
Spherically Stratified Point Projection: Feature Image Generation for Object Classification Using 3D LiDAR Data


Abstract
:1. Introduction
- We propose a feature-image descriptor, which includes geometric information, based on only 3D points collected through a LiDAR sensor;
- The generated feature images include distribution information such as the location, distance, and density of surrounding points near a target point;
- The proposed feature-image-generation method is applicable to all 3D point clouds and enables pointwise classification through the popular image classifiers such as the CNN model;
- The proposed sP method was validated through learning based on the feature-image-generation method, and image-classification networks are evaluated on the KNU and KITTI datasets.
2. Spherically Stratified Point Projection
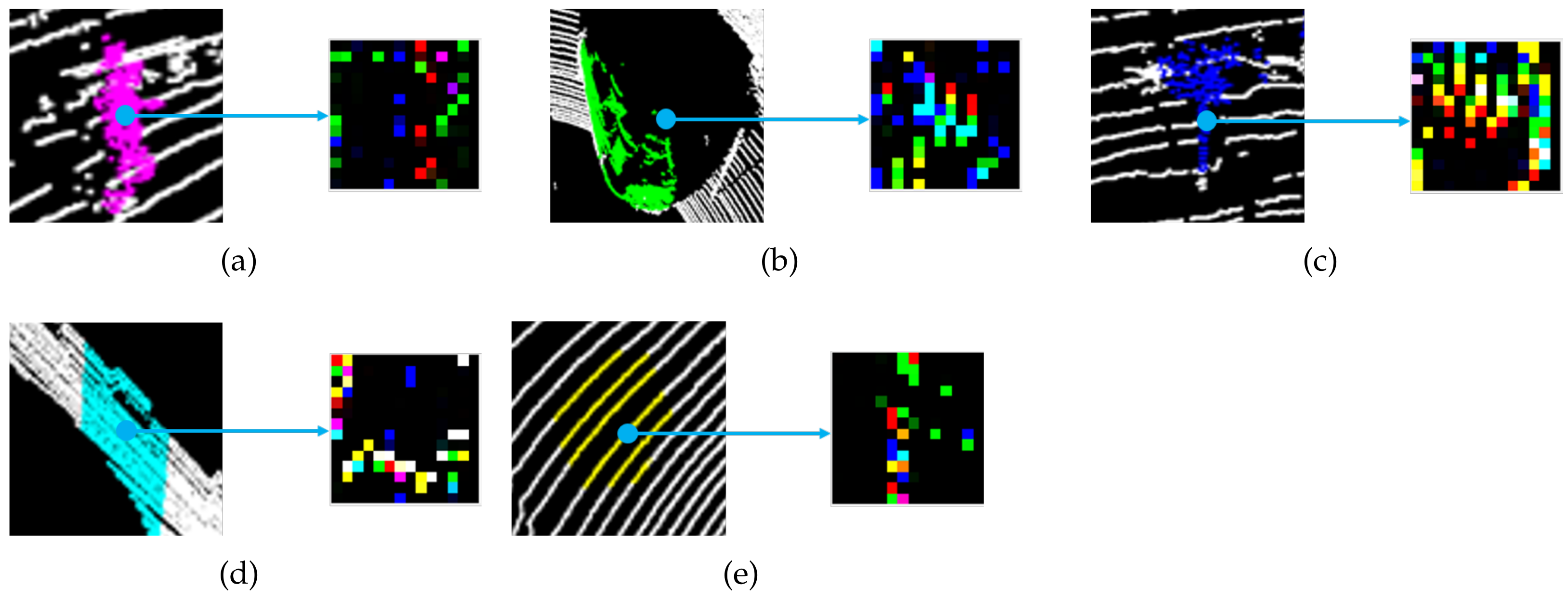
2.1. Image Descriptor
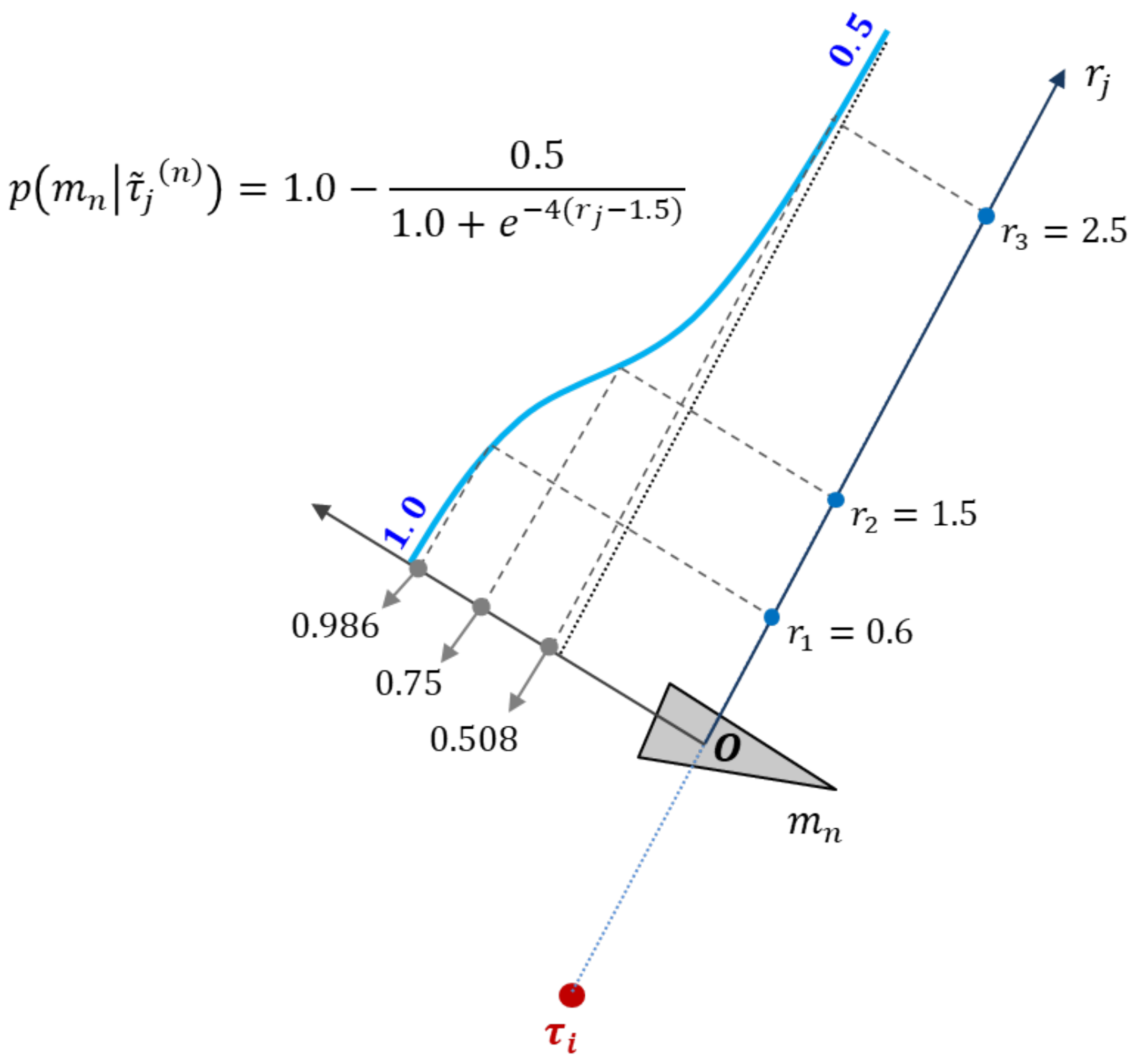
2.2. Occupancy Grid Update
2.3. Image Generation
| Algorithm 1:sP image generation. |
Input: (), , , ▹() represents the coordinates of n point clouds collected from LiDAR ▹, , and are the grid information corresponding to layers R, G, and B Output: sP image with dimensions of corresponding to Parameters: , , ▹, , and are the spherical radii demarcating the three layers
|
3. Experimental Evaluation
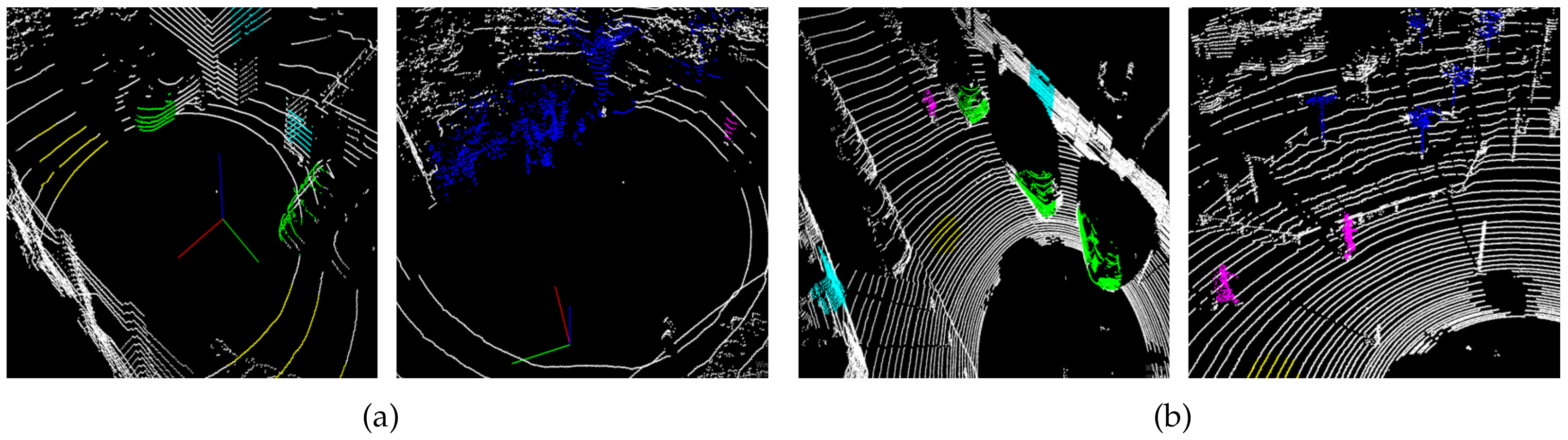
3.1. Datasets and Training Setup
3.2. Classification Performance
3.3. Raw 3D Point Cloud Classification
4. Conclusions and Further Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| sP | Spherically stratified point projection |
| LiDAR | Light detection and ranging |
| CNN | Convolutional neural network |
| RANSAC | Random sample consensus |
| IMU | Inertial measurement Unit |
| SSD | Spherical signature descriptor |
| MSSD | Modified spherical signature descriptor |
| IoU | Intersection over union |
References
- Grigorescu, S.; Trasnea, B.; Cocias, T.; Macesanu, G. A survey of deep learning techniques for autonomous driving. J. Field Rob. 2020, 37, 362–386. [Google Scholar] [CrossRef]
