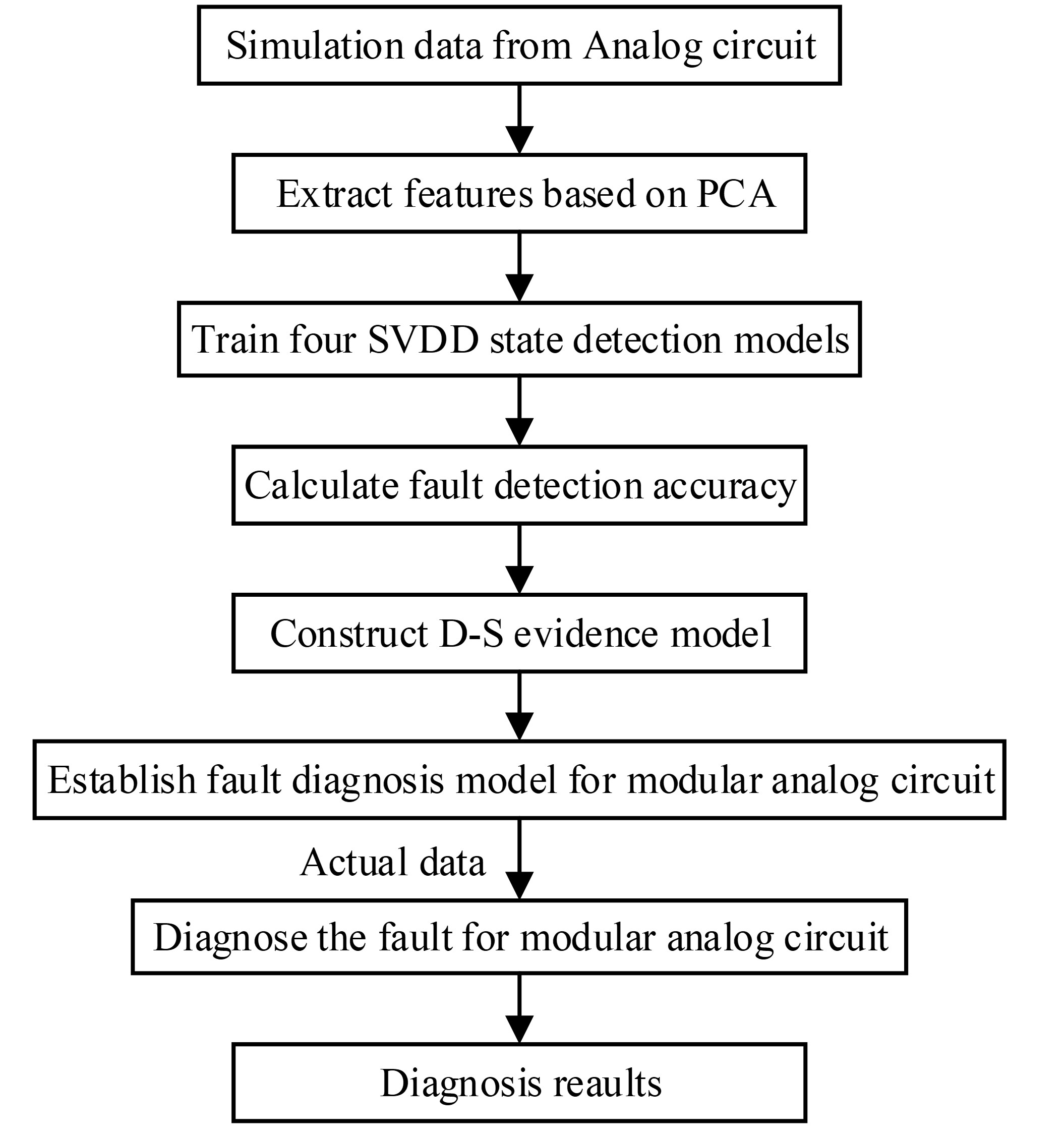
4.1. Establishing Fault Diagnosis Model for the Dual Band-Pass Filters
To prove the effectiveness of the proposed circuit fault diagnosis method based on SVDD and D–S evidence theory, a dual bandpass filter circuit is selected for experiments. The circuit is composed of a Sallen–Key circuit, and the circuit structure is as shown in
Figure 8.
At the beginning of the experiment, we need to establish a fault diagnosis model for the circuit through simulation experiments. According to the division principle, the circuit is divided into five modules P1–P5, and the components and functions are shown in
Table 1. Modules P2 and P3 are parallel modules, and they are in series with other modules. The output nodes of the five modules are selected as five test points. The passbands of the dual bandpass circuit are 50 Hz–1 kHz and 5 k–50 kHz, respectively.
