
A Coarse-to-Fine Method for Estimating the Axis Pose Based on 3D Point Clouds in Robotic Cylindrical Shaft-in-Hole Assembly



Abstract
:1. Introduction
- (i)
- Reducing the hole pose to its axis pose, we propose a novel coarse-to-fine method for estimating the axis pose based on 3D point clouds. Our method can provide the pose estimation for the hole, which is reliable for both position and orientation and reaches better performance compared to the popular methods for estimating the axis.
- (ii)
- Under our devised robotic platform, we employ the above method for estimating the axis pose, together with an approach of admittance control, to promote the cylindrical shaft-in-hole assembly. Using this assembly strategy, the shaft-in-hole assembly with a large aspect ratio is accomplished efficiently.
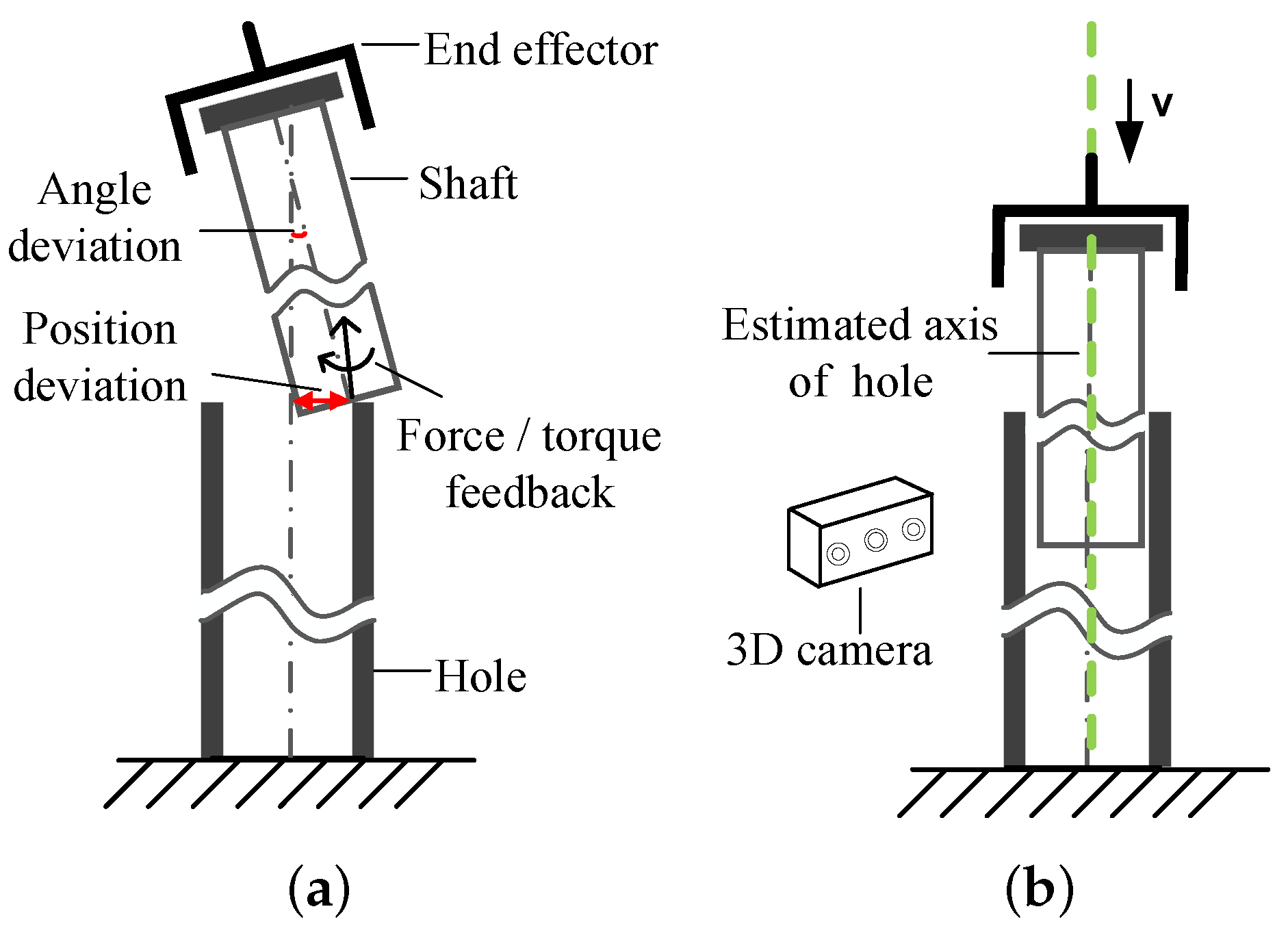
2. Robotic Platform and Principles for Assembly
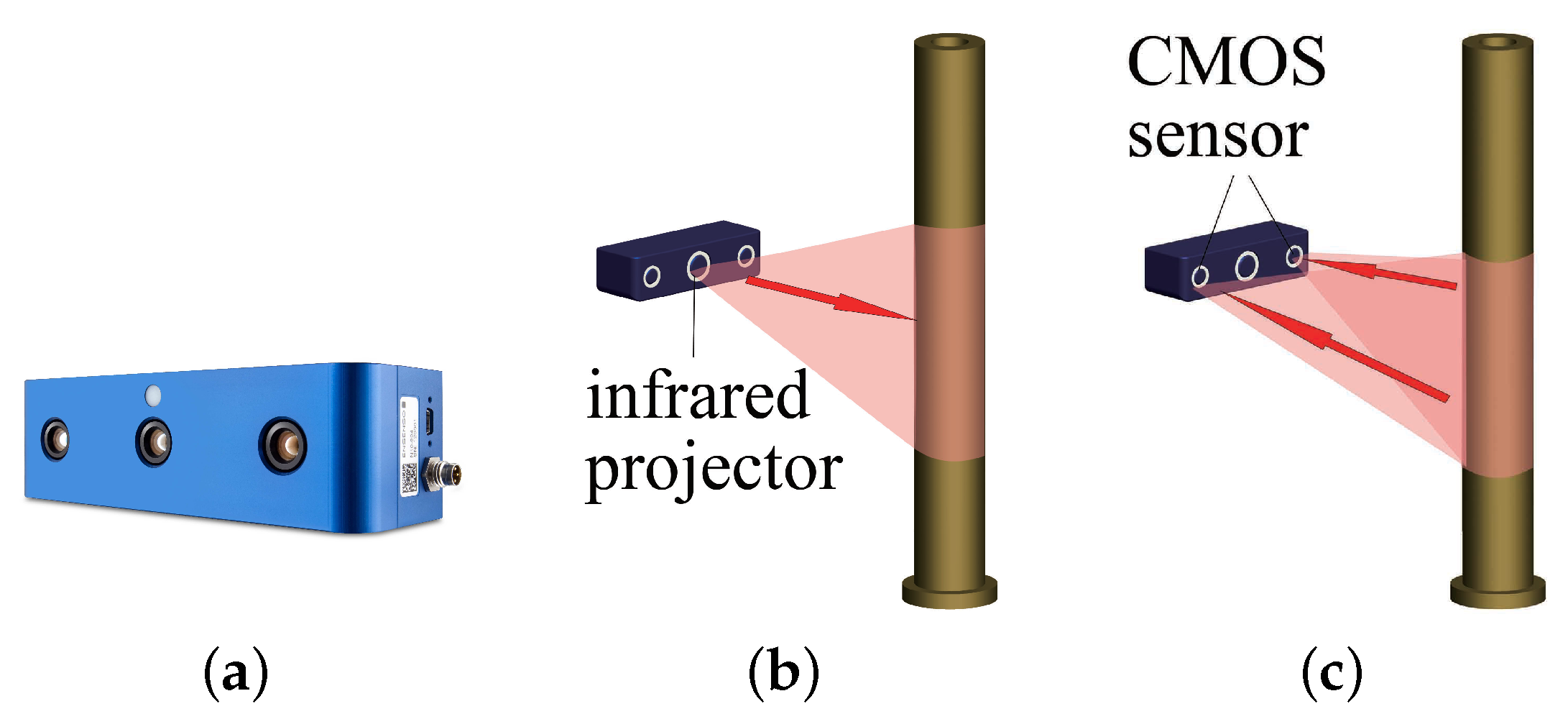
2.1. Robotic Platform
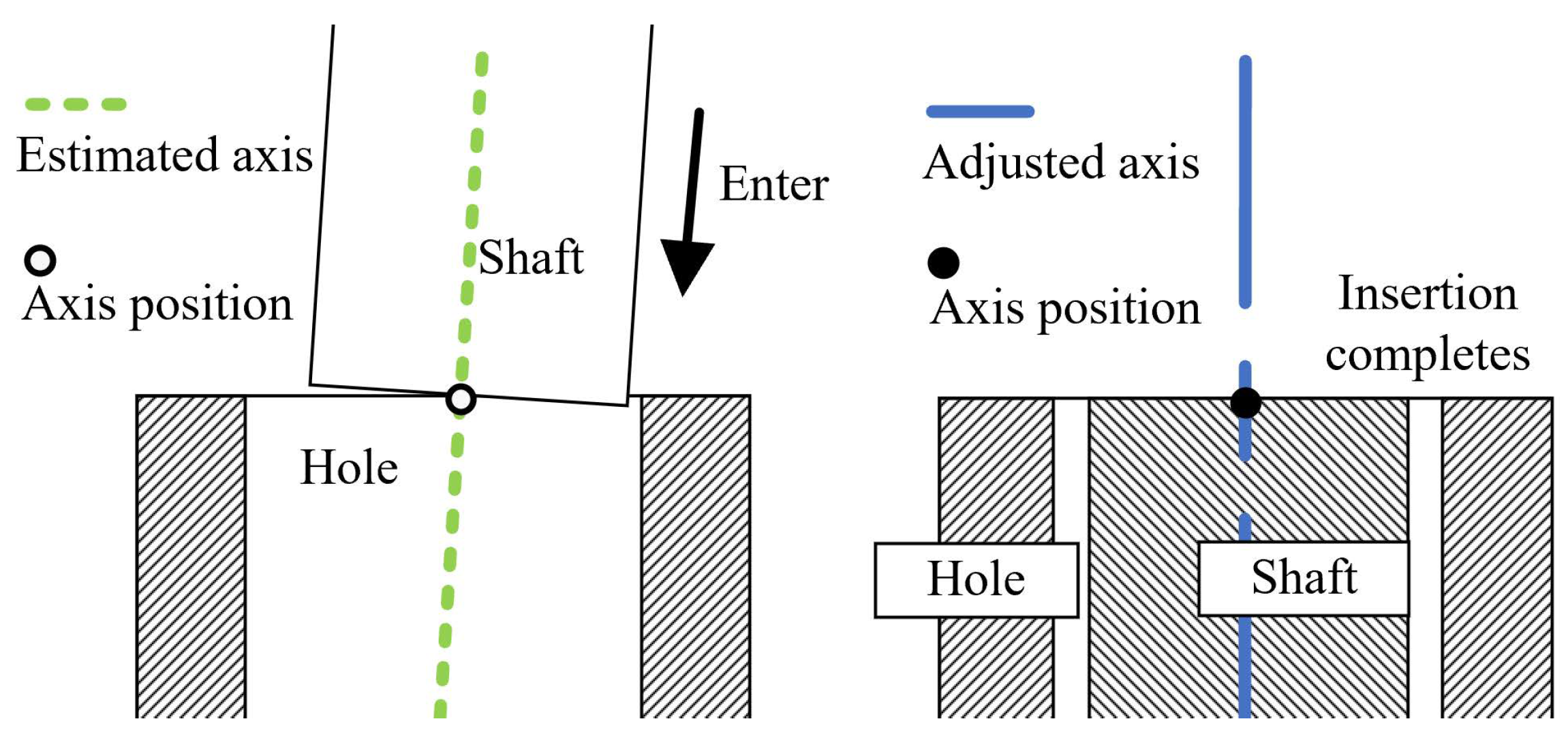
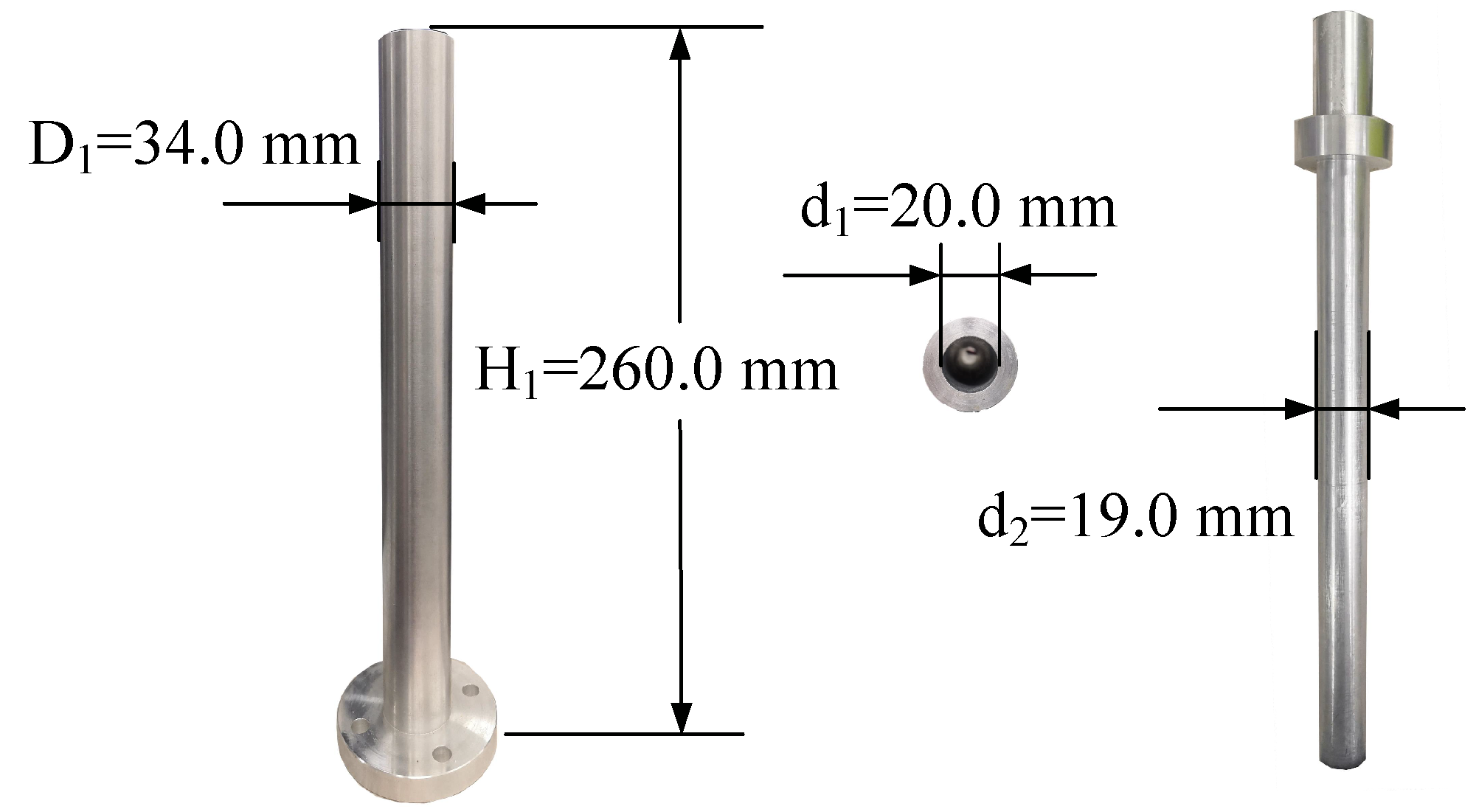
2.2. Principles for Assembly
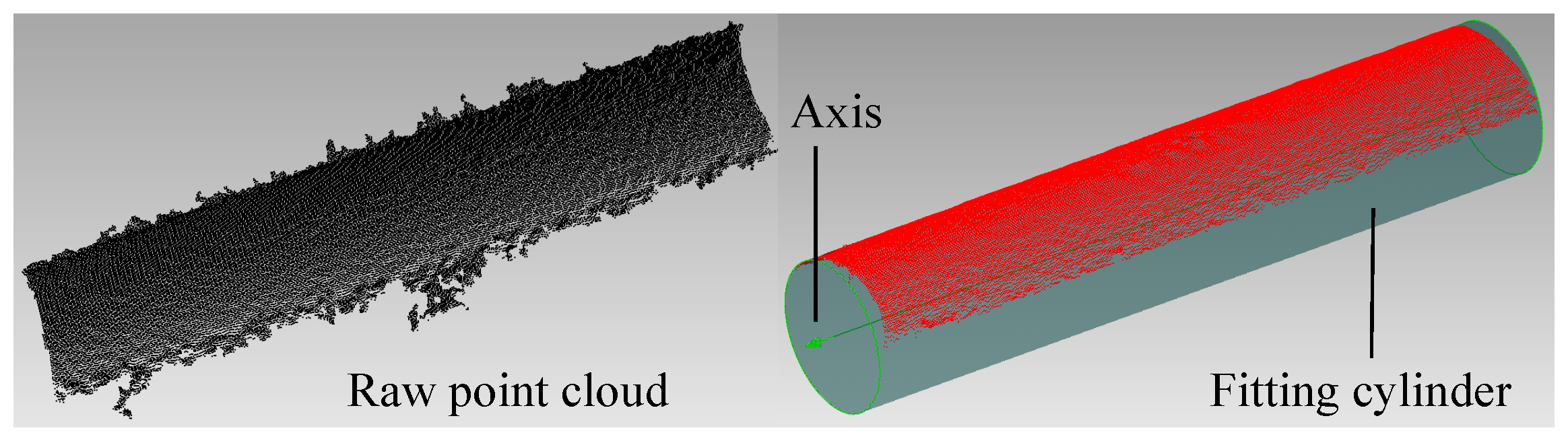
3. Method for Estimating the Axis Pose
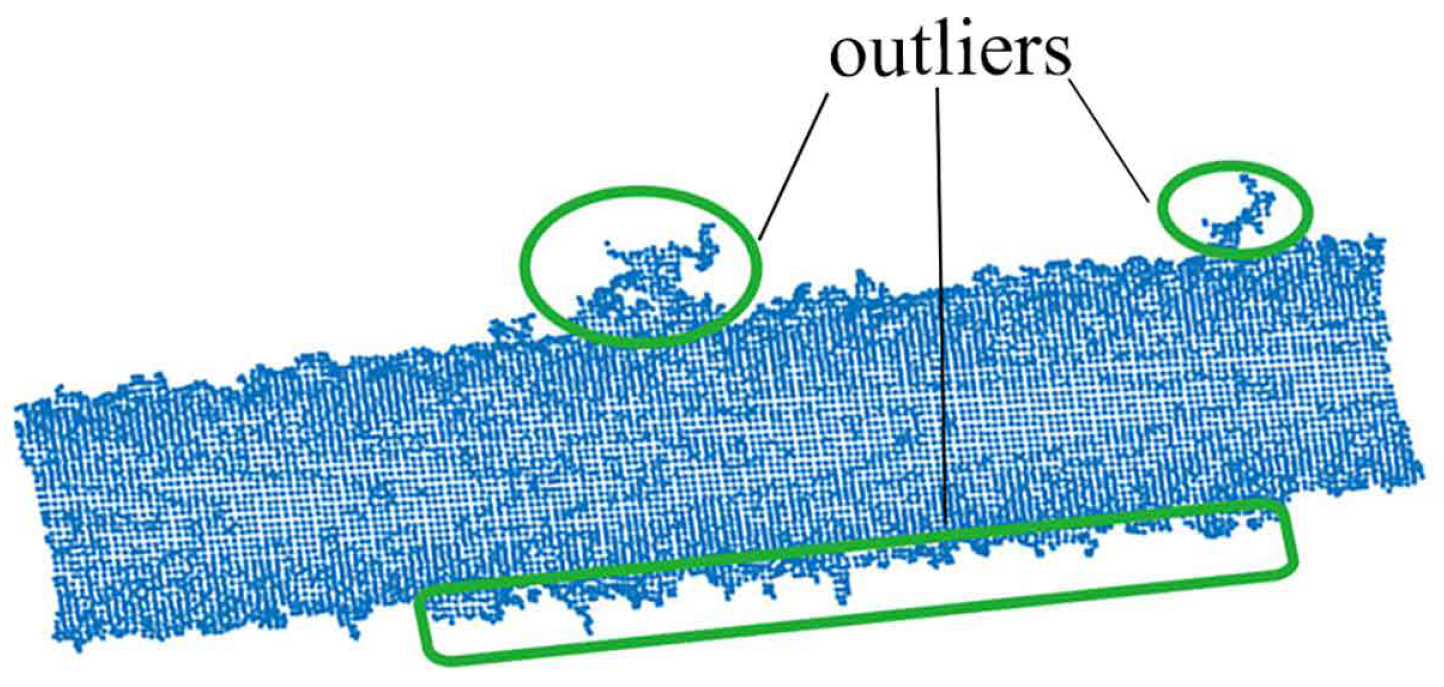
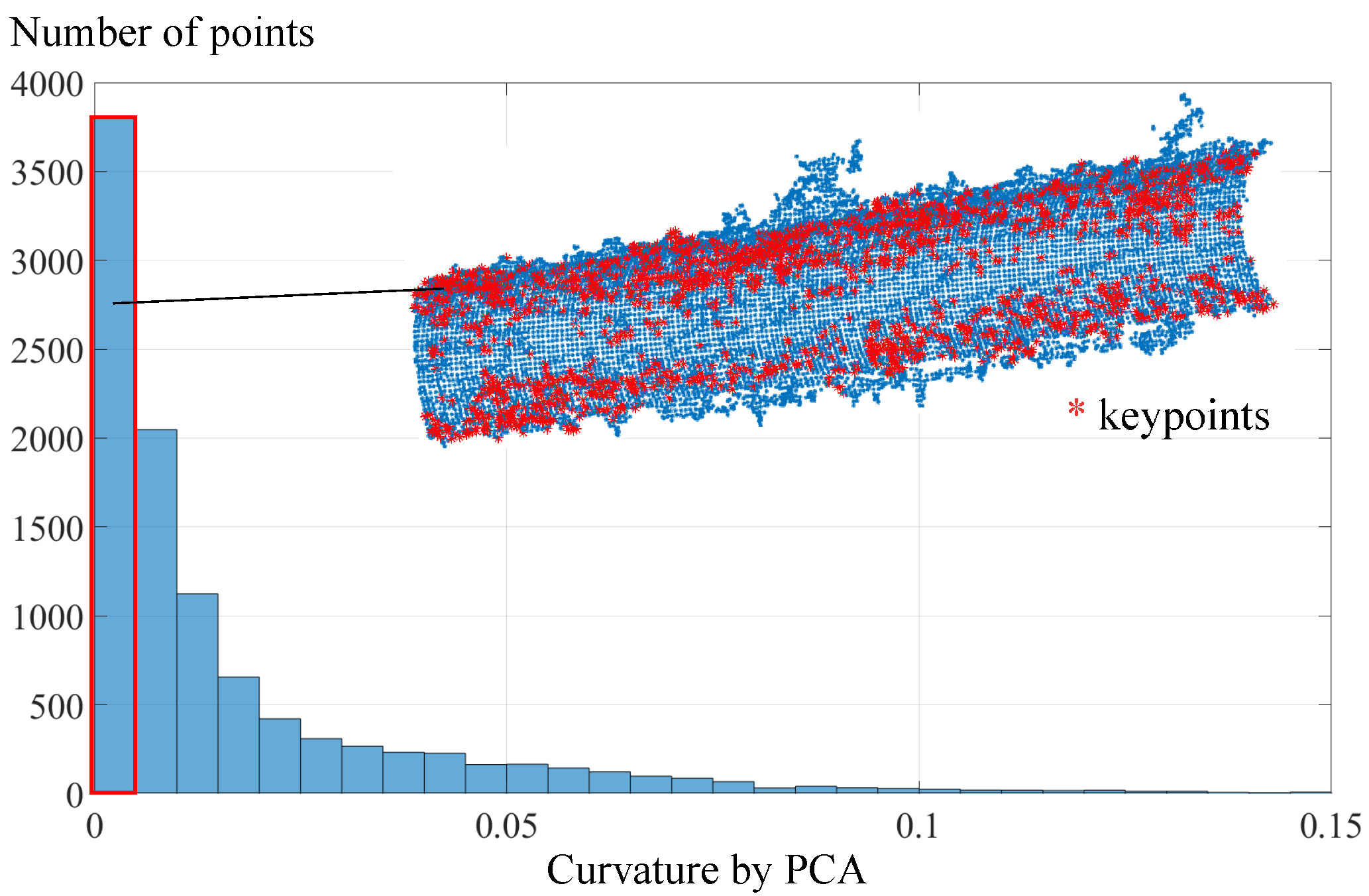
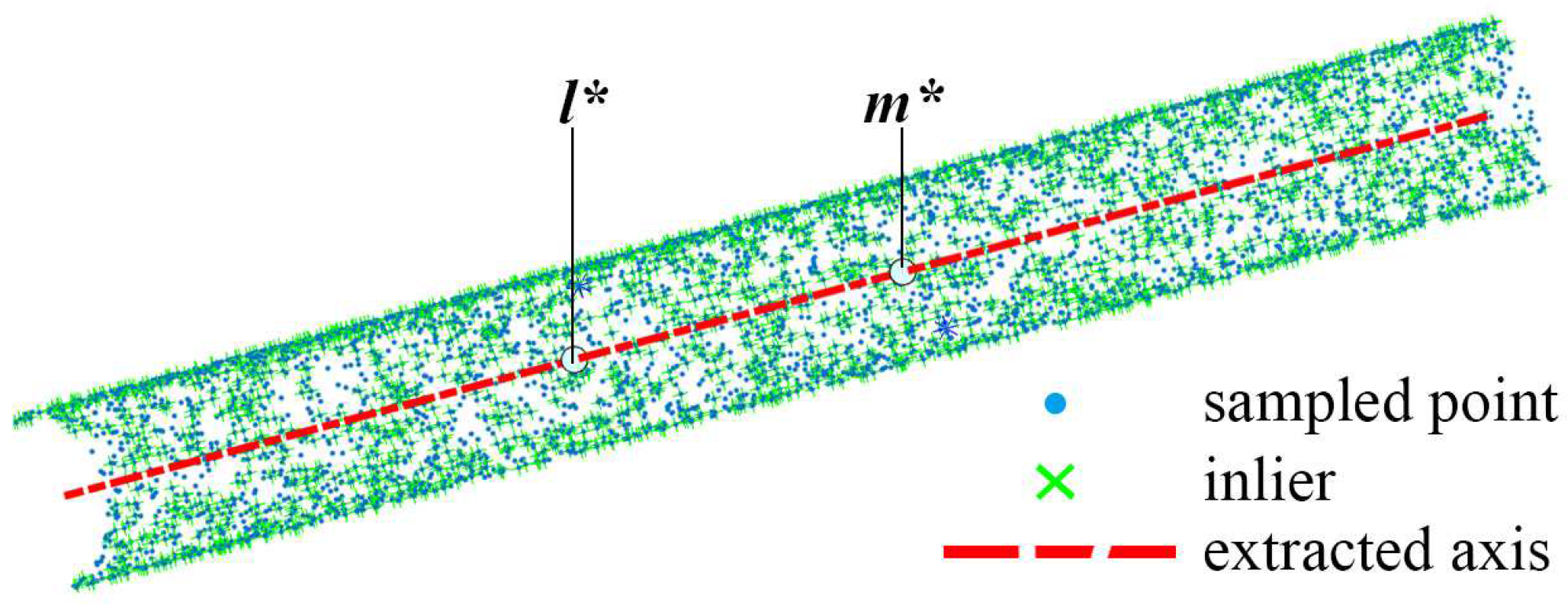
3.1. Keypoint Selection by Curvature
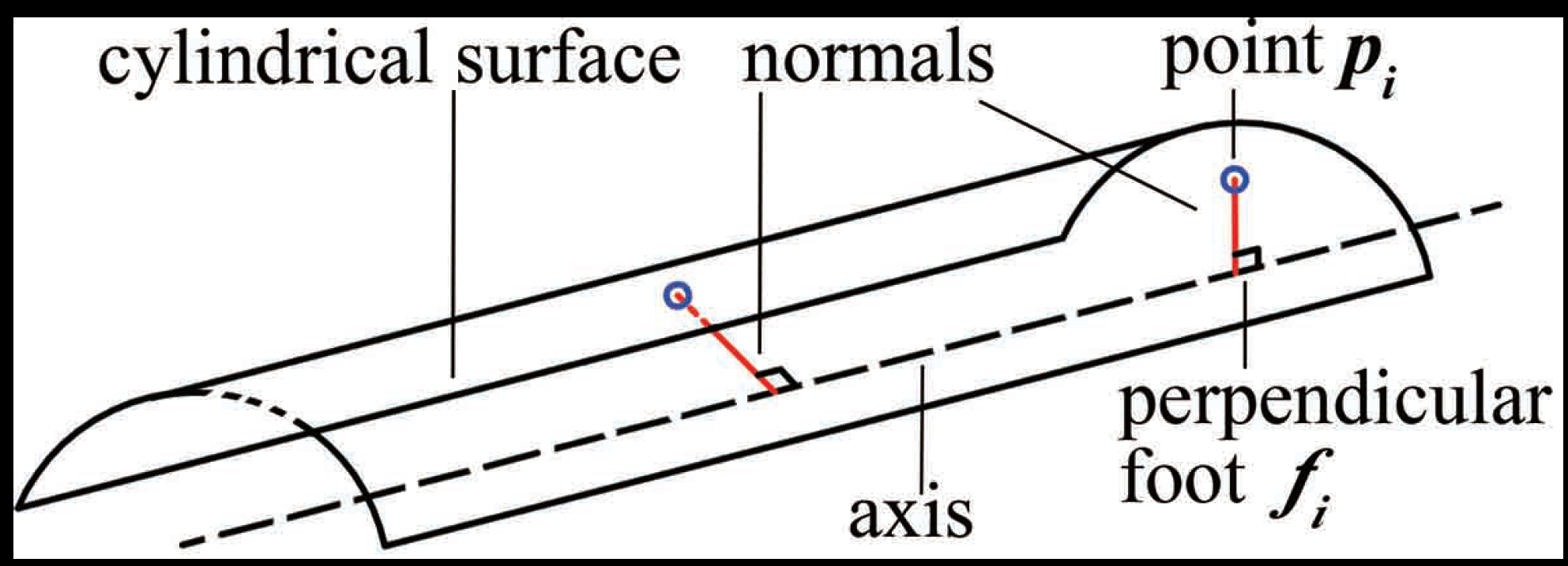
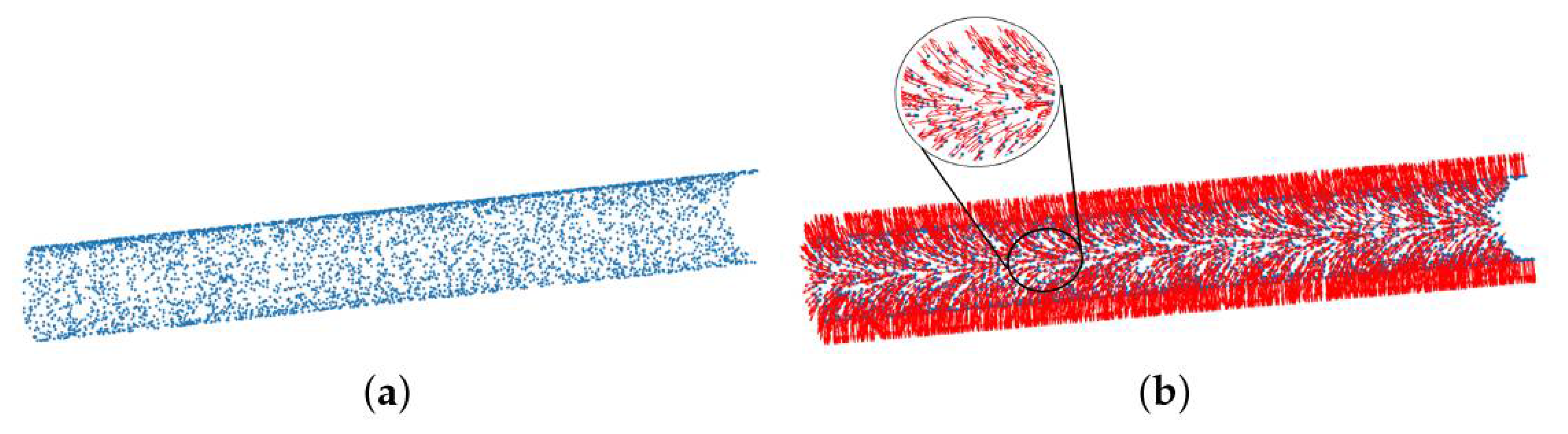
