
Hyperspectral Image Classification Using Deep Genome Graph-Based Approach


Abstract
:1. Introduction
2. Literature Review
2.1. Extraction and Learning in the HSIC Process
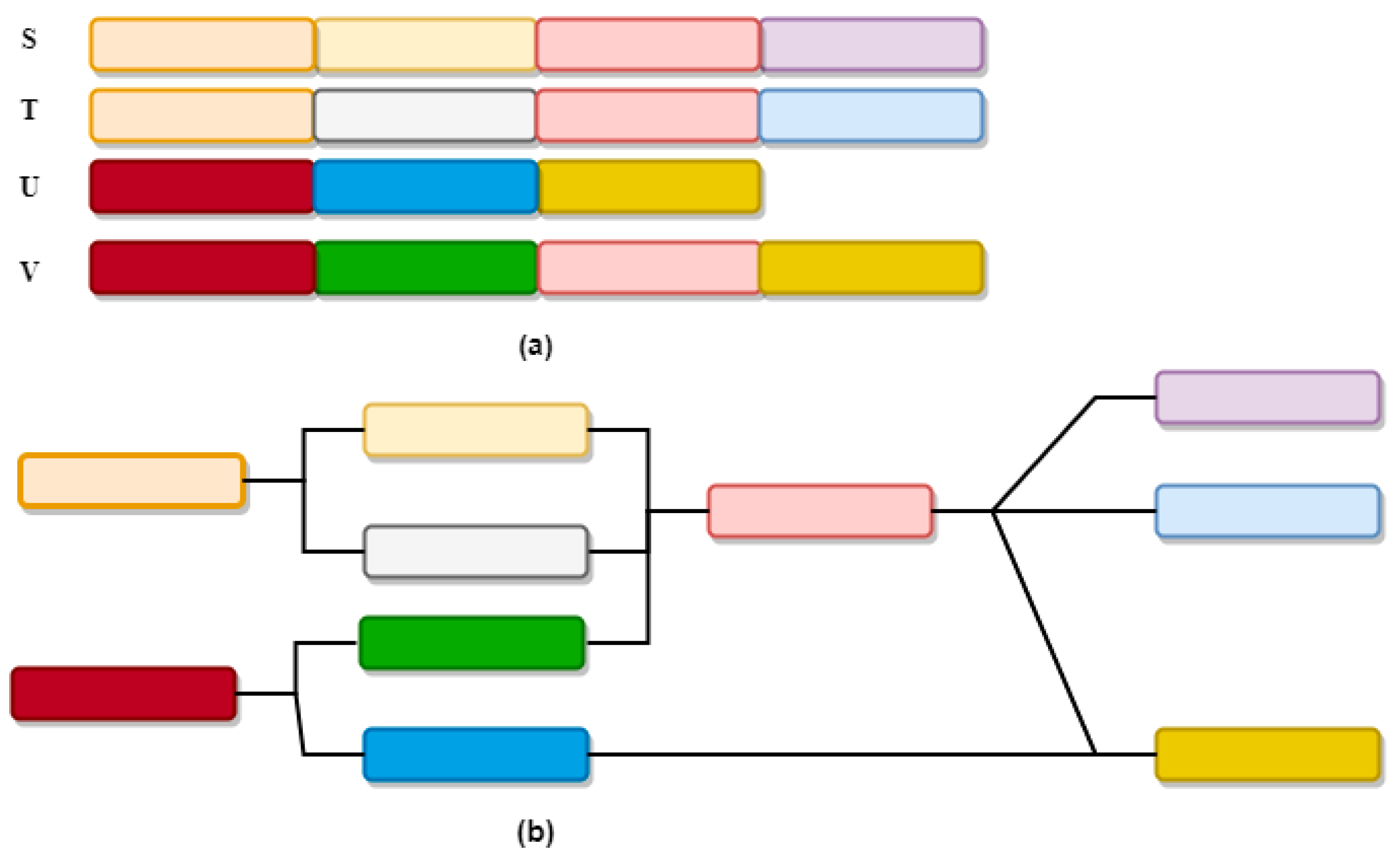
2.2. The Biological Genome Graphs
3. The Proposed Model Framework
3.1. The Preprocessing Section
| Algorithm 1: Principle Component Analysis (PCA) | |
| 1 | Input: Original Hyperspectral image , M pixels, L spectral bands. |
| 2 | Centre and standardize , putting it into matrix . |
| 3 | Compute the covariance matrix |
| 4 | Compute the eigenvalues and eigenvector of C, such that , where holds the eigenvectors of , and is the diagonal eigenvalue matrix. |
| 5 | Sort D into the order of decreasing eigenvalues, and apply the same order to V. |
| 6 | Eigenvalues less than some are rejected, leaving D dimensions in data which is the new dimensional feature subspace. |
| 7 | Output: Reduced Hyperspectral image , where and . |
3.2. Genome Graph-Based Network (GGBN)
4. Materials and Methods
4.1. Description
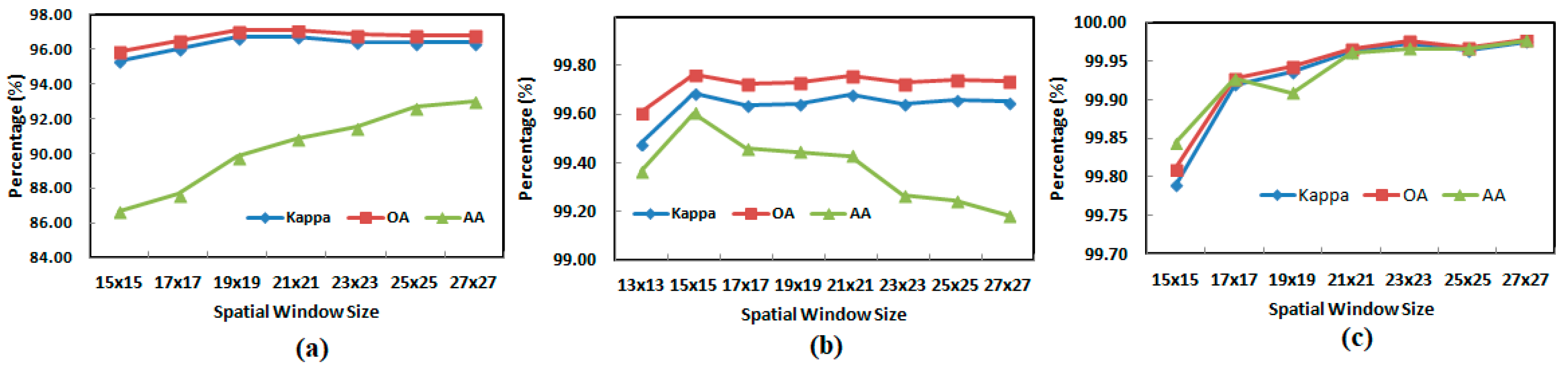
4.2. Parameter Settings
5. Experimental Results and Discussion
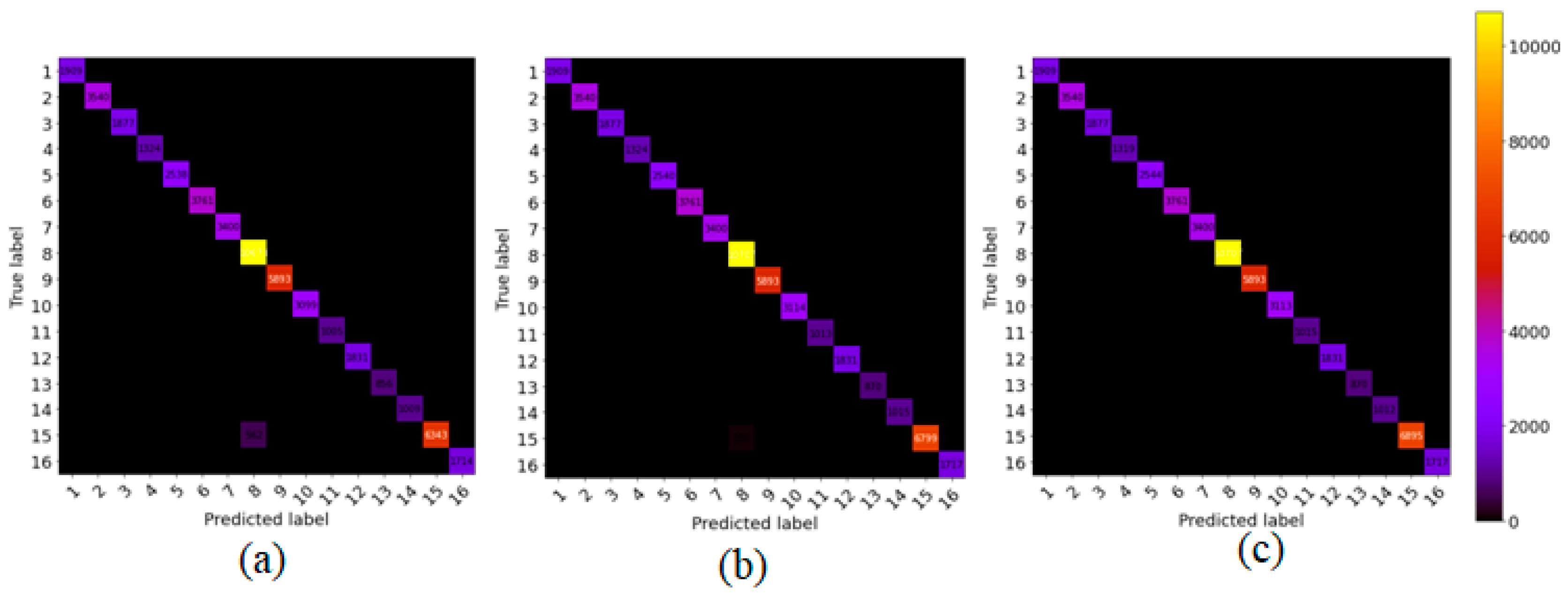
5.1. Classification Results for the Indian Pines (IP) Dataset
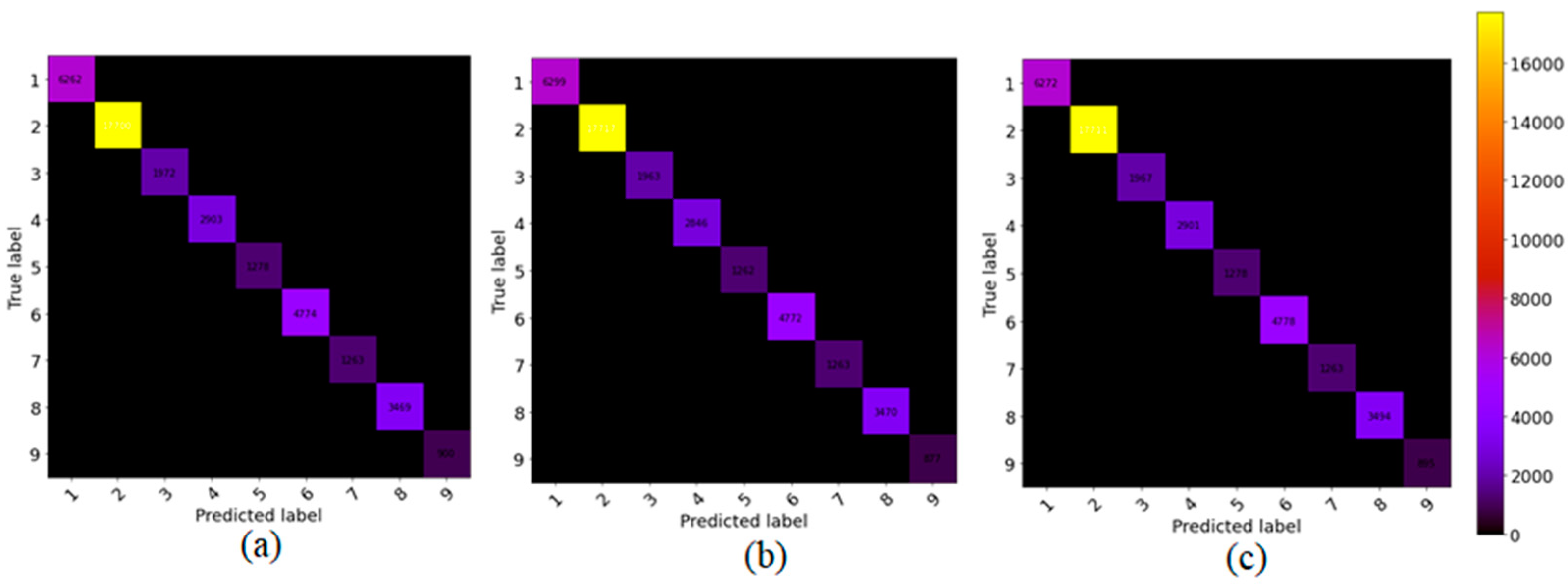
5.2. Classification Results for the University of Pavia (UP) Dataset
5.3. Classification Results for the Salina Scene (SA) Dataset
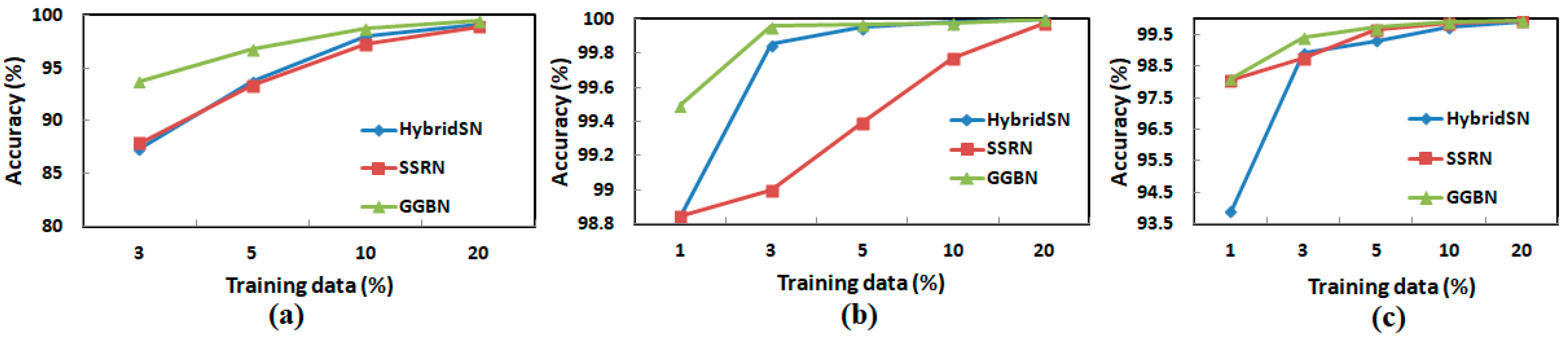
5.4. Model Performance on Varied Training Sample Data over IP, UP, and SA Datasets
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Paoletti, M.E.; Haut, J.M.; Plaza, J.; Plaza, A. ISPRS Journal of Photogrammetry and Remote Sensing Deep learning classifiers for hyperspectral imaging: A review. ISPRS J. Photogramm. Remote Sens. 2019, 158, 279–317. [Google Scholar] [CrossRef]
- Ghamisi, P.; Yokoya, N.; Li, J.; Liao, W.; Liu, S.; Plaza, J.; Rasti, B.; Plaza, A. Advances in Hyperspectral Image and Signal Processing: A Comprehensive Overview of the State of the Art. IEEE Geosci. Remote Sen. Mag. 2017, 5, 37–78. [Google Scholar] [CrossRef] [Green Version]
