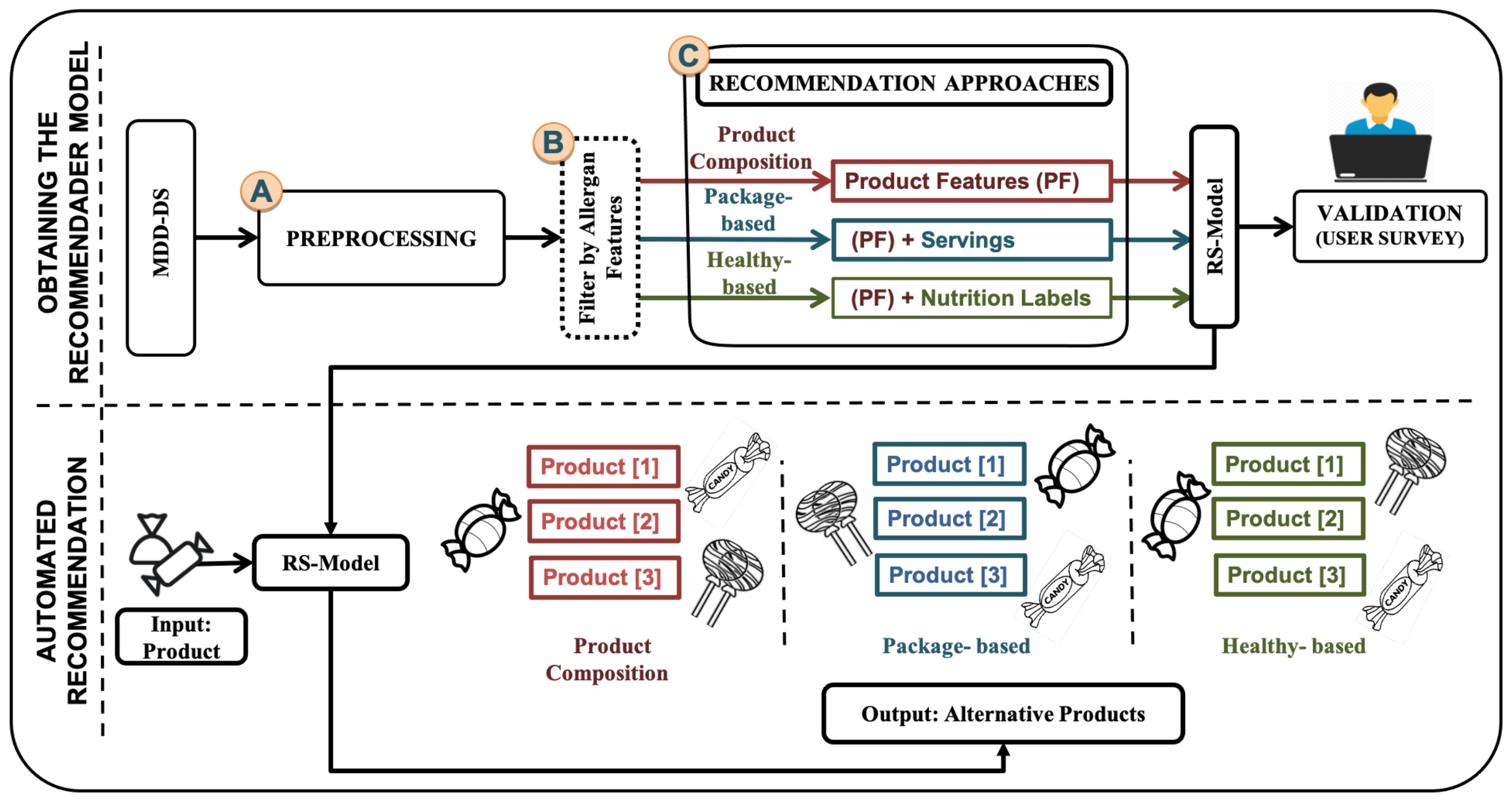
It begins with PRO-COM and PK-BD approach to performing preprocessing and building the product matrix. The algorithm in both approaches will be explained similarly, with the added feature of the PK-BD approach.
