Congested Crowd Counting via Adaptive Multi-Scale Context Learning †

Abstract
:1. Introduction

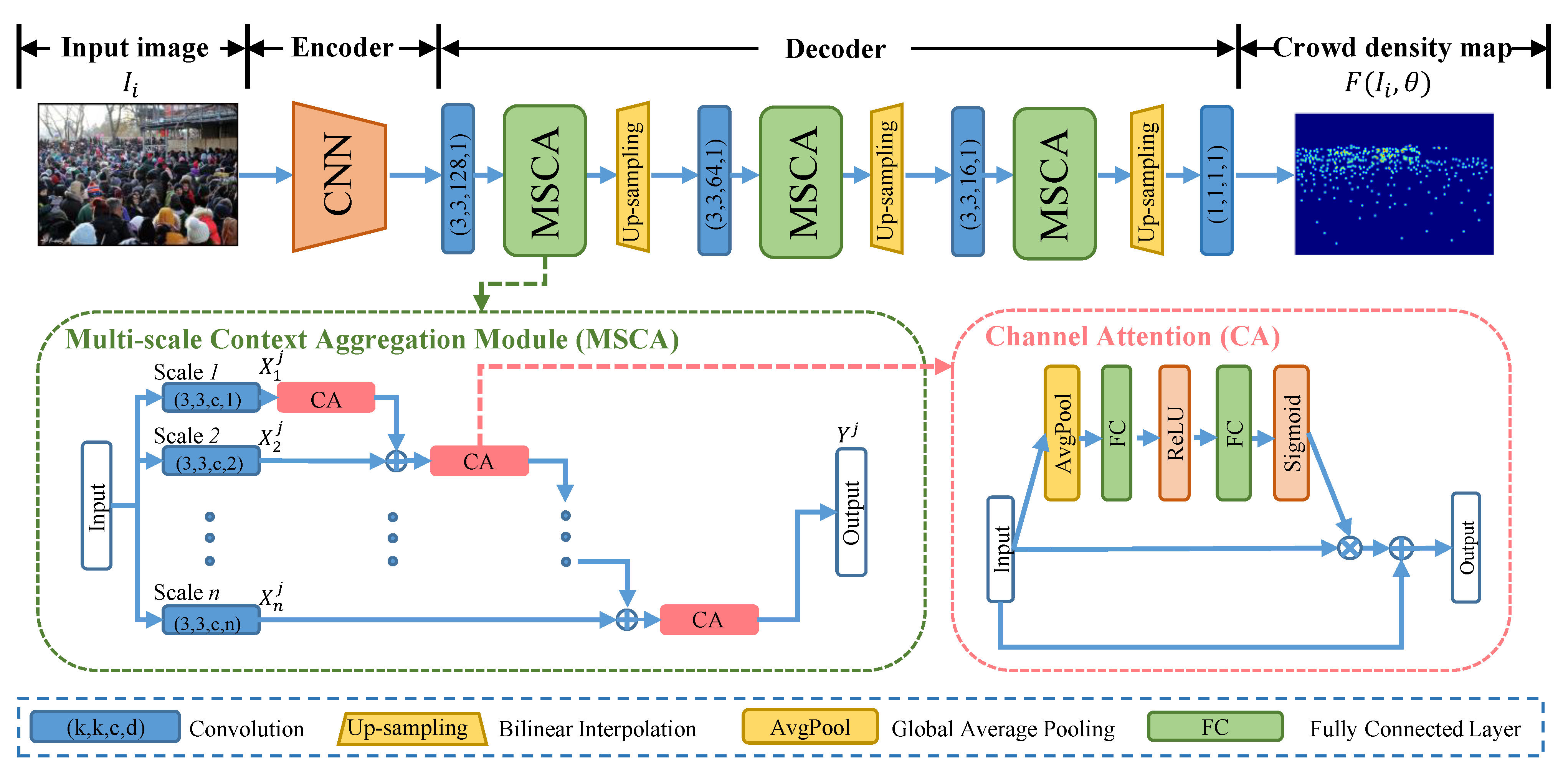
- We propose a MSCA to adaptively aggregate small-scale context representation with large-scale context representation in a cascade manner, which encodes more compact global context features for crowds at various scales.
- Employing multiple MSCAs, we introduce the MSCANet to obtain multi-scale context features with different resolutions. This can efficiently address the ambiguous appearance challenge, especially under crowded scenes with complex backgrounds.