- Chen, M.; Tang, Y.; Zou, X.; Huang, K.; Li, L.; He, Y. High-accuracy multi-camera reconstruction enhanced by adaptive point cloud correction algorithm. Opt. Lasers Eng. 2019, 122, 170–183. [Google Scholar] [CrossRef]
- Zhang, B.; Wu, D.; Zhang, L.; Jiao, Q.; Li, Q. Application of hyperspectral remote sensing for environment monitoring in mining areas. Environ. Earth Sci. 2012, 65, 649–658. [Google Scholar] [CrossRef]
- Du, B.; Zhang, Y.; Zhang, L.; Tao, D. Beyond the Sparsity-Based Target Detector: A Hybrid Sparsity and Statistics-Based Detector for Hyperspectral Images. IEEE Trans. Image Process. 2016, 25, 5345–5357. [Google Scholar] [CrossRef] [PubMed]
- Murphy, R.J.; Monteiro, S.T.; Schneider, S. Evaluating classification techniques for mapping vertical geology using field-based hyperspectral sensors. IEEE Trans. Geosci. Remote Sens. 2012, 50, 3066–3080. [Google Scholar] [CrossRef]
- Zhang, M.; Hu, C.; Kowalewski, M.G.; Janz, S.J. Atmospheric correction of hyperspectral GCAS airborne measurements over the north atlantic ocean and Louisiana shelf. IEEE Trans. Geosci. Remote Sens. 2018, 56, 168–179. [Google Scholar] [CrossRef]
- Chen, M.; Tang, Y.; Zou, X.; Huang, Z.; Zhou, H.; Chen, S. 3D global mapping of large-scale unstructured orchard integrating eye-in-hand stereo vision and SLAM. Comput. Electron. Agric. 2021, 187, 106237. [Google Scholar] [CrossRef]
- Hao, S.; Wang, W.; Ye, Y.; Nie, T.; Bruzzone, L. Two-stream deep architecture for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2349–2361. [Google Scholar] [CrossRef]
- Rakocevic, G.; Semenyuk, V.; Lee, W.-P.; Spencer, J.; Browning, J.; Johnson, I.J.; Arsenijevic, V.; Nadj, J.; Ghose, K.; Kural, D.; et al. Fast and accurate genomic analyses using genome graphs. Nat. Genet. 2019, 51, 354–362. [Google Scholar] [CrossRef]
- Schatz, M.C.; Witkowski, J.; McCombie, W.R. Current challenges in de novo plant genome sequencing and assembly. Genome Biol. 2012, 13, 243. [Google Scholar] [CrossRef] [PubMed]
