
Super-Resolution Generative Adversarial Network Based on the Dual Dimension Attention Mechanism for Biometric Image Super-Resolution



Abstract
:1. Introduction
- We propose DDA-SRGAN, a GAN-based SR framework using a dual-dimension attention mechanism for image SR. It will automatically locate the ROI region without given prior knowledge and further enhance the feature details inside the corresponding region.
- Our proposed attention module will capture the ROI features in the LR image by considering the interdependence of feature maps with respect to the spatial dimension and the channel dimensions. Furthermore, the DDA mechanism forces the generator in GAN to generate more informative SR images and enhance the performance of the downstream tasks.
- We have built an SR framework for enhancing the existing authentication system of BiometricIoT, and further decrease the possibility of compromising sensor.
2. Literature Review
3. Materials and Methods
3.1. Proposed Network Architecture for SR
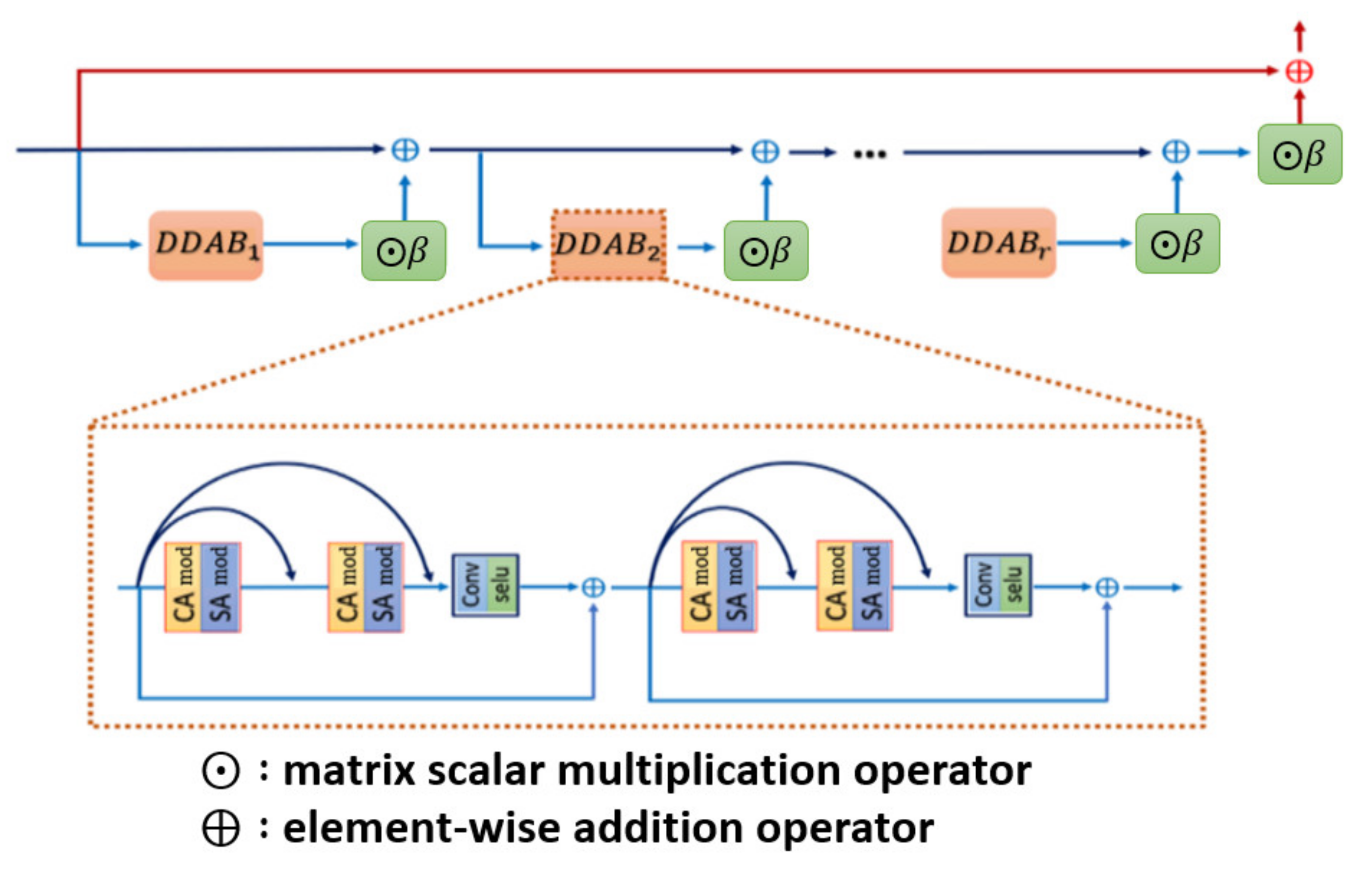
3.1.1. Overall Network Architecture
3.1.2. Attention Mechanism Module
3.2. The Kernel Modules of Dual Dimension Attention Block
3.2.1. Channel Attention Module (CAM)
3.2.2. Spatial Attention Module (SAM)
3.3. Overall Network Loss Function
4. Experiments and Results
