1. Introduction
The ongoing trend in social life to often use a virtual environment is accelerated by the COVID-19 pandemic. Throughout the last year in particular, work, social, and leisure behaviors have changed rapidly towards the digital world. This development finds resonance in the May 2020 Sandvine report, which revealed that global Internet traffic was dominated by video, gaming, and social usage in particular, with these accounting for more than 80% of the total traffic [
1], with YouTube hosting over 15% of these volumes.
For video streaming, the Quality of Experience (QoE) is the most significant metric for capturing the perceived quality for the end user. The initial playback delay, streaming quality, quality changes, and video rebuffering events are the most important influencing factors [
2,
3,
4]. Due to the increasing demand, streaming platforms like YouTube and Netflix have had to throttle the streaming quality in Europe in order to enable adequate quality for everybody on the Internet [
5]. This affects the overall streaming QoE for all end users, and ultimately the streaming provider’s revenue from long-term user churn.
From the perspective of an Internet Service Provider (ISP), responsible for network monitoring, the goal is to satisfy their customers and operate economically. Intelligent and predictive service and network management is becoming more important to guarantee good streaming quality and meet user demands. However, since most of the data traffic is encrypted these days, in-depth monitoring with deep packet inspection is no longer possible for an ISP to determine crucial streaming related quality parameters. It is therefore necessary to predict quality by other flow monitoring and prediction techniques. Furthermore, the increasing load and different volumes of flows, and consequently the processing power required to monitor each flow, make detailed prediction even more complex, especially for a centralized monitoring entity.
In this scenario, given the enormous number of different streaming sessions and the associated humongous global data exchange, the analysis of every video stream at packet level cannot be carried out. To enable monitoring in a decentralized way with limited resources available in the last mile, a lightweight approach without unmanageable overhead is important to improve current services. This leads to a scalable in-network QoE monitoring at decentralized entities through a proper QoE prediction model.
This work reviews several different Machine Learning (ML) approaches to estimate the initial playback delay, video playback quality, video quality changes, and video rebuffering events using data originating from the native YouTube client on a mobile device. The goal of this work is to investigate the following research questions:
Is estimation of the most important QoE parameters possible using only low-volume uplink data?
What data is required and how much prediction accuracy impairment is acceptable with only uplink data, compared to state-of-the-art downlink-based ML prediction approaches?
From our investigation, we show that the Random Forest (RF)-based approach in particular shows promising results for all metrics. Using only uplink information, this approach is lightweight compared to downlink-based predictions. Based on a dataset that was measured over 28 months between November 2017 and April 2020, a total of over 13,000 video runs and 65 days of playback are evaluated. Studying the performance of the models provides valuable insights, helping to draw conclusions on the applicability of specific models and parameter options. The contribution of this work is threefold:
Three different general ML models are defined, compared, and evaluated on the entire dataset with YouTube streaming data from the mobile app in order to predict the most common QoE-relevant metrics. It is shown that even a simple RF-based approach with selected features shows F1 scores of close to 0.90 to help decide whether video rebuffering occurs during the download of a video chunk request.
Details of ML improvements are discussed. This defines a lightweight approach that only uses uplink traffic information, but with only a marginal decrease in prediction accuracy for a target metric. The learning is based on the fact that during a streaming session, the uplink requests are sent in series to the content server to fill the client’s buffer. After playback starts and the buffer is full, the behavior changes to an on–off traffic pattern, which is characteristic for streaming today. This is utilized in the learning algorithm, since the complete playback behavior is reflected in a change in the inter-arrival times of the uplink requests.
The third contribution is to verify that the approach is practically feasible and requires lesser monitoring resources by estimating the processing and monitoring effort for random artificially-generated video content and defining a queuing model for studying the load of a monitoring system.
Each model is validated using videos other than those utilized for testing, which leads to only slightly worse results. As a result, our work is a valuable input for network management to improve streaming quality for the end user. The remainder of this work is structured as follows: in
Section 2, background information is defined with a focus on video streaming and streaming behavior used as information in the methodology in this work to predict streaming quality. The streaming quality metrics are also introduced here.
Section 3 summarizes related work, first with a literature overview and afterwards through a differentiation between uplink and complete packet trace monitoring, as done in most related works by an effort analysis.
Section 4 summarizes the measurement process involving the testbed and the studied scenarios, and
Section 5 presents the dataset. A general overview of relevant information in the dataset is provided, with focus on the relevant streaming quality metrics. The dataset is used to train the models presented in
Section 6, where additional information about the features and feature sets is given. The results are discussed in
Section 7 for each QoE relevant streaming metric.
Section 8 concludes the paper.
3. Related Work
There are different methodologies in the literature to quantify the video playback quality, detect and estimate the metrics influencing the Quality of Service (QoS), and at the end predict the perceived QoE for the end user. For that reason, this section covers the literature discussing methods to detect or estimate quality degradation metrics, QoS or QoE measurement or prediction approaches, and different ideas to quantify playback quality. Furthermore, request and feature extraction approaches relevant for streaming based works are presented. An overview of selected, especially relevant, related work is summarized in
Table 1. The main influencing factors as reflected in the table, which differentiate approaches, are six: real time applicability, the target platform, the approach itself, the prediction goal, the data focus, and the target granularity from time window based approach to a complete session.
There are many works in the literature describing, predicting, or analyzing the QoE. A comprehensive survey of QoE in HAS is given by Seufert in [
3]. Besides knowing the influencing factors, another important goal is to measure all relevant parameters for good streaming behavior. One of the first works tackling streaming measurements calculating the application QoS and estimating the QoE based on a Mean Opinion Score (MOS) scale was published in 2011 by Mok [
19]. However, with the widespread adoption of encryption in the Internet, and also in video streaming, the approaches became more complex, and simple Deep Packet Inspection (DPI) to receive the current buffer level was no longer possible.
Nowadays, several challenges must be resolved for in-depth quality estimation in video streaming: First, data must be measured on a large scale. This is already being done for several platforms, including, among others, YouTube [
20], Netflix and Hulu [
21], and the Amazon Echo Show [
22]. Afterwards, a flow separation and detection is essential to receive only the correct video flow for further prediction. Here, several approaches exist for streaming, e.g., [
7,
23], as ISP middle-box [
24], or with different ML techniques [
25].
After determination of the correct video flow, the approach is defined. In modern streaming, two approach types are well adapted: session reconstruction and ML models. The session reconstruction-based approaches show that it is possible to predict all relevant QoE metrics. Whereas in [
26], only stalling is predicted with session reconstruction, Mangla shows its utility in [
17] for modeling other QoE metrics and comparing them to ML-based approaches. Similar works have been published by Schatz [
27] and Dimopoulos [
28] to estimate video stalls by packet trace inspection of HTTP logs.
Especially in recent years, several ML based approaches have been published for video QoE estimation. For YouTube in particular, according to
Table 1, an overall QoE prediction with real time approaches and focus on inspecting all network packets, is available from Mazhar [
10], Wassermann [
11], and Orsolic [
12]. For all works, an in-depth analysis of voluminous network data is done, and more than 100 features each are extracted. While Mazhar only provides information about prediction results for the YouTube desktop version, the mobile version is also considered by Wassermann. Furthermore, Wassermann shows that a prediction of up to 1 s granularity is possible with a time-window based approach, with accuracies of more than 95%. The received recall for stalling as the most important QoE metric is 65% for their bagging approach and 55% for the RF approach. The precision is 87% and 88%, respectively. In this work, we receive macro average recall values of more than 80% and a comparable precision. Furthermore, Orsolic provides a framework that can also be utilized for other streaming platforms.
Different approaches are adopted by, among others, Bronzino [
13] and Dimopoulos [
14]. Although the two works are not real time capable, Dimopoulos studies the QoE of YouTube with up to 70 features, while Bronzino also trains the presented model with Amazon and Twitch streaming data by calculating information like throughput, packet count, or byte count.