- Roy, S.K.; Krishna, G.; Dubey, S.R.; Chaudhuri, B.B. HybridSN: Exploring 3-D-2-D CNN Feature Hierarchy for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2019, 17, 277–281. [Google Scholar] [CrossRef] [Green Version]
- Villa, A.; Benediktsson, J.A.; Chanussot, J.; Jutten, C. Hyperspectral image classification with Independent component discriminant analysis. IEEE Trans. Geosci. Remote Sens. 2011, 49, 4865–4876. [Google Scholar] [CrossRef] [Green Version]
- Bandos, T.V.; Bruzzone, L.; Camps-Valls, G. Classification of hyperspectral images with regularized linear discriminant analysis. IEEE Trans. Geosci. Remote Sens. 2009, 47, 862–873. [Google Scholar] [CrossRef]
- Prasad, S.; Bruce, L.M. Limitations of principal components analysis for hyperspectral target recognition. IEEE Geosci. Remote Sens. Lett. 2008, 5, 625–629. [Google Scholar] [CrossRef]
- Licciardi, G.; Marpu, P.R.; Chanussot, J.; Benediktsson, J.A. Linear versus nonlinear PCA for the classification of hyperspectral data based on the extended morphological profiles. IEEE Geosci. Remote Sens. Lett. 2012, 9, 447–451. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Bioucas-Dias, J.M.; Plaza, A. Semisupervised hyperspectral image segmentation using multinomial logistic regression with active learning. IEEE Trans. Geosci. Remote Sens. 2010, 48, 4085–4098. [Google Scholar] [CrossRef] [Green Version]
- Melgani, F.; Bruzzone, L. Classification of hyperspectral remote sensing images with support vector machines. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1778–1790. [Google Scholar] [CrossRef] [Green Version]
- Du, B.; Zhang, L. Random-selection-based anomaly detector for hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2011, 49, 1578–1589. [Google Scholar] [CrossRef]
- Zhong, Y.; Zhang, L. An adaptive artificial immune network for supervised classification of multi-/hyperspectral remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2012, 50, 894–909. [Google Scholar] [CrossRef]
- He, L.; Li, J.; Liu, C.; Li, S. Recent Advances on Spectral-Spatial Hyperspectral Image Classification: An Overview and New Guidelines. IEEE Trans. Geosci. Remote Sens. 2018, 56, 1579–1597. [Google Scholar] [CrossRef]