4.1. Iris Dataset Specification
4.2. Face Dataset Specification
4.3. Partition of Experimental Dataset
4.3.1. Iris Dataset Partition
4.3.2. Face Dataset Partition
4.4. Domain Knowledge of Biometrics
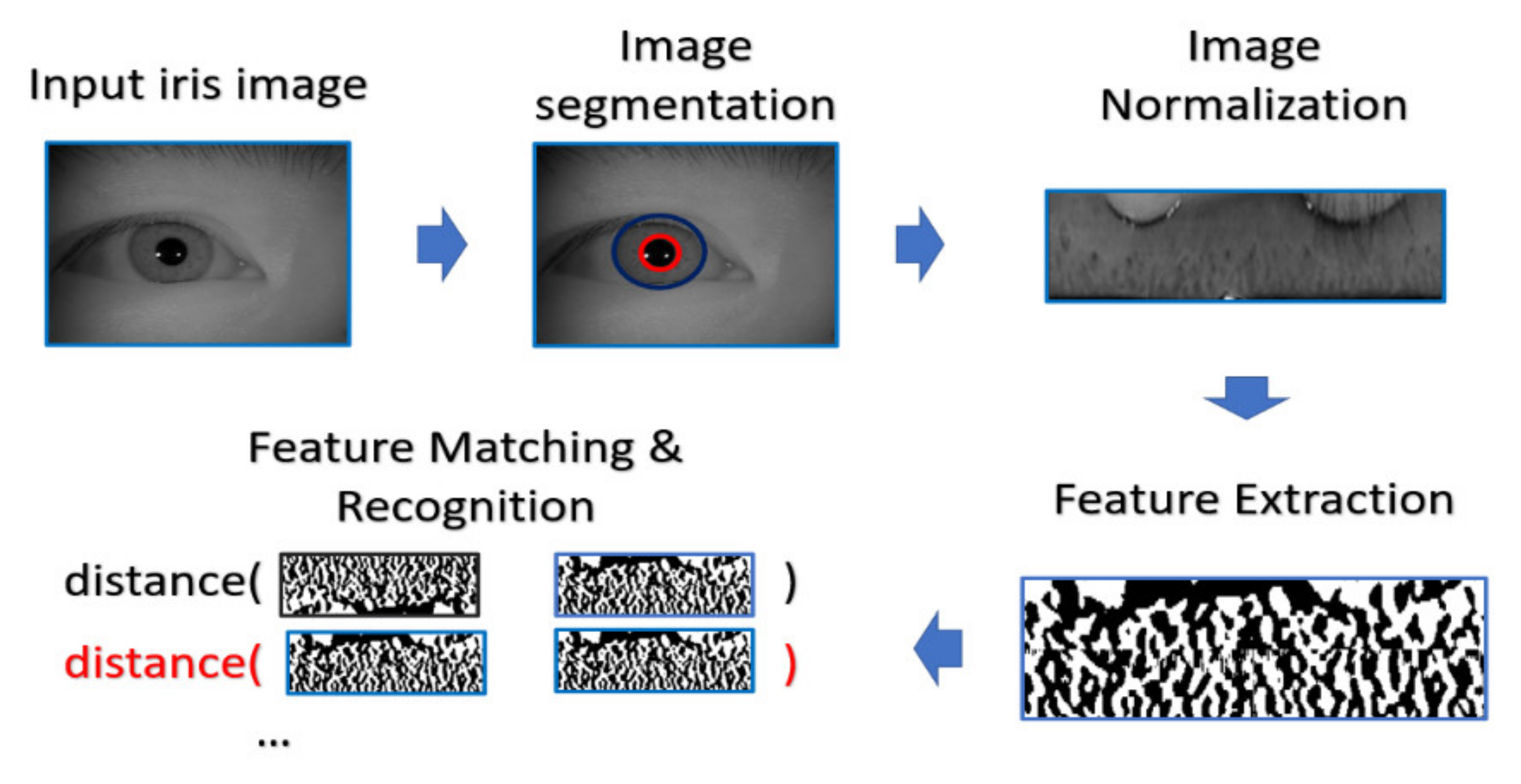
4.4.1. Common Procedure of Biometrics
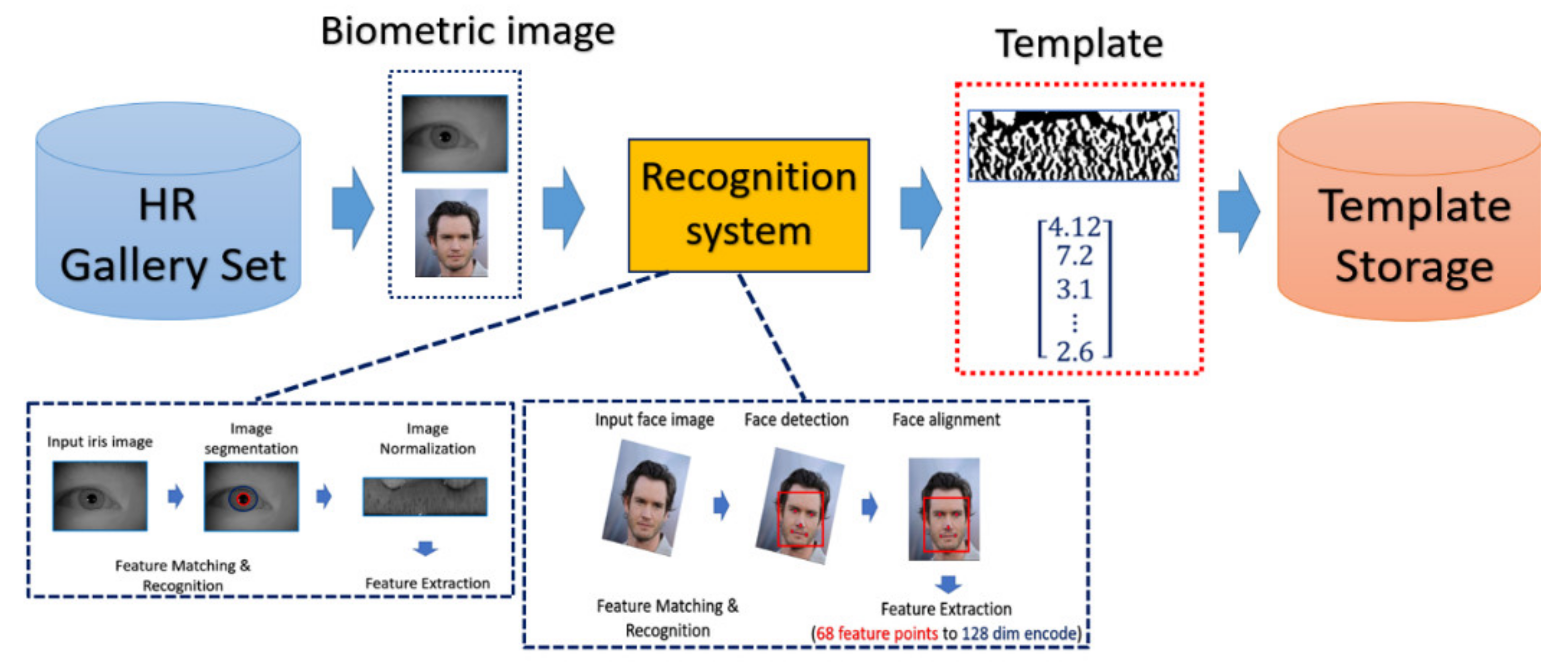
- Enrollment stage: we load the HR image (iris image or face image) from the gallery set and take the image as input of recognition system to extract the corresponding features for enrolling the feature template of gallery set. Later on, the feature templates are stored in the local database. The enrollment stage is illustrated in Figure 6.
