
Experimental Analysis in Hadoop MapReduce: A Closer Look at Fault Detection and Recovery Techniques

 , , , , ,
, , , , ,
Abstract
:1. Introduction
1.1. Motivation
- How does the current fault-tolerance in Hadoop MapReduce handle faults when they occur at various infrastructure levels and in different fault conditions?
- Why do the existing fault detection and recovery techniques in Hadoop MapReduce lead to significant response time penalties?
1.2. Our Contributions
- We conducted a series of experiments on a real-world Hadoop YARN cluster to examine the impact of fail-stop and fail-slow when they occur at the node, service, and task;
- We simulated actual production faults: fail-stop and fail-slow to be injected at runtime and monitor their implications for the response time;
- We highlight the limitations of the current fault-tolerance method, including its fault detection and recovery techniques.
1.3. Paper Organisation
2. Related Works
2.1. Experimenting with Hadoop Fault-Tolerance
2.2. Improving Fault Detection
2.3. Improving Fault Recovery
3. Faults in Hadoop MapReduce
- Fail-arbitrary is also called byzantine, which impacts the system’s behaviour by setting incorrect data values, returning a value of incorrect type, interrupting, or taking incorrect actions;
- Fail-stop causes unresponsive behaviour that is continuous for a fixed period [28];
- Fail-slow is also known struggler, which makes the system accessible, but with poor performance [29].
3.1. Fault Detection
3.2. Fault Recovery
4. Experiment and Evaluation
4.1. Experiment Setup
4.1.1. Workload Application and Dataset
4.1.2. Benchmark and Fault Injection Frameworks
4.1.3. Fault Scenarios
4.2. Evaluation Parameters
4.2.1. Response Time
4.2.2. Fault Detection Time
4.2.3. Fault Recovery Time
5. Results and Discussions
5.1. Response Time
5.2. Fault Detection and Recovery Times
5.3. Discussion
- Service fail-stop has the highest response time penalties compared to the other faults;
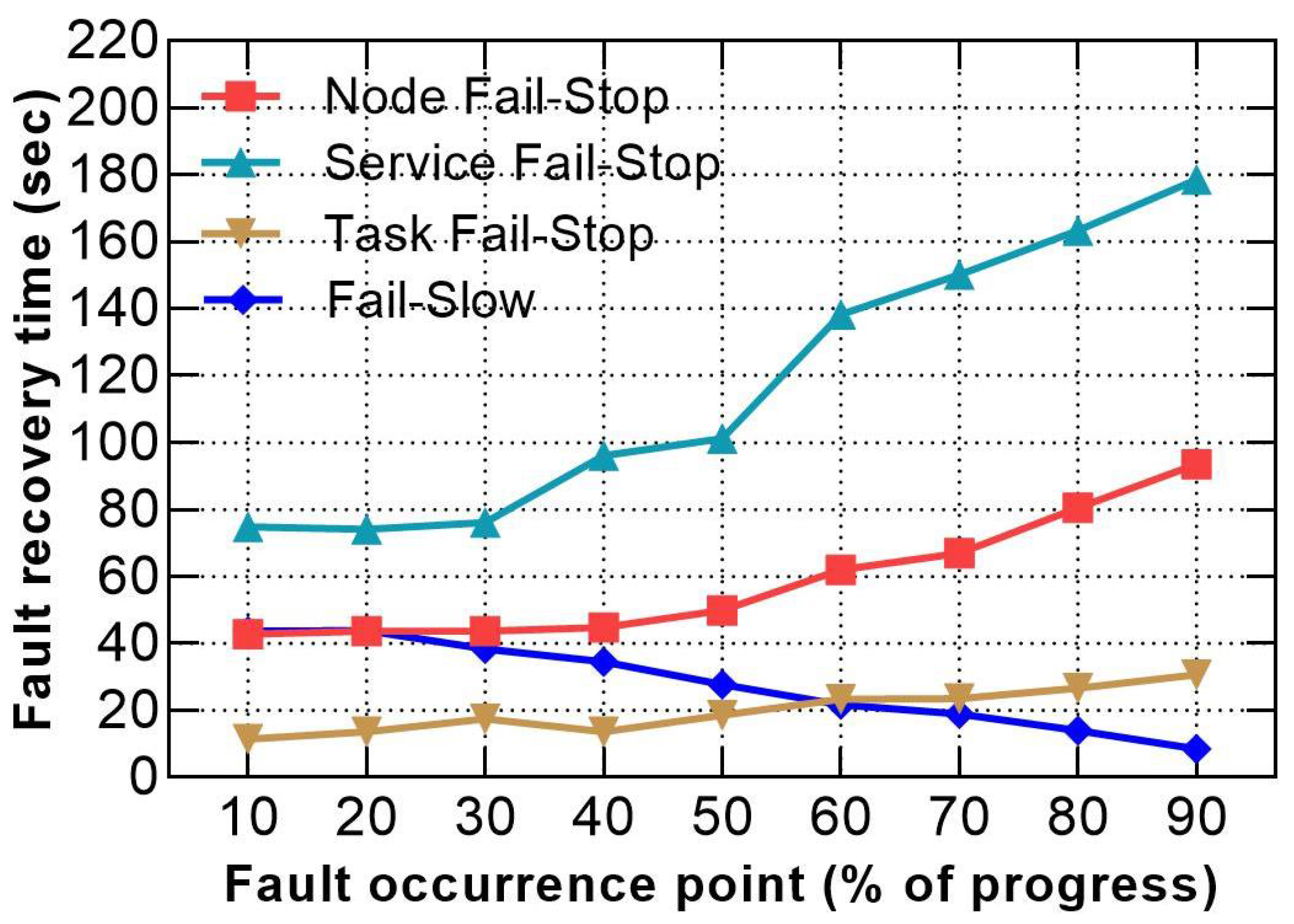
- When the size of a task’s workload increases due to a large data block, the recovery time also increases because of the re-computation of the entire block;
- Fault occurrence at the late point of the job lifetime incurs higher penalties for node and service fail-stop and lower penalties for task fail-stop and fail-slow;
- The current fault-tolerance method does not consider the programming logic of the application to detect and recover faults and failures;
- The response time decreases when setting small timeout values but with higher resource consumption;
- The recovery of a single fault leads to an average of 67.6% response time penalty.
- The current fault-tolerance method of Hadoop handles fail-stop and fail-slow from node and service based on the static heartbeat messages and re-execution techniques. If the entire node fails, all its active services and tasks fail as well regardless of their progress, and they will be subject to re-execution. The identification of fail-stop only happens when the node is entirely inactive within a static timeout interval. When a service fails, Hadoop is not able to realise the failure because the master node still receives heartbeat messages from the same node that runs the failed service, which leads to a substantial waiting time. Fail-slow has a direct impact on the task level only, and Hadoop detects task fail-slow and fail-stop by comparing the slow task progress with other healthy tasks. Slow tasks are also subject to restart from scratch on another node and based on the scheduler decision in terms of data locality and resource availability.