- Moser, G.; Serpico, S.B.; Benediktsson, J.A. Land-cover mapping by markov modeling of spatial-contextual information in very-high-resolution remote sensing images. Proc. IEEE 2013, 101, 631–651. [Google Scholar] [CrossRef]
- Camps-Valls, G.; Tuia, D.; Bruzzone, L.; Benediktsson, J.A. Advances in hyperspectral image classification: Earth monitoring with statistical learning methods. IEEE Signal Process. Mag. 2014, 31, 45–54. [Google Scholar] [CrossRef] [Green Version]
- Song, B.; Li, J.; Dalla Mura, M.; Li, P.; Plaza, A.; Bioucas-Dias, J.M.; Benediktsson, J.A.; Chanussot, J. Remotely sensed image classification using sparse representations of morphological attribute profiles. IEEE Trans. Geosci. Remote Sens. 2014, 52, 5122–5136. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef] [Green Version]
- Klosowski, P. Deep learning for natural language processing and language modelling. In Proceedings of the 2018 Signal Processing: Algorithms, Architectures, Arrangements, and Applications (SPA), Poznan, Poland, 19–21 September 2018; Volume 2018, pp. 223–228. [Google Scholar] [CrossRef]
- Yang, X.; Zhang, X.; Ye, Y.; Lau, R.Y.; Lu, S.; Li, X.; Huang, X. Synergistic 2D/3D convolutional neural network for hyperspectral image classification. Remote Sens. 2020, 12, 2033. [Google Scholar] [CrossRef]
- Chen, Y.; Jiang, H.; Li, C.; Jia, X.; Ghamisi, P. Deep Feature Extraction and Classification of Hyperspectral Images Based on Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Zhang, H.; Shen, Q. Spectral-spatial classification of hyperspectral imagery with 3D convolutional neural network. Remote Sens. 2017, 9, 67. [Google Scholar] [CrossRef] [Green Version]
- Hamida, A.B.; Benoit, A.; Lambert, P.; Amar, C.B. 3-D deep learning approach for remote sensing image classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4420–4434. [Google Scholar] [CrossRef] [Green Version]
- Consortium, G.P.; Auton, A.; Brooks, L.D.; Durbin, R.M.; Garrison, E.P.; Kang, H.M. A global reference for human genetic variation. Nature 2017, 526, 68–74. [Google Scholar] [CrossRef] [Green Version]
