
Artificial Vision Algorithms for Socially Assistive Robot Applications: A Review of the Literature

 , , and
, , and
Abstract
:1. Introduction
Methods
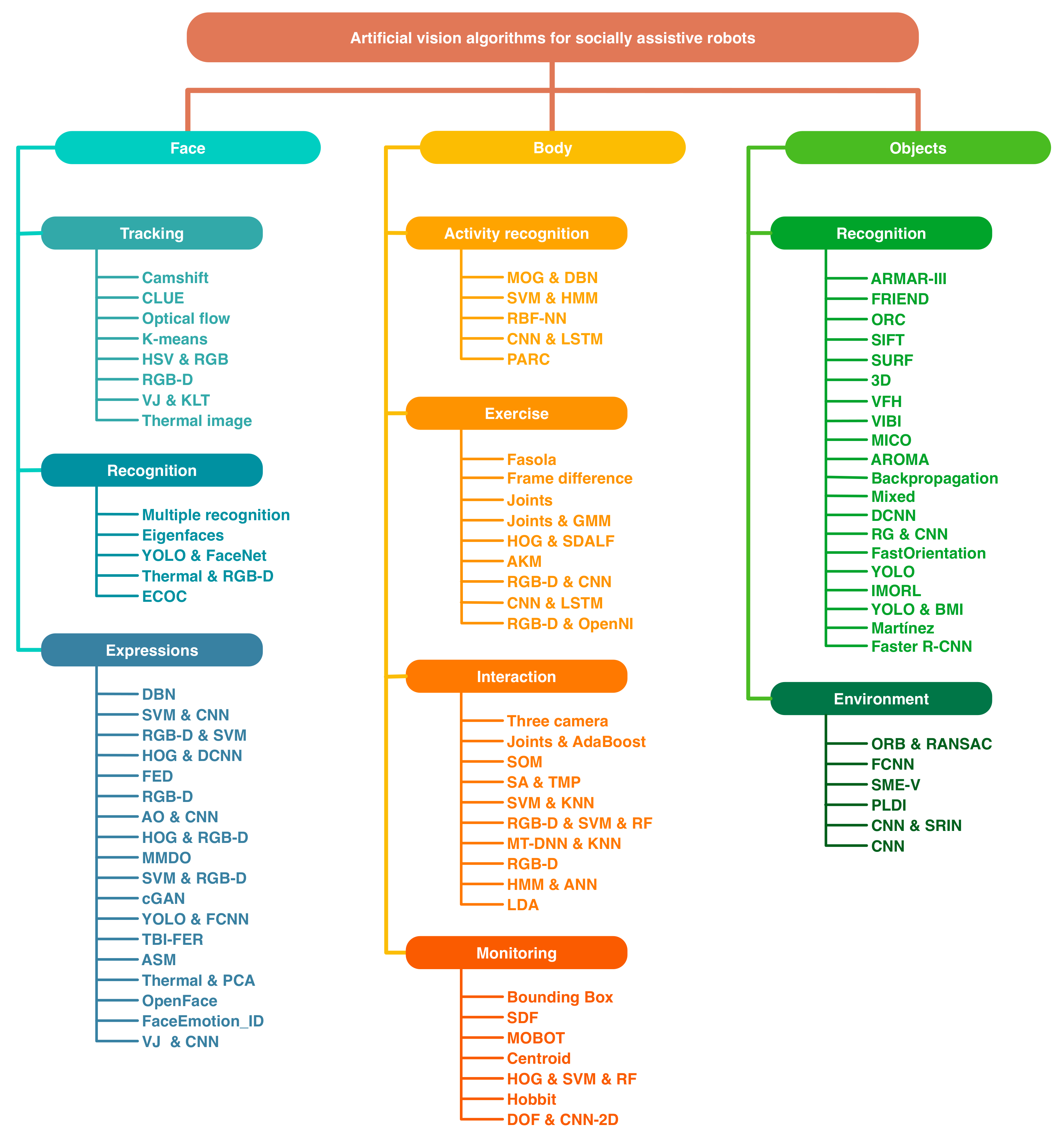
2. Algorithms Used for Face Recognition and Tracking
2.1. Tracking
2.2. Recognition
2.3. Facial Expressions

{kind=link}
| Algorithm | PERF | Speed | Hardware and Software | Application |
|---|---|---|---|---|
| Camshift (2010) [14] | 85% | real time | OpenCV | Tracking |
| CLUE (2010) [13] | - | - | MANUS Assistive Robotic Manipulator (ARM) and OpenCV | Tracking |
| Optical Flow (2013) [16] | - | real time | - | Tracking |
| DBN (2013) [39] | - | 25 FPS | 2.8 GHz Intel(R) Core(TM) i7 CPU and 4GB RAM running using GNU/Linux Ubuntu 10.10 | Expressions |
| K-means (2013) [17] | - | 10 FPS | Computer at 2.4 GHz | Tracking |
| HSV & RGB (2015) [18] | 99% | real time | 2 GHz Intel Core2Duo and 2 GB RAM. Programming in Matlab | Tracking |
| Multiple face recognition (2015) [21] | 91% | real time | 2.3 GHz i5 and 4 GB of RAM running using Windows 7 (×64) | Recognition |
| SVM & CNN (2016) [27] | 96.26% | real time | NAO robot | Expressions |
| RGB-D (2016) [19] | 73.33% | real time | NAO and Wifibot robots, a Kinect v2 sensor, and two conventional laptops | Tracking |
| Eigenfaces (2016) [22] | - | - | InMoov Robot, an open-source robot that can be printed, and conventional PC | Recognition |
| RGB-D & SVM (2017) [37] | 93.6% | real time | RoboKind Zeno R50 (ZECA) robot | Expressions |
| HOG & DCNN (2018) [28] | 99.14% | real time | NAO robot | Expressions |
| VJ & KLT (2018) [12] | - | 10 FPS | PC whit GPU does not specify which | Tracking |
| FED (2018) [34] | 80% | offline | Raspberry Pi 3 Model B+ | Expressions |
| RGB-D (2018) [40] | 90% | real time | The R-50 Alice (Mina) robot | Expressions |
| RGB-D (2018) [35] | 93.2% | real time | The R-50 Alice (Mina) robot | Expressions |
| AO & CNN (2018) [29] | 91% | real time | NAO robot and Kinect sensor | Expressions |
| VJ & KLT (2018) [8] | 90% | 28.32 FPS | Intel Core i5-6600 CPU @ 3.30 GHz, 8 GB RAM | Tracking |
| HOG & RGB-D (2018) [41] | - | 4 FPS | Intel Core i5 | Expressions |
| MMDO (2018) [26] | - | 27 FPS | Two workstations with GTX960 GPU, and one workstation with GTX580 GPU, all with a processor of Intel Core i5 | Expressions |
| SVM & RGB-D (2018) [36] | 88% | offline | Mini robot | Expressions |
| Thermal image (2018) [20] | - | real time | Enrichme robot and Optris PI-450 camera | Tracking |
| YOLO & FaceNet (2018) [23] | - | 30 FPS | Pepper robot | Recognition |
| cGAN (2019) [30] | 74.80% | offline | Workstation with GeForce GTX 1080Ti GPU | Expressions |
| Thermal & RGB-D (2019) [24] | 90.59% | real time | THIAGo robot, the Ambient Intelligence System (AIS), the Networked Care Platform (NCP), and Optris PI450 thermal camera | Recognition |
| YOLO & FCNN (2019) [31] | 72.47% | real time | PC with i7 CPU processor and Nvidia Tesla K80 GPU | Expressions |
| TBI-FER (2019) [32] | 88% | real time | Pepper robot | Expressions |
| ASM (2019) [38] | 97.67% | real time | NAO robot and PC with AMD Geode with 500 MHz CPU, 256 MB SDRAM and 1 GB flash memory | Expressions |
| Thermal & PCA (2019) [42] | 85.75% | 2 FPS | N-MARIA robot | Expressions |
| OpenFace (2020) [44] | 90% | real time | Kiwi robot, conventional camera and tablet | Expressions |
| FaceEmotion_ID (2020) [46] | - | - | NAO robot | Expressions |
| ECOC (2020) [25] | 90% | - | ROBCO 20 robot whit intel Core i7-8705G CPU | Recognition |
| VJ & CNN (2020) [33] | 82% | real time | NAO robot | Expressions |
3. Algorithms Used for the Body
3.1. Activity Recognition
3.2. Exercise
3.3. Interaction
| Algorithm | PERF | Speed | Hardware and Software | Application |
|---|---|---|---|---|
| Fasola (2010) [52] | - | 20 FPS | The torso comprises 19 controllable degrees of freedom and a Pioneer 2DX mobile base. OpenCV | Exercise |
| Three camera (2011) [63] | - | real time | Dell workstation with Intel Xeon 3.2 GHz CPU and 2.0 GB RAM utilizing Matlab | Interaction |
| Frame Difference (2011) [54] | - | real time | Humanoid RoboPhilo Robot. 32-bit PC with Windows XP, intel Core 2 Duo CPU, 4 GB of RAM | Exercise |
| MOG & DBN (2014) [47] | 93.6% | - | Brian 2.1 robot | Activity |
| SVM & HMM (2014) [48] | 98.11% | real time | - | Activity |
| Bounding Box (2015) [75] | 92.6% | off-line | Conventional workstation with Ubuntu | Monitoring |
| Joints (2016) [55] | - | real time | NAO robot, Kinect sensor, and conventional laptop | Exercise |
| Joints & GMM (2016) [58] | - | real time | Poppy robot, Kinect sensor, and open source | Exercise |
| Joints & AdaBoost (2016) [66] | 97% | - | Kinect sensor | Interaction |
| RBF-NN (2017) [51] | - | 20 FPS | Standard desktop computer with Intel i3 processor and 8 GB of RAM. Coded in Matlab 2014a | Activity |
| SOM (2017) [72] | 91.1% | offline | Not described | Interaction |
| HOG & SDALF (2017) [59] | 95% | real time | Robot platform ROREAS | Exercise |
