
3D Vehicle Trajectory Extraction Using DCNN in an Overlapping Multi-Camera Crossroad Scene


Abstract
:1. Introduction
2. Materials and Methodology
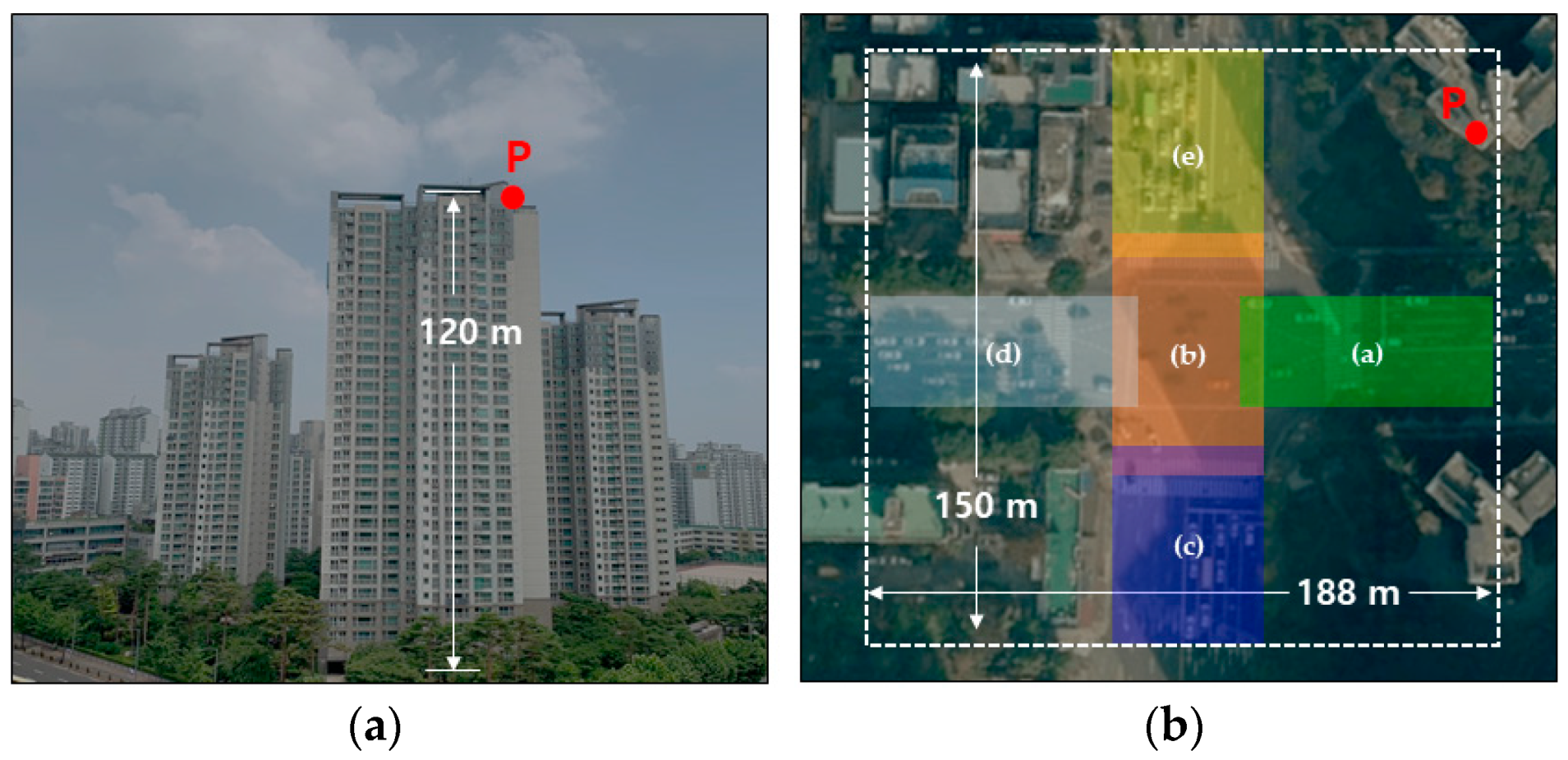
2.1. Data Collection from Heavy Traffic Flow
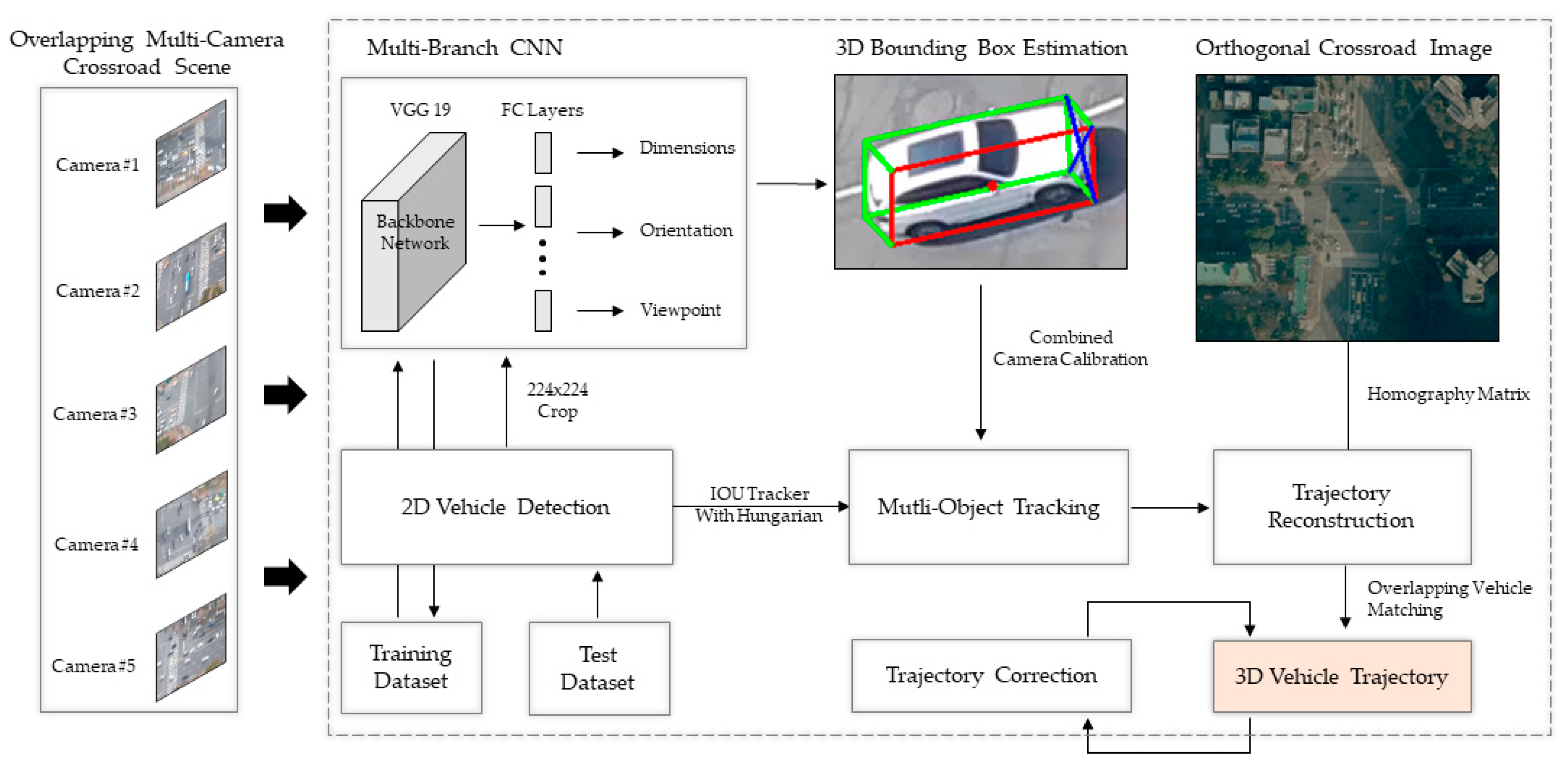
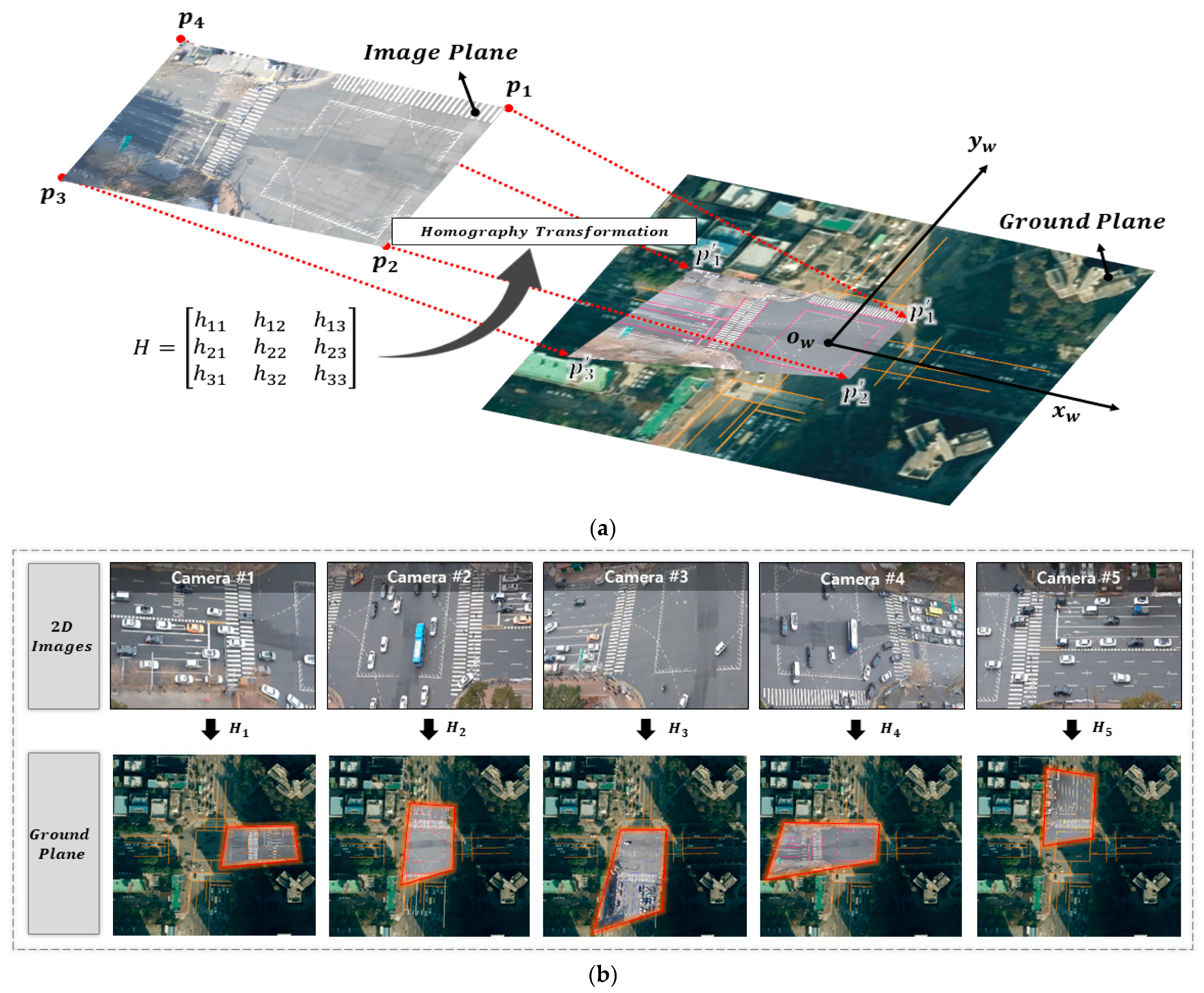
2.2. Framework