2. Related Works
2.1. Crowd Counting
2.2. Crowd Localization
2.3. Remote Sensing Object Counting
3. Proposed Method
3.1. Problem Formulation
3.2. Multi-Scale Context Aggregation Module
| Algorithm 1 Pseudocode of Multi-scale Context Aggregation Module with three branches in a PyTorch-like style. |
|
3.3. Multi-Scale Context Aggregation Network
3.4. Compared to Other Context Modules
3.5. Extension of MSCANet
4. Experiments
4.1. Datasets
4.2. Evaluation Metrics
4.3. Comparison with State-of-the-Arts
4.3.1. Crowd Counting
4.3.2. Crowd Localization
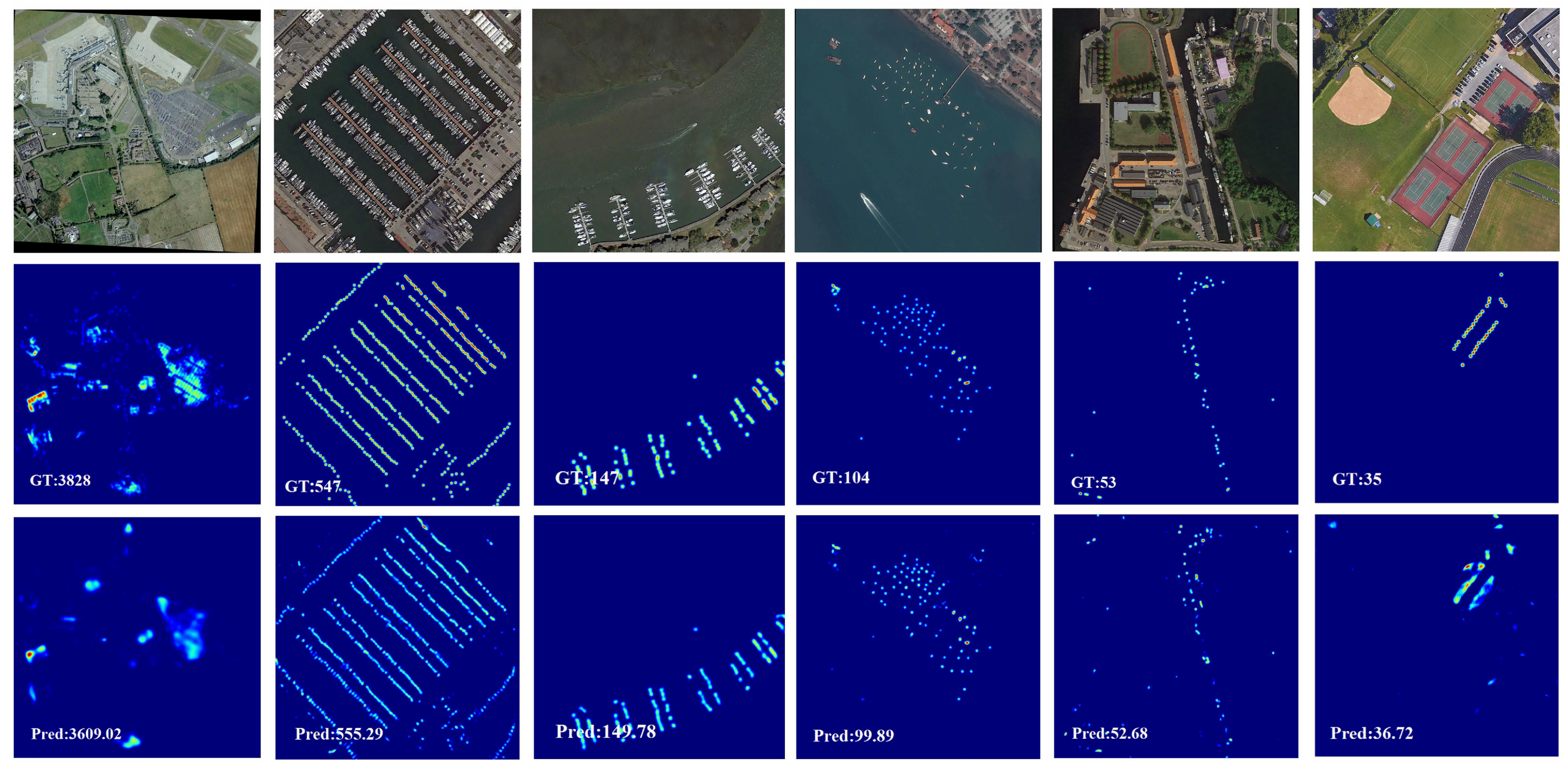
4.3.3. Remote Sensing Object Counting
4.4. Ablation Study
4.4.1. Multi-Scale Context Aggregation Module
4.4.2. Multi-Scale Context Modules
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yu, Y.; Huang, J.; Du, W.; Xiong, N. Design and analysis of a lightweight context fusion CNN scheme for crowd counting. Sensors 2019, 19, 2013. [Google Scholar] [CrossRef] [Green Version]
- Tong, M.; Fan, L.; Nan, H.; Zhao, Y. Smart camera aware crowd counting via multiple task fractional stride deep learning. Sensors 2019, 19, 1346. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Csönde, G.; Sekimoto, Y.; Kashiyama, T. Crowd counting with semantic scene segmentation in helicopter footage. Sensors 2020, 20, 4855. [Google Scholar] [CrossRef] [PubMed]
- Ilyas, N.; Shahzad, A.; Kim, K. Convolutional-neural network-based image crowd counting: Review, categorization, analysis, and performance evaluation. Sensors 2020, 20, 43. [Google Scholar] [CrossRef] [Green Version]
- Fortino, G.; Savaglio, C.; Spezzano, G.; Zhou, M. Internet of Things as System of Systems: A Review of Methodologies, Frameworks, Platforms, and Tools. IEEE Trans. Syst. Man Cybern. Syst. 2020. [Google Scholar] [CrossRef]
- Abualsaud, K.; Elfouly, T.M.; Khattab, T.; Yaacoub, E.; Ismail, L.S.; Ahmed, M.H.; Guizani, M. A survey on mobile crowd-sensing and its applications in the IoT era. IEEE Access 2018, 7, 3855–3881. [Google Scholar] [CrossRef]
- Solmaz, G.; Wu, F.J.; Cirillo, F.; Kovacs, E.; Santana, J.R.; Sánchez, L.; Sotres, P.; Munoz, L. Toward understanding crowd mobility in smart cities through the internet of things. IEEE Commun. Mag. 2019, 57, 40–46. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Zhang, X.; Chen, D. Csrnet: Dilated convolutional neural networks for understanding the highly congested scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1091–1100. [Google Scholar]
- Zhang, C.; Li, H.; Wang, X.; Yang, X. Cross-scene crowd counting via deep convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 833–841. [Google Scholar]
- Zhang, Y.; Zhou, D.; Chen, S.; Gao, S.; Ma, Y. Single-image crowd counting via multi-column convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 589–597. [Google Scholar]
- Onoro-Rubio, D.; López-Sastre, R.J. Towards perspective-free object counting with deep learning. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 615–629. [Google Scholar]
- Deb, D.; Ventura, J. An aggregated multicolumn dilated convolution network for perspective-free counting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–23 June 2018; pp. 195–204. [Google Scholar]
- Wang, Z.; Xiao, Z.; Xie, K.; Qiu, Q.; Zhen, X.; Cao, X. In Defense of Single-column Networks for Crowd Counting. arXiv 2018, arXiv:1808.06133. [Google Scholar]