Gutterman [
18] has a different approach, in which, compared to the packet based approaches, a video chunk-based approach is chosen, with four states: increasing buffer, decreasing buffer, stalling, and steady buffer. The approach is similar to this work, while the data resolution on application layer is higher in the approach from Gutterman. It is evident that in Gutterman’s dataset the phases with dropping buffer are even more underrepresented, from 5.9% to nearly 7%. In contrast, in the present work it is 9.9%. Furthermore, Gutterman uses sliding windows up to a size of 20, including historic information up to 200 s. Overall, similar results are achieved. When we compare the video phase prediction to the best results of Gutterman’s study that is received for the Requet App-LTE scenario, slightly better precision and recall scores for the stalling phase are achieved by Gutterman. The results for the steady phase and the recall for the buffer increase is similar. In the buffer decay phase (depletion in this work), we outperform Gutterman by more than 6% in the precision score and 50% in the recall score. Nevertheless, with the difference in dataset and the amount of included historic information, a complete comparison is difficult.
While different ML algorithms are investigated, most of the related approaches mentioned use at least one type of tree-based ML model. This popularity is a result of multiple factors, including ease of development and lower consumption of computational resources. Moreover, the tree-based algorithms, e.g., RF, perform on a similar level or better than others [
11,
13,
18], when comparing multiple algorithms within one work.
Gutterman [
18] investigates the performance of a NN, with similar results compared to a tree-based approach. Shen [
15] uses a Convolutional Neural Network (CNN) to infer initial delay, resolution, and stalling. The real-time approach uses video data from YouTube and Bilibili and predicts QoE-metrics for windows of 10 s length. Among the tested ML algorithms, the CNN achieves the best results. The potential of deep learning to predict QoE is emphasized further in the work of Lopez [
16] by combining CNN and Recurrent Neural Network (RNN).
3.1. Preliminary Considerations on Monitoring and Processing Effort
The approaches in the literature use different time windows and parameters of uplink and downlink in different granularity. Given the varying degrees of complexity, there is a trade-off between accuracy and computational effort.
This is especially important in terms of predicting streaming video parameters in communication networks on a large, distributed scale. An efficient approach is usually preferred here, which can be adopted on the last mile close to customers where little computing power is available. Hence, the question arises, with regard to the related work above: How much monitoring and computational effort is required to achieve high accuracy with machine learning techniques for video streaming?
In preparation for the following study, we examine how much data might be generated during video streaming of arbitrary videos and how much data needs to be monitored and processed with regard to the various methods available in the literature. While there are a large number of proposed approaches that detect quality, stalling, and the playback phases, the approach in this work focuses exclusively on partial information for monitoring and processing, e.g., the uplink information and the features generated from it.
In the following steps, 9518 random artificially generated videos are created according to models from the literature [
29,
30], and the effort is quantified that is required to obtain the specified partial information while streaming them (streaming simulation). Note that this is meant to be a pre-study with focus on arbitrary video content. For the dataset used for the actual study later, we refer to
Section 4.2 and
Section 5 for more information on the dataset and measurement scenarios. The generated data, scripts, and additional evaluation are available in [
31]. The aim is to show how much data and effort is required when machine learning is used with partial data in comparison to a full monitoring. Later on, in the next sections, machine learning is carried out that quantifies the accuracy for different feature sets on partial data.
3.1.1. Methodology
The basis for this evaluation is the modeling of different videos with data-rate models generating video streaming content that is then streamed with the help of a simulation of adaptive bitrate adaptation logics (ABRs), which are then mapped to requests at the network layer in order to determine the amount of data while streaming. All traffic models for H264/MPEG-like encoded variable bitrate video in the literature can be broadly categorized into (1) data-rate models (DRMs) and (2) frame-size models (FSMs) [
29]. FSMs focus on generating single frames for video content in order to gain the ability to create arbitrary yet realistic videos [
30,
32]. The approach works as follows: First, we create the video content in different resolutions. This results in a variable bitrate per second video content for each resolution. Afterwards, adaptation is applied to the video content with ABRs. In this case, an adaption of three quality switches is applied with a duration of one third of the total video length. Finally, this can be used to calculate how many bytes must be processed and monitored if (1) the entire video has to be considered or (2) if only 5, 3, or 1 HTTP requests in up- and downlink have to be considered.
3.1.2. Results
Table 2 shows the generated video content according to [
30,
32]. We have generated a total of 9518 videos from 9518 samples each for every common resolution from 144p to 1080p.
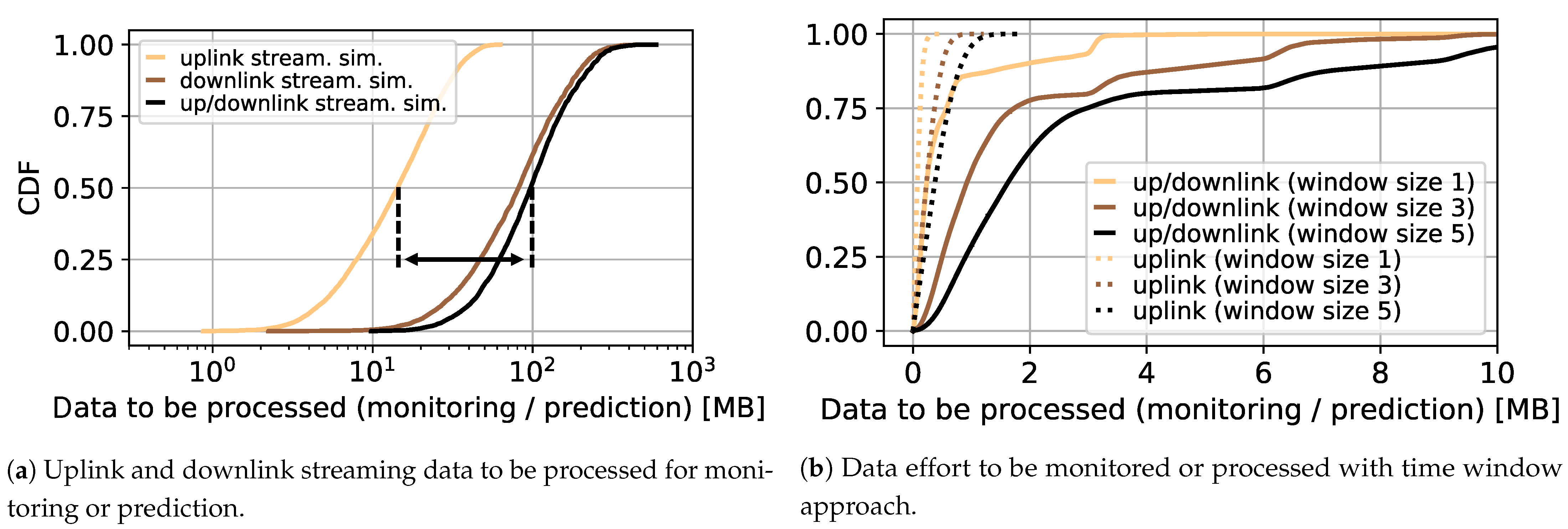
Figure 1a shows the empirical cumulative density function (CDF) for the bytes required for streaming a randomly generated video. The individual lines in the plot reflect the effort required to consider the downlink traffic, the uplink traffic, and the entire corresponding traffic. Overall, the 50% quantile results in a traffic reduction of around 86% if only the uplink has to be considered. This shows the advantage of approaches that only require uplink data for monitoring and prediction. As suggested above, these approaches are particularly interesting in practice when there are no large computational resources available; for example, when making predictions close to the user within the last mile.
Figure 1b shows the data effort if only a time window of the last
x HTTP requests (1, 3, or 5 requests) is used. This is of particular interest for the prediction itself, since only a small amount of data has to be processed here.
3.2. Queuing Model of QoE Monitoring Entity
This statement is further evaluated by a simple queuing model studying the monitoring load of a monitoring entity for QoE prediction depending only on uplink traffic, compared to a full packet trace consisting of uplink and downlink traffic. A visualization of the model is given in
Figure 2.
