
Vehicle Trajectory Prediction with Lane Stream Attention-Based LSTMs and Road Geometry Linearization


Abstract
:1. Introduction
2. Related Work
3. Proposed Vehicle Trajectory Prediction Method
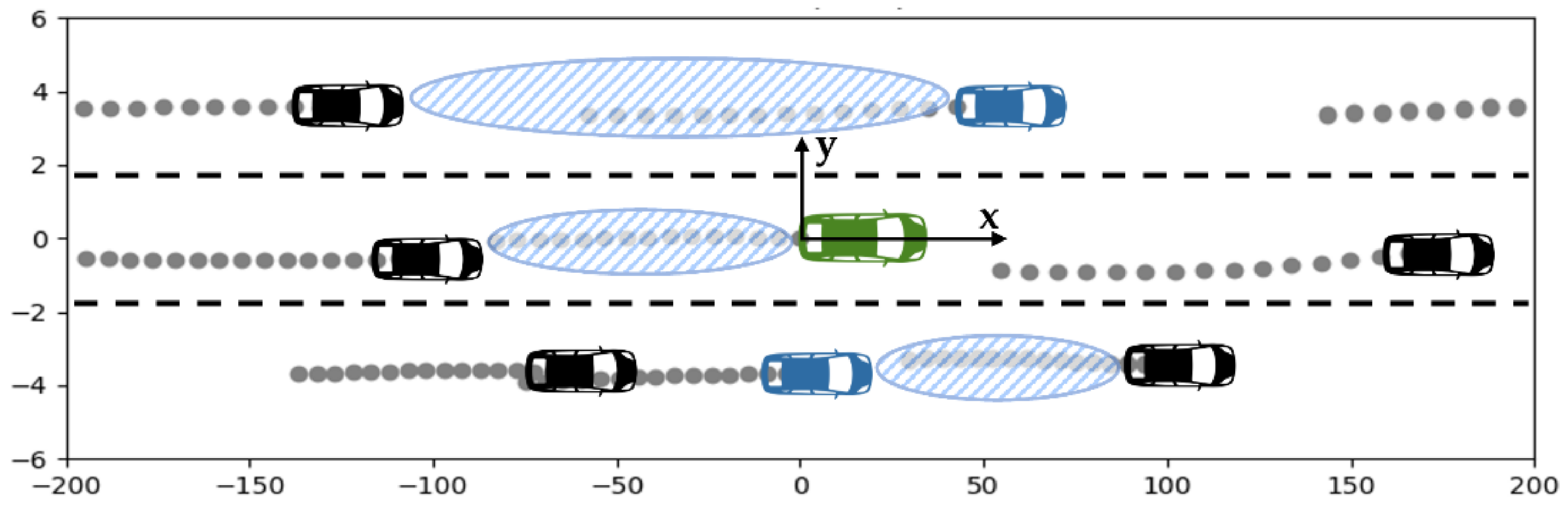
3.1. Problem Formulation
3.2. Surrounding Vehicle Data Processing
3.3. Base LSTM Encoder–Decoder Trajectory Prediction Model
- Input and output data: Our model’s input comprised the data related to the traffic flow of the target vehicle’s lane as well as the lanes to the left and right of the target vehicle for a fixed amount of time.
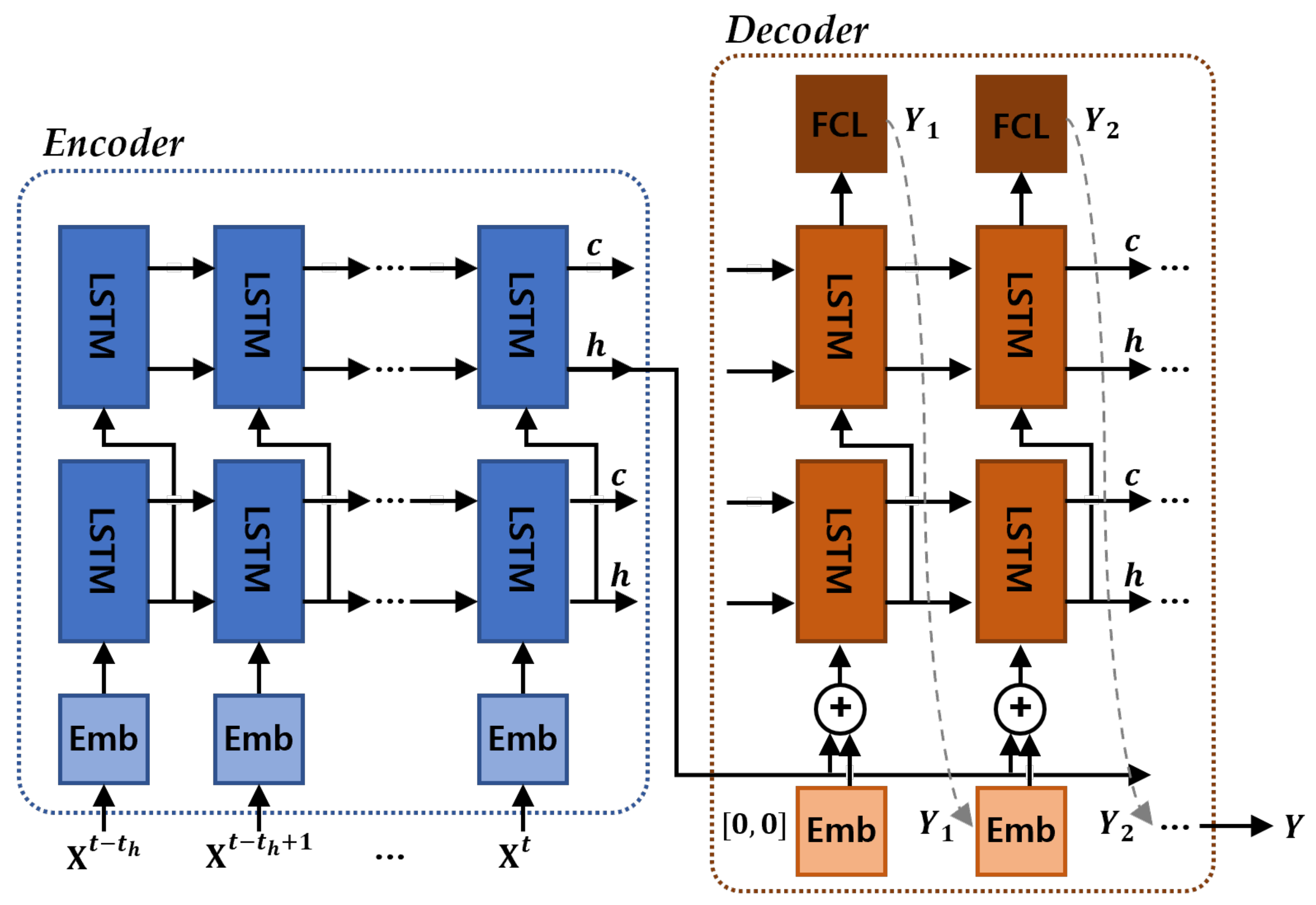
- Encoder: The encoding layer receives data from each time as the input and sends it through the embedding and LSTM layers to convert it to hidden state vectors. The cell and hidden state vectors that are calculated in the LSTM for each time step are sent to the next step. The topmost LSTM layer’s hidden state at the final time point acts as the context vector in which the driving information of the vehicles for a fixed amount of time is encoded. The LSTM has memory cells that summarize the past input sequences and store them, and these cells consist of the following gating mechanisms that properly combine the new input and memory information (Figure 4).
- Decoder: The context vectors that summarize the past driving information are sent from the encoding layer to the decoder layer’s input. The hidden states that are calculated in the LSTM layer for each time step are converted to x and y coordinates by the fully connected neural network layer. The position vectors that are ultimately produced as an output become the input of the next step, and a similar process is repeated until the goal prediction time is reached to determine a continuous future prediction position at each time point. The peaky LSTM encoder–decoder model connects the position vectors that become the input of each time step and the context vectors that are produced as an output by the encoding layer. The prediction performance can be improved by not sending the context vector solely on the decoder’s first step and then using the past driving information at each step.