- Davidson, B.L. Doubling down on siRNAs in the brain. Nat. Biotechnol. 2019, 37, 865–866. [Google Scholar] [CrossRef]
- Kaul, S.; Koo, H.L.; Jenkins, J.; Rizzo, M.; Rooney, T.; Tallon, L.J.; Feldbyum, T.; Nierman, W.; Benito, M.I.; Lin, X.; et al. Analysis of the genome sequence of the flowering plant Arabidopsis thaliana. Nature 2000, 408, 796–815. [Google Scholar] [CrossRef] [Green Version]
- Schnable, P.S.; Ware, D.; Fulton, R.S.; Stein, J.C.; Wei, F.; Pasternak, S.; Liang, C.; Zhang, J.; Fulton, L.; Presting, G.G.; et al. The B73 maize genome: Complexity, diversity, and dynamics. Science 2009, 326, 1112–1115. [Google Scholar] [CrossRef] [Green Version]
- Sasaki, T. The map-based sequence of the rice genome. Nature 2005, 436, 793–800. [Google Scholar] [CrossRef] [PubMed]
- Ming, R.; Hou, S.; Feng, Y.; Yu, Q.; Dionne-Laporte, A.; Saw, J.H.; Senin, P.; Wang, W.; Ly, B.V.; Lewis, K.L.T.; et al. The draft genome of the transgenic tropical fruit tree papaya (Carica papaya Linnaeus). Nature 2008, 452, 991–996. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhou, X.; Ren, L.; Meng, Q.; Li, Y.; Yu, Y.; Yu, J. The next-generation sequencing technology and application. Protein Cell 2010, 1, 520–536. [Google Scholar] [CrossRef] [Green Version]
- Park, S.J.; Jiang, K.; Schatz, M.C.; Lippman, Z.B. Rate of meristem maturation determines inflorescence architecture in tomato. Proc. Natl. Acad. Sci. USA 2012, 109, 639–644. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Moose, S.P.; Mumm, R.H. Molecular plant breeding as the foundation for 21st century crop improvement. Plant Physiol. 2008, 147, 969–977. [Google Scholar] [CrossRef] [Green Version]
- Morrell, P.L.; Buckler, E.S.; Ross-Ibarra, J. Crop genomics: Advances and applications. Nat. Rev. Genet. 2012, 13, 85–96. [Google Scholar] [CrossRef]
- Meyers, L.A.; Levin, D.A. On the Abundance of Polyploids in Flowering Plants. Evolution 2006, 60, 1198–1206. [Google Scholar] [CrossRef]
- Yang, X.; Lee, W.P.; Ye, K.; Lee, C. One reference genome is not enough. Genome Biol. 2019, 20, 104. [Google Scholar] [CrossRef] [Green Version]
