3.1. GraphNets for Arbitrary Inductive Biases
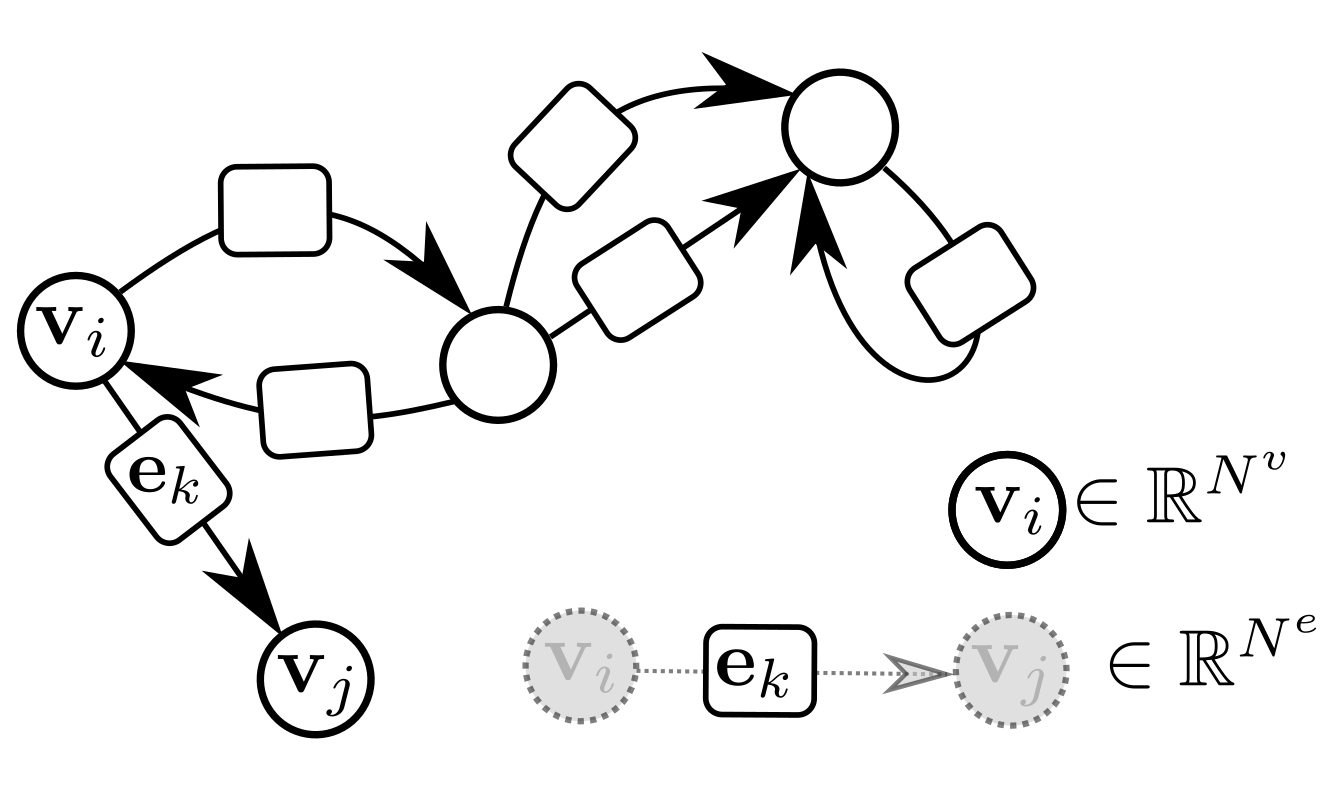
GraphNets (GNs) are a class of machine learning algorithms operating with (typically predefined) attributed graph data, which generalize several graph neural network architectures. An attributed graph, in essence, is a set of nodes (vertices)
and edges
, with
and
. Each edge is a triplet
(or equivalently
) and contains a reference to a receiver node
, a sender node
as well as a (vector) attribute
. Self-edges, i.e., when
are allowed. See
Figure 3 for an example of an attributed graph.
In [
6], a more general class of GraphNets is presented, where global variables which affect all nodes and edges are allowed. A GN with no global variables consists of a node-function
, an edge function
, and an edge aggregation function
. The function
should be (1) invariant to the permutation of its inputs and (2) able to accept a variable number of inputs. In what follows this will be referred to as the edge aggregation function. Simple valid aggregation functions are
,
,
and
. Inventing more general aggregation functions (for instance by combining them) and investigating how these affect the approximation properties of GNs currently forms an active research topic [
47].
