
Weed Classification Using Explainable Multi-Resolution Slot Attention

 , , ,
, , ,  and
and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Utilized Datasets
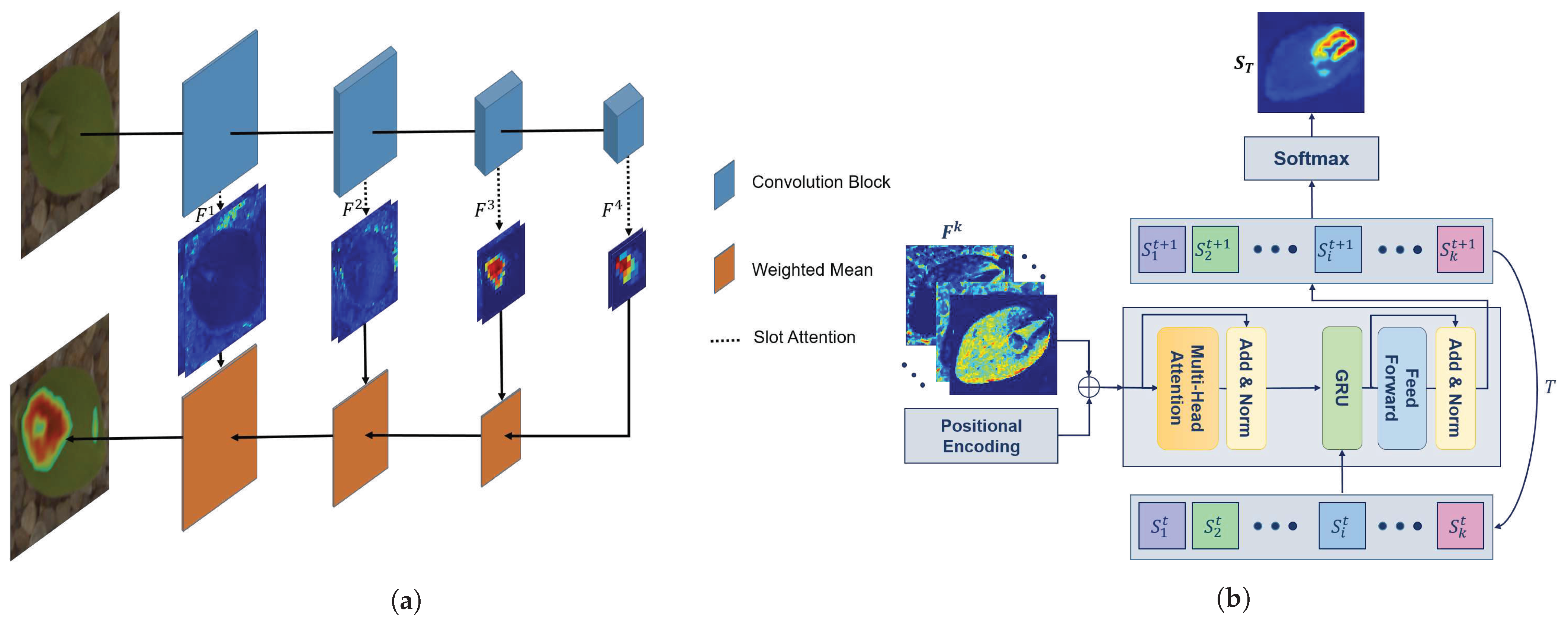
2.2. Neural Network Architecture
2.2.1. Slot Attention
2.2.2. Fusion Rule
2.2.3. Loss
2.3. Parameter Setting
3. Results
3.1. Multi-Resolution Attention
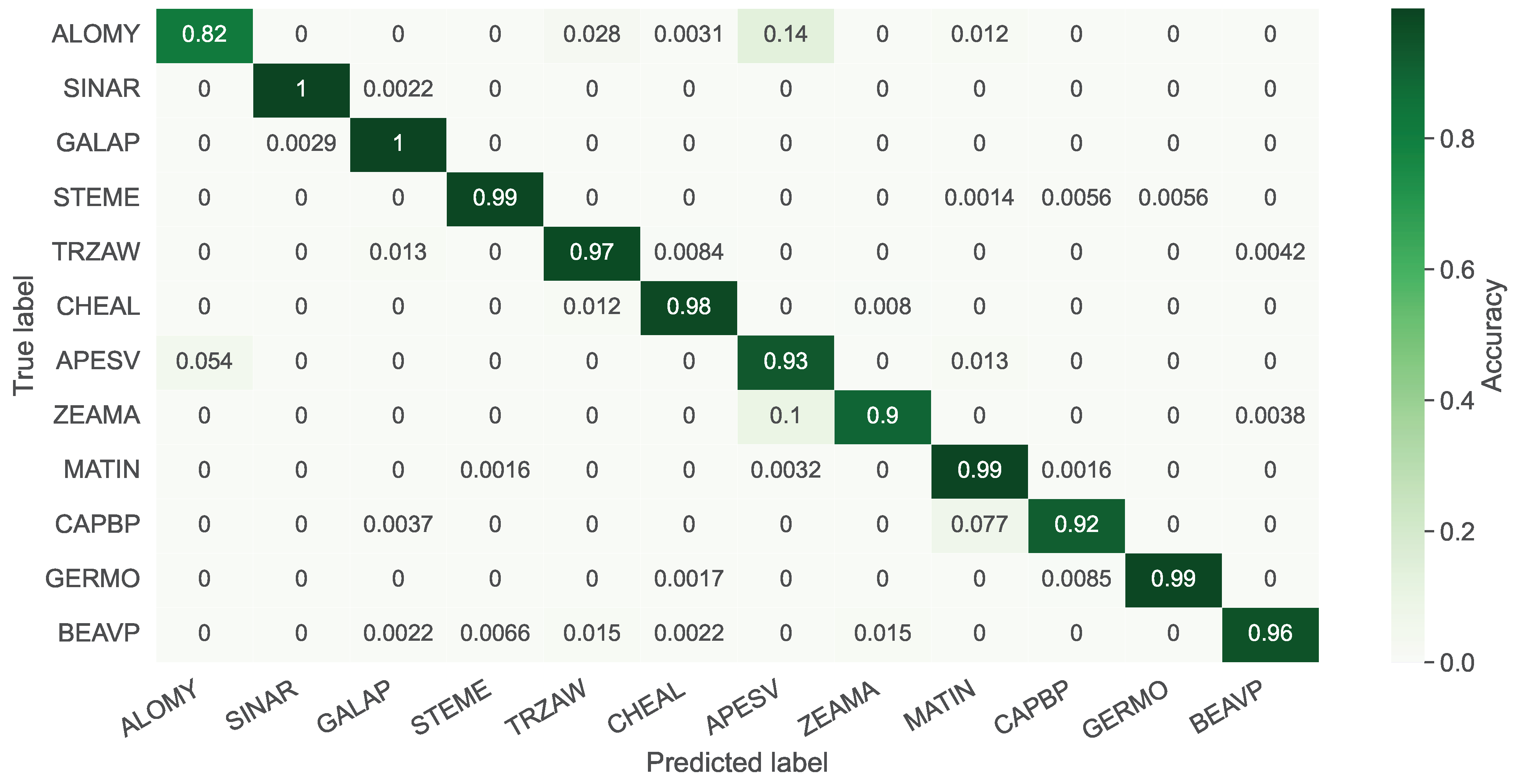
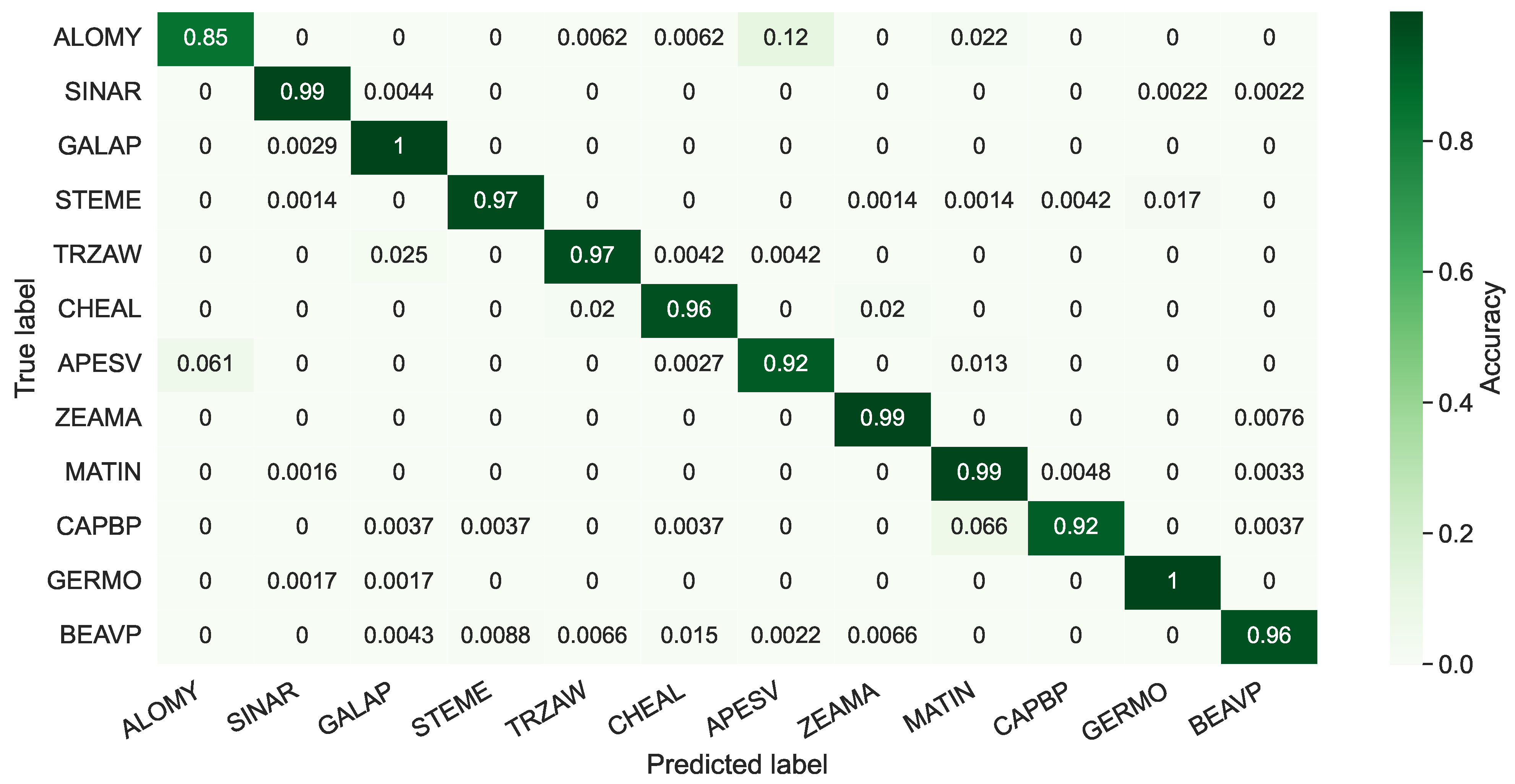
3.2. Evaluations on the PSD
3.3. Evaluations on PSD and OPPD
4. Discussion
- 1.
- Growth stage;
- 2.
- Partial or heavy occlusion;
- 3.
- Partial plant appearance.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| CNN | Convolutional neural network |
| D | Dicot |
| DNN | Deep neural network |
| EPPO | European and Mediterranean Plant Protection Organization |
| GRU | Gated recurrent unit |
| M | Monocot |
| MLP | Multi-layer perceptron |
| OPPD | Open Plant Phenotyping Dataset |
| PSD | Plant Seedlings Dataset |
| ReLU | Rectified linear unit |
| WIK | Weed identification key |
| XAI | Explainable artificial intelligence |
References
- Singh, C.B. Grand Challenges in Weed Management. Front. Agron. 2020, 1. [Google Scholar] [CrossRef]
- Sharma, A.; Shukla, A.; Attri, K.; Kumar, M.; Kumar, P.; Suttee, A.; Singh, G.; Barnwal, R.P.; Singla, N. Global trends in pesticides: A looming threat and viable alternatives. Ecotoxicol. Environ. Saf. 2020, 201, 110812. [Google Scholar] [CrossRef]
- Abbas, T.; Zahir, Z.A.; Naveed, M. Field application of allelopathic bacteria to control invasion of little seed canary grass in wheat. Environ. Sci. Pollut. Res. 2021, 28, 9120–9132. [Google Scholar] [CrossRef]
- Ren, W.; Banger, K.; Tao, B.; Yang, J.; Huang, Y.; Tian, H. Global pattern and change of cropland soil organic carbon during 1901–2010: Roles of climate, atmospheric chemistry, land use and management. Geogr. Sustain. 2020, 1, 59–69. [Google Scholar] [CrossRef]
- Maggipinto, M.; Beghi, A.; McLoone, S.; Susto, G. DeepVM: A Deep Learning-based Approach with Automatic Feature Extraction for 2D Input Data Virtual Metrology. J. Process. Control 2019, 84, 24–34. [Google Scholar] [CrossRef]