- Mozaffari, S.; Al-Jarrah, O.Y.; Dianati, M.; Jennings, P.; Mouzakitis, A. Deep learning-based vehicle behavior prediction for autonomous driving applications: A review. IEEE Trans. Intell. Transp. Syst. 2020. [Google Scholar] [CrossRef]
- Ben-Shabat, Y.; Lindenbaum, M.; Fischer, A. 3DMFV: Three-dimensional point cloud classification in real-time using convolutional neural networks. IEEE Rob. Autom. Lett. 2018, 3, 3145–3152. [Google Scholar] [CrossRef]
- Uçar, A.; Demir, Y.; Güzeliş, C. Object recognition and detection with deep learning for autonomous driving applications. Simulation 2017, 93, 759–769. [Google Scholar] [CrossRef]
- Weon, I.S.; Lee, S.G.; Ryu, J.K. Object recognition based interpolation With 3D LIDAR and vision for autonomous driving of an intelligent vehicle. IEEE Access 2020, 8, 65599–65608. [Google Scholar] [CrossRef]
- Wen, Z.; Liu, D.; Liu, X.; Zhong, L.; Lv, Y.; Jia, Y. Deep learning based smart radar vision system for object recognition. J. Ambient Intell. Hum. Comput. 2019, 10, 829–839. [Google Scholar] [CrossRef]
- Han, X.; Laga, H.; Bennamoun, M. Image-based 3D object reconstruction: State-of-the-art and trends in the deep learning era. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 1578–1604. [Google Scholar] [CrossRef] [Green Version]
- Kim, E.S.; Park, S.Y. Extrinsic calibration between camera and LiDAR sensors by matching multiple 3D planes. Sensors 2020, 20, 52. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Ma, L.; Zhong, Z.; Liu, F.; Chapman, M.A.; Cao, D.; Li, J. Deep learning for LiDAR point clouds in autonomous driving: A review. IEEE Trans. Neural Networks Learn. Syst. 2020, 32, 3412–3432. [Google Scholar] [CrossRef]
- Song, W.; Zhang, L.; Tian, Y.; Fong, S.; Liu, J.; Gozho, A. CNN-based 3D object classification using Hough space of LiDAR point clouds. Hum.-Cent. Comput. Inf. 2020, 10, 1–14. [Google Scholar] [CrossRef]
- Hartling, S.; Sagan, V.; Sidike, P.; Maimaitijiang, M.; Carron, J. Urban tree species classification using a WorldView-2/3 and LiDAR data fusion approach and deep learning. Sensors 2019, 19, 1284. [Google Scholar] [CrossRef] [Green Version]