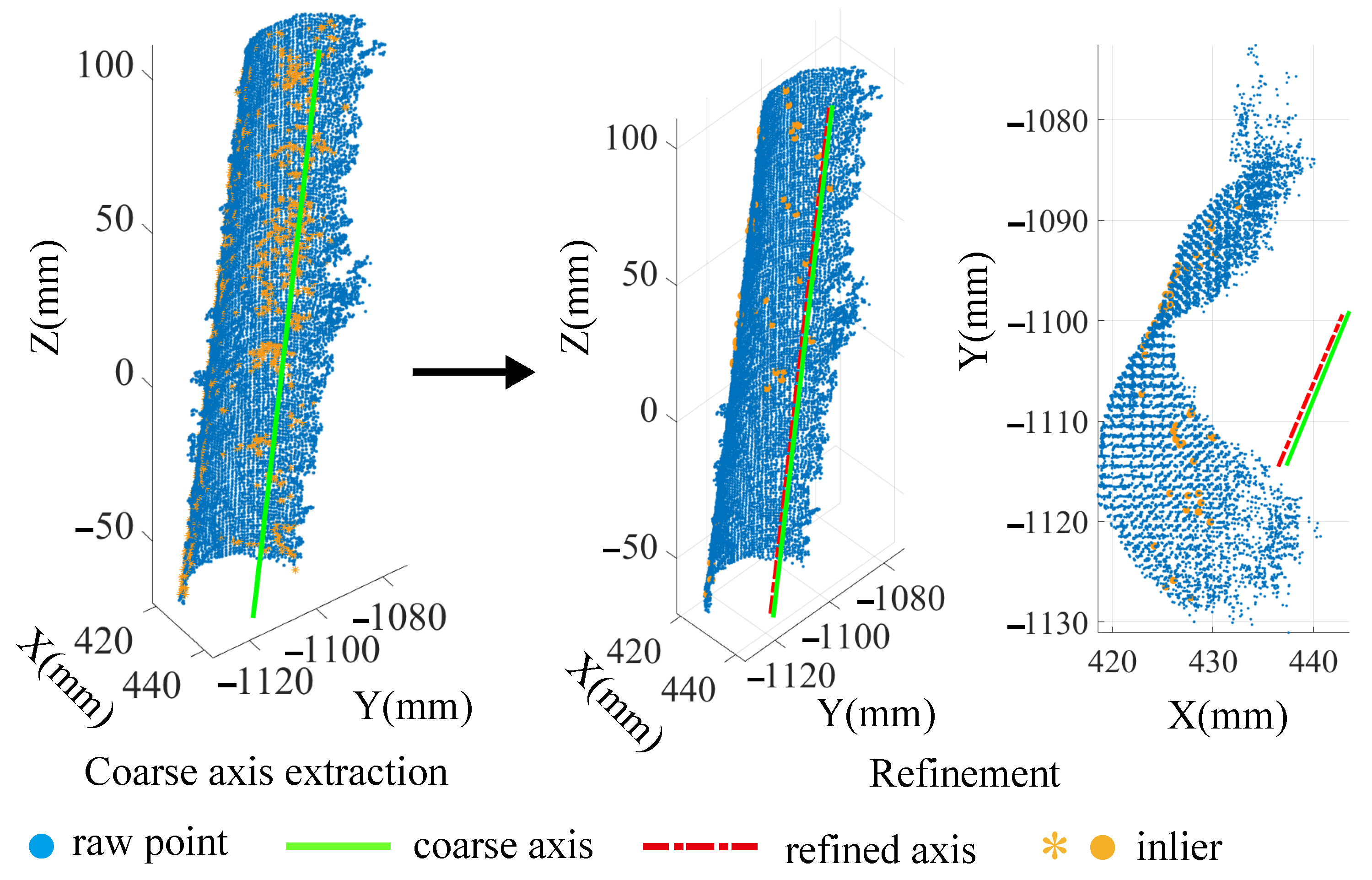
3.2. Coarse Axis Extraction Based on the Surface Normals
| Algorithm 1: Coarse axis extraction. |
 |
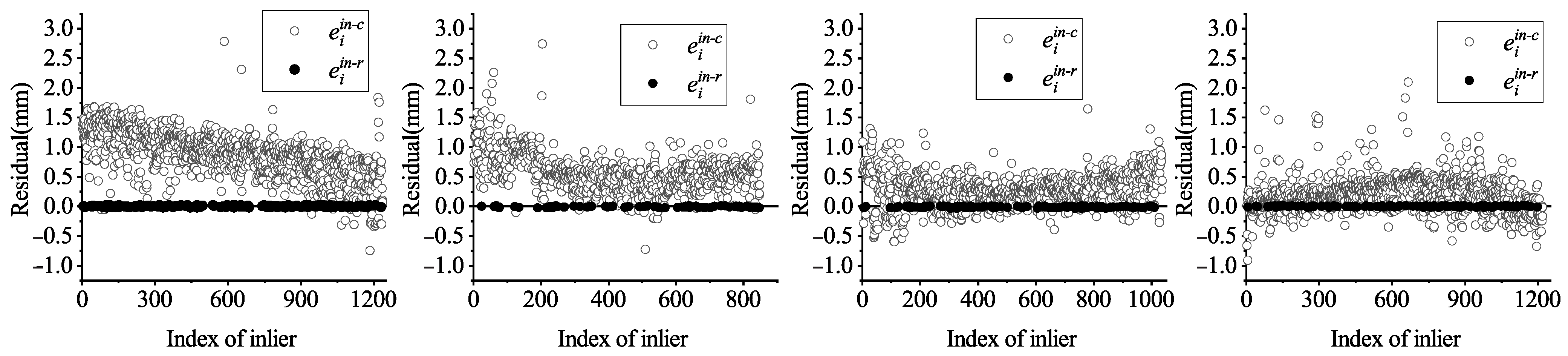
3.3. Refinement of the Coarse Axis by Iterative Robust Least Squares
| Algorithm 2: Refinement of the coarse axis. |
 |
4. Experiments and Assessment
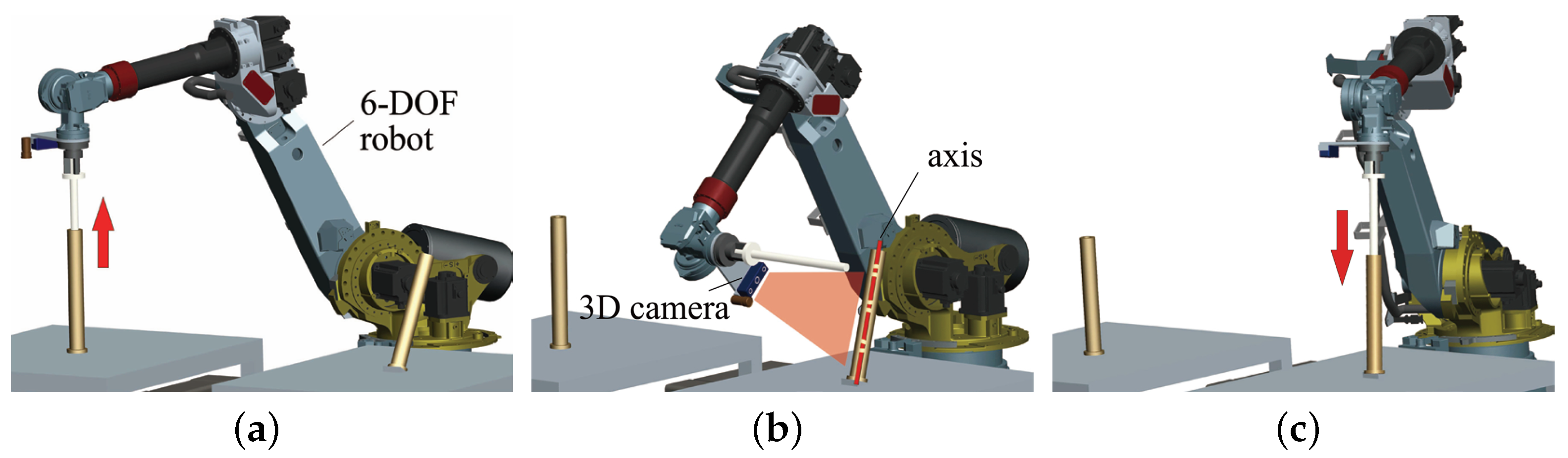
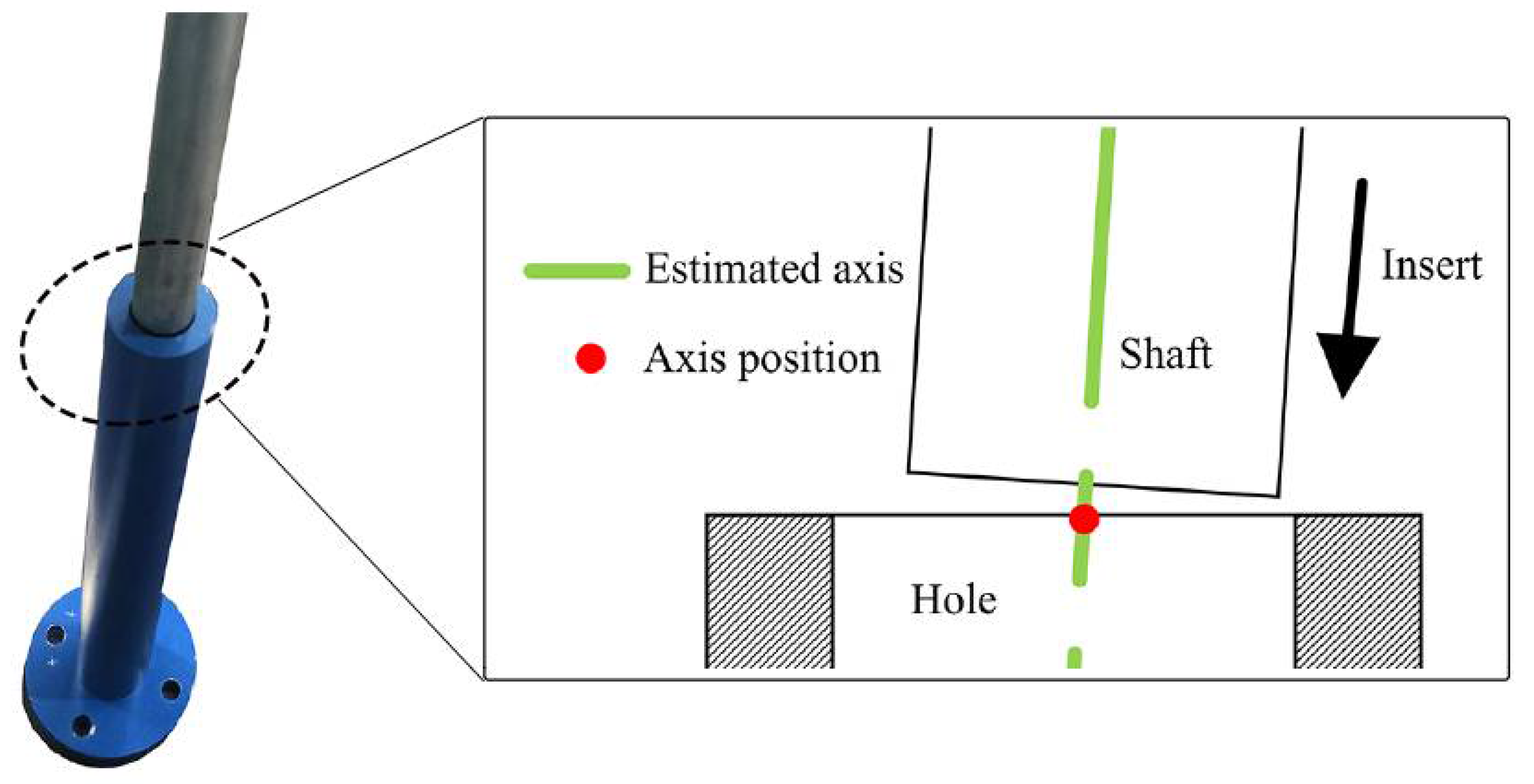
4.1. Procedure of the Axis Pose Estimation
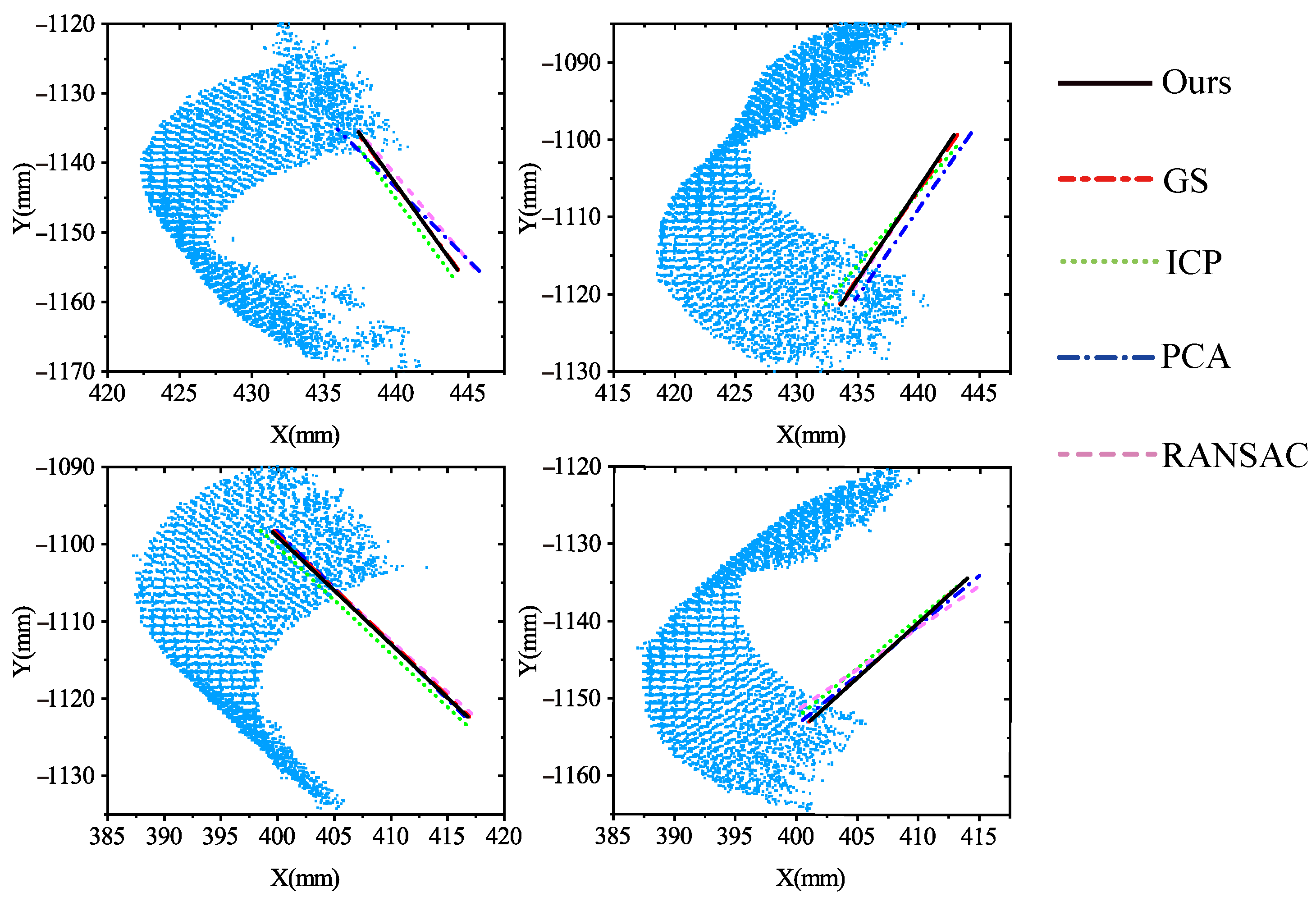
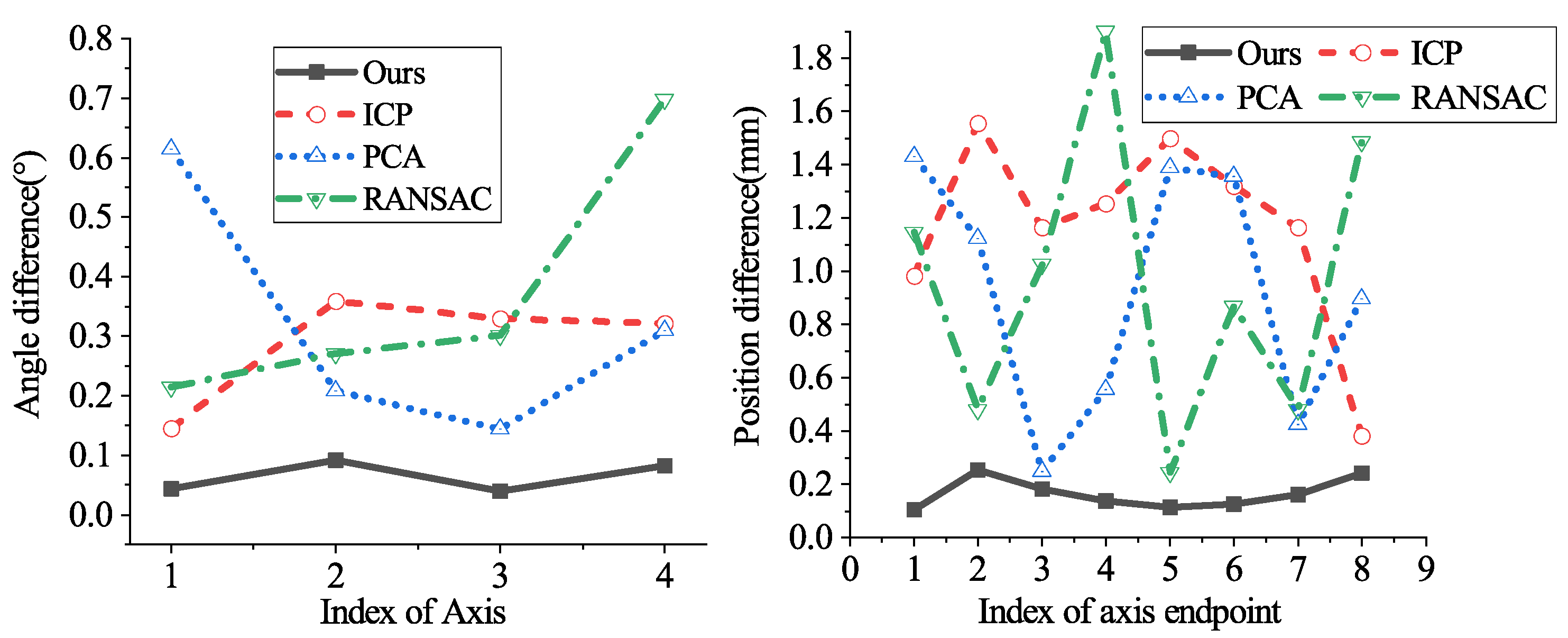
4.2. Comparisons between Our Method and Others
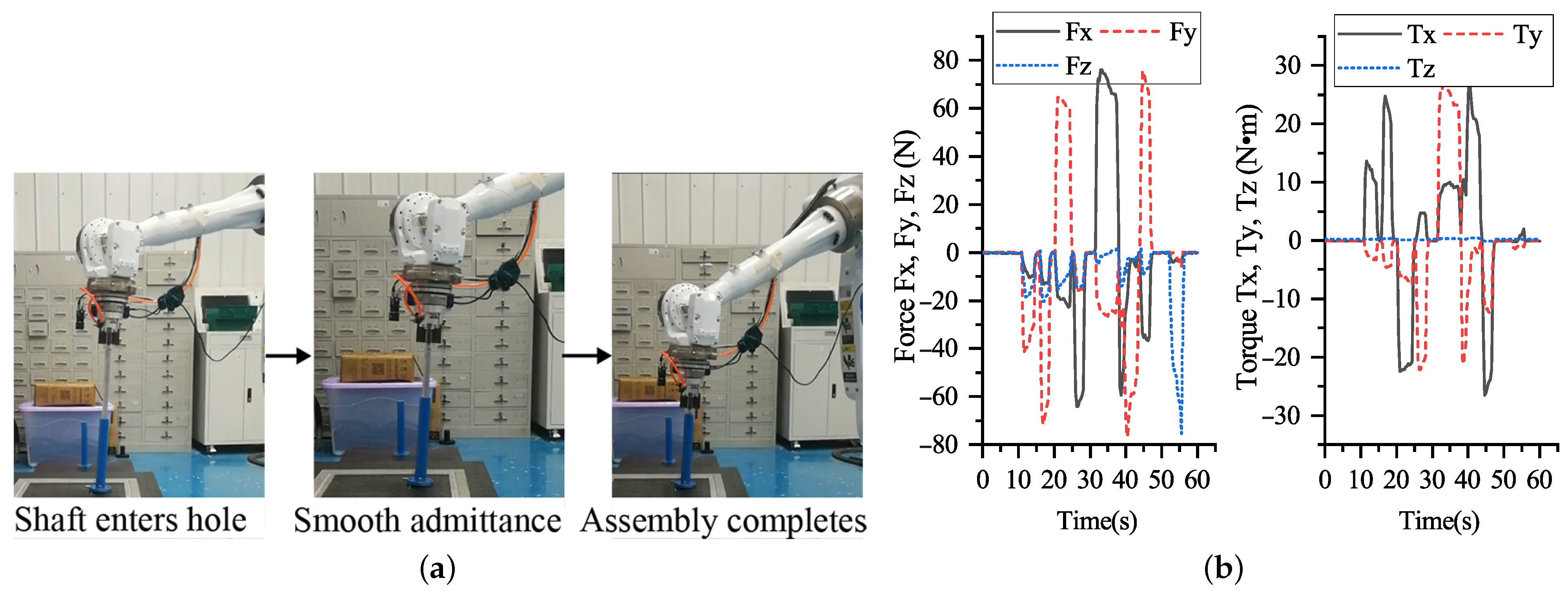
4.3. Effectiveness of the Axis Pose Estimation in Shaft-in-Hole Assembly
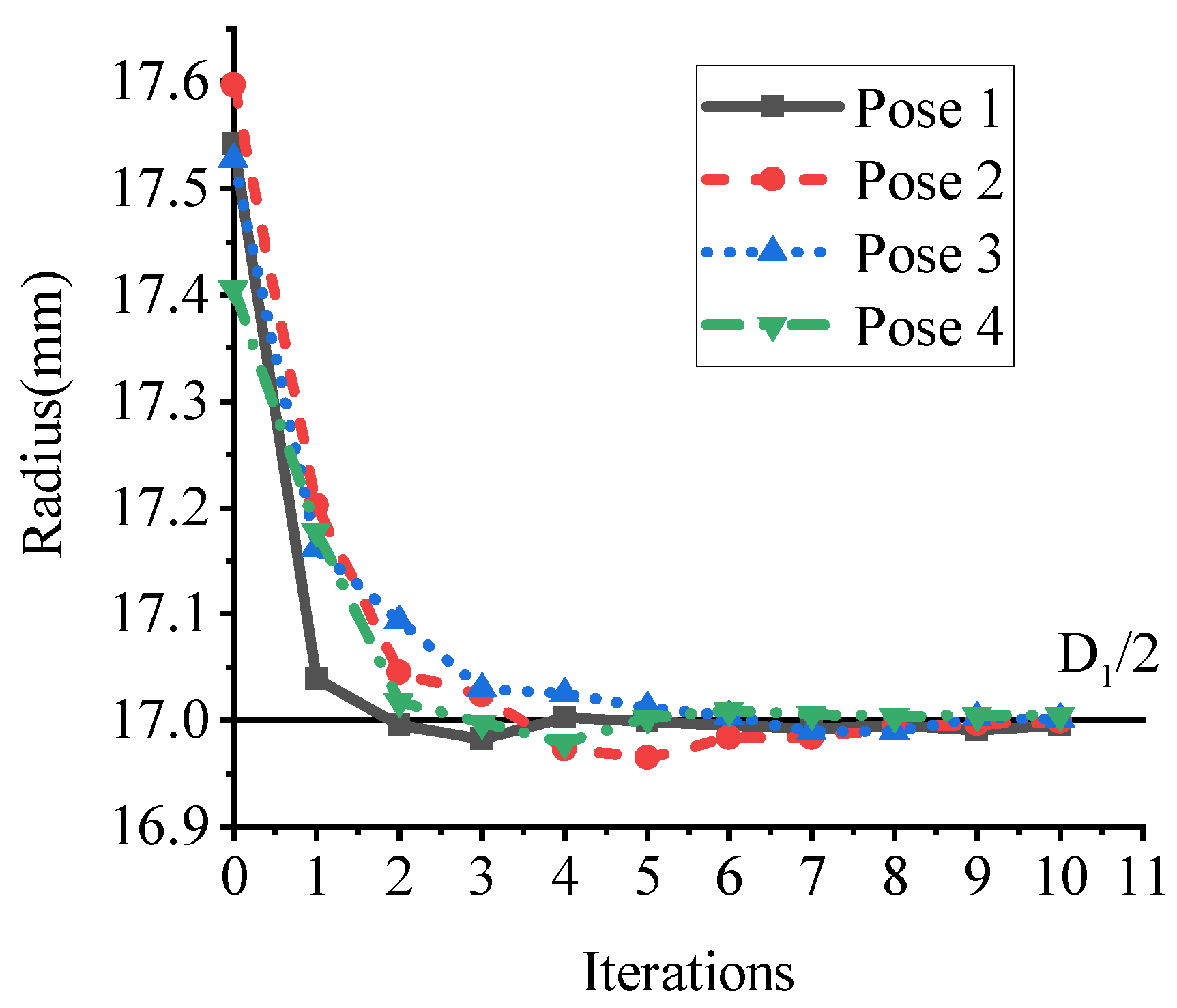
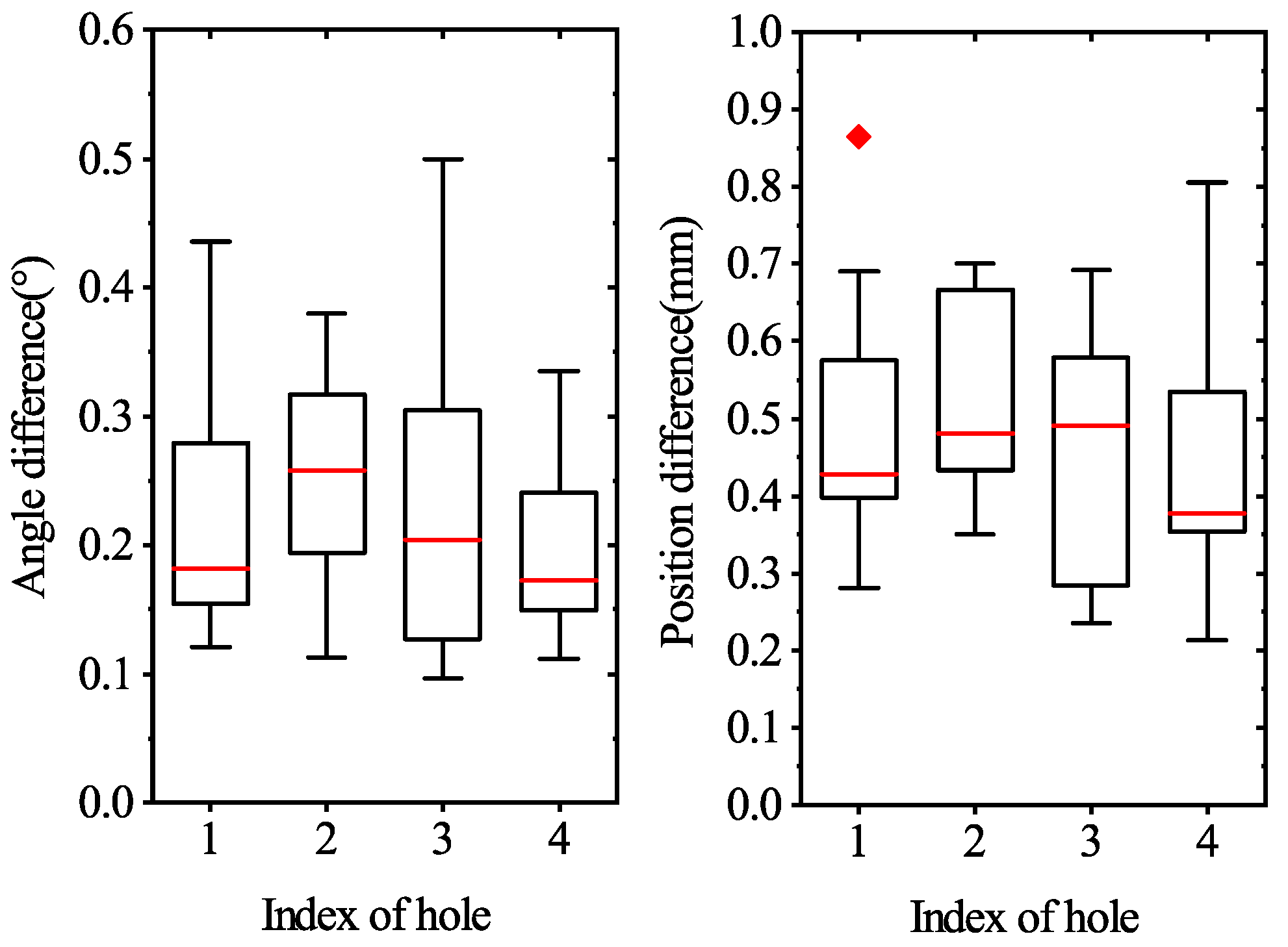
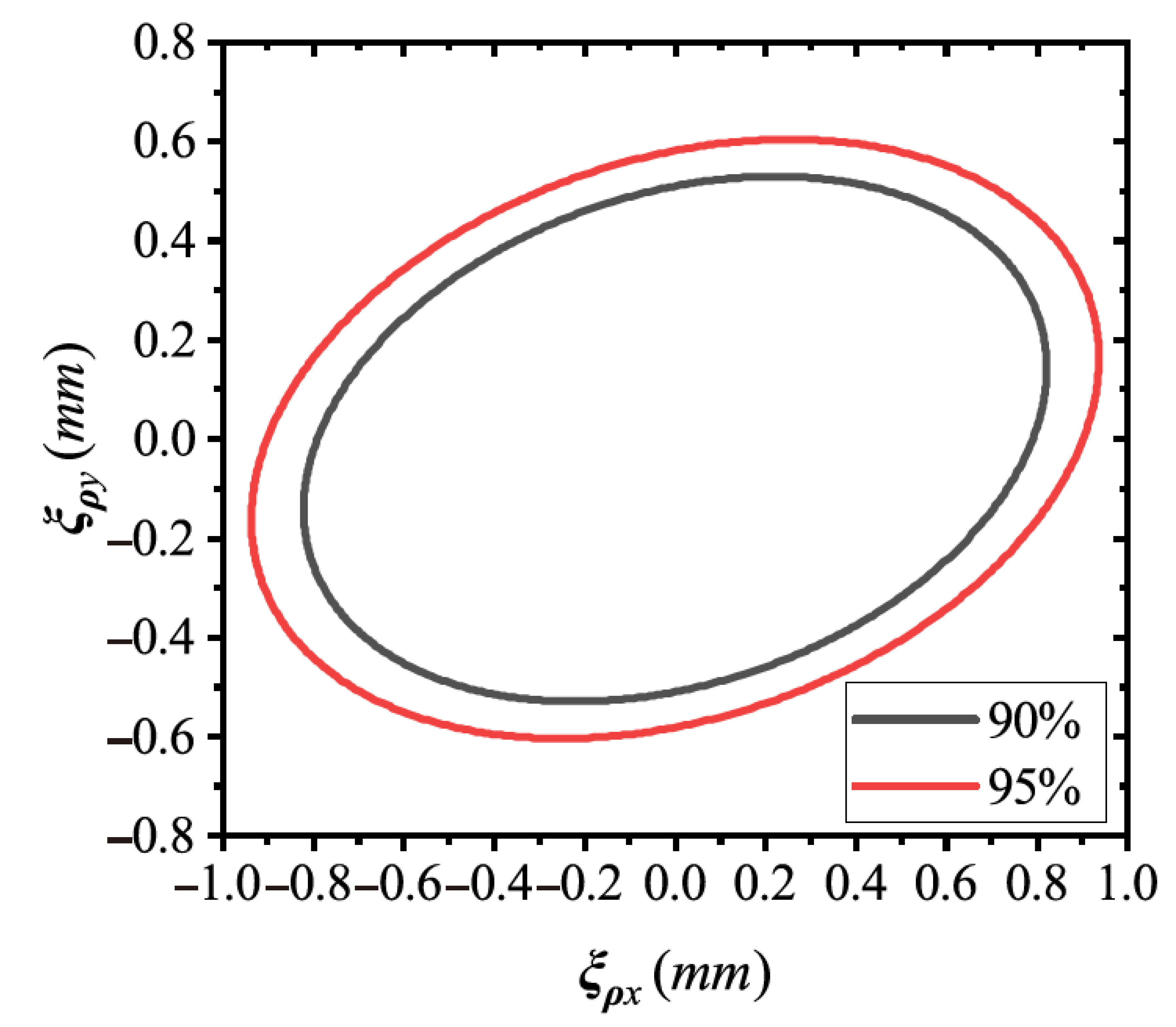
4.4. Error Analysis of Axis Pose in Robotic Platform
4.5. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Stolt, A.; Linderoth, M.; Robertsson, A.; Johansson, R. Force controlled robotic assembly without a force sensor. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, Saint Paul, MN, USA, 14–18 May 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 1538–1543. [Google Scholar]
- Chen, H.; Liu, Y. Robotic assembly automation using robust compliant control. Robot. Comput. Integr. Manuf. 2013, 29, 293–300. [Google Scholar] [CrossRef]
