
A Deep Learning Based Approach for Localization and Recognition of Pakistani Vehicle License Plates

 , , , ,
, , , ,  , and
, and
Abstract
:1. Introduction
- To train and test the model, a new Pakistani license plate dataset (PLPD) is developed.
- A deep end-to-end model is developed, which localizes, rectifies, and recognizes the uniform and non-uniform license plates.
- Detailed experiments are performed to compare the effectiveness of the proposed model with state-of-the-art methods.
2. Related Work
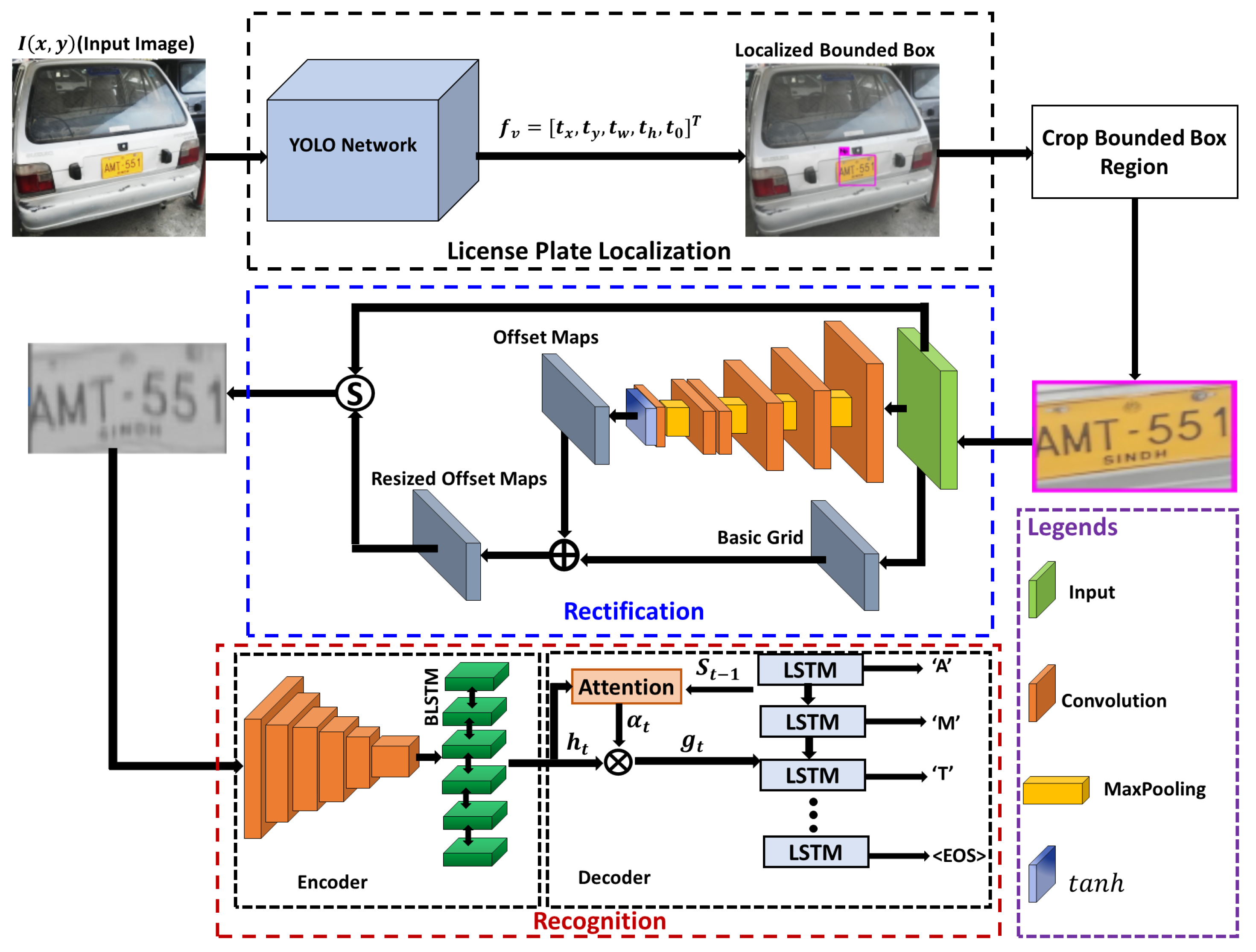
3. Proposed Model
3.1. License Plate Localization
3.2. License Plate Rectification
3.3. License Plate Recognition
4. Experimental Details
4.1. Datasets
4.2. Performance Measures
4.3. Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Sakthivel, N.; Swamydoss, D. An Optimized Algorithm for Car Plate Recognition Using Artificial Neural Network for a Mobile Application without Segmentation. Asian J. Appl. Sci. 2017, 5. Available online: https://www.ajouronline.com/index.php/AJAS/article/view/4645 (accessed on 16 January 2021).