- Wang, F.; Jiang, M.; Qian, C.; Yang, S.; Li, C.; Zhang, H.; Wang, X.; Tang, X. Residual attention network for image classification. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3156–3164. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Maturana, D.; Scherer, S. Voxnet: A 3d convolutional neural network for real-time object recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 922–928. [Google Scholar]
- Zermas, D.; Izzat, I.; Papanikolopoulos, N. Fast segmentation of 3d point clouds: A paradigm on lidar data for autonomous vehicle applications. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Marina Bay Sands, Singapore, 29 May–3 June 2017; pp. 5067–5073. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3D classification and segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. arXiv 2017, arXiv:1706.02413. [Google Scholar]
- Huang, J.; You, S. Point cloud labeling using 3D convolutional neural network. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 2670–2675. [Google Scholar]
- Wang, C.; Cheng, M.; Sohel, F.; Bennamoun, M.; Li, J. NormalNet: A voxel-based CNN for 3D object classification and retrieval. Neurocomputing 2019, 323, 139–147. [Google Scholar] [CrossRef]
- Safaie, A.H.; Rastiveis, H.; Shams, A.; Sarasua, W.A.; Li, J. Automated street tree inventory using mobile LiDAR point clouds based on Hough transform and active contours. ISPRS J. Photogramm. Remote Sens. 2021, 174, 19–34. [Google Scholar] [CrossRef]
- Tian, Y.; Song, W.; Chen, L.; Sung, Y.; Kwak, J.; Sun, S. Fast planar detection system using a GPU-based 3D Hough transform for LiDAR point clouds. Appl. Sci. 2020, 10, 1744. [Google Scholar] [CrossRef] [Green Version]
- Behley, J.; Garbade, M.; Milioto, A.; Quenzel, J.; Behnke, S.; Stachniss, C.; Gall, J. Semantickitti: A dataset for semantic scene understanding of LiDAR sequences. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 9297–9307. [Google Scholar]