| SA & TMP (2017) [67] | - | real time | FACE robot and Kinect sensor | Interaction |
| SDF (2017) [76] | 97.4% | 24 FPS | Workstation with GPU | Monitoring |
| MOBOT (2017) [77] | 93% | real time | MOBOT robot | Monitoring |
| Centroid (2017) [78] | - | offline | Mobile robot, Kinect sensor, Arduino mega board and standard laptop | Monitoring |
| HOG, SVM & HSV (2017) [79] | - | real time | Not described | Monitoring |
| SVM & KNN (2017) [73] | 99.73% | offline | Not described | Interaction |
| Hobbit (2018) [80] | - | real time | Hobbit Robot | Monitoring |
| RGB-D, SVM & RF (2018) [74] | 92.32% | offline | Not described | Interaction |
| AKM (2018) [61] | - | real time | Windows 64-Bit PC with 4 GB RAM, Kinect Sensor (Version 2), its Windows Adapter, telescopic robotic for Double Robotics and Kinect v2 | Exercise |
| RGB-D & CNN (2018) [62] | 97.8% | real time | PC with i5 processor, GeForce GTX1060 GPU, and Kinect v2 | Exercise |
| MT-DNN & KNN (2018) [68] | 50% | off-line | Not described | Interaction |
| RGB-D (2018) [71] | - | real time | Kinect sensor and Workstation not described. Simulated robot hardware | Interaction |
| CNN & LSTM (2018) [49] | - | - | Pepper robot | Activity |
| CNN & LSTM (2019) [57] | 99.87% | - | Pepper robot | Exercise |
| RGBD & OpenNI (2019) [56] | 95% | 30 FPS | Mobile robot, conventional workstation, and Arduino board | Exercise |
| HMM & ANN (2019) [69] | 97.97% | real time | Robovie R3 Robot | Interaction |
| DOF & CNN 2D (2020) [81] | - | 5 FPS | iRobot Roomba mobile base, an Apple iPhone, and an Intel i5 processor mini PC | Monitoring |
| PARC (2020) [50] | 80% | real time | Off-board ASUS Zenbook with an Intel Core i5-6200U CPU, 8 GB RAM, an Intel RealSense D-435 RGB-D camera, and a Turtlebot 2e mobile platform1. The software is developed in C++ with OpenCV libraries and YOLO V3 | Activity |
| LDA (2020) [70] | 90% | 10 FPS | Pepper robot | Interaction |
3.4. Monitoring
4. Algorithms Used for Objects
4.1. Algorithms Used for Object Recognition
4.2. Algorithms Used to Detect the Environment
| Algorithm | PERF | Speed | Hardware and Software | Application |
|---|---|---|---|---|
| ARMAR-III (2010) [82] | - | - | ARMAR-III robot with a DSP56F803 from Motorola and a FPGA EPF10k30a from Altera | Objects |
| FRIEND (2011) [86] | - | offline | FRIEND robot and PC with a 1 GHz Intel-Processor | Objects |
| ORC (2013) [88] | - | offline | Not described | Objects |
| SIFT (2013) [89] | 93.650% | real time | Pioneer 3-DX mobile robot | Objects |
| SURF (2013) [90] | - | - | SAM robot | Objects |
| 3D (2013) [91] | 77.8% | real time | Robotic arm, a Kinect and EGG sensors | Objects |
| ORB & RANSAC (2014) [104] | - | - | Not described | Environment |
| VFH (2014) [92] | - | real time | Workstation with Intel Core2 Quad Q9550 processor, 3 GB RAM, and Windows 7 | Objects |
| VIBI (2015) [93] | - | - | JACO robot and Kinect sensor | Objects |
| MICO (2016) [94] | 82% | real time | Mico robot arm and Intel Core i7 Quad-Core processor PC with 12 GB of RAM, and Ubuntu 12.04 | Objects |
| AROMA (2016) [100] | 85% | real time | JACO robot and Senz3D 3D camera | Objects |
| FCNN (2017) [105] | 100% | on line | PR2 robot and Kinect | Environment |
| Backpropagation (2017) [95] | 95% | real time | JACO robot and Kinect, 3.60 GHz Intels CoreTM i7-4790 CPU, 16 GB of RAM, and an NVIDIA GeForces GTX 760 GPU | Objects |
| Mixed (2017) [83] | 96.1% | real time | NVIDIA GeForce GTX 745. It includes 384 Compute Unified Device Architecture (CUDA) cores with 4 GB memory | Objects |
| DCNN (2017) [96] | 90% | real time | Baxter robot | Objects |
| RG & CNN (2017) [97] | 99.05% | real time | Not described | Objects |
| SME-V (2018) [107] | 91.7% | - | Toyota’s Human Support Robot, Xtion PRO LIVE, an RGB-D camera | Environment |
| FastOrient (2018) [84] | 91.1% | - | Universal Robots UR10 robot and Matlab | Objects |
| PLDI (2018) [106] | 73.5% | real time | ROMEO2 robot and Workstation with i7 Intel processor | Environment |
| CNN (2018) [98] | - | real time | Turtlebot 2 robot and a workstation with an Intel i5 and a NVIDIA GTX-1080 with 8 GB of memory | Environment |
| YOLO (2018) [101] | 94.4% | real time | JACO 2 robot and a workstation with Intel i7 processor, 8 GB of RAM and a Nvidia GeForce GTX680 GPU | Objects |
| IMORL (2018) [102] | 79% | real time | JACO 2 robot | Objects |
| YOLO & BMI (2019) [103] | 78% | real time | Not described | Objects |
| Martinez (2019) [85] | 97.5% | real time | Baxter robot, the Pepper robot, and the Hobbit robot | Objects |
| Faster R-CNN (2019) [99] | 78.35% | 21.62 FPS | Workstation whit CUDA enabled NVIDIA Tesla K80 GPU, and 8 GB RAM. Simulated on Virtual Robotics Experimentation Platform | Objects |
| CNN & SRIN (2020) [108] | 97.96% | real time | NAO Robot | Environment |
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ADL | Activities of Daily Living |
| AKM | Angular Kinematics Model |
| ANN | Artificial Neural Network |
| AO | Adam Optimizer |
| ASD | Autism Spectrum Disorders |