- Fang, S.; Huang, X.; Chen, H.; Xi, N. Dual-arm robot assembly system for 3C product based on vision guidance. In Proceedings of the 2016 IEEE International Conference on Robotics and Biomimetics (ROBIO), Qingdao, China, 3–7 December 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 807–812. [Google Scholar]
- Jiang, T.; Cui, H.; Cheng, X. A calibration strategy for visually guided robot assembly system of large cabin. Measurement 2020, 163, 107991. [Google Scholar] [CrossRef]
- Peng, G.; Ji, M.; Xue, Y.; Sun, Y. Development of a novel integrated automated assembly system for large volume components in outdoor environment. Measurement 2020, 168, 108294. [Google Scholar] [CrossRef]
- Jasim, I.F.; Plapper, P.W.; Voos, H. Position identification in force-guided robotic peg-in-hole assembly tasks. Procedia Cirp 2014, 23, 217–222. [Google Scholar] [CrossRef] [Green Version]
- Song, H.C.; Kim, Y.L.; Song, J.B. Guidance algorithm for complex-shape peg-in-hole strategy based on geometrical information and force control. Adv. Robot. 2016, 30, 552–563. [Google Scholar] [CrossRef]
- Zhao, Y.; Gao, F.; Zhao, Y.; Chen, Z. Peg-in-Hole Assembly Based on Six-Legged Robots with Visual Detecting and Force Sensing. Sensors 2020, 20, 2861. [Google Scholar] [CrossRef] [PubMed]
