.H.; Lo, Y.S.; Chen, J.Y.; Tang, S.K. Air-Writing Recognition Based on Deep Convolutional Neural Networks. IEEE Access 2021, 9, 142827–142836. [Google Scholar] [CrossRef]
- Alam, M.S.; Kwon, K.C.; Imtiaz, S.M.; Hossain, M.B.; Rupali, S.; Hyun, J. Air-writing recognition using a fusion CNN-LSTM neural network. In Proceedings of the 8th International Conference on Electronics, Electrical Engieering, Computer Scicence: Innovationa and Convergence, Osaka, Japan, 21–23 July 2021. [Google Scholar]
- Alam, M.S.; Kwon, K.C.; Kim, N. Implementation of a Character Recognition System Based on Finger-Joint Tracking Using a Depth Camera. IEEE Trans. Hum. Mach. Syst. 2021, 51, 229–241. [Google Scholar] [CrossRef]
- Xu, S.; Xue, Y.; Zhang, X.; Jin, L. A Novel Unsupervised domain adaptation method for inertia-Trajectory translation of in-air handwriting. Pattern Recognit. 2021, 116, 107939. [Google Scholar] [CrossRef]
- Lepot, M.; Aubin, J.B.; Clemens, F.H. Interpolation in time series: An introductive overview of existing methods, their performance criteria and uncertainty assessment. Water 2017, 9, 796. [Google Scholar] [CrossRef] [Green Version]
- Chen, M.; AlRegib, G.; Juang, B.H. 6dmg: A new 6d motion gesture database. In Proceedings of the 3rd Multimedia Systems Conference, Chapel Hill, NC, USA, 22–24 February 2012; pp. 83–88. [Google Scholar]
- Alam, M.S.; Kwon, K.; Kim, N. Trajectory-Based Air-Writing Character Recognition Using Convolutional Neural Network. In Proceedings of the 4th International Conference on Control, Robotics and Cybernetics, CRC 2019, Tokyo, Japan, 27–30 September 2019; pp. 86–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Wu, H.; Gu, X. Towards Dropout Training for Convolutional Neural Networks. Neural Netw. 2015, 71, 1–10. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Park, S.; Kwak, N. Analysis on the dropout effect in convolutional neural networks. In Asian Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 189–204. [Google Scholar]
- Keys, R. Cubic convolution interpolation for digital image processing. IEEE Trans. Acoust Speech Signal Process. 1981, 29, 1153–1160. [Google Scholar] [CrossRef] [Green Version]
- Burger, W.; Burge, M.J. Digital Image Processing: An Algorithmic Introduction Using Java; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Athawale, T.; Entezari, A. Uncertainty quantification in linear interpolation for isosurface extraction. IEEE Trans. Vis. Comput. Graph. 2013, 19, 2723–2732. [Google Scholar] [CrossRef]
- Carrizosa, E.; Olivares-Nadal, A.V.; Ramírez-Cobo, P. Time series interpolation via global optimization of moments fitting. Eur. J. Oper. Res. 2013, 230, 97–112. [Google Scholar] [CrossRef]
- Gnauck, A. Interpolation and approximation of water quality time series and process identification. Anal. Bioanal. Chem. 2004, 380, 484–492. [Google Scholar] [CrossRef]
- Hubel, D.H.; Wiesel, T.N. Receptive fields and functional architecture of monkey striate cortex. J. Physiol. 1968, 195, 215–243. [Google Scholar] [CrossRef]