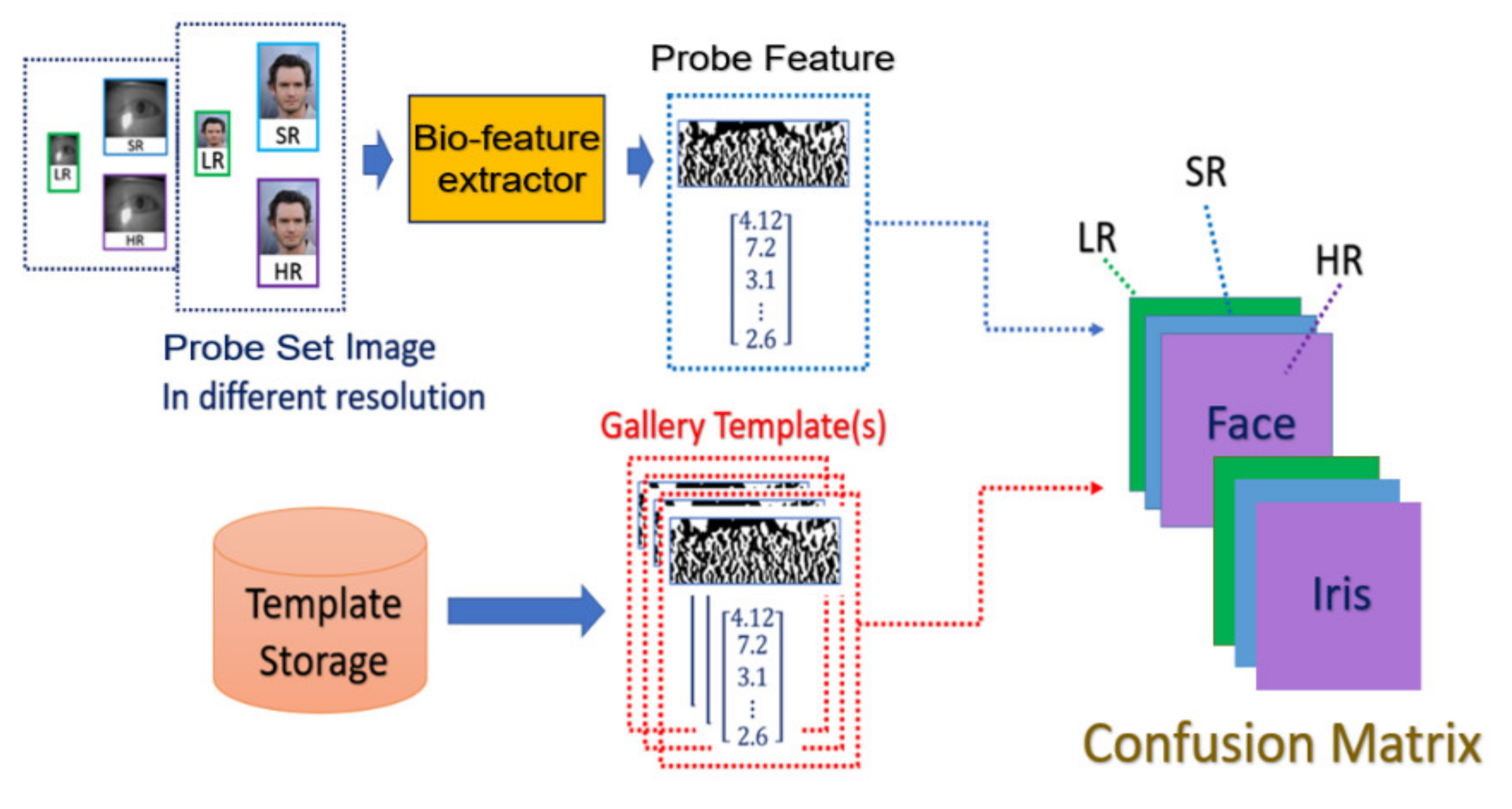
- SR generation stage: we load the HR image from the probe set, and the corresponding LR images are obtained by downsampling the HR images with the scaling factor of ×4. We further feed the LR images into the SR generator to enhance the image resolution, as shown in the illustration in Figure 7.
- Matching stage: the SR image obtained from the SR model will be further taken as the input of biometric recognition system, and the SR image feature will be extracted by the recognition system. After that, all of the feature templates extracted from the SR images will be compared by all the enrolled feature obtained from the local database to calculate the distances (Hamming distance or Euclidean distance). The resulting confusion matrix will be obtained by further calculating those distance. The matching stage is illustrated in Figure 8.