5.1. Preprocessing
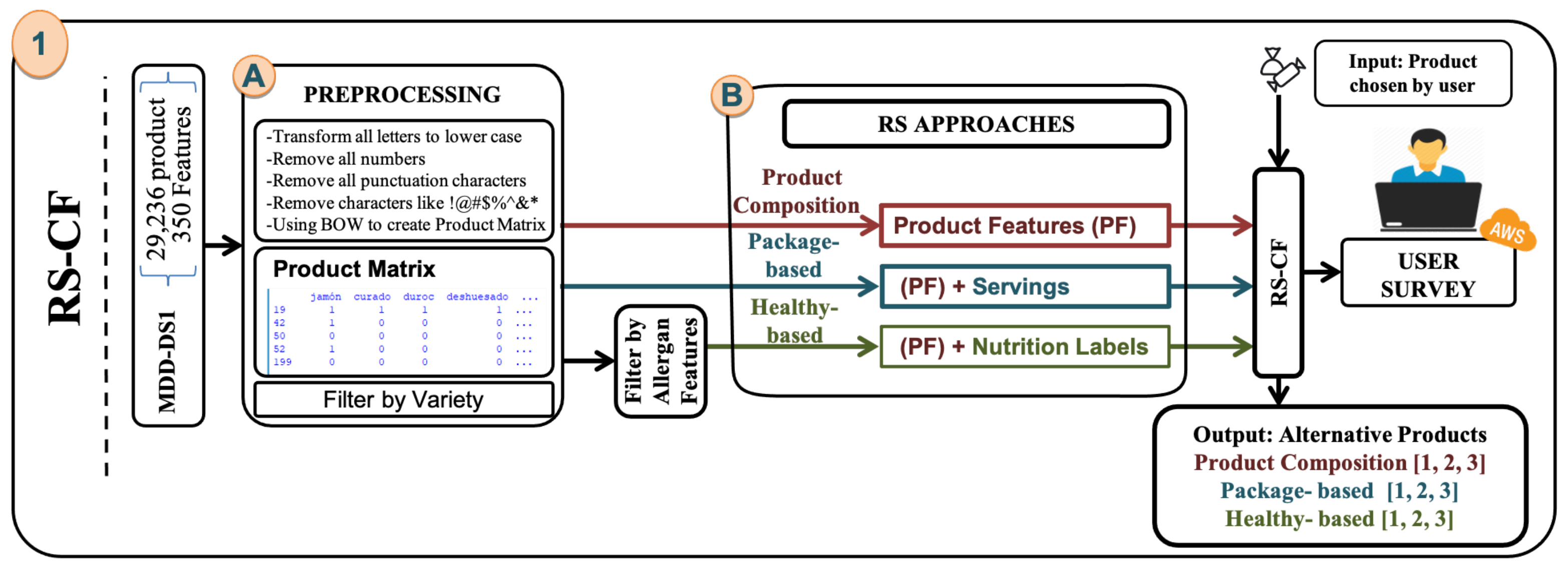
The PRO-COM and PK-BD approaches are the first two RS-CF approaches that use the first data release (MDD-DS1). MDD-DS1 comprises 29,236 products, so the data was processed and cleaned by removing the empty rows from the variable
name and
serving as well. The EAN column is then scanned for duplicates and removed. Next, we ignore that the variety contains fewer than four products; this number is required to implement the algorithm; the main focus of this investigation is when the primary product is not found. Therefore, keep at least three alternatives of the same variety. Therefore, the number of products after cleaning the data is 20,371, we mentioned the last steps in Algorithm 1 as a
(MDD-DS1) step. The data is then preprocessed by extracting all the words for the attributes
name,
legal name, and
ingredients. Consider a Corpus
C of each product
p,
C(
p[Name],
p[Legal Name],
p[Ingredients]). That means that the three attributes are combined in a single text to describe the product
. This description was obtained (
) after cleaning the product
by following these steps: (i) transform the parentheses into space; (ii) the numbers, stopwords, punctuation, and extra spaces are removed; (iii) all letters are converted to lowercase; and (iv) duplicate strings are removed. Algorithm 1 shows all the preprocessing steps for PRO-COM and PK-BD.
| Algorithm 1 RS-CF: PRO-COM and PK-BD preprocessing pseudocode. |
- 1:
procedurePreprocess(MDD-DS1) - 2:
(MDD-DS1) - 3:
new_list(m) - 4:
new_vector (0) - 5:
for i ← 1: m do - 6:
MDD-DS1 - 7:
← C(p[Name], p[Legal Name], p[Ingredients]) - 8:
← () - 9:
← - 10:
- 11:
←∪ - 12:
end for - 13:
end procedure
|
Thus, the words are divided and a vector of words is created for
, an example is shown in
Table 5.