- Lee, C.; Grasso, C.; Sharlow, M.F. Multiple sequence alignment using partial order graphs. Bioinformatics 2002, 18, 452–464. [Google Scholar] [CrossRef] [PubMed]
- Ye, Y.; Godzik, A. Multiple flexible structure alignment using partial order graphs. Bioinformatics 2005, 21, 2362–2369. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, M.; Li, B.; Chen, H. Multi-scale 3D deep convolutional neural network for hyperspectral image classification. In Proceedings of the International Conference on Image Processing, ICIP, Beijing, China, 17–20 September 2017; pp. 3904–3908. [Google Scholar] [CrossRef]
- Zhong, Z.; Li, J.; Luo, Z.; Chapman, M. Spectral-Spatial Residual Network for Hyperspectral Image Classification: A 3-D Deep Learning Framework. IEEE Trans. Geosci. Remote Sens. 2018, 56, 847–858. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data | SSRN | HybridSN | GGBN | |||
|---|---|---|---|---|---|---|
| Train | Test | Train | Test | Train | Test | |
| IP | 70.9 | 1.5 | 36.9 | 2.7 | 163.5 | 2.5 |
| UP | 417.7 | 4.0 | 37.5 | 4.7 | 62.8 | 4.3 |
| SA | 527.7 | 4.9 | 45.4 | 5.6 | 227.8 | 7.4 |
| Class No. | Class Labels | Samples (Pixels) | Cover (%) | M3D-CNN (%) | SSRN (%) | HybridSN (%) | GGBN (%) |
|---|---|---|---|---|---|---|---|
| 1 | Alfalfa | 46 | 0.45 | 30.75 | 12.73 | 55.23 | 46.36 |
| 2 | Corn-no till | 1428 | 13.93 | 72.76 | 92.73 | 92.97 | 94.78 |
| 3 | Corn-min till | 830 | 8.1 | 61.76 | 93.59 | 90.18 | 98.38 |
| 4 | Corn | 237 | 2.31 | 57.46 | 72.80 | 84.22 | 94.49 |
| 5 | Grass-pasture | 483 | 4.71 | 85.19 | 98.19 | 94.01 | 99.15 |
| 6 | Grass-trees | 730 | 7.12 | 92.13 | 99.67 | 97.63 | 98.02 |
| 7 | Grass-pasture-mowed | 28 | 0.27 | 45.54 | 0.74 | 73.70 | 87.78 |
| 8 | Hay-windrowed | 478 | 4.66 | 94.01 | 99.82 | 99.76 | 99.85 |
| 9 | Oats | 20 | 0.2 | 20.45 | 0.00 | 88.95 | 78.95 |
| 10 | Soybean-no till | 972 | 9.48 | 70.97 | 91.54 | 95.41 | 97.82 |
| 11 | Soybean-min till | 2455 | 23.95 | 76.75 | 95.21 | 97.08 | 97.98 |
| 12 | Soybean-clean | 593 | 5.79 | 59.35 | 87.83 | 82.02 | 92.97 |
| 13 | Wheat | 205 | 2 | 94.36 | 98.62 | 94.31 | 97.64 |