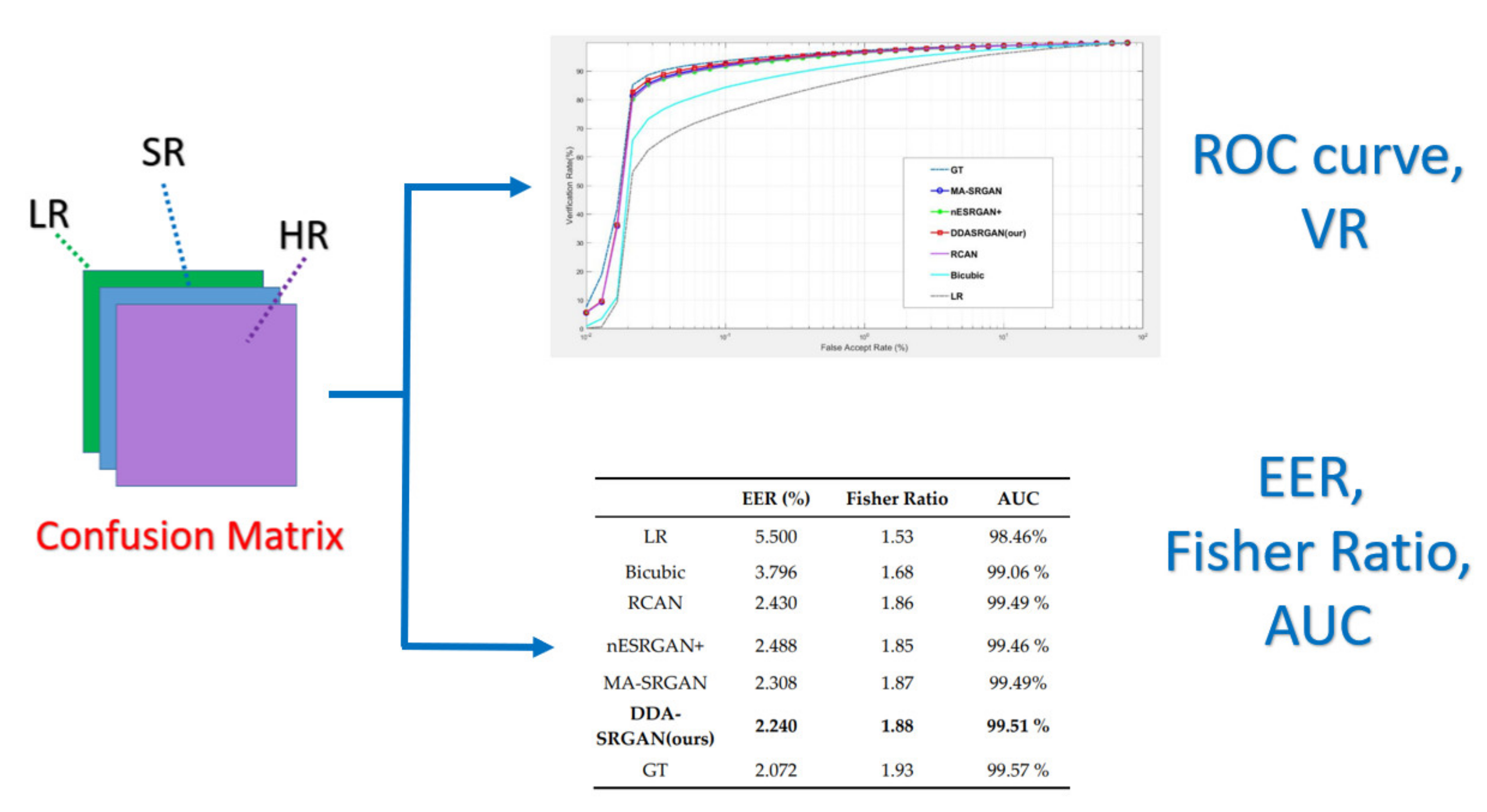
- Performance evaluation stage: finally, the corresponding EER, Fisher ratio, and area under curve (AUC) information are calculated by the given confusion matrix, and the corresponding receiver operating characteristic (ROC) curves are plotted to visualize the overall performance of the recognition system as illustrated in Figure 9.




