
The Role of Global Appearance of Omnidirectional Images in Relative Distance and Orientation Retrieval


Abstract
:1. Introduction
2. Global Appearance Descriptors
2.1. Descriptors Based on the Discrete Fourier Transform
2.2. Descriptors Based on Histograms of Oriented Gradients
2.3. Descriptors Based on Gist
2.4. Descriptors Based on Wi-SURF
2.5. Descriptors Based on BRIEF-Gist
2.6. Descriptors Based on Radon Transform
3. Solving the Absolute Localization Problem
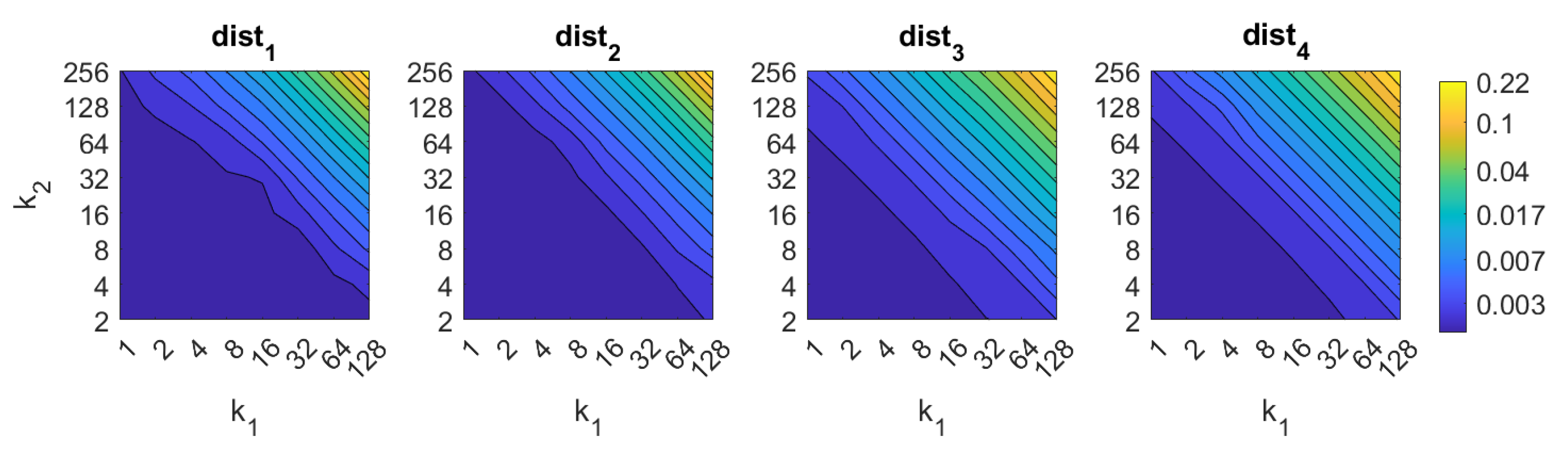
3.1. Descriptors Based on the Discrete Fourier Transform
- A set of artificial rotations is applied to the test image. The shift theorem of the unidimensional DFT can be used to generate the argument matrices of the test image rotated siblings. The step between consecutive rotations is . This is equivalent to making a shift of the columns of the panoramic image with a magnitude of d pixels, where . In the experiments, we consider . This means that the angular step between consecutive artificial rotations is . This is the resolution of the method.
- After this process, a set of arguments matrices are available at time instant t.
- The Hadamard product of the matrix and every matrix is calculated. The sum of the components of each resulting matrix is obtained, and the result is an array of data:
- The estimated relative rotation is the value whose coefficient presents the maximum value.where is the relative orientation between the image and the nearest neighbor of the map, . This way, the absolute orientation of the robot at time instant t can be calculated as:In this equation, is the orientation that the robot had when the map image was captured, with respect to the global reference system.
3.2. Descriptors Based on Histograms of Oriented Gradients
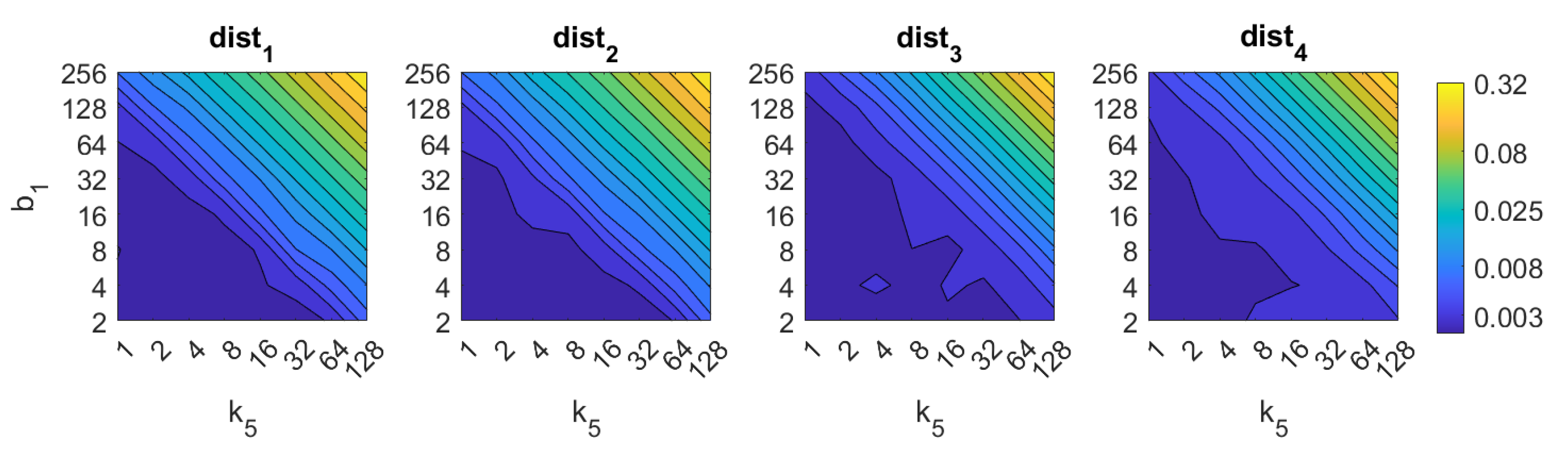
3.3. Descriptors Based on Gist
3.4. Descriptors Based on Wi-SURF
3.5. Descriptors Based on BRIEF-Gist
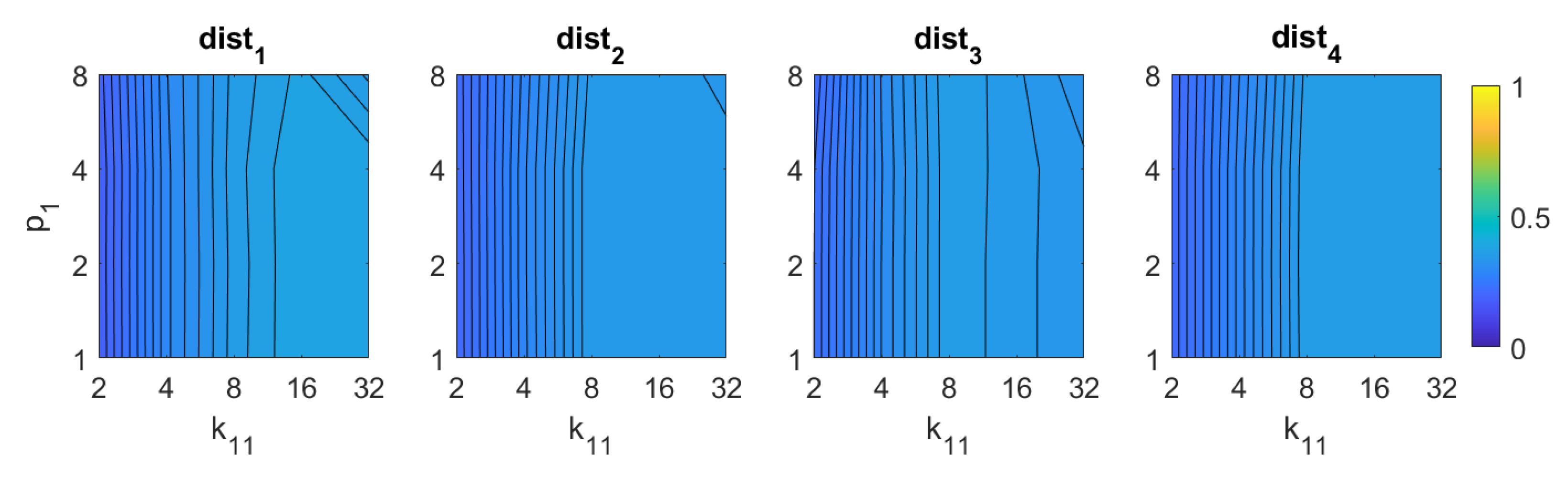
3.6. Descriptors Based on the Radon Transform
3.6.1. Radon–Fourier Method
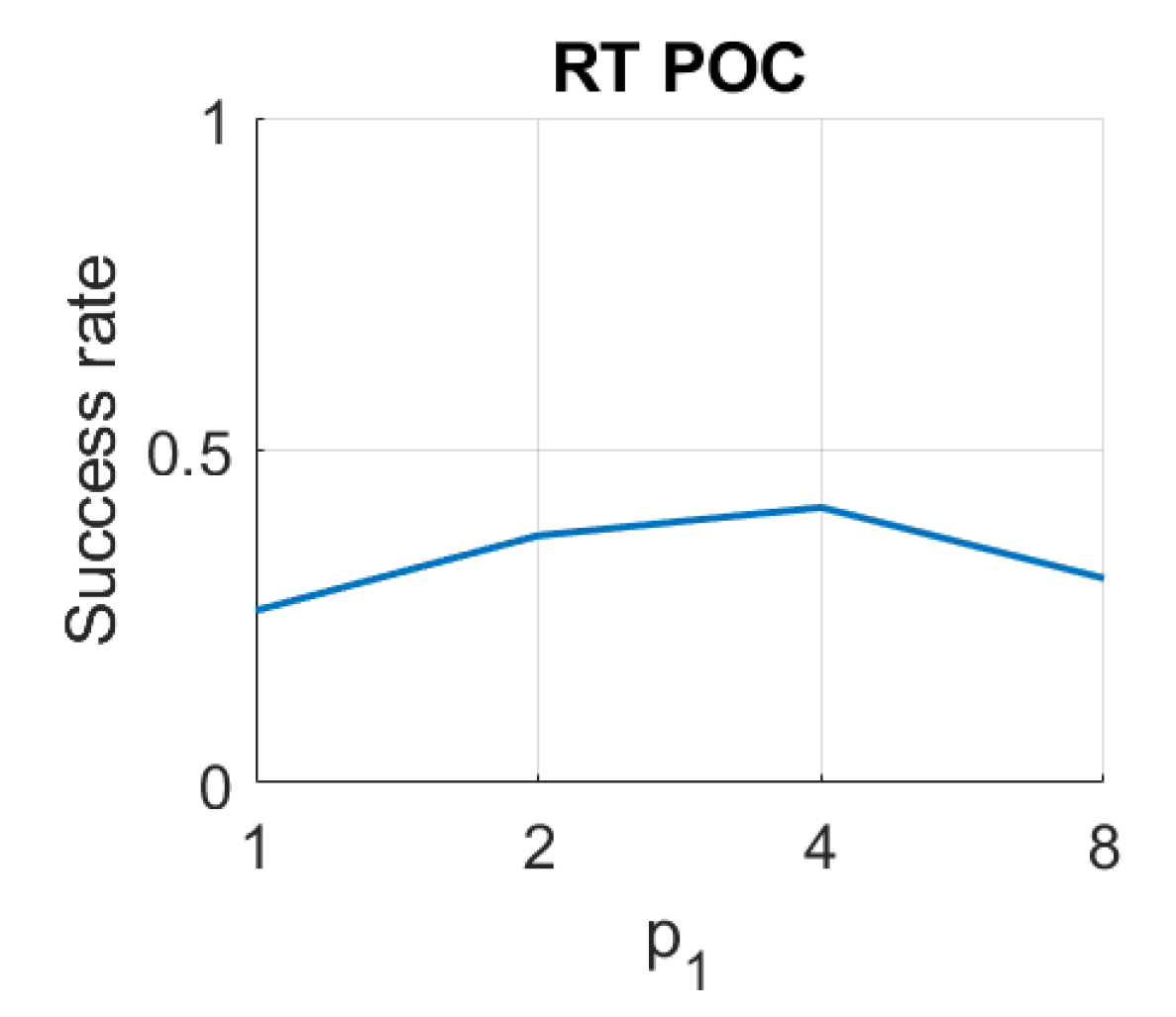
3.6.2. Radon–POC Method
4. Experimental Setup
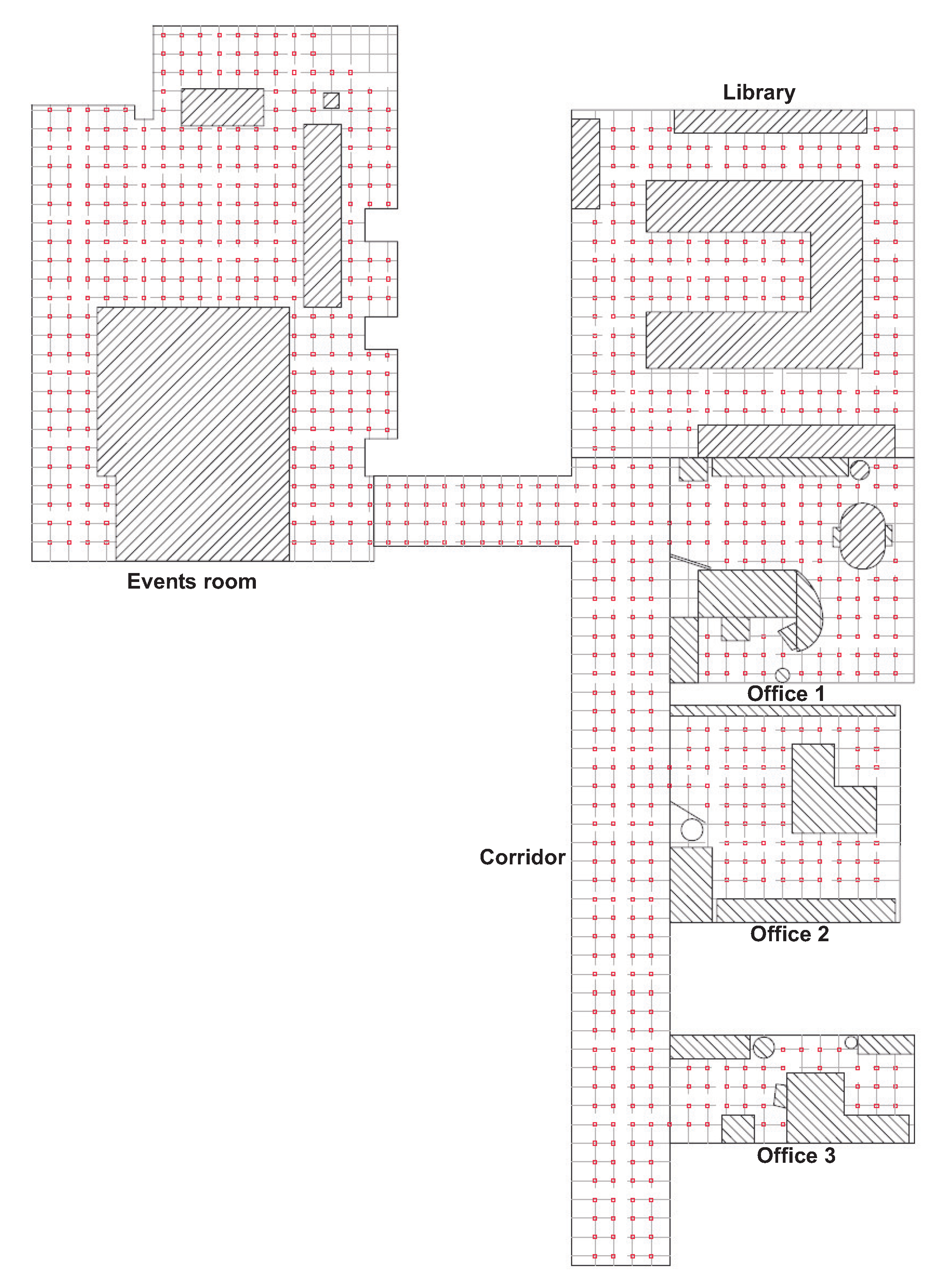
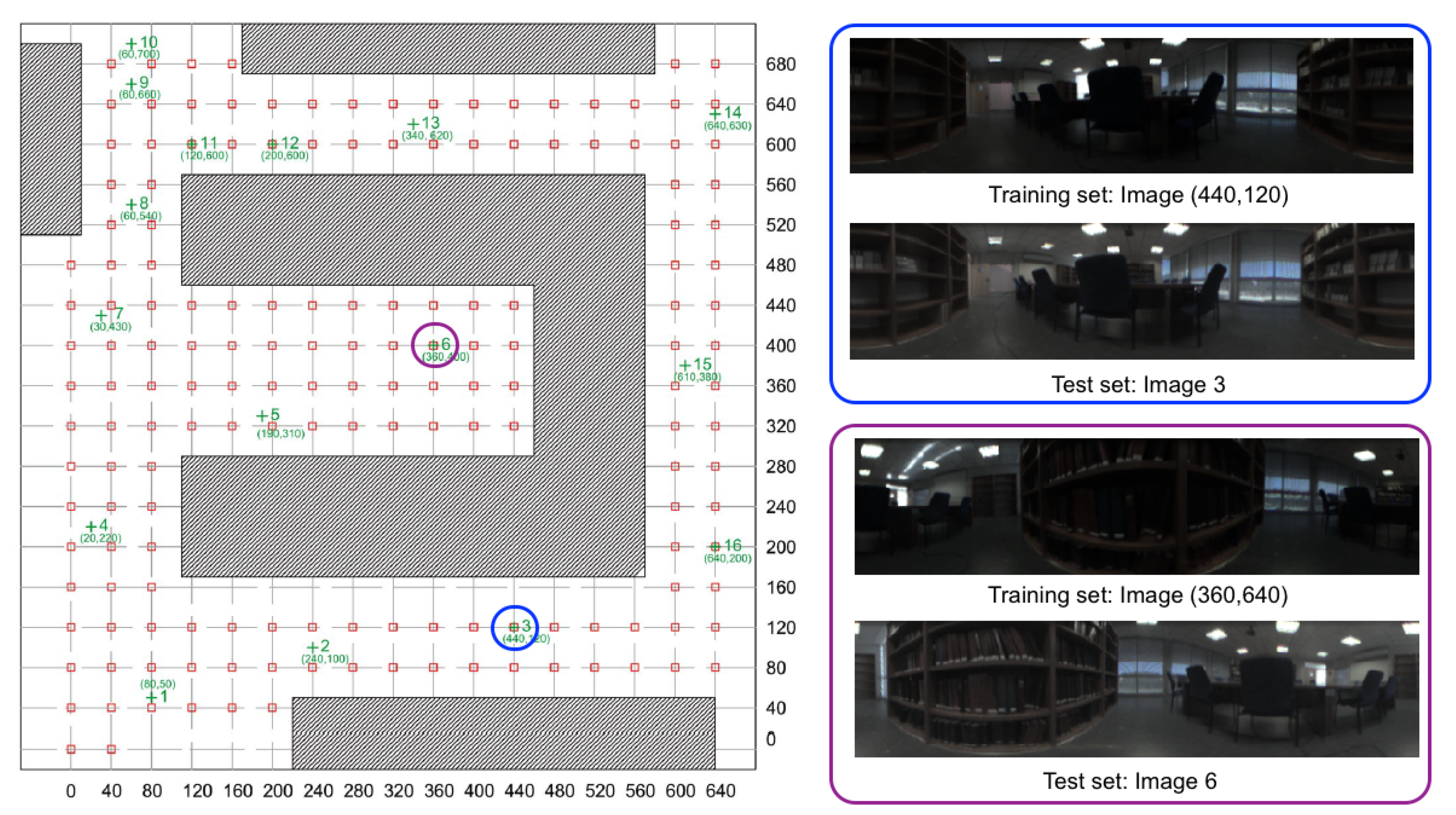
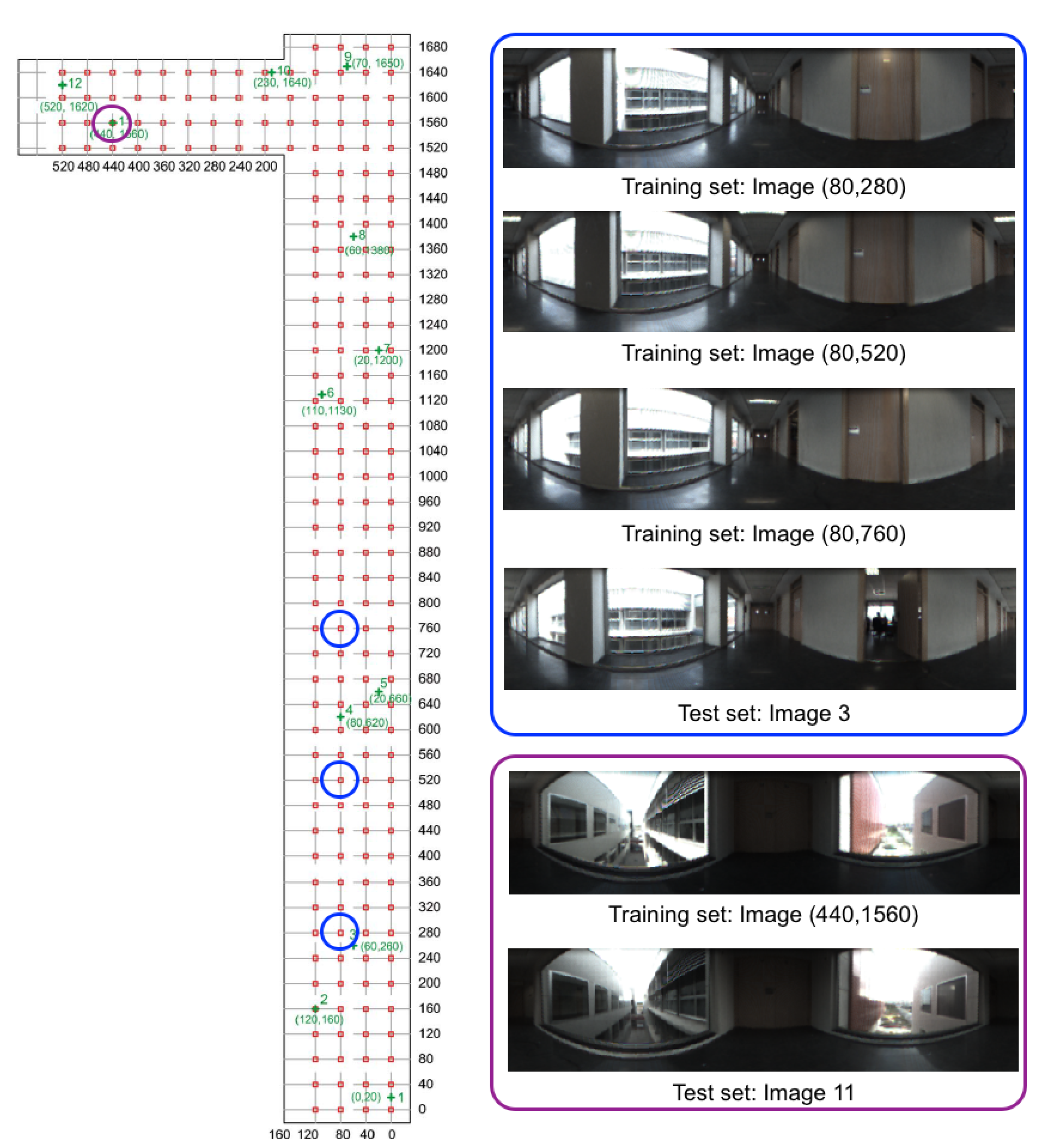
4.1. Sets of Images
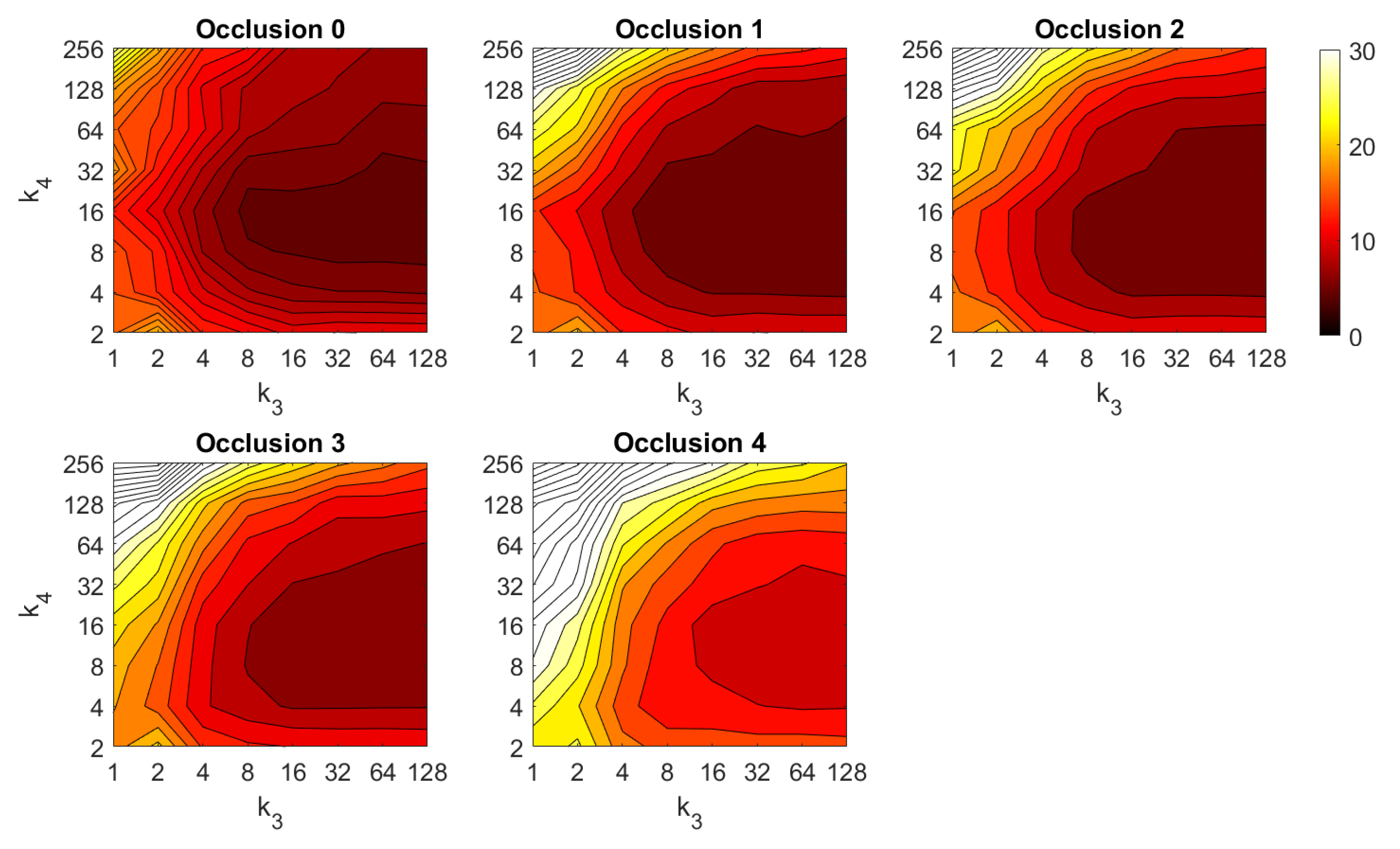
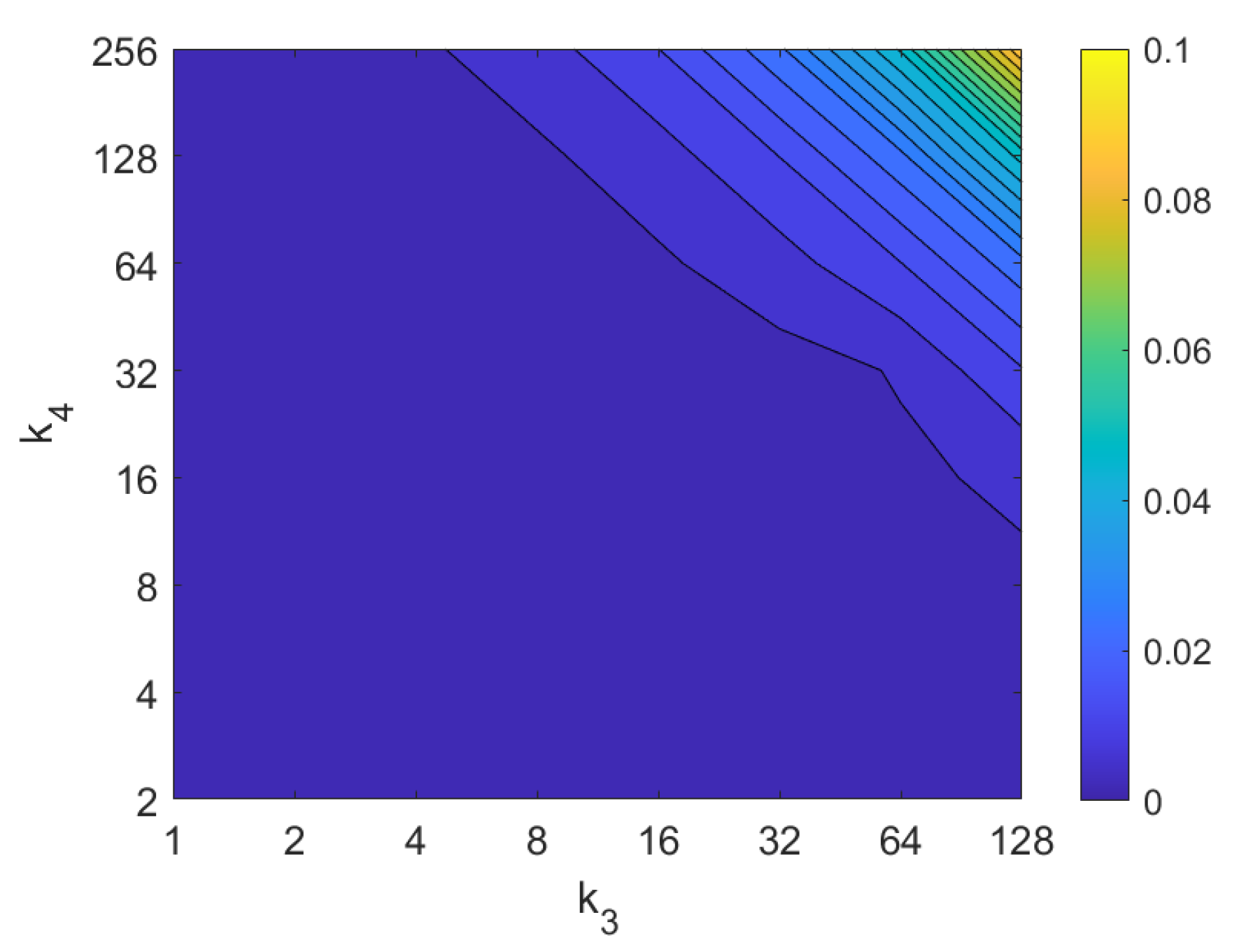
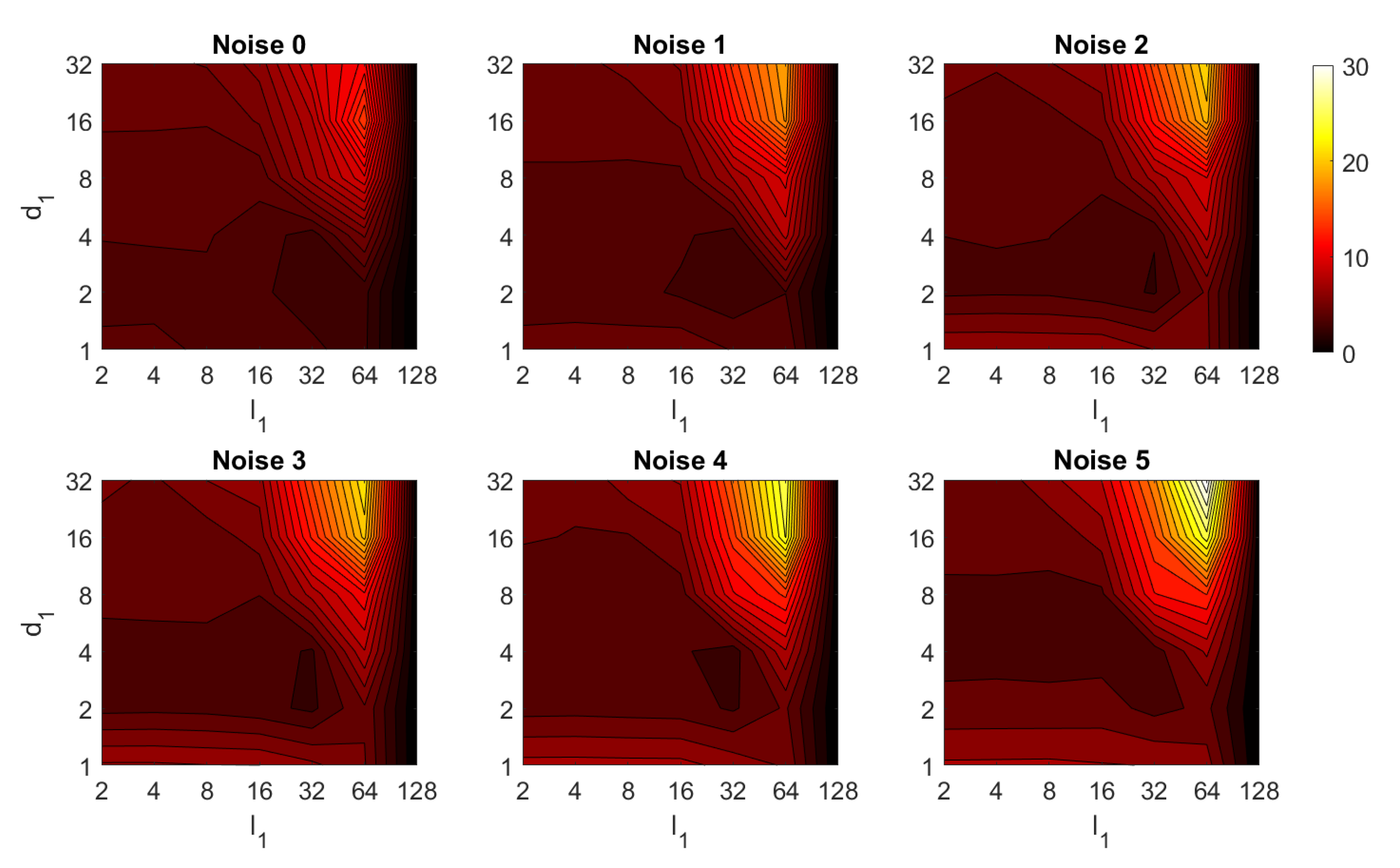
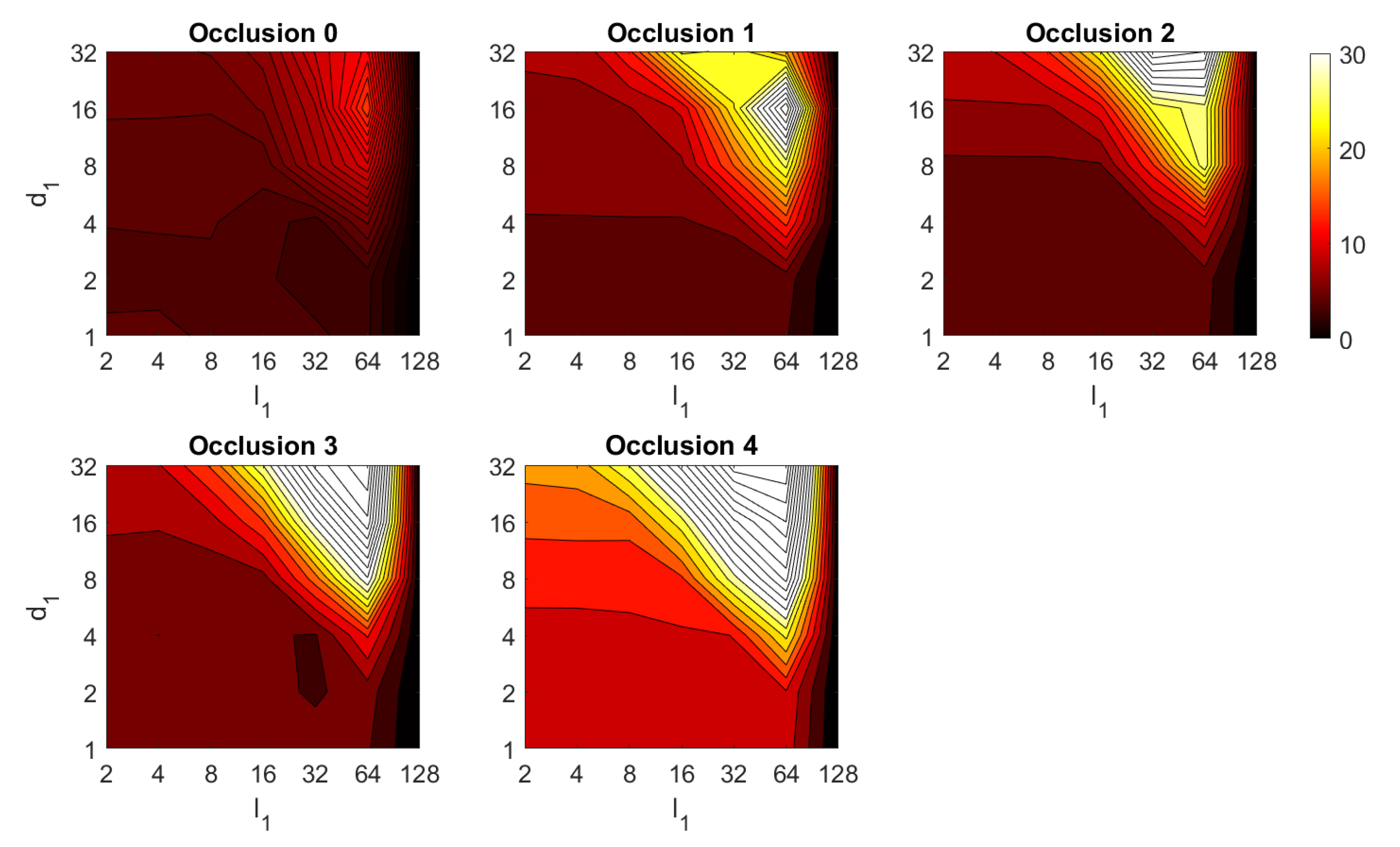
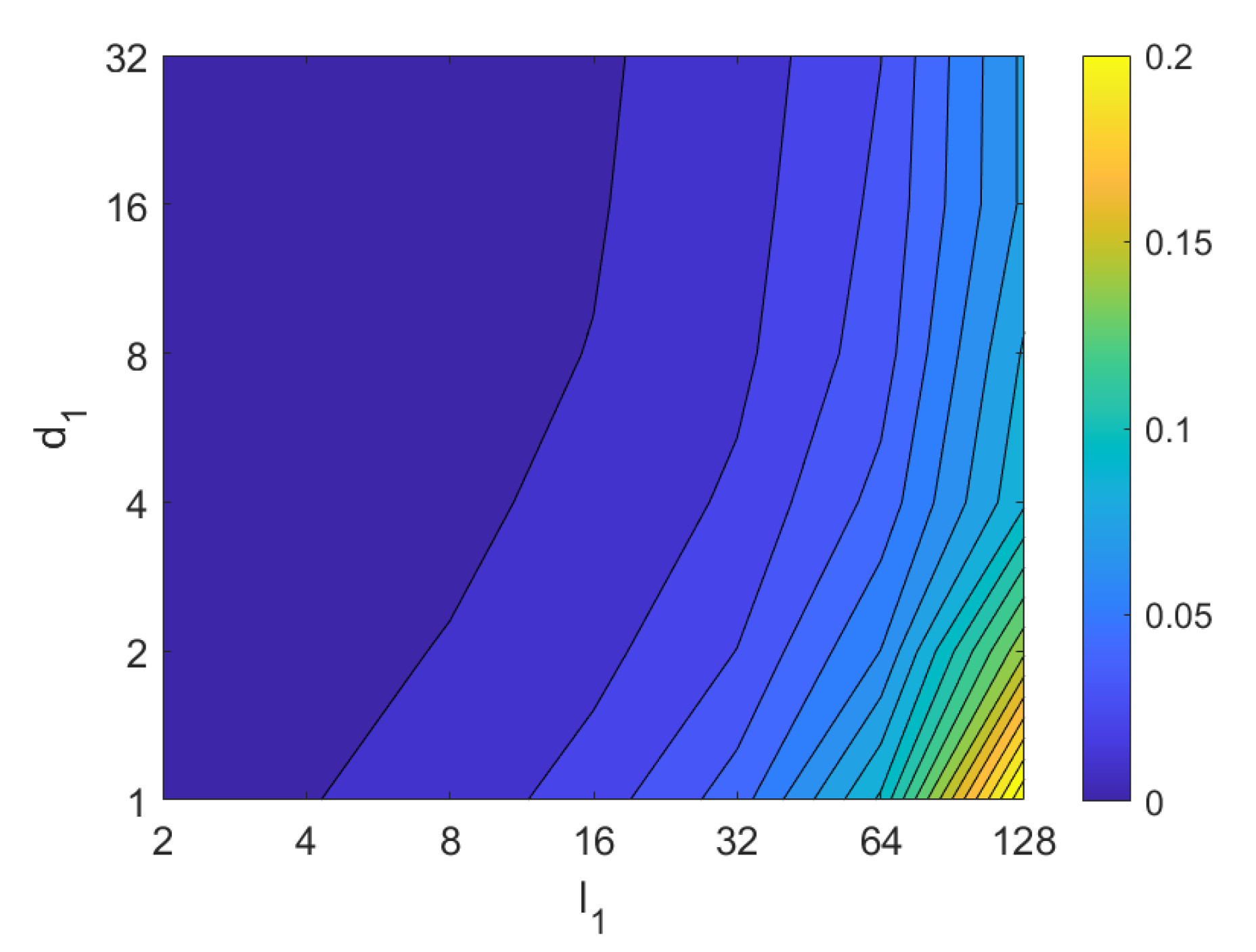
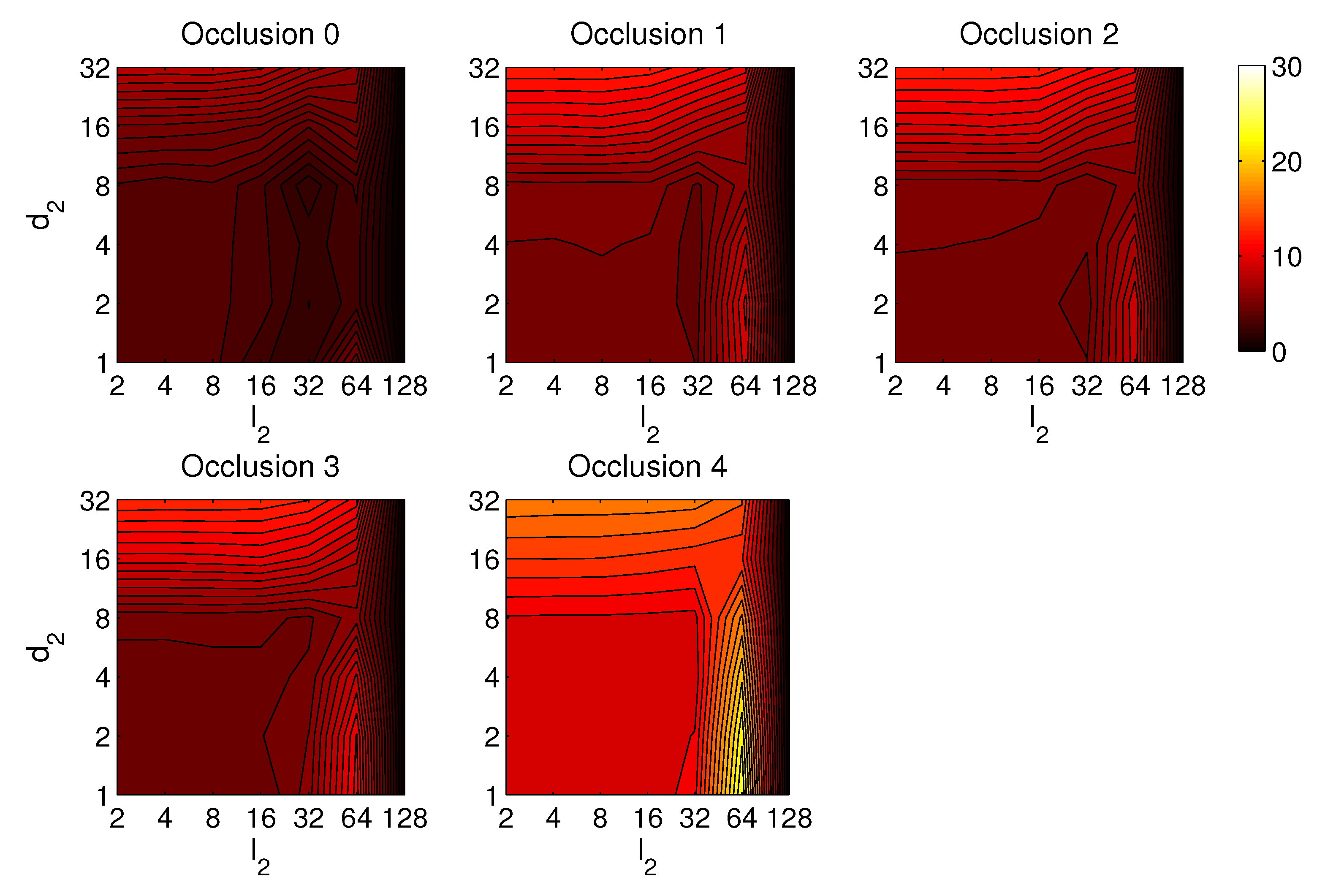
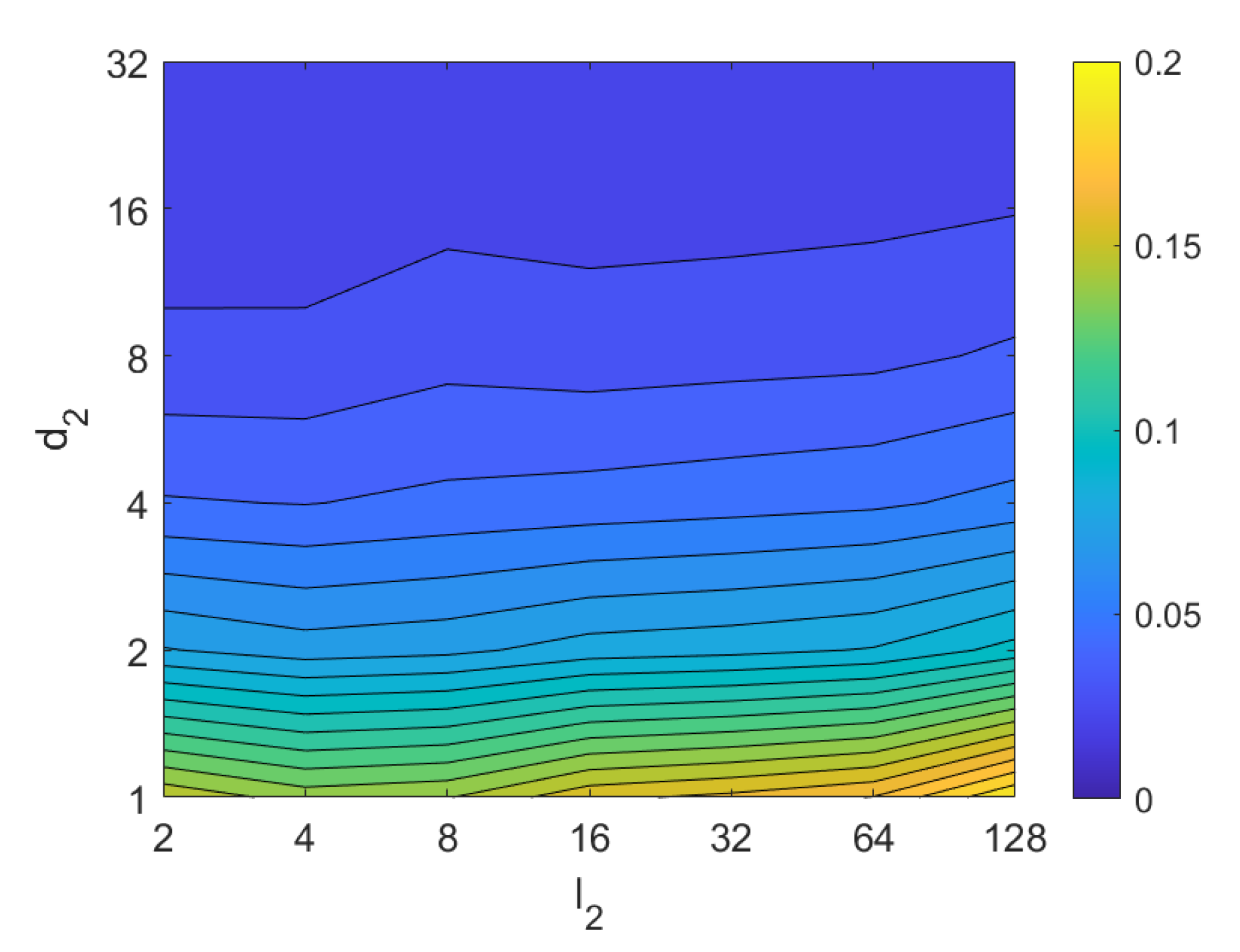
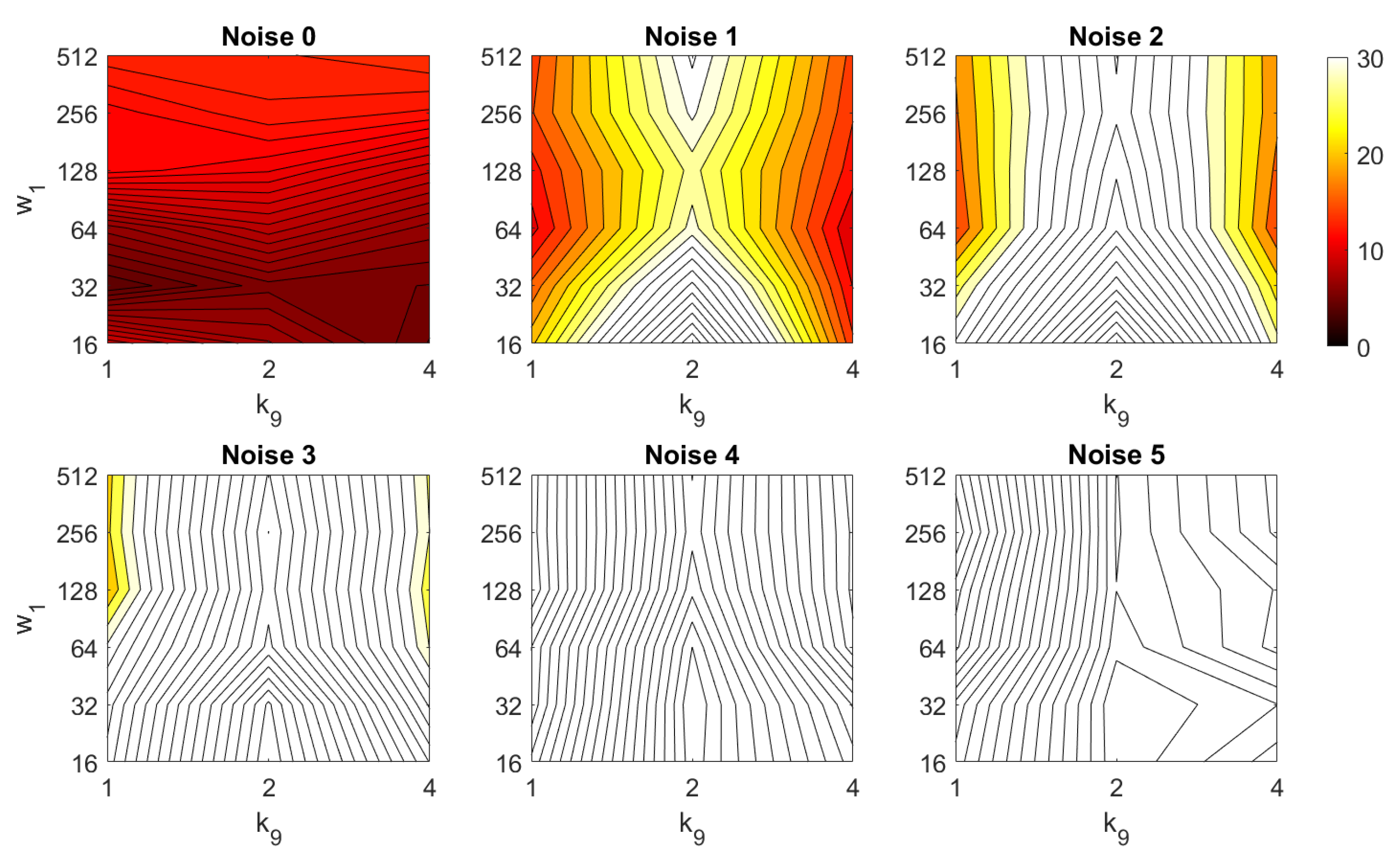
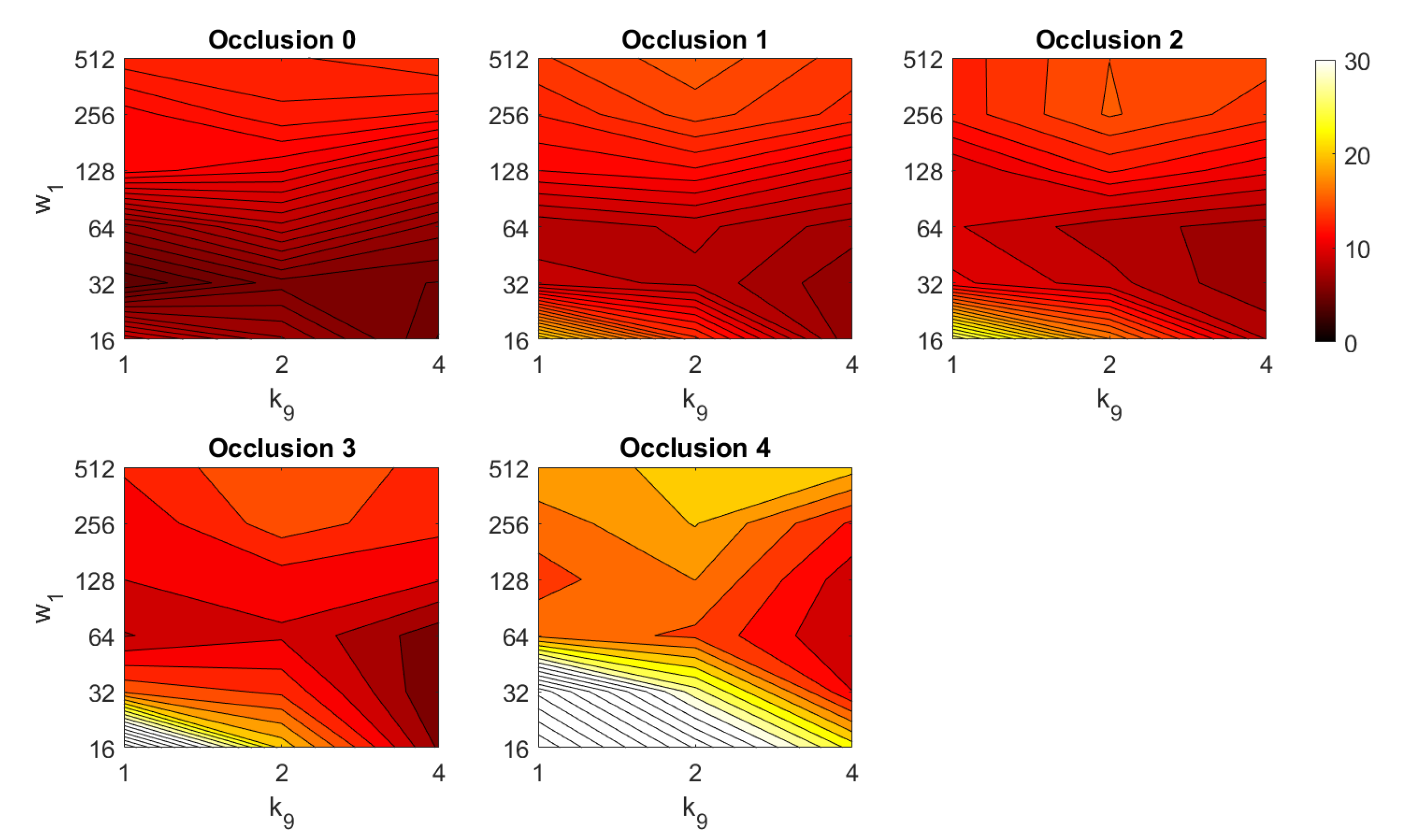
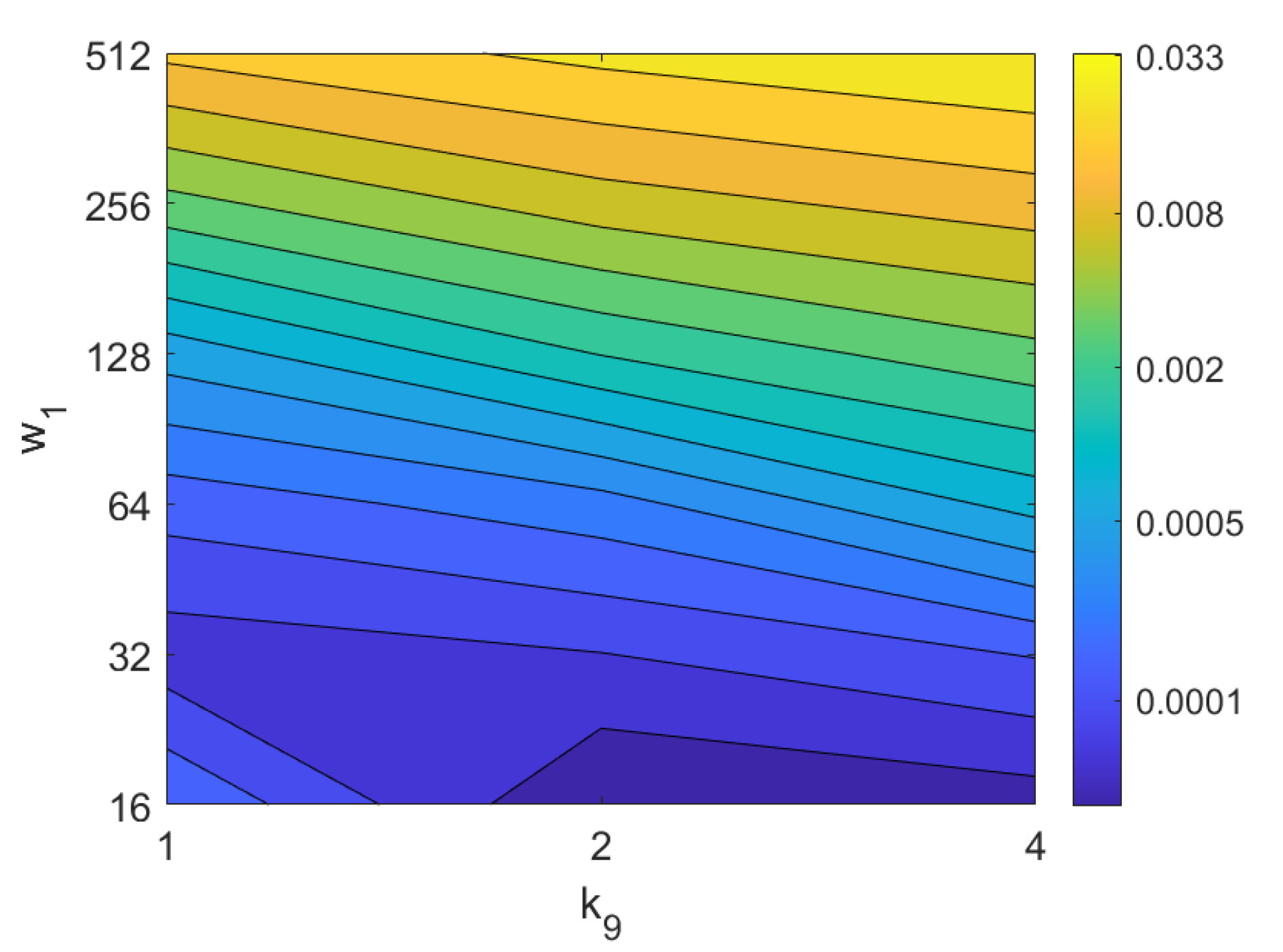
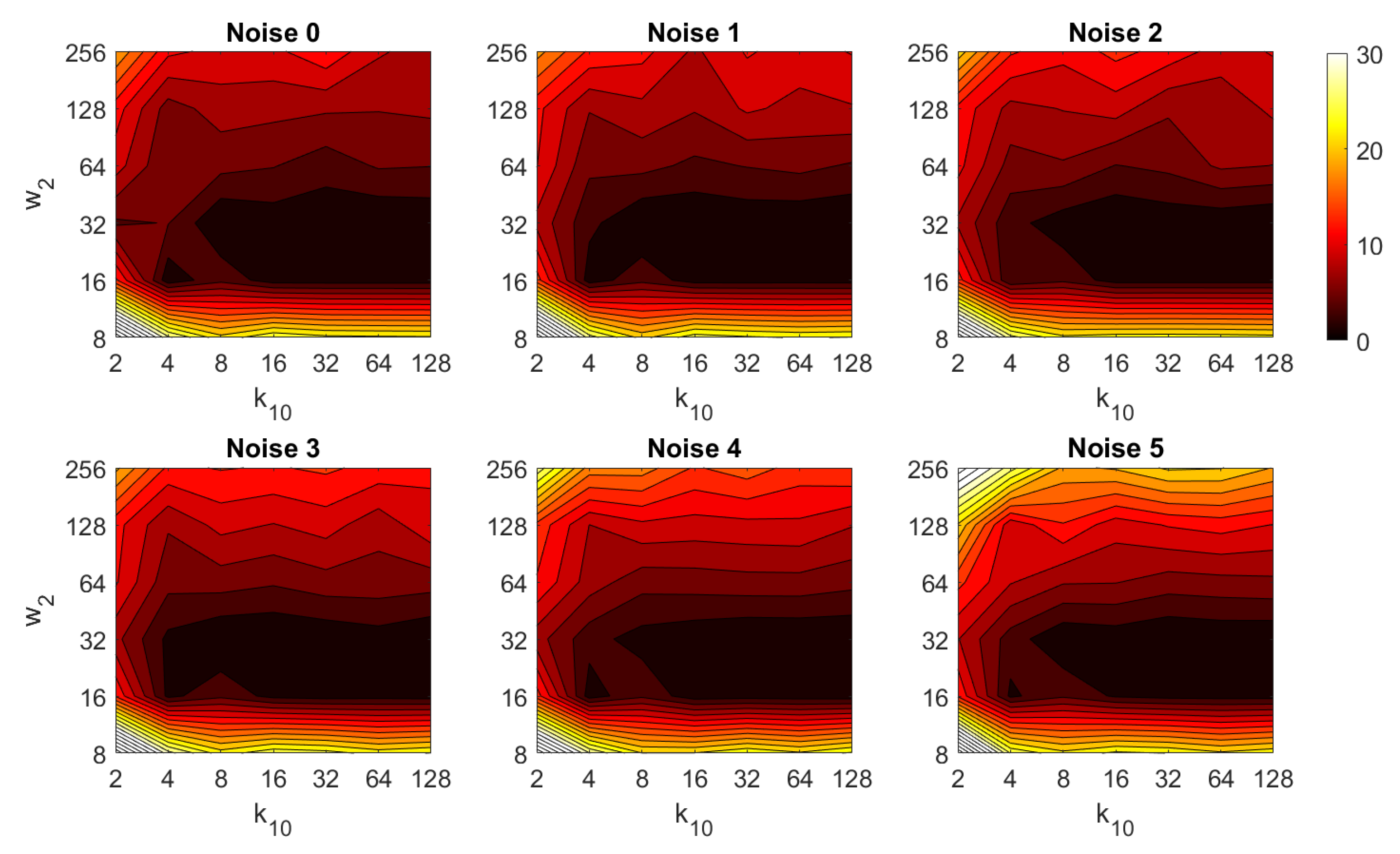
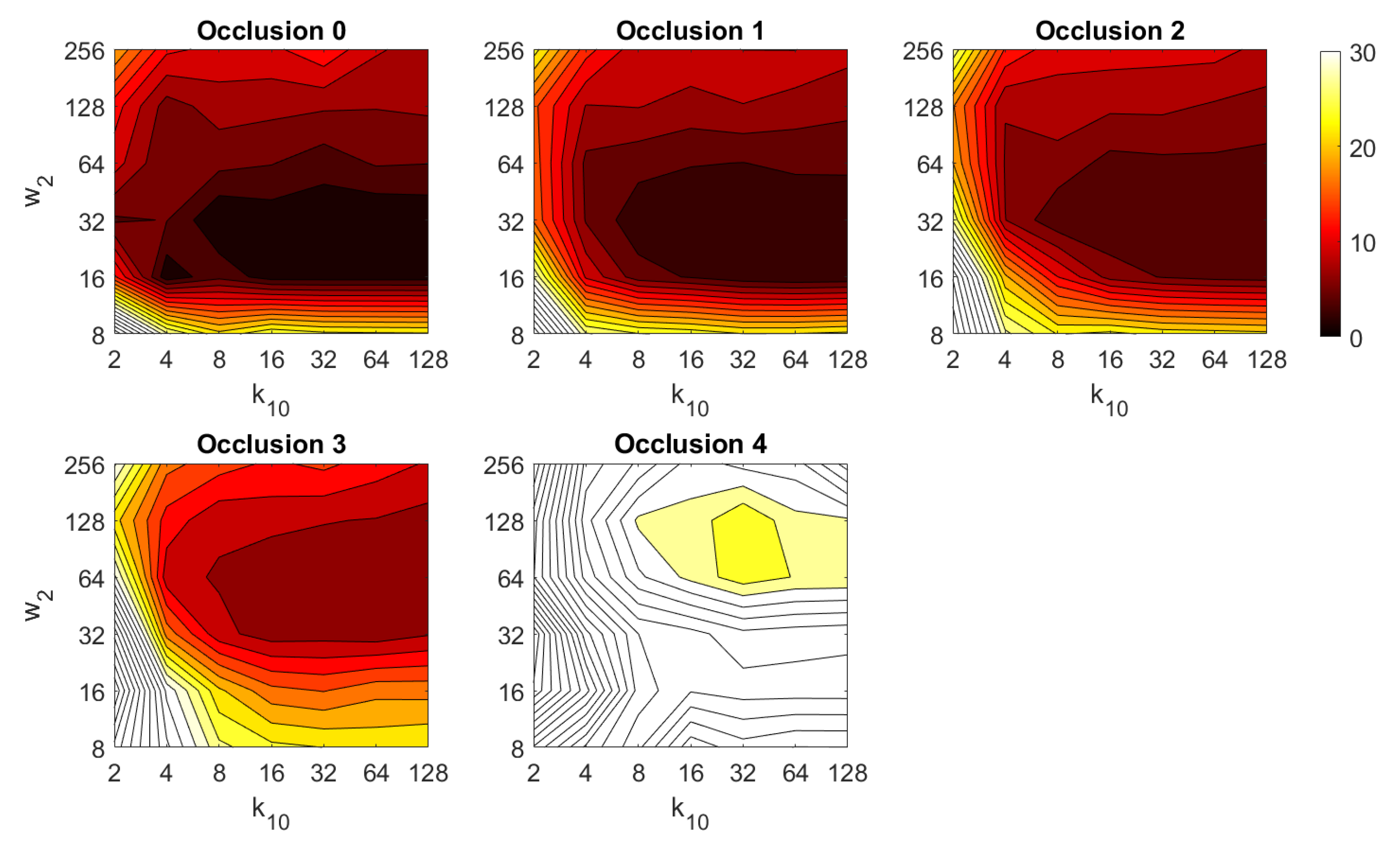
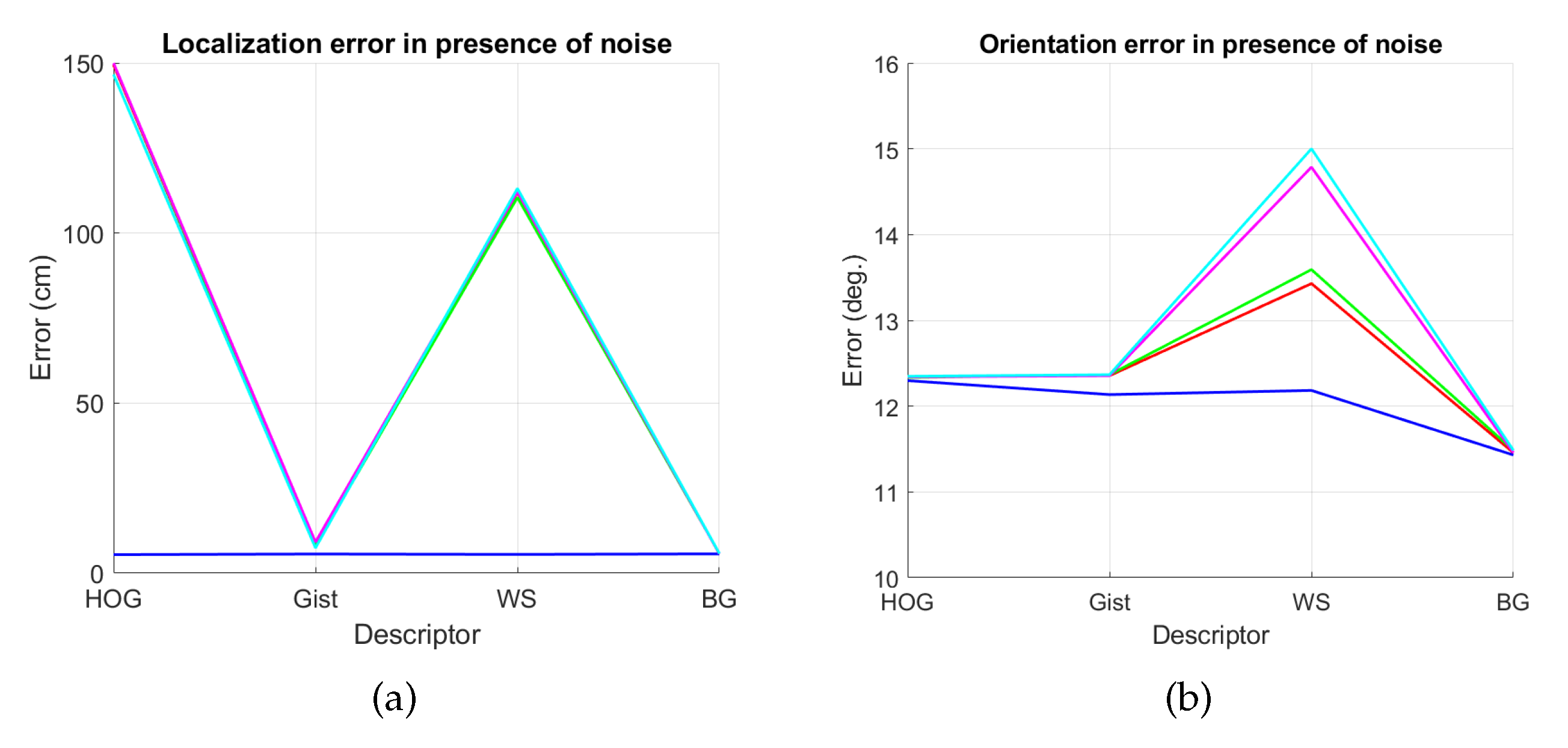
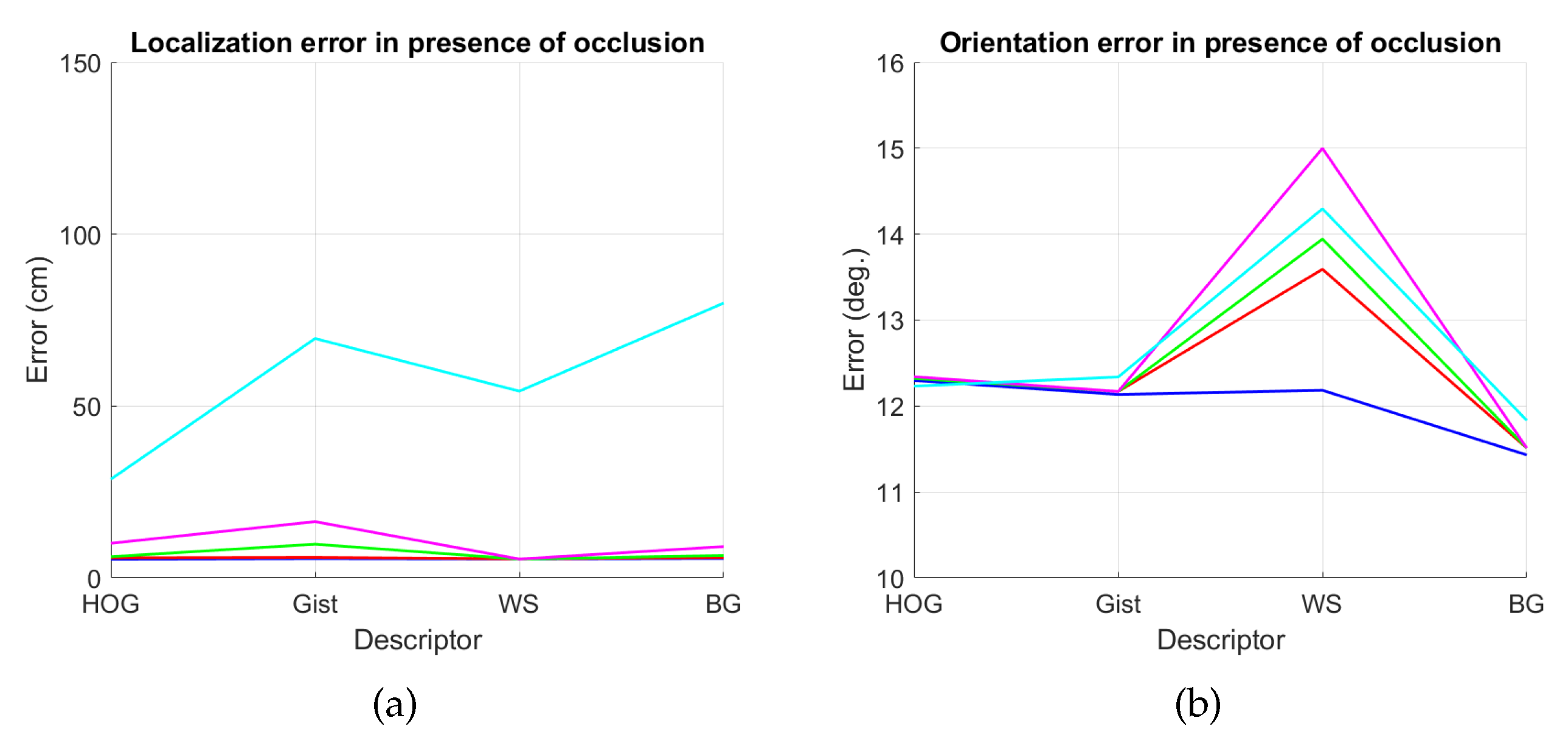
4.2. Addition of Noise and Occlusions
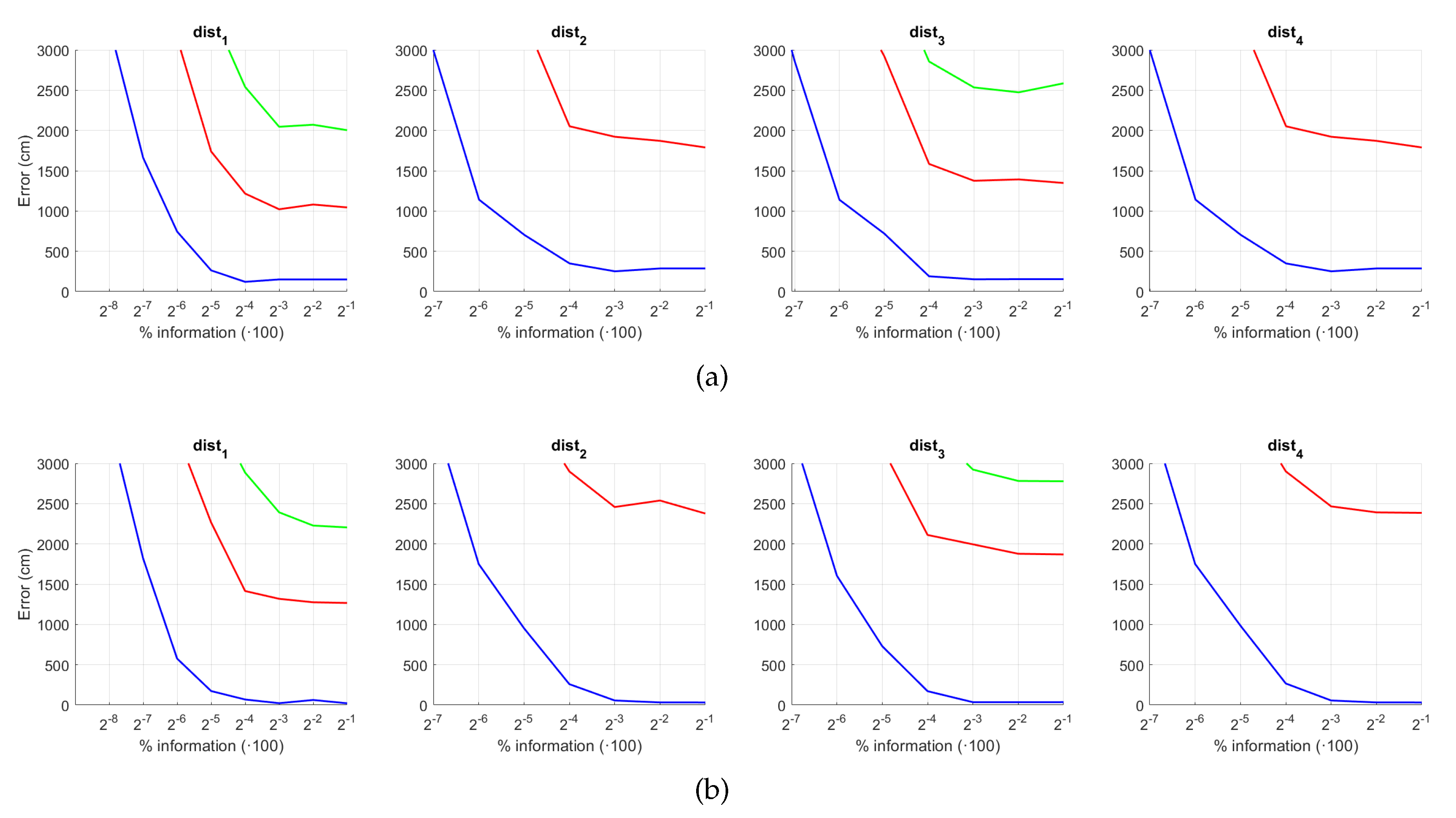
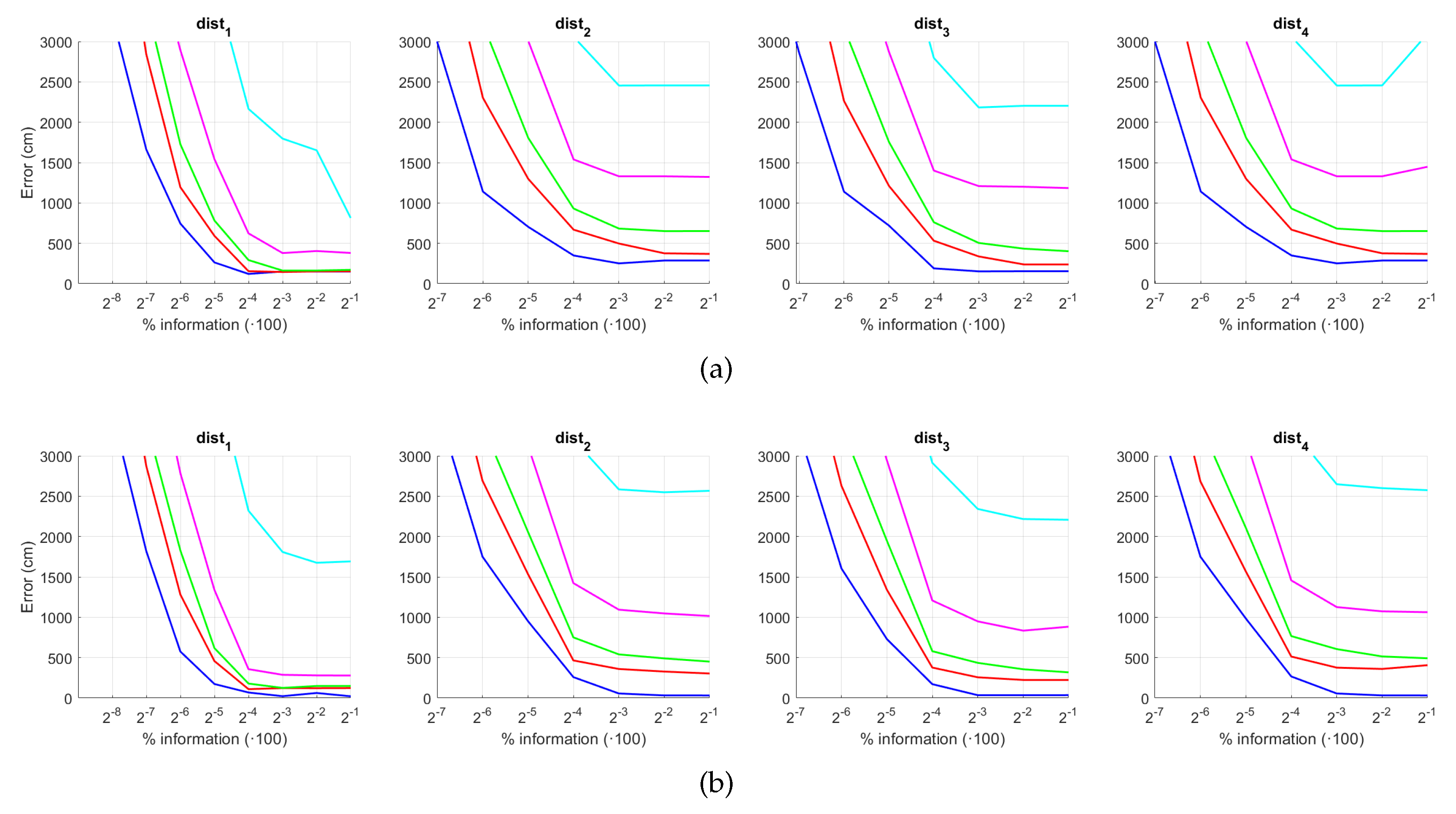
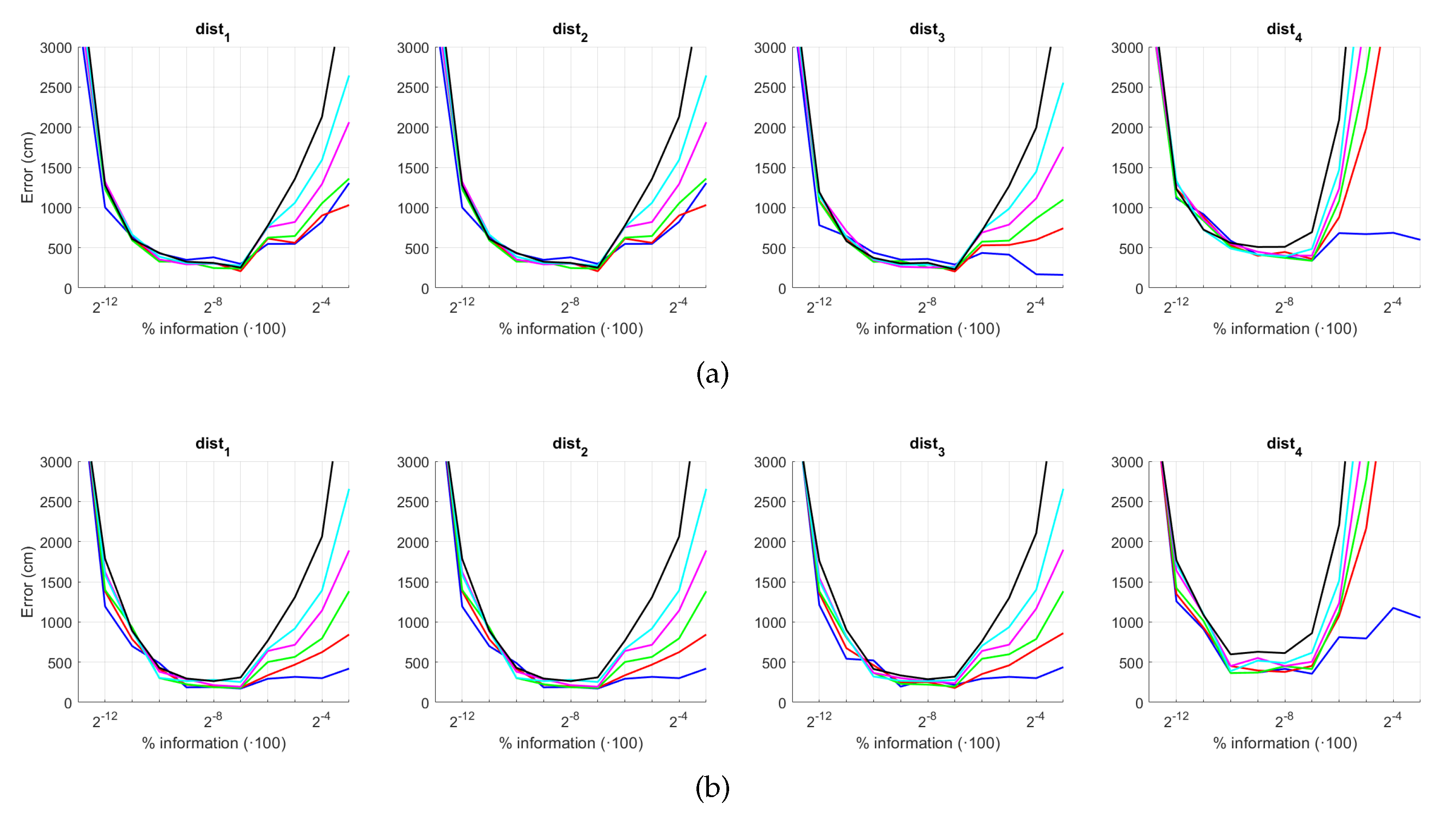
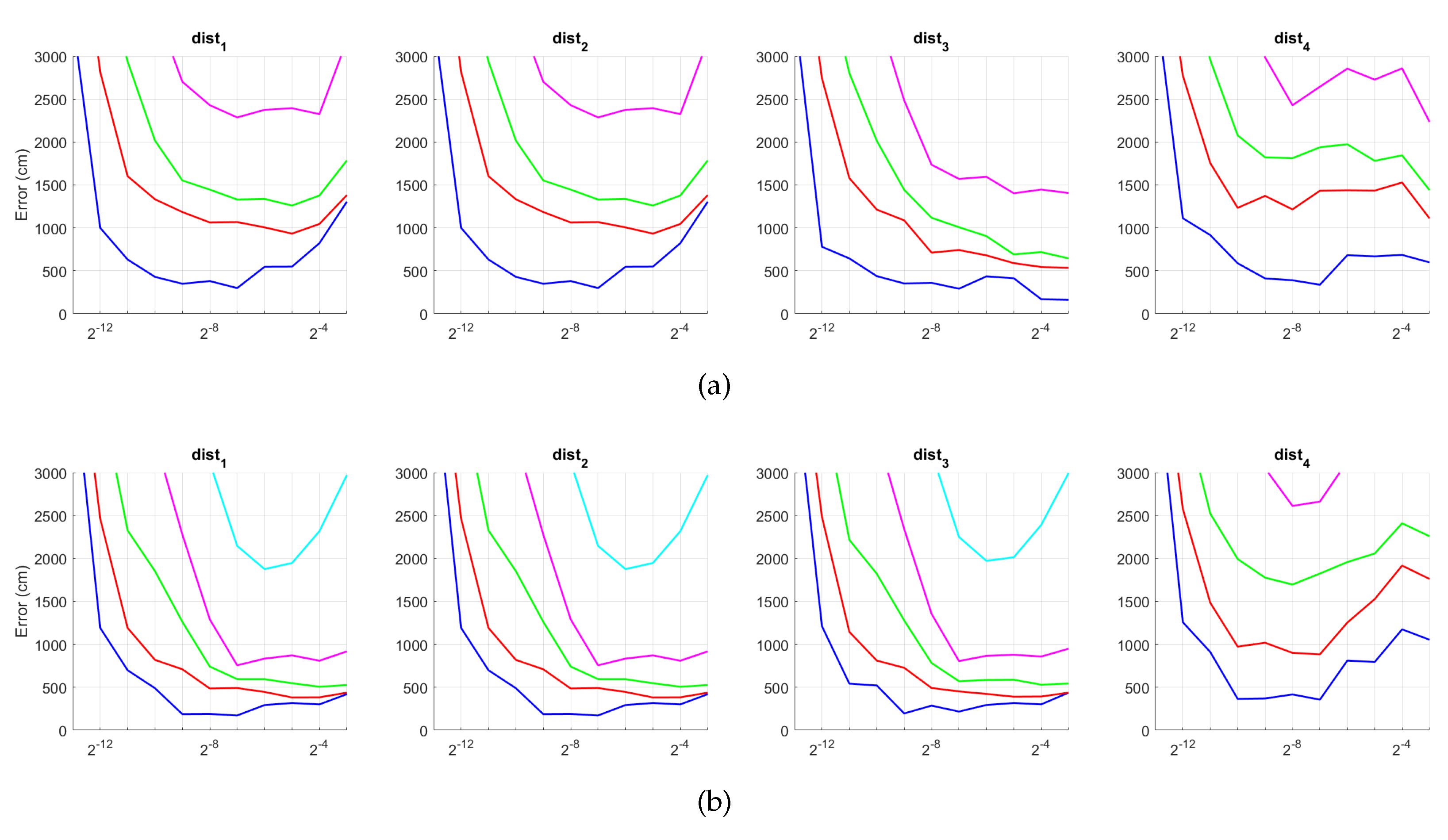
5. Results and Discussion
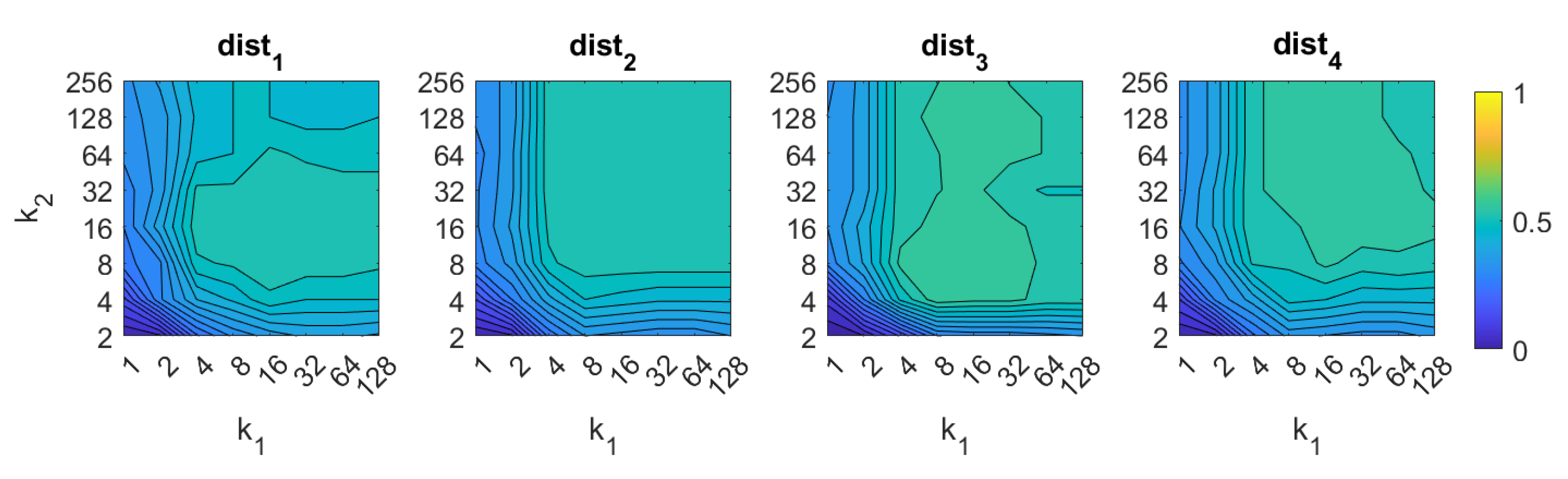
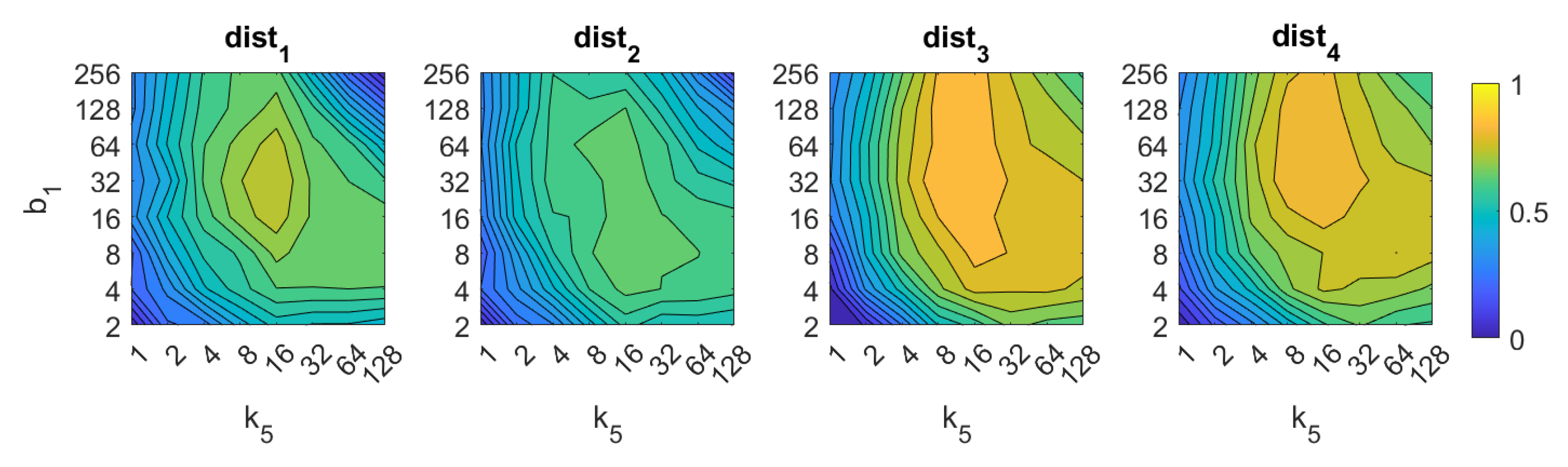
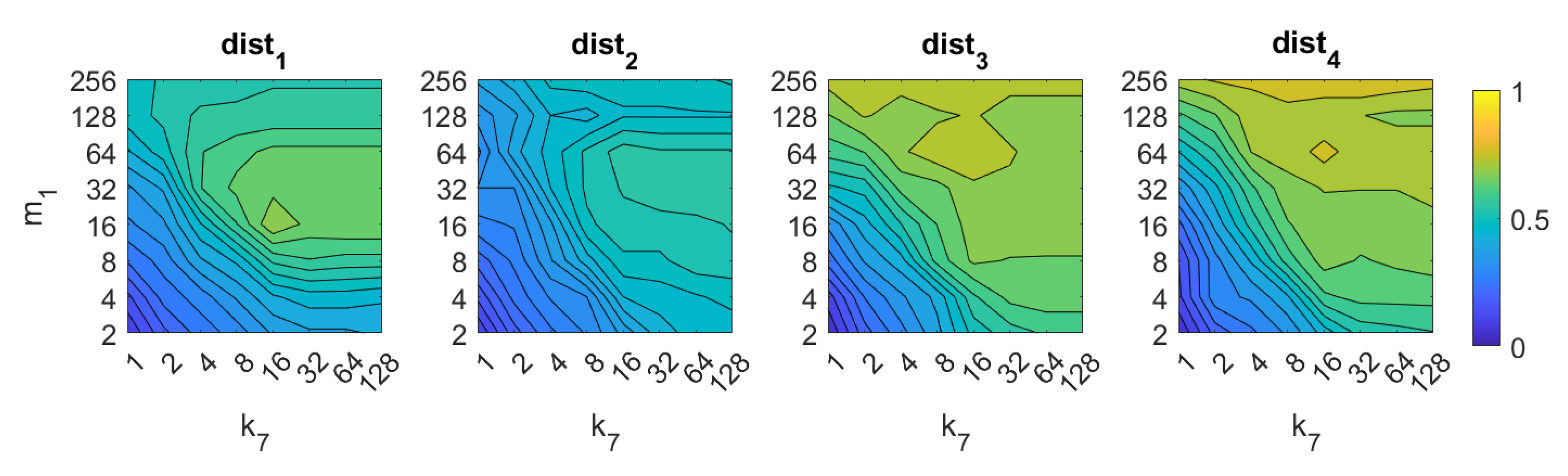
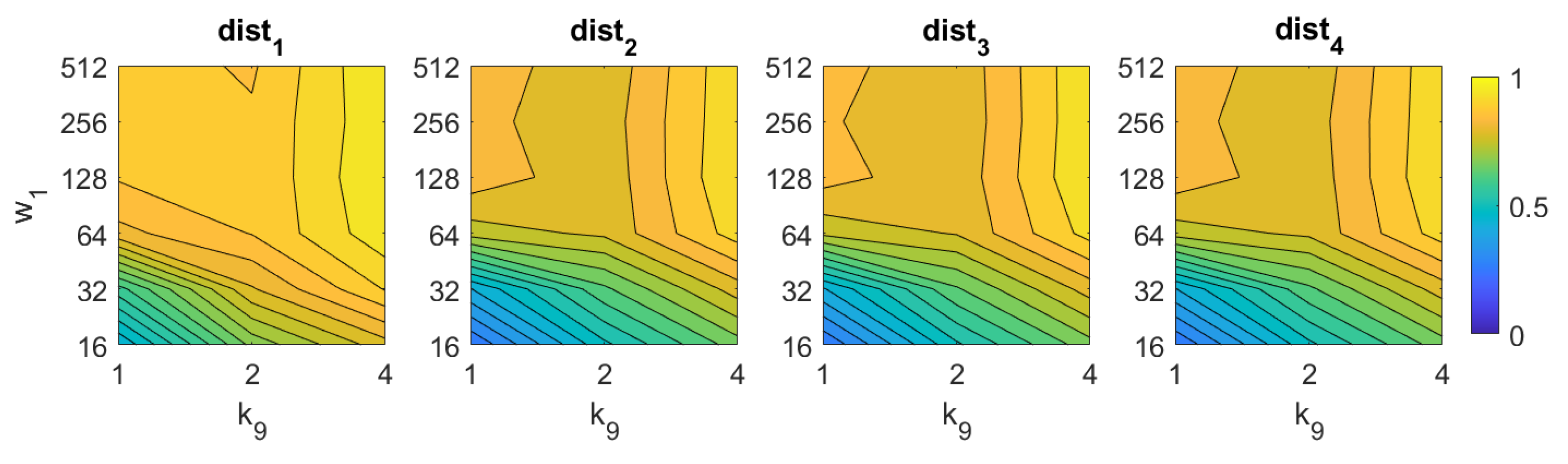
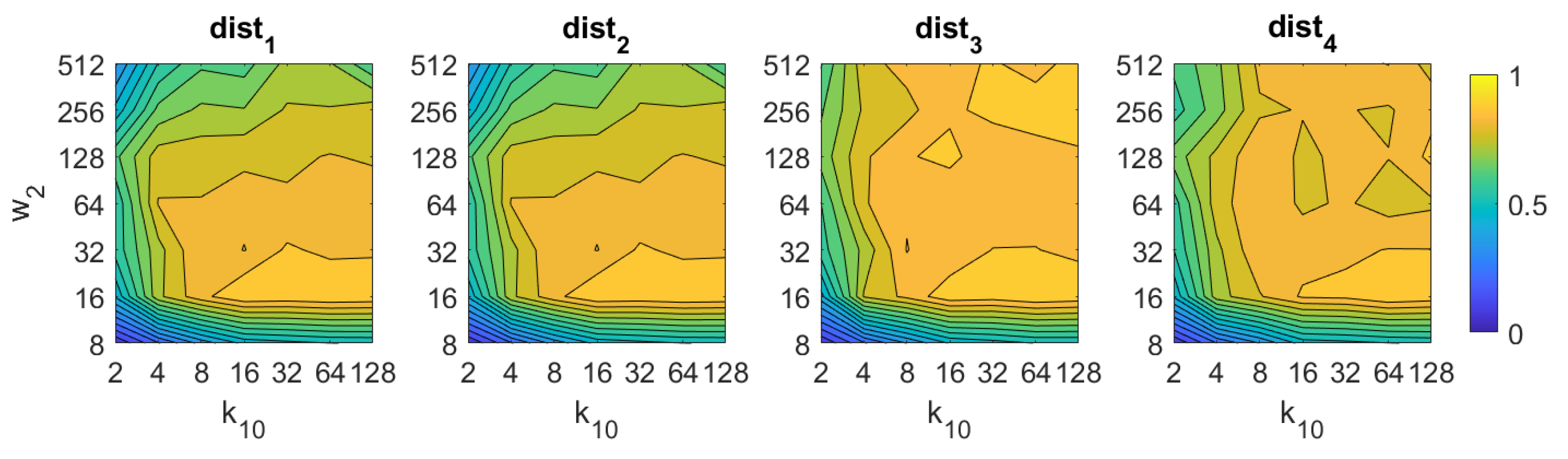
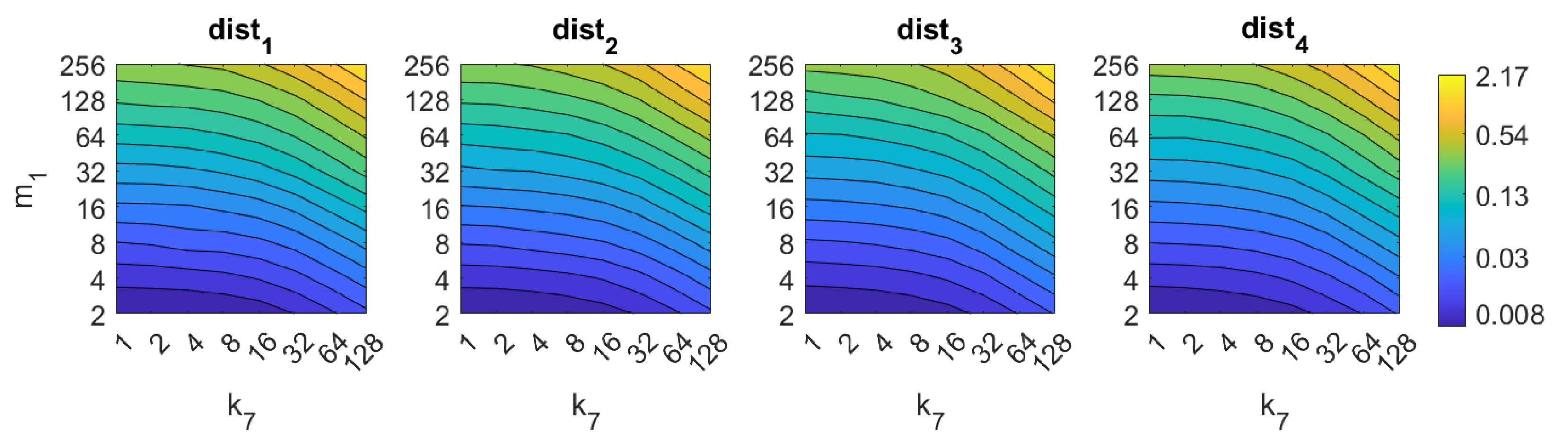
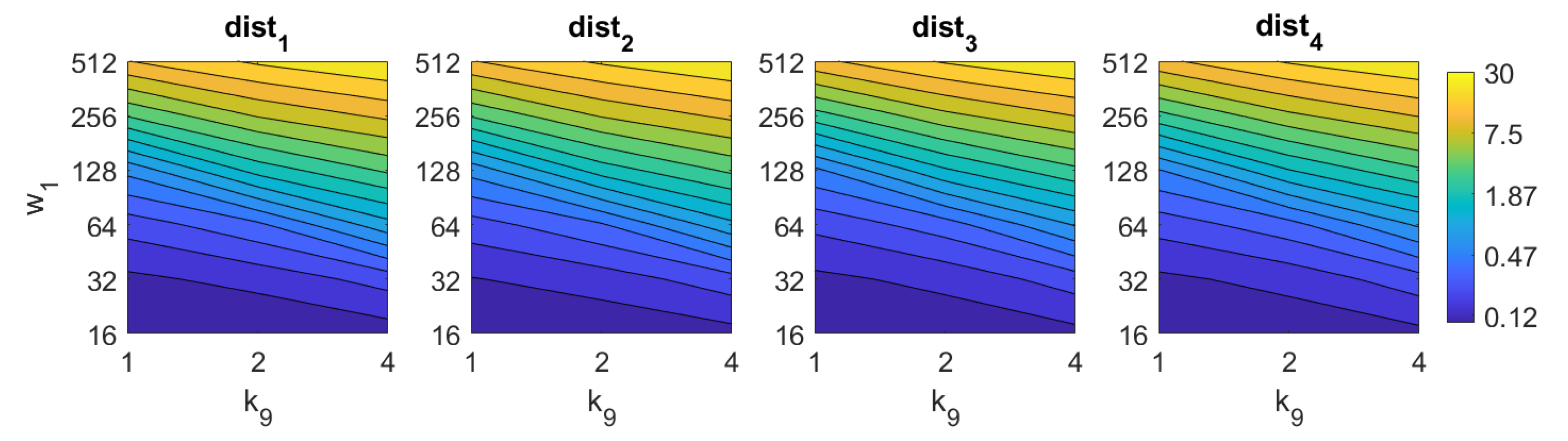
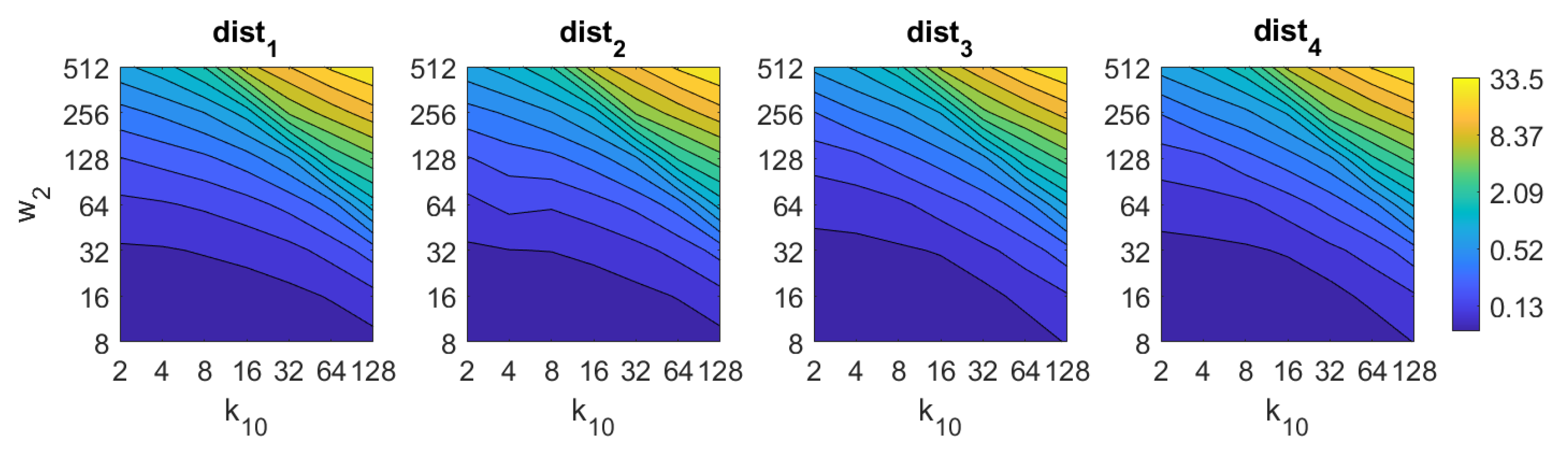
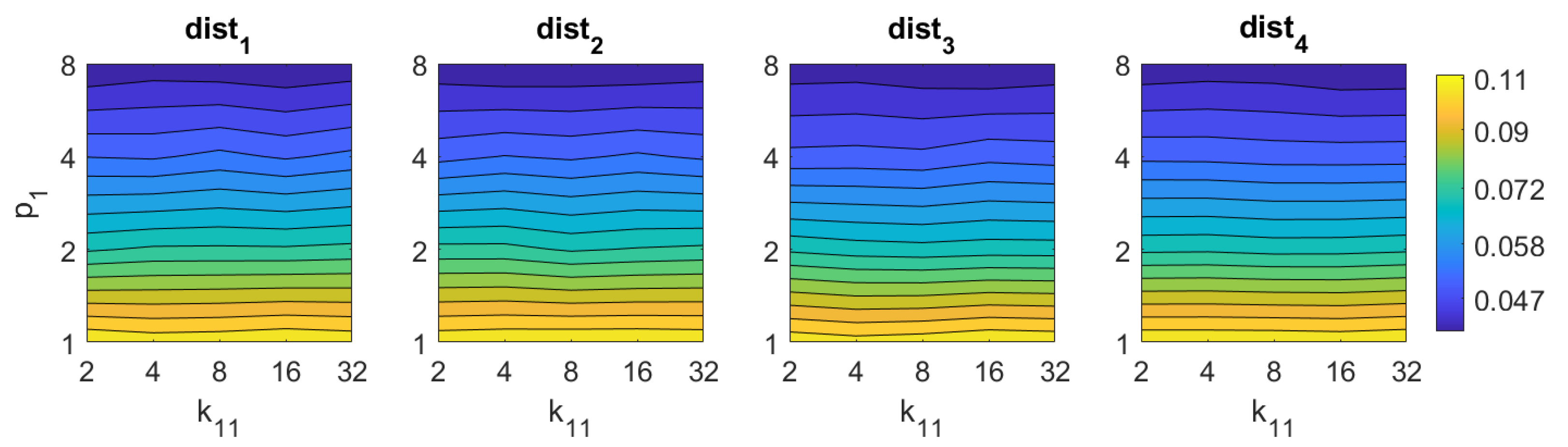