3.2.1. General Modeling Approach
During traffic flow monitoring, all packets of a video stream arrive at the monitoring instance, wait until the monitoring entity is free, and are subsequently processed. This is described by a Markov model with a packet arrival process
A, an unlimited queue, and a processing unit
B. The arrival process can be described as a Poisson process with rate
when a sufficient amount of flows are monitored in parallel [
33]. This holds true for this approach, since studying a small number of flows does not require this effort. The processing unit
B processes the packets in the system with rate
. To analyze the model, a general independent processing time distribution with expected average processing time
can be assumed. This holds true, for example, for a deterministic processing time distribution. Then, the system can be described as an
system. For a stable system
is given, which means the arrival rate must not exceed the processing rate, in order to not overload the system. Furthermore, for real-time monitoring or to satisfy specific network management service level agreements (SLA), a sojourn time or system response time
can be defined, while
x describes the delay in the system. For reasons of simplicity and since the model is only used as an illustration, the following model is analyzed as an
system with an exponential processing time distribution.
3.2.2. Modeling Results
For the usability study of the approach in a real environment, two different questions are answered: (1) What is the average sojourn time or average response time of the system
dependent on the processing time of the processing unit within the monitoring entity; and (2) How many video streams, or streaming flows, can be monitored in parallel without exceeding a target delay with a probability
q? Both questions are answered, based on the arrival rates for uplink traffic (
s) and the complete packet trace containing uplink and downlink traffic (
s) received by the streaming simulation above. Furthermore, the uplink traffic rate (
s) and the complete uplink and downlink traffic rate (
s) of the complete dataset used for this work are used. A detailed overview of the dataset follows, in
Section 5.
To answer the first question, Little [
34] is used to receive the average response time by
, with
as long-term average number of customers in a stationary system and
as utilization of the processing unit. With Little [
34],
is received as
with
as average processing time of the processing unit within the monitoring entity. As processing time, a value range between 1 s and 1 s is studied in
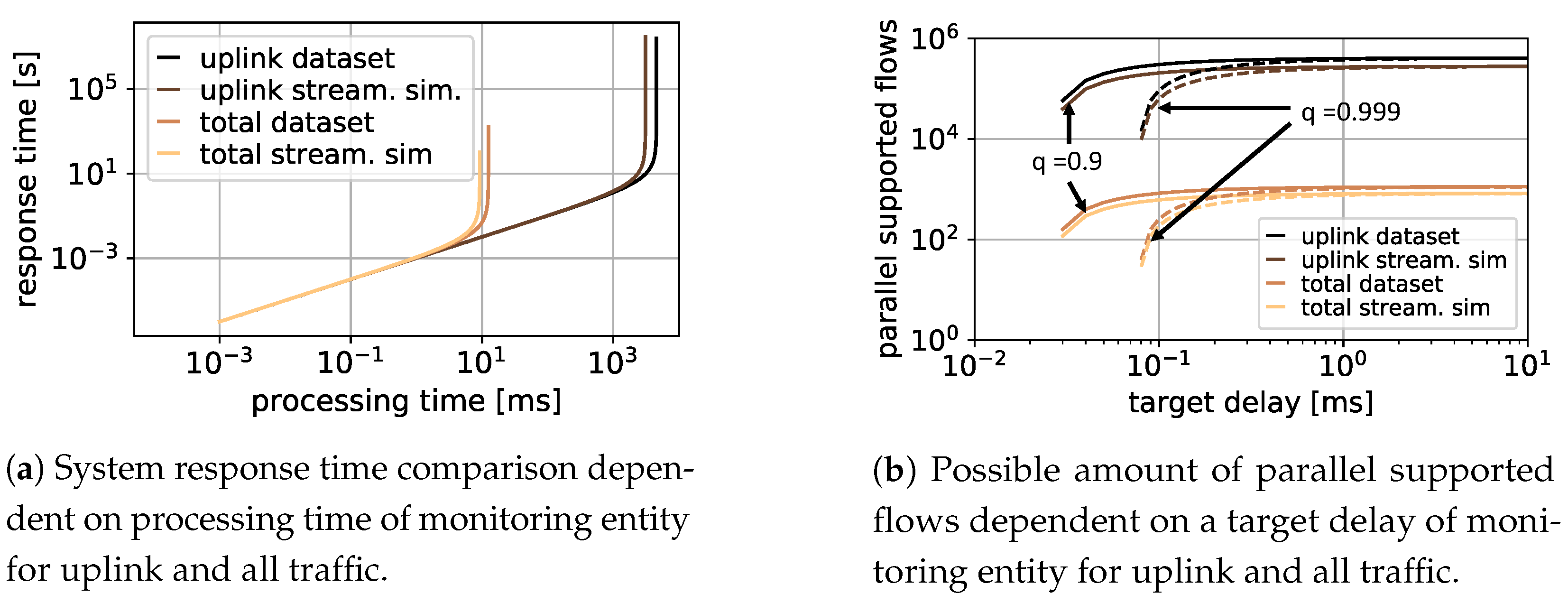
Figure 3a at the x-axis. The y-axis shows the resulting response time of the system. The yellow line shows the result when monitoring uplink and downlink data considering the streaming simulation, whereas the orange line is the result considering the full packet trace received by the dataset. The results are shown in brown when monitoring only uplink traffic for the streaming simulation, and in black for the dataset. It is evident that the average response time is similar up to a processing time of 10 ms per packet. For slower systems, the processing entity of the monitoring system is not able to analyze all packets of the complete stream anymore. Thus, the response time increases drastically. When only the uplink data is to be monitored, the processing entity can process all data up to a processing time of more than 1 s per packet. Thus, slower and cheaper hardware could be used.
To answer the second question of how many streaming flows can be supported in parallel,
or
with x as target processing time or target delay in seconds is introduced. Furthermore,
q is the target probability describing the percentage of packets that must be analyzed faster than
x to guarantee specific SLAs. For positive
t-values, the distribution function for the response time is described by
. Solving this, the supported positive arrival rate
is dependent on the target probability
q according to
.
Figure 3b shows the amount of flows supported in parallel by a 1 G switch for monitoring only uplink traffic, compared to all uplink and downlink packets based on a target delay
x in milliseconds. The assumption is that the switch can process 1 Gbps and the packets always fill the maximal transmission unit (MTU) in the Internet, of 1500 B. The target probability
q is set to 90% and 99.9%, respectively. It is obvious that focusing on only uplink-based monitoring allows 100 to 1000 times more flows compared to full packet trace monitoring. Furthermore, since there is an active trend towards increasing data rates with higher resolutions and qualities, uplink-based monitoring is a valuable methodology to deal with current and future video streams while saving hardware costs or distributing monitoring entities.
5. Dataset
For an in-depth analysis of the streaming behavior, a dataset is required that covers specific and regular behavior for all QoE relevant metrics, which are initial delay, streaming quality, for YouTube the video resolution, quality changes, and stalling. For that reason, a dataset is created in this work using the above-mentioned testbed and measurement scenarios, which covers 13,759 valid video runs and more than 65 days of total playback time. Parts of the dataset are already published for the research community [
8,
20]. In the following subsection, first the dataset postprocessing is explained, giving details on network and application data. Afterwards, a dataset overview is presented, with the main focus being on streaming relevant metrics.
5.1. Postprocessing
The postprocessing of the application data and network traces in this work is twofold. First, the network traces are analyzed and all video related flows are extracted. Afterwards, the application data are postprocessed and combined information from the application and the network is logged for further usage.