In PSPICE, a pulse signal with a period of 500 μs, a pulse width of 20 μs, and an amplitude of 5 V is selected as the test excitation signal. 5% tolerance is set for all components. At first, the TSG state detection model is used to judge working state of module P1, and its detection accuracy are obtain as follows: 550 times of Monte Carlo analysis are carried out to obtain the time-domain voltage signal samples from node N1. PCA method is used to extract and normalize the sampled data. These 550 sets of sample data are the positive samples of the circuit module P1 under normal working conditions. 500 sets of samples are used to train SVDD model, and the remaining 50 samples are used to calculate the accuracy of the model. For each component in module P1, 40% and 50% parameter drifts are respectively injected into the components as fault states. 300 Monte Carlo analyses (50 sets for each fault module) are performed separately, and the obtained fault samples will extracted by PCA method are used as the testing data of the SVDD model. Based on TSG state detection model, the fault detection accuracy from test point N1 to N5 are shown in
Table 2 row 3. When different modules are in the fault states, respectively. The results are shown as
Table 2.
The table shows that the fault detection effect of the TSG state detection model is ideal. When the component has 50% fault drift, its average detection rate is above 90%. However, the detection accuracy of the TSG state detection model for a few circuit fault modules needs to be improved. The FSG and FSP state detection models are established using the frequency-domain features of the circuit. Therefore, a sweep signal with an amplitude of 4 V and a frequency of 1 Hz–1 MHz is selected as the test excitation. The frequency-domain voltage signals acquired from the test points are used as positive samples. The method of establishing the FSG and FSP state detection models is similar, and are not described in this paper.
The detection accuracy at 40% and 50% failures in
Table 2 are averaged as the average detection rate of the TSG model, as shown in
Table 3. The D–S evidence body
is established according to
Table 3.
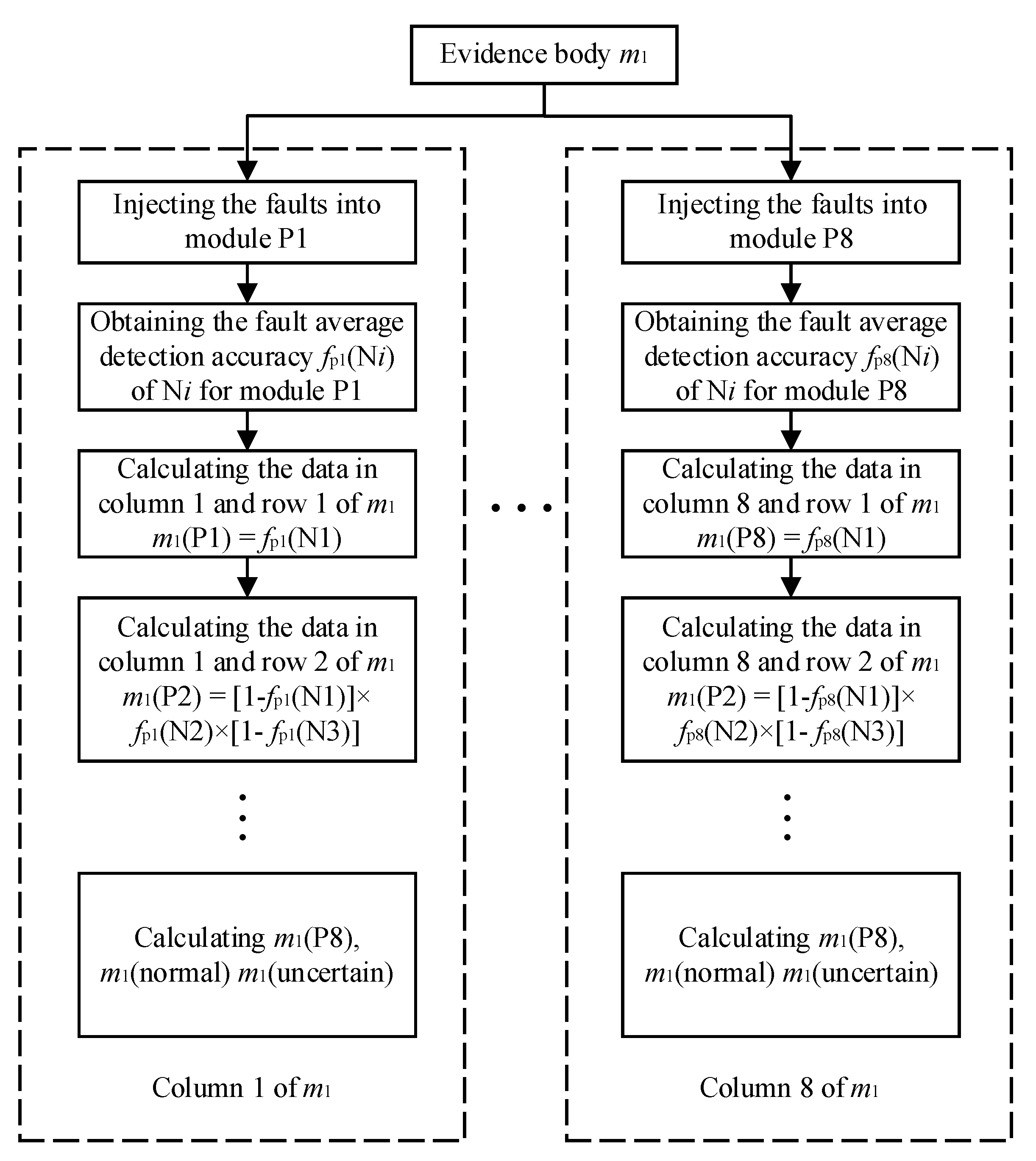
Step 1: when constructing the first column of data for the evidence body
, we assume that module P1 is faulty. According to the fault detection result of
Table 3, the fault average detection rate of the node N1 is expressed as the probability of the model detection of abnormality at N1. It indicates the support degree of the TSG state detection for module P1 failure, recorded as
(P1) = 0.9792. This value is the data in column 1 and row 1 of the evidence body
.