- Peng, J.; Xu, W.; Liang, B.; Wu, A.G. Pose measurement and motion estimation of space non-cooperative targets based on laser radar and stereo-vision fusion. IEEE Sens. J. 2018, 19, 3008–3019. [Google Scholar] [CrossRef]
- Yang, X.; Wang, R.; Wang, H.; Yang, Y. A novel method for measuring pose of hydraulic supports relative to inspection robot using LiDAR. Measurement 2020, 154, 107452. [Google Scholar] [CrossRef]
- Wang, Z.; Zhang, X.; Shen, Y.; Zheng, Z. Pose Calibration of Line Structured Light Probe Based on Ball Bar Target in Cylindrical Coordinate Measuring Machines. Measurement 2020, 171, 108760. [Google Scholar] [CrossRef]
- Li, P.; Wang, R.; Wang, Y.; Tao, W. Evaluation of the ICP Algorithm in 3D Point Cloud Registration. IEEE Access 2020, 8, 68030–68048. [Google Scholar] [CrossRef]
- Yang, J.; Li, H.; Campbell, D.; Jia, Y. Go-ICP: A globally optimal solution to 3D ICP point-set registration. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 2241–2254. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhou, Q.Y.; Park, J.; Koltun, V. Fast global registration. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 766–782. [Google Scholar]
- Liu, H.; Liu, T.; Li, Y.; Xi, M.; Li, T.; Wang, Y. Point cloud registration based on MCMC-SA ICP algorithm. IEEE Access 2019, 7, 73637–73648. [Google Scholar] [CrossRef]