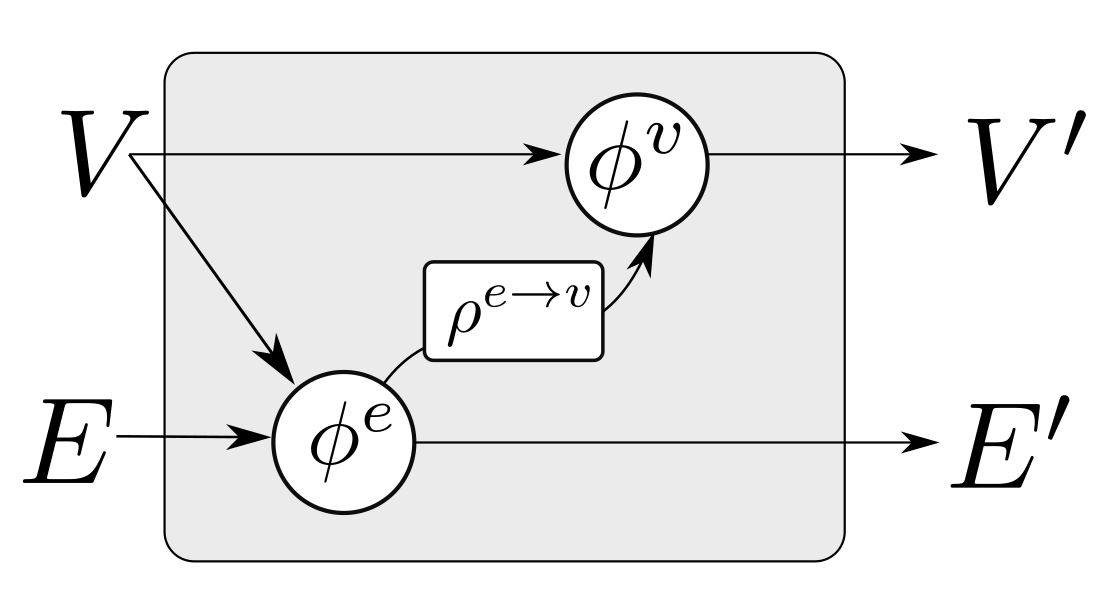
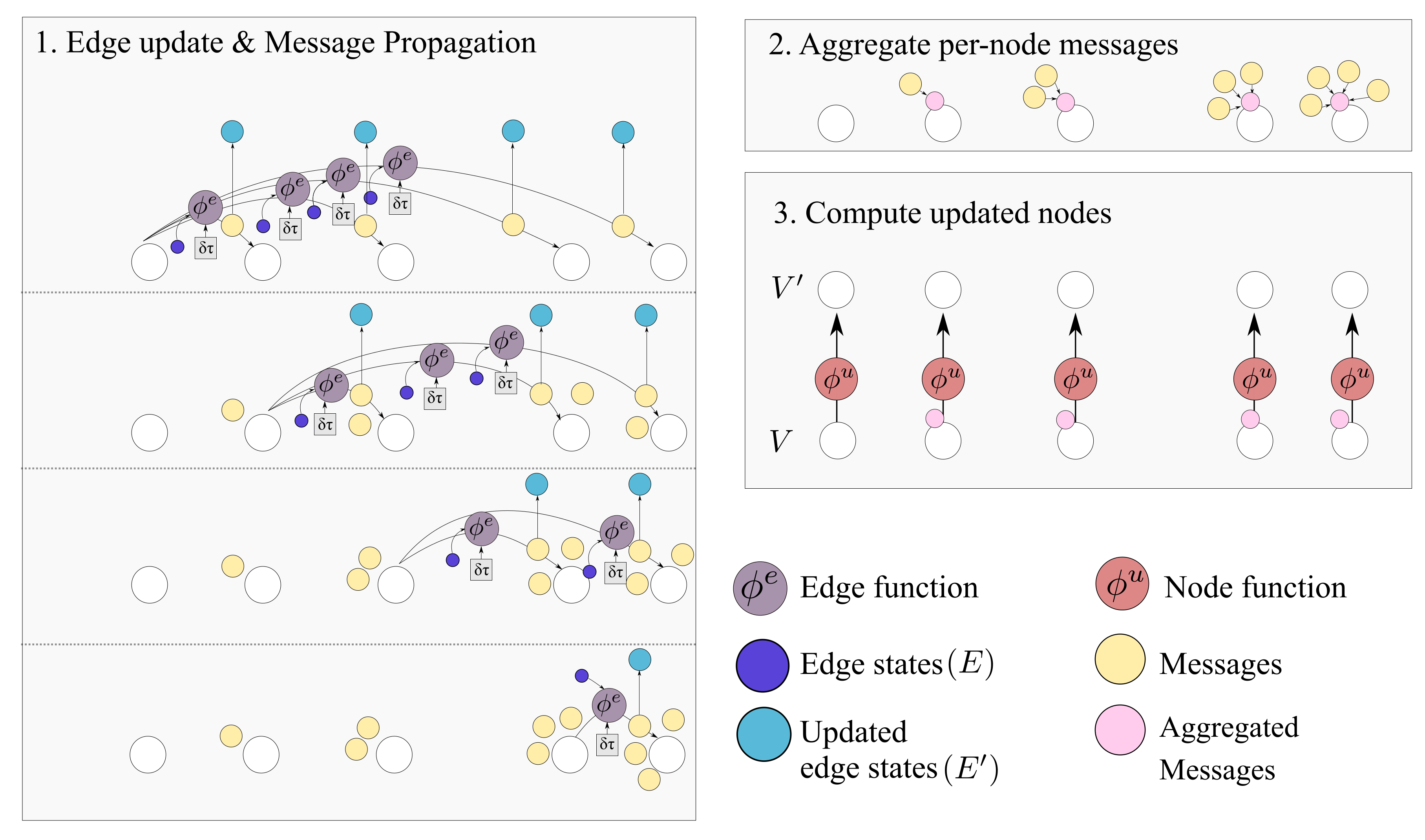
Ignoring global graph attributes, the GraphNet computation procedure is as detailed in Algorithm 1. First, the new edge states are evaluated using the sender and receiver vertex attributes (
and
correspondingly) and the previous edge state
as arguments to the edge function
. The arguments of the edge function may contain any combination of the source and target node attributes and the edge attribute. Afterwards, the nodes of the graph are iterated and the incoming edges for each node are used to compute an aggregated incoming edge message
. The aggregated edge message together with the node attributes are used to compute an updated node state. Typically, small Multi-Layer Perceptrons (MLPs) are used for the edge and node GraphNet functions
and
. It is possible to compose GN blocks by using the output of a GN as the input to another GN block. Since a single GN block allows only first order neighbors to exchange messages, GN blocks are composed as
where “∘” denotes composition. The first GN block may cast the input graph data to a lower dimension so as to allow for more efficient computation. The first GN block may comprise edge functions that depend only on edge states
and correspondingly node functions that depend only on node states