We obtain
unique tokens/words extracted from the corpus
C(
p[Name],
p[Legal Name],
p[Ingredients]), which is the different meaningful tokens in the dataset after preprocessing. Therefore,
contains 10,707 unique tokens, an example (We have translated
and
to make it readable) shows in the
Table 6. Let
be the
n-dimensional vector obtained from
such that
and
is a string ∈
and
. The
N tokens will form
and the count vector size in product matrix
X will be given by
.
The product matrix
is a
matrix, where each row
M represents a product
p of the MDD-DS1 so that
M is the total number of products; and each column
N represents a token
. The next step is to use BOW to rate the words on each product. The goal is to convert each free text product into a vector that we can use as an RS model input. Since we know that the vocabulary in
contains 10,707 words, we can use a fixed-length document-representation of 10,707, with a position in the vector to score each word. The simplest scoring method is to mark the presence of words as a boolean value, 0 for absent, 1 for present. Using the arbitrary order of
listed above in our vocabulary
, we can loop through the products and convert them to a binary vector, as shown in
Table 7.
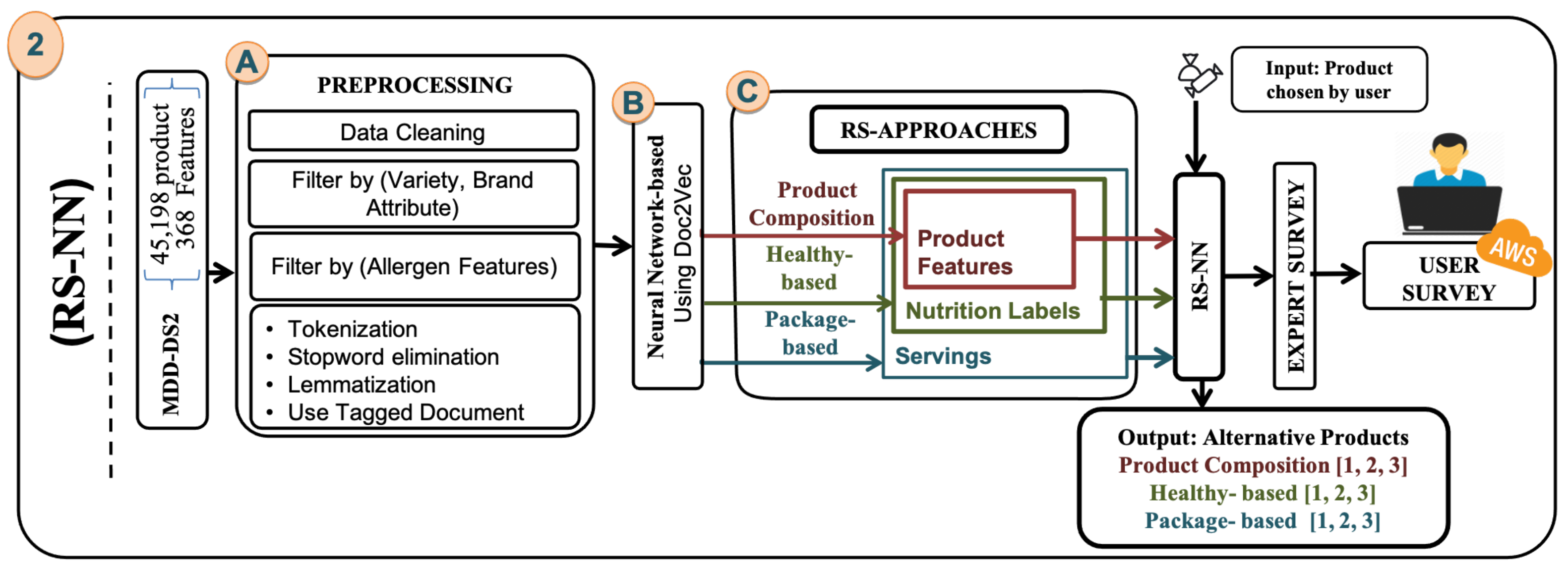
5.4. RS-CF: Health-Based Approach
The health-based approach (HTH-BD) is the tricky one to consider, recommending health products to the user based on their choices. The most common nutritional table properties
fats,
sugar are used to help recommend healthy products. The cleanliness of the data mentioned in
Section 5.1 is used in addition to replacing the
serving with the additional properties, which are
fats,
sugars, so that the rows with blank values for the name of the product, sugar and fat are eliminated, so that the sugar values in the remaining products range between 1 and 1087 g, and the fat values in the remaining products also range between 1 and 937 g. Additionally, 13 additional columns named
Messages that provide allergen information are being considered. The number of products becomes 20,259 products and 24 features after cleaning the data.