- Bručienė, I.; Aleliūnas, D.; Šarauskis, E.; Romaneckas, K. Influence of Mechanical and Intelligent Robotic Weed Control Methods on Energy Efficiency and Environment in Organic Sugar Beet Production. Agriculture 2021, 11, 449. [Google Scholar] [CrossRef]
- Veeranampalayam Sivakumar, A.N.; Li, J.; Scott, S.; Psota, E.; Jhala, A.J.; Luck, J.D.; Shi, Y. Comparison of object detection and patch-based classification deep learning models on mid-to late-season weed detection in UAV imagery. Remote Sens. 2020, 12, 2136. [Google Scholar] [CrossRef]
- Olsen, A. Improving the Accuracy of Weed Species Detection for Robotic Weed Control in Complex Real-Time Environments. Ph.D. Thesis, James Cook University, Queensland, Australia, 2020. [Google Scholar]
- Schwarzländer, M.; Hinz, H.L.; Winston, R.; Day, M. Biological control of weeds: An analysis of introductions, rates of establishment and estimates of success, worldwide. BioControl 2018, 63, 319–331. [Google Scholar] [CrossRef] [Green Version]
- Gonzalez-de Santos, P.; Ribeiro, A.; Fernandez-Quintanilla, C.; Lopez-Granados, F.; Brandstoetter, M.; Tomic, S.; Pedrazzi, S.; Peruzzi, A.; Pajares, G.; Kaplanis, G.; et al. Fleets of robots for environmentally-safe pest control in agriculture. Precis. Agric. 2017, 18, 574–614. [Google Scholar] [CrossRef]
- Awan, A.F. Multi-Sensor Weed Classification Using Deep Feature Learning. Ph.D. Thesis, Australian Defence Force Academy, Canberra, Australia, 2020. [Google Scholar]
- Dyrmann, M.; Mortensen, A.K.; Midtiby, H.S.; Jørgensen, R.N. Pixel-wise classification of weeds and crops in images by using a Fully Convolutional neural network. In Proceedings of the International Conference on Agricultural Engineering, Aarhus, Denmark, 26–29 June 2016. [Google Scholar]
- Skovsen, S.; Dyrmann, M.; Mortensen, A.K.; Laursen, M.S.; Gislum, R.; Eriksen, J.; Farkhani, S.; Karstoft, H.; Jorgensen, R.N. The GrassClover Image Dataset for Semantic and Hierarchical Species Understanding in Agriculture. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Seattle, WA, USA, 14–19 June 2019. [Google Scholar]