- Tang, H.; Liu, Z.; Zhao, S.; Lin, Y.; Lin, J.; Wang, H.; Han, S. Searching efficient 3D architectures with sparse point-voxel convolution. In Proceedings of the 2020 European Conference on Computer Vision (ECCV), Virtual Conference, 23–28 August 2020; pp. 685–702. [Google Scholar]
- Zhou, H.; Zhu, X.; Song, X.; Ma, Y.; Wang, Z.; Li, H.; Lin, D. Cylinder3D: An effective 3D framework for driving-scene LiDAR semantic segmentation. arXiv 2020, arXiv:2008.01550. [Google Scholar]
- Xu, J.; Zhang, R.; Dou, J.; Zhu, Y.; Sun, J.; Pu, S. RPVNet: A deep and ffficient range-point-voxel fusion network for LiDAR point cloud segmentation. arXiv 2021, arXiv:2103.12978. [Google Scholar]
- Cortinhal, T.; Tzelepis, G.; Aksoy, E.E. SalsaNext: Fast, uncertainty-aware semantic segmentation of LiDAR point clouds for autonomous driving. arXiv 2020, arXiv:2003.03653. [Google Scholar]
- Aksoy, E.E.; Baci, S.; Cavdar, S. SalsaNet: Fast road and vehicle segmentation in lidar point clouds for autonomous driving. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 23–26 June 2020; pp. 926–932. [Google Scholar]
- Koppula, H.S.; Anand, A.; Joachims, T.; Saxena, A. Semantic labeling of 3D point clouds for indoor scenes. In Proceedings of the Conference on Neural Information Processing Systems (NIPS), Granada, Spain, 12–17 December 2011; pp. 244–252. [Google Scholar]
- Wu, B.; Zhou, X.; Zhao, S.; Yue, X.; Keutzer, K. Squeezesegv2: Improved model structure and unsupervised domain adaptation for road-object segmentation from a lidar point cloud. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 4376–4382. [Google Scholar]
- Wu, B.; Wan, A.; Yue, X.; Keutzer, K. Squeezeseg: Convolutional neural nets with recurrent crf for real-time road-object segmentation from 3d lidar point cloud. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 1887–1893. [Google Scholar]