| ARMs | Assistive Robotic Manipulators |
| AROMA | Assistive Robotic Manipulation Assistance |
| cGAN | Conditional Generative Adversarial Network |
| CLNF | Conditional Local Neural Fields algorithm |
| CNN | Convolutional Neural Network |
| CLUE | Coded Landmark for Ubiquitous Environment |
| DBN | Dynamic Bayesian Network |
| DCNN | Deep Convolutional Neural Network |
| DOF | Dense Optical Flow |
| FCNN | Fully Convolutional Neural Network |
| FED | Facial Expression Detection |
| FPS | Frames Per Second |
| GMM | Gaussian Mixture Models |
| GPU | Graphics Processing Unit |
| HOF | Hall-of-Fame |
| HOG | Histogram of Oriented Gradients |
| HMM | Hidden Markov Model |
| HSV | Hue, Saturation, Value |
| IMORL | Incremental Multiple-Object Recognition and Localization |
| KLT | Kanade–Lucas–Tomasi |
| KNN | K-Nearest Neighbors |
| LBPH | Local Binary Pattern Histogram |
| LDA | Latent Dirichlet Allocation |
| LSTM | Long Short-Term Memory |
| MBH | Markov–Block–Hankel |
| MCI | Mild Cognitive Impairments |
| MMDO | Maximum Margin Object Detection Model |
| MOG | Mixture of Gaussians |
| MTCNN | Multi-Task Cascade Convolutional Neural Network |
| MT-DNN | Multi-Task Deep Neural Network |
| ORC | Optical Character Reader |
| PANORAMA | Panoramic Object Representation for Accurate Model Attributing |
| PCA | Principal Component Analysis |
| PLDIP | Projective Light Diffusion Imaging Process |
| RANSAC | Random Sample Consensus |
| RBF-NN | Radial Basis Function Neural Network |
| RF | Random Forest |
| RGB | Red, Green, Blue |
| RGB-D | Red, Green, Blue and Depth |
| SA | Scene Analyzer |
| SARs | Socially Assistive robots |
| SDALF | Symmetry-Driven Accumulation of Local Features |
| SDF | Signed Distance Functions |
| SDM | Supervised Descent Method |
| SIFT | Scale-Invariant Feature Transform |
| SRIN | Social Robot Indoor Navigation |
| SURF | Sped-Up Robust Features |
| SOM | Self Organizing Map |
| SVM | Support Vector Machines |
| TBI-FER | Traumatic Brain Injured Facial Expression Recognition |
| VFH | Viewpoint Feature Histogram |
| VIBI | Vision-Based Interface |
| VJ | Viola–Jones |
| YOLO | You Only Look Once |
References
- Mancioppi, G.; Fiorini, L.; Timpano Sportiello, M.; Cavallo, F. Novel Technological Solutions for Assessment, Treatment, and Assistance in Mild Cognitive Impairment: A Systematic Review. Front. Neuroinform. 2019, 13, 58. [Google Scholar] [CrossRef] [Green Version]
- Wu, Y.H.; Cristancho-Lacroix, V.; Fassert, C.; Faucounau, V.; de Rotrou, J.; Rigaud, A.S. The attitudes and perceptions of older adults with mild cognitive impairment toward an assistive robot. J. Appl. Gerontol. 2016, 35, 3–17. [Google Scholar] [CrossRef]
- De Graaf, M.M.; Allouch, S.B.; van Dijk, J.A. Long-term evaluation of a social robot in real homes. Interact. Stud. 2016, 17, 462–491. [Google Scholar] [CrossRef] [Green Version]
- Vercelli, A.; Rainero, I.; Ciferri, L.; Boido, M.; Pirri, F. Robots in elderly care. Digit.-Sci. J. Digit. Cult. 2018, 2, 37–50. [Google Scholar]
- Sheridan, T.B. Human–robot interaction: Status and challenges. Hum. Factors 2016, 58, 525–532. [Google Scholar] [CrossRef]
- Costa, A.; Martinez-Martin, E.; Cazorla, M.; Julian, V. PHAROS—PHysical assistant RObot system. Sensors 2018, 18, 2633. [Google Scholar] [CrossRef] [Green Version]
- Montaño Serrano, V.M. Propuesta Conceptual de un Sistema de Asistencia Tecnológica para un Paciente con Deterioro Cognitivo Leve: Un Caso de Estudio; Universidad Autónoma del Estado de México: Ciudad de México, Mexico, 2019. [Google Scholar]
- Putro, M.D.; Jo, K.H. Real-time Face Tracking for Human-Robot Interaction. In Proceedings of the 2018 International Conference on Information and Communication Technology Robotics (ICT-ROBOT), Busan, Korea, 6–8 September 2018; pp. 1–4. [Google Scholar]
- Chrysos, G.G.; Antonakos, E.; Snape, P.; Asthana, A.; Zafeiriou, S. A comprehensive performance evaluation of deformable face tracking “in-the-wild”. Int. J. Comput. Vis. 2018, 126, 198–232. [Google Scholar] [CrossRef] [Green Version]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2001), Kauai, HI, USA, 8–14 December 2001; Volume 1, p. I. [Google Scholar]
- Dandashy, T.; Hassan, M.E.; Bitar, A. Enhanced Face Detection Based on Haar-Like and MB-LBP Features. Int. J. Eng. Manag. Res. 2019, 9, 117–124. [Google Scholar]
- Cilmi, B.; Mercimek, M. Design and Implementation of Real Time Face Tracking Humanoid Robot. In Proceedings of the 2018 6th International Conference on Control Engineering & Information Technology (CEIT), Istanbul, Turkey, 25–27 October 2018; pp. 1–6. [Google Scholar]
- Tanaka, H.; Sumi, Y.; Matsumoto, Y. Assistive robotic arm autonomously bringing a cup to the mouth by face recognition. In Proceedings of the 2010 IEEE Workshop on Advanced Robotics and its Social Impacts, Tokyo, Japan, 26–28 October 2010; pp. 34–39. [Google Scholar]
- Boccanfuso, L.; O’kane, J.M. Adaptive robot design with hand and face tracking for use in autism therapy. In International Conference on Social Robotics; Springer: Berlin/Heidelberg, Germany, 2010; pp. 265–274. [Google Scholar]