- Lu, Y.; Young, S. A survey of public datasets for computer vision tasks in precision agriculture. Comput. Electron. Agric. 2020, 178, 105760. [Google Scholar] [CrossRef]
- Wang, Y.; Fang, Z.; Wang, M.; Peng, L.; Hong, H. Comparative study of landslide susceptibility mapping with different recurrent neural networks. Comput. Geosci. 2020, 138, 104445. [Google Scholar] [CrossRef]
- Rai, A.K.; Mandal, N.; Singh, A.; Singh, K.K. Landsat 8 OLI Satellite Image Classification Using Convolutional Neural Network. Procedia Comput. Sci. 2020, 167, 987–993. [Google Scholar] [CrossRef]
- Castañeda-Miranda, A.; Castaño-Meneses, V.M. Internet of things for smart farming and frost intelligent control in greenhouses. Comput. Electron. Agric. 2020, 176, 105614. [Google Scholar] [CrossRef]
- Büyükşahin, Ü.Ç.; Ertekin, Ş. Improving forecasting accuracy of time series data using a new ARIMA-ANN hybrid method and empirical mode decomposition. Neurocomputing 2019, 361, 151–163. [Google Scholar] [CrossRef] [Green Version]
- Farkhani, S.; Skovsen, S.K.; Mortensen, A.K.; Laursen, M.S.; Jørgensen, R.N.; Karstoft, H. Initial evaluation of enriching satellite imagery using sparse proximal sensing in precision farming. In Proceedings of the Remote Sensing for Agriculture, Ecosystems, and Hydrology XXII, London, UK, 20–25 September 2020; SPIE: Bellingham, WA, USA, 2020; Volume 11528, pp. 58–70. [Google Scholar]
- Jiang, H.; Zhang, C.; Qiao, Y.; Zhang, Z.; Zhang, W.; Song, C. CNN feature based graph convolutional network for weed and crop recognition in smart farming. Comput. Electron. Agric. 2020, 174, 105450. [Google Scholar] [CrossRef]
- Sharma, A.; Jain, A.; Gupta, P.; Chowdary, V. Machine learning applications for precision agriculture: A comprehensive review. IEEE Access 2020, 9, 4843–4873. [Google Scholar] [CrossRef]
- Hasan, A.M.; Sohel, F.; Diepeveen, D.; Laga, H.; Jones, M.G. A survey of deep learning techniques for weed detection from images. Comput. Electron. Agric. 2021, 184, 106067. [Google Scholar] [CrossRef]