- The significant response time penalties happen because of the static waiting time spent by Hadoop to detect a failure. This waiting time is critical because if one node fails out of thousands, the entire job response time is extended per one node fault detection and recovery times. Even though the detection time is optimised based on short monitoring intervals, the recovery time can still be long because it depends on the cluster behaviour in the recovery stage in terms of resource capacity and the locations of data blocks.
6. Conclusions and Future Works
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| HDFS | Hadoop Distributed File System |
| YARN | Yet Another Resource Negotiator |
| MT | Map Task |
| RT | Reduce Task |
| RM | Resource Manager |
| NN | Name Node |
| NM | Node Manager |
| DN | Data Node |
| AM | Application Master |
| MTTD | Mean Time to Detect |
| MTTR | Mean Time to Repair |
References
- Ean, J.; Ghemawat, S. MapReduce: Simplified data processing on large cluster. In Proceedings of the 6th Symposium on Operating Systems Design & Implementation, Berkeley, CA, USA, 6–8 December 2008; pp. 6–8. [Google Scholar]
- Alkasem, A.; Liu, H.; Shafiq, M. Improving fault diagnosis performance using hadoop mapreduce for efficient classification and analysis of large data sets. J. Comput. 2018, 29, 185–202. [Google Scholar]
- Azeez, N.A.; Ayemobola, T.J.; Misra, S.; Maskeliūnas, R.; Damaševičius, R. Network intrusion detection with a hashing based apriori algorithm using Hadoop MapReduce. Computers 2019, 8, 86. [Google Scholar] [CrossRef] [Green Version]
- Kumar Behera, R.; Kumar Rath, S.; Misra, S.; Damaševičius, R.; Maskeliūnas, R. Distributed centrality analysis of social network data using MapReduce. Algorithms 2019, 12, 161. [Google Scholar] [CrossRef] [Green Version]
- Torres-Huitzil, C.; Girau, B. Fault and error tolerance in neural networks: A review. IEEE Access 2017, 5, 17322–17341. [Google Scholar] [CrossRef]
- Nabi, M.; Toeroe, M.; Khendek, F. Availability in the cloud: State of the art. J. Netw. Comput. Appl. 2016, 60, 54–67. [Google Scholar] [CrossRef]
- Liu, J.; Shen, H.; Chi, H.; Narman, H.S.; Yang, Y.; Cheng, L.; Chung, W. A Low-Cost Multi-Failure Resilient Replication Scheme for High-Data Availability in Cloud Storage. IEEE/ACM Trans. Netw. 2020. [Google Scholar] [CrossRef]
- Asghar, H.; Nazir, B. Analysis and implementation of reactive fault tolerance techniques in Hadoop: A comparative study. J. Supercomput. 2021, 1–27. [Google Scholar] [CrossRef]
- Memishi, B.; Pérez, M.S.; Antoniu, G. Failure detector abstractions for MapReduce-based systems. Inf. Sci. 2017, 379, 112–127. [Google Scholar] [CrossRef] [Green Version]
- Kadirvel, S.; Fortes, J.A. Towards self-caring MapReduce: A study of performance penalties under faults. Concurr. Comput. Pract. Exp. 2015, 27, 2310–2328. [Google Scholar] [CrossRef]