- Loss function: In deep learning models, training progresses in the direction of reducing the loss function. Our ultimate training goal was to determine prediction points at the closest distance to the actual future position. Therefore, we adopted the Root Mean Square Error (RMSE), which corresponds to distance error, as the loss function. Additionally, more importance was placed on lateral accuracy than longitudinal accuracy [21].
3.4. Lane Stream Attention-Based LSTM Encoder–Decoder Trajectory Prediction Model
- Input and output data: The proposed attention-based model uses three encoders to depict the driving flow of the lanes that are adjacent to the target vehicle and one encoder that focuses on the target vehicle. The input data comprise central information that is considered with great caution when a human driver adjusts the vehicle’s velocity or changes lanes [66,67]. The lane driving flow encoder’s input is
- Attention: The final hidden state that is produced as an output by each encoder summarizes the sequence of driving information, and the influence of the most recent information is strongly reflected; therefore, it is appropriate to use this as a context vector that predicts the future position. The weight of each context vector is calculated as follows:
- Encoder–decoder: The encoding and decoding layers are similar to those described in the basic LSTM structure. However, in an attention-based model, a total of four encoding layers are utilized and a context vector that reflects the attention weights is added to the decoding layer. To prevent the challenge of the model becoming overfitted to the training data in the training process, the data are scaled and dropout is applied to the LSTM layer.