- Papazov, C.; Burschka, D. An efficient ransac for 3D object recognition in noisy and occluded scenes. In Proceedings of the Asian Conference on Computer Vision, Queenstown, New Zealand, 8–12 November 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 135–148. [Google Scholar]
- Drost, B.; Ulrich, M.; Navab, N.; Ilic, S. Model globally, match locally: Efficient and robust 3D object recognition. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 998–1005. [Google Scholar]
- Guo, Y.; Wang, H.; Hu, Q.; Liu, H.; Liu, L.; Bennamoun, M. Deep learning for 3d point clouds: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020. [Google Scholar] [CrossRef] [PubMed]
- Wong, J.M.; Kee, V.; Le, T.; Wagner, S.; Mariottini, G.L.; Schneider, A.; Hamilton, L.; Chipalkatty, R.; Hebert, M.; Johnson, D.M.; et al. Segicp: Integrated deep semantic segmentation and pose estimation. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 5784–5789. [Google Scholar]
- Wang, C.; Xu, D.; Zhu, Y.; Martín-Martín, R.; Lu, C.; Fei-Fei, L.; Savarese, S. Densefusion: 6d object pose estimation by iterative dense fusion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3343–3352. [Google Scholar]
- Fischler, M.; Bolles, R. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Ballard, D.H. Generalizing the Hough transform to detect arbitrary shapes. Pattern Recognit. 1981, 13, 111–122. [Google Scholar] [CrossRef] [Green Version]