- Boccanfuso, L.; O’Kane, J.M. CHARLIE: An adaptive robot design with hand and face tracking for use in autism therapy. Int. J. Soc. Robot. 2011, 3, 337–347. [Google Scholar] [CrossRef]
- Perez, E.; Soria, C.; López, N.M.; Nasisi, O.; Mut, V. Vision-based interfaces applied to assistive robots. Int. J. Adv. Robot. Syst. 2013, 10, 116. [Google Scholar] [CrossRef] [Green Version]
- Perez, E.; López, N.; Orosco, E.; Soria, C.; Mut, V.; Freire-Bastos, T. Robust human machine interface based on head movements applied to Assistive robotics. Sci. World J. 2013, 2013, 589636. [Google Scholar] [CrossRef] [Green Version]
- Bhattacharjee, A.; Das, P.; Kundu, D.; Ghosh, S.; Gupta, S.D. A Real-Time Face Motion Based Approach towards Modeling Socially Assistive Wireless Robot Control with Voice Recognition. IJACSA Int. J. Adv. Comput. Sci. Appl. 2015, 6, 205–220. [Google Scholar] [CrossRef] [Green Version]
- Canal, G.; Escalera, S.; Angulo, C. A real-time human-robot interaction system based on gestures for assistive scenarios. Comput. Vis. Image Underst. 2016, 149, 65–77. [Google Scholar] [CrossRef] [Green Version]
- Coşar, S.; Yan, Z.; Zhao, F.; Lambrou, T.; Yue, S.; Bellotto, N. Thermal camera based physiological monitoring with an assistive robot. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 18–22 July 2018; pp. 5010–5013. [Google Scholar]
- Shoani, M.T.A. Face Recognition Based Security Robot Incorporating Omnidirectional Vision. Ph.D. Thesis, Universiti Teknologi Malaysia, Skudai, Malaysia, 2015. [Google Scholar]
- John, E.S.; Rigo, S.J.; Barbosa, J. Assistive robotics: Adaptive multimodal interaction improving people with communication disorders. IFAC-PapersOnLine 2016, 49, 175–180. [Google Scholar] [CrossRef]
- Ghiţă, Ş.A.; Barbu, M.Ş.; Gavril, A.; Trăscău, M.; Sorici, A.; Florea, A.M. User detection, tracking and recognition in robot assistive care scenarios. In Annual Conference Towards Autonomous Robotic Systems; Springer: Berlin/Heidelberg, Germany, 2018; pp. 271–283. [Google Scholar]
- Coşar, S.; Fernandez-Carmona, M.; Agrigoroaie, R.; Pages, J.; Ferland, F.; Zhao, F.; Yue, S.; Bellotto, N.; Tapus, A. ENRICHME: Perception and Interaction of an Assistive Robot for the Elderly at Home. Int. J. Soc. Robot. 2020, 12, 779–805. [Google Scholar] [CrossRef] [Green Version]
- Chivarov, N.; Chikurtev, D.; Pleva, M.; Ondas, S.; Liao, Y.F. User identification and prioritization control of service robot teleoperation. In Proceedings of the 2020 11th IEEE International Conference on Cognitive Infocommunications (CogInfoCom), Online, 23–25 September 2020; pp. 33–38. [Google Scholar]
- Ramirez-Duque, A.A.; Frizera-Neto, A.; Bastes, T.F. Robot-assisted diagnosis for children with autism spectrum disorder based on automated analysis of nonverbal cues. In Proceedings of the 2018 7th IEEE International Conference on Biomedical Robotics and Biomechatronics (Biorob), Enschede, The Netherlands, 26–29 August 2018; pp. 456–461. [Google Scholar]
- Ruiz-Garcia, A.; Elshaw, M.; Altahhan, A.; Palade, V. A hybrid deep learning neural approach for emotion recognition from facial expressions for socially assistive robots. Neural Comput. Appl. 2018, 29, 359–373. [Google Scholar] [CrossRef]
- Ruiz-Garcia, A.; Webb, N.; Palade, V.; Eastwood, M.; Elshaw, M. Deep learning for real time facial expression recognition in social robots. In International Conference on Neural Information Processing; Springer: Berlin/Heidelberg, Germany, 2018; pp. 392–402. [Google Scholar]
- Babu, A.R.; Rajavenkatanarayanan, A.; Brady, J.R.; Makedon, F. Multimodal approach for cognitive task performance prediction from body postures, facial expressions and EEG signal. In Proceedings of the Workshop on Modeling Cognitive Processes from Multimodal Data, Boulder, CO, USA, 16 October 2018; pp. 1–7. [Google Scholar]
- Deng, J.; Pang, G.; Zhang, Z.; Pang, Z.; Yang, H.; Yang, G. cGAN based facial expression recognition for human-robot interaction. IEEE Access 2019, 7, 9848–9859. [Google Scholar] [CrossRef]
- Benamara, N.K.; Val-Calvo, M.; Álvarez-Sánchez, J.R.; Díaz-Morcillo, A.; Vicente, J.M.F.; Fernández-Jover, E.; Stambouli, T.B. Real-time emotional recognition for sociable robotics based on deep neural networks ensemble. In International Work-Conference on the Interplay Between Natural and Artificial Computation; Springer: Berlin/Heidelberg, Germany, 2019; pp. 171–180. [Google Scholar]
- Ilyas, C.M.A.; Schmuck, V.; Haque, M.A.; Nasrollahi, K.; Rehm, M.; Moeslund, T.B. Teaching Pepper Robot to Recognize Emotions of Traumatic Brain Injured Patients Using Deep Neural Networks. In Proceedings of the 2019 28th IEEE International Conference on Robot and Human Interactive Communication (RO-MAN), New Delhi, India, 14–18 October 2019; pp. 1–7. [Google Scholar]
- Ramis, S.; Buades, J.M.; Perales, F.J. Using a social robot to Evaluate facial expressions in the wild. Sensors 2020, 20, 6716. [Google Scholar] [CrossRef]