- Liu, N.; Long, Y.; Zou, C.; Niu, Q.; Pan, L.; Wu, H. ADCrowdNet: An Attention-injective Deformable Convolutional Network for Crowd Understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 3225–3234. [Google Scholar]
- Liu, W.; Salzmann, M.; Fua, P. Context-Aware Crowd Counting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 5099–5108. [Google Scholar]
- Chen, X.; Bin, Y.; Sang, N.; Gao, C. Scale pyramid network for crowd counting. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 7–11 January 2019; pp. 1941–1950. [Google Scholar]
- Idrees, H.; Tayyab, M.; Athrey, K.; Zhang, D.; Al-Maadeed, S.; Rajpoot, N.; Shah, M. Composition loss for counting, density map estimation and localization in dense crowds. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 532–546. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Zhang, Y.; Zhao, H.; Zhou, F.; Zhang, Q.; Shi, Y.; Liang, L. MSCANet: Adaptive Multi-scale Context Aggregation Network for Congested Crowd Counting. In Proceedings of the 27th International Conference on Multimedia Modeling, Prague, Czech Republic, 22–24 June 2021; pp. 1–12. [Google Scholar]
- Chan, A.B.; Liang, Z.S.J.; Vasconcelos, N. Privacy preserving crowd monitoring: Counting people without people models or tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 24–26 June 2008; pp. 1–7. [Google Scholar]
- Zhang, J.; Tan, B.; Sha, F.; He, L. Predicting pedestrian counts in crowded scenes with rich and high-dimensional features. IEEE Trans. Intell. Transp. Syst. 2011, 12, 1037–1046. [Google Scholar] [CrossRef]
- Ma, Z.; Chan, A.B. Counting people crossing a line using integer programming and local features. IEEE Trans. Circuits Syst. Video Technol. 2015, 26, 1955–1969. [Google Scholar] [CrossRef]
- Zheng, H.; Lin, Z.; Cen, J.; Wu, Z.; Zhao, Y. Cross-line pedestrian counting based on spatially-consistent two-stage local crowd density estimation and accumulation. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 787–799. [Google Scholar] [CrossRef]
- Sheng, B.; Shen, C.; Lin, G.; Li, J.; Yang, W.; Sun, C. Crowd counting via weighted VLAD on a dense attribute feature map. IEEE Trans. Circuits Syst. Video Technol. 2016, 28, 1788–1797. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Xue, Y.; Wang, W.; Ouyang, G. Cross-Level Parallel Network for Crowd Counting. IEEE Trans. Ind. Inf. 2020, 16, 566–576. [Google Scholar] [CrossRef]
- Liu, L.; Qiu, Z.; Li, G.; Liu, S.; Ouyang, W.; Lin, L. Crowd counting with deep structured scale integration network. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–3 November 2019; pp. 1774–1783. [Google Scholar]
- Cheng, Z.Q.; Li, J.X.; Dai, Q.; Wu, X.; He, J.Y.; Hauptmann, A.G. Improving the learning of multi-column convolutional neural network for crowd counting. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 1897–1906. [Google Scholar]
- Qiu, Z.; Liu, L.; Li, G.; Wang, Q.; Xiao, N.; Lin, L. Crowd counting via multi-view scale aggregation networks. In Proceedings of the IEEE International Conference on Multimedia and Expo, Shanghai, China, 8–12 July 2019; pp. 1498–1503. [Google Scholar]
- Kang, D.; Chan, A. Crowd Counting by Adaptively Fusing Predictions from an Image Pyramid. In Proceedings of the British Machine Vision Conference, Newcastle, UK, 2–6 September 2018. [Google Scholar]