4. Evaluation of Vehicle Trajectory Prediction Model with Traffic Dataset
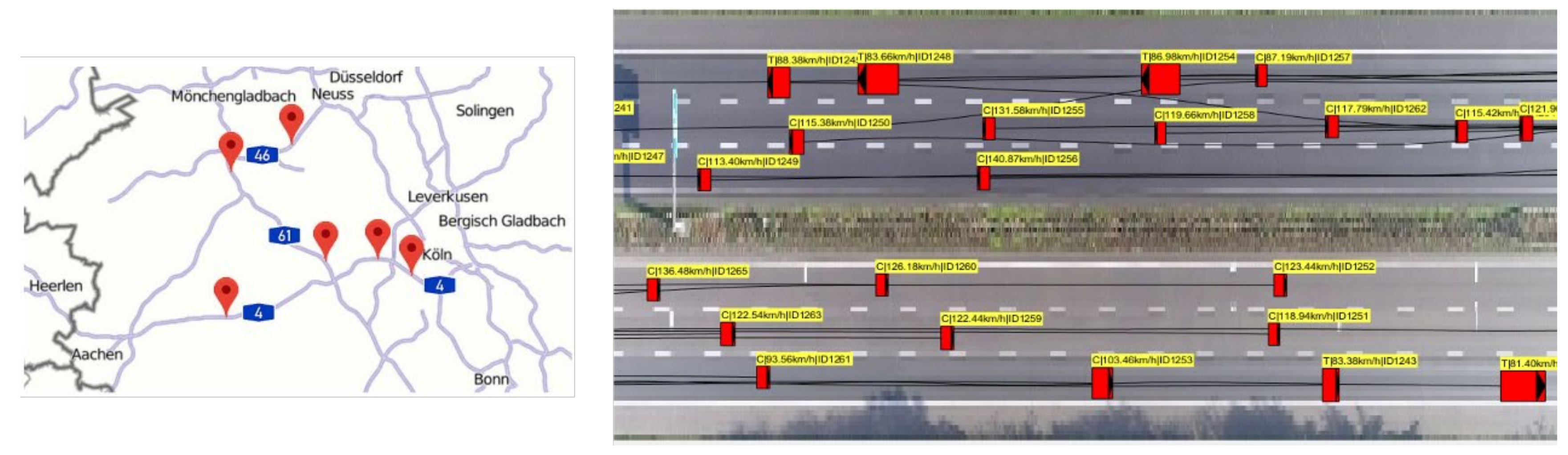
4.1. HighD Traffic Dataset
4.2. Training Results of Trajectory Prediction Model
5. Road Geometry Linearization Method for Trajectory Prediction in Real Driving Environments
5.1. Road Geometry Linearization Method
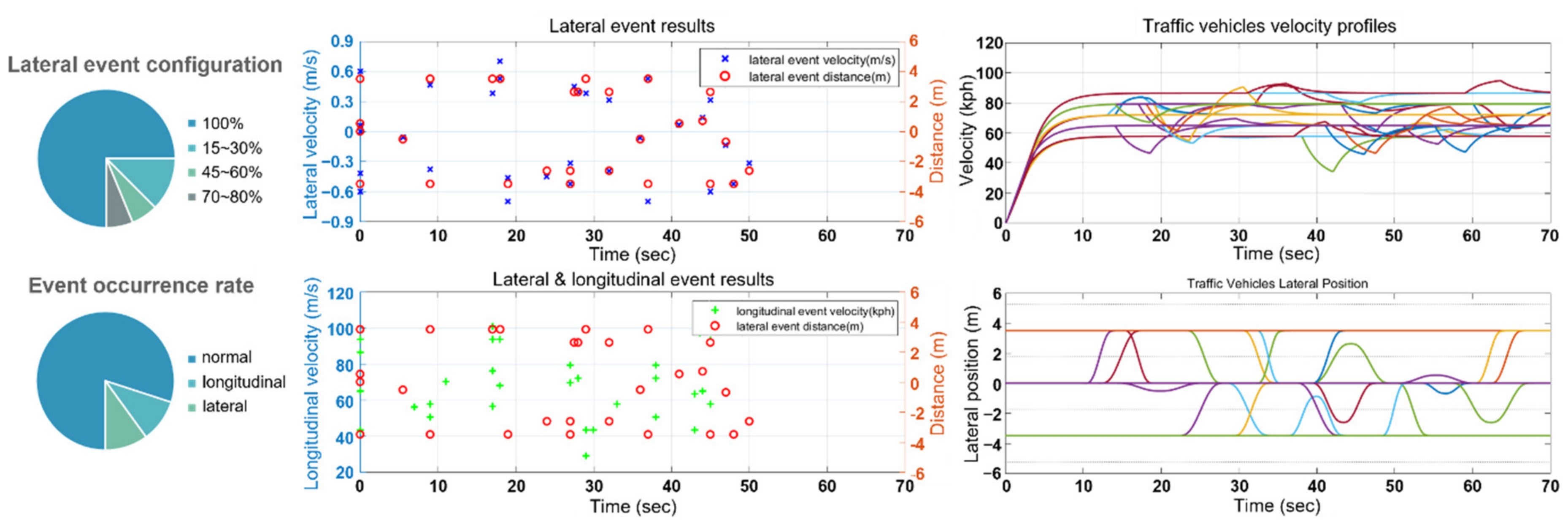
5.2. Complex Traffic Driving Data Generation in Simulation Environment
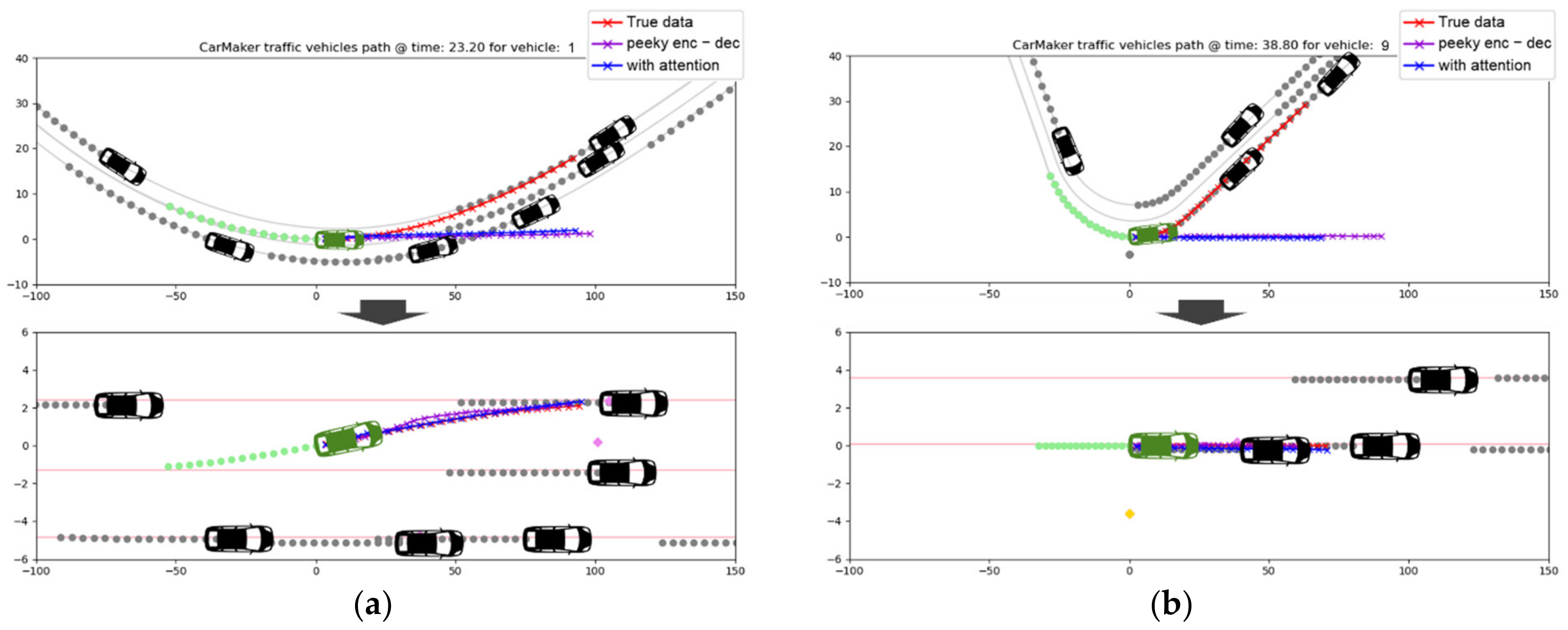
6. Experimental Evaluation
6.1. Evaluation of Trajectory Prediction Model with Path Linearization Method
- Scenario 1: Driving on a straight road section that is approximately 1.2 km long with lane changes (a driving environment like that in the HighD dataset).
- Scenario 2: Repeatedly driving on a complex, closed-loop road section that is approximately 1.5 km long and has straight road and curved road sections and intersections (left and right turns) without lane changes.
- Scenario 3: Driving on a similar road to the one described in Scenario 2 with lane changes.
6.2. Discussion
7. Conclusions
- The proposed lane stream attention-based trajectory prediction model improved long-term prediction accuracy by 25.4% compared to other methods. The ability to transform the context of each driving situation of the attention mechanism applied to the encoder–decoder model can predict the long-term trajectory more accurately.
- The proposed road shape linearization method simplifies the complex real road situation and expands the application range of the trajectory prediction model. In the complex traffic scenario acquired in the virtual driving environment, the distance error of the trajectory prediction model with the path linearization method was reduced by 76.7% compared to the result without the method. It is a more efficient and realistic method that can be applied to autonomous vehicles that drive on real roads rather than building large-scale traffic datasets on roads of numerous shapes.