. This is referred to as a Graph Independent GN block and it is used as the type of layer for the first and the last GN block. The inner GN steps (i.e.,
to
) are full GN blocks, where message passing takes place. This general computational pattern is referred to as encode-process-decode [
6]. The inner GN blocks have shared weights, yielding a lower memory footprint for the whole model, or can comprise different weights, which amount to different GN functions that need to be trained for each level. Sharing weights and repeatedly applying the same GN block helps propagate and combine information from more connected nodes in the graph. A message passing GN block which does not contain the global variable, as the ones used in this work, is shown in
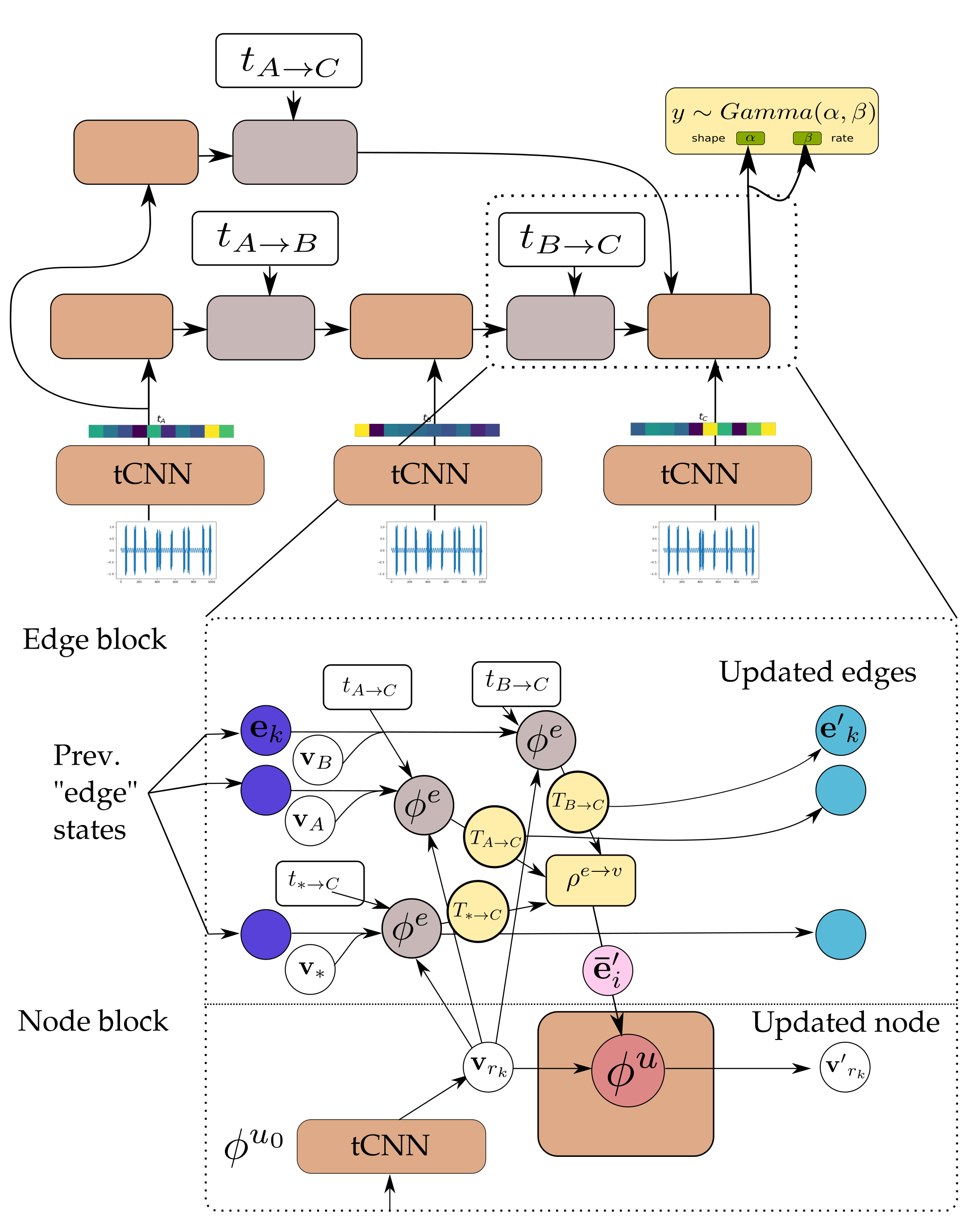
Figure 4.
| Algorithm 1: GN block without global variables [6]. |
functionGraphNetwork (E, V) for do ▹ 1. Compute updated edges end for for do let ▹ 2. Aggregate edges per node ▹ 3. Compute updated nodes end for let let return end function
|
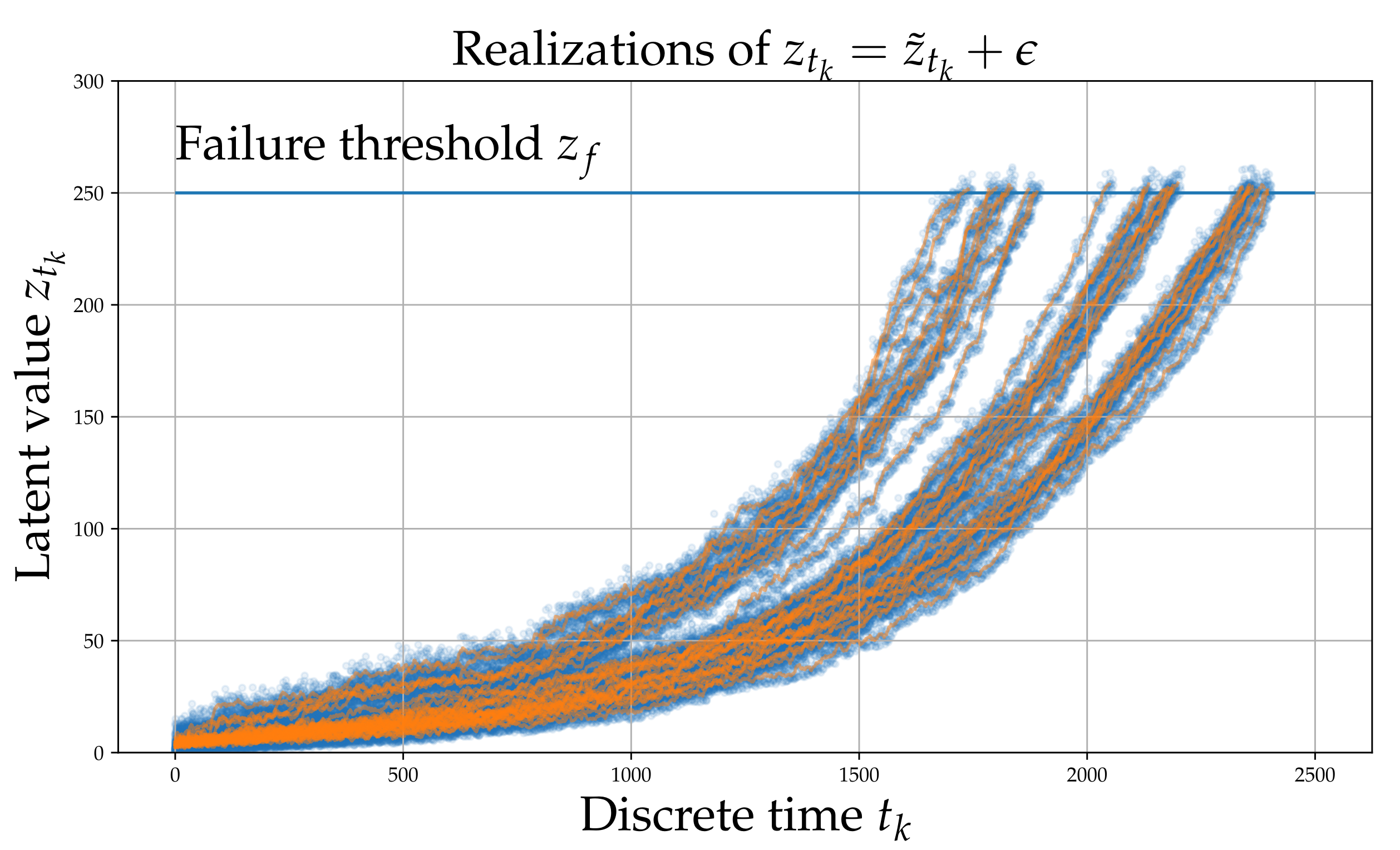
In the present work, as is the case with RNNs [
48] and causal CNNs [
49], the causal structure of time series is exploited, which serves as a good inductive bias for the problem at hand, although without requiring that the data is processed as a chain-graph or that the data are equidistant. Instead, an