About the
Messages columns, after analyzing all the tags indicating the absence of allergens 50 different strings are obtained in the form
Table 10 and stored in a vector named
. Here, taking into account the law of the European Union (BOE, Regulation (EU) n. 1169/2011 of the European Parliament and of the Council) on the labeling of food products that obliges companies to report certain allergens that may endanger the health of the customer, sensitivity will be taken into account.
A law with similar objectives was previously approved in Spain in 2004 and amended in 2008 (BOE, Royal Decree 1245/2008, of 18 July, which modifies the General Regulations for Labeling, Presentation and Advertising of Food Products, Approved by Royal Decree 1334/1999 of 31 July). Of the 50 different strings obtained previously, 17 are relevant in terms of allergies, as can be seen in
Table 11. After performing the necessary analysis and clarification, the information obtained from MDD-DS1 is useful for developing the RS-CF HTH-BD algorithm.
Aside from the data obtained from the Ingredients variable, the Messages columns associated with the respective product are also obtained for each iteration. Here, for each product, the 13 Messages columns are handled in the following way: (1) 13 columns for the current product in the iteration are obtained, with the blank columns removed; (2) To remove additional information unrelated to the allergen, values are also removed from columns that do not begin with the string “without”; (3) The duplicate strings obtained are removed, strings are converted to lowercase; (4) The strings are divided by a point followed by a space, substrings preceded by a comma are removed; (5) Some incorrect parsed characters (overridden characters such as ∖r and ∖n backslashes) are removed, as well as some strings with errors and full stops are removed. The word vector is constructed with the resulting string.
As in the PRO-COM and PK-BD approaches, the
list is generated with the difference that here just the
Ingredients column is considered. This is, it contains a number of elements equal to the number of different products existing in the MDD-DS1 (in the HTH-BD approach, the MDD-DS1 has 20,259 elements). The vector of words belonging to each product obtained in the text string processing is stored in each element of the list after using the steps of
. The list is shown in
Table 12.
In addition, a list called
withoutlist, which stores the vector with the healthy features obtained from the
Messages columns for each product, is created. The vector
withoutwords stores the different healthy features once, having 50 elements. The list and the vector are shown in
Table 13 and
Table 14, respectively. The entire preprocessing is shown in Algorithm 2. It is relevant to know that a subset comprising 17 elements of the
withoutwords vector is considered in order to check for allergens in a product, whose data about it can be accessed by indexing the
withoutlist with the index of the product in the MDD-DS1.
| Algorithm 2 RS-CF: HTH-BD: Preprocessing pseudocode. |
- 1:
procedurePreprocess(MDD-DS1) - 2:
(MDD-DS1) - 3:
new_list(m) - 4:
new_list(m) - 5:
new_vector (0) - 6:
for i ← 1: m do - 7:
MDD-DS1 - 8:
← (p[Ingredients])▹ Just the Ingredientes column is taken into account - 9:
p - 10:
← () - 11:
- 12:
MDD-DS1▹ The information contained in the 13 Messages columns is loaded - 13:
remove_empty_strings(m) - 14:
m[which(m.startsWith(“without ”)]▹Just the values in the m vector which start with the string “without ” are loaded - 15:
remove_duplicates(m) - 16:
transform_into_lowercase(m) - 17:
split(m,“[.] ”)▹ The strings are splitted by a dot followed by a space - 18:
split(m,“[,].*”)▹ The strings are splitted by a comma, removing what is after it - 19:
remove_malformed_strings(m) - 20:
remove_full_stops(m) - 21:
∪m - 22:
m - 23:
end for - 24:
end procedure
|
After processing the data to be valid for building the health-based approach, let be the withoutwords vector (50 elements). Then, . Let be the subset of the withoutwords vector considering allergens (17 elements). Hence, . Let be a the m-dimensional wordvectors list. Each element contains a vector . Hence . Likewise, where is the length of the vector contained in the i element of the list . Note that is a string. Let be a -dimensional subset of the Z elements of the m-dimensional wordvectors list. Each element contains a vector . Hence and . Likewise, where is the length of the vector contained in the i element of the list . Note that is a string. Let be a -dimensional vector. Here, where . Each element denotes the processing level of a product.