5.1.1. Network Data
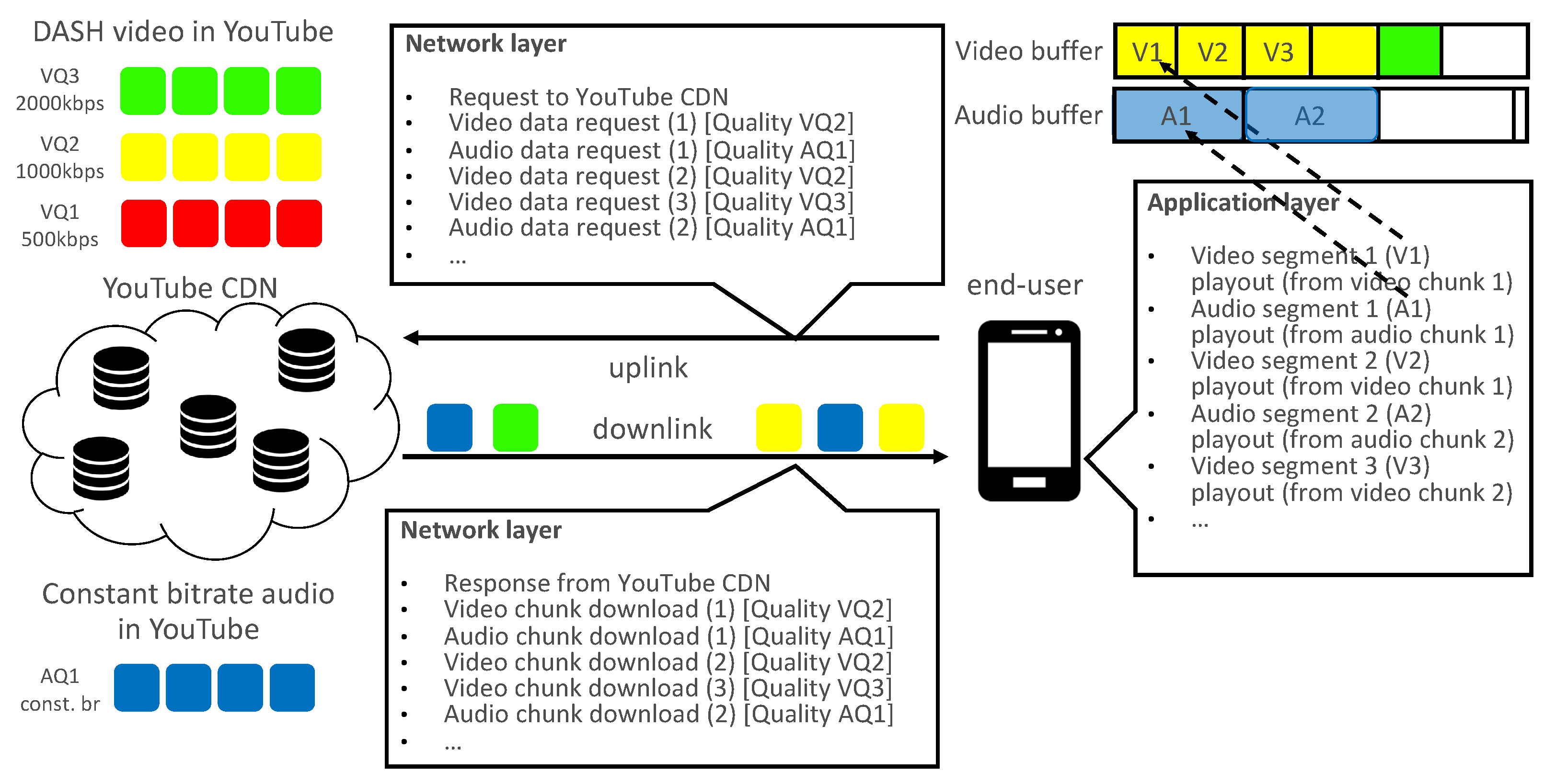
The network data are captured in the pcap tcpdump format. By following the IP and port addresses of the
googlevideo.com DNS, all traffic associated with the YouTube video can be separated from cross traffic like advertising, additional video recommendations, or pictures. For each packet of this traffic, the packet arrival time, the packet source and destination IP address and port, and the payload size in bytes are extracted.
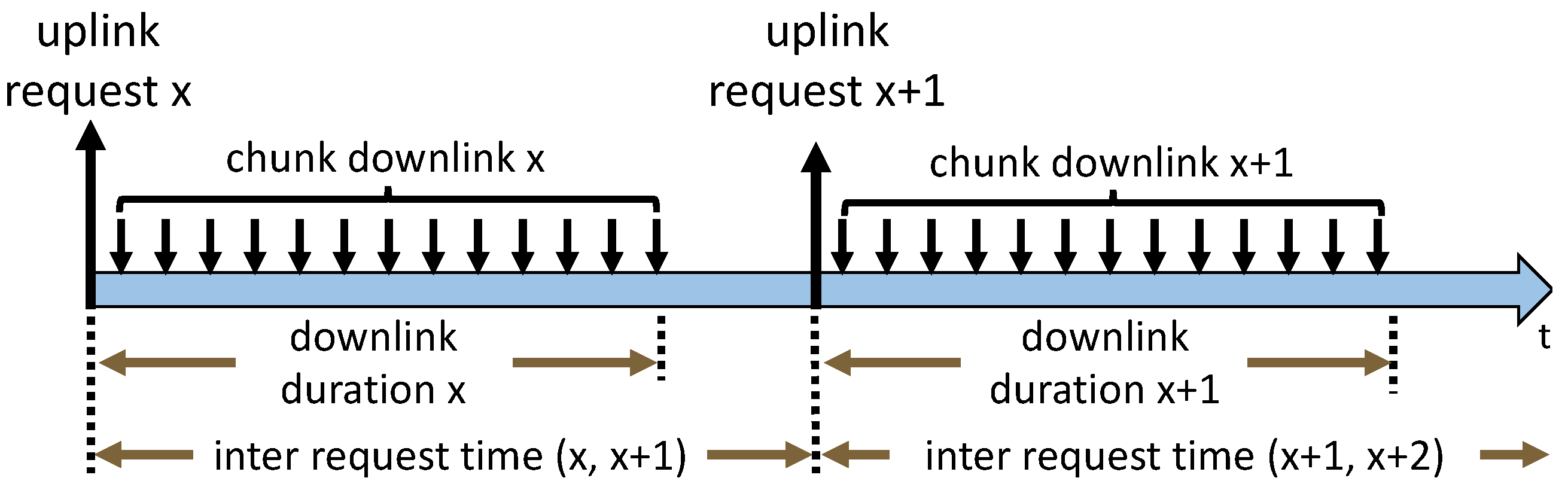
Consecutive download of video data is required in video streaming to guarantee smooth playback. Therefore, requests are detected in the uplink, asking for video data from the YouTube server. Thus, all packets containing payload to the YouTube server are extracted from the received packets and named as uplink chunk requests. Here, we assume that the video is downloaded in a consecutive manner according to
Figure 4. This means request
x is always requested before request
x + 1 and downloaded completely. Thus, all downlink traffic following a request in the same flow is marked as associated to that specific request, before the next one is sent to the server. In this way, information such as the amount of uplink and downlink traffic in bytes, amount of uplink and downlink packets, and protocol associated with one request can be extracted. Furthermore, the last downlink packet of request
x, the end of
downlink duration x in
Figure 4, need not necessarily match with the next uplink request timestamp.
5.1.2. Application Data
The application information Stats for nerds is available as a JSON-based file. There, several application specific parameters are logged together with a timestamp in 1 s granularity.
Table 3 gives an overview of all parameters relevant for this work. The postprocessed application data are added to the network data for further usage. The full dataset with all information for each request used in the learning process in this work is available in [
31]. Further details about data extraction are presented in [
8,
20].
5.2. Data Overview
After data postprocessing, a more detailed overview of the dataset is visible, as shown in
Table 4. The table shows that 7015 of all videos, or 51.0%, have at least one change of the
fmt-value in Stats for nerds. This change is a playback resolution change according to the YouTube HAS algorithm, also used as quality change. Thus, in the following paragraphs, the terms resolution change and quality change are used interchangeably. The dataset shows 22,015 quality changes in all. This is detectable by having different video format ID values (fmt-values) in a single video run. Furthermore, 2961 videos or 21.5% have at least one stalling event, accounting for a total of 5934 stalling instances and more than 32 h of stalling time. The stalling is detected by analyzing the buffer health and the played out frames. If the timestamp of the log is increasing faster than the frames are played out and the buffer health is close to zero, the player is assumed to stall.