- Wang, Y.; Shi, T.; Yun, P.; Tai, L.; Liu, M. Pointseg: Real-time semantic segmentation based on 3D lidar point cloud. arXiv 2018, arXiv:1807.06288. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Conference on Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The KITTI vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Jaffray, J.Y. Bayesian updating and belief functions. IEEE Trans. Syst. Man Cybern. 1992, 22, 1144–1152. [Google Scholar] [CrossRef]
- Lee, S.; Kim, D. Spherical signature description of 3D point cloud and environmental feature learning based on deep belief nets for urban structure classification. J. Korea Robot. Soc. 2016, 11, 115–126. [Google Scholar] [CrossRef]
- Bae, C.H.; Lee, S. A study of 3D point cloud classification of urban structures based on spherical signature descriptor using LiDAR sensor data. Trans. Korean Soc. Mech. Eng. A 2019, 43, 85–91. [Google Scholar] [CrossRef]
- Xu, C.; Wu, B.; Wang, Z.; Zhan, W.; Vajda, P.; Keutzer, K.; Tomizuka, M. SqueezeSegV3: Spatially-adaptive convolution for efficient point-cloud segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 1–19. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Person | Car | Tree | Building | Floor |
|---|---|---|---|---|---|
| SSD [37] | - | 90.1% | 83.6% | 91.7% | 95.1% |
| MSSD [38] | 88.2% | 82.25% | 90.65% | 86.15% | - |
| sP | 99.2% | 94.4% | 94.6% | 98.2% | 99.2% |
| Dataset | Label | Person | Car | Tree | Building | Floor | Accuracy |
|---|---|---|---|---|---|---|---|
| Person | 496 | 2 | 2 | 0 | 0 | 99.2% | |
| Car | 0 | 472 | 23 | 1 | 4 | 94.4% | |
| KNU | Tree | 5 | 10 | 473 | 10 | 2 | 94.6% |
| Building | 1 | 1 | 7 | 491 | 0 | 98.2% | |
| Floor | 0 | 2 | 2 | 0 | 496 | 99.2% | |
| Person | 996 | 0 | 4 | 0 | 0 | 99.6% | |
| Car | 1 | 986 | 10 | 3 | 0 | 98.6% | |
| KITTI | Tree | 3 | 2 | 992 | 2 | 1 | 99.2% |
| Building | 0 | 2 | 5 | 993 | 0 | 99.3% | |
| Floor | 0 | 1 | 1 | 0 | 998 | 99.8% |
| Methods | mIoU | Car | Bicycle | Motorcycle | Truck | Other-Vehicle | Person | Bicyclist | Motorcyclist | Road | Parking | Sidewalk | Other-Ground | Building | Fence | Vegetation | Trunk | Terrain | Pole | Traffic Sign |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PointNet [16] | 14.6 | 46.3 | 1.3 | 0.3 | 0.1 | 0.8 | 0.2 | 0.2 | 0.0 | 61.6 | 15.8 | 35.7 | 1.4 | 41.4 | 12.9 | 31.0 | 4.6 | 17.6 | 2.4 | 3.7 |
