1. Introduction
Recently, cameras and sensors in autonomous vehicles and outdoor vision systems, such as closed-circuit televisions and dashboard cameras, are rapidly becoming important. Information obtained from visual and miscellaneous sensors should be as accurate as possible, because erroneous information can compromise both safety and property. However, the internal process of obtaining an image from a real scene using a camera is very complicated and is always accompanied by noise for various reasons. Since the shape and pattern of noise are random and unpredictable, it is difficult to design an appropriate denoising filter. Sometimes noise is caused by the external environment rather than the camera itself, including raindrops, snowflakes and even captions in images. So, various deep neural network approaches [
1,
2,
3,
4,
5] have been proposed to remove such environmental noises.
There are two noise removal approaches, hand-crafted and deep neural network approaches. First, hand-crafted approaches use various image features to remove noise. Buades et al. [
6] utilized the fact that natural images often exhibit repetitive local patterns and many similar regions throughout the image. Therefore, similarity can be calculated by calculating the L2 distance between the kernel region and any region of an image. Then, the filtered value is obtained by computing the weighted average of similar regions, where the weights are determined based on the similarity. Some transform-based methods have been proposed by assuming that a clean image is sparsely represented in a transform domain [
7,
8,
9]. However, various types of images cannot be guaranteed to be well sparsely represented with a single transformation. Elad et al. [
7] proposed a dictionary learning method. In this context, the dictionary is a collection of basic elements that can represent an image as their linear combination. The dictionary is updated and improved using the k-singular value decomposition (K-SVD) method for more appropriate sparse representations. Therefore, a denoised image can be estimated from the sparse representation using the final updated dictionary. However, this method consumes lots of computation to obtain the final updated dictionary. Inspired by the similarity concept used in the literature [
6], Dabov et al. [
8] proposed an advanced sparse representation method. Sparse representations are extracted from high similarity image regions instead of the entire image region, achieving approximately 0.3 dB higher denoised image quality than the method in [
7]. Gu et al. [
9] suggested weighted singular values to improve the SVD method and showed
dB better performance than the method in [
8]. These methods typically require a high computational load to obtain denoised images and have performance limitations for unknown or variable noises, leading to the following deep neural network approaches. Second, some deep neural network methods have been proposed using state-of-the-art artificial intelligence technologies [
10,
11,
12,
13,
14]. Zhang et al. [
10] proposed a supervised learning model that can effectively remove Gaussian noise of various noise levels. A 20-layer convolution neural network (CNN) model is used with residual learning [
15] and batch normalization [
16]. Zhao et al. [
17] improved the network model designed in [
10] by combining temporary noises extracted from the last few network layers with the ground-truth noise. Usually, these supervised methods have a relatively good noise-filtering ability but require a dataset of noisy and clean image pairs, which is considerably difficult to obtain in the real-world. Thus, in most cases, such paired datasets are generated synthetically by adding synthetic noise to clean images.
On the other hand, self-supervised learning methods do not explicitly require the corresponding clean images, unlike supervised ones. Self-supervised methods use the ground-truth data created by slightly modifying or transforming the filter input data, which is not always easy and practical. Lehtinen et al. [
12] proposed a noise-to-noise (N2N) learning method, where the ground-truth is a number of noisy images with noise exhibiting the same statistical characteristics as the original noise. The noise is supposed to be additive random noise with zero mean. If the L2 loss function is used, the deep neural network can learn a denoising ability even when multiple noisy images are used as ground-truth instead of a single clean image. The performance of the N2N method is somewhat inferior to those of the supervised learning methods. Additionally, creating target noisy images is occasionally difficult because the original and target noisy images have the same clean image, which is frequently impossible. To avoid this impractical situation, Krull et al. [
13] designed a noise-to-void (N2V) technique, where ground-truth images are created by replacing pixels in the original noisy image with adjacent pixels. Since this method attempts to imitate the N2N, its performance is approximately 1.1 dB lower than that. For enhanced performance, a clever pixel replacement technique was suggested by Batson et al. [
18], where ground-truth images are created by replacing pixel values with random numbers. This technique achieved a slightly better noise removal performance than the N2V [
13]. Niu et al. [
19] suggested another N2V model that creates ground-truth images by replacing pixels with the center pixel in a region with high similarity based on the concept defined in [
6]. This method shows approximately a
dB better performance than the N2V [
13]. Xu et al. [
20] proposed a practical version of the N2N method using a doubly noisy image as the input image. A doubly noisy image is created by adding noise, which is statistically similar to the original noise, to the original noisy image. This approach achieved a performance similar to that of the N2N method at low noise levels but showed deteriorated performance when the noise increased above a certain level. Another method that does not require paired noisy and clean datasets was proposed by Lin et al. [
14], called noise-to-blur (N2B) method. In this method, the target image is a blurred image filtered with a strong low-pass filter; the method almost eliminates the noise as well as the image details from the original noisy image. In this process, many types of noise, such as raindrops, snowflakes and dust, can be successfully removed along with image details, which means that the N2B method can remove various types of noise, unlike the N2N and N2V. However, it shows lower performance than the N2N method.