- Sridhar, R.; Wang, H.; McAllister, P.; Zheng, H. E-Bot: A facial recognition based human-robot emotion detection system. In Proceedings of the 32nd International BCS Human Computer Interaction Conference (HCI), Belfast, UK, 4–6 July 2018; pp. 1–5. [Google Scholar]
- Pour, A.G.; Taheri, A.; Alemi, M.; Meghdari, A. Human–robot facial expression reciprocal interaction platform: Case studies on children with autism. Int. J. Soc. Robot. 2018, 10, 179–198. [Google Scholar]
- Castillo, J.C.; Álvarez-Fernández, D.; Alonso-Martín, F.; Marques-Villarroya, S.; Salichs, M.A. Social robotics in therapy of apraxia of speech. J. Healthc. Eng. 2018, 2018, 7075290. [Google Scholar] [CrossRef] [Green Version]
- Silva, V.; Soares, F.; Esteves, J.S. Mirroring and recognizing emotions through facial expressions for a RoboKind platform. In Proceedings of the 2017 IEEE 5th Portuguese Meeting on Bioengineering (ENBENG), Coimbra, Portugal, 16–18 February 2017; pp. 1–4. [Google Scholar]
- Pino, O.; Palestra, G.; Trevino, R.; De Carolis, B. The humanoid robot nao as trainer in a memory program for elderly people with mild cognitive impairment. Int. J. Soc. Robot. 2020, 12, 21–33. [Google Scholar] [CrossRef]
- Cid, F.; Prado, J.A.; Bustos, P.; Nunez, P. A real time and robust facial expression recognition and imitation approach for affective human-robot interaction using gabor filtering. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013; pp. 2188–2193. [Google Scholar]
- Meghdari, A.; Alemi, M.; Pour, A.G.; Taheri, A. Spontaneous human-robot emotional interaction through facial expressions. In International Conference on Social Robotics; Springer: Berlin/Heidelberg, Germany, 2016; pp. 351–361. [Google Scholar]
- Fang, Q.; Kyrarini, M.; Ristic-Durrant, D.; Gräser, A. RGB-D camera based 3D human mouth detection and tracking towards robotic feeding assistance. In Proceedings of the 11th PErvasive Technologies Related to Assistive Environments Conference, Corfu, Greece, 26–29 June 2018; pp. 391–396. [Google Scholar]
- Goulart, C.; Valadão, C.; Delisle-Rodriguez, D.; Funayama, D.; Favarato, A.; Baldo, G.; Binotte, V.; Caldeira, E.; Bastos-Filho, T. Visual and thermal image processing for facial specific landmark detection to infer emotions in a child-robot interaction. Sensors 2019, 19, 2844. [Google Scholar] [CrossRef] [Green Version]
- Bastos, T.; Lampier, L.; Goulart, C.; Binotte, V.; Baldo, G.; Valadão, C.; Caldeira, E.; Delisle, D. Development of a Socially Assistive Robot Controlled by Emotions Based on Heartbeats and Facial Temperature of Children with Autistic Spectrum Disorder. In Proceedings of the Future Technologies Conference; Springer: Berlin/Heidelberg, Germany, 2020; pp. 228–239. [Google Scholar]
- Jain, S.; Thiagarajan, B.; Shi, Z.; Clabaugh, C.; Matarić, M.J. Modeling engagement in long-term, in-home socially assistive robot interventions for children with autism spectrum disorders. Sci. Robot. 2020, 5, eaaz3791. [Google Scholar] [CrossRef] [Green Version]
- Shi, Z.; Groechel, T.R.; Jain, S.; Chima, K.; Rudovic, O.; Matarić, M.J. Toward Personalized Affect-Aware Socially Assistive Robot Tutors in Long-Term Interventions for Children with Autism. arXiv 2021, arXiv:2101.10580. [Google Scholar]
- Lamas, C.M.; Bellas, F.; Guijarro-Berdiñas, B. SARDAM: Service Assistant Robot for Daily Activity Monitoring. Proceedings 2020, 54, 3. [Google Scholar] [CrossRef]
- McColl, D.; Nejat, G. Determining the affective body language of older adults during socially assistive HRI. In Proceedings of the 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems, Chicago, IL, USA, 14–18 September 2014; pp. 2633–2638. [Google Scholar]
- Wu, H.; Pan, W.; Xiong, X.; Xu, S. Human activity recognition based on the combined SVM&HMM. In Proceedings of the 2014 IEEE International Conference on Information and Automation (ICIA), Hailar, China, 28–30 July 2014; pp. 219–224. [Google Scholar]
- Rossi, S.; Ercolano, G.; Raggioli, L.; Valentino, M.; Di Napoli, C. A Framework for Personalized and Adaptive Socially Assistive Robotics. In Proceedings of the 19th Workshop “From Objects to Agents”, Palermo, Italy, 28–29 June 2018; pp. 90–95. [Google Scholar]
- Massardi, J.; Gravel, M.; Beaudry, É. Parc: A plan and activity recognition component for assistive robots. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 31 May–30 June 2020; pp. 3025–3031. [Google Scholar]
- Ravichandar, H.; Dani, A. Intention inference for human-robot collaboration in assistive robotics. In Human Modelling for Bio-Inspired Robotics; Elsevier: Amsterdam, The Netherlands, 2017; pp. 217–249. [Google Scholar]
- Fasola, J.; Mataric, M.J. Robot exercise instructor: A socially assistive robot system to monitor and encourage physical exercise for the elderly. In Proceedings of the 19th International Symposium in Robot and Human Interactive Communication, Viareggio, Italy, 13 September 2010; pp. 416–421. [Google Scholar]