- Chandra, A.L.; Desai, S.V.; Guo, W.; Balasubramanian, V.N. Computer vision with deep learning for plant phenotyping in agriculture: A survey. arXiv 2020, arXiv:2006.11391. [Google Scholar]
- Masuda, K.; Suzuki, M.; Baba, K.; Takeshita, K.; Suzuki, T.; Sugiura, M.; Niikawa, T.; Uchida, S.; Akagi, T. Noninvasive Diagnosis of Seedless Fruit Using Deep Learning in Persimmon. Hortic. J. 2021, 90, 172–180. [Google Scholar] [CrossRef]
- Leggett, R.; Kirchoff, B.K. Image use in field guides and identification keys: Review and recommendations. AoB Plants 2011, 2011, plr004. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, L.; Wang, B.; Verma, M.; Nakashima, Y.; Kawasaki, R.; Nagahara, H. SCOUTER: Slot attention-based classifier for explainable image recognition. arXiv 2020, arXiv:2009.06138. [Google Scholar]
- Locatello, F.; Weissenborn, D.; Unterthiner, T.; Mahendran, A.; Heigold, G.; Uszkoreit, J.; Dosovitskiy, A.; Kipf, T. Object-centric learning with slot attention. arXiv 2020, arXiv:2006.15055. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A Survey on Visual Transformer. arXiv 2020, arXiv:2012.12556. [Google Scholar]
- Giselsson, T.M.; Dyrmann, M.; Jørgensen, R.N.; Jensen, P.K.; Midtiby, H.S. A Public Image Database for Benchmark of Plant Seedling Classification Algorithms. arXiv 2017, arXiv:1711.05458. [Google Scholar]
- Madsen, S.L.; Mathiassen, S.K.; Dyrmann, M.; Laursen, M.S.; Paz, L.C.; Jørgensen, R.N. Open Plant Phenotype Database of Common Weeds in Denmark. Remote Sens. 2020, 12, 1246. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Zhao, Q.; Sheng, T.; Wang, Y.; Tang, Z.; Chen, Y.; Cai, L.; Ling, H. M2det: A single-shot object detector based on multi-level feature pyramid network. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 9259–9266. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Vyas, A.; Katharopoulos, A.; Fleuret, F. Fast transformers with clustered attention. arXiv 2020, arXiv:2007.04825. [Google Scholar]
