1. Introduction
Hajj is an annual religious gathering for Muslims. Every year, millions of people of different ages, races, and cultures from all over the world come to the Kingdom of Saudi Arabia, specifically Mecca and Medina, to perform the rituals of Hajj and Umrah [
1]. This diversified nature of crowds would not have been a reality without the use of modern technologies such as wireless networking, computer vision, spatial computing, data analytics, mobile applications, immersive technologies, and crowd modelling and simulation [
2]. The safety of the participants is of primary importance, and it is managed by observing crowd behavior and accurately identifying human activity [
3]. Although there is a considerable investment made by the Saudi government towards wireless visual sensor networks with over 5000 cameras installed, along with scalar sensor technologies such as mobile phones equipped with GPS sensors that are used for pilgrim tracking and monitoring, the monitoring of such an event is very challenging due to large numbers of pilgrims attending each year. As a result, stampedes and other violent activities occur, resulting in the loss of precious human lives, as reported in
Table 1.
Accurate identification of violent activity is challenging also due to complex patterns, different perspectives, and variance [
4]. Researchers have proposed various techniques to efficiently monitor violent crowds during Hajj and Umrah. Dirgahayu and Hidayat [
5] have developed a geofencing emergency warning system to help pilgrims in an emergency. They track the pilgrims with their mobile numbers using a built-in GPS unit. Similarly, Mohandas et al. [
6] developed a wireless sensor network to monitor pilgrims utilisingutilizing a network that can withstand delay. Every pilgrim has a mobile sensor kit that includes a GPS unit, microcontroller, antennas, and battery. The kit sends identification numbers, longitude, and time to track the user in real time. However, these solutions are based on scalar sensor technology, which has several defects. For example, this technology fails to be of use in certain worship areas and other places where GPS does not work due to signal issues. Secondly, providing each pilgrim with a mobile sensor kit proves to be a very costly affair. Researchers have recently been inspired by computer vision and pattern recognition from the performance of CNN in self-driving cars [
7], the smart home [
8,
9], transportation [
10], and other similar fields where it has been applied. Therefore, computer vision and machine learning researchers have also proposed new approaches for efficiently monitoring and managing crowds.
As an instance of computer vision techniques, Khanet al. [
11] have developed a system used to detect pilgrims. After training two object detection models from Faster RCNN and YOLO-v3, their performance was analysed. For the dataset, 1339 photos of pilgrims and 952 photos of non-pilgrims were collected from the internet. The authors claim that Faster-RCNN with inception-v2 has achieved 0.59% accuracy with 0.66 F1-score on YOLO-v3, respectively. Likewise, Khan et al. [
12] have developed a crowd monitoring system to efficiently manage crowds during Hajj. The crowd’s images were taken from the internet and categorised into normal-crowded, semi-crowded, light, and overcrowded. They have used the two-layer CNN architecture; in the first layer, 32 filters have been used, while in the second layer, 64 filters with 0.5 dropouts have been used, achieving an accuracy of 98%.
Similarly, Hassner et al. [
13] have proposed a Bag of Words model framework with handcrafted features called animated blobs that distinguish between combat and non-combat sequences to identify violent crowd activity. Spatial and temporal features were used for feature extraction and classification purposes. Hassner et al. [
13] have proposed a descriptor based on the changes in the optical flow magnitude between two frames. The violent stream descriptor that classifies behaviors is based on the Support Vector Machine (SVM).