Author Contributions
Funding
Conflicts of Interest
References
- Nilsson, J.; Silvlin, J.; Brannstrom, M.; Coelingh, E.; Fredriksson, J. If, When, and How to Perform Lane Change Maneuvers on Highways. IEEE Intell. Transp. Syst. Mag. 2016, 8, 68–78. [Google Scholar] [CrossRef]
- Sivaraman, S.; Trivedi, M.M. Dynamic Probabilistic Drivability Maps for Lane Change and Merge Driver Assistance. IEEE Trans. Intell. Transp. Syst. 2014, 15, 2063–2073. [Google Scholar] [CrossRef]
- Zhang, Y.; Lin, Q.; Wang, J.; Verwer, S.; Dolan, J.M. Lane-change intention estimation for car-following control in autonomous driving. IEEE Trans. Intell. Veh. 2018, 3, 276–286. [Google Scholar] [CrossRef]
- Vahidi, A.; Sciarretta, A. Energy saving potentials of connected and automated vehicles. Transp. Res. Part C Emerg. Technol. 2018, 95, 822–843. [Google Scholar] [CrossRef]
- Lindner, L.; Sergiyenko, O.; Rivas-López, M.; Ivanov, M.; Rodríguez-Quiñonez, J.C.; Hernández-Balbuena, D.; Flo-res-Fuentes, W.; Tyrsa, V.; Muerrieta-Rico, F.N.; Mercorelli, P. Machine vision system errors for unmanned aerial vehicle navigation. In Proceedings of the 2017 IEEE 26th International Symposium on Industrial Electronics (ISIE), Edinburgh, UK, 19–21 June 2017; pp. 1615–1620. [Google Scholar]
- Ivanov, M.; Sergiyenko, O.; Tyrsa, V.; Mercorelli, P.; Kartashov, V.; Hernandez, W.; Sheiko, S.; Kolendovska, M. Individual Scans Fusion in Virtual Knowledge Base for Navigation of Mobile Robotic Group with 3D TVS. In Proceedings of the IECON 2018—44th Annual Conference of the IEEE Industrial Electronics Society, Washington, DC, USA, 21–23 October 2018; pp. 3187–3192. [Google Scholar]
- Ammoun, S.; Nashashibi, F. Real time trajectory prediction for collision risk estimation between vehicles. In Proceedings of the 2009 IEEE 5th International Conference on Intelligent Computer Communication and Processing, Cluj-Napoca, Romania, 27–29 August 2009; pp. 417–422. [Google Scholar]
- Barrios, C.; Motai, Y. Improving Estimation of Vehicle’s Trajectory Using the Latest Global Positioning System With Kalman Filtering. IEEE Trans. Instrum. Meas. 2011, 60, 3747–3755. [Google Scholar] [CrossRef]
- Kim, B.; Yi, K. Probabilistic and Holistic Prediction of Vehicle States Using Sensor Fusion for Application to Integrated Vehicle Safety Systems. IEEE Trans. Intell. Transp. Syst. 2014, 15, 2178–2190. [Google Scholar] [CrossRef]
- Wiest, J.; Hoffken, M.; Kresel, U.; Dietmayer, K. Probabilistic trajectory prediction with Gaussian mixture models. In Proceedings of the Intelligent Vehicles Symposium (IV), Madrid, Spain, 3–7 June 2012. [Google Scholar] [CrossRef]
- Gindele, T.; Brechtel, S.; Dillmann, R. Learning Driver Behavior Models from Traffic Observations for Decision Making and Planning. IEEE Intell. Transp. Syst. Mag. 2015, 7, 69–79. [Google Scholar] [CrossRef]
- Mikolov, T.; Karafiát, M.; Burget, L.; Cernocký, J.; Khudanpur, S. Recurrent neural network based language model. In Proceedings of the Interspeech 2010, 11th Annual Conference of the International Speech Communication Association, Chiba, Japan, 26–30 September 2010; pp. 1045–1048. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Graves, A. Generating Sequences With Recurrent Neural Networks. arXiv 2013, arXiv:1308.0850. [Google Scholar]
- Karpathy, A. The Unreasonable Effectiveness of Recurrent Neural Networks. 2016. Available online: http://karpathy.github.io/2015/05/21/rnn-effectiveness (accessed on 23 October 2021).
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montréal, QC, Canada, 8–11 December 2014; pp. 3104–3112. [Google Scholar]
- Park, S.H.; Kim, B.; Kang, C.M.; Chung, C.C.; Choi, J.W. Sequence-to-sequence prediction of vehicle trajectory via LSTM encoder-decoder architecture. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 1672–1678. [Google Scholar] [CrossRef] [Green Version]
- Deo, N.; Trivedi, M.M. Convolutional Social Pooling for Vehicle Trajectory Prediction. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 1549–15498. [Google Scholar]
- Messaoud, K.; Yahiaoui, I.; Verroust-Blondet, A.; Nashashibi, F. Non-local Social Pooling for Vehicle Trajectory Prediction. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 975–980. [Google Scholar]
- Yan, J.; Peng, Z.; Yin, H.; Wang, J.; Wang, X.; Shen, Y.; Stechele, W.; Cremers, D. Trajectory prediction for intelligent vehicles using spatial-attention mechanism. IET Intell. Transp. Syst. 2020, 14, 1855–1863. [Google Scholar] [CrossRef]