The stalling duration varies from less then one second to 117 s for all videos in the dataset. Short stalling of less than 5 s occurs in 20% of all stalling cases. The medium stalling duration is 10.5 s and the mean is detected at 19.87 s. So as to have no conflict with the initial playback delay, stalling within the first 5 s of video playback time is not considered. Furthermore, for a learning approach with historic information as investigated in this work, stalling prediction at the beginning of the video is not possible.
The dataset contains videos streamed with TCP and UDP, visible in the network data. Among all runs, 22.9% are streamed with TCP, and the remainder with UDP. A more detailed investigation of the main QoE degradation factors initial delay, playback quality, quality changes, and stalling in the dataset follows in the respective sections of the methodology.
To acquire more information about the parameters influencing specific streaming relevant metrics, first of all a dataset study is done. Since no video specific information like video ID or resolution is available from encrypted network traffic, this is not studied in this work. Furthermore, the available downlink bandwidth to stream the videos is not analyzed, since it is not directly detectable from the traffic trace. Note that there is no explicit analysis of the amount of totally downloaded and uploaded bytes for specific QoE relevant metrics, since this is not the main focus of this work and is highly dependent on the video resolution. The focus in the following paragraphs is on the most relevant influencing parameters with an impact on the prediction result. Additional data set analysis is presented in
Appendix B.
5.3. Initial Delay
By using the first non-zero played out frames value, information is received when the first playback is logged in the Stats for nerds data. Since the logging granularity there is about 1 s, the exact play start cannot be extracted from the data. Using the number of played out frames and the video fps, showing how many frames are played out within one second, the initial playback start can be calculated. Furthermore, the initial video chunk request timestamp is logged in the network data file. That is subtracted from the playback start timestamp to receive the ground truth initial delay. The analysis shows that the mean ground truth initial delay is 2.64 s.
Request Study
Since the main objective of this work is estimating QoE relevant metrics based on uplink request, the required number of uplink requests to start the video playback are studied for initial delay prediction. Therefore, all detected chunk requests before the playback starts are summed up.
Figure 5a shows in black the number of requests sent to the YouTube server before the playback starts for all videos as CDF. The brown line shows the number of requests completely downloaded according to the network data analysis presented above. The figure shows that the playback can start when only a single request is sent, and for a very little percentage of all videos before the first request is downloaded completely. Furthermore, for more than 60% of all measured runs, five requests must be sent to start the video and in total up to ten requests can be required until the initial video playback starts. Since according to
Figure 5a, the number of chunk request downloads started before playback start can be higher than the number of chunk request downloads ended, video playback can start in the middle of an open chunk request download. This happened in 69.72% of all runs. However, no additional information is received by further analyzing this behavior.
5.4. Video Quality
For an in-depth analysis of the streaming behavior, next to the initial delay, the video quality is an important metric. The video quality is described by the overall playback quality and the extent of quality changes. Since this work deals with the analysis of playback quality with network data without studying the effect of packet loss, no frame errors like blur or fragments in single frames are observed. Thus, only the YouTube format ID as quality is taken into consideration in this work.
In total, more than 1.1 million requests are measured, as summarized in
Table 5. The table shows that, except for the 1444p resolution, more than 80,000 requests are measured each. The highest representative is 720p, which is the target resolution for many videos at the smartphone without triggering higher quality manually. Since only 841 requests are measured for 1440p video resolution and YouTube did not automatically trigger 1440p quality, in the following sections only quality up to 1080p is studied. Furthermore, except for newest generation smartphones, which incidentally also start using 4K videos, most smartphones do not support quality higher than 1080p. A screen resolution of 1440p or higher was used at end 2019 in less than 15% of all phones [
40]. For that reason, 1440p video resolutions are omitted from further evaluation.
To gain greater insight into the requesting behavior of the different quality representations within the dataset, the inter-request time of specific resolutions is studied in the paragraphs that follow.
Inter-Request Time Study
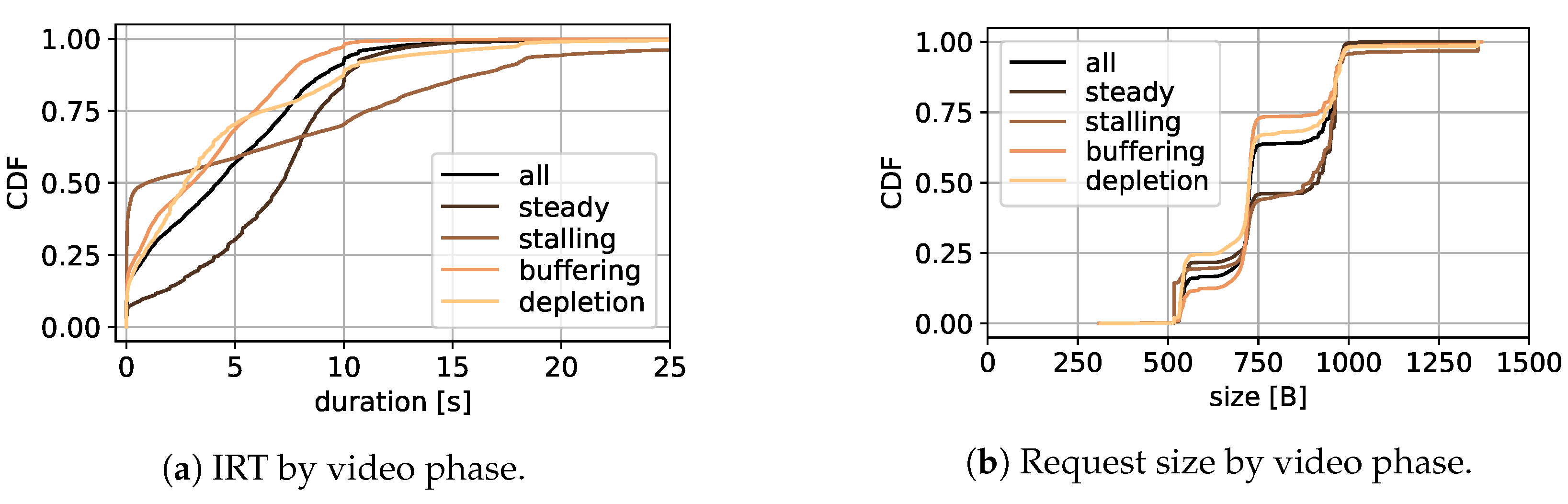
Inter-request time is the main metric to describe the streaming process in this work. An overview of the inter-request time for all available video resolutions is given in
Figure 5b as CDF. The x-axis shows the inter-request time in seconds, whereas the colors of the lines represent the different resolutions, starting at 144p and ending with 1080p, with lighter colors for higher resolutions.
The figure shows that the inter-request time for 10% to 20% of all requests, regardless of resolution, is very small. The measurement shows that this behavior is visible most likely at the beginning of the video, where many requests are sent. For lower resolution, in the best effort phase at the beginning of the video, the data for a single request can be downloaded very fast when enough bandwidth is available, since it is rather small. For that reason, the next request is sent with only a short delay, leading to a short inter-request time. Another explanation for this behavior is the parallel requesting of audio and video data. A more detailed explanation of this is given in [
26], although this plays no further part in this work.
Figure 5b shows, for all resolutions, that more than 70% of all inter-request times are between 0.1 s and 12 s. The rather linear distribution for resolution between 240p to 720p in that time interval in particular is visible, with 240p having the lowest gradient. This means that the inter-request times for all quality levels between 240p to 720p, discussed first in the following paragraphs, show a similar distribution, with 240p having slightly fewer smaller inter-request times compared to the others. For 240p, nearly 60% of all requests show an inter-request time of less than 6 s, while for the others it is 65% to 70%.