2.2.1. 2D Vehicle Detection and Multi-Object Tracking
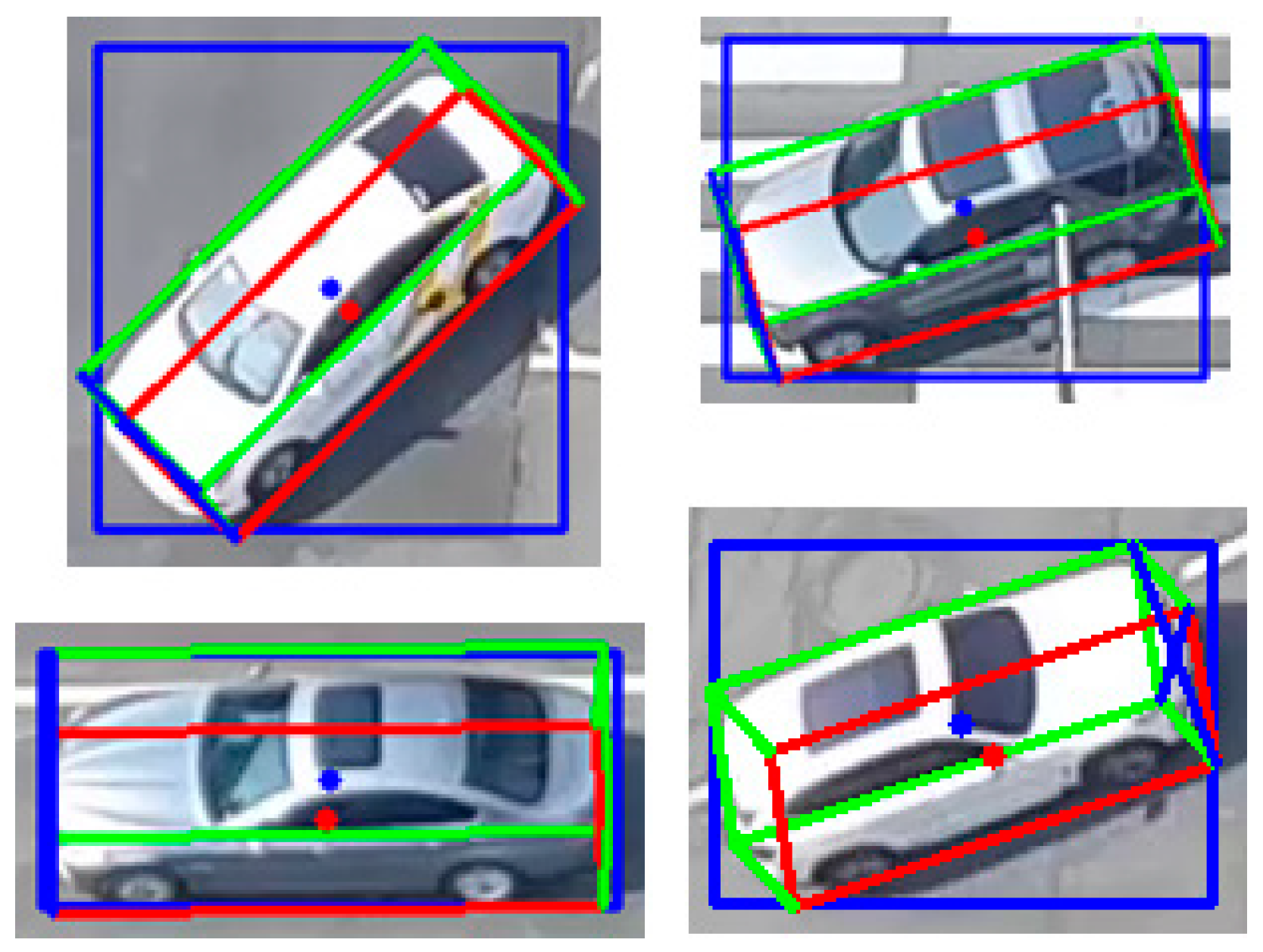
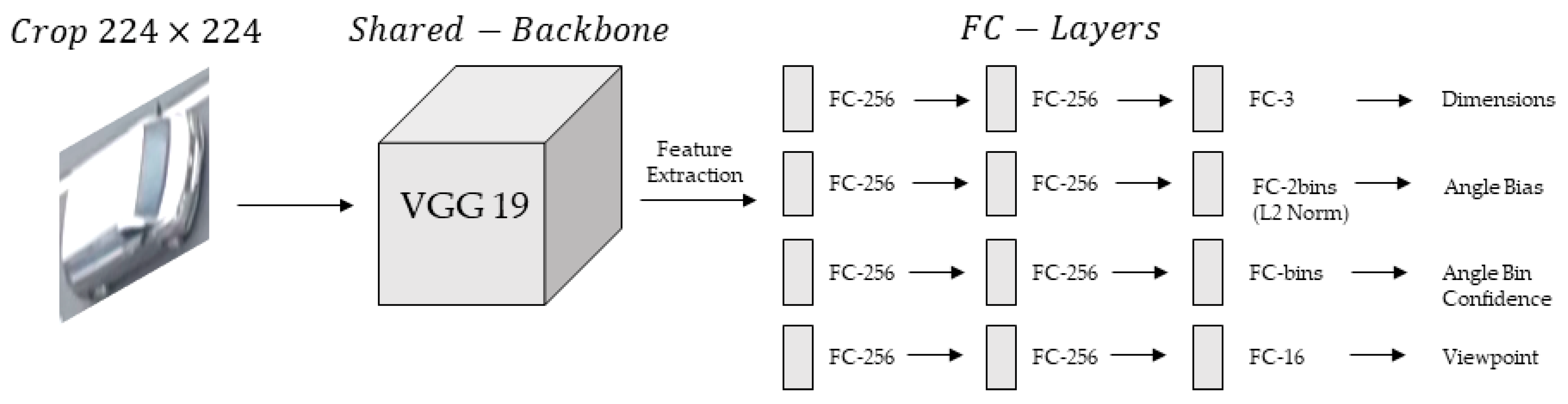
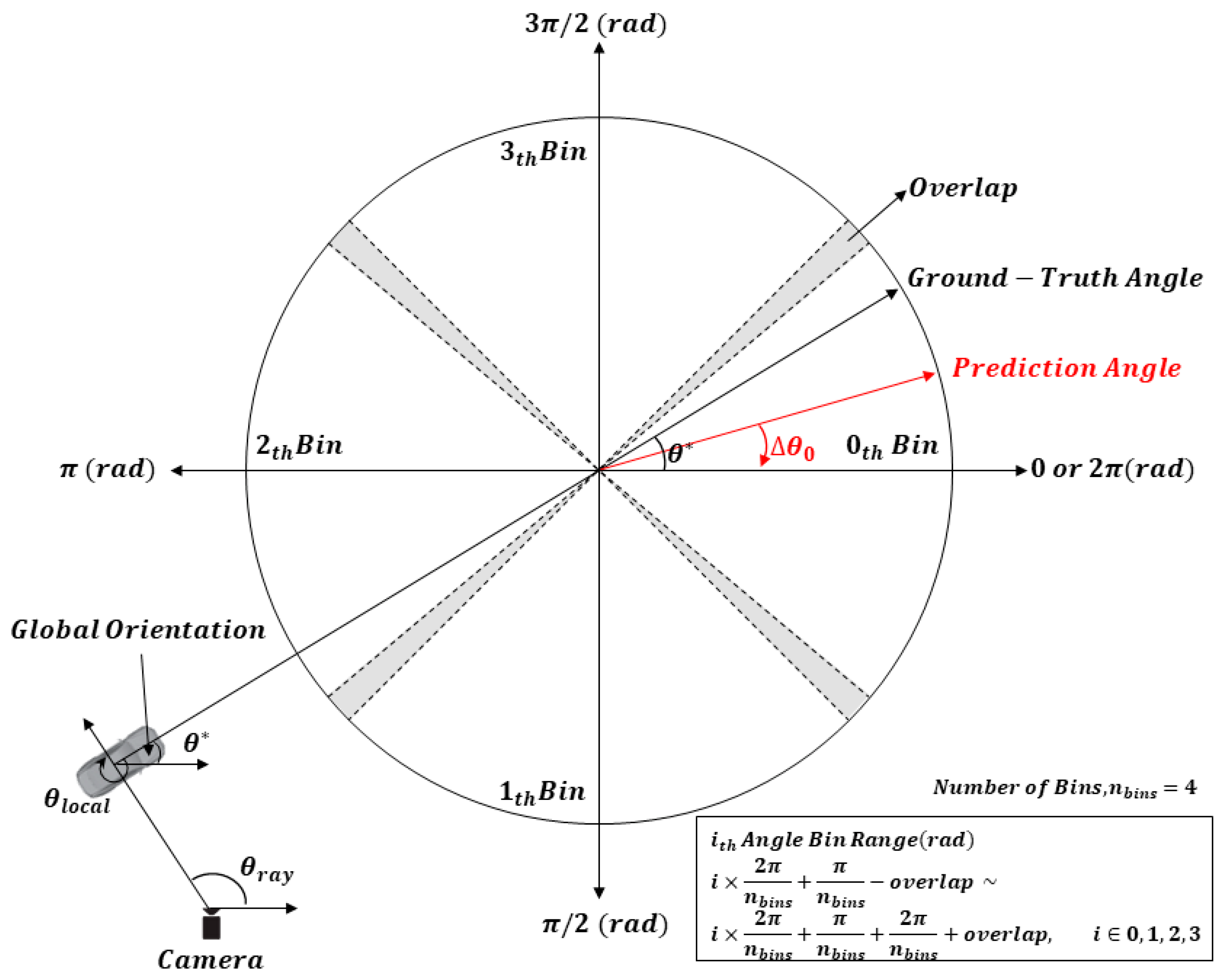
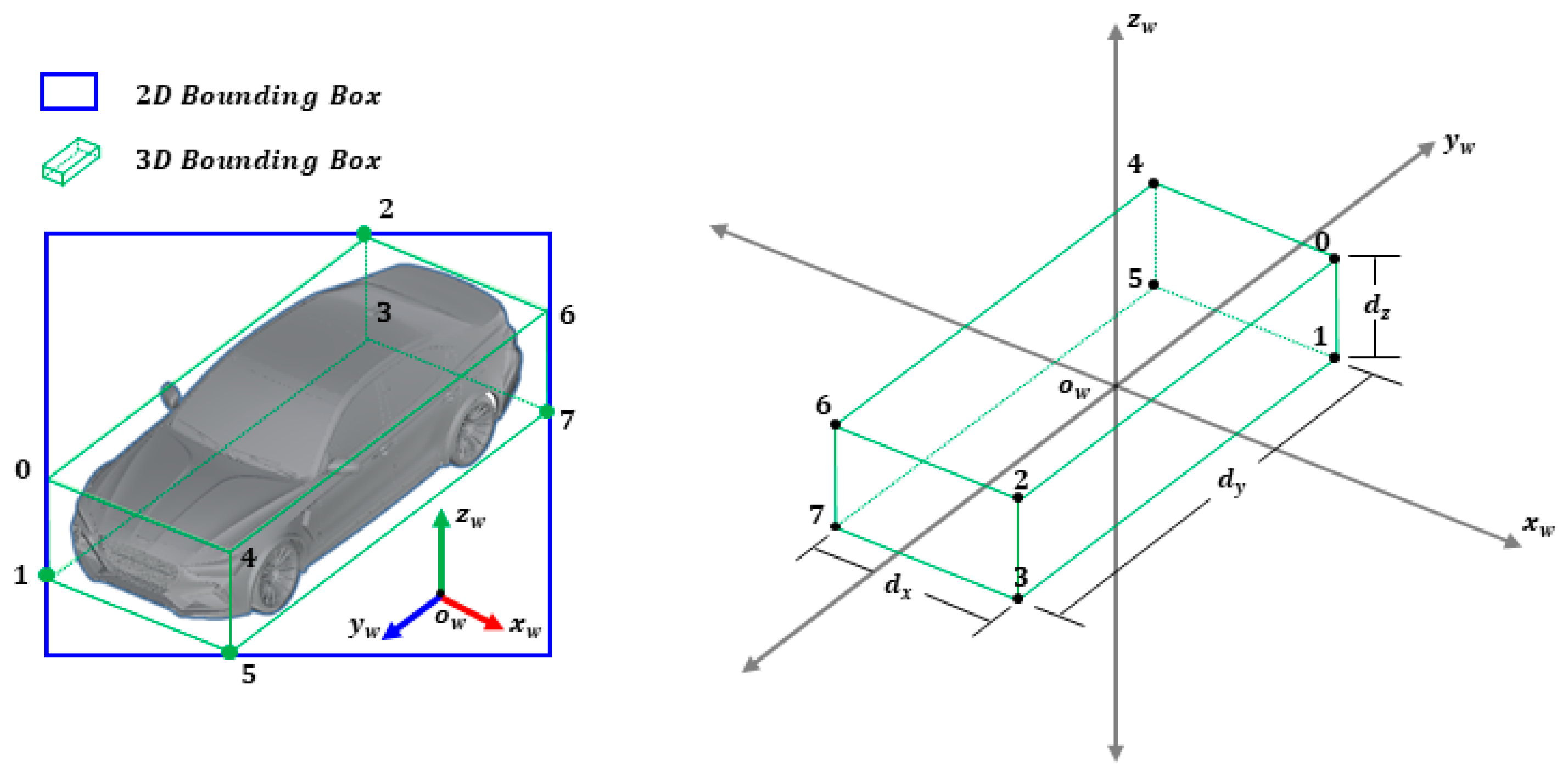
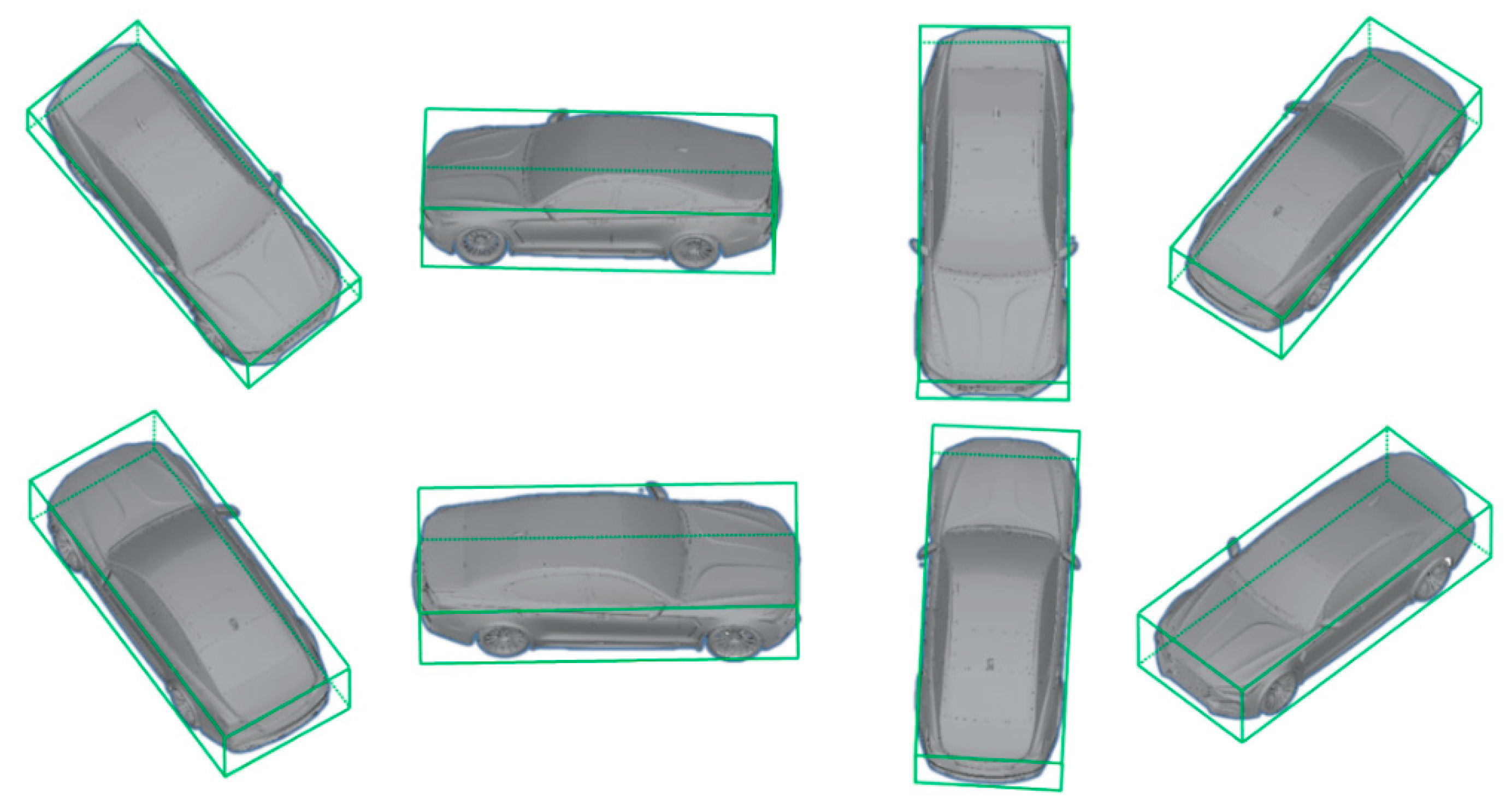
2.2.2. 3D Bounding Box Estimation Using Multi-Branch CNN
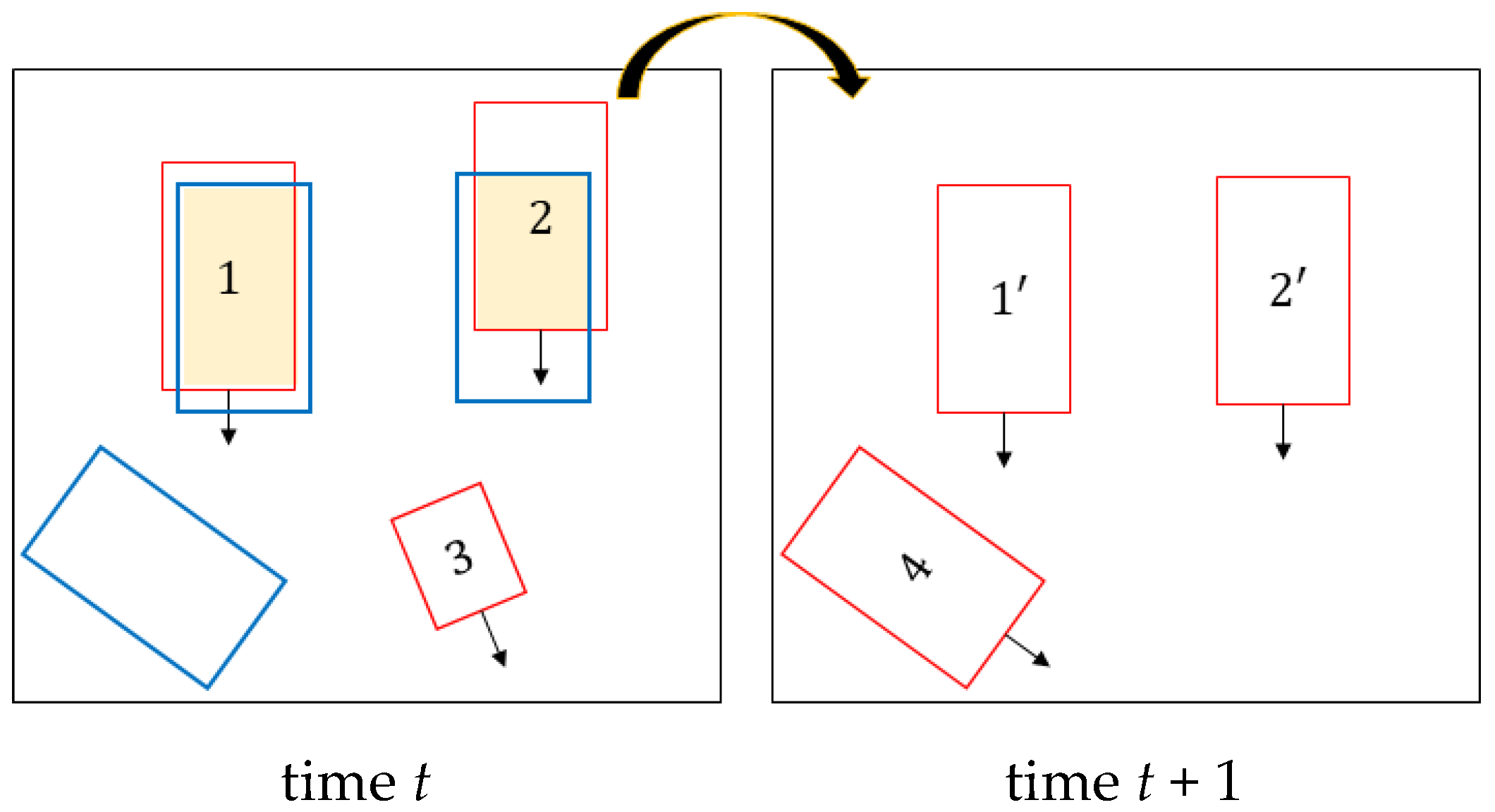
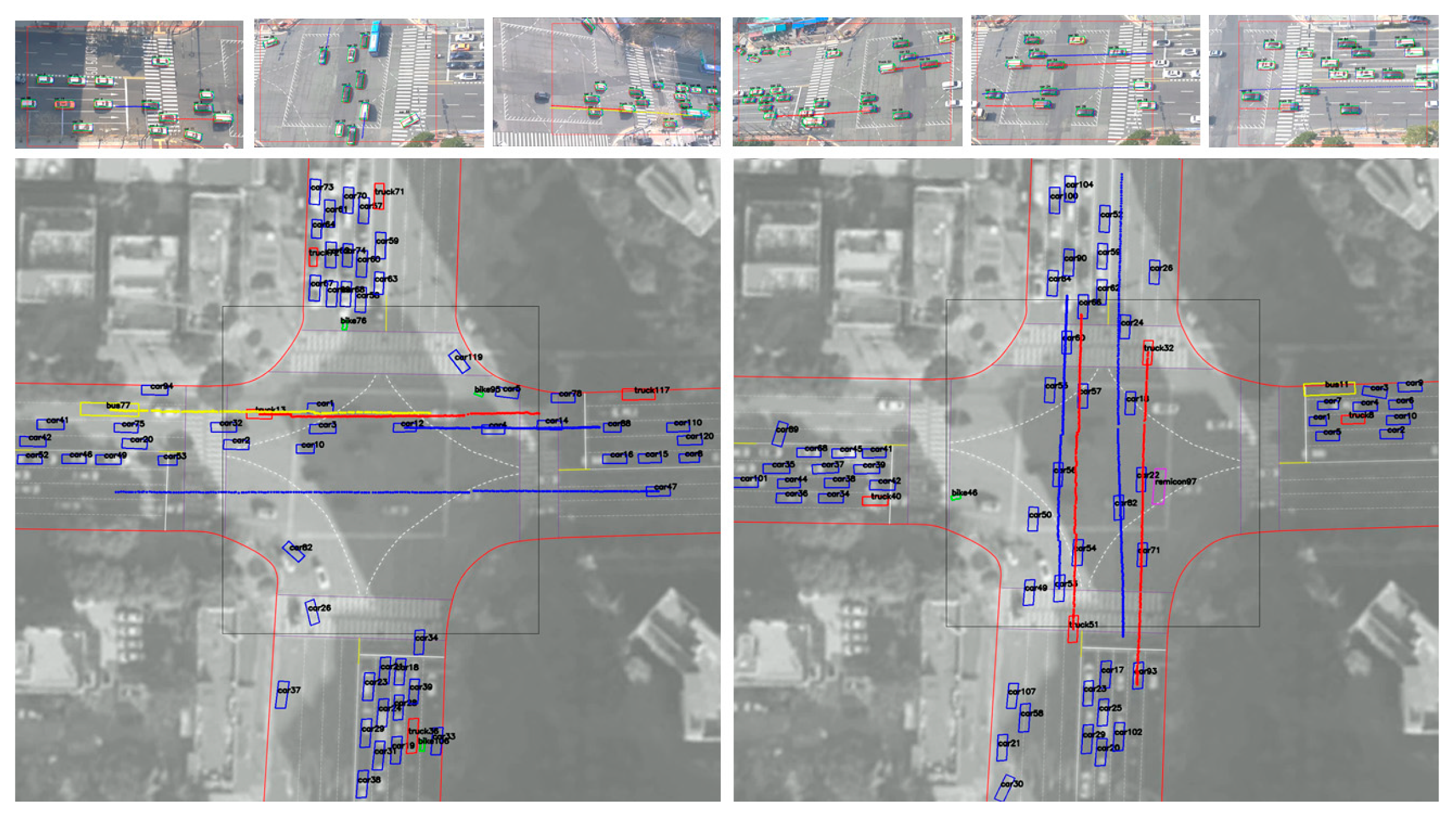