- Fukushima, K.; Miyake, S. Neocognitron: A self-organizing neural network model for a mechanism of visual pattern recognition. In Competition and Cooperation in Neural Nets; Springer: Berlin/Heidelberg, Germany, 1982; pp. 267–285. [Google Scholar]
- Zeng, M.; Nguyen, L.T.; Yu, B.; Mengshoel, O.J.; Zhu, J.; Wu, P.; Zhang, J. Convolutional neural networks for human activity recognition using mobile sensors. In Proceedings of the 6th International Conference on Mobile Computing, Applications and Services, Austin, TX, USA, 6–7 November 2014; pp. 197–205. [Google Scholar]
- Duffner, S.; Berlemont, S.; Lefebvre, G.; Garcia, C. 3D gesture classification with convolutional neural networks. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 5432–5436. [Google Scholar]
- Yang, J.; Nguyen, M.N.; San, P.P.; Li, X.; Krishnaswamy, S. Deep Convolutional Neural Networks on Multichannel Time Series for Human Activity Recognition. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, IJCAI 2015, Buenos Aires, Argentina, 25–31 July 2015; pp. 3995–4001. [Google Scholar]
- Ha, S.; Choi, S. Convolutional neural networks for human activity recognition using multiple accelerometer and gyroscope sensors. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 381–388. [Google Scholar]
- Lee, S.M.; Yoon, S.M.; Cho, H. Human activity recognition from accelerometer data using Convolutional Neural Network. In Proceedings of the 2017 IEEE International Conference on Big Data and Smart Computing, Jeju, Korea, 13–16 February 2017; pp. 131–134. [Google Scholar]
- Panwar, M.; Dyuthi, S.R.; Prakash, K.C.; Biswas, D.; Acharyya, A.; Maharatna, K.; Gautam, A.; Naik, G.R. CNN based approach for activity recognition using a wrist-worn accelerometer. In Proceedings of the 2017 39th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Jeju Island, Korea, 11–15 July 2017; pp. 2438–2441. [Google Scholar]
- Li, T.; Zhang, Y.; Wang, T. SRPM–CNN: A combined model based on slide relative position matrix and CNN for time series classification. Complex Intell. Syst. 2021, 7, 1619–1631. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Carneiro, T.; Medeiros Da NóBrega, R.V.; Nepomuceno, T.; Bian, G.B.; De Albuquerque, V.H.C.; Filho, P.P.R. Performance Analysis of Google Colaboratory as a Tool for Accelerating Deep Learning Applications. IEEE Access 2018, 6, 61677–61685. [Google Scholar] [CrossRef]
- Bradski, G. The OpenCV Library. J. Softw. Tools 2000. Available online: https://github.com/opencv/opencv (accessed on 21 November 2021).
- Chollet, F. Keras. 2015. Available online: https://github.com/fchollet/keras (accessed on 21 November 2021).
- Xu, S.; Xue, Y. A Long Term Memory Recognition Framework on Multi-Complexity Motion Gestures. In Proceedings of the 14th IAPR International Conference on Document Analysis and Recognition, ICDAR 2017, Kyoto, Japan, 9–15 November 2017; pp. 201–205. [Google Scholar] [CrossRef]