- Alahi, A.; Goel, K.; Ramanathan, V.; Robicquet, A.; Fei-Fei, L.; Savarese, S. Social LSTM: Human Trajectory Prediction in Crowded Spaces. In Proceedings of the 29th IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 961–971. [Google Scholar] [CrossRef] [Green Version]
- Krajewski, R.; Bock, J.; Kloeker, L.; Eckstein, L. The highD Dataset: A Drone Dataset of Naturalistic Vehicle Trajectories on German Highways for Validation of Highly Automated Driving Systems. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 15 April 2018; pp. 2118–2125. [Google Scholar]
- Lefèvre, S.; Vasquez, D.; Laugier, C. A survey on motion prediction and risk assessment for intelligent vehicles. ROBOMECH J. 2014, 1, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Barth, A.; Franke, U. Where will the oncoming vehicle be the next second? In Proceedings of the 2008 IEEE Intelligent Vehicles Symposium, Eindhoven, The Netherlands, 4–6 June 2008; pp. 1068–1073. [Google Scholar]
- Toledo-Moreo, R.; Zamora-Izquierdo, M.A. IMM-Based Lane-Change Prediction in Highways With Low-Cost GPS/INS. IEEE Trans. Intell. Transp. Syst. 2009, 10, 180–185. [Google Scholar] [CrossRef] [Green Version]
- Broadhurst, A.; Baker, S.; Kanade, T. Monte Carlo road safety reasoning. In Proceedings of the IEEE Intelligent Vehicles Symposium, Las Vegas, NV, USA, 6–8 June 2005; pp. 319–324. [Google Scholar]
- Schreier, M.; Willert, V.; Adamy, J. Bayesian, maneuver-based, long-term trajectory prediction and criticality assessment for driver assistance systems. In Proceedings of the 17th International IEEE Conference on Intelligent Transportation Systems (ITSC), Qingdao, China, 8–11 October 2014; pp. 334–341. [Google Scholar]
- Mandalia, H.M.; Salvucci, M.D.D. Using Support Vector Machines for Lane-Change Detection. Proc. Hum. Factors Ergon. Soc. Annu. Meet. 2005, 49, 1965–1969. [Google Scholar] [CrossRef]
- Aoude, G.S.; Luders, B.D.; Lee, K.K.; Levine, D.S.; How, J.P. Threat assessment design for driver assistance system at intersections. In Proceedings of the 13th International IEEE Conference on Intelligent Transportation Systems, Funchal, Portugal, 19–22 September 2010; pp. 1855–1862. [Google Scholar]
- Laugier, C.; Paromtchik, I.E.; Perrollaz, M.; Yong, M.Y.; Yoder, J.-D.; Tay, C.; Mekhnacha, K.; Nègre, A. Probabilistic Analysis of Dynamic Scenes and Collision Risks Assessment to Improve Driving Safety. IEEE Intell. Transp. Syst. Mag. 2011, 3, 4–19. [Google Scholar] [CrossRef] [Green Version]
- Liu, P.; Kurt, A.; Ozguner, U. Trajectory prediction of a lane changing vehicle based on driver behavior estimation and classification. In Proceedings of the 17th International IEEE Conference on Intelligent Transportation Systems (ITSC), Qingdao, China, 8–11 October 2014; pp. 942–947. [Google Scholar]
- Schlechtriemen, J.; Wedel, A.; Hillenbrand, J.; Breuel, G.; Kuhnert, K.-D. A lane change detection approach using feature ranking with maximized predictive power. In Proceedings of the 2014 IEEE Intelligent Vehicles Symposium Proceedings, Dearborn, MI, USA, 8–11 June 2014; pp. 108–114. [Google Scholar]
- Deo, N.; Rangesh, A.; Trivedi, M.M. How Would Surround Vehicles Move? A Unified Framework for Maneuver Classification and Motion Prediction. IEEE Trans. Intell. Veh. 2018, 3, 129–140. [Google Scholar] [CrossRef] [Green Version]
- Bahram, M.; Hubmann, C.; Lawitzky, A.; Aeberhard, M.; Wollherr, D. A Combined Model- and Learning-Based Framework for Interaction-Aware Maneuver Prediction. IEEE Trans. Intell. Transp. Syst. 2016, 17, 1538–1550. [Google Scholar] [CrossRef]
- Lawitzky, A.; Althoff, D.; Passenberg, C.F.; Tanzmeister, G.; Wollherr, D.; Buss, M. Interactive scene prediction for auto-motive applications. In Proceedings of the 2013 IEEE Intelligent Vehicles Symposium (IV), Gold Coast, Australia, 23–26 June 2013; pp. 1028–1033. [Google Scholar]
- Schlechtriemen, J.; Wirthmueller, F.; Wedel, A.; Breuel, G.; Kuhnert, K.-D. When will it change the lane? A probabilistic regression approach for rarely occurring events. In Proceedings of the 2015 IEEE Intelligent Vehicles Symposium (IV), Seoul, Korea, 28 June–1 July 2015; pp. 1373–1379. [Google Scholar]
- Gonzalez, D.S.; Dibangoye, J.S.; Laugier, C. High-speed highway scene prediction based on driver models learned from demonstrations. In Proceedings of the 2016 IEEE 19th International Conference on Intelligent Transportation Systems (ITSC), Rio de Janeiro, Brazil, 1–4 November 2016; pp. 149–155. [Google Scholar]