- Fasola, J.; Matarić, M.J. A socially assistive robot exercise coach for the elderly. J. Hum.-Robot Interact. 2013, 2, 3–32. [Google Scholar] [CrossRef] [Green Version]
- Gadde, P.; Kharrazi, H.; Patel, H.; MacDorman, K.F. Toward monitoring and increasing exercise adherence in older adults by robotic intervention: A proof of concept study. J. Robot. 2011, 2011, 438514. [Google Scholar] [CrossRef] [Green Version]
- Görer, B.; Salah, A.A.; Akın, H.L. An autonomous robotic exercise tutor for elderly people. Auton. Robot. 2017, 41, 657–678. [Google Scholar] [CrossRef]
- Fang, J.; Qiao, M.; Pei, Y. Vehicle-mounted with tracked Robotic System Based on the Kinect. In Proceedings of the 2019 2nd World Conference on Mechanical Engineering and Intelligent Manufacturing (WCMEIM), Shanghai, China, 22–24 November 2019; pp. 521–524. [Google Scholar]
- Martinez-Martin, E.; Cazorla, M. A socially assistive robot for elderly exercise promotion. IEEE Access 2019, 7, 75515–75529. [Google Scholar] [CrossRef]
- Nguyen, S.M.; Tanguy, P.; Rémy-Néris, O. Computational architecture of a robot coach for physical exercises in kinaesthetic rehabilitation. In Proceedings of the 2016 25th IEEE International Symposium on Robot and Human Interactive Communication (RO-MAN), New York, NY, USA, 26–31 August 2016; pp. 1138–1143. [Google Scholar]
- Gross, H.M.; Scheidig, A.; Debes, K.; Einhorn, E.; Eisenbach, M.; Mueller, S.; Schmiedel, T.; Trinh, T.Q.; Weinrich, C.; Wengefeld, T.; et al. ROREAS: Robot coach for walking and orientation training in clinical post-stroke rehabilitation—Prototype implementation and evaluation in field trials. Auton. Robot. 2017, 41, 679–698. [Google Scholar] [CrossRef]
- Meyer, S.; Fricke, C. Robotic companions in stroke therapy: A user study on the efficacy of assistive robotics among 30 patients in neurological rehabilitation. In Proceedings of the 2017 26th IEEE International Symposium on Robot and Human Interactive Communication (RO-MAN), Lisbon, Portugal, 28–31 August 2017; pp. 135–142. [Google Scholar]
- Lotfi, A.; Langensiepen, C.; Yahaya, S.W. Socially assistive robotics: Robot exercise trainer for older adults. Technologies 2018, 6, 32. [Google Scholar] [CrossRef] [Green Version]
- Ma, B.; Sun, G.; Sun, Y. Utilization of color-depth combination features and multi-level refinement CNN for upper-limb posture recognition. In Proceedings of the 2018 International Conference on Image and Graphics Processing, Hong Kong, China, 24–26 February 2018; pp. 3–7. [Google Scholar]
- McColl, D.; Zhang, Z.; Nejat, G. Human body pose interpretation and classification for social human-robot interaction. Int. J. Soc. Robot. 2011, 3, 313. [Google Scholar] [CrossRef]
- Guler, A.; Kardaris, N.; Chandra, S.; Pitsikalis, V.; Werner, C.; Hauer, K.; Tzafestas, C.; Maragos, P.; Kokkinos, I. Human joint angle estimation and gesture recognition for assistive robotic vision. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 415–431. [Google Scholar]
- Rodomagoulakis, I.; Kardaris, N.; Pitsikalis, V.; Mavroudi, E.; Katsamanis, A.; Tsiami, A.; Maragos, P. Multimodal human action recognition in assistive human-robot interaction. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 2702–2706. [Google Scholar]
- Ge, B.; Park, H.W.; Howard, A.M. Identifying engagement from joint kinematics data for robot therapy prompt interventions for children with autism spectrum disorder. In International Conference on Social Robotics; Springer: Berlin/Heidelberg, Germany, 2016; pp. 531–540. [Google Scholar]
- Cominelli, L.; Carbonaro, N.; Mazzei, D.; Garofalo, R.; Tognetti, A.; De Rossi, D. A multimodal perception framework for users emotional state assessment in social robotics. Future Internet 2017, 9, 42. [Google Scholar] [CrossRef] [Green Version]
- Marinoiu, E.; Zanfir, M.; Olaru, V.; Sminchisescu, C. 3d human sensing, action and emotion recognition in robot assisted therapy of children with autism. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2158–2167. [Google Scholar]
- Gürpınar, C.; Uluer, P.; Akalın, N.; Köse, H. Sign recognition system for an assistive robot sign tutor for children. Int. J. Soc. Robot. 2019, 12, 1–15. [Google Scholar] [CrossRef]
- Rodríguez-Moreno, I.; Martínez-Otzeta, J.M.; Goienetxea, I.; Rodriguez-Rodriguez, I.; Sierra, B. Shedding Light on People Action Recognition in Social Robotics by Means of Common Spatial Patterns. Sensors 2020, 20, 2436. [Google Scholar] [CrossRef]
- Kurien, M.; Kim, M.K.; Kopsida, M.; Brilakis, I. Real-time simulation of construction workers using combined human body and hand tracking for robotic construction worker system. Autom. Constr. 2018, 86, 125–137. [Google Scholar] [CrossRef] [Green Version]
- Tuyen, N.T.V.; Jeong, S.; Chong, N.Y. Learning human behavior for emotional body expression in socially assistive robotics. In Proceedings of the 2017 14th International Conference on Ubiquitous Robots and Ambient Intelligence (URAI), Jeju, Korea, 28 June–1 July 2017; pp. 45–50. [Google Scholar]