- Faghri, F.; Bazarbayev, S.; Overholt, M.; Farivar, R.; Campbell, R.H.; Sanders, W.H. Failure scenario as a service (FSaaS) for Hadoop clusters. In Proceedings of the Workshop on Secure and Dependable Middleware for Cloud Monitoring and Management, Montreal, QC, USA, 4 December 2012; pp. 1–6. [Google Scholar]
- Dinu, F.; Ng, T.E. Understanding the effects and implications of compute node related failures in hadoop. In Proceedings of the 21st International Symposium on High-Performance Parallel and Distributed Computing, Delft, The Netherlands, 18–22 June 2012; pp. 187–198. [Google Scholar]
- Vavilapalli, V.; Murthy, A.; Douglas, C.; Agarwal, S.; Konar, M.; Evans, R.; Graves, T.; Lowe, J.; Shah, H.; Seth, S.; et al. Apache hadoop yarn: Yet another resource negotiator. In Proceedings of the 4th annual Symposium on Cloud Computing, Santa Clara, CA, USA, 1 October 2013; Volume 704, p. 5. [Google Scholar]
- Rahman, M.T.; Gabriel, E.; Subhlok, J. Performance implications of failures on MapReduce applications. In Proceedings of the 2017 IEEE International Conference on Cluster Computing (CLUSTER), Honolulu, HI, USA, 5–8 September 2017; pp. 741–748. [Google Scholar]
- Zaharia, M.; Konwinski, A.; Joseph, A.D.; Katz, R.H.; Stoica, I. Improving MapReduce performance in heterogeneous environments. Osdi 2008, 8, 7. [Google Scholar]
- Chen, Q.; Zhang, D.; Guo, M.; Deng, Q.; Guo, S. Samr: A self-adaptive mapreduce scheduling algorithm in heterogeneous environment. In Proceedings of the 2010 10th IEEE International Conference on Computer and Information Technology, Bradford, UK, 29 June–1 July 2010; pp. 2736–2743. [Google Scholar]
- Gupta, C.; Bansal, M.; Chuang, T.C.; Sinha, R.; Ben-Romdhane, S. Astro: A predictive model for anomaly detection and feedback-based scheduling on Hadoop. In Proceedings of the 2014 IEEE International Conference on Big Data (Big Data), Anchorage, AK, USA, 27 June–2 July 2014; pp. 854–862. [Google Scholar]
- Rosa, A.; Chen, L.Y.; Binder, W. Catching failures of failures at big-data clusters: A two-level neural network approach. In Proceedings of the 2015 IEEE 23rd International Symposium on Quality of Service (IWQoS), Portland, OR, USA, 15–16 June 2015; pp. 231–236. [Google Scholar]
- Soualhia, M.; Khomh, F.; Tahar, S. ATLAS: An adaptive failure-aware scheduler for hadoop. In Proceedings of the 2015 IEEE 34th International Performance Computing and Communications Conference (IPCCC), Nanjing, China, 14–16 December 2015; pp. 1–8. [Google Scholar]
- Soualhia, M.; Khomh, F.; Tahar, S. A dynamic and failure-aware task scheduling framework for hadoop. IEEE Trans. Cloud Comput. 2018, 8, 553–569. [Google Scholar] [CrossRef]
- Yildiz, O.; Ibrahim, S.; Antoniu, G. Enabling fast failure recovery in shared Hadoop clusters: Towards failure-aware scheduling. Future Gener. Comput. Syst. 2017, 74, 208–219. [Google Scholar] [CrossRef] [Green Version]
- Kadirvel, S.; Ho, J.; Fortes, J.A. Fault management in Map-Reduce through early detection of anomalous nodes. In Proceedings of the 10th International Conference on Autonomic Computing (ICAC 13), San Jose, CA, USA, 26–28 June 2013; pp. 235–245. [Google Scholar]