- Patel, C.; Shah, D.; Patel, A. Automatic number plate recognition system (anpr): A survey. Int. J. Comput. Appl. 2013, 69. [Google Scholar] [CrossRef]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object detection via region-based fully convolutional networks. In Proceedings of the 30th International Conference on Neural Information Processing Systems (NIPS), Barcelona, Spain, 5–10 December 2016; Curran Associates Inc.: Red Hook, NY, USA, 2016; pp. 379–387. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1520–1528. [Google Scholar]
- Haq, N.U.; Khan, A.; Rehman, Z.u.; Din, A.; Shao, L.; Shah, S. A novel weight initialization with adaptive hyper-parameters for deep semantic segmentation. Multimed. Tools Appl. 2021, 80, 21771–21787. [Google Scholar] [CrossRef]
- Haq, N.U.; Ur Rehman, Z.; Khan, A.; Din, A.; Shah, S.; Ullah, A.; Qayum, F. Impact of data smoothing on semantic segmentation. Neural Comput. Appl. 2020, 1–10. [Google Scholar] [CrossRef]
- Nam, H.; Han, B. Learning multi-domain convolutional neural networks for visual tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4293–4302. [Google Scholar]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H. Fully-convolutional siamese networks for object tracking. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October; Springer: Berlin/Heidelberg, Germany, 2016; pp. 850–865. [Google Scholar]
- Guo, Y.; Liu, Y.; Oerlemans, A.; Lao, S.; Wu, S.; Lew, M.S. Deep learning for visual understanding: A review. Neurocomputing 2016, 187, 27–48. [Google Scholar] [CrossRef]
- Kendall, A.; Badrinarayanan, V.; Cipolla, R. Bayesian segnet: Model uncertainty in deep convolutional encoder-decoder architectures for scene understanding. arXiv 2015, arXiv:1511.02680. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ciregan, D.; Meier, U.; Schmidhuber, J. Multi-column deep neural networks for image classification. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3642–3649. [Google Scholar]
- Rafeeq, M.J.; Rehman, Z.u.; Khan, A.; Khan, I.A.; Jadoon, W. Ligature categorization based Nastaliq Urdu recognition using deep neural networks. Comput. Math. Organ. Theory 2019, 25, 184–195. [Google Scholar] [CrossRef]
- Khan, Z.; Khana, F.G.; Khan, A.; Rehman, Z.u.; Shah, S.; Qummar, S.; Ali, F.; Pack, S. Diabetic Retinopathy Detection Using VGG-NIN a Deep Learning Architecture. IEEE Access 2021, 9, 61408–61416. [Google Scholar] [CrossRef]
- Qummar, S.; Khan, F.G.; Shah, S.; Khan, A.; Shamshirband, S.; Rehman, Z.U.; Ahmed Khan, I.; Jadoon, W. A Deep Learning Ensemble Approach for Diabetic Retinopathy Detection. IEEE Access 2019, 7, 150530–150539. [Google Scholar] [CrossRef]
- Huang, W.; Qiao, Y.; Tang, X. Robust scene text detection with convolution neural network induced mser trees. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 497–511. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a deep convolutional network for image super-resolution. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 184–199. [Google Scholar]
- Malik, S.M.; Hafiz, R. Automatic Number Plate Recognition based on connected component analysis technique. In Proceedings of the 2nd International Conference on Emerging Trends in Engineering and Technology (ICETET’2014), London, UK, 30–31 May 2014. [Google Scholar]
- Singh, B.; Kaur, M.; Singh, D.; Singh, G. Automatic number plate recognition system by character position method. Int. J. Comput. Vis. Robot. 2016, 6, 94–112. [Google Scholar] [CrossRef] [Green Version]
- Khan, J.A.; Shah, M.A. Car Number Plate Recognition (CNPR) system using multiple template matching. In Proceedings of the 2016 22nd International Conference on Automation and Computing (ICAC), Colchester, UK, 7–8 September 2016; pp. 290–295. [Google Scholar]
- Khan, J.A.; Shah, M.A.; Wahid, A.; Khan, M.H.; Shahid, M.B. Enhanced car number plate recognition (ECNPR) system by improving efficiency in preprocessing steps. In Proceedings of the 2017 International Conference on Communication Technologies (ComTech), Rawalpindi, Pakistan, 19–21 April 2017; pp. 156–161. [Google Scholar]