- Attene, M.; Patanè, G. Hierarchical structure recovery of point-sampled surfaces. In Computer Graphics Forum; Wiley Online Library: Hoboken, NJ, USA, 2010; Volume 29, pp. 1905–1920. [Google Scholar]
- Chaperon, T.; Goulette, F. Extracting Cylinders in Full 3D Data Using a Random Sampling Method and the Gaussian Image. In Proceedings of the Vision Modeling and Visualization Conference 2001 (VMV-01), Stuttgart, Germany, 21–23 November 2001; Volume 2001, pp. 35–42. [Google Scholar]
- Schnabel, R.; Wahl, R.; Klein, R. Efficient RANSAC for Point-Cloud Shape Detection. Comput. Graph. Forum 2007, 26, 214–226. [Google Scholar] [CrossRef]
- Rabbani, T.; Van Den Heuvel, F. Efficient hough transform for automatic detection of cylinders in point clouds. Isprs Wg Iii/3 Iii/4 2005, 3, 60–65. [Google Scholar]
- Rahayem, M.; Werghi, N.; Kjellander, J. Best ellipse and cylinder parameters estimation from laser profile scan sections. Opt. Lasers Eng. 2012, 50, 1242–1259. [Google Scholar] [CrossRef]
- Nievergelt, Y. Fitting cylinders to data. J. Comput. Appl. Math. 2013, 239, 250–269. [Google Scholar] [CrossRef]
- Tran, T.T.; Cao, V.T.; Laurendeau, D. Extraction of cylinders and estimation of their parameters from point clouds. Comput. Graph. 2015, 46, 345–357. [Google Scholar] [CrossRef]
- Kawashima, K.; Kanai, S.; Date, H. As-built modeling of piping system from terrestrial laser-scanned point clouds using normal-based region growing. J. Comput. Des. Eng. 2014, 1, 13–26. [Google Scholar] [CrossRef]