- Quiané-Ruiz, J.A.; Pinkel, C.; Schad, J.; Dittrich, J. RAFTing MapReduce: Fast recovery on the RAFT. In Proceedings of the 2011 IEEE 27th International Conference on Data Engineering, Hannover, Germany, 11–16 April 2011; pp. 589–600. [Google Scholar]
- Zhu, Y.; Samsudin, J.; Kanagavelu, R.; Zhang, W.; Wang, L.; Aye, T.T.; Goh, R.S.M. Fast Recovery MapReduce (FAR-MR) to accelerate failure recovery in big data applications. J. Supercomput. 2020, 76, 3572–3588. [Google Scholar] [CrossRef]
- Liu, J.; Wang, P.; Zhou, J.; Li, K. McTAR: A multi-trigger checkpointing tactic for fast task recovery in MapReduce. IEEE Trans. Serv. Comput. 2019. [Google Scholar] [CrossRef]
- Shvachko, K.; Kuang, H.; Radia, S.; Chansler, R. The hadoop distributed file system. In Proceedings of the 2010 IEEE 26th Symposium on Mass Storage Systems and Technologies (MSST), Lake Tahoe, NV, USA, 3–7 May 2010; pp. 1–10. [Google Scholar]
- Li, R.; Hu, H.; Li, H.; Wu, Y.; Yang, J. MapReduce parallel programming model: A state-of-the-art survey. Int. J. Parallel Program. 2016, 44, 832–866. [Google Scholar] [CrossRef]
- Elnozahy, E.N.; Alvisi, L.; Wang, Y.M.; Johnson, D.B. A survey of rollback-recovery protocols in message-passing systems. ACM Comput. Surv. 2002, 34, 375–408. [Google Scholar] [CrossRef] [Green Version]
- Xie, J.; Yin, S.; Ruan, X.; Ding, Z.; Tian, Y.; Majors, J.; Manzanares, A.; Qin, X. Improving mapreduce performance through data placement in heterogeneous hadoop clusters. In Proceedings of the 2010 IEEE International Symposium on Parallel & Distributed Processing, Workshops and Phd Forum (IPDPSW), Atlanta, GA, USA, 19–23 April 2010; pp. 1–9. [Google Scholar]
- Avizienis, A.; Laprie, J.C.; Randell, B.; Landwehr, C. Basic concepts and taxonomy of dependable and secure computing. IEEE Trans. Dependable Secur. Comput. 2004, 1, 11–33. [Google Scholar] [CrossRef] [Green Version]
- Ayari, N.; Barbaron, D.; Lefevre, L.; Primet, P. Fault tolerance for highly available internet services: Concepts, approaches, and issues. IEEE Commun. Surv. Tutor. 2008, 10, 34–46. [Google Scholar] [CrossRef]
- Liu, J.; Tang, S.; Xu, G.; Ma, C.; Lin, M. A Novel Configuration Tuning Method Based on Feature Selection for Hadoop MapReduce. IEEE Access 2020, 8, 63862–63871. [Google Scholar] [CrossRef]
- Nachiappan, R.; Javadi, B.; Calheiros, R.N.; Matawie, K.M. Cloud storage reliability for big data applications: A state of the art survey. J. Netw. Comput. Appl. 2017, 97, 35–47. [Google Scholar] [CrossRef]
- Zhu, H.; Chen, H. Adaptive failure detection via heartbeat under Hadoop. In Proceedings of the 2011 IEEE Asia-Pacific Services Computing Conference, Jeju, Korea, 12–15 December 2011; pp. 231–238. [Google Scholar]
- Chen, Y.; Ganapathi, A.S.; Griffith, R.; Katz, R.H. A methodology for understanding mapreduce performance under diverse workloads. In EECS Department, University of California, Berkeley, Tech. Rep. UCB/EECS-2010-135; University of California: Berkeley, CA, USA, 2010. [Google Scholar]
- Chen, Y.; Alspaugh, S.; Katz, R. Interactive analytical processing in big data systems: A cross-industry study of mapreduce workloads. arXiv 2012, arXiv:1208.4174. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Framework/Techniques | Fault Type | Command |
|---|---|---|
| AnarchyApe | Node fail-stop | java -jar ape.jar -L -F |