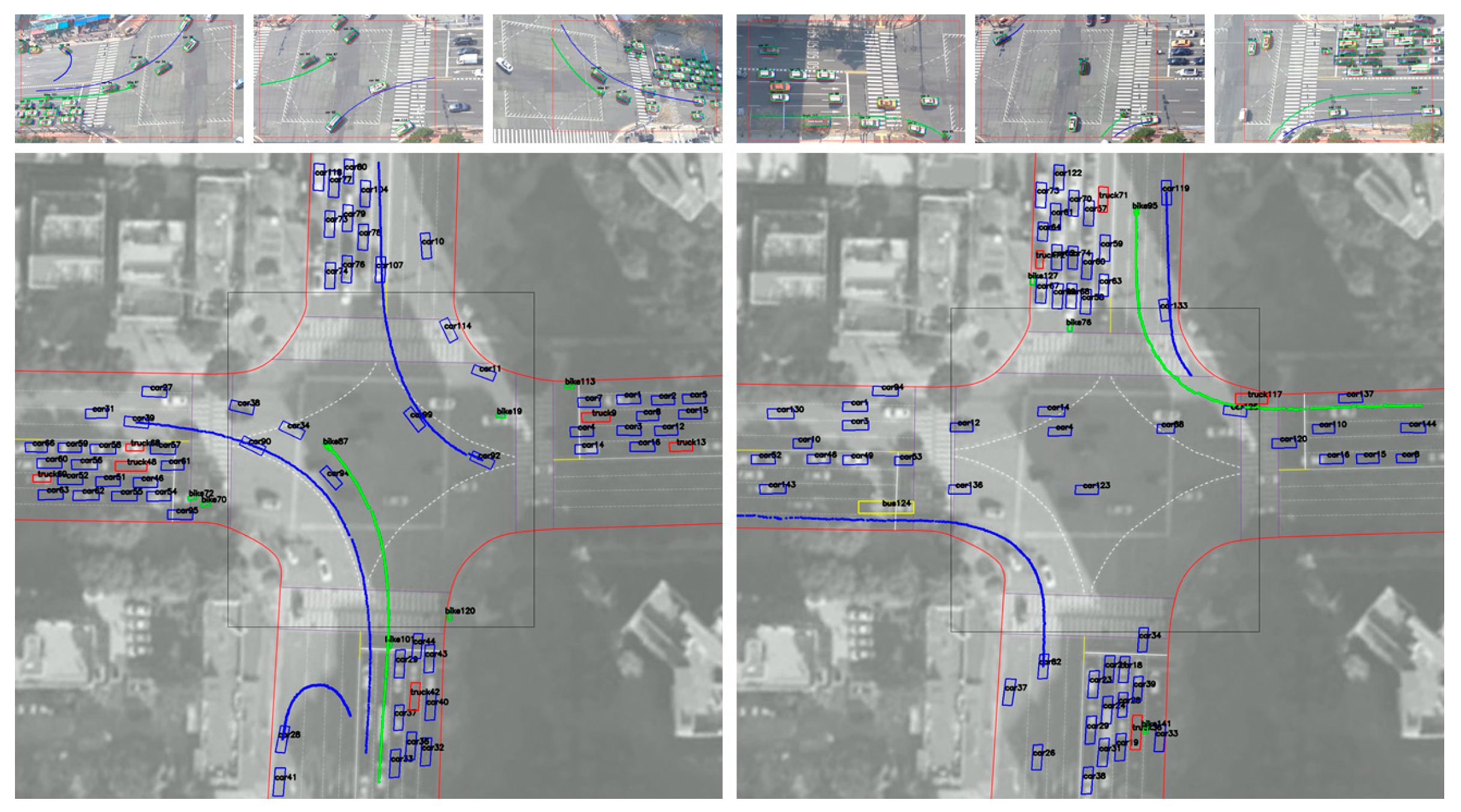
2.2.3. Trajectory Reconstruction and Overlapping Vehicle Matching
| Algorithm 1. Overlapping vehicle matching on the ground plane |
| Input: , set of all trackers in overlapping area. |
| Input:d, minimum distance to determine if it is the same object. |
| Output: O, set of trackers remaining after removing duplicate ID in overlapping area. |