- Nurunnabi, A.; Sadahiro, Y.; Lindenbergh, R.; Belton, D. Robust cylinder fitting in laser scanning point cloud data. Measurement 2019, 138, 632–651. [Google Scholar] [CrossRef]
- Hogan, N. Impedance control: An approach to manipulation: Part I—Theory. J. Dyn. Sys. Meas. Control. 1985, 107, 1–7. [Google Scholar] [CrossRef]
- Ott, C.; Mukherjee, R.; Nakamura, Y. Unified impedance and admittance control. In Proceedings of the 2010 IEEE International Conference on Robotics and Automation, Anchorage, AK, USA, 3–7 May 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 554–561. [Google Scholar]
- Rusu, R.B. Semantic 3D object maps for everyday manipulation in human living environments. KI-Künstliche Intell. 2010, 24, 345–348. [Google Scholar] [CrossRef] [Green Version]
- Klasing, K.; Althoff, D.; Wollherr, D.; Buss, M. Comparison of surface normal estimation methods for range sensing applications. In Proceedings of the 2009 IEEE international conference on robotics and automation, Kobe, Japan, 12–17 May 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 3206–3211. [Google Scholar]
- Chebrolu, N.; Läbe, T.; Vysotska, O.; Behley, J.; Stachniss, C. Adaptive Robust Kernels for Non-Linear Least Squares Problems. arXiv 2020, arXiv:2004.14938. [Google Scholar]