Let be the m-dimensional withoutlist list. Each element contains a vector . Hence . Likewise, where is the length of the vector contained in the i element of the list . Note that is a string. Let be a -dimensional subset of the Z elements of the m-dimensional withoutlist list. Each element contains a vector . Hence and . Likewise, where is the length of the vector contained in the i element of the list . Note that is a string. Let be a -dimensional vector. Here, where . Each element denotes the number of healthy features of a product.
Let
be a
-dimensional vector. Here,
where
. It stores the fat and sugar features about the products. Here,
and
denote, respectively, the fat and sugar quantities in grams of the product
. Let
. This denotes the following similarity measure (taking into account allergens) of the product
with respect to the product
as shown in Equation (
5).
∈
/
=
.
The product
being unavailable, the alternative product
is obtained by the following the next steps: (1) The first criterion is to consider the similarity about allergens. Thus, the alternative product
is selected according to that measure:
If there is more than one
value, a
-dimensional vector
is created being
the number of alternatives. (2) Secondly, the sum of the sugar and fat quantities are considered to select the alternative product
among the ones in vector
:
If there is more than one
value, a
-dimensional vector
is created being
the number of alternatives. (3) The next criterion to get the alternative product
(among the ones in vector
) is the number of healthy features:
If there is more than one
value, a
-dimensional vector
is created being
the number of alternatives. (4) The last step to get the alternative product
involves the level of processing of the products selecting from the vector
:
If there is more than one value, a -dimensional vector is created being the number of alternatives.
In conclusion, Algorithm 3 compares first each
product in the variety
Z to the product
p with regards to the similar features about allergens. Similar products are then ranked considering these features in order: the sum of the fat and sugar amounts (in increasing order), the number