- Liu, L.; Wang, H.; Li, G.; Ouyang, W.; Lin, L. Crowd Counting Using Deep Recurrent Spatial-aware Network. In Proceedings of the 27th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 849–855. [Google Scholar]
- Amirgholipour, S.; He, X.; Jia, W.; Wang, D.; Zeibots, M. A-CCNN: Adaptive CCNN for Density Estimation and Crowd Counting. In Proceedings of the IEEE International Conference on Image Processing, Athens, Greece, 7–10 October 2018; pp. 948–952. [Google Scholar]
- Ding, X.; Lin, Z.; He, F.; Wang, Y.; Huang, Y. A Deeply-Recursive Convolutional Network For Crowd Counting. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Seoul, South Korea, 22–27 April 2018; pp. 1942–1946. [Google Scholar]
- Zhang, L.; Shi, M.; Chen, Q. Crowd counting via scale-adaptive convolutional neural network. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1113–1121. [Google Scholar]
- Cao, X.; Wang, Z.; Zhao, Y.; Su, F. Scale aggregation network for accurate and efficient crowd counting. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Luo, A.; Yang, F.; Li, X.; Nie, D.; Jiao, Z.; Zhou, S.; Cheng, H. Hybrid Graph Neural Networks for Crowd Counting. arXiv 2020, arXiv:2002.00092. [Google Scholar] [CrossRef]
- Shi, M.; Yang, Z.; Xu, C.; Chen, Q. Revisiting perspective information for efficient crowd counting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 7279–7288. [Google Scholar]
- Yan, Z.; Yuan, Y.; Zuo, W.; Tan, X.; Wang, Y.; Wen, S.; Ding, E. Perspective-guided convolution networks for crowd counting. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–3 November 2019; pp. 952–961. [Google Scholar]
- Sam, D.B.; Surya, S.; Babu, R.V. Switching convolutional neural network for crowd counting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 24–30 June 2017; pp. 4031–4039. [Google Scholar]
- Sindagi, V.A.; Patel, V.M. Generating high-quality crowd density maps using contextual pyramid cnns. In Proceedings of the International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1861–1870. [Google Scholar]
- Gao, J.; Wang, Q.; Li, X. PCC Net: Perspective Crowd Counting via Spatial Convolutional Network. IEEE Trans. Circuits Syst. Video Technol. 2019. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, W.; Zhou, T.; Yu, F.; Dai, J.; Konukoglu, E.; Van Gool, L. Exploring cross-image pixel contrast for semantic segmentation. arXiv 2021, arXiv:2101.11939. [Google Scholar]
- Li, X.; Zhou, T.; Li, J.; Zhou, Y.; Zhang, Z. Group-Wise Semantic Mining for Weakly Supervised Semantic Segmentation. arXiv 2020, arXiv:2012.05007. [Google Scholar]
- Zhou, T.; Qi, S.; Wang, W.; Shen, J.; Zhu, S.C. Cascaded parsing of human-object interaction recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2021. [Google Scholar] [CrossRef]
- Zhou, T.; Li, J.; Wang, S.; Tao, R.; Shen, J. Matnet: Motion-attentive transition network for zero-shot video object segmentation. IEEE Trans. Image Process. 2020, 29, 8326–8338. [Google Scholar] [CrossRef]
- Sindagi, V.A.; Patel, V.M. Ha-ccn: Hierarchical attention-based crowd counting network. IEEE Trans. Image Process. 2019, 29, 323–335. [Google Scholar] [CrossRef] [Green Version]