- Abdi, H.; Williams, L.J. Principal component analysis. Wiley Interdiscip. Rev. Comput. Stat. 2010, 2, 433–459. [Google Scholar] [CrossRef]
- Besl, P.J.; McKay, N.D. Method for registration of 3-D shapes. In Sensor Fusion IV: Control Paradigms and Data Structures; International Society for Optics and Photonics: Bellingham, WA, USA, 1992; Volume 1611, pp. 586–606. [Google Scholar]

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | () | (mm) |
|---|---|---|
| RANSAC | 0.4177 | 1.0892 |
| ICP | 0.3008 | 1.2153 |
| PCA | 0.3664 | 1.0267 |
| Our method | 0.0683 | 0.1727 |
| Method | (mm) |
|---|---|
| RANSAC | 6.0245 |
| ICP | 5.9782 |
| PCA | 5.5837 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, C.; Chen, P.; Xu, X.; Wang, X.; Yin, A. A Coarse-to-Fine Method for Estimating the Axis Pose Based on 3D Point Clouds in Robotic Cylindrical Shaft-in-Hole Assembly. Sensors 2021, 21, 4064. https://doi.org/10.3390/s21124064
Li C, Chen P, Xu X, Wang X, Yin A. A Coarse-to-Fine Method for Estimating the Axis Pose Based on 3D Point Clouds in Robotic Cylindrical Shaft-in-Hole Assembly. Sensors. 2021; 21(12):4064. https://doi.org/10.3390/s21124064
Chicago/Turabian StyleLi, Can, Ping Chen, Xin Xu, Xinyu Wang, and Aijun Yin. 2021. "A Coarse-to-Fine Method for Estimating the Axis Pose Based on 3D Point Clouds in Robotic Cylindrical Shaft-in-Hole Assembly" Sensors 21, no. 12: 4064. https://doi.org/10.3390/s21124064