The 144p and 1080p resolutions show a different behavior. While 144p shows more instances of larger inter-request times, with only 38% smaller than 6 s, more instances of smaller times are visible for 1080p, with 88% being below 6 s. This observation shows the tendency of having larger inter-request times for poorer quality. One reason for this behavior is the different amounts of data that must be downloaded for specific resolutions, with less data for smaller ones. To minimize the overhead, more seconds of video playback can be requested with a single request for lower resolution. Another reason for this behavior is that lower resolution is used during phases with bandwidth issues. There, the next request can be delayed because the download of the previous one is not finished. Additionally, in the course of this work, the downlink duration and the downlink size per request are studied. The results are similar to the inter-request time study, and thus presented in the
Appendix C.
5.5. Quality Change
The other video quality based metric influencing the received streaming QoE of an end user is quality change. According to the literature, the duration and the volume of quality change are of interest [
3]. Furthermore, the difference in quality before and after the quality change is important; that is, whether the next higher or lower resolution is chosen after a quality change or if available resolutions are skipped [
41]. A more detailed overview of quality change detected in the dataset is provided in the following lines.
In total, 22,123 instances of quality change are detected. By mapping these quality changes to requests, 1.94% of all requests are marked as requests with changing quality. A quality change is mapped to request
x, if it occurs between the request of
x and
according to
Figure 4. An in-depth analysis of the quality before and after change is added in
Appendix D for interested readers.
5.6. Stalling
An overview of the stalling behavior is provided next, as the most important metric influencing streaming quality degradation. Out of the 13,759 valid video runs in the dataset, stalling is detected in 3328 runs, totaling 6450 stalls. In about 50% of the stalling videos, one stalling event is detected, and a second event is detected in another 25% of the runs. Only in less than 3% of all stalling videos are more than 5 stalling events measured. Furthermore, in 40% of all videos where stalling is detected, two or more different qualities were played out when stalling occurred. This means that, although the quality is adapted to the currently available bandwidth, a stalling event occurred. With further regard to the network parameters investigated in cases of stalling, the data show that stalling occurred while starting the download of from one up to 30 requests. This means that stalling continues although other video chunk requests are sent. For that reason, it might be not sufficient to only monitor high inter-request times or delayed requests for stalling detection. More details about stalling position, duration, and distribution across the qualities in the dataset are available in
Appendix E.
7. Evaluation
This section presents the results for predicting the most important QoE metrics: initial delay, video quality, quality change, and stalling. For quality change and stalling prediction, the results for video phase prediction as the basis are presented according to
Section 6.
7.1. Initial Delay
In this section, the performance of the introduced approach is evaluated by first presenting the result of the RF learning approach, followed by the performance and challenges of the deep learning model.
7.1.1. Random Forest Model
To study the performance of the RF model, three different initial settings can be varied: the videos in the training and test sets, the tree generation in the RF algorithm, and the features themselves. For that reason, four scenarios are defined according to
Table 11. For all scenarios, a random video split in training set and test set is done according to the above-mentioned approach. Using a fixed seed of a specific value, the run produces repeatable, reproducible results. By using random seeds for the video split, the videos used for training and testing are varied, and thus the behavior and possibly the model performance change. Furthermore, since the problem of learning an optimal decision tree is known to be NP-complete [
48], different tree generations can be tested to determine the performance variation. This is done by varying the sample of the features to consider, when looking for the best split at each node of the tree. The
video seed of
Table 11 describes the variation in the video distribution in test and training set, and the
tree seed describes the tree generation as mentioned above.
In the baseline scenario, both video and tree seed are fixed to a specific value (42 in this case). In the three variation scenarios, either the video or the tree seed or both are set to random. For each variation scenario, 15 repetitions are done to see differences in the performance of the initial delay estimation. Thus, in total 45 runs are compared to the baseline scenario. Furthermore, all single runs are evaluated to investigate the performance of any random split compared to the baseline scenario.
From a detailed examination of all 45 scenarios, no significant improvement to the baseline scenario of any specific run can be detected. Moreover, the results in
Table 11 show that the mean absolute error (MAE), the 75% percentile, and the 90% percentile are comparable for all variations. It is shown that variation 3 with random test and tree seed performs a little better than the others. However, since the difference is slight, this is not analyzed in detail in the following steps.
It is evident, therefore, that using random seeds in the model creation does not make for significantly better performance in this case, and thus the fixed value of 42 for both the video and the tree seed is used for better and active reproducibility. Note that with other seed values, an additional minor performance improvement may be possible. However, studying this is not the main focus of this work. On the other hand, the improvement of another seed could be a drawback with another dataset.
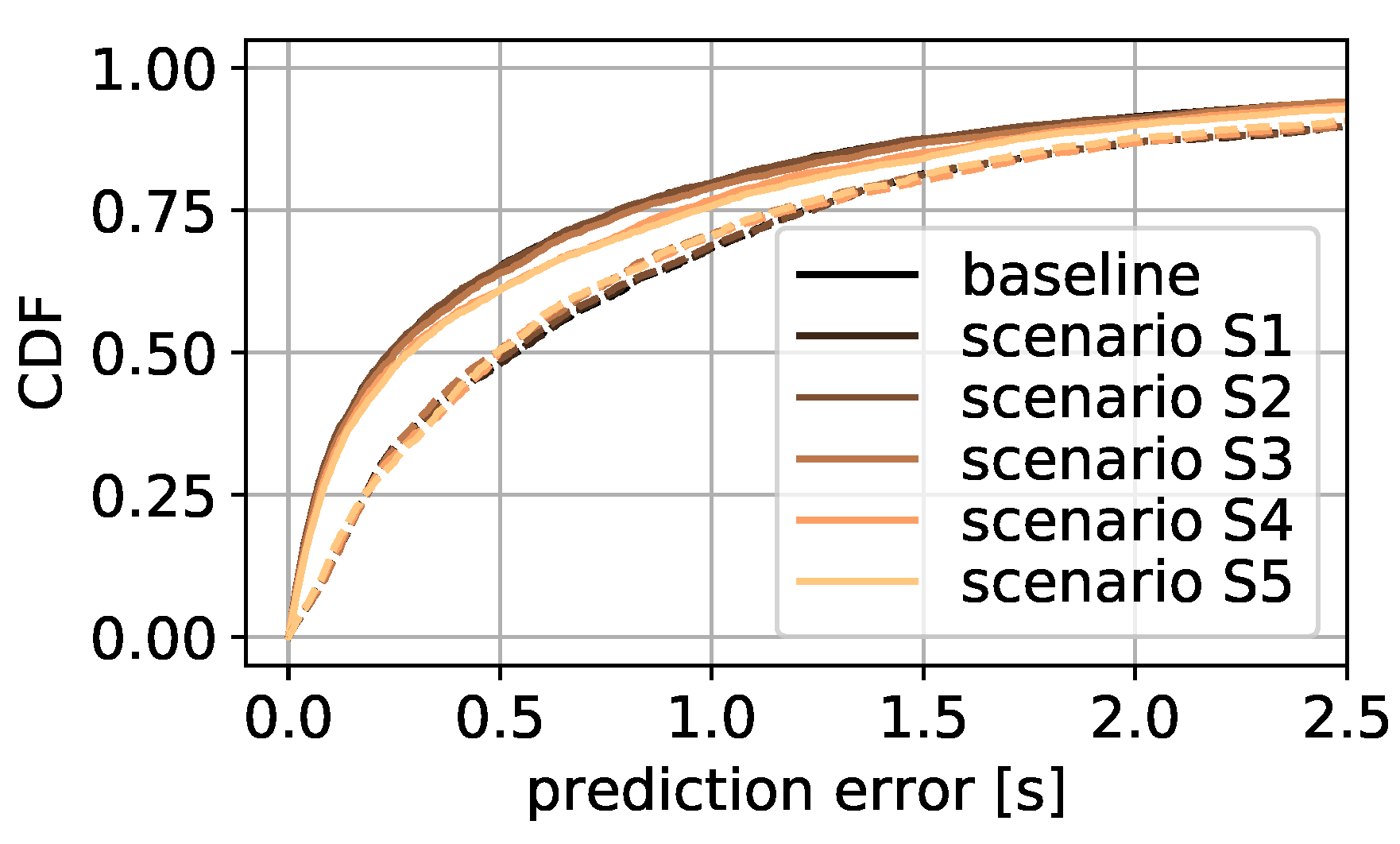
The next study focuses on the number of requests used for RF learning, where the number of requests varies between 5, 10, 15, and 20. The influence of this variation on the initial delay estimation is presented in
Figure 7a as CDF of the prediction error in seconds. The line in black for 20 requests is the baseline of the earlier study. Training the model with 15 requests is shown in brown, 10 requests in orange, and 5 requests in yellow. It is evident that the learning performs similarly for 10 to 20 requests. For 5 requests, a discernible performance loss is presented. The MAE for the scenario with 5 requests is 0.96 s. Compared to that, for 10, 15, and 20 requests it is 0.68 s, 0.65 s, and 0.70 s, respectively. That being the case, the following models are trained with 10 requests as the new baseline scenario, since there is no significant performance loss compared to the other scenarios while using a minimum number of requests.