- Mozaffari, S.; Al-Jarrah, O.Y.; Dianati, M.; Jennings, P.; Mouzakitis, A. Deep Learning-Based Vehicle Behavior Prediction for Autonomous Driving Applications: A Review. IEEE Trans. Intell. Transp. Syst. 2020, 1–15. [Google Scholar] [CrossRef]
- Lee, D.; Kwon, Y.P.; McMains, S.; Hedrick, J.K. Convolution neural network-based lane change intention prediction of surrounding vehicles for ACC. In Proceedings of the 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), Yokohama, Japan, 16–19 October 2017; pp. 1–6. [Google Scholar]
- Cui, H.; Radosavljevic, V.; Chou, F.-C.; Lin, T.-H.; Nguyen, T.; Huang, T.-K.; Schneider, J.; Djuric, N. Multimodal Trajectory Predictions for Autonomous Driving using Deep Convolutional Networks. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 2090–2096. [Google Scholar]
- Hoermann, S.; Bach, M.; Dietmayer, K. Dynamic Occupancy Grid Prediction for Urban Autonomous Driving: A Deep Learning Approach with Fully Automatic Labeling. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 2056–2063. [Google Scholar]
- Luo, W.; Yang, B.; Urtasun, R. Fast and Furious: Real Time End-to-End 3D Detection, Tracking and Motion Forecasting with a Single Convolutional Net. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3569–3577. [Google Scholar]
- Casas, S.; Luo, W.; Urtasun, R. Intentnet: Learning to predict intention from raw sensor data. In Proceedings of the 2nd Conference on Robot Learning, Zürich, Switzerland, 29–31 October 2018; pp. 947–956. [Google Scholar]
- Zhao, T.; Xu, Y.; Monfort, M.; Choi, W.; Baker, C.; Zhao, Y.; Wang, Y.; Wu, Y.N. Multi-Agent Tensor Fusion for Contextual Trajectory Prediction. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 12118–12126. [Google Scholar]
- Lee, N.; Choi, W.; Vernaza, P.; Choy, C.B.; Torr, P.H.S.; Chandraker, M. DESIRE: Distant Future Prediction in Dynamic Scenes with Interacting Agents. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 22–25 July 2017; pp. 2165–2174. [Google Scholar]
- Schreiber, M.; Hoermann, S.; Dietmayer, K. Long-Term Occupancy Grid Prediction Using Recurrent Neural Networks. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 9299–9305. [Google Scholar]
- Deo, N.; Trivedi, M.M. Multi-Modal Trajectory Prediction of Surrounding Vehicles with Maneuver based LSTMs. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 1179–1184. [Google Scholar]
- Tian, Y.; Pan, L. Predicting Short-Term Traffic Flow by Long Short-Term Memory Recurrent Neural Network. In Proceedings of the 2015 IEEE International Conference on Smart City/SocialCom/SustainCom (SmartCity), Chengdu, China, 19–21 December 2015; pp. 153–158. [Google Scholar] [CrossRef]
- Zambrano-Martinez, J.L.; Calafate, C.T.; Soler, D.; Lemus-Zúñiga, L.-G.; Cano, J.-C.; Manzoni, P.; Gayraud, T. A central-ized route-management solution for autonomous vehicles in urban areas. Electronics 2019, 8, 722. [Google Scholar] [CrossRef] [Green Version]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Luong, M.; Pham, H.; Manning, C.D. Effective Approaches to Attention-Based Neural Machine Translation. arXiv 2015, arXiv:1508.04025. [Google Scholar]
- Lin, L.; Li, W.; Bi, H.; Qin, L. Vehicle Trajectory Prediction Using LSTMs with Spatial-Temporal Attention Mechanisms. IEEE Intell. Transp. Syst. Mag. 2021. [Google Scholar] [CrossRef]
- Messaoud, K.; Yahiaoui, I.; Verroust-Blondet, A.; Nashashibi, F. Attention Based Vehicle Trajectory Prediction. IEEE Trans. Intell. Veh. 2021, 6, 175–185. [Google Scholar] [CrossRef]
- Kim, H.; Kim, D.; Kim, G.; Cho, J.; Huh, K. Multi-Head Attention based Probabilistic Vehicle Trajectory Prediction. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020; pp. 1720–1725. [Google Scholar]
- James Colyar, J.H. US Highway 101 Dataset; FHWA-HRT07-030; Federal Highway Administration (FHWA): Washington, DC, USA, 2007.
- James Colyar, J.H. US Highway i-80 Dataset; FHWA-HRT-06-137; Federal Highway Administration (FHWA): Washington, DC, USA, 2006.
- Yoon, Y.; Kim, T.; Lee, H.; Park, J. Road-Aware Trajectory Prediction for Autonomous Driving on Highways. Sensors 2020, 20, 4703. [Google Scholar] [CrossRef]
- Tijerina, L.; Garrott, W.; Glecker, M.; Stoltzfus, D.; Parmer, E. Van and Passenger Car Driver Eye Glance Behavior during Lane Change Decision Phase, Interim Report; Transportation Research Center Report; National Highway Transportation Safety Administration: Washington, DC, USA, 1997. [Google Scholar]
- Toledo, T.; Zohar, D. Modeling Duration of Lane Changes. Transp. Res. Rec. J. Transp. Res. Board 2007, 1999, 71–78. [Google Scholar] [CrossRef]