| SqueezeSegV3 [39] | 55.9 | 92.5 | 38.7 | 36.5 | 29.6 | 33.0 | 45.6 | 46.2 | 20.1 | 91.7 | 63.4 | 74.8 | 26.4 | 89.0 | 59.4 | 82.0 | 58.7 | 65.4 | 49.6 | 58.9 |
| SalsaNext [26] | 59.5 | 91.9 | 48.3 | 38.6 | 38.9 | 31.9 | 60.2 | 59.0 | 19.4 | 91.7 | 63.7 | 75.8 | 29.1 | 90.2 | 64.2 | 81.8 | 63.6 | 66.5 | 54.3 | 62.1 |
| Cylinder3D [24] | 67.8 | 97.1 | 67.6 | 64.0 | 59.0 | 58.6 | 73.9 | 67.9 | 36.0 | 91.4 | 65.1 | 75.5 | 32.3 | 91.0 | 66.5 | 85.4 | 71.8 | 68.5 | 62.6 | 65.6 |
| SPVNAS [23] | 67.0 | 97.2 | 50.6 | 50.4 | 56.6 | 58.0 | 67.4 | 67.1 | 50.3 | 90.2 | 67.6 | 75.4 | 21.8 | 91.6 | 66.9 | 86.1 | 73.4 | 71.0 | 64.3 | 67.3 |
| RPVNet [25] | 70.3 | 97.6 | 68.4 | 68.7 | 44.2 | 61.1 | 75.9 | 74.4 | 73.4 | 93.4 | 70.3 | 80.7 | 33.3 | 93.5 | 72.1 | 86.5 | 75.1 | 71.7 | 64.8 | 61.4 |
| mIoU | Person (Pedestrian+Cyclist) | Car (Car+truck) | Tree (Pole+Trunk+Vegetation) | Building (Wall) | Floor (Road) | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | IoU | Precision | Recall | IoU | Precision | Recall | IoU | Precision | Recall | IoU | Precision | Recall | IoU | ||
| sP | 50.2 | 35.7 | 98.4 | 35.5 | 49.7 | 81.2 | 44.6 | 15.7 | 53.1 | 13.8 | 88.1 | 68.6 | 62.8 | 99.1 | 95.2 | 94.4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bae, C.; Lee, Y.-C.; Yu, W.; Lee, S. Spherically Stratified Point Projection: Feature Image Generation for Object Classification Using 3D LiDAR Data. Sensors 2021, 21, 7860. https://doi.org/10.3390/s21237860
Bae C, Lee Y-C, Yu W, Lee S. Spherically Stratified Point Projection: Feature Image Generation for Object Classification Using 3D LiDAR Data. Sensors. 2021; 21(23):7860. https://doi.org/10.3390/s21237860
Chicago/Turabian StyleBae, Chulhee, Yu-Cheol Lee, Wonpil Yu, and Sejin Lee. 2021. "Spherically Stratified Point Projection: Feature Image Generation for Object Classification Using 3D LiDAR Data" Sensors 21, no. 23: 7860. https://doi.org/10.3390/s21237860