4.4.2. Iris Recognition Procedure
4.4.3. Face Recognition Procedure
4.5. Details for Training and Parameters Tuning
5. Experimental Results
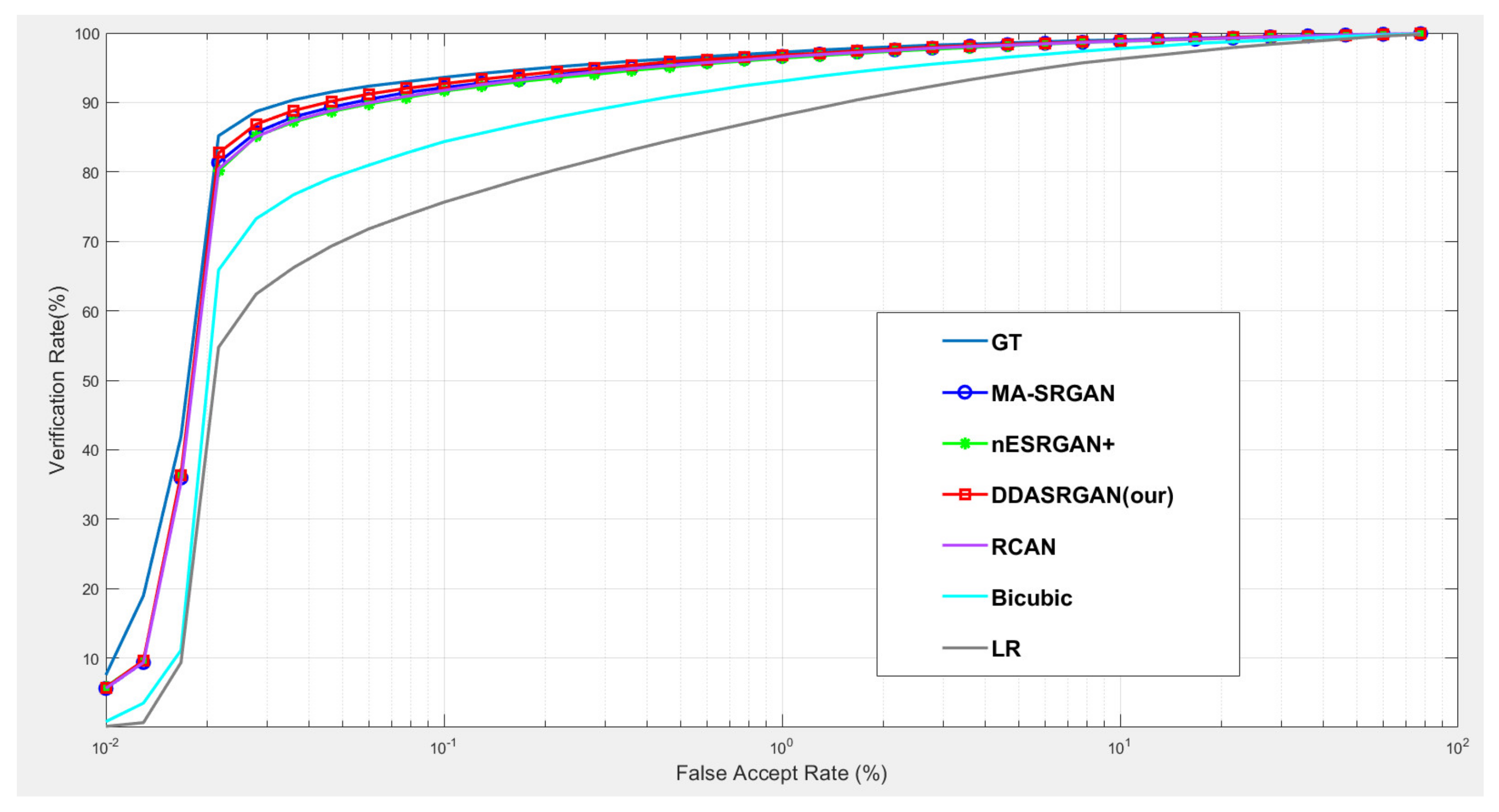
5.1. Downstream Task: Iris Recognition
5.2. Downstream Task: Face Recognition
5.3. Visual Evaluation
5.4. Quantitative Evaluation
5.5. The Comparison between the Previous Work
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Number of Internet of Things (IoT) Connected Devices Worldwide from 2019 to 2030. Available online: https://www.statista.com/statistics/1183457/iot-connected-devices-worldwide/ (accessed on 14 September 2021).