- Yang, C.; Ku, B.; Han, D.; Ko, H. Alpha-numeric hand gesture recognition based on fusion of spatial feature modelling and temporal feature modelling. Electron. Lett. 2016, 52, 1679–1681. [Google Scholar] [CrossRef]
- Yana, B.; Onoye, T. Fusion networks for air-writing recognition. In International Conference on Multimedia Modeling; Springer: Berlin/Heidelberg, Germany, 2018; pp. 142–152. [Google Scholar]



{kind=link}
{kind=link}
| Dataset | No. of Classes, n | No. of Features, n | No. of Users | No. of Samples | Training Principle | |
|---|---|---|---|---|---|---|
| User Dependent | User Independent | |||||
| RTD * [5] | 10 | 2 | 10 | 20,000 | ✓ | ✗ |
| RTC * [36] | 26 | 3 | 10 | 30,000 | ✓ | ✗ |
| Smart-band [2] | 26 | 6 | 55 | 21,450 | ✓ | ✓ |
| 6DMG-digit [35] | 10 | 13 | 6 | 600 | ✓ | ✓ |
| 6DMG-lower [35] | 26 | 13 | 6 | 1470 | ✓ | ✓ |
| 6DMG-upper [35] | 26 | 13 | 25 | 6500 | ✓ | ✓ |
| 6DMG-all [35] | 62 | 13 | 25 | 8570 | ✓ | ✓ |
| Operation Group | Layer Name | Filter Size | No. of Filters | Stride Size | Padding Size | Activation Function | Output Size * | No. of Parameters * |
|---|---|---|---|---|---|---|---|---|
| - | Input | - | - | - | - | - | 0 | |
| Group1 | Conv1-1 | 32 | ReLU | 160 | ||||
| Conv1-2 | 32 | ReLU | 4128 | |||||
| MaxPool1 | 1 | 0 | - | 0 | ||||
| Dropout | 0 | |||||||
| Group2 | Conv2-1 | 64 | ReLU | 8256 | ||||
| Conv2-2 | 64 | ReLU | 16,448 | |||||
| MaxPool2 | 1 | 0 | - | 0 | ||||
| Dropout | 0 | |||||||
| Group3 | Conv3-1 | 128 | ReLU | 32,896 | ||||
| Conv3-2 | 128 | ReLU | 65,664 | |||||
| MaxPool3 | 1 | 0 | - | 0 | ||||
| Dropout | 0 | |||||||
| Group4 | Flatten | - | - | - | - | - | 3200 | 0 |
| Dense | - | - | - | - | ReLU | 512 | 1,638,912 | |
| Dropout | 512 | 0 | ||||||
| Dense | - | - | - | - | Softmax | 26 | 13,338 | |
| Total | 1,779,802 | |||||||
| Upsampling Method | Downsampling Method | Signal Length, l | Accuracy | |
|---|---|---|---|---|
| Avg. (%) | Std. | |||
| Bicubic | Bicubic | 100 | 87.35 | 0.41 |
| Lanczos | 87.21 | 0.59 | ||
| Bilinear | 87.76 | 0.45 | ||
| Nearest neighbor | 87.04 | 0.21 | ||
| Lanczos | Bicubic | 100 | 87.54 | 0.18 |
| Lanczos | 86.50 | 0.70 | ||
| Bilinear | 86.84 | 0.46 | ||
| Nearest neighbor | 86.73 | 0.27 | ||
| Bilinear | Bicubic | 100 | 86.91 | 0.77 |
| Lanczos | 86.77 | 0.63 | ||
| Bilinear | 86.25 | 0.80 | ||
| Nearest neighbor | 87.38 | 0.09 | ||
| Nearest neighbor | Bicubic | 100 | 87.38 | 0.37 |
| Lanczos | 87.32 | 0.76 | ||
| Bilinear | 86.67 | 0.58 | ||
| Nearest neighbor | 87.08 | 1.24 | ||
| Bicubic | Bicubic | 200 | 88.54 | 0.31 |
| Lanczos | Lanczos | 87.35 | 0.31 | |
| Bilinear | Bilinear | 88.46 | 0.19 | |
| Nearest neighbor | Nearest neighbor | 88.08 | 0.59 | |
| Approach | Sequence Length, l | # Padded or Upsampled Samples | # Truncated or Downsampled Samples | # Flops | Inference Time (ms) | Accuracy | |
|---|---|---|---|---|---|---|---|
| Avg. (%) | Std. | ||||||
| Pre-sequence Padding and Truncation | 50 | 212 | 21,238 | 599,177 | 1.648 | 59.87 | 0.52 |
| 100 | 10,892 | 10,558 | 992,393 | 1.492 | 84.57 | 0.30 | |
| 200 | 21,161 | 289 | 1,778,825 | 1.709 | 86.58 | 0.37 | |