- Zhang, A.; Shen, J.; Xiao, Z.; Zhu, F.; Zhen, X.; Cao, X.; Shao, L. Relational attention network for crowd counting. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–3 November 2019; pp. 6788–6797. [Google Scholar]
- Zhang, A.; Yue, L.; Shen, J.; Zhu, F.; Zhen, X.; Cao, X.; Shao, L. Attentional neural fields for crowd counting. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–3 November 2019; pp. 5714–5723. [Google Scholar]
- Guo, D.; Li, K.; Zha, Z.J.; Wang, M. Dadnet: Dilated-attention-deformable convnet for crowd counting. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 1823–1832. [Google Scholar]
- Zhao, M.; Zhang, J.; Zhang, C.; Zhang, W. Leveraging heterogeneous auxiliary tasks to assist crowd counting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 12736–12745. [Google Scholar]
- Jiang, S.; Lu, X.; Lei, Y.; Liu, L. Mask-aware networks for crowd counting. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 3119–3129. [Google Scholar] [CrossRef] [Green Version]
- Wu, X.; Zheng, Y.; Ye, H.; Hu, W.; Yang, J.; He, L. Adaptive scenario discovery for crowd counting. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Brighton, UK, 12–17 May 2019; pp. 2382–2386. [Google Scholar]
- Sajid, U.; Wang, G. Plug-and-Play Rescaling Based Crowd Counting in Static Images. arXiv 2020, arXiv:2001.01786. [Google Scholar]
- Wang, Q.; Gao, J.; Lin, W.; Yuan, Y. Learning from synthetic data for crowd counting in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 8198–8207. [Google Scholar]
- Li, W.; Yongbo, L.; Xiangyang, X. CODA: Counting Objects via Scale-Aware Adversarial Density Adaption. In Proceedings of the IEEE International Conference on Multimedia and Expo, Shanghai, China, 8–12 July 2019; pp. 193–198. [Google Scholar]
- Lempitsky, V.; Zisserman, A. Learning to count objects in images. Adv. Neural Inf. Process. Syst. 2010, 23, 1324–1332. [Google Scholar]
- Wan, J.; Chan, A. Adaptive density map generation for crowd counting. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–3 November 2019; pp. 1130–1139. [Google Scholar]
- Sindagi, V.A.; Yasarla, R.; Patel, V.M. Pushing the frontiers of unconstrained crowd counting: New dataset and benchmark method. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–3 November 2019; pp. 1221–1231. [Google Scholar]
- Sindagi, V.A.; Patel, V.M. Multi-level bottom-top and top-bottom feature fusion for crowd counting. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–3 November 2019; pp. 1002–1012. [Google Scholar]
- Ma, Z.; Wei, X.; Hong, X.; Gong, Y. Bayesian loss for crowd count estimation with point supervision. In Proceedings of the International Conference on Computer Vision, Seoul, Korea, 27 October–3 November 2019; pp. 6142–6151. [Google Scholar]
- Shen, Z.; Xu, Y.; Ni, B.; Wang, M.; Hu, J.; Yang, X. Crowd counting via adversarial cross-scale consistency pursuit. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5245–5254. [Google Scholar]
- Zhou, Y.; Yang, J.; Li, H.; Cao, T.; Kung, S.Y. Adversarial learning for multiscale crowd counting under complex scenes. IEEE Trans. Cybern. 2020. [Google Scholar] [CrossRef]
- Cheng, Z.Q.; Li, J.X.; Dai, Q.; Wu, X.; Hauptmann, A.G. Learning spatial awareness to improve crowd counting. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–3 November 2019; pp. 6152–6161. [Google Scholar]