- Dhvani, S.; Vinayak, H. IoT Based Biometrics Implementation on Raspberry Pi. In Proceedings of the International Conference on Communication, Computing and Virtualization (ICCCV), Amsterdam, The Netherlands, 26–27 February 2016; Volume 79, pp. 328–336. [Google Scholar] [CrossRef] [Green Version]
- Ehsan, N.T.; Adel, N.T.; Reza, G.; Rajkumar, B. Integrated IoT and Cloud Environment for Fingerprint Recognition. In Proceedings of the International Conference on Fog Computing and Internet of Things (ICFCIOT 2017), Hyderabad, India, 21–22 December 2017. [Google Scholar]
- Farid, F.; Elkhodr, M.; Sabrina, F.; Ahamed, F.; Gide, E. A Smart Biometric Identity Management Framework for Personalised IoT and Cloud Computing-Based Healthcare Services. Sensors 2021, 21, 552. [Google Scholar] [CrossRef] [PubMed]
- Kenneth, L.A.; Kah, P.S. Biometrics-based Internet of Things and Big data design framework. Math. Biosci. Eng. 2021, 18, 4461–4476. [Google Scholar] [CrossRef]
- Boucher, A.; Kyriakidis, P.C.; Cronkite-Ratcliff, C. Geostatistical solutions for super-resolution land cover mapping. IEEE Trans. Geosci. Remote Sens. 2007, 46, 272–283. [Google Scholar] [CrossRef]
- Yang, W.; Zhang, X.; Tian, Y.; Wang, W.; Xue, J.-H.; Liao, Q. Deep learning for single image super-resolution: A brief review. IEEE Trans. Multimed. 2019, 21, 3106–3121. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Dai, T.; Zha, H.; Jiang, Y.; Xia, S. Image super-resolution via residual block attention networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Kim, D.; Kim, M.; Kwon, G.; Kim, D. Progressive Face Super-Resolution via Attention to Facial Landmark. In Proceedings of the 30th British Machine Vision Conference (BMVC), Cardiff, UK, 9–12 September 2019. [Google Scholar]
- Li, Q.; Yu, Z.; Wang, Y.; Zheng, H. TumorGAN: A Multi-Modal Data Augmentation Framework for Brain Tumor Segmentation. Sensors 2020, 20, 4203. [Google Scholar] [CrossRef] [PubMed]
- Huang, C.-E.; Chang, C.-C.; Li, Y.-H. Mask Attention-SRGAN for Mobile Sensing Networks. Sensors 2021, 21, 5973. [Google Scholar] [CrossRef] [PubMed]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a deep convolutional network for image super-resolution. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 184–199. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual dense network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2018, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2472–2481. [Google Scholar]
- Lai, W.-S.; Huang, J.-B.; Ahuja, N.; Yang, M.-H. Deep laplacian pyramid networks for fast and accurate super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 624–632. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Deeply-recursive convolutional network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 1637–1645. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X. Image super-resolution via deep recursive residual network. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 3147–3155. [Google Scholar]
- Haris, M.; Shakhnarovich, G.; Ukita, N. Deep back-projection networks for super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2018, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1664–1673. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Tong, T.; Li, G.; Liu, X.; Gao, Q. Image super-resolution using dense skip connections. In Proceedings of the IEEE International Conference on Computer Vision 2017, Venice, Italy, 22–29 October 2017; pp. 4799–4807. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 694–711. [Google Scholar]
- Bruna, J.; Sprechmann, P.; LeCu, Y. Super-resolution with deep convolutional sufficient statistics. arXiv 2015, arXiv:1511.05666. [Google Scholar]
- Sajjadi, M.S.; Scholkopf, B.; Hirsch, M. Enhancenet: Single image super-resolution through automated texture synthesis. In Proceedings of the IEEE International Conference on Computer Vision 2017, Venice, Italy, 22–29 October 2017; pp. 4491–4500. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1409–1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Rakotonirina, N.C.; Rasoanaivo, A. Esrgan+: Further improving enhanced super-resolution generative adversarial network. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing, Barcelona, Spain, 4–8 May 2020. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2018, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, F.; Jiang, M.; Qian, C.; Yang, S.; Li, C.; Zhang, H.; Wang, X.; Tang, X. Residual attention network for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 3156–3164. [Google Scholar]
- Li, K.; Wu, Z.; Peng, K.-C.; Ernst, J.; Fu, Y. Tell me where to look: Guided attention inference network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2018, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9215–9223. [Google Scholar]
- Cao, C.; Liu, X.; Yang, Y.; Yu, Y.; Wang, J.; Wang, Z.; Huang, Y.; Wang, L.; Huang, C.; Xu, W. Look and think twice: Capturing top-down visual attention with feedback convolutional neural networks. In Proceedings of the IEEE International Conference on Computer Vision 2015, Santiago, Chile, 7–13 December 2015; pp. 2956–2964. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A. Spatial transformer networks. Adv. Neural Inf. Process. Syst. 2015, 28, 2017–2025. [Google Scholar]
- Bluche, T. Joint line segmentation and transcription for end-to-end handwritten paragraph recognition. Adv. Neural Inf. Process. Syst. 2016, 29, 838–846. [Google Scholar]
- Miech, A.; Laptev, I.; Sivic, J. Learnable pooling with context gating for video classification. arXiv 2017, arXiv:1706.06905. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV) 2018, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Institute of Automation, Chinese Academy of Science. CASIA v4.0 Iris Image Database. Available online: http://www.cbsr.ia.ac.cn/china/Iris%20Databases%20CH.asp (accessed on 15 September 2021).