- Adama, D.A.; Lotfi, A.; Langensiepen, C.; Lee, K. Human activities transfer learning for assistive robotics. In UK Workshop on Computational Intelligence; Springer: Berlin/Heidelberg, Germany, 2017; pp. 253–264. [Google Scholar]
- Adama, D.A.; Lotfi, A.; Langensiepen, C.; Lee, K.; Trindade, P. Human activity learning for assistive robotics using a classifier ensemble. Soft Comput. 2018, 22, 7027–7039. [Google Scholar] [CrossRef] [Green Version]
- Dimitrov, V.; Jagtap, V.; Wills, M.; Skorinko, J.; Padır, T. A cyber physical system testbed for assistive robotics technologies in the home. In Proceedings of the 2015 International Conference on Advanced Robotics (ICAR), Istanbul, Turkey, 27–31 July 2015; pp. 323–328. [Google Scholar]
- Vasileiadis, M.; Malassiotis, S.; Giakoumis, D.; Bouganis, C.S.; Tzovaras, D. Robust human pose tracking for realistic service robot applications. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 1363–1372. [Google Scholar]
- Koumpouros, Y.; Karavasili, A.; Efthimiou, E.; Fotinea, S.E.; Goulas, T.; Vacalopoulou, A. User Evaluation of the MOBOT rollator type robotic mobility assistive device. Technologies 2017, 5, 73. [Google Scholar] [CrossRef] [Green Version]
- Ahmad, A.M.; Bazzal, Z.; Youssef, H. Kinect-Based Moving Human Tracking System with Obstacle Avoidance. Adv. Sci. Technol. Eng. Syst. J. 2017, 2, 191–197. [Google Scholar] [CrossRef] [Green Version]
- Htwe, T.T.; Win, W.Y.; Shwe, L.L.T. Vision-Based Autonomous Human Tracking Mobile Robot. Am. Sci. Res. J. Eng. Technol. Sci. 2017, 38, 325–340. [Google Scholar]
- Bajones, M.; Fischinger, D.; Weiss, A.; Wolf, D.; Vincze, M.; de la Puente, P.; Körtner, T.; Weninger, M.; Papoutsakis, K.; Michel, D.; et al. Hobbit: Providing fall detection and prevention for the elderly in the real world. J. Robot. 2018, 2018, 1754657. [Google Scholar] [CrossRef]
- Chin, W.H.; Tay, N.N.W.; Kubota, N.; Loo, C.K. A Lightweight Neural-Net with Assistive Mobile Robot for Human Fall Detection System. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, Scotland, 9 November 2020; pp. 1–6. [Google Scholar]
- Yamazaki, K.; Watanabe, Y.; Nagahama, K.; Okada, K.; Inaba, M. Recognition and manipulation integration for a daily assistive robot working on kitchen environments. In Proceedings of the 2010 IEEE International Conference on Robotics and Biomimetics, Tianjin, China, 14–18 December 2010; pp. 196–201. [Google Scholar]
- Martinez-Martin, E.; Del Pobil, A.P. Object detection and recognition for assistive robots: Experimentation and implementation. IEEE Robot. Autom. Mag. 2017, 24, 123–138. [Google Scholar] [CrossRef]
- Maymó, M.R.; Shafti, A.; Faisal, A.A. Fast orient: Lightweight computer vision for wrist control in assistive robotic grasping. In Proceedings of the 2018 7th IEEE International Conference on Biomedical Robotics and Biomechatronics (Biorob), Enschede, The Netherlands, 26–29 August 2018; pp. 207–212. [Google Scholar]
- Martinez-Martin, E.; Del Pobil, A.P. Vision for Robust Robot Manipulation. Sensors 2019, 19, 1648. [Google Scholar] [CrossRef] [Green Version]
- Natarajan, S.K.; Ristic-Durrant, D.; Leu, A.; Gräser, A. Robust stereo-vision based 3D modelling of real-world objects for assistive robotic applications. In Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems, Francisco, CA, USA, 25–30 September 2011; pp. 786–792. [Google Scholar]
- Ristic-Durrant, D.; Grigorescu, S.M.; Graser, A.; Cojbasic, Z.; Nikolic, V. Robust stereo-vision based 3d object reconstruction for the assistive robot friend. Adv. Electr. Comput. Eng. 2011, 11, 15–22. [Google Scholar] [CrossRef]
- Yamazaki, K.; Nishino, T.; Nagahama, K.; Okada, K.; Inaba, M. A vision system for daily assistive robots using character information in daily environments. In Proceedings of the 2013 IEEE/SICE International Symposium on System Integration, Kobe, Japan, 15–17 December 2013; pp. 901–906. [Google Scholar]
- Zhang, J.; Zhuang, L.; Wang, Y.; Zhou, Y.; Meng, Y.; Hua, G. An egocentric vision based assistive co-robot. In Proceedings of the 2013 IEEE 13th International Conference on Rehabilitation Robotics (ICORR), Seattle, WA, USA, 24–26 June 2013; pp. 1–7. [Google Scholar]
- Leroux, C.; Lebec, O.; Ghezala, M.B.; Mezouar, Y.; Devillers, L.; Chastagnol, C.; Martin, J.C.; Leynaert, V.; Fattal, C. Armen: Assistive robotics to maintain elderly people in natural environment. IRBM 2013, 34, 101–107. [Google Scholar] [CrossRef]
- McMullen, D.P.; Hotson, G.; Katyal, K.D.; Wester, B.A.; Fifer, M.S.; McGee, T.G.; Harris, A.; Johannes, M.S.; Vogelstein, R.J.; Ravitz, A.D.; et al. Demonstration of a semi-autonomous hybrid brain–machine interface using human intracranial EEG, eye tracking, and computer vision to control a robotic upper limb prosthetic. IEEE Trans. Neural Syst. Rehabil. Eng. 2013, 22, 784–796. [Google Scholar] [CrossRef] [Green Version]
- Loconsole, C.; Stroppa, F.; Bevilacqua, V.; Frisoli, A. A robust real-time 3D tracking approach for assisted object grasping. In International Conference on Human Haptic Sensing and Touch Enabled Computer Applications; Springer: Berlin/Heidelberg, Germany, 2014; pp. 400–408. [Google Scholar]