- Liu, J.; Gao, C.; Meng, D.; Hauptmann, A.G. Decidenet: Counting varying density crowds through attention guided detection and density estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5197–5206. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.B.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. arXiv 2015, arXiv:1506.01497. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lian, D.; Li, J.; Zheng, J.; Luo, W.; Gao, S. Density Map Regression Guided Detection Network for RGB-D Crowd Counting and Localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 1821–1830. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- He, G.; Ma, Z.; Huang, B.; Sheng, B.; Yuan, Y. Dynamic Region Division for Adaptive Learning Pedestrian Counting. In Proceedings of the IEEE International Conference on Multimedia and Expo, Shanghai, China, 8–12 July 2019; pp. 1120–1125. [Google Scholar]
- Liu, C.; Weng, X.; Mu, Y. Recurrent Attentive Zooming for Joint Crowd Counting and Precise Localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 1217–1226. [Google Scholar]
- Shi, Z.; Mettes, P.; Snoek, C.G. Counting with focus for free. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–3 November 2019; pp. 4200–4209. [Google Scholar]
- Xu, C.; Qiu, K.; Fu, J.; Bai, S.; Xu, Y.; Bai, X. Learn to Scale: Generating Multipolar Normalized Density Map for Crowd Counting. arXiv 2019, arXiv:1907.12428. [Google Scholar]
- Xu, C.; Liang, D.; Xu, Y.; Bai, S.; Zhan, W.; Bai, X.; Tomizuka, M. Autoscale: Learning to scale for crowd counting. arXiv 2019, arXiv:1912.09632. [Google Scholar]
- Khan, S.D.; Ullah, H.; Uzair, M.; Ullah, M.; Ullah, R.; Cheikh, F.A. Disam: Density Independent and Scale Aware Model for Crowd Counting and Localization. In Proceedings of the IEEE International Conference on Image Processing, Taipei, Taiwan, 22–25 September 2019; pp. 4474–4478. [Google Scholar]
- Wang, S.; Lu, Y.; Zhou, T.; Di, H.; Lu, L.; Zhang, L. SCLNet: Spatial context learning network for congested crowd counting. Neurocomputing 2020, 404, 227–239. [Google Scholar] [CrossRef]
- Xia, G.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A Large-Scale Dataset for Object Detection in Aerial Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3974–3983. [Google Scholar]
- Bazi, Y.; Al-Sharari, H.; Melgani, F. An automatic method for counting olive trees in very high spatial remote sensing images. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Cape Town, South Africa, 12–17 July 2009; Volume 2, pp. 125–128. [Google Scholar]
- Santoro, F.; Tarantino, E.; Figorito, B.; Gualano, S.; D’Onghia, A.M. A tree counting algorithm for precision agriculture tasks. Int. J. Digital Earth 2013, 6, 94–102. [Google Scholar] [CrossRef]
- Xue, Y.; Wang, T.; Skidmore, A.K. Automatic counting of large mammals from very high resolution panchromatic satellite imagery. Remote Sens. 2017, 9, 878. [Google Scholar] [CrossRef] [Green Version]
- Salamí, E.; Gallardo, A.; Skorobogatov, G.; Barrado, C. On-the-fly olive tree counting using a UAS and cloud services. Remote Sens. 2019, 11, 316. [Google Scholar] [CrossRef] [Green Version]
- Mubin, N.A.; Nadarajoo, E.; Shafri, H.Z.M.; Hamedianfar, A. Young and mature oil palm tree detection and counting using convolutional neural network deep learning method. Int. J. Remote Sens. 2019, 40, 7500–7515. [Google Scholar] [CrossRef]