| AnarchyApe | Service fail-stop | java -jar ape.jar -L -k <serviceName> |
| Manual script | Task fail-stop | Sudo kill -9 <processID> |
| Stress-ng | Fail-slow | stress-ng –cpu 8 –io 8 –vm 1–vm-bytes 16G –timeout 150 s |
| Infrastructure Parameters | Description |
|---|---|
| Node number | The number of the active nodes in the cluster. |
| Data size | The size of input data to be processed by the active nodes. |
| Block size | The size of each chunk of data after distribution across the nodes. |
| Map task number | The total number of map tasks to be executed on the active nodes. |
| Reduce task number | The total number of reduce tasks to write the output on HDFS. |
| Replication number | The number of replicas per each data block. |
| Timeout value | The time difference between each heartbeat message sends to check the instance liveness. |
| Slow-task threshold | The standard deviations number for a task average progress. |
| Fault occurrence point | The actual timestamp of injecting a fault during the job lifetime. |
| Fault Detection Parameter | Default Value | Tuned Value | Description |
|---|---|---|---|
| yarn.nm.liveness-monitor.expiry-interval-ms | 600 s | 10 s | Time in seconds to wait until considering the NM dead. |
| yarn.nodemanager.health-checker.interval-ms | 600 s | 10 s | Frequency of running node health script. |
| mapreduce.task.timeout | 600 s | 10 s | Time in seconds before a task will be terminated if it neither reads an input, writes an output, nor updates its status string. |
| mapreduce.job.speculative.slowtaskthreshold | 1.0 | 0.1 | Standard deviations number by which a task average progress must be lower than the average of all running tasks. |
| Group | Fault Type | Fault Point (%) | Recovery Time (sec) | Response Time Penalty (%) |
|---|---|---|---|---|
| Best | Node fail-stop | 10 | 42.73 | 53.03 |
| Service fail-stop | 10 | 74.911 | 88.79 | |
| Task fail-stop | 10 | 11.414 | 18.24 | |
| Fail-Slow | 90 | 8.46 | 14.96 | |
| Median | Node fail-stop | 50 | 49.927 | 61.03 |
| Service fail-stop | 50 | 101.241 | 118.05 | |
| Task fail-stop | 50 | 18.632 | 26.26 | |
| Fail-slow | 50 | 27.678 | 36.31 | |
| Extreme | Node fail-stop | 90 | 93.503 | 109.45 |
| Service fail-stop | 90 | 178.555 | 203.95 | |
| Task fail-stop | 90 | 30.749 | 39.72 | |
| Fail-slow | 20 | 43.798 | 54.22 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saadoon, M.; Hamid, S.H.A.; Sofian, H.; Altarturi, H.; Nasuha, N.; Azizul, Z.H.; Sani, A.A.; Asemi, A. Experimental Analysis in Hadoop MapReduce: A Closer Look at Fault Detection and Recovery Techniques. Sensors 2021, 21, 3799. https://doi.org/10.3390/s21113799
Saadoon M, Hamid SHA, Sofian H, Altarturi H, Nasuha N, Azizul ZH, Sani AA, Asemi A. Experimental Analysis in Hadoop MapReduce: A Closer Look at Fault Detection and Recovery Techniques. Sensors. 2021; 21(11):3799. https://doi.org/10.3390/s21113799
Chicago/Turabian StyleSaadoon, Muntadher, Siti Hafizah Ab Hamid, Hazrina Sofian, Hamza Altarturi, Nur Nasuha, Zati Hakim Azizul, Asmiza Abdul Sani, and Adeleh Asemi. 2021. "Experimental Analysis in Hadoop MapReduce: A Closer Look at Fault Detection and Recovery Techniques" Sensors 21, no. 11: 3799. https://doi.org/10.3390/s21113799