| //v is a custom class and contains ID, camera type, and age attributes. |
| //. |
| //. |
| //. |
| if then |
| for all do |
| if |
| if then //Center is the intersection. |
| continue |
| else |
| ID of |
| for each s in S |
| //Remove trackers with duplicate ID |
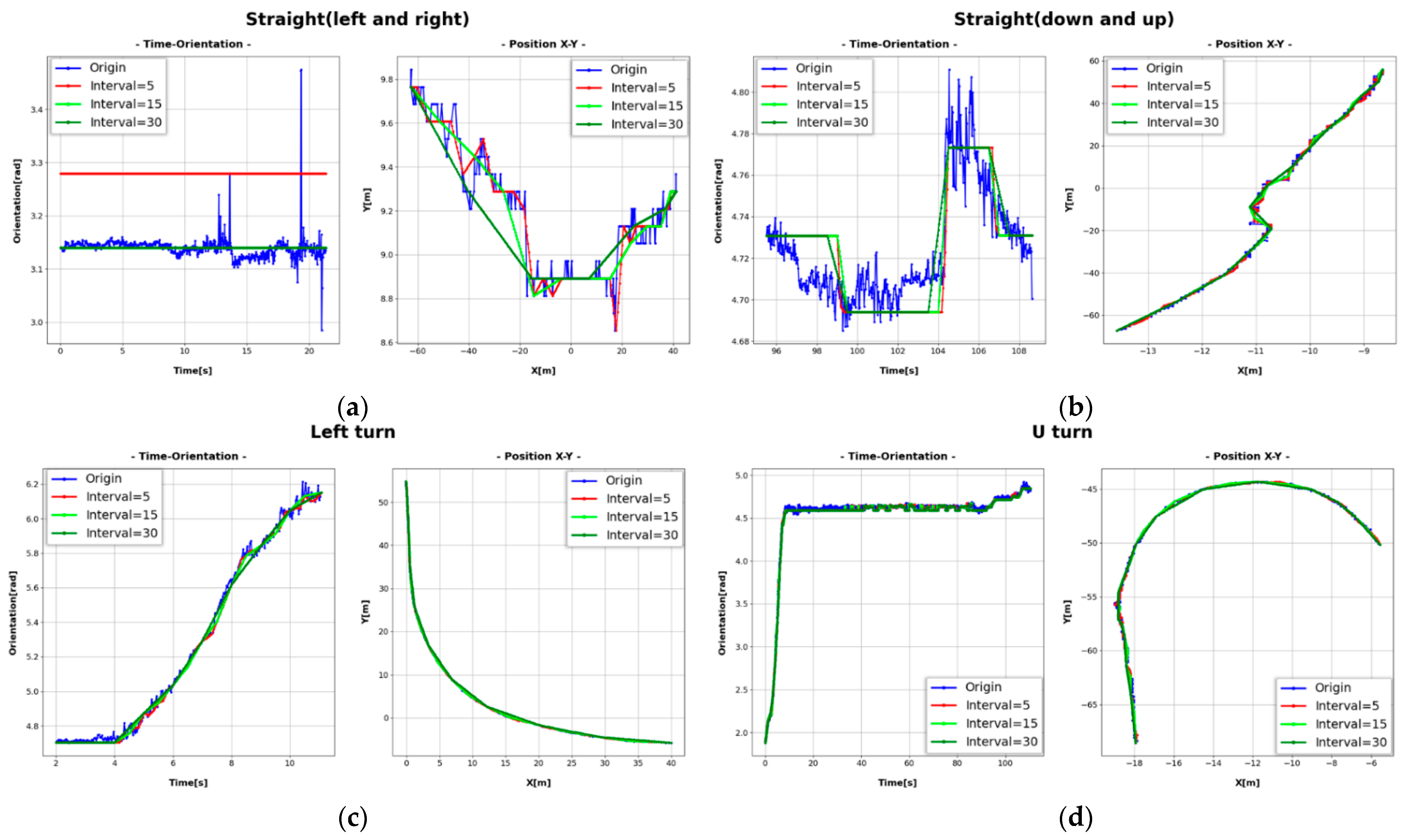
2.2.4. Vehicle Trajectory Correction
| Algorithm 2. Trajectory correction using linear regression and interpolation |
| Input: , set of all trajectories of vehicles included position, orientation. |
| Input: σ, orientation threshold at which the vehicle can turn for time Δt. |
| Input: β, position threshold at which the vehicle can move for time Δt. |
| Input: γ, interval frames to interpolate. |
| for all do |
| //Set of position trajectories x of |
| //Set of position trajectories y of |
| //Set of orientation trajectories of |
| for all do//Remove outliers |
| if then |
| if then |
| for interval do//Interpolation through Linear Regression |
| Calculate the linear equation for on the interval to |
| for to about |
| depends on the orientation or Y–X |
3. Experiments and Results
3.1. Dataset Labeling and Training Results
3.2. 3D Vehicle Trajectory Extraction and Result Analysis
4. Conclusions
- A method for estimating 3D bounding boxes of vehicles through YOLOv4, MOT, and multi-branch CNN is proposed on the basis of camera calibration and correspondence constraints.