- Soomro, S.R.; Javed, M.A.; Memon, F.A. Vehicle number recognition system for automatic toll tax collection. In Proceedings of the 2012 International Conference of Robotics and Artificial Intelligence, Rawalpindi, Pakistan, 22–23 October 2012; pp. 125–129. [Google Scholar]
- Haider, S.A.; Khurshid, K. An implementable system for detection and recognition of license plates in Pakistan. In Proceedings of the 2017 International Conference on Innovations in Electrical Engineering and Computational Technologies (ICIEECT), Karachi, Pakistan, 5–7 April 2017; pp. 1–5. [Google Scholar]
- Rasheed, S.; Naeem, A.; Ishaq, O. Automated number plate recognition using hough lines and template matching. In Proceedings of the World Congress on Engineering and Computer Science, San Francisco, CA, USA, 24–26 October 2012; Volume 1, pp. 24–26. [Google Scholar]
- Samra, G.A.; Khalefah, F. Localization of license plate number using dynamic image processing techniques and genetic algorithms. IEEE Trans. Evol. Comput. 2013, 18, 244–257. [Google Scholar]
- Gou, C.; Wang, K.; Yao, Y.; Li, Z. Vehicle license plate recognition based on extremal regions and restricted Boltzmann machines. IEEE Trans. Intell. Transp. Syst. 2015, 17, 1096–1107. [Google Scholar] [CrossRef]
- Bhutta, M.U.M.; Mahmood, H.; Malik, H. An intelligent approach for robust detection and recognition of multiple color and font styles automobiles license plates: A feature-based algorithm. In Proceedings of the 2014 International Conference on Audio, Language and Image Processing, Shanghai, China, 7–9 July 2014; pp. 956–961. [Google Scholar]
- Li, H.; Shen, C. Reading car license plates using deep convolutional neural networks and lstms. arXiv 2016, arXiv:1601.05610. [Google Scholar]
- Selmi, Z.; Halima, M.B.; Alimi, A.M. Deep learning system for automatic license plate detection and recognition. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 1, pp. 1132–1138. [Google Scholar]
- Cheang, T.K.; Chong, Y.S.; Tay, Y.H. Segmentation-free vehicle license plate recognition using ConvNet-RNN. arXiv 2017, arXiv:1701.06439. [Google Scholar]
- Zang, D.; Chai, Z.; Zhang, J.; Zhang, D.; Cheng, J. Vehicle license plate recognition using visual attention model and deep learning. J. Electr. Imaging 2015, 24, 033001. [Google Scholar] [CrossRef] [Green Version]
- Jain, V.; Sasindran, Z.; Rajagopal, A.; Biswas, S.; Bharadwaj, H.S.; Ramakrishnan, K. Deep automatic license plate recognition system. In Proceedings of the Tenth Indian Conference on Computer Vision, Graphics and Image Processing, Guwahati, Assam, India, 18–22 December 2016; pp. 1–8. [Google Scholar]
- Laroca, R.; Severo, E.; Zanlorensi, L.A.; Oliveira, L.S.; Gonçalves, G.R.; Schwartz, W.R.; Menotti, D. A robust real-time automatic license plate recognition based on the YOLO detector. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–10. [Google Scholar]
- Liu, Y.; Huang, H.; Cao, J.; Huang, T. Convolutional neural networks-based intelligent recognition of Chinese license plates. Soft Comput. 2018, 22, 2403–2419. [Google Scholar] [CrossRef]
- Zhuang, J.; Hou, S.; Wang, Z.; Zha, Z.J. Towards human-level license plate recognition. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 306–321. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Luo, C.; Jin, L.; Sun, Z. Moran: A multi-object rectified attention network for scene text recognition. Pattern Recognit. 2019, 90, 109–118. [Google Scholar] [CrossRef]
- Shi, B.; Yang, M.; Wang, X.; Lyu, P.; Yao, C.; Bai, X. Aster: An attentional scene text recognizer with flexible rectification. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 2035–2048. [Google Scholar] [CrossRef] [PubMed]
- Silvano, G.; Endo, P.T.; Ribeiro, V.C.T.; Greati, V.; Silva, I.; Lynn, T.; Bezerra, A. Artificial Mercosur License Plates, V2. Available online: https://data.mendeley.com/datasets/nx9xbs4rgx/2 (accessed on 16 January 2021).