arbitrary causal graph for the underlying state is built, together with functions to infer the quantity of interest which is the remaining useful life of a component given a set of non-consecutive short-term observations.
3.2. Incorporation of Temporal Causal Structure with GNs and Temporal CNNs (GNN-tCNN)
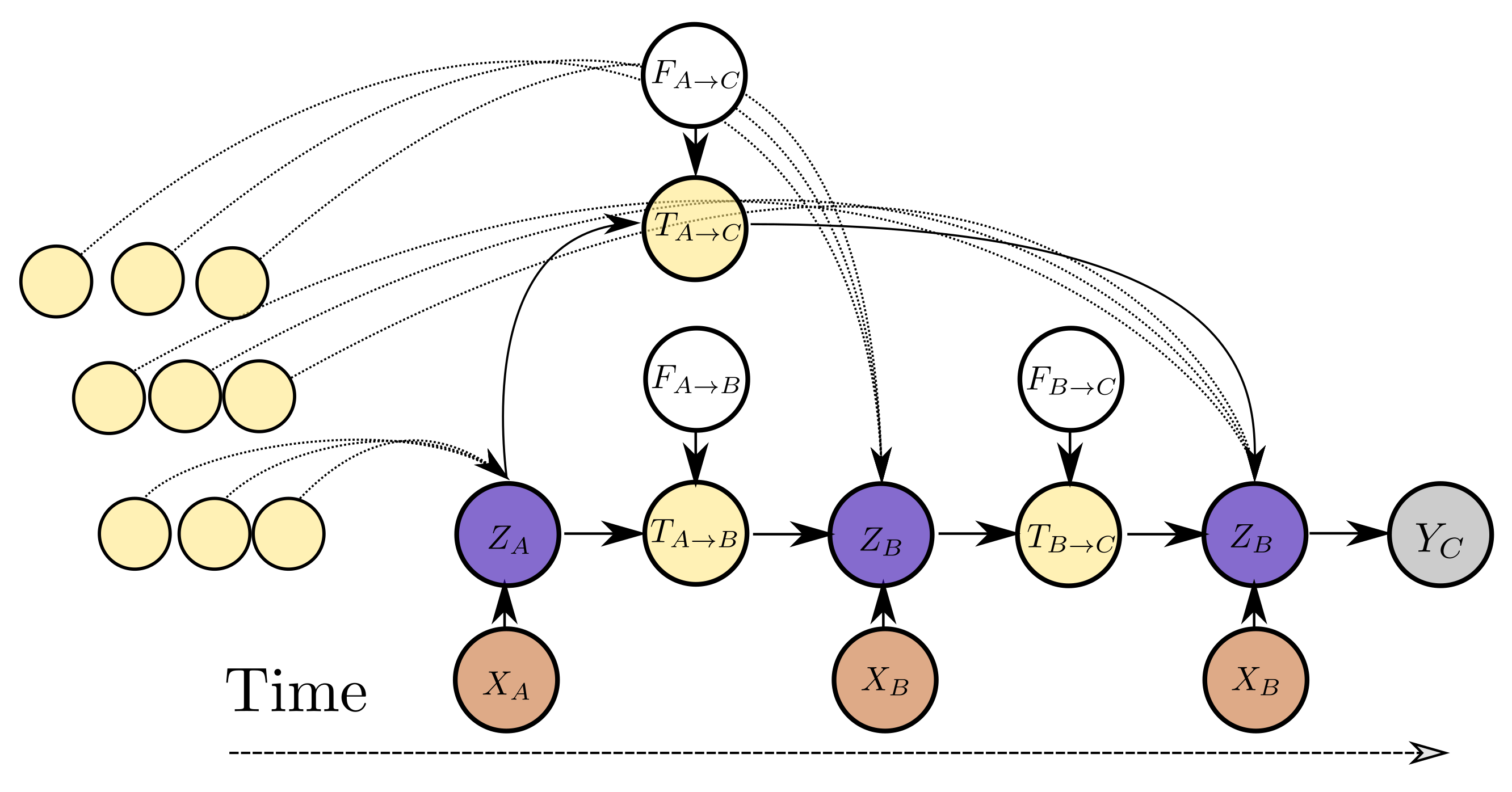
The variable dependencies of the proposed model are depicted in
Figure 5 for three observations. The computational architecture is depicted in detail in
Figure 6. The variable
represents the current estimate for the latent state of the system. This corresponds to the node states
V. The variable
, which represents the propagated latent state from past observations, depends on the latent state
, an exogenous input
that controls the propagation of state
to
and potentially other propagated latent state estimates from instants before
. The variable
corresponds to an updated edge state
and the exogenous inputs
can be the edge state before the edge step
E. The exogenous input
to the state propagation function can be as simple as the elapsed time between two time instants, i.e.,
or encode more complex inductive biases, such as the values representing different operating conditions during the interval between observations. An arbitrary number of past states can be propagated from past observations and aggregated in order to yield better estimates for a latent state