Step 2: calculate the support degree of the TSG state detection for module P2 failure. It is equal to the probability that the node N1 detection result is normal, the node N2 result is abnormal, and the node N3 result is normal. (P2) = (1 − 0.9792) × 0.7511 × (1 − 0.3303) = 0.0105. It is the data in column 1 and row 2 of .
Step 3: calculate the support degree of the TSG state detection for module P3 failure. It is equal to the probability that the node N1 detection result is normal, the node N2 result is normal, and the node N3 result is abnormal. (P3) = (1 − 0.9792) × (1 − 0.7511) × 0.3303 = 0.0017. It is the data in column 1 and row 3 of .
Step 4: calculate the support degree of the TSG state detection for module P4 failure. It is equal to the probability that the nodes N1, N2 and N3 detection results are normal, the node N4 result is abnormal. (P4) = (1 − 0.9792) × (1 − 0.7511) × (1 − 0.3303) × 0.1952 = 0.0000. It is the data in column 1 and row 4 of .
Step 5: calculate the support degree of the TSG state detection for module P5 failure. It is equal to the probability that the nodes N1, N2, N3 and N4 detection results are normal, the node N5 result is abnormal. (P5) = (1 − 0.9792) × (1 − 0.7511) × (1 − 0.3303) × (1 − 0.1952) × 0.1189 = 0.0000. It is the data in column 1 and row 5 of .
Step 6: calculate the support degree of the TSG state detection for fault-free state. It is equal to the probability that the nodes N1, N2, N3, N4 and N5 detection results are all normal. (normal) = (1 − 0.9792) × (1 − 0.7511) × (1 − 0.3303) × (1 − 0.1952) × (1 − 0.1189) = 0.0025. It is the data in column 1 and row 6 of .
Step 7: Calculate the support degree of the TSG state detection for uncertain state. It is equal to the probability that nodes N1, N4 and N5 detection results are normal, nodes N2 and N3 detection results are abnormal. (uncertain) = (1 − 0.9792) × 0.7511 × 0.3303 × (1 − 0.1952) × (1 − 0.1189) = 0.0052. It value is the data in column 1 and row 7 of .
At this point, the first column of values in the evidence body
was constructed, which is named as P1-fault evidence in
. The construction of other evidence is similar to the above process. The evidence bodies
,
,
and
are shown in
Table 4,
Table 5,
Table 6 and
Table 7.
In the actual detection process, four state detection models are used to judge the working state of each circuit module. The position of the fault circuit module is initially determined using the SLDM. It is easy to find the column corresponding to the fault in the evidence body. This column serves as a piece of evidence for the state detection model. Finally, the four pieces of evidences obtained are fused using Formula (13). The location of the fault module is determined by .
The following is a detailed introduction to the use of evidence: if the fault location result of TSG model using SLDM is module P3, the third column in the evidence body will be taken as the first piece of evidence. Similarly, if the fault location result of TSP model is module P2, the second column in the evidence body will be taken as the second piece of evidence. According to the same method, if the fault location result of the FSG model is module P3, the third column in the evidence body will be taken as the third evidence. If the fault location result of the FSG model is normal state, the sixth column in the evidence body will be taken as the fourth evidence.
The result of the fusion using the D–S evidence theory is the last column of
Table 8, which is calculated by Formula (13). Among them, 0.6960 is the maximum, which is far more than the second largest number of 0.1668. At the same time,
meets FMD principle mentioned in
Section 3.3. It indicates that circuit module P3 is fault. Although the fault location results of the four state detection models are not the same, the final diagnosis result is still module P3, which is consistent with our assumptions. Therefore, D–S evidence theory increases the error-tolerant rate of the single detection model, making the final diagnosis more reliable.
We established the fault diagnosis model of dual bandpass filter circuit. Next, we will test the accuracy of the fault diagnosis model through simulation and hardware experiment.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}