- Roboflow. License Plates Dataset. Available online: https://public.roboflow.com/object-detection/license-plates-us-eu (accessed on 16 January 2021).
- Usmankhujaev, S.; Lee, S.; Kwon, J. Korean license plate recognition system using combined neural networks. In Proceedings of the International Symposium on Distributed Computing and Artificial Intelligence, Avila, Spain, 26–28 June 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 10–17. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer Type | Hyper-Parameters | Size |
|---|---|---|
| Input | – | |
| MaxPool | ||
| Conv | ||
| MaxPool | ||
| Conv | ||
| MaxPool | ||
| Conv | ||
| Conv | ||
| Conv | ||
| MaxPool | ||
| – | ||
| Resize | – |
| Layers | Out Size | Configuration | |
|---|---|---|---|
| Encoder | Block 0 | ||
| Block 1 | |||
| Block 2 | |||
| Block 3 | |||
| Block 4 | |||
| Block 5 | |||
| BiLSTM l | 25 | 256 hidden units | |
| BiLSTM 2 | 25 | 256 hidden units | |
| Decoder | Att. LSTM | * | 256 attention units |
| 256 attention units | |||
| Att. LSTM | * | 256 attention units | |
| 256 attention units |
| Model | IOU |
|---|---|
| DALPR [34] | 0.60 |
| KLPR [43] | 0.72 |
| Proposed method | 0.89 |
| Model | Accuracy | Recall | Precision | F1 Score |
|---|---|---|---|---|
| DALPR [34] | 0.20 | 0.37 | 0.80 | 0.50 |
| KLPR [43] | 0.53 | 0.70 | 0.87 | 0.77 |
| Proposed method | 0.82 | 0.99 | 0.94 | 0.96 |
| Model | Accuracy | Recall | Precision | F1 Score |
|---|---|---|---|---|
| DALPR [34] | 0.00 | 0.00 | 0.00 | 0.00 |
| KLPR [43] | 0.70 | 0.82 | 0.79 | 0.80 |
| Proposed method | 0.87 | 0.96 | 0.93 | 0.94 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yousaf, U.; Khan, A.; Ali, H.; Khan, F.G.; Rehman, Z.u.; Shah, S.; Ali, F.; Pack, S.; Ali, S. A Deep Learning Based Approach for Localization and Recognition of Pakistani Vehicle License Plates. Sensors 2021, 21, 7696. https://doi.org/10.3390/s21227696
Yousaf U, Khan A, Ali H, Khan FG, Rehman Zu, Shah S, Ali F, Pack S, Ali S. A Deep Learning Based Approach for Localization and Recognition of Pakistani Vehicle License Plates. Sensors. 2021; 21(22):7696. https://doi.org/10.3390/s21227696
Chicago/Turabian StyleYousaf, Umair, Ahmad Khan, Hazrat Ali, Fiaz Gul Khan, Zia ur Rehman, Sajid Shah, Farman Ali, Sangheon Pack, and Safdar Ali. 2021. "A Deep Learning Based Approach for Localization and Recognition of Pakistani Vehicle License Plates" Sensors 21, no. 22: 7696. https://doi.org/10.3390/s21227696