| 14 | Woods | 1265 | 12.34 | 94.55 | 99.84 | 98.96 | 99.03 |
| 15 | Buildings-Grass-Trees-Drives | 386 | 3.77 | 51.21 | 83.68 | 79.84 | 92.29 |
| 16 | Stone-Steel-Towers | 93 | 0.91 | 64.39 | 81.25 | 77.61 | 88.75 |
| Kappa | 66.98 | 92.39 | 92.82 | 96.41 | |||
| OA | 76.09 | 93.35 | 93.72 | 96.85 | |||
| AA | 72.57 | 75.39 | 87.62 | 91.51 |
| Class No. | Class Labels | Samples (Pixels) | Cover (%) | M3D-CNN (%) | SSRN (%) | HybridSN (%) | GGBN (%) |
|---|---|---|---|---|---|---|---|
| 1 | Asphalt | 6631 | 15.5 | 95.44 | 99.65 | 99.55 | 99.58 |
| 2 | Meadows | 18,649 | 43.6 | 93.98 | 99.96 | 99.98 | 99.95 |
| 3 | Gravel | 2099 | 4.91 | 90.36 | 98.14 | 98.69 | 98.41 |
| 4 | Trees | 3064 | 7.16 | 97.37 | 99.67 | 98.20 | 99.43 |
| 5 | Painted_metal_sheets | 1345 | 3.14 | 99.75 | 100 | 98.85 | 99.95 |
| 6 | Bare_Soil | 5029 | 11.76 | 92.14 | 100 | 99.99 | 99.99 |
| 7 | Bitumen | 1330 | 3.11 | 92.62 | 99.59 | 99.89 | 99.99 |
| 8 | Self-Blocking_Bricks | 3682 | 8.61 | 94.62 | 98.56 | 97.42 | 99.47 |
| 9 | Shadows | 947 | 2.21 | 99.24 | 99.97 | 94.21 | 99.57 |
| Kappa | 95.06 | 99.57 | 99.10 | 99.65 | |||
| OA | 92.50 | 99.68 | 99.32 | 99.74 | |||
| AA | 90.19 | 99.50 | 98.46 | 99.59 |
| Class No. | Class Labels | Samples (Pixels) | Cover (%) | M3D-CNN (%) | SSRN (%) | HybridSN (%) | GGBN (%) |
|---|---|---|---|---|---|---|---|
| 1 | Brocoli_green_weeds | 2009 | 3.71 | 97.35 | 100.00 | 100.00 | 100.00 |
| 2 | Brocoli_green_weeds | 3726 | 6.88 | 99.81 | 99.99 | 100.00 | 100.00 |
| 3 | Fallow | 1976 | 3.65 | 97.98 | 100.00 | 100.00 | 100.00 |
| 4 | Fallow_rough_plow | 1394 | 2.58 | 99.21 | 99.85 | 99.95 | 99.99 |
| 5 | Fallow_smooth | 2678 | 4.95 | 99.18 | 99.76 | 99.71 | 99.54 |
| 6 | Stubble | 3959 | 7.31 | 99.17 | 100.00 | 99.97 | 99.98 |
| 7 | Celery | 3579 | 6.61 | 99.21 | 99.99 | 99.99 | 99.99 |
| 8 | Grapes_untrained_ | 11,271 | 20.82 | 87.9 | 99.29 | 99.99 | 100.00 |
| 9 | Soil_vinyard_develop | 6203 | 11.46 | 99.29 | 100.00 | 100.00 | 100.00 |
| 10 | Corn_senesced_green_weeds | 3278 | 6.06 | 94.13 | 99.82 | 99.98 | 100.00 |
| 11 | Lettuce_romaine_4wk | 1068 | 1.97 | 95.94 | 99.86 | 99.91 | 100.00 |