Similarly, Gao et al. in [
14] have proposed a Violent Oriented Flow (OViF) descriptor, which extracts information on the magnitude and direction of movement. The linear SVM is trained on these extracted features to recognise both violent and nonviolent activities. Khan et al. [
15] have used the lightweight, optimised MobileNetV1 architecture to identify movies. In [
16], the authors have used the sliding window approach and have improved the Fisher vector method for detecting violence. They have achieved an accuracy of 99.5%, 96.4%, and 93.7% in identifying movie violence, violent crowds, and hockey fight datasets. Serrano et al. [
17] have recently used Hough Forests with 2DCNN to detect violent activity. Their proposed approach obtained an accuracy of 94.6% in the Hockey Fight dataset. Yu et al. [
18] have used Bag of Visual Words (BoVW), feature pooling, and Dimensional Histograms of Gradient Orientation (HOG3D) for violent scenes in videos. The author combines these features based on a Kernel Extreme Learning Machine (KELM) for generalised capabilities. Recently, Habib et al. [
19] have proposed a pilgrim’s counter to efficiently monitor pilgrims during Hajj and Umrah in the case of the COVID-19 satiation.
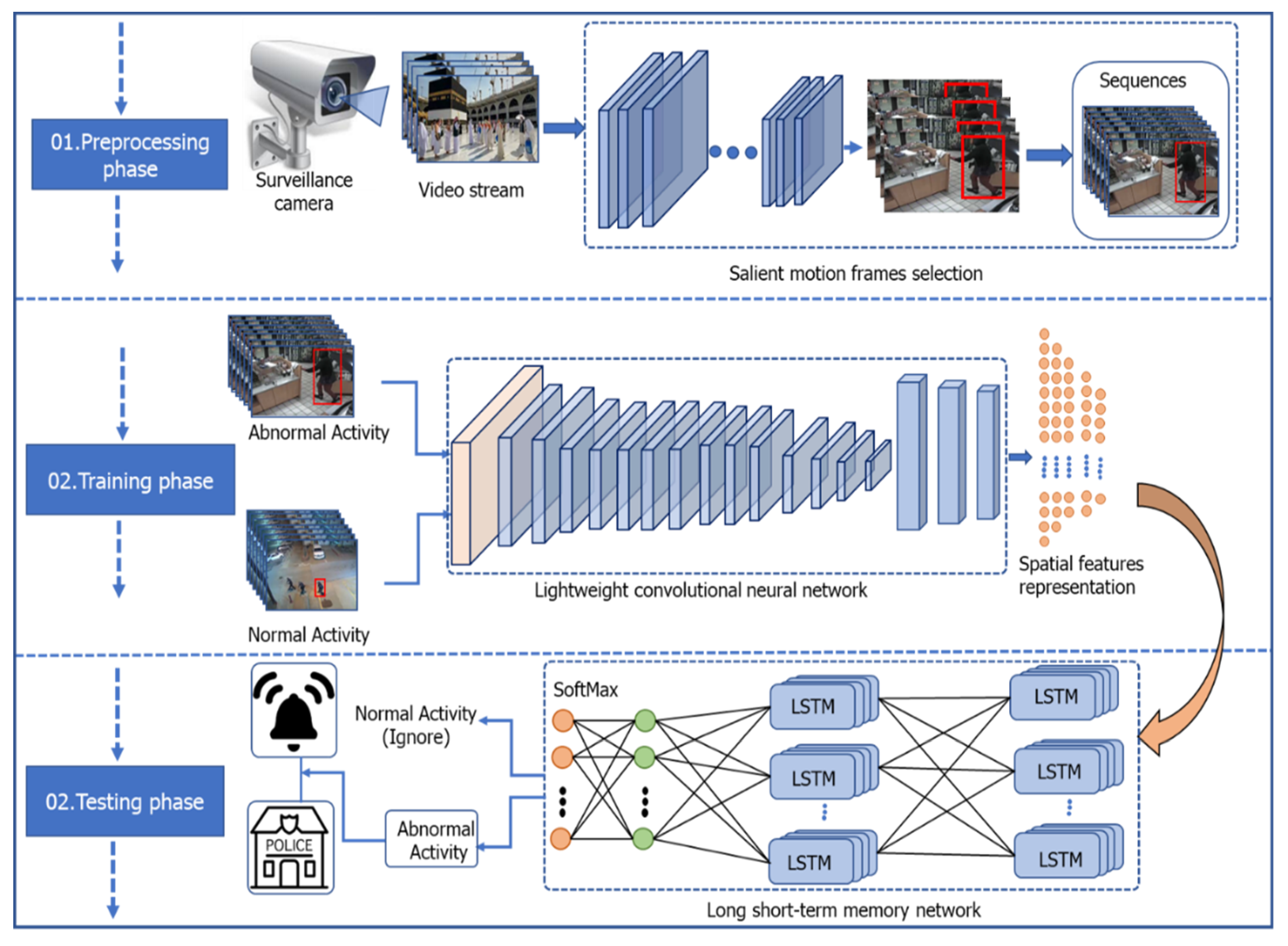
Accurate and precise identification of violent activity in surveillance environments still faces significant challenges such as cluttered backgrounds, different points of view, changing light conditions, different scales, and high computation of CNN models. However, current conventional methods are used to sample algorithms and ergonomic engineering techniques that fail to address these challenges. Recently, methods based on deep learning have solved these challenges to some extent by using recurrent neural network (RNN), long short term memory network (LSTM), bi-directional LSTM, and gated recurrent unit (GRU). However, they do not focus on selecting discriminative features and lightweight models to reduce computational costs. Violent activity is recognised as movements of various human body parts such as legs and arms, etc., in connecting multiple video frames. Therefore, both spatial and temporal information need to be analysed in order to identify violent activity accurately. This paper develops a lightweight framework for identifying violent activity in surveillance during Hajj and Umrah. The following is a summary of the main contributions of the proposed framework:
A deep learning assistive framework is developed for the efficient recognition of violent activity by using the visual sensor. In order to efficiently utilise our proposed framework, a lightweight CNN object detector is trained on the pilgrims’ datasets to select only the pilgrims’ prominent frames for further processing.