of healthy features (in decreasing order) and the processing level (in increasing order). An example of a matrix with vectors defining each of the criterions as columns is shown in
Table 15.
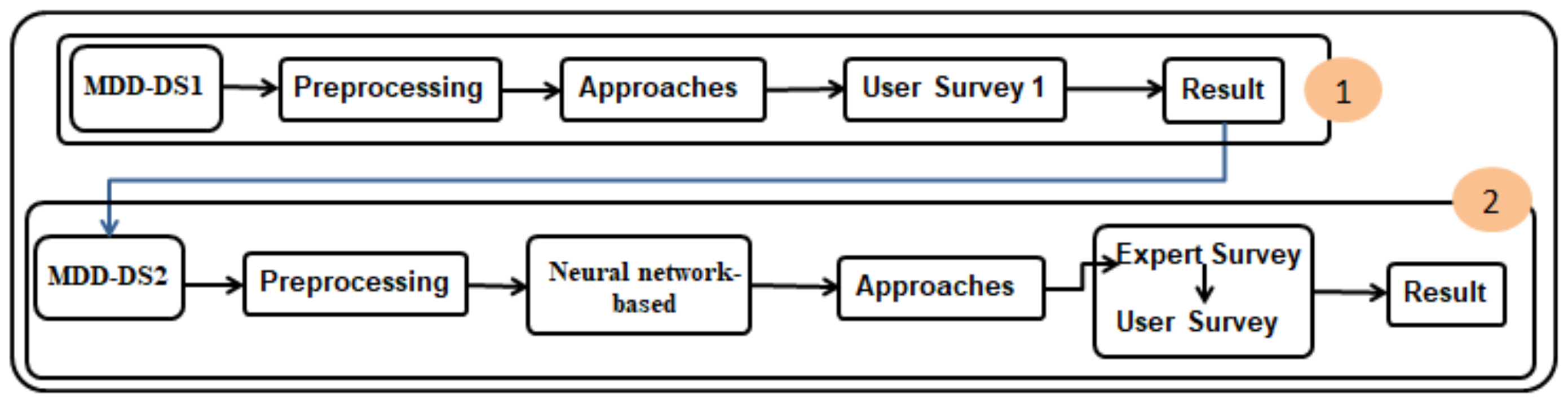
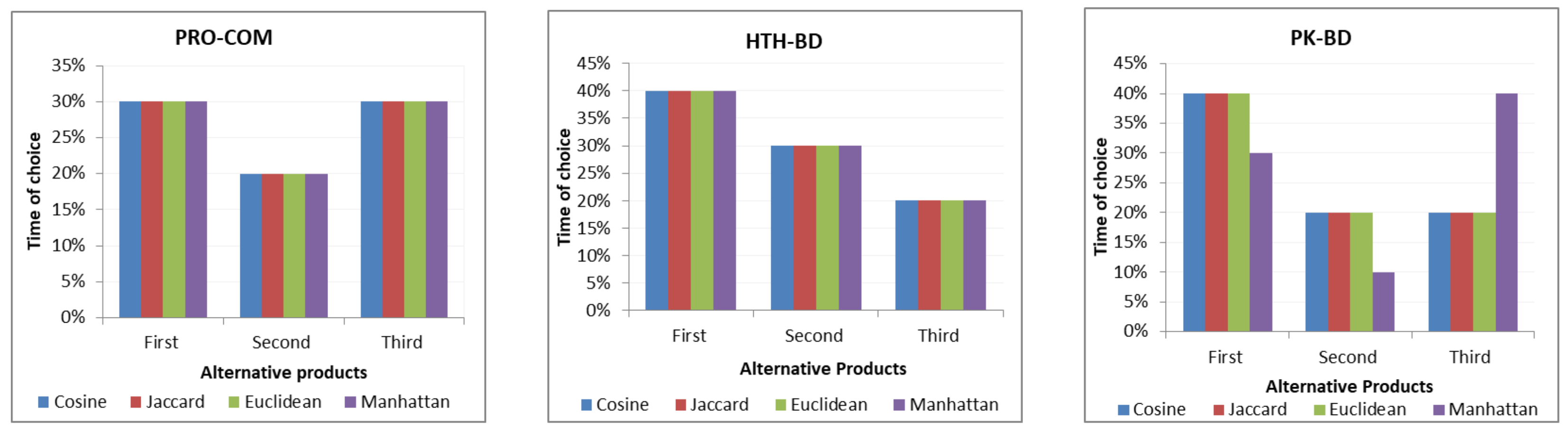
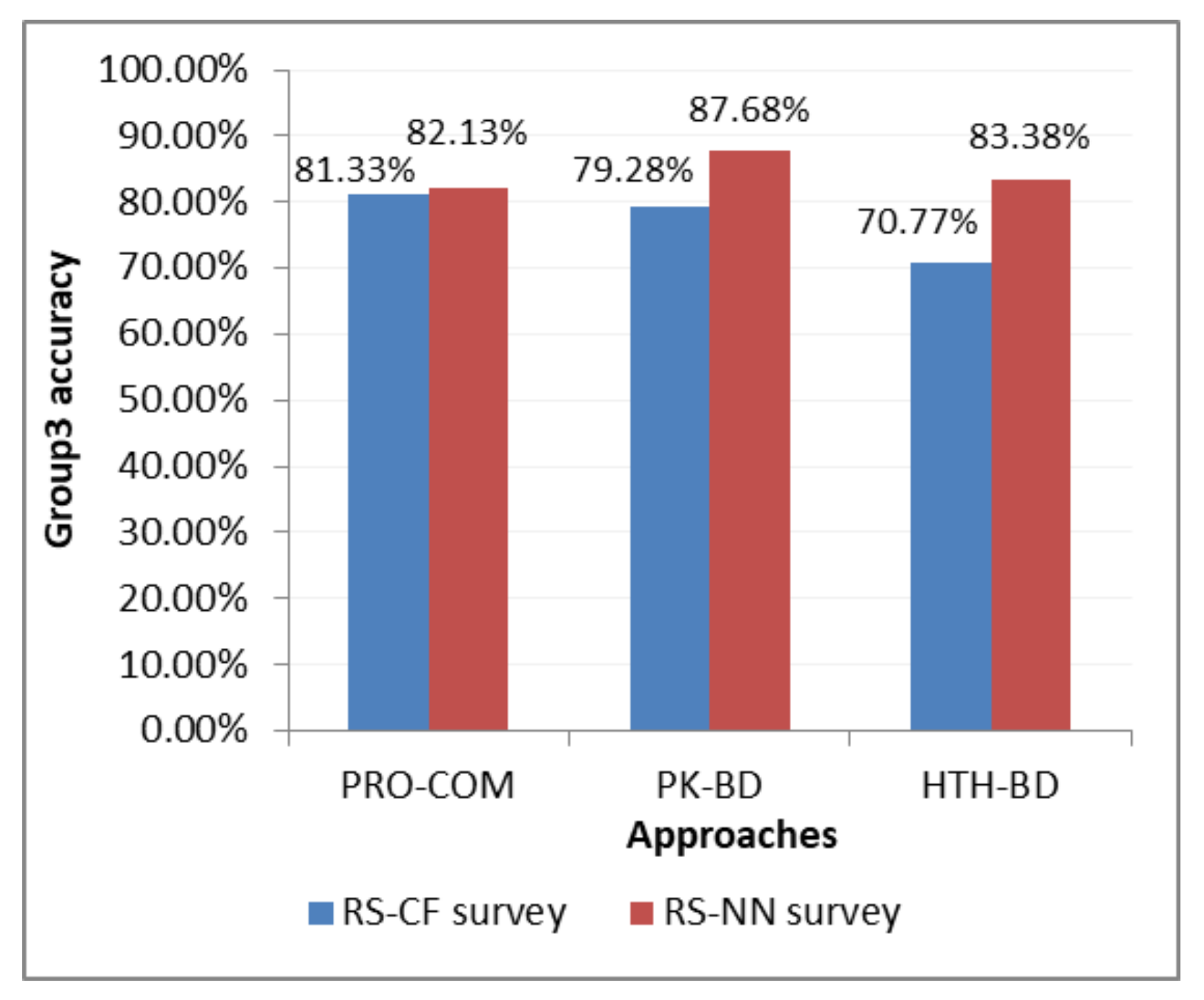
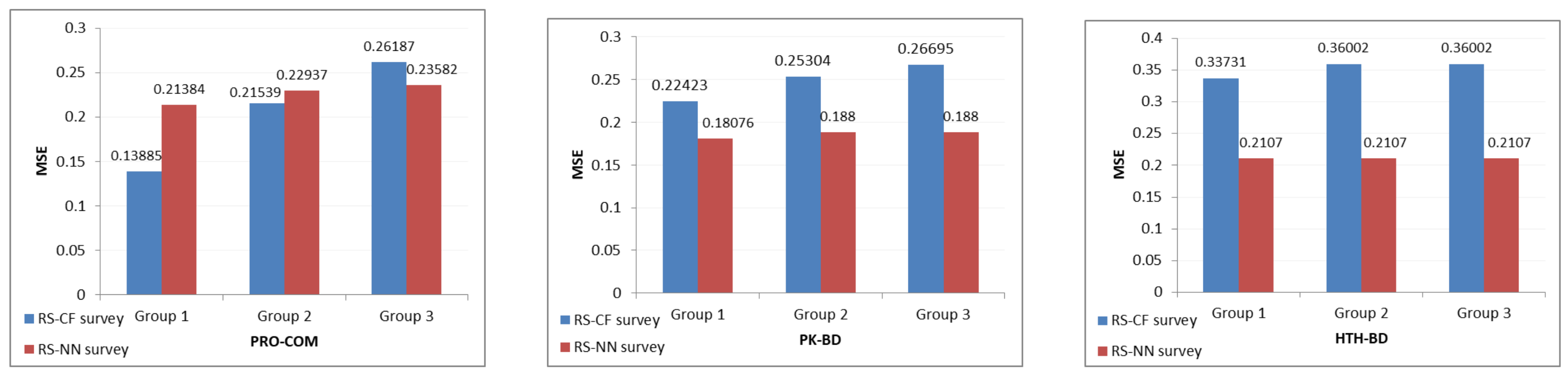
After building the three approaches, a user survey was conducted. Products and alternatives were presented according to each approach. Subsequently, the analyses of the results were compiled. We developed the approach to improve the results and meet the company’s requirements.
| Algorithm 3 HTH-BD approach of RS-CF: Algorithm pseudocode. |
- 1:
procedureAlgorithm(p, , , , ) ▹p is the index of the unavailable product - 2:
for do - 3:
if then - 4:
continue - 5:
end if - 6:
which(a∈) - 7:
if ∀, then - 8:
- 9:
else - 10:
- 11:
end if - 12:
- 13:
- 14:
end for - 15:
sort(-, , -, ) ▹ The products are sorted. The minus sign means the order is decreasing. - 16:
end procedure
|


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}