| 400 | 21,449 | 1 | 3,417,225 | 2.056 | 86.38 | 0.24 | |
| Post-sequence Padding and Truncation | 50 | 212 | 21,238 | 599,177 | 1.429 | 48.15 | 0.44 |
| 100 | 10,892 | 10,558 | 992,393 | 1.843 | 80.25 | 0.23 | |
| 200 | 21,161 | 289 | 1,778,825 | 1.770 | 85.84 | 0.42 | |
| 400 | 21,449 | 1 | 3,417,225 | 2.519 | 85.63 | 0.35 | |
| Bicubic Interpolation | 50 | 212 | 21,238 | 599,177 | 1.475 | 84.98 | 0.35 |
| 100 | 10,892 | 10,558 | 992,393 | 1.533 | 87.35 | 0.41 | |
| 200 | 21,161 | 289 | 1,778,825 | 1.687 | 88.54 | 0.31 | |
| 400 | 21,449 | 1 | 3,417,225 | 2.430 | 88.02 | 0.48 | |
| Dataset | Min | Max | Signal Length, l |
|---|---|---|---|
| RTD | 18 | 150 | 125 |
| RTC | 21 | 173 | 125 |
| Smart-band | 34 | 438 | 200 |
| 6DMG-digit | 29 | 218 | 175 |
| 6DMG-lower | 27 | 163 | 150 |
| 6DMG-upper | 27 | 412 | 250 |
| 6DMG-all | 27 | 412 | 250 |
| Training Principle | Approach | Accuracy | ||
|---|---|---|---|---|
| Smart-Band | RTC | RTD | ||
| User-dependent principle (10-fold CV) | KNN-DTW based [2] | 89.20 | - | - |
| 2D-CNN based [36] | - | 97.29 | - | |
| LSTM based [5] | - | - | 99.17 | |
| CNN-LSTM fusion [31] | - | 98.74 | 99.63 | |
| Proposed | 91.34 | 99.63 | 99.76 | |
| User-independent principle | 1D-CNN [2] | 83.20 | - | - |
| Proposed | 85.59 | - | - | |
| Training Principle | Approach | Accuracy | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Digit | Lower | Upper | All | ||||||
| Avg. (%) | Std. | Avg. (%) | Std. | Avg. (%) | Std. | Avg. (%) | Std. | ||
| User- dependent principle (5-fold CV) | HMM-based [4] | - | - | - | - | 98.16 | 2.37 | - | - |
| LSTM-bases [61] | 97.33 | 1.49 | 96.80 | 0.57 | 98.34 | 0.50 | 94.75 | 0.31 | |
| CRF-CNN fusion [62] | - | - | - | - | 98.57 | - | - | - | |
| BiLSTM-CNN fusion [63] | 99.33 | - | - | - | 99.27 | - | - | - | |
| CHMM-based [16] | 99.00 | 1.09 | 98.22 | 0.73 | 97.29 | 0.66 | 95.91 | 0.47 | |
| UDA [33] | 99.78 | 0.03 | 98.94 | 0.08 | 99.55 | 0.06 | 97.03 | 0.11 | |
| Proposed | 100.00 | 0.00 | 99.47 | 0.39 | 99.80 | 0.20 | 98.99 | 0.23 | |
| User- independent principle | CHMM [16] | 96.70 | 4.08 | 76.38 | 5.25 | 91.03 | 1.54 | 62.69 | 2.91 |
| UDA [33] | 98.74 | 0.34 | 92.86 | 0.48 | 96.99 | 0.45 | 87.69 | 0.58 | |
| Proposed | 99.26 | 0.12 | 94.48 | 0.45 | 99.23 | 0.94 | 91.24 | 0.86 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abir, F.A.; Siam, M.A.; Sayeed, A.; Hasan, M.A.M.; Shin, J. Deep Learning Based Air-Writing Recognition with the Choice of Proper Interpolation Technique. Sensors 2021, 21, 8407. https://doi.org/10.3390/s21248407
Abir FA, Siam MA, Sayeed A, Hasan MAM, Shin J. Deep Learning Based Air-Writing Recognition with the Choice of Proper Interpolation Technique. Sensors. 2021; 21(24):8407. https://doi.org/10.3390/s21248407
Chicago/Turabian StyleAbir, Fuad Al, Md. Al Siam, Abu Sayeed, Md. Al Mehedi Hasan, and Jungpil Shin. 2021. "Deep Learning Based Air-Writing Recognition with the Choice of Proper Interpolation Technique" Sensors 21, no. 24: 8407. https://doi.org/10.3390/s21248407