Violent activity is understood as a sequence of motion patterns in the connective video frames. Therefore, both spatial and temporal features are important. For spatial features extraction, since the lightweight MobileNetV2 is transferred for learning violent activity recognition, a lightweight sequential learning LSMT model is proposed for the temporal features extraction.
For performance evaluation, we have conducted experiments on two publicly available datasets: Hockey Fight and Surveillance Fight Dataset. Furthermore, an ablation study is undertaken on spatial and temporal features extraction models in order to efficiently recognize violent activities. Finally, the proposed framework triggers an alarm to notify the law enforcement agency to take appropriate action in the case of any violent activity.
The rest of the paper is organised as follows:
Section 2 presents the proposed methodology. The experimental setup and evaluation are discussed in
Section 3 and
Section 4.
Section 5 concludes the article, discussing the potential for future investigation.
5. Conclusions
This paper has presented a framework for identifying violent activity in surveillance videos to avoid accidents during Hajj and Umrah. When a violent activity occurs, the system can sound an alarm and notify law enforcement agencies to take the appropriate safety actions required. In order to identify violent activity, we have assessed the performance of our proposed model by using publicly available Hockey Fight and Surveillance Fight datasets. After running multiple experiments, we have achieved 96% accuracy on Hockey Fight and 81.05% on Surveillance Fight datasets, the highest accuracy achieved in comparison with state-of-the-art methods. Furthermore, we have succeeded in balancing the computational complexity of the model suitable for resource-constrained devices. The proposed system can be used in the existing surveillance system to monitor Hajj, especially for crowd monitoring pilgrims on the way to Jamarat.
The existing framework is riddled with a few limitations; we intend to cover them in future research. In this paper, violent activity is recognised from a single view. They cannot cover the full 360° coverage of activity. In the future, we want to recognise violent activity from multiple views to obtain insights on activities. Furthermore, in this research, we have used the publicly available dataset for violent activity. We are currently preparing our own Hajj crowd dataset for violent activity recognition to use in further research. Furthermore, we will explore the performances of different deep learning models, such as two-stream networks, in order to learn both motion and spatio-temporal features efficiently.


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}