- Quintero, C.P.; Ramirez, O.; Jägersand, M. Vibi: Assistive vision-based interface for robot manipulation. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 4458–4463. [Google Scholar]
- Jain, S.; Argall, B. Grasp detection for assistive robotic manipulation. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 2015–2021. [Google Scholar]
- Bousquet-Jette, C.; Achiche, S.; Beaini, D.; Cio, Y.L.K.; Leblond-Ménard, C.; Raison, M. Fast scene analysis using vision and artificial intelligence for object prehension by an assistive robot. Eng. Appl. Artif. Intell. 2017, 63, 33–44. [Google Scholar] [CrossRef]
- Gualtieri, M.; Kuczynski, J.; Shultz, A.M.; Ten Pas, A.; Platt, R.; Yanco, H. Open world assistive grasping using laser selection. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 4052–4057. [Google Scholar]
- Zhang, Z.; Huang, Y.; Chen, S.; Qu, J.; Pan, X.; Yu, T.; Li, Y. An intention-driven semi-autonomous intelligent robotic system for drinking. Front. Neurorobot. 2017, 11, 48. [Google Scholar] [CrossRef] [Green Version]
- Erol, B.A.; Majumdar, A.; Lwowski, J.; Benavidez, P.; Rad, P.; Jamshidi, M. Improved deep neural network object tracking system for applications in home robotics. In Computational Intelligence for Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2018; pp. 369–395. [Google Scholar]
- Wang, C.; Freer, D.; Liu, J.; Yang, G.Z. Vision-based Automatic Control of a 5-Fingered Assistive Robotic Manipulator for Activities of Daily Living. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 627–633. [Google Scholar]
- Ka, H.; Ding, D.; Cooper, R.A. Three dimentional computer vision-based alternative control method for assistive robotic manipulator. Symbiosis 2016, 1. in press. [Google Scholar]
- Ivorra, E.; Ortega, M.; Alcañiz, M.; Garcia-Aracil, N. Multimodal computer vision framework for human assistive robotics. In Proceedings of the 2018 Workshop on Metrology for Industry 4.0 and IoT, Brescia, Italy, 16–18 April 2018; pp. 1–5. [Google Scholar]
- Kasaei, S.H.; Oliveira, M.; Lim, G.H.; Lopes, L.S.; Tomé, A.M. Towards lifelong assistive robotics: A tight coupling between object perception and manipulation. Neurocomputing 2018, 291, 151–166. [Google Scholar] [CrossRef]
- Shim, K.H.; Jeong, J.H.; Kwon, B.H.; Lee, B.H.; Lee, S.W. Assistive robotic arm control based on brain-machine interface with vision guidance using convolution neural network. In Proceedings of the 2019 IEEE International Conference on Systems, Man and Cybernetics (SMC), Bari, Italy, 6–9 October 2019; pp. 2785–2790. [Google Scholar]
- Meng, L.; De Silva, C.W.; Zhang, J. 3D visual SLAM for an assistive robot in indoor environments using RGB-D cameras. In Proceedings of the 2014 9th International Conference on Computer Science & Education, Piscataway, NJ, USA, 22–24 August 2014; pp. 32–37. [Google Scholar]
- Furuta, Y.; Wada, K.; Murooka, M.; Nozawa, S.; Kakiuchi, Y.; Okada, K.; Inaba, M. Transformable semantic map based navigation using autonomous deep learning object segmentation. In Proceedings of the 2016 IEEE-RAS 16th International Conference on Humanoid Robots (Humanoids), Cancun, Mexico, 15–17 November 2016; pp. 614–620. [Google Scholar]
- Papadakis, P.; Filliat, D. Generic object discrimination for mobile assistive robots using projective light diffusion. In Proceedings of the 2018 IEEE Winter Applications of Computer Vision Workshops (WACVW), Lake Tahoe, Nevada, 12–15 March 2018; pp. 60–68. [Google Scholar]
- Nagahama, K.; Takeshita, K.; Yaguchi, H.; Yamazaki, K.; Yamamoto, T.; Inaba, M. Estimating door shape and manipulation model for daily assistive robots based on the integration of visual and touch information. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 7660–7666. [Google Scholar]
- Othman, K.M.; Rad, A.B. A doorway detection and direction (3Ds) system for social robots via a monocular camera. Sensors 2020, 20, 2477. [Google Scholar] [CrossRef] [PubMed]
- Murray, S. Real-time multiple object tracking-a study on the importance of speed. arXiv 2017, arXiv:1709.03572. [Google Scholar]

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Montaño-Serrano, V.M.; Jacinto-Villegas, J.M.; Vilchis-González, A.H.; Portillo-Rodríguez, O. Artificial Vision Algorithms for Socially Assistive Robot Applications: A Review of the Literature. Sensors 2021, 21, 5728. https://doi.org/10.3390/s21175728
Montaño-Serrano VM, Jacinto-Villegas JM, Vilchis-González AH, Portillo-Rodríguez O. Artificial Vision Algorithms for Socially Assistive Robot Applications: A Review of the Literature. Sensors. 2021; 21(17):5728. https://doi.org/10.3390/s21175728
Chicago/Turabian StyleMontaño-Serrano, Victor Manuel, Juan Manuel Jacinto-Villegas, Adriana Herlinda Vilchis-González, and Otniel Portillo-Rodríguez. 2021. "Artificial Vision Algorithms for Socially Assistive Robot Applications: A Review of the Literature" Sensors 21, no. 17: 5728. https://doi.org/10.3390/s21175728