7.1.2. Deep Learning Model
In order to provide a more general statement about the initial delay estimation based on uplink requests with ML methods, the results achieved from the deep learning approach presented in
Section 6.4.4 are discussed in the following paragraphs.
Model Performance Analysis
For examining the behavior of the model, the prediction performance with an input of 5, 10, 15, and 20 requests is studied. Therefore, the model is trained for 300 epochs, since this value showed good results without overfitting. More than 120 training and testing reruns are done for each study. The MAE achieved for all runs is analyzed. Note that each single result of the study is the MAE of a complete run with 120 training and testing reruns. Thus, single initial delays are estimated with smaller or larger errors.
First, the results show that the number of requests has an influence on performance. For 5 requests, the MAE over all runs is close to 1 s, with a smaller variance and a maximal value of 1.6 s. For 10 requests as input, some predictions show a MAE of about 0.5 s and more than 50% show a MAE of more than 1.5 s. A similar performance is achieved for 15 and 20 requests, while the MAE is smaller for a larger percentage of runs. In more than 60% of all runs, 15 requests as input show a MAE of about 0.5 s; for 20 requests it is nearly 90%. On the other hand, some runs show a MAE of more than 1.5 s. This result is different from that of the RF approach. There, the MAE for several reruns of one specific scenario is always in the range of less than ±0.1 s; as shown, for example, in the initial model setting comparison. The result variance in the deep learning approach is larger, with maximal values in the MAE of single runs of several seconds not applicable.
The prediction performance on unknown videos is studied next, with completely different results, depending on the videos in the test set. For one specific video set, the model performs much better than in the random video case, with most MAEs at about 0.5 s, whereas with other videos in the test set, the MAE is always at about 1.5 s or above. Thus, we assume that this behavior is the reason for large variance in the random video case. Furthermore, we conclude that performance with the presented model is highly dependent on the videos used for testing, and therefore the model is not useful for this prediction without any improvement.
Studying the prediction performance with different, reduced feature sets shows only little improvement, without the uplink bytes and downlink packets. Overall, no statistically significant improvement is visible in the results, either when leaving out single features or when training the model with other feature sets; see
Appendix G,
Table A2 for more information. The same is obvious when adding an additional convolutional layer, which also leads to much longer training duration. We conclude, therefore, that either the dataset is too small for a comprehensive initial delay investigation based on a NN, or that the NN approach performs worse than the RF approach on the uplink data based prediction. To conclude, though, this does not mean that a RF based approach always outperforms NNs for streaming prediction. An in-depth model tuning and feature importance analysis can influence the estimator performance, although in many cases this requires much longer training duration and is much more complex. This, however, was not the main aim of this work, the objective being rather to create and use a simple and lightweight approach.
7.2. Quality Estimation
The results for the video quality estimation according to
Section 6.4.6 are presented next with the
full-, the
selected-, and the
uplink-feature sets of
Table 7.
7.2.1. Full Feature Set
The correct quality for the full feature set is predicted with 84.3%. The full confusion matrix is presented in
Table 12. The highest value is determined for predicting 720p quality. There, prediction accuracy, precision, recall, and F1 score are 92%. The worst performance is for 240p, with a prediction accuracy of 75%, a precision of 75%, a recall of 62%, and an F1 score of 68%. The reason for the large prediction difference is the nature of the different qualities. While the qualities are more distinguishable based on the downlink size for larger qualities compared to 144p, 240p, and 360p, the differentiation, especially between 720p and 1080p, is clearly visible by the inter-request time, as shown in
Figure 5b. This is less clear for the resolutions between 240p and 480p.
The different number of requests of each resolution influence slightly the overall prediction quality. The macro average precision is 0.81, compared to 0.84 for the weighted average precision. The macro average recall is 0.72 and the macro average F1 score is 0.74. In comparison, the weighted average precision and F1 score are 0.84. This little imbalance cannot be counterbalanced by bootstrapping, since during hyperparameter optimization, using bootstrapping for the requests did not increase the overall performance. An overall prediction accuracy of 84.68% is achieved with hyperparameter optimization. The macro and weighted average values for precision, recall, and F1 score are similar to the prediction without bootstrapping. Furthermore, it is evident that in most mis-predictions the adjacent resolution is predicted. The error for non-adjacent resolutions is less than 10% for all resolutions.
Furthermore, no statistically significant differences in prediction results are achieved when using only unknown videos in the test set. It is assumed that the video information has no significant impact on the prediction and is thus not relevant.
7.2.2. Selected Feature Set
For the selected feature set, a prediction accuracy of 83.11% is achieved. The weighted average precision, recall, and F1 score are at 0.83, while the macro average precision is 0.79 and the macro average recall and F1 score is 0.78. This shows a minor class imbalance due to the higher percentage of 720p-resolution requests. Compared to the estimation with the full feature set, though, the macro average values are improved. Thus, it is assumed that removing less relevant features reduces overfitting without losing overall prediction accuracy.
7.2.3. Uplink Feature Set
For the uplink feature set, results regarding precision, recall, and F1 score for all resolutions are shown in
Table 13 to present the influence of the reduced feature set on the prediction quality for each resolution. It is evident that for the 720p resolution, the prediction still works rather well, whereas for the 240p resolution and the 360p resolution, the prediction is much worse compared to the full feature set. This is so especially for the 240p quality, where in 24.23% instances the 144p resolution is predicted. A similar result is seen for the macro average precision with 0.75, recall with 0.73, and F1 score with 0.74. The weighted average values are 0.79 each. Thus, it becomes clear that the uplink feature set is not enough to predict each resolution accurately. For low resolutions in particular, this does not work, although for high resolutions, especially 720p in this case, the results are good. For the 720p quality, the accuracy, recall, and F1 score are at 0.89 and the precision is 0.88.
7.3. Video Phase Estimation
The video phase prediction according to
Section 6.4.8 is presented next. This is essential to receive details about the status of the video player, if for example enough bandwidth is available, and thus enough data for the player to keep the buffer at a steadily high level. The results for the approaches and all feature sets are summarized in
Table 14. The top of the table shows the feature sets and the performance metrics listed in the columns. The column at extreme left shows the prediction, in this case either the phase, the macro average score, or the weighted average score. The ML approach is listed in the second column.
Prediction Accuracy
In the RF case, the results show large differences, depending on the predicted phase. The filling and steady phases especially are predicted with good results and F1 scores of 0.94 and 0.90, respectively, for the full feature set. The result is different for the depletion phase and the stalling phase, with F1 scores below 0.80. In the depletion phase, most prediction errors predict the steady phase. For the stalling phase, most mis-predictions are of the depletion phase or the filling phase. The difference in the macro and weighted average scores is a result of the class imbalance in the nature of streamed videos, with their having many more requests in the steady and filling phases compared to the stalling and depletion phases. This could be one reason for the difference in the prediction result. For the LSTM-based prediction, the results are similar for the full feature set.