- A method of processing trajectory reconstruction and vehicle matching to obtain a continuous 3D vehicle trajectory in a multi-camera crossroad scene is proposed.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, Y. Big Data Technology and its Analysis of Application in Urban Intelligent Transportation System. In Proceedings of the International Conference on Intelligent Transportation—Big Data Smart City, Xiamen, China, 25–26 January 2018; pp. 17–19. [Google Scholar]
- Sreekumar, U.K.; Devaraj, R.; Li, Q.; Liu, K. Real-Time Traffic Pattern Collection and Analysis Model for Intelligent Traffic Intersection. In Proceedings of the 2018 IEEE International Conference on Edge Computing (EDGE), San Francisco, CA, USA, 2–7 July 2018; pp. 140–143. [Google Scholar] [CrossRef]
- Tsuboi, T.; Yoshikawa, N. Traffic Flow Analysis in Ahmedabad (India). Case Stud. Transp. Policy 2019, 8, 215–228. [Google Scholar] [CrossRef]
- Špaňhel, J.; Juránek, R.; Herout, A.; Novák, J.; Havránek, P. Analysis of Vehicle Trajectories for Determining Cross-Sectional Load Density Based on Computer Vision. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 1001–1006. [Google Scholar]
- Hiribarren, G.; Herrera, J.C. Real time traffic states estimation on arterials based on trajectory data. Transp. Res. Part B-Methodol. 2014, 69, 19–30. [Google Scholar] [CrossRef]
- Yu, L.; Zhang, D.; Chen, X.; Hauptmann, A. Traffic Danger Recognition with Surveillance Cameras without Training Data. In Proceedings of the 2018 15th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Auckland, New Zealand, 27–30 November 2018; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Maaloul, B. Video-Based Algorithms for Accident Detections. Data Structures and Algorithms [cs.DS]. Ph.D. Thesis, Université de Valenciennes et du Hainaut-Cambresis, Valenciennes, France, Université de Mons, Mons, Belgium, 2018. [Google Scholar]
- Chen, Z.; Wu, C.; Huang, Z.; Lyu, N.; Hu, Z.; Zhong, M.; Cheng, Y.; Ran, B. Dangerous driving behavior detection using video-extracted vehicle trajectory histograms. J. Intell. Transp. Syst. 2017, 21, 409–421. [Google Scholar] [CrossRef]
- Jahagirdar, S.; Koli, S. Automatic Accident Detection Techniques using CCTV Surveillance Videos: Methods, Data sets and Learning Strategies. Int. J. Eng. Adv. Technol. (IJEAT) 2020, 9, 2249–8958. [Google Scholar] [CrossRef]
- Maha Vishnu, V.C.; Rajalakshmi, M.; Nedunchezhian, R. Intelligent traffic video surveillance and accident detection system with dynamic traffic signal control. Clust. Comput. 2018, 21, 135–147. [Google Scholar] [CrossRef]
- Ma, Y.; Meng, H.; Chen, S.; Zhao, J.; Li, S.; Xiang, Q. Predicting Traffic Conflicts for Expressway Diverging Areas Using Vehicle Trajectory Data. J. Transp. Eng. 2020, 146, 04020003. [Google Scholar] [CrossRef]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple online and realtime tracking. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3464–3468. [Google Scholar]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar]
- Baek, M.; Jeong, D.; Choi, D.; Lee, S. Vehicle Trajectory Prediction and Collision Warning via Fusion of Multisensors and Wireless Vehicular Communications. Sensors 2020, 20, 288. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Zhang, D.; Yang, X.; Hou, X. Traffic accident reconstruction based on occupant trajectories and trace identification. ASME J. Risk Uncertain. Part B 2019, 5, 20903–20914. [Google Scholar]
- Seong, S.; Song, J.; Yoon, D.; Kim, J.; Choi, J. Determination of Vehicle Trajectory through Optimization of Vehicle Bounding Boxes using a Convolutional Neural Network. Sensors 2019, 19, 4263. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kocur, V.; Ftáčnik, M. Detection of 3D Bounding Boxes of Vehicles Using Perspective Transformation for Accurate Speed Measurement. arXiv 2020, arXiv:2003.13137. [Google Scholar] [CrossRef]
- Peng, J.; Shen, T.; Wang, Y.; Zhao, T.; Zhang, J.; Fu, X. Continuous Vehicle Detection and Tracking for Non-overlapping Multi-camera Surveillance System. In Proceedings of the International Conference on Internet Multimedia Computing and Service, Xi’an, China, 19–21 August 2016; pp. 122–125. [Google Scholar]
- Castañeda, J.N.; Jelaca, V.; Frías, A.; Pizurica, A.; Philips, W.; Cabrera, R.R.; Tuytelaars, T. Non-Overlapping Multi-camera Detection and Tracking of Vehicles in Tunnel Surveillance. In Proceedings of the 2011 International Conference on Digital Image Computing: Techniques and Applications, Noosa, QLD, Australia, 6–8 December 2011; pp. 591–596. [Google Scholar] [CrossRef] [Green Version]
- Tang, X.; Song, H.; Wang, W.; Yang, Y. Vehicle Spatial Distribution and 3D Trajectory Extraction Algorithm in a Cross-Camera Traffic Scene. Sensors 2020, 20, 6517. [Google Scholar] [CrossRef]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object Detection with Discriminatively Trained Part-Based Models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1627–1645. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R.; Darrell, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the CVPR, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the 2015 28th International Conference on Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the 2016 European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Kuhn, H.W. The Hungarian method for the assignment problem. Nav. Res. Logist. Q. 1955, 2, 83–97. [Google Scholar] [CrossRef] [Green Version]
- Lingtao, Z.; Jiaojiao, F.; Guizhong, L. Object Viewpoint Classification Based 3D Bounding Box Estimation for Autonomous Vehicles. arXiv 2019, arXiv:1909.01025. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The KITTI vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar] [CrossRef]
- Sochor, J.; Juránek, R.; Špaňhel, J.; Maršík, L.; Široký, A.; Herout, A.; Zemčík, P. Comprehensive Data Set for Automatic Single Camera Visual Speed Measurement. IEEE Trans. Intell. Transp. Syst. 2018, 20, 1633–1643. [Google Scholar] [CrossRef] [Green Version]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Vehicle Orientation | Vehicle Position | Continuous 3D Trajectory | Multi-Camera Scene | Straight Road | Crossroad |
|---|---|---|---|---|---|---|
| Seong et al. [16] | X | O | O | X | O | O |
| Kocur et al. [17] | O | O | O | X | O | X |
| Peng et al. [18] | X | O | X | X | O | O |
| Castaneda et al. [19] | X | X | X | O | O | X |
| Tang et al. [20] | O | O | O | O | O | X |
| Our method | O | O | O | O | O | O |
| Number | World Coordinate |
|---|---|
| 0 | ( |
| 1 | ( |
| 2 | ( |
| 3 | ( |
| 4 | ( |
| 5 | ( |
| 6 | ( |
| 7 | ( |
| Our Method | AOS | RMSE (x) | RMSE (y) |
|---|---|---|---|
| Origin | 79.6% (±54°) | 29.1 cm | 26.5 cm |
| Interval = 5 frames | 99.2% (±10°) | 19.5 cm | 23.1 cm |
| Interval = 15 frames | 99.8% (±5°) | 12.9 cm | 15.2 cm |
| Interval = 30 frames | 98.5% (±12°) | 26.7 cm | 30.5 cm |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Heo, J.; Kwon, Y. 3D Vehicle Trajectory Extraction Using DCNN in an Overlapping Multi-Camera Crossroad Scene. Sensors 2021, 21, 7879. https://doi.org/10.3390/s21237879
Heo J, Kwon Y. 3D Vehicle Trajectory Extraction Using DCNN in an Overlapping Multi-Camera Crossroad Scene. Sensors. 2021; 21(23):7879. https://doi.org/10.3390/s21237879
Chicago/Turabian StyleHeo, Jinyeong, and Yongjin (James) Kwon. 2021. "3D Vehicle Trajectory Extraction Using DCNN in an Overlapping Multi-Camera Crossroad Scene" Sensors 21, no. 23: 7879. https://doi.org/10.3390/s21237879