- Shao, W.; Kawakami, R.; Yoshihashi, R.; You, S.; Kawase, H.; Naemura, T. Cattle detection and counting in UAV images based on convolutional neural networks. Int. J. Remote Sens. 2020, 41, 31–52. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 24–30 June 2017; pp. 7263–7271. [Google Scholar]
- Mundhenk, T.N.; Konjevod, G.; Sakla, W.A.; Boakye, K. A large contextual dataset for classification, detection and counting of cars with deep learning. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 785–800. [Google Scholar]
- Fahim, M.; Baker, T.; Khattak, A.M.; Shah, B.; Aleem, S.; Chow, F. Context mining of sedentary behaviour for promoting self-awareness using a smartphone. Sensors 2018, 18, 874. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hsieh, M.R.; Lin, Y.L.; Hsu, W.H. Drone-based object counting by spatially regularized regional proposal network. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4145–4153. [Google Scholar]
- Gao, G.; Liu, Q.; Wang, Y. Counting From Sky: A Large-Scale Data Set for Remote Sensing Object Counting and a Benchmark Method. IEEE Trans. Geosci. Remote Sens. 2020. [Google Scholar] [CrossRef]
- Wan, J.; Wang, Q.; Chan, A.B. Kernel-based Density Map Generation for Dense Object Counting. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 1. [Google Scholar] [CrossRef] [PubMed]
- Zhang, P.; Liu, W.; Lei, Y.; Lu, H.; Yang, X. Cascaded Context Pyramid for Full-Resolution 3D Semantic Scene Completion. arXiv 2019, arXiv:1908.00382. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 24–30 June 2017; pp. 2881–2890. [Google Scholar]
- Idrees, H.; Saleemi, I.; Seibert, C.; Shah, M. Multi-source multi-scale counting in extremely dense crowd images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2547–2554. [Google Scholar]
- Gao, J.; Lin, W.; Zhao, B.; Wang, D.; Gao, C.; Wen, J. C3 Framework: An Open-source PyTorch Code for Crowd Counting. arXiv 2019, arXiv:1907.02724. [Google Scholar]
- Wang, Q.; Gao, J.; Lin, W.; Yuan, Y. Pixel-Wise Crowd Understanding via Synthetic Data. Int. J. Comput. Vision 2021, 129, 225–245. [Google Scholar] [CrossRef]
- Ranjan, V.; Le, H.; Hoai, M. Iterative crowd counting. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 270–285. [Google Scholar]
- Jiang, X.; Xiao, Z.; Zhang, B.; Zhen, X.; Cao, X.; Doermann, D.; Shao, L. Crowd Counting and Density Estimation by Trellis Encoder-Decoder Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 6133–6142. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 24–30 June 2017; pp. 2261–2269. [Google Scholar]
- Sindagi, V.A.; Patel, V.M. Cnn-based cascaded multi-task learning of high-level prior and density estimation for crowd counting. In Proceedings of the 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017; pp. 1–6. [Google Scholar]
- Gao, J.; Wang, Q.; Yuan, Y. SCAR: Spatial-/channel-wise attention regression networks for crowd counting. Neurocomputing 2019, 363, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Zhu, L.; Zhao, Z.; Lu, C.; Lin, Y.; Peng, Y.; Yao, T. Dual path multi-scale fusion networks with attention for crowd counting. arXiv 2019, arXiv:1902.01115. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | SHA | UCF_CC_50 | UCF-QNRF | |||