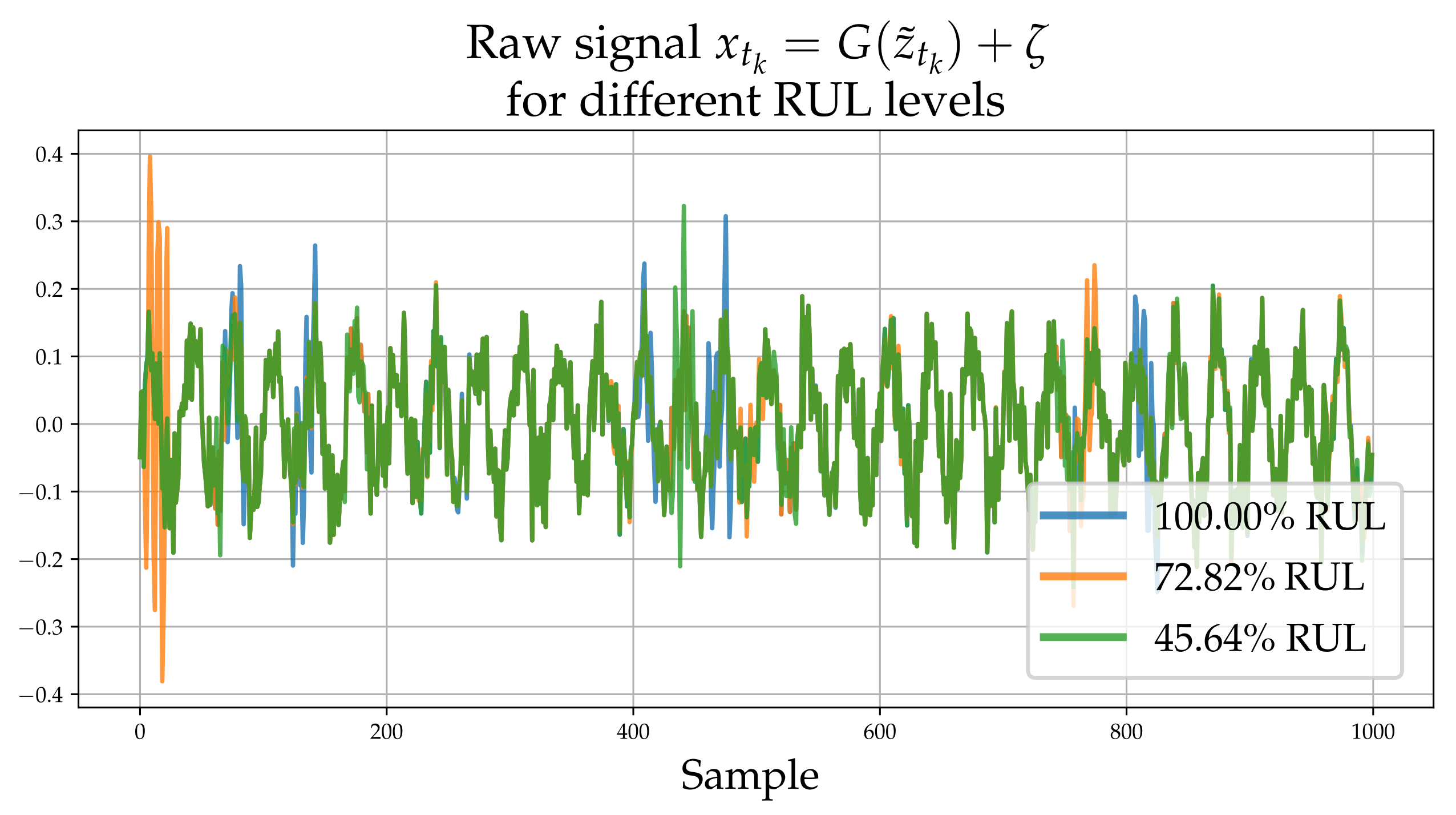
. In addition to propagated latent states, instantaneous observations of raw data
inform the latent state
. For instance, in
Figure 5,
depends on
but at the same time on
and potentially more propagated states from past observations (other yellow nodes in the graph) and at the same time to an instantaneous observation
. Each inferred latent state
can be transformed to a distribution for the quantity of interest
. The value of the propagated state variable from state
s to state
d,
, depends jointly on the edge attributes and on the latent state of the source node. In a conventional RNN model,
corresponds to an exogenous input for the RNN cell. In contrast to an RNN model, in this work the dependence of the estimate of each state depends on multiple states by introducing a propagated state that is modulated by the exogenous input. In this manner, an arbitrary and variable number of past states can be used directly for refining the estimate of the current latent state, instead of the estimate summarized in the latent cell state of the RNN. In the proposed model, the parameters of the functions relating the variables of the model are learned directly from the data and essentially define the inductive biases following naturally from the temporal