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep Learning Face Attributes in the Wild. In Proceedings of the International Conference on Computer Vision (ICCV) 2015, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- King, D.E. Dlib-ml: A Machine Learning Toolkit. J. Mach. Learn. Res. 2009, 10, 1755–1758. [Google Scholar]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset Type | CASIA (Iris Image) | CelebA (Face Image) |
|---|---|---|
| Number of Categories | 2000 | 6000 |
| Number of Images in each category | 10 | 20 |
| Image Resolution | 640 × 480 | 160 × 200 |
| Image Type | Categories | Number of Images per Class | Total Number of Images |
|---|---|---|---|
| Iris image | 1000 | 10 | 10,000 |
| Face Image | 4200 | 20 | 84,000 |
| Enrollment Dataset | Query Dataset | |||||
|---|---|---|---|---|---|---|
| Image Type | Categories | Number of Images per Class | Total Number of Images | Categories | Number of Images per Class | Total Number of Images |
| Iris image | 1000 | 5 | 5000 | 1000 | 5 | 5000 |
| Face Image | 1800 | 10 | 18,000 | 1800 | 10 | 18,000 |
| EER (%) | Fisher Ratio | AUC | VR | |
|---|---|---|---|---|
| LR | 5.500 | 1.53 | 98.46% | 75.62% |
| Bicubic | 3.796 | 1.68 | 99.06% | 84.35% |
| RCAN | 2.430 | 1.86 | 99.49% | 91.74% |
| nESRGAN+ | 2.488 | 1.85 | 99.46% | 91.65% |
| MA-SRGAN | 2.308 | 1.87 | 99.49% | 92.23% |
| DDA-SRGAN(ours) | 2.240 | 1.88 | 99.51% | 92.7% |
| GT | 2.072 | 1.93 | 99.57% | 93.62% |
| EER (%) | Fisher Ratio | AUC | VR | |
|---|---|---|---|---|
| Bicubic | 11.310 | 1.16 | 92.34% | 24.18% |
| RCAN | 8.260 | 1.40 | 95.67% | 68.74% |
| nESRGAN+ | 6.247 | 1.65 | 97.36% | 87.71% |
| MA-SRGAN | 6.237 | 1.64 | 97.41% | 89.75 |
| DDA-SRGAN (ours) | 6.840 | 1.53 | 97.02% | 84.24% |
| GT | 5.506 | 1.86 | 97.91% | 92.01% |
| PSNR | SSIM (%) | Inception Score | |
|---|---|---|---|
| Bicubic | 33.91 | 89% | 2.1 |
| RCAN | 34.88 | 89.5% | 2.23 |
| nESRGAN+ | 20.75 | 83.5% | 2.35 |
| MA-SRGAN | 23.36 | 84.9% | 2.29% |
| DDA-SRGAN (ours) | 28.27 | 80% | 2.3% |
| GT | inf | 100% | - |
| PSNR | SSIM (%) | Inception Score | |
|---|---|---|---|
| Bicubic | 26.62 | 81.9% | 3.18 |
| RCAN | 26.38 | 79.9% | 3.11 |
| nESRGAN+ | 22.4 | 76.6% | 2.88 |
| MA-SRGAN | 21.22 | 74.5% | 2.96 |
| DDA-SRGAN (ours) | 22.21 | 65.8% | 2.73 |
| GT | inf | 100% | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, C.-E.; Li, Y.-H.; Aslam, M.S.; Chang, C.-C. Super-Resolution Generative Adversarial Network Based on the Dual Dimension Attention Mechanism for Biometric Image Super-Resolution. Sensors 2021, 21, 7817. https://doi.org/10.3390/s21237817
Huang C-E, Li Y-H, Aslam MS, Chang C-C. Super-Resolution Generative Adversarial Network Based on the Dual Dimension Attention Mechanism for Biometric Image Super-Resolution. Sensors. 2021; 21(23):7817. https://doi.org/10.3390/s21237817
Chicago/Turabian StyleHuang, Chi-En, Yung-Hui Li, Muhammad Saqlain Aslam, and Ching-Chun Chang. 2021. "Super-Resolution Generative Adversarial Network Based on the Dual Dimension Attention Mechanism for Biometric Image Super-Resolution" Sensors 21, no. 23: 7817. https://doi.org/10.3390/s21237817