Furthermore, the table shows that the different feature sets perform similarly in the phase detection case. The selected feature set shows slightly worse results compared to the full feature set. The result for the uplink based feature set improves compared to that of the selected feature set. Thus, in contrast to the video resolution prediction presented above, the uplink-based feature set is convenient for predicting the current video phase, and shows that uplink-based data is enough for phase prediction.
The LSTM-based approach shows slightly better results for the selected feature set compared to the RF approach. Especially for the depletion phase and the stalling phase, slightly better results for recall, F1 score, and macro avg are visible. The same, though less clearly, is evident for the uplink feature set. Thus, the LSTM-based approach can handle the underrepresented classes better. However, for the much more complex algorithm tuning and longer and more resource intense runtime, the difference is very small.
When using only unknown videos in the test set, the results are similar to the other phase prediction experiment for both approaches, with some limitations; again, there is no large difference between using the full feature set, the selected feature set, or the uplink based feature set. Furthermore, the filling phase and steady phase prediction works rather well, with only slightly worse precision, recall, and F1 score values compared to the known video experiments. The limitation is in predicting the depletion and stalling phases, where precision, recall, and F1 score values of 0.5 or less are achieved. The goal for future work is to improve this result by increasing the percentage of requests in the underrepresented classes.
The results for the NN approach are worse compared to the other estimations. The best prediction is achieved for the filling phase, with F1 scores of more than 0.9 for all feature sets. The other phases, especially the depletion and stalling phases, are predicted much worse, with an F1 score of less than 0.75 for both phases for the full feature set. The overall macro average F1 score is 0.8 or lower for all feature sets. Especially in the stalling phase, the depletion phase is often predicted falsely.
7.4. Quality Change Estimation
Several studies are carried out to predict the quality changes. The best results, as summarized in
Table 15, are achieved with a random test- and training-set split and the correct video phase as additional input feature. The table shows that the prediction of no quality change works very well, with F1 scores of 0.97 and higher, both for the RF and the LSTM approaches for all feature sets. Note that the results listed with a score of 1.00 show high 99% results. Since the negligible differences in the high 99% range have no influence on the overall statement, no more digits are provided after the comma.
In contrast, predicting the requests with quality change does not work so well. Different results are seen in those cases for both ML approaches. While for the RF-based prediction, the precision at about 0.80 is rather good, the recall shows values only slightly above 0.50. For the LSTM-based approach, the results are vice versa, with results of only about 0.30 precision. This is explainable by the common streaming behavior, where not many quality changes are visible compared to the total playtime according to
Section 5.5. For that reason, the dataset is not balanced, with 22,123 requests with quality change out of a total of more than 1.1 million requests. Second, a downward shift to lower quality is usually triggered in the middle of depletion phases or after stalling. However, there is also change to higher quality during filling phases. This variety of situations where quality changes can be triggered makes prediction difficult.
A more detailed observation of the results reveals that both ML approaches have benefits, based on the prediction goal. The high precision in the RF based approach shows a high true positive rate, and thus most predicted quality changes could be identified as such. The drawback is that many are missed. The high recall for the LSTM-based approach shows that many quality changes are detected, though with the drawback of falsely classifying many requests as quality change requests.
Two additional experiments are done for the quality change prediction: using only unknown videos in the test set and predicting quality change without knowing the video phase during prediction. The results show that knowing the video phase before predicting quality change increases the prediction result by up to 3% for both approaches. As such, an initial video phase determination is essential for good quality change prediction.
Not knowing the video has a significant influence on a metric with previously lower score. This is the recall for the RF and the precision for the LSTM-based approach. For a more general approach with unknown videos in the test set, a more detailed study is required. Moreover, according to the phase prediction, a more balanced dataset could be valuable. This can also help to improve performance in the NN approach, where the results were much worse compared to the others.
7.5. Stalling Estimation
Video stalls are estimated in this subsection, as the last but most important QoE metric. The prediction results, with the approaches presented in
Section 6, a random test- and training-set split, and without video phase as input feature, are summarized in
Table 16. The general table structure is retained as earlier. The
no stalling line describes the prediction result for all requests that did not stall, and the
stalling line for all requests that did stall. It is evident here, again, that precision, recall, and F1 score for the
no stalling case are higher compared to the
stalling case for both models. This, also, is a result of the higher number of
no stalling requests compared to
stalling ones. However, it is also obvious that regarding the
stalling prediction, both approaches perform similarly for the
full- and the
selected-feature sets. For the
uplink-feature set, the RF-approach performs slightly better. The precision in particular is lower in the LSTM-based prediction. Additionally, regarding the F1 score, it is evident that similar results are achieved for all feature sets with the RF-based approach, whereas the performance of the LSTM-based approach decreases with fewer features in the feature sets. To conclude, it is possible to predict stalling events at network layer with uplink requests only with an F1 score of 0.89 with a RF approach. In addition, for 60% of all false positives in case of the RF-based prediction and for nearly 80% in the LSTM-based approach, a video buffer of less than 9 s is detected, independent of the used feature set.
Other experiments show that the current video phase is also a valuable input to increase the prediction performance. However, since in this work the stalling phase is defined as one of the streaming phases, the input of the phases is meaningless. Nevertheless, the exclusion of buffering and steady phases, which are detected quite accurately, offers high potential to improve the overall performance. With only unknown videos in the test set, the macro average F1 score drops to 0.67 or less. The precision and recall values for the stalling case in particular are lower for all experiments with only unknown videos in the test set. Here, again, improvement potential is visible upon including the streaming phase.
The prediction quality of the NN approach is comparable to the above scores. Overall, a macro average F1 score of 0.85 is achieved for the full feature set, while the stalling class only shows an F1 score of 0.71. The other feature sets show worse results, with a macro average F1 score of only 0.81 for the uplink feature set. The class imbalance, again, is assumed to be the reason for the poorer performance in those cases.
8. Conclusions
In this work, the most relevant QoE metrics, i.e., initial playback delay, video streaming quality, quality change, and video rebuffering events are studied with a large-scale dataset of more than 13,000 YouTube video streaming runs watched using the native YouTube app. Three ML models are developed and compared to estimate the playback behavior based on uplink request information. The main focus was to develop a lightweight approach using as few features as possible while retaining state-of-the-art levels of performance.
The results show that a simple RF approach outperforms a NN on the given dataset. With the NN, the variance in the resulting estimation error is larger, while for some runs it is comparable to the RF approach. Nevertheless, large outliers and long training time make it useless as a lightweight approach. The presented LSTM-based approach shows similar performance for the investigated metrics, but with higher complexity and computational effort. The presented RF approach, however, performs reasonably well for all important QoE metrics for a known testing set, and only slightly worse for an unknown set. Especially when using only uplink based data and reducing the feature sets, only a marginal decrease in estimation performance is discernible. For example, for stalling, as the most important quality impairment metric for video streaming, a macro average F1 score of 0.84 is achieved. High recall values of nearly 0.9 show that most requests predicted as stalling are predicted correctly. Additionally, for 60% of all false positives, a video buffer of less than 9 s is detected. In comparison to related state-of-the-art works, where in most cases downlink based approaches or full packet traces are used for QoE prediction with stalling detection rates of 90–95%, the approach is valuable, especially from a monitoring effort point of view, with acceptable prediction accuracy impairment. The good result with a simple RF approach is especially possible by an in-depth study of the streaming process and feature selection. Given this valuable information and a good choice of input features and hyperparameter optimization, we have excellent pre-conditions for good learning.
Accordingly, we conclude that it is possible, based on uplink requests only, to estimate the main influencing metrics for the perceived QoE for the end-user of YouTube videos, decreasing the amount of required data drastically from full packet traces with uplink and downlink data to only chunk requests, inter-arrival times in the uplink data, and a few additional features dependent on the predicted metric only. The goal in future work will be to investigate the generalizability of the approach for other streaming platforms and live streaming.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}