ordering of the observations. This approach allows for uniform treatment of all observations from the past and allows for the consideration of an arbitrary number of such observations to yield an estimate of current latent state.
The connections from all observable past states and the ultimate one, where prediction (read-out) is performed, are implemented as a node-to-edge transformation and subsequent aggregations. Aggregation corresponds to the edge-aggregation function
of the GraphNet. In this manner, it is possible to propagate information from all distant past states on a single computation step. As mentioned also in the introduction, this is one of the computational advantages of the transformer architecture [
18], which is related to GNs. In contrast to using a causal transformer architecture, the causal GNN approach proposed herein allows for parametrizing the edges between different states. This key difference is what allows the proposed model to work on arbitrarily spaced data. The different steps of the causal GN computation and how they relate to the general GN, are further detailed in
Figure 7.
As is the case when using transformer layers, the computational burden increases quadratically with the context window. Therefore, the computation of all available past states would be inefficient. To remedy this, it is possible to randomly sample past observations in order to perform predictions for the current step. Similarly, during training, it is possible to yield unbiased estimates of gradients for the propagation and feature extraction model by randomly sampling the past states. It was found that for the presented use-cases this was an effective strategy for training.
In GN terms, the “encode” GraphNet block (
) is a graph-independent block consisting of the node function
and edge function
. The node function is a temporal convolutional neural network (temporal CNNs), with architecture detailed in
Table 3.
The edge update function is a feed-forward neural network. The input of the edge function is the temporal difference between observations. Both networks cast their inputs to vectors of the same size. The
network consists of small feed-forward neural networks for the node MLP
and the edge MLP
. The input of the edge MLP is the sender and receiver state and the previous edge state. The MLP is implemented with a residual connection to allow for better propagation of gradients through multiple steps [
50].
In this work, the
aggregation function was chosen, which does not depend strongly on the in-degree of the state nodes
(i.e., number of incoming messages) which corresponds to step 2 in Algorithm 1. The node MLP of the core network is also implemented as a residual MLP.