- Lee, S.E.; Olsen, E.C.; Wierwille, W.W. A Comprehensive Examination of Naturalistic Lane-Changes; United States; National Highway Traffic Safety Administration: Washington, DC, USA, 2004. [Google Scholar]
- Hanowski, R.J. The Impact of Local/Short Haul Operations on Driver Fatigue; Virginia Polytechnic Institute and State University: Montgomery County, MD, USA, 2000. [Google Scholar]
- Neubig, G. Neural machine translation and sequence-to-sequence models: A tutorial. arXiv 2017, arXiv:1703.01619 2017. [Google Scholar]
- Sun, C.; Shrivastava, A.; Singh, S.; Gupta, A. Revisiting unreasonable effectiveness of data in deep learning era. In Proceedings of the 16th IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 843–852. [Google Scholar]
- Sarker, I.H. Machine Learning: Algorithms, Real-World Applications and Research Directions. SN Comput. Sci. 2021, 2, 160. [Google Scholar] [CrossRef] [PubMed]
- Phillips, D.J.; Wheeler, T.A.; Kochenderfer, M.J. Generalizable intention prediction of human drivers at intersections. In Proceedings of the 2017 IEEE Intelligent Vehicles Symposium (IV), Los Angeles, CA, USA, 11–14 June 2017; pp. 1665–1670. [Google Scholar]
- Palazzi, A.; Solera, F.; Calderara, S.; Alletto, S.; Cucchiara, R. Learning where to attend like a human driver. In Proceedings of the 2017 IEEE Intelligent Vehicles Symposium (IV), Los Angeles, CA, USA, 11–14 June 2017; pp. 920–925. [Google Scholar]
- Ponziani, R.L. Turn Signal Usage Rate Results: A Comprehensive Field Study of 12,000 Observed Turning Vehicles; SAE Technical Paper; SAE International: Warrendale, PA, USA, 2012. [Google Scholar] [CrossRef]
- Faw, H.W. To signal or not to signal: That should not be the question. Accid. Anal. Prev. 2013, 59, 374–381. [Google Scholar] [CrossRef]
- Park, C.; Jeong, N.-T.; Yu, D.; Hwang, S.-H. Path Generation Algorithm Based on Crash Point Prediction for Lane Changing of Autonomous Vehicles. Int. J. Automot. Technol. 2019, 20, 507–519. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Prediction Horizon (s) | Position-Based Methods | Position + Other Features-Based Methods | ||||||
|---|---|---|---|---|---|---|---|---|
| CS-LSTM | NLS-LSTM | MHA-LSTM | MHA-LSTM(+f) | ED-LSTM | P-LSTM | ED-LSTM +CS | LS-LSTM | |
| 1 | 0.22 | 0.20 | 0.19 | 0.06 | 0.30 | 0.30 | 0.32 | 0.30 |
| 2 | 0.61 | 0.57 | 0.55 | 0.09 | 0.50 | 0.43 | 0.61 | 0.38 |
| 3 | 1.24 | 1.14 | 1.10 | 0.24 | 0.76 | 0.60 | 0.98 | 0.45 |
| 4 | 2.10 | 1.90 | 1.84 | 0.54 | 1.08 | 0.88 | 1.45 | 0.60 |
| 5 | 3.27 | 2.91 | 2.78 | 1.18 | 1.48 | 1.26 | 1.99 | 0.88 |
| Prediction Horizon (s) | Longitudinal Position | Lateral Position | ||||||
|---|---|---|---|---|---|---|---|---|
| ED-LSTM | P-LSTM | ED-LSTM +CS | LS-LSTM | ED-LSTM | P-LSTM | ED-LSTM +CS | LS-LSTM | |
| 1 | 0.25 | 0.28 | 0.31 | 0.28 | 0.18 | 0.08 | 0.09 | 0.09 |
| 2 | 0.39 | 0.40 | 0.58 | 0.36 | 0.31 | 0.15 | 0.17 | 0.13 |
| 3 | 0.62 | 0.56 | 0.95 | 0.41 | 0.44 | 0.22 | 0.26 | 0.18 |
| 4 | 0.92 | 0.83 | 1.41 | 0.54 | 0.56 | 0.30 | 0.36 | 0.25 |
| 5 | 1.32 | 1.19 | 1.94 | 0.81 | 0.67 | 0.39 | 0.46 | 0.33 |
| Prediction Horizon (s) | Scenario 1 | Scenario 2 | Scenario 3 | |||
|---|---|---|---|---|---|---|
| P-LSTM (Long, Lat) | LS-LSTM (Long, Lat) | LS-LSTM w/o Linearization | LS-LSTM w/ Linearization | LS-LSTM w/o Linearization | LS-LSTM w/ Linearization | |
| 1 | 0.35, 0.09 | 0.37, 0.07 | 0.84, 0.39 | 0.80, 0.06 | 0.67, 0.48 | 0.73, 0.07 |
| 2 | 0.60, 0.15 | 0.68, 0.12 | 1.21, 1.47 | 1.02, 0.10 | 1.10, 1.75 | 1.14, 0.13 |
| 3 | 0.80, 0.20 | 0.75, 0.16 | 1.65, 3.12 | 1.37, 0.11 | 1.45, 3.69 | 1.54, 0.16 |
| 4 | 1.12, 0.24 | 0.83, 0.18 | 2.28, 5.28 | 1.54, 0.13 | 2.17, 6.26 | 1.83, 0.19 |
| 5 | 1.50, 0.28 | 0.91, 0.20 | 3.56, 7.87 | 1.96, 0.13 | 3.35, 9.37 | 2.31, 0.22 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, D.; Lee, H.; Kim, T.; Hwang, S.-H. Vehicle Trajectory Prediction with Lane Stream Attention-Based LSTMs and Road Geometry Linearization. Sensors 2021, 21, 8152. https://doi.org/10.3390/s21238152
Yu D, Lee H, Kim T, Hwang S-H. Vehicle Trajectory Prediction with Lane Stream Attention-Based LSTMs and Road Geometry Linearization. Sensors. 2021; 21(23):8152. https://doi.org/10.3390/s21238152
Chicago/Turabian StyleYu, Dongyeon, Honggyu Lee, Taehoon Kim, and Sung-Ho Hwang. 2021. "Vehicle Trajectory Prediction with Lane Stream Attention-Based LSTMs and Road Geometry Linearization" Sensors 21, no. 23: 8152. https://doi.org/10.3390/s21238152