|---|---|---|---|---|---|---|
| MAE | MSE | MAE | MSE | MAE | MSE | |
| Lempitsky et al. [56] | - | - | 493.4 | 487.1 | - | - |
| Zhang et al. [9,10] | 181.8 | 277.7 | 467.0 | 498.5 | - | - |
| Idrees et al. [17,91] | - | - | 419.5 | 541.6 | 315 | 508 |
| MCNN, [10,17] | 110.2 | 173.2 | 377.6 | 509.1 | 277 | - |
| Switching CNN, [17,38] | 90.4 | 135.0 | 318.1 | 439.2 | 228 | 445 |
| CL, [17] | - | - | - | - | 132 | 191 |
| CP-CNN, [39] | 73.6 | 106.4 | 298.8 | 320.9 | - | - |
| CSRNet(baseline), [8] | 68.2 | 115.0 | 266.1 | 397.5 | - | - |
| ic-CNN(one stage), [94] | 69.8 | 117.3 | - | - | - | - |
| ic-CNN(two stage), [94] | 68.5 | 116.2 | - | - | - | - |
| CFF, [70] | 65.2 | 109.4 | - | - | - | - |
| TEDNet, [95] | 64.2 | 109.1 | 249.4 | 354.5 | 113 | 188 |
| MSCANet (Ours) | 66.5 | 102.1 | 242.8 | 329.8 | 104.1 | 183.8 |
| Method | Av. Precision | Av. Recall | F1-Measure |
|---|---|---|---|
| MCNN [10] | 59.93% | 63.50% | 61.66% |
| DenseNet63 [96] | 70.19% | 58.10% | 63.87% |
| CL [17] | 75.80% | 59.75% | 66.82% |
| SCLNet [74] | 83.99% | 57.62% | 67.36% |
| MSCANet (Ours) | 83.65% | 61.07% | 69.64% |
| Method | Building | Small Vehicle | Large Vehicle | Ship | ||||
|---|---|---|---|---|---|---|---|---|
| MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | |
| MCNN [10,17] | 13.65 | 16.56 | 488.65 | 1317.44 | 36.56 | 55.55 | 263.91 | 412.30 |
| CMTL [97] | 12.78 | 15.99 | 490.53 | 1321.11 | 61.02 | 78.25 | 251.17 | 403.07 |
| CSRNet [8] | 8.00 | 11.78 | 443.72 | 1252.22 | 34.10 | 46.42 | 240.01 | 394.81 |
| SANet [34] | 29.01 | 32.96 | 497.22 | 1276.66 | 62.78 | 79.65 | 302.37 | 436.91 |
| SFCN [93] | 8.94 | 12.87 | 440.70 | 1248.27 | 33.93 | 49.74 | 240.16 | 394.81 |
| SPN [16] | 7.74 | 11.48 | 445.16 | 1252.92 | 36.21 | 50.65 | 241.43 | 392.88 |
| SCAR [98] | 26.90 | 31.35 | 497.22 | 1276.65 | 62.78 | 79.64 | 302.37 | 436.92 |
| CAN [15] | 9.12 | 13.38 | 457.36 | 1260.39 | 34.56 | 49.63 | 282.69 | 423.44 |
| SFANet [99] | 8.18 | 11.75 | 435.29 | 1284.15 | 29.04 | 47.01 | 201.61 | 332.87 |
| ASPDNet [86] | 7.59 | 10.66 | 433.23 | 1238.61 | 18.76 | 31.06 | 193.83 | 318.95 |
| MSCANet (Ours) | 11.13 | 16.02 | 221.16 | 430.90 | 60.92 | 78.20 | 41.93 | 60.73 |
| PS | MAE | MSE |
|---|---|---|
| {1} | 110.9 | 197.2 |
| {1,2} | 105.2 | 184.6 |
| {1,2,3} | 104.1 | 183.8 |
| {1,2,3,4} | 104.8 | 186.1 |
| Configuration | MAE | MSE |
|---|---|---|
| Decoder (baseline) | 111.3 | 182.0 |
| MSCA w/o CA | 105.7 | 186.9 |
| MSCA | 104.1 | 183.8 |
| CSRNet (our reimplementation) | 118.8 | 204.4 |
| CAN [15] | 107.0 | 183.0 |
| CCPM | 111.9 | 182.3 |
| SPM | 108.1 | 187.2 |
| SACM | 116.2 | 211.2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Zhao, H.; Duan, Z.; Huang, L.; Deng, J.; Zhang, Q. Congested Crowd Counting via Adaptive Multi-Scale Context Learning. Sensors 2021, 21, 3777. https://doi.org/10.3390/s21113777
Zhang Y, Zhao H, Duan Z, Huang L, Deng J, Zhang Q. Congested Crowd Counting via Adaptive Multi-Scale Context Learning. Sensors. 2021; 21(11):3777. https://doi.org/10.3390/s21113777
Chicago/Turabian StyleZhang, Yani, Huailin Zhao, Zuodong Duan, Liangjun Huang, Jiahao Deng, and Qing Zhang. 2021. "Congested Crowd Counting via Adaptive Multi-Scale Context Learning" Sensors 21, no. 11: 3777. https://doi.org/10.3390/s21113777