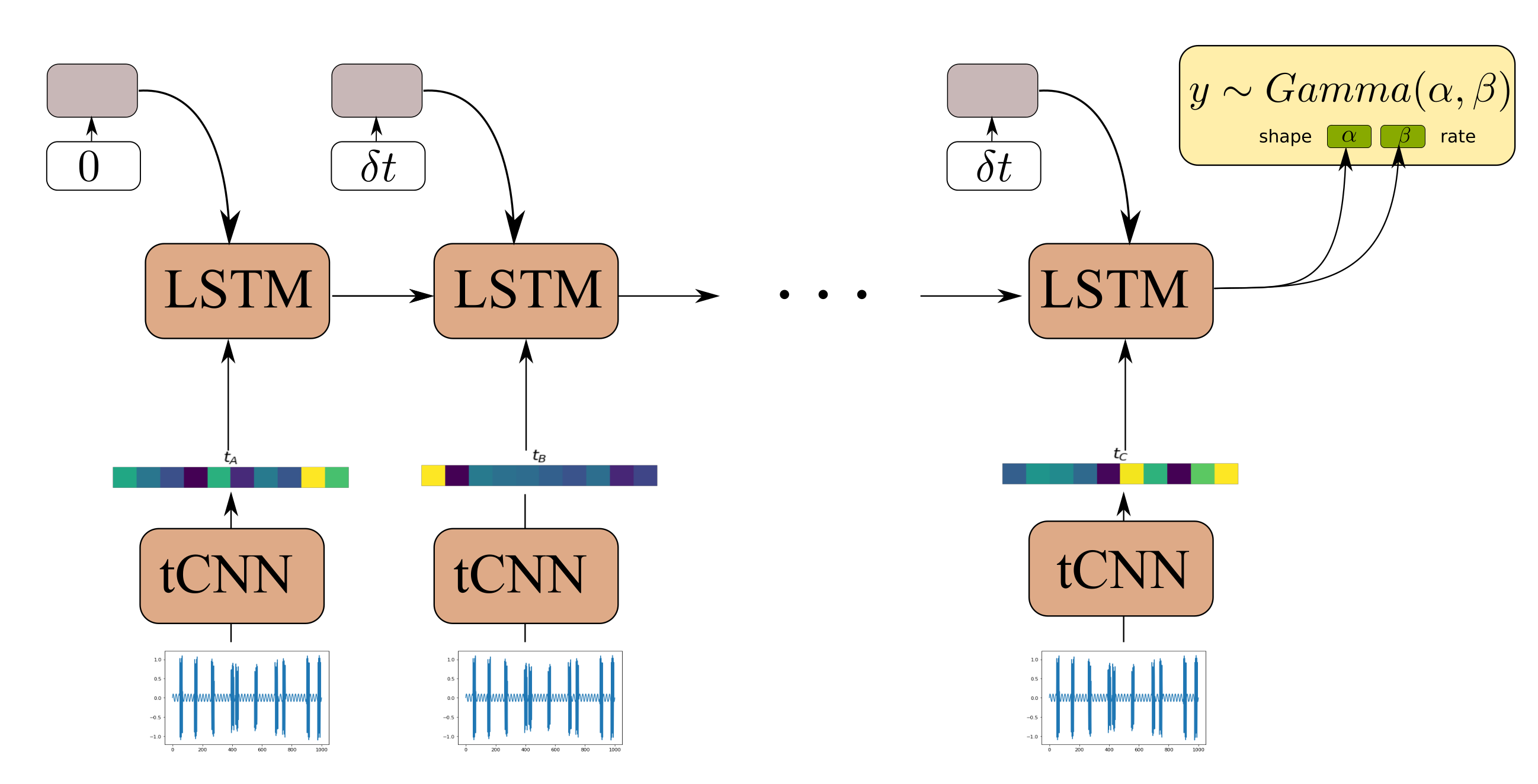
The
network is applied multiple times to the output of
. This ammounts to the shared weights variant of GNs, which allows for propagation of information from multiple steps while costing a small memory footprint. After the last
step is applied, a final graph-independent layer is employed. At this point, only the final state of the last node is needed for further computation, i.e., the state corresponding to the last observation. The state of the last node is passed through two MLPs that terminate with
activation functions
The
activation is needed for forcing the outputs to be positive, since they are used as parameters for a
distribution which in turn is used to represent the RUL estimates. The GraphNet computation procedure detailed above is denoted as
where
denotes
compositions of the
GraphNet and “
” are the input and output graphs. The vertex attribute of the final node as mentioned before is in turn used as the rate (
) and concentration (
) parameters of a
distribution. For ease of notation, the parameters (weights) of all the functions involved are denoted by “
” and the functions that return the rate and concentration are denoted as
and
correspondingly to denote explicitly their dependence on “
”. The
distribution was chosen for the output values since they correspond to remaining time and they are necessarily positive. The GN described above is trained so as to directly maximize the expected likelihood of the remaining useful life estimates. For numerical reasons, equivalently, the negative log-likelihood (
NLL) is maximized. The optimization problem reads,
where
corresponds to the sets of input causal graphs, and
corresponds to the estimate of RUL for the last observation of each graph. The input graphs in our case consist of nodes, which correspond to observations and edges with time-difference as their features. Correspondingly
and
are single samples from the aforementioned set of causal graphs and remaining useful life estimates and
denotes the number of sampled causal graphs from experiment
p that are used for computing the loss (i.e., the batch size). The expectation symbol is approximated by an expectation over the set of available training experiments denoted as
and the random causal graphs created for training
. The gradients of Equation (5) are computable through implicit re-parametrization gradients [
51]. This technique allows for low-variance estimates for the gradient of the NLL loss with respect to the parameters of the distribution, which in turn allows for a complete end-to-end differentiable training procedure for the proposed architecture.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}