| 12 | Lettuce_romaine_5wk | 1927 | 3.56 | 98.11 | 100.00 | 100.00 | 100.00 |
| 13 | Lettuce_romaine_6wk | 916 | 1.69 | 97.4 | 99.92 | 99.87 | 99.99 |
| 14 | Lettuce_romaine_7wk | 1070 | 1.98 | 96.43 | 99.55 | 99.82 | 99.98 |
| 15 | Vinyard_untrained | 7268 | 13.43 | 79.97 | 96.99 | 99.87 | 99.96 |
| 16 | Vinyard_vertical_trellis | 1807 | 3.34 | 90.61 | 99.55 | 100.00 | 100.00 |
| Kappa | 95.73 | 99.32 | 99.95 | 99.96 | |||
| OA | 92.49 | 99.39 | 99.95 | 99.97 | |||
| AA | 91.66 | 99.66 | 99.94 | 99.96 |
| Model | Training Sample Data in Percentage | |||
|---|---|---|---|---|
| 3% | 5% | 10% | 20% | |
| M3D-CNN | 66.23 | 76.09 | 84.38 | 91.95 |
| SSRN | 87.89 | 93.35 | 97.30 | 98.93 |
| HybridSN | 87.35 | 93.72 | 97.97 | 99.16 |
| GGBN | 93.78 | 96.85 | 98.80 | 99.45 |
| Model | Training Sample Data in Percentage | ||||
|---|---|---|---|---|---|
| 1% | 3% | 5% | 10% | 20% | |
| M3D-CNN | 86.29 | 90.78 | 92.50 | 93.82 | 94.60 |
| SSRN | 98.07 | 98.78 | 99.68 | 99.88 | 99.96 |
| HybridSN | 93.88 | 98.92 | 99.32 | 99.73 | 99.92 |
| GGBN | 98.13 | 99.42 | 99.74 | 99.92 | 99.95 |
| Model | Training Sample Data in Percentage | ||||
|---|---|---|---|---|---|
| 1% | 3% | 5% | 10% | 20% | |
| M3D-CNN | 86.37 | 90.38 | 92.49 | 93.44 | 94.47 |
| SSRN | 98.85 | 99.00 | 99.39 | 99.77 | 99.97 |
| HybridSN | 98.85 | 99.85 | 99.95 | 99.98 | 100.00 |
| GGBN | 99.50 | 99.96 | 99.97 | 99.98 | 100.00 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tinega, H.; Chen, E.; Ma, L.; Mariita, R.M.; Nyasaka, D. Hyperspectral Image Classification Using Deep Genome Graph-Based Approach. Sensors 2021, 21, 6467. https://doi.org/10.3390/s21196467
Tinega H, Chen E, Ma L, Mariita RM, Nyasaka D. Hyperspectral Image Classification Using Deep Genome Graph-Based Approach. Sensors. 2021; 21(19):6467. https://doi.org/10.3390/s21196467
Chicago/Turabian StyleTinega, Haron, Enqing Chen, Long Ma, Richard M. Mariita, and Divinah Nyasaka. 2021. "Hyperspectral Image Classification Using Deep Genome Graph-Based Approach" Sensors 21, no. 19: 6467. https://doi.org/10.3390/s21196467