- Yu, Y.; Si, X.; Hu, C.; Zhang, J. A review of recurrent neural networks: LSTM cells and network architectures. Neural Comput. 2019, 31, 1235–1270. [Google Scholar] [CrossRef] [PubMed]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Ofori, M.; El-Gayar, O. An Approach for Weed Detection Using CNNs And Transfer Learning. In Proceedings of the 54th Hawaii International Conference on System Sciences, Hawaii, HI, USA, 5–8 January 2021; p. 888. [Google Scholar]
- Gupta, K.; Rani, R.; Bahia, N.K. Plant-Seedling Classification Using Transfer Learning-Based Deep Convolutional Neural Networks. Int. J. Agric. Environ. Inf. Syst. 2020, 11, 25–40. [Google Scholar] [CrossRef]
- Haoyu, L.; Rui, F. Weed Seeding Recognition Based on Multi-Scale Fusion Convolutional Neutral Network. Comput. Sci. Appl. 2020, 10, 2406. [Google Scholar]
- Zhang, P.; Dai, X.; Yang, J.; Xiao, B.; Yuan, L.; Zhang, L.; Gao, J. Multi-scale vision longformer: A new vision transformer for high-resolution image encoding. arXiv 2021, arXiv:2103.15358. [Google Scholar]
- Caron, M.; Touvron, H.; Misra, I.; Jégou, H.; Mairal, J.; Bojanowski, P.; Joulin, A. Emerging properties in self-supervised vision transformers. arXiv 2021, arXiv:2104.14294. [Google Scholar]
- Tian, C.; Xu, Y.; Li, Z.; Zuo, W.; Fei, L.; Liu, H. Attention-guided CNN for image denoising. Neural Netw. 2020, 124, 117–129. [Google Scholar] [CrossRef]
- Chen, G.; Li, C.; Wei, W.; Jing, W.; Woźniak, M.; Blažauskas, T.; Damaševičius, R. Fully convolutional neural network with augmented atrous spatial pyramid pool and fully connected fusion path for high resolution remote sensing image segmentation. Appl. Sci. 2019, 9, 1816. [Google Scholar] [CrossRef] [Green Version]
- Tay, Y.; Dehghani, M.; Aribandi, V.; Gupta, J.; Pham, P.; Qin, Z.; Bahri, D.; Juan, D.C.; Metzler, D. Omninet: Omnidirectional representations from transformers. arXiv 2021, arXiv:2103.01075. [Google Scholar]
- Brdar, M.; Brdar-Szabó, R.; Perak, B. Separating (non-) figurative weeds from wheat. In Figurative Meaning Construction in Thought and Language; John Benjamins Publishing Company: Amsterdam, The Netherlands, 2020; pp. 46–70. Available online: https://benjamins.com/catalog/ftl.9.02brd (accessed on 17 September 2021).
- Saikawa, T.; Cap, Q.H.; Kagiwada, S.; Uga, H.; Iyatomi, H. AOP: An anti-overfitting pretreatment for practical image-based plant diagnosis. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 5177–5182. [Google Scholar]
- Takahashi, Y.; Dooliokhuu, M.; Ito, A.; Murata, K. How to Improve the Performance of Agriculture in Mongolia by ICT. Applied Studies in Agribusiness and Commerce. Ph.D. Thesis, University of Debrecen, Debrecen, Hungary, 2019. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| EPPO Code | English Name | Mono/Dicot |
|---|---|---|
| ALOMY | Black grass | M |
| APESV | Loose silky-bent | M |
| BEAVP | Sugar beet | D |
| CAPBP | Shepherd’s purse | D |
| CHEAL | Fat hen | D |
| GALAP | Cleavers | D |
| GERMO | Small-flowered crane’s bill | D |
| MATIN | Scentless mayweed | D |
| SINAR | Charlock | D |
| STEME | Common chickweed | D |
| TRZAW | Common wheat | D |
| ZEAMA | Maize | M |
| Dataset | Accuracy (%) | Parameters (M) | |
|---|---|---|---|
| EffNet [39] | OPPD | 95.44 | 7.8 |
| ResNet50 [40] | OPPD | 95.23 | 25 |
| Ours− | OPPD | 95.42 | 23.98 |
| Ours+ | OPPD | 96.00 | 23.98 |
| SE-Module [41] | PSD | 96.32 | 1.79 |
| Ours− | PSD | 97.78 | 23.54 |
| Ours+ | PSD | 97.83 | 23.54 |
| Original Image | Positive Attention | Negative Attention | |||||||
|---|---|---|---|---|---|---|---|---|---|
| ALOMY | SINAR | GALAP | STEME | GERMO | APESV | CAPBP | MATIN | ||
 |  |  |  |  |  |  |  |  |  |
 |  |  |  |  |  |  |  |  |  |
 |  |  |  |  |  |  |  |  |  |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Farkhani, S.; Skovsen, S.K.; Dyrmann, M.; Jørgensen, R.N.; Karstoft, H. Weed Classification Using Explainable Multi-Resolution Slot Attention. Sensors 2021, 21, 6705. https://doi.org/10.3390/s21206705
Farkhani S, Skovsen SK, Dyrmann M, Jørgensen RN, Karstoft H. Weed Classification Using Explainable Multi-Resolution Slot Attention. Sensors. 2021; 21(20):6705. https://doi.org/10.3390/s21206705
Chicago/Turabian StyleFarkhani, Sadaf, Søren Kelstrup Skovsen, Mads Dyrmann, Rasmus Nyholm Jørgensen, and Henrik Karstoft. 2021. "Weed Classification Using Explainable Multi-Resolution Slot Attention" Sensors 21, no. 20: 6705. https://doi.org/10.3390/s21206705