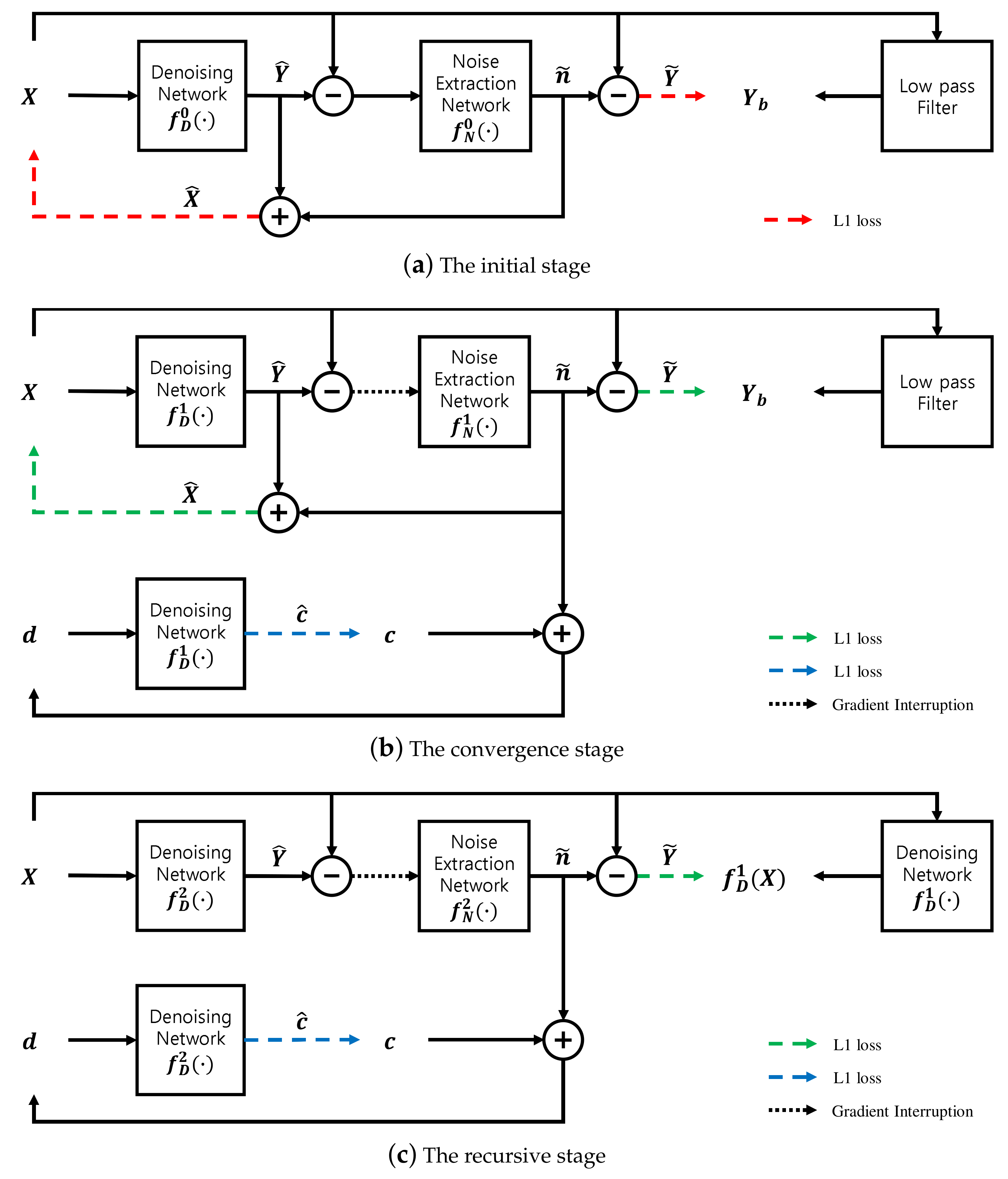
Generally, the deep neural network-based approaches can handle more diverse and complex types of noise than hand-crafted ones owing to their learning ability. However, supervised deep neural networks require a hard-to-generate dataset, despite their good noise removal ability. The N2V and N2B methods are not limited by dataset issues but show relatively low performance. In this paper, we propose a high-performance and self-supervised method without dataset problems by introducing a recursive learning stage and a stage-dependent objective function. The rest of the paper is structured as follows. In
Section 2, the basic structure and concept of the N2B model are depicted.
Section 3 describes the details of the proposed model.
Section 4 describes dataset, experimental setup and simulation results. Finally,
Section 5 concludes this paper.
5. Conclusions
Collecting only noisy data is easy and cheap. In this work, we suggest a novel denoising deep neural network model that does not require a noisy and clean data pair for ensuring the practicality of the proposed method. In addition, since the proposed N2BeC model is based on the N2B model, it can be extended to remove environmental noises such as raindrops, snowflakes and dust. Importantly, the noise removal performance is superior to those of the N2V and N2B models, which are real supervised methods. Therefore, the N2BeC model is not only practical and extendable but also has good performance due to the introduced recursive learning stage and stage-dependent loss functions. The multi-stage learning method using deep neural networks approaches the correct answer by giving more accurate hints as the stages progress. In this paper, the number of recursive stages is limited to two, but if the number can be increased in the future, it is expected that the performance can be further improved. In addition, it is possible to find an adaptive method that can be applied to more various types of noise.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}