
Diabetic Retinopathy Fundus Image Classification and Lesions Localization System Using Deep Learning



Abstract
:1. Introduction
2. Related Works
2.1. Binary Classification
2.2. Multi-Level Classification
2.3. Hybrid Classification
3. Materials and Methods
3.1. Datasets
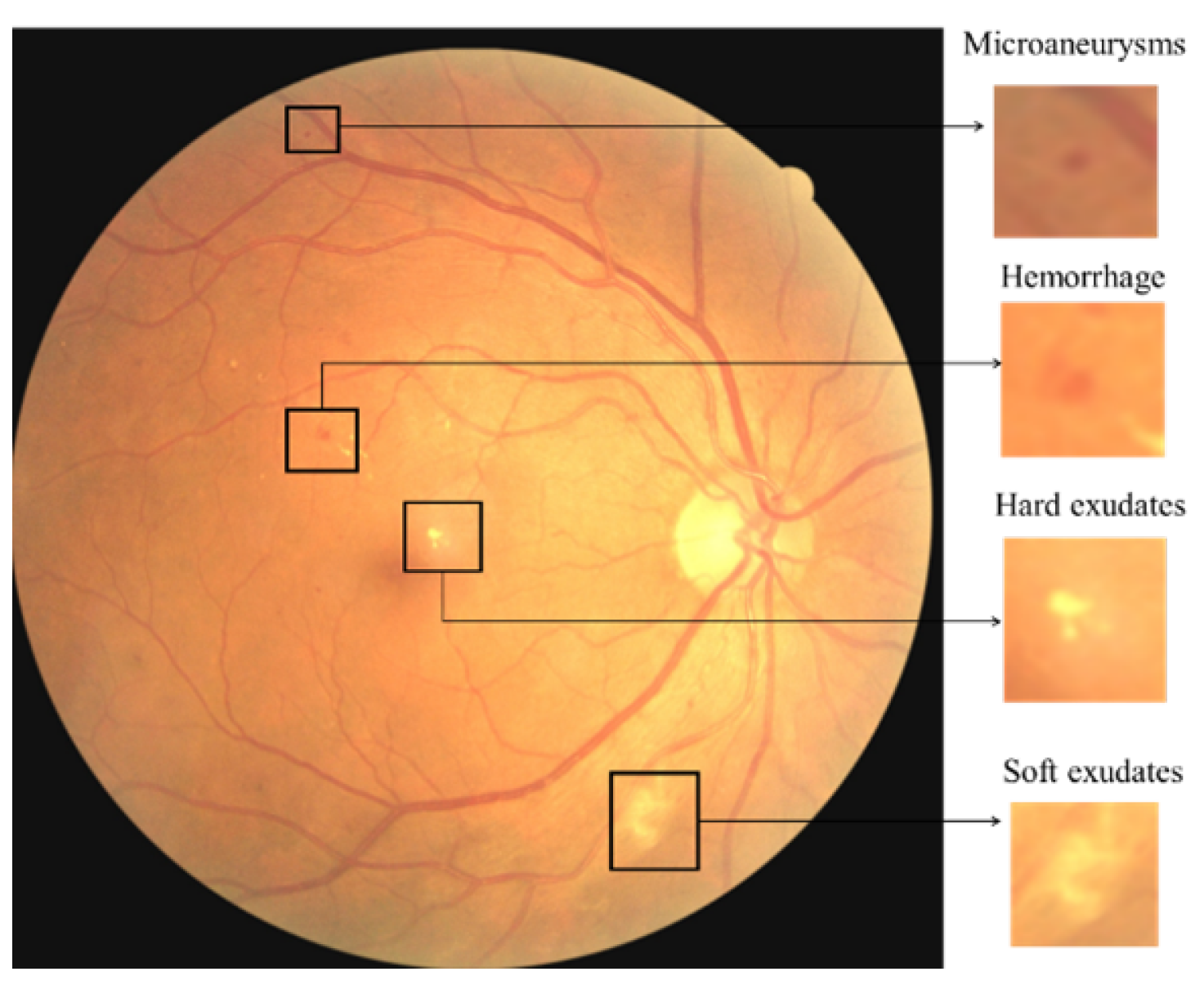
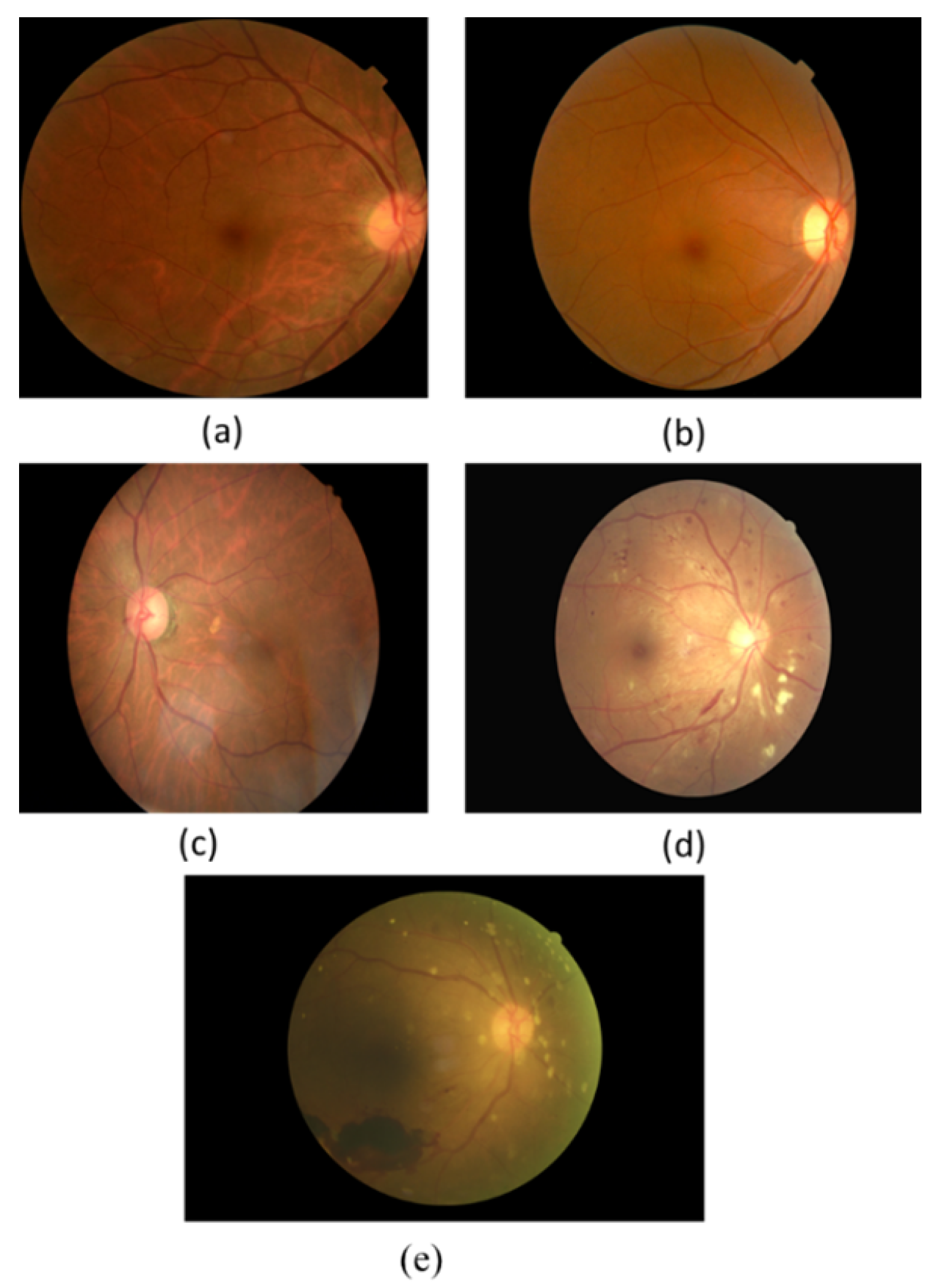
- The DDR dataset [37] consists of 13673 fundus images acquired at a 45 field of view (FOV). Among these, there are 1151 ungradable images, 6266 normal images, and 6256 DR images. There are 757 images annotated by providing a bounding box for lesions (MA, HM, hard EX, and soft EX) to locate all DR lesion types. The dataset has different image sizes, classified to five DR stages and split into train, valid, and test images. The distribution of the dataset is imbalanced in that the normal images are more than the DR images. The annotated lesions distribution is shown in Table 4.
- The APTOS 2019 Kaggle dataset [46] consists of 3662 retina images with different image sizes. Only the ground truths of the training images are publicly available. The dataset is classified into five DR stages. In addition, 1805 of the images are normal and 1857 are DR images. The distribution of the dataset is imbalanced, with most of the images normal.
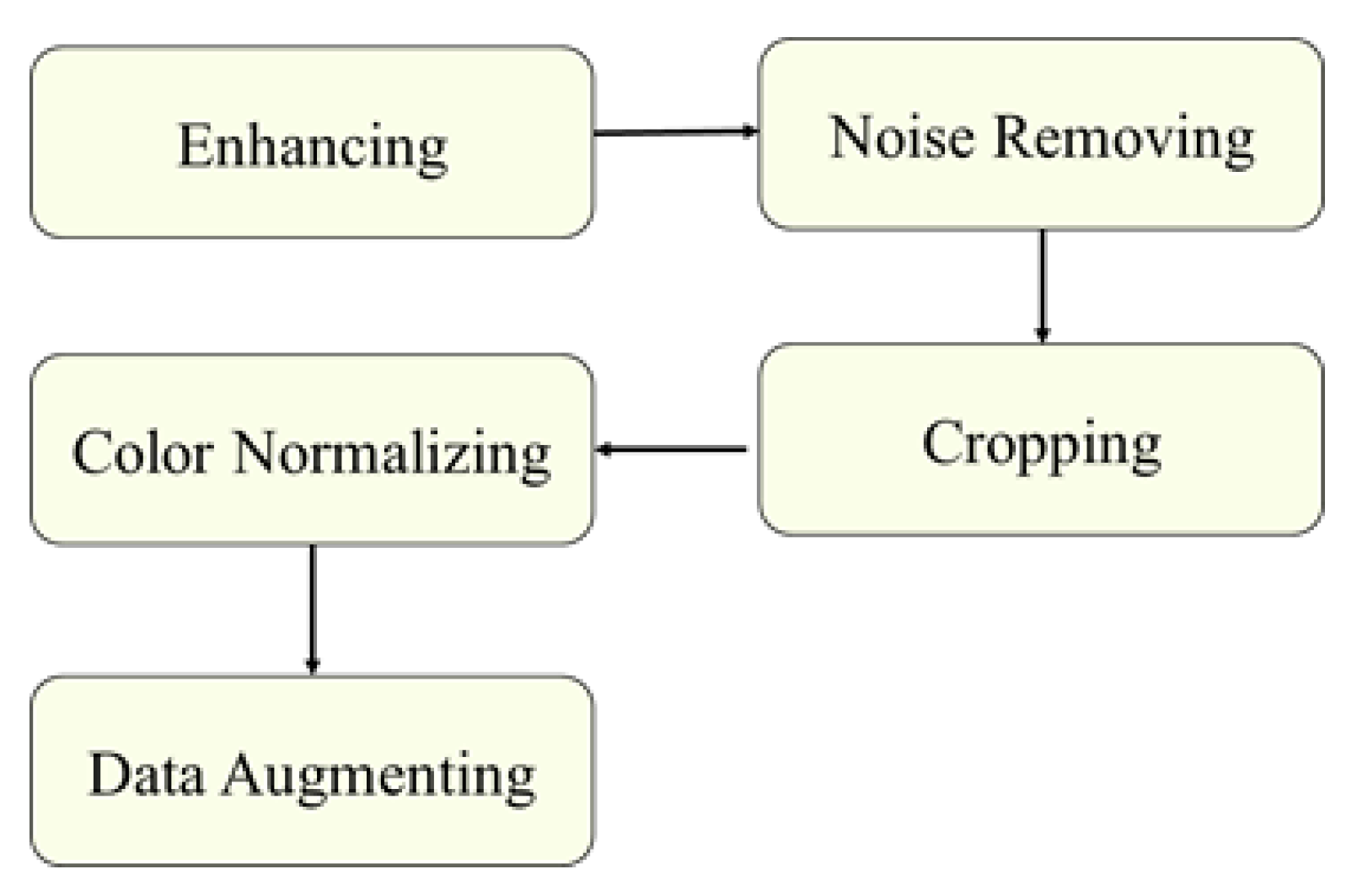
3.2. Preprocessing
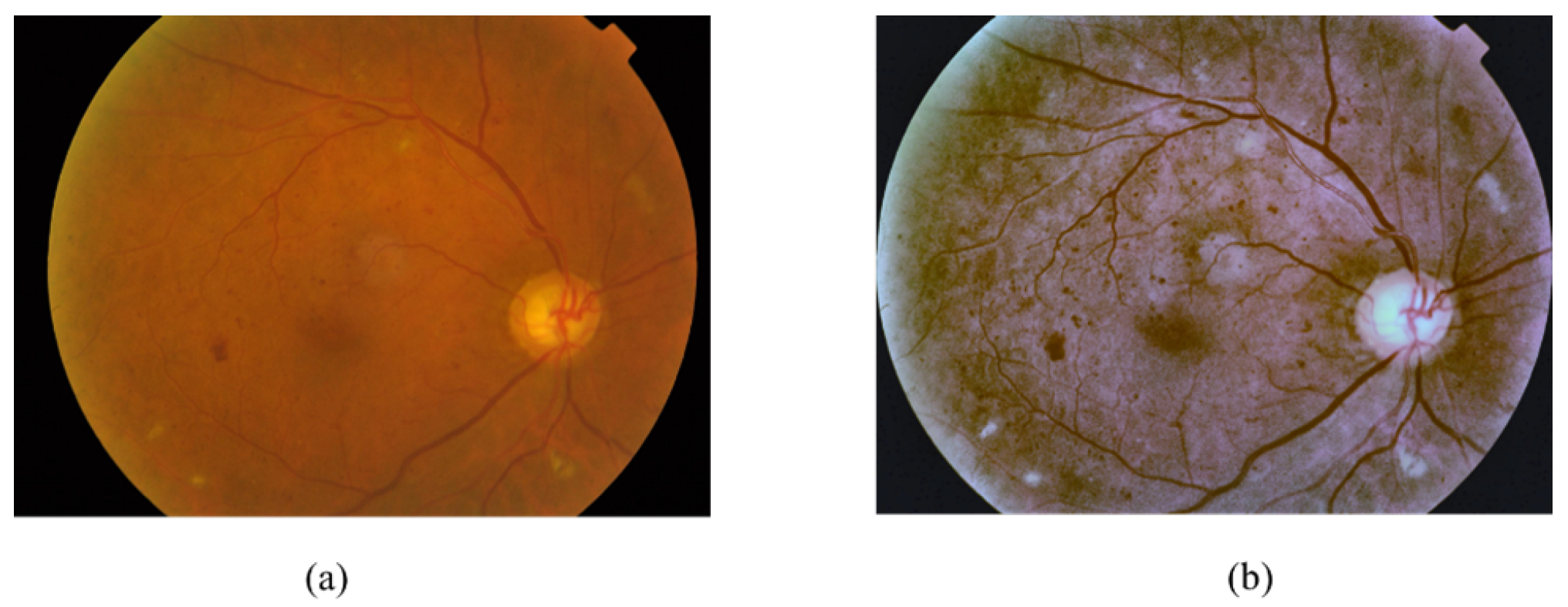
- Image Enhancement: Two methods were used to enhance the images, the enhance luminosity method [54] and Contrast Limited Adaptive Histogram Equalization (CLAHE). CLAHE [55] is successful in enhancing the contrast of the fundus images [56] and improving the low contrast of medical images [57]. CLAHE is applied to the L channel of the retina images that have a higher contrast [44], with tile size 8 × 8 and Clip Limit 5.0.
- Image Cropping: The images were cropped to eliminate the unnecessary black pixels around the retina. Thus, the bounding box lesion positions in the annotation files were changed. To fix that, we automated changing the bounding box position of each image based on the number of removed pixels around the retina.
- Colour Normalisation: The retina images were captured from patients of different age, and various ethnicity [58], at different levels of lighting in the fundus image. These conditions have an effect on the value of pixel intensity of each image and create unnecessary variation in the image [58]. To overcome this, the retina images were normalised by normalising each channel of RGB images. For the normalization, we subtract the mean, and after that, divide the variance of the images [25], as shown in Equation (2).where x is training RGB retina images, u is the mean of the RGB retina training images and s is the standard deviation of the training RGB retina images.
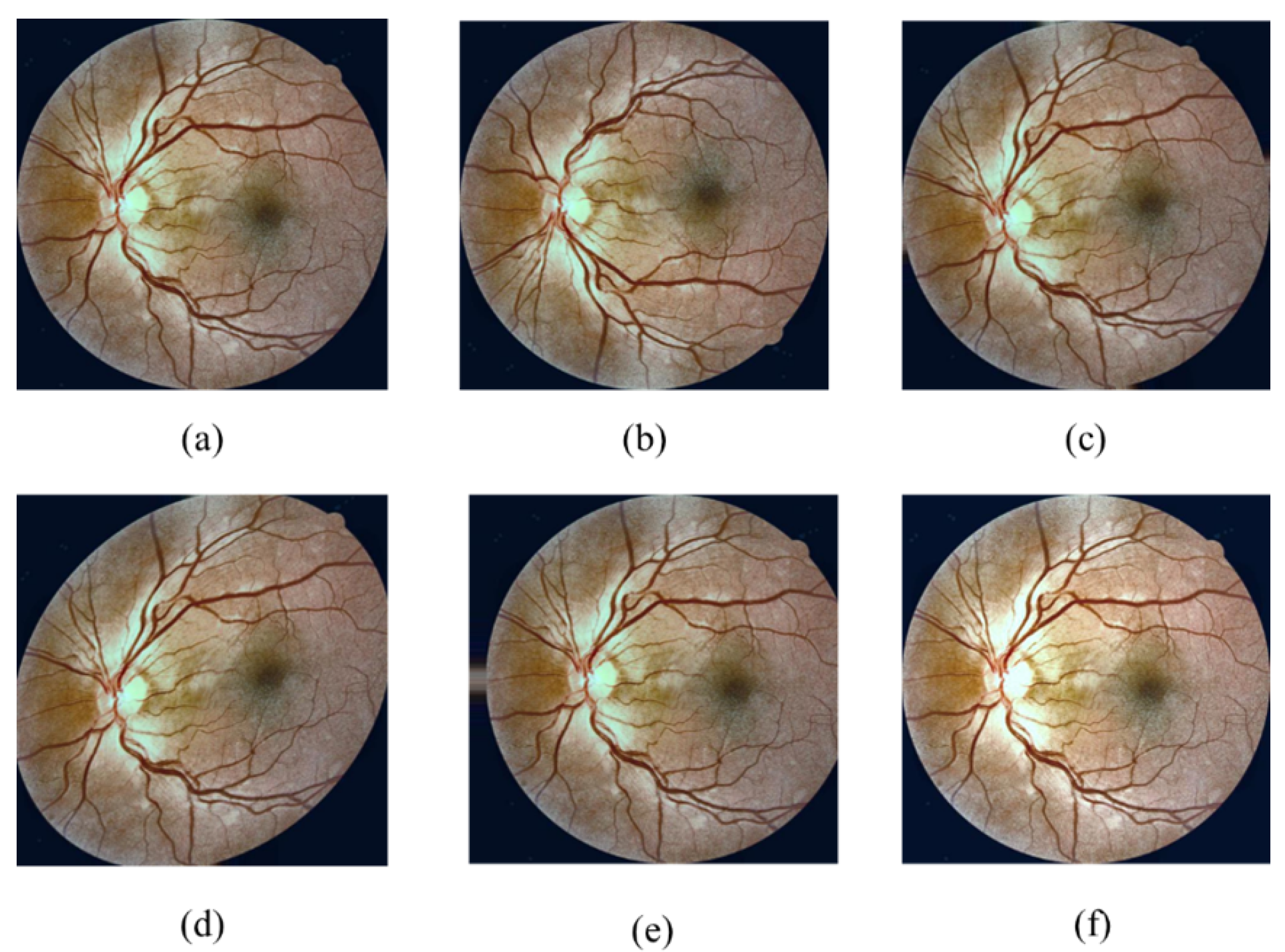
- Online data augmentation was adopted to enlarge the training dataset and to improve the generalisation and performance of the CNN. The images were augmented by performing rotation, flipping, shearing, and translation, as well as randomly darkening and brightening them, as shown in Figure 8. The augmentation parameters are presented in Table 5. Finally, the images were resized into a fixed size that varied according to the CNN used.
- Extract Lesions Patches: Some preprocessing methods were applied for Lesion localization Method to extract the lesion patches from each image for the CNN training. First, we cropped the annotated bounding box of each lesion and then padded it by zero if its size was less than (65 × 65); otherwise, we resized the patch to (65 × 65) to standardise the size of the patches.
| Algorithm 1: Automate detecting and removing duplicate lesions. |
 |
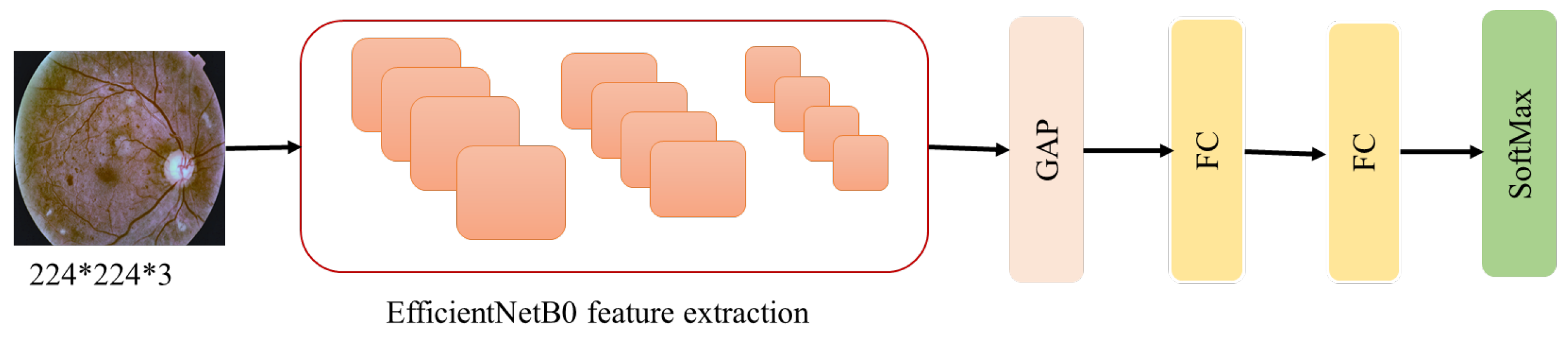
3.3. Image Based Method
3.3.1. Designed CNN Model
3.3.2. Using Transfer Learning
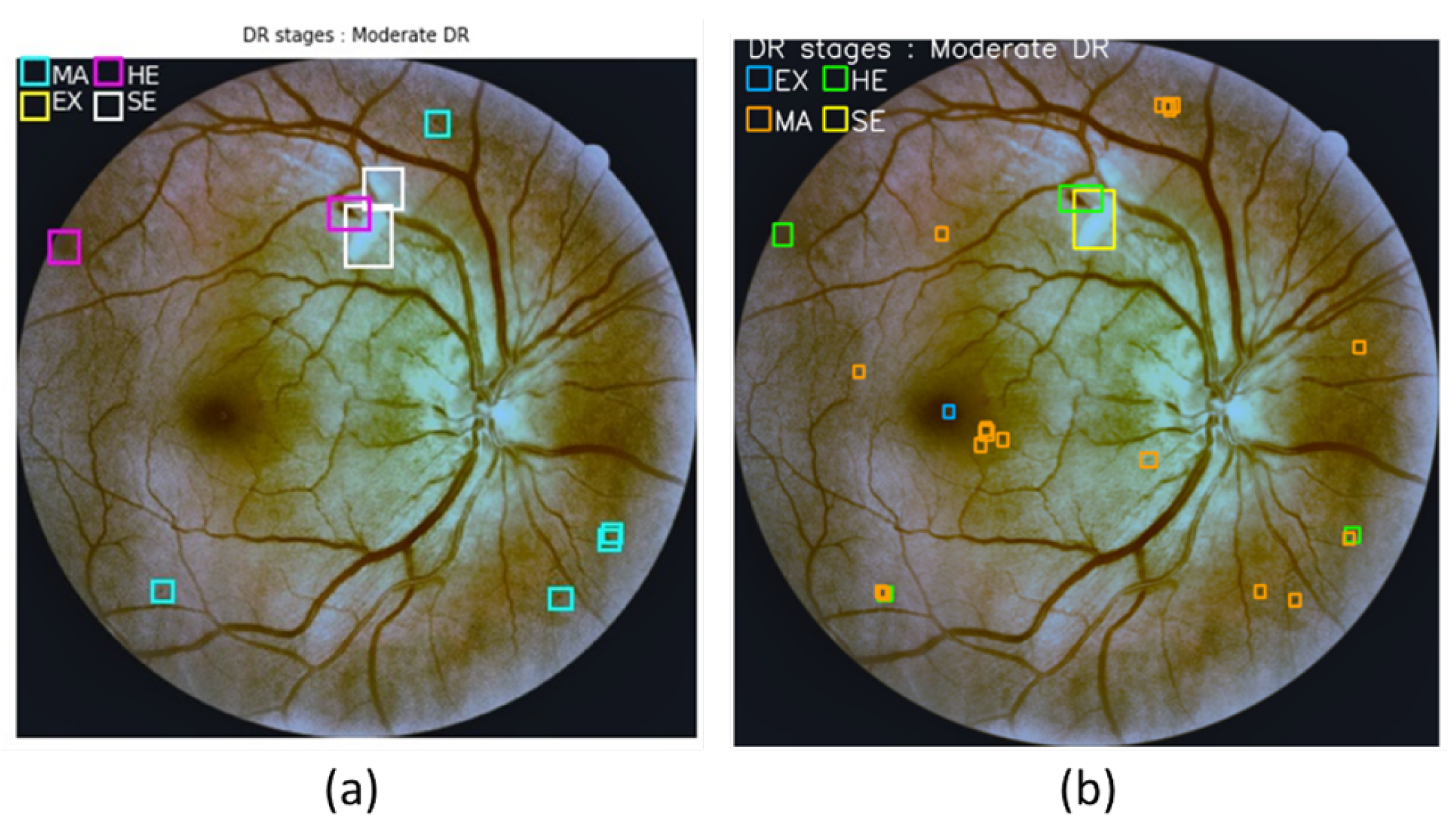
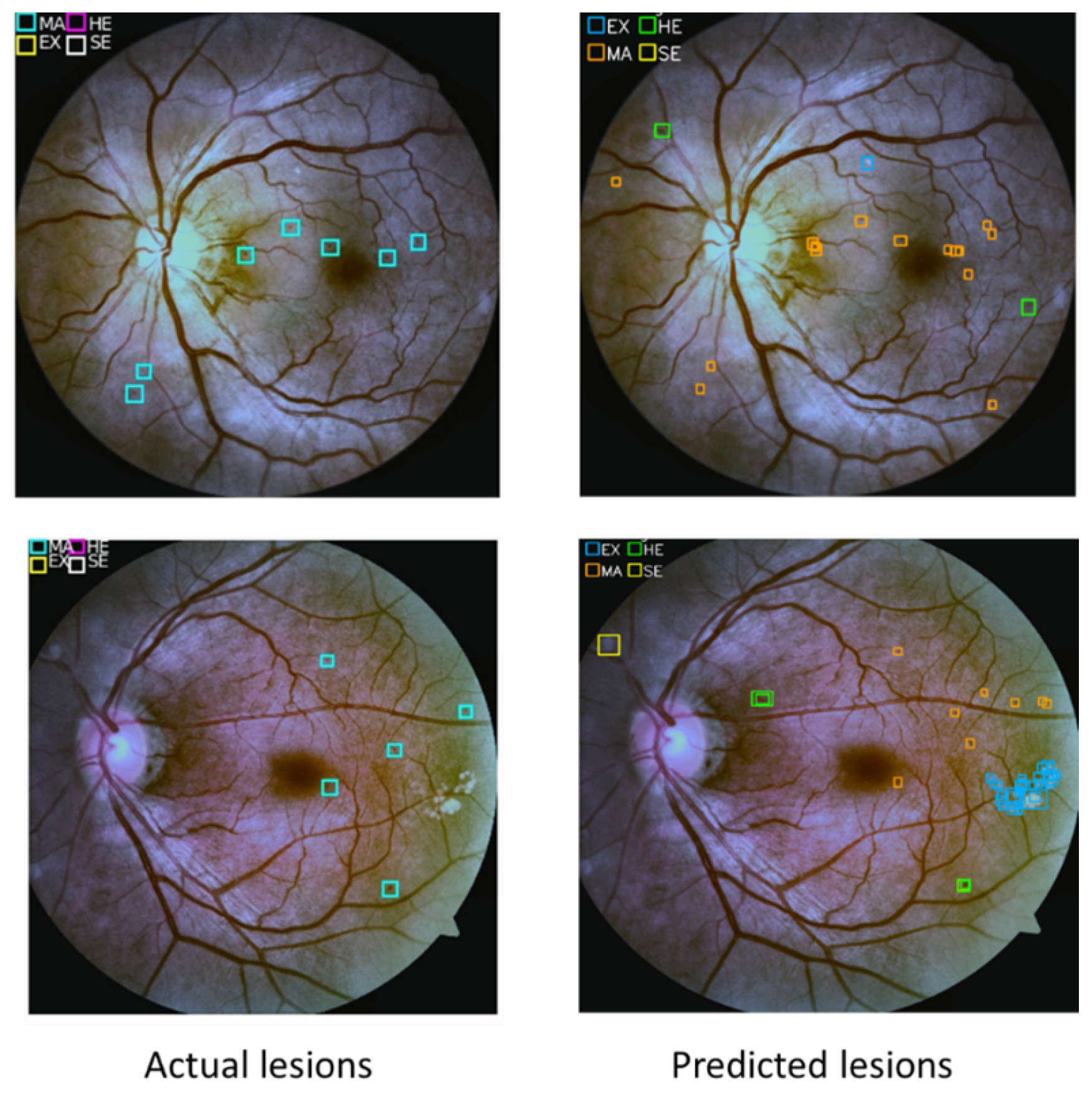
3.4. Lesion Localization Method
4. Experiments and Results
4.1. Configuration
4.2. Performance Metrics
4.3. Image Based Method Results
4.4. Lesion Localization Method Results
4.5. Comparison against State-of-the-Art Methods
4.6. Models Fusion
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- American Academy of Ophthalmology-What Is Diabetic Retinopathy. Available online: https://www.aao.org/eye-health/diseases/what-is-diabetic-retinopathy (accessed on 1 January 2019).
- Bourne, R.R.; Stevens, G.A.; White, R.A.; Smith, J.L.; Flaxman, S.R.; Price, H.; Jonas, J.B.; Keeffe, J.; Leasher, J.; Naidoo, K.; et al. Causes of vision loss worldwide, 1990-2010: A systematic analysis. Lancet Glob. Health 2013, 1, 339–349. [Google Scholar] [CrossRef] [Green Version]
- Taylor, R.; Batey, D. Handbook of Retinal Screening in Diabetes: Diagnosis and Management, 2nd ed.; John Wiley & Sons, Ltd., Wiley-Blackwell: Hoboken, NJ, USA, 2012; pp. 1–173. [Google Scholar] [CrossRef]
- Wilkinson, C.P.; Ferris, F.L.; Klein, R.E.; Lee, P.P.; Agardh, C.D.; Davis, M.; Dills, D.; Kampik, A.; Pararajasegaram, R.; Verdaguer, J.T.; et al. Proposed international clinical diabetic retinopathy and diabetic macular edema disease severity scales. Am. Acad. Ophthalmol. 2003, 110, 1677–1682. [Google Scholar] [CrossRef]
- Deng, L.; Yu, D. Deep learning: Methods and applications. Found. Trends Signal Process. 2014, 7, 197–387. [Google Scholar] [CrossRef] [Green Version]
- Vega, R.; Sanchez-Ante, G.; Falcon-Morales, L.E.; Sossa, H.; Guevara, E. Retinal vessel extraction using lattice neural networks with dendritic processing. Comput. Biol. Med. 2015, 58, 20–30. [Google Scholar] [CrossRef] [PubMed]
- Al Zaid, E.; Shalash, W.M.; Abulkhair, M.F. Retinal blood vessels segmentation using Gabor filters. In Proceedings of the 2018 1st International Conference on Computer Applications & Information Security (ICCAIS), Riyadh, Saudi Arabia, 4–6 April 2018; pp. 1–6. [Google Scholar]
- Sikder, N.; Masud, M.; Bairagi, A.K.; Arif, A.S.M.; Nahid, A.A.; Alhumyani, H.A. Severity Classification of Diabetic Retinopathy Using an Ensemble Learning Algorithm through Analyzing Retinal Images. Symmetry 2021, 13, 670. [Google Scholar] [CrossRef]
- Bakator, M.; Radosav, D. Deep learning and medical diagnosis: A review of literature. Multimodal Technol. Interact. 2018, 2, 47. [Google Scholar] [CrossRef] [Green Version]
- Litjens, G.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.A.; Ciompi, F.; Ghafoorian, M.; van der Laak, J.A.; van Ginneken, B.; Sánchez, C.I. A survey on deep learning in medical image analysis. Med. Image Anal. 2017, 42, 60–88. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lu, L.; Zheng, Y.; Carneiro, G.; Yang, L. Deep Learning and Convolutional Neural Networks for Medical Image Computing; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking model scaling for convolutional neural networks. In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, Beach, CA, USA, 10–15 June 2019; pp. 6105–6114. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Pal, P.; Kundu, S.; Dhara, A.K. Detection of red lesions in retinal fundus images using YOLO V3. Curr. Indian Eye Res. J. Ophthalmic Res. Group 2020, 7, 49. [Google Scholar]
- Pires, R.; Avila, S.; Wainer, J.; Valle, E.; Abramoff, M.D.; Rocha, A. A data-driven approach to referable diabetic retinopathy detection. Artif. Intell. Med. 2019, 96, 93–106. [Google Scholar] [CrossRef]
- Kaggle 2015 Dataset. Available online: https://kaggle.com/c/diabetic-retinopathy-detection (accessed on 1 April 2019).
- Decenciere, E.; Zhang, X.; Cazuguel, G.; Lay, B.; Cochener, B.; Trone, C.; Gain, P.; Ordonez, R.; Massin, P.; Erginay, A.; et al. Feedback on a publicly distributed image database: The messidor database. Image Anal. Stereol. 2014, 33, 231–234. [Google Scholar] [CrossRef] [Green Version]
- Jiang, H.; Yang, K.; Gao, M.; Zhang, D.; Ma, H.; Qian, W. An Interpretable Ensemble Deep Learning Model for Diabetic Retinopathy Disease Classification. In Proceedings of the 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Berlin, Germany, 23–27 July 2019; pp. 2045–2048. [Google Scholar] [CrossRef]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 4278–4284. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2818–2826. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.P.; Li, Z.; Xu, C.; Li, J.; Liang, R. Referable diabetic retinopathy identification from eye fundus images with weighted path for convolutional neural network. Artif. Intell. Med. 2019, 99, 101694. [Google Scholar] [CrossRef] [PubMed]
- Das, S.; Kharbanda, K.; Suchetha, M.; Raman, R.; Dhas, E. Deep learning architecture based on segmented fundus image features for classification of diabetic retinopathy. Biomed. Signal Process. Control 2021, 68, 102600. [Google Scholar] [CrossRef]
- Wang, X.; Lu, Y.; Wang, Y.; Chen, W.B. Diabetic retinopathy stage classification using convolutional neural networks. In Proceedings of the International Conference on Information Reuse and Integration for Data Science, Salt Lake City, UT, USA, 6–9 July 2018; pp. 465–471. [Google Scholar] [CrossRef]
- Wan, S.; Liang, Y.; Zhang, Y. Deep convolutional neural networks for diabetic retinopathy detection by image classification. Comput. Electr. Eng. 2018, 72, 274–282. [Google Scholar] [CrossRef]
- Mobeen-Ur-Rehman; Khan, S.H.; Abbas, Z.; Danish Rizvi, S.M. Classification of Diabetic Retinopathy Images Based on Customised CNN Architecture. In Proceedings of the 2019 Amity International Conference on Artificial Intelligence, AICAI 2019, Dubai, United Arab Emirates, 4–6 February 2019; pp. 244–248. [Google Scholar] [CrossRef]
- Zhang, W.; Zhong, J.; Yang, S.; Gao, Z.; Hu, J.; Chen, Y.; Yi, Z. Automated identification and grading system of diabetic retinopathy using deep neural networks. Knowl. Based Syst. 2019, 175, 12–25. [Google Scholar] [CrossRef]
- Harangi, B.; Toth, J.; Baran, A.; Hajdu, A. Automatic screening of fundus images using a combination of convolutional neural network and hand-crafted features. In Proceedings of the 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Berlin, Germany, 23–27 July 2019; pp. 2699–2702. [Google Scholar] [CrossRef]
- Shanthi, T.; Sabeenian, R.S. Modified Alexnet architecture for classification of diabetic retinopathy images. Comput. Electr. Eng. 2019, 76, 56–64. [Google Scholar] [CrossRef]
- Li, X.; Hu, X.; Yu, L.; Zhu, L.; Fu, C.W.; Heng, P.A. CANet: Cross-disease Attention Network for Joint Diabetic Retinopathy and Diabetic Macular Edema Grading. IEEE Trans. Med Imaging 2020, 39, 1483–1493. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dekhil, O.; Naglah, A.; Shaban, M.; Ghazal, M.; Taher, F.; Elbaz, A. Deep Learning Based Method for Computer Aided Diagnosis of Diabetic Retinopathy. In Proceedings of the IST 2019—IEEE International Conference on Imaging Systems and Techniques, Abu Dhabi, United Arab Emirates, 9–10 December 2019; pp. 1–4. [Google Scholar] [CrossRef]
- He, A.; Li, T.; Li, N.; Wang, K.; Fu, H. CABNet: Category Attention Block for Imbalanced Diabetic Retinopathy Grading. IEEE Trans. Med. Imaging 2020, 40, 143–153. [Google Scholar] [CrossRef] [PubMed]
- Kassani, S.H.; Kassani, P.H.; Khazaeinezhad, R.; Wesolowski, M.J.; Schneider, K.A.; Deters, R. Diabetic retinopathy classification using a modified xception architecture. In Proceedings of the 2019 IEEE International Symposium on Signal Processing and Information Technology (ISSPIT), Ajman, United Arab Emirates, 10–12 December 2019; pp. 1–6. [Google Scholar]
- Bodapati, J.D.; Shaik, N.S.; Naralasetti, V. Composite deep neural network with gated-attention mechanism for diabetic retinopathy severity classification. J. Ambient. Intell. Humaniz. Comput. 2021, 1–15. [Google Scholar] [CrossRef]
- Hsieh, Y.T.; Chuang, L.M.; Jiang, Y.D.; Chang, T.J.; Yang, C.M.; Yang, C.H.; Chan, L.W.; Kao, T.Y.; Chen, T.C.; Lin, H.C.; et al. Application of deep learning image assessment software VeriSee™ for diabetic retinopathy screening. J. Formos. Med Assoc. 2021, 120, 165–171. [Google Scholar] [CrossRef]
- Zago, G.T.; Andreão, R.V.; Dorizzi, B.; Teatini Salles, E.O. Diabetic retinopathy detection using red lesion localization and convolutional neural networks. Comput. Biol. Med. 2019, 116, 103537. [Google Scholar] [CrossRef] [PubMed]
- Li, T.; Gao, Y.; Wang, K.; Guo, S.; Liu, H.; Kang, H. Diagnostic assessment of deep learning algorithms for diabetic retinopathy screening. Inf. Sci. 2019, 501, 511–522. [Google Scholar] [CrossRef]
- Wang, J.; Luo, J.; Liu, B.; Feng, R.; Lu, L.; Zou, H. Automated diabetic retinopathy grading and lesion detection based on the modified R-FCN object-detection algorithm. IET Comput. Vis. 2020, 14, 1–8. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Zisserman, K.S.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Porwal, P.; Pachade, S.; Kamble, R.; Kokare, M.; Deshmukh, G.; Sahasrabuddhe, V.; Meriaudeau, F. Indian Diabetic Retinopathy Image Dataset (IDRiD): A Database for Diabetic Retinopathy Screening Research. Data 2018, 3, 25. [Google Scholar] [CrossRef] [Green Version]
- APTOS 2019 Blindness Detection. Available online: https://www.kaggle.com/c/aptos2019-blindness-detection/overview/evaluation (accessed on 1 January 2020).
- Alyoubi, W.L.; Shalash, W.M.; Abulkhair, M.F. Diabetic Retinopathy Detection through Deep Learning Technique: A Review. Inform. Med. Unlocked 2020, 20, 1–11. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object detection via region-based fully convolutional networks. arXiv 2016, arXiv:1605.06409. [Google Scholar]
- Li, T.; Bo, W.; Hu, C.; Kang, H.; Liu, H.; Wang, K.; Fu, H. Applications of Deep Learning in Fundus Images: A Review. Med. Image Anal. 2021, 69, 101971. [Google Scholar] [CrossRef]
- Esfahani, M.T.; Ghaderi, M.; Kafiyeh, R. Classification of diabetic and normal fundus images using new deep learning method. Leonardo Electron. J. Pract. Technol. 2018, 17, 233–248. [Google Scholar]
- Dutta, S.; Manideep, B.C.; Basha, S.M.; Caytiles, R.D.; Iyengar, N.C.S.N. Classification of Diabetic Retinopathy Images by Using Deep Learning Models. Int. J. Grid Distrib. Comput. 2018, 11, 99–106. [Google Scholar] [CrossRef]
- Zhou, M.; Jin, K.; Wang, S.; Ye, J.; Qian, D. Color Retinal Image Enhancement Based on Luminosity and Contrast Adjustment. IEEE Trans. Biomed. Eng. 2018, 65, 521–527. [Google Scholar] [CrossRef] [PubMed]
- Pisano, E.D.; Zong, S.; Hemminger, B.M.; Deluca, M.; Johnston, R.E.; Muller, K.; Braeuning, M.P.; Pizer, S.M. Contrast Limited Adaptive Histogram Equalization Image Processing to Improve the Detection of Simulated Spiculations in Dense Mammograms. J. Digit. Imaging 1998, 11, 193–200. [Google Scholar] [CrossRef] [Green Version]
- Zuiderveld, K. Contrast Limited Adaptive Histogram Equalization. Graph. Gems IV 1994, 474–485. [Google Scholar] [CrossRef]
- Sonali; Sahu, S.; Singh, A.K.; Ghrera, S.; Elhoseny, M. An approach for de-noising and contrast enhancement of retinal fundus image using CLAHE. Optics Laser Technol. 2019, 110, 87–98. [Google Scholar] [CrossRef]
- Pratt, H.; Coenen, F.; Broadbent, D.M.; Harding, S.P.; Zheng, Y. Convolutional Neural Networks for Diabetic Retinopathy. Procedia Comput. Sci. 2016, 90, 200–205. [Google Scholar] [CrossRef] [Green Version]
- Ketkar, N. Deep Learning with Python; Springer: Berlin/Heidelberg, Germany, 2017; pp. 1–235. [Google Scholar] [CrossRef]
- Shalash, W.M. Driver Fatigue Detection with Single EEG Channel Using Transfer Learning. In Proceedings of the 2019 IEEE International Conference on Imaging Systems and Techniques (IST), Abu Dhabi, United Arab Emirates, 9–10 December 2019. [Google Scholar]
- COVER, T.; HART, P. Nearest Neighbor Pattern Classfication. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Keras. Available online: https://keras.io/ (accessed on 1 January 2019).
- Lee, W.Y.; Park, S.M.; Sim, K.B. Optimal hyperparameter tuning of convolutional neural networks based on the parameter-setting-free harmony search algorithm. Optik 2018, 172, 359–367. [Google Scholar] [CrossRef]
- Bergstra, J.; Bengio, Y. Random search for hyper-parameter optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Huang, Q.; Mao, J.; Liu, Y. An improved grid search algorithm of SVR parameters optimization. In Proceedings of the 2012 IEEE 14th International Conference on Communication Technology, Chengdu, China, 9–11 November 2012; pp. 1022–1026. [Google Scholar]
- Maclaurin, D.; Duvenaud, D.; Adams, R. Gradient-based hyperparameter optimization through reversible learning. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 7–9 July 2015; pp. 2113–2122. [Google Scholar]
- Smith, L.N. Cyclical learning rates for training neural networks. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, WACV 2017, Santa Rosa, CA, USA, 24–31 March 2017; pp. 464–472. [Google Scholar] [CrossRef] [Green Version]
- Ahn, S.; Pham, Q.; Shin, J.; Song, S.J. Future Image Synthesis for Diabetic Retinopathy Based on the Lesion Occurrence Probability. Electronics 2021, 10, 726. [Google Scholar] [CrossRef]
- Anton, N.; Dragoi, E.N.; Tarcoveanu, F.; Ciuntu, R.E.; Lisa, C.; Curteanu, S.; Doroftei, B.; Ciuntu, B.M.; Chiseliţă, D.; Bogdănici, C.M. Assessing Changes in Diabetic Retinopathy Caused by Diabetes Mellitus and Glaucoma Using Support Vector Machines in Combination with Differential Evolution Algorithm. Appl. Sci. 2021, 11, 3944. [Google Scholar] [CrossRef]
- Aziz Computer. Available online: http://hpc.kau.edu.sa (accessed on 1 January 2019).
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| DR Severity Level | Lesions |
|---|---|
| No DR | No lesions. |
| Mild DR | MA only. |
| Moderate DR | More than just MA but less than severe DR. |
| Severe DR | Any of the following: more than 20 intraretinal HM in each of 4 quadrants; definite venous beading in 2+ quadrants; Prominent intraretinal microvascular abnormalities in 1+ quadrant and no signs of proliferative DR. |
| Proliferative DR | One or more of the following: neovascularization, pre-retinal HM. |
| Ref. | Number of Classes | Detect Lesion | Dataset | Performance Measure | |||
|---|---|---|---|---|---|---|---|
| AUC | ACC | SEN | SP | ||||
| [15] | 2 | No | Messidor-2, DR2 | 98.2% 98% | - | - | - |
| [22] | 2 | No | private dataset, STARE | 0.9823 0.951 | 94.23% 90.84% | 90.94% | 95.74% |
| [18] | 2 | No | private dataset | 0.946 | 88.21% | 85.57% | 90.85% |
| [23] | 2 | No | private dataset | - | 98.7% | 0.996 | 98.2% |
| [24] | 5 | No | Kaggle | - | 63.23% | - | - |
| [25] | 5 | No | Kaggle | 0.978 | 95.6% | 86.4% | 97.4% |
| [26] | 4 | No | Messidor | - | 98.15% | 98.94% | 97.87% |
| [27] | 4 | No | private dataset | - | 96.5% | 98.1% | 98.9% |
| [28] | 5 | No | IDRiD | - | 90.07% | - | - |
| [29] | 4 | No | Messidor | - | 96.35 | 92.35 | 97.45 |
| [30] | 5 | No | IDRiD | - | 65.1% | - | - |
| [31] | 5 | No | APTOS 2019 | - | 0.77 | - | - |
| [32] | 5 | No | Messidor, DDR, Kaggle | - | 0.8408 0.8569 0.8668 | - | - |
| [33] | 5 | No | APTOS 2019 | - | 83.09 | 88.24 | 87 |
| [34] | 5 | No | APTOS 2019 | - | 82.54 | 83 | - |
| [35] | 3 | No | private dataset, EYEPACS | 0.955, 0.984, 0.955 | - | - | - |
| [36] | 2 | Red lesion only | Messidor | 0.912 | - | 0.94 | - |
| [37] | 5 | Yes | DDR | - | 0.8284 | - | - |
| [38] | 5 | Red lesion only | private dataset, Messidor | - 0.972 | 92.95 - | 99.39% 92.59% | 99.93% 96.20% |
| DDR | DDR Lesions Annotated | APTOS 2019 Kaggle | |
|---|---|---|---|
| Training | 10,019 images | 606 images | 2929 images |
| Testing | 2503 images | 149 images | 733 images |
| No DR | 6266 images | - | 1805 images |
| Mild | 630 images | 99 images | 370 images |
| Moderate | 4477 images | 548 images | 999 images |
| Severe | 236 images | 34 images | 193 images |
| Proliferative | 913 images | 74 images | 295 images |
| Image Size | Different image size | Different image size | Different image size |
| Total | 12,522 images | 755 images | 3662 images |
| MA Number | HM Number | Hard EX Number | Soft EX Number | Total | |
|---|---|---|---|---|---|
| Training | 7824 | 11,196 | 21,739 | 944 | 41,703 |
| Testing | 2556 | 1342 | 1920 | 349 | 6167 |
| Total | 10,380 | 12,538 | 23,659 | 1293 | 47,870 |
| Transformation Type | Description |
|---|---|
| Rotation | Rotate the image randomly between (, 35). |
| Flipping | Horizontal and vertical flip for the images. |
| Shearing | Randomly Shear images with angle between and 15. |
| Translation | Randomly with shift between −10% and 10% of pixels. |
| Brightness range | Randomly darken the image and brighten. The values less than 1.0 the image darken whereas values larger than 1.0 brighten the image. The used values (0.25, 1.25). |
| Layer | Operator | Layer Details |
|---|---|---|
| Input Layer | Zero Padding layer | Padding (2,2) |
| Layer 1 | 2D CONV layer | Kernel number = 32, kernel size = 3 |
| Layer 2 | Batch Normalization layer | - |
| Layer 3 | Relu layer | - |
| Layer 4 | Max Pooling layer | Pooling size (2,2) |
| Layer 5 | 2D CONV layer | Kernel number = 64, kernel size = 3 |
| Layer 6 | Batch Normalization layer | - |
| Layer 7 | Relu layer | - |
| Layer 8 | Max Pooling layer | Pooling size (2,2) |
| Layer 9 | 2D CONV layer | Kernel number = 96, kernel size = 3 |
| Layer 10 | Batch Normalization layer | - |
| Layer 11 | Relu layer | - |
| Layer 12 | Max Pooling layer | Pooling size (2,2) |
| Layer 13 | 2D CONV layer | Kernel number = 96, kernel size = 3 |
| Layer 14 | Batch Normalization layer | - |
| Layer 15 | Relu layer | - |
| Layer 16 | Max Pooling layer | Pooling size (2,2) |
| Layer 17 | Flatten layer | - |
| Layer 18 | FC layer | Neurons number = 1000 |
| Layer 19 | Batch Normalization layer | - |
| Layer 20 | Relu layer | - |
| Layer 21 | FC layer | Neurons number = 500 |
| Layer 22 | Batch Normalization layer | - |
| Layer 23 | Relu layer | - |
| Layer 24 | FC layer | With SoftMax activation |
| Layer | Operator | Layer Details |
|---|---|---|
| Input Layer | Zero Padding layer | Padding (2,2) |
| Layer 1 | 2D CONV layer | Kernel number = 32, kernel size = 3 |
| Layer 2 | Batch Normalization layer | - |
| Layer 3 | Relu layer | - |
| Layer 4 | Max Pooling layer | Pooling size (2,2) |
| Layer 5 | 2D CONV layer | Kernel number = 64, kernel size = 3 |
| Layer 6 | Batch Normalization layer | - |
| Layer 7 | Relu layer | - |
| Layer 8 | Max Pooling layer | Pooling size (2,2) |
| Layer 9 | 2D CONV layer | Kernel number = 96, kernel size = 3 |
| Layer 10 | Batch Normalization layer | - |
| Layer 11 | Relu layer | - |
| Layer 12 | Max Pooling layer | Pooling size (2,2) |
| Layer 13 | 2D CONV layer | Kernel number = 96, kernel size = 3 |
| Layer 14 | Batch Normalization layer | - |
| Layer 15 | Relu layer | - |
| Layer 16 | Max Pooling layer | Pooling size (2,2) |
| Layer 17 | 2D CONV layer | Kernel number = 128, kernel size = 3 |
| Layer 18 | Batch Normalization layer | - |
| Layer 19 | Relu layer | - |
| Layer 20 | Max Pooling layer | Pooling size (2,2) |
| Layer 21 | 2D CONV layer | Kernel number = 200, kernel size = 3 |
| Layer 22 | Batch Normalization layer | - |
| Layer 23 | Relu layer | - |
| Layer 24 | Max Pooling layer | Pooling size (2,2) |
| Layer 25 | Flatten layer | - |
| Layer 26 | FC layer | Neurons number = 1000 |
| Layer 27 | Batch Normalization layer | - |
| Layer 28 | Relu layer | - |
| Layer 29 | FC layer | Neurons number = 500 |
| Layer 30 | Batch Normalization layer | - |
| Layer 31 | Relu layer | - |
| Layer 32 | FC layer | With SoftMax activation |
| Configuration | Values |
|---|---|
| Optimizer | SGD |
| Momentum | 0.9 |
| Max Learning rate | in custom CNNs in EfficientNetB0 |
| Base Learning rate | |
| Mode | triangular |
| Class weight | auto |
| Dropout | 0.5 |
| Augmentation | 20 times |
| Configuration | Values |
|---|---|
| Optimizer | SGD and Adam |
| Momentum | 0.9 |
| Learning rate | |
| Anchors number | 9 |
| Augmentation | 5 times |
| Input size | (416,416,3) |
| CNN model | Darknet53 |
| Object threshold | 0.45 |
| NMS threshold | 0.45 |
| Dropout | 0.5 |
| Model | Image Size | ACC | SEN | SP | AUC |
|---|---|---|---|---|---|
| Tao Li et al. [37] | 224 | 0.828 | - | - | - |
| Along He et al. [32] | 512 | 0.856 | - | - | - |
| CNN299 | 299 | 0.800 | - | - | - |
| CNN299 + dropout | 299 | 0.833 | - | - | - |
| CNN512 | 512 | 0.858 | 0.858 | 0.963 | 0.975 |
| CNN512 + dropout | 512 | 0.886 | 0.886 | 0.971 | 0.979 |
| EfficientNetB0 | 224 | 0.823 | - | - | - |
| EfficientNetB0 + dropout | 224 | 0.822 | - | - | - |
| Models fusion | 512 | 0.890 | 0.890 | 0.973 | 0.970 |
| Model | Image Size | ACC | SEN | SP | AUC |
|---|---|---|---|---|---|
| Omar Dekhil et al. [31] | 224 | 0.77 | - | - | - |
| kassani et al. [33] | 600 | 83.09 | 88.2 | 87.0 | - |
| Bodapati et al. [34] | - | 82.54 | 83 | - | - |
| CNN299 | 299 | 0.821 | - | - | - |
| CNN299 + dropout | 299 | 0.832 | - | - | - |
| CNN299 + dropout + enhance luminosity | 299 | 0.832 | - | - | - |
| CNN512 | 512 | 0.834 | 0.834 | 0.957 | 0.97 |
| CNN512 + dropout | 512 | 0.841 | 0.841 | 0.960 | 0.973 |
| EfficientNetB0 | 224 | 0.823 | - | - | - |
| EfficientNetB0 + dropout | 224 | 0.822 | - | - | - |
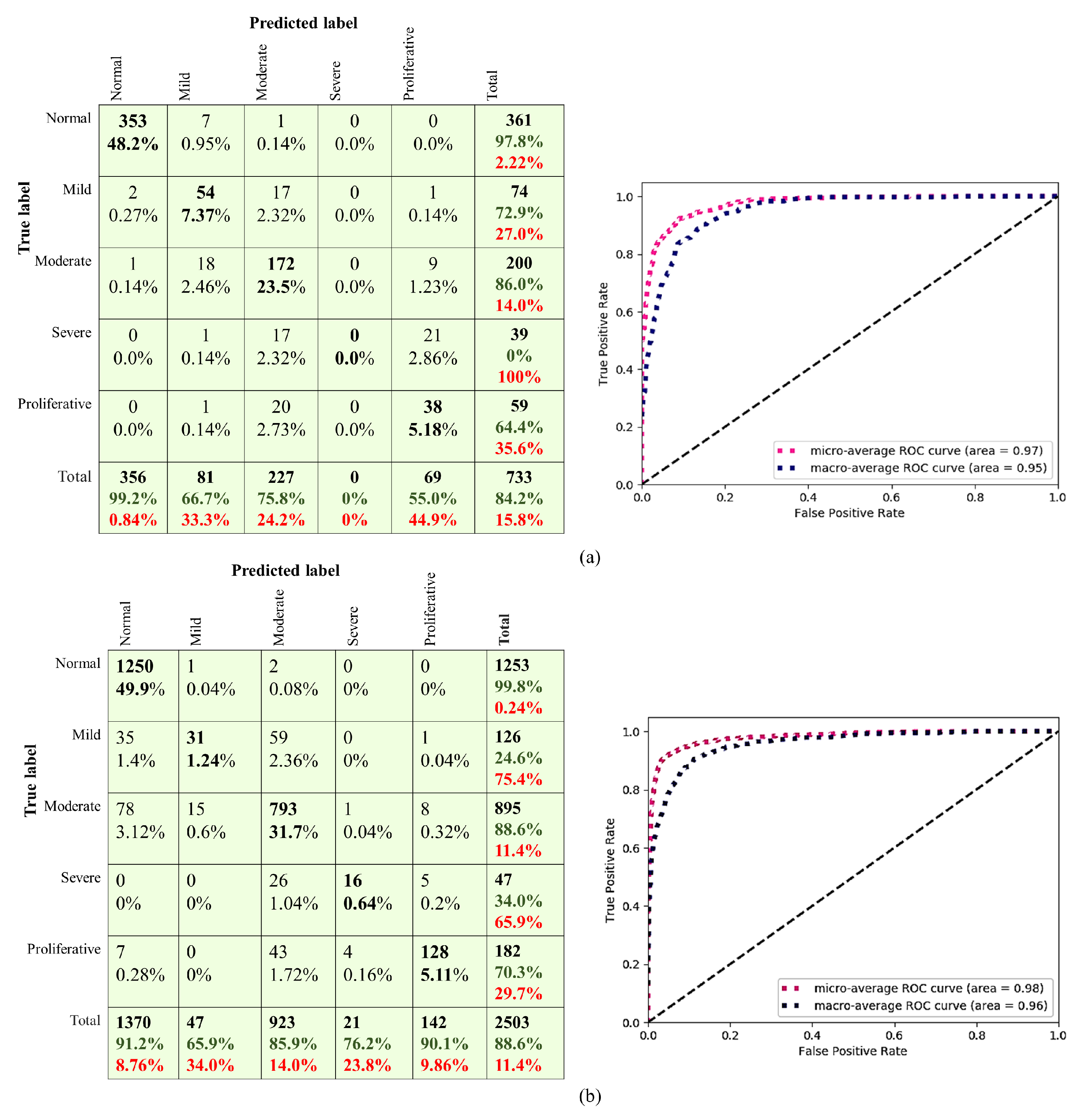
| Stage | SEN | SP | PPV | NPV |
|---|---|---|---|---|
| No DR | 0.978 | 0.991 | 0.991 | 0.979 |
| Mild DR | 0.730 | 0.959 | 0.667 | 0.969 |
| Moderate DR | 0.860 | 0.897 | 0.758 | 0.945 |
| Severe DR | 0 | 100 | 0 | 0.947 |
| Proliferative DR | 0.644 | 0.954 | 0.550 | 0.968 |
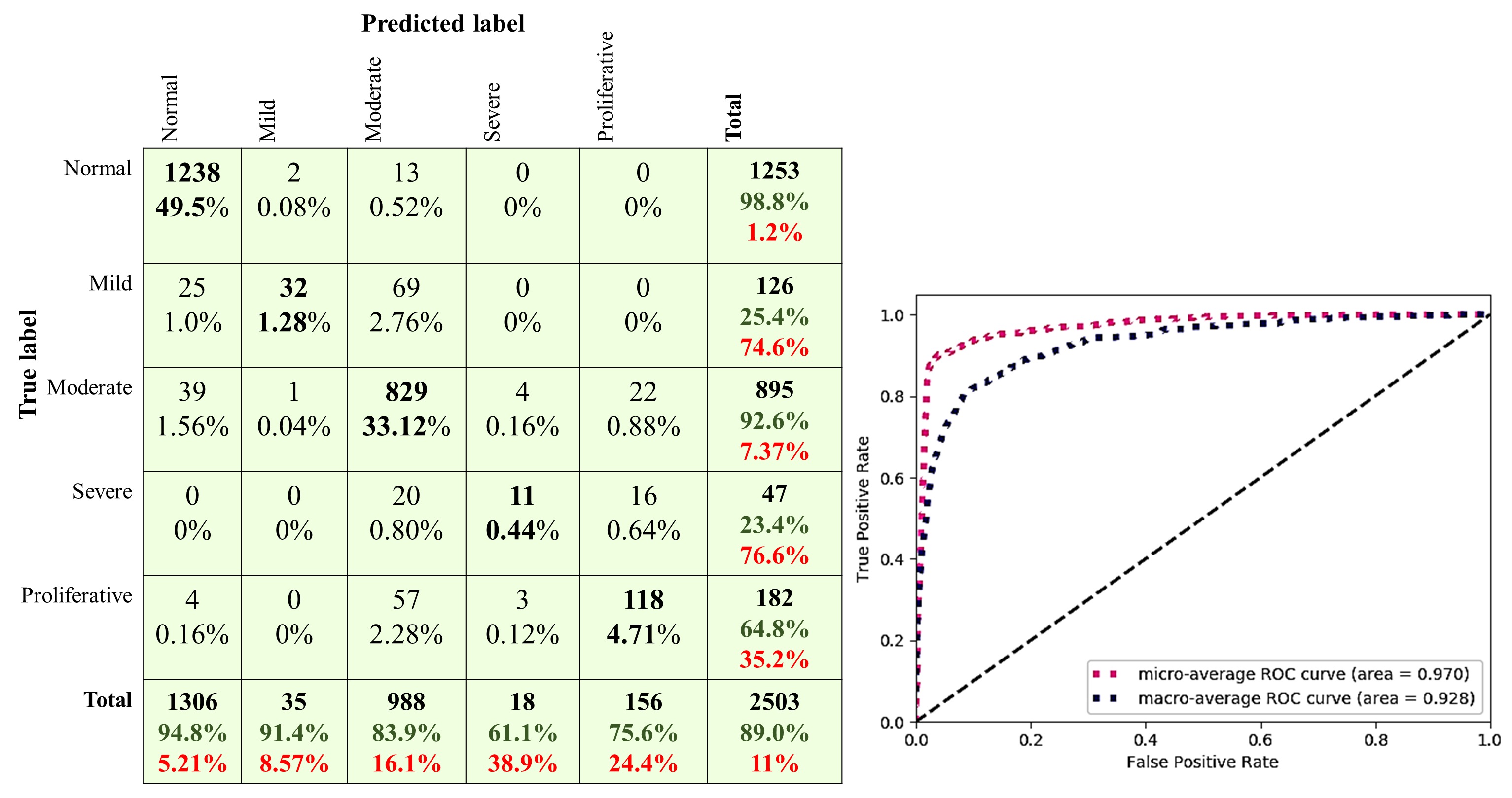
| Stage | SEN | SP | PPV | NPV |
|---|---|---|---|---|
| No DR | 0.998 | 0.904 | 0.912 | 0.997 |
| Mild DR | 0.246 | 0.993 | 0.660 | 0.961 |
| Moderate DR | 0.886 | 0.919 | 0.859 | 0.935 |
| Severe DR | 0.340 | 0.998 | 0.762 | 0.988 |
| Proliferative DR | 0.703 | 0.993 | 0.901 | 0.977 |
| Model | mAP |
|---|---|
| YOLOv3 + SGD | 0.110 |
| YOLOv3 + SGD+ dropout | 0.171 |
| YOLOv3 + Adam optimizer + dropout | 0.216 |
| Model | ACC |
|---|---|
| KNN | 0.985 |
| ANN | 0.893 |
| SVM | 0.872 |
| Model | Valid Images Number | ACC | SEN | SP | AUC |
|---|---|---|---|---|---|
| CNN299 + KNN | 250 images | 0.62 | 0.62 | 0.90 | 0.762 |
| YOLOv3 + SGD+ dropout + KNN | 250 images | 0.712 | 0.712 | 0.928 | 0.820 |
| YOLOv3 + Adam+ dropout + KNN | 250 images | 0.552 | 0.552 | 0.888 | 0.720 |
| YOLOv3 + SGD+ dropout + KNN | 2503 images | 0.528 | 0.528 | 0.882 | 0.705 |
| YOLOv3 + ADAM+ dropout +ANN | 2503 images | 0.481 | 0.481 | 0.870 | 0.789 |
| Model | mAP |
|---|---|
| Tao li et al. [37] | 0.092 |
| YOLOv3 + Adam optimizer + dropout | 0.216 |
| Model | EfficientNetB0 + Dropout | CNN299 + Dropout | CNN512 + Dropout | Model Fusion | |||
|---|---|---|---|---|---|---|---|
| Dataset | APTOS | DDR | APTOS | DDR | APTOS | DDR | DDR |
| ACC | 0.822 | 0.822 | 0.832 | 0.833 | 0.841 | 0.886 | 0.890 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alyoubi, W.L.; Abulkhair, M.F.; Shalash, W.M. Diabetic Retinopathy Fundus Image Classification and Lesions Localization System Using Deep Learning. Sensors 2021, 21, 3704. https://doi.org/10.3390/s21113704
Alyoubi WL, Abulkhair MF, Shalash WM. Diabetic Retinopathy Fundus Image Classification and Lesions Localization System Using Deep Learning. Sensors. 2021; 21(11):3704. https://doi.org/10.3390/s21113704
Chicago/Turabian StyleAlyoubi, Wejdan L., Maysoon F. Abulkhair, and Wafaa M. Shalash. 2021. "Diabetic Retinopathy Fundus Image Classification and Lesions Localization System Using Deep Learning" Sensors 21, no. 11: 3704. https://doi.org/10.3390/s21113704
APA StyleAlyoubi, W. L., Abulkhair, M. F., & Shalash, W. M. (2021). Diabetic Retinopathy Fundus Image Classification and Lesions Localization System Using Deep Learning. Sensors, 21(11), 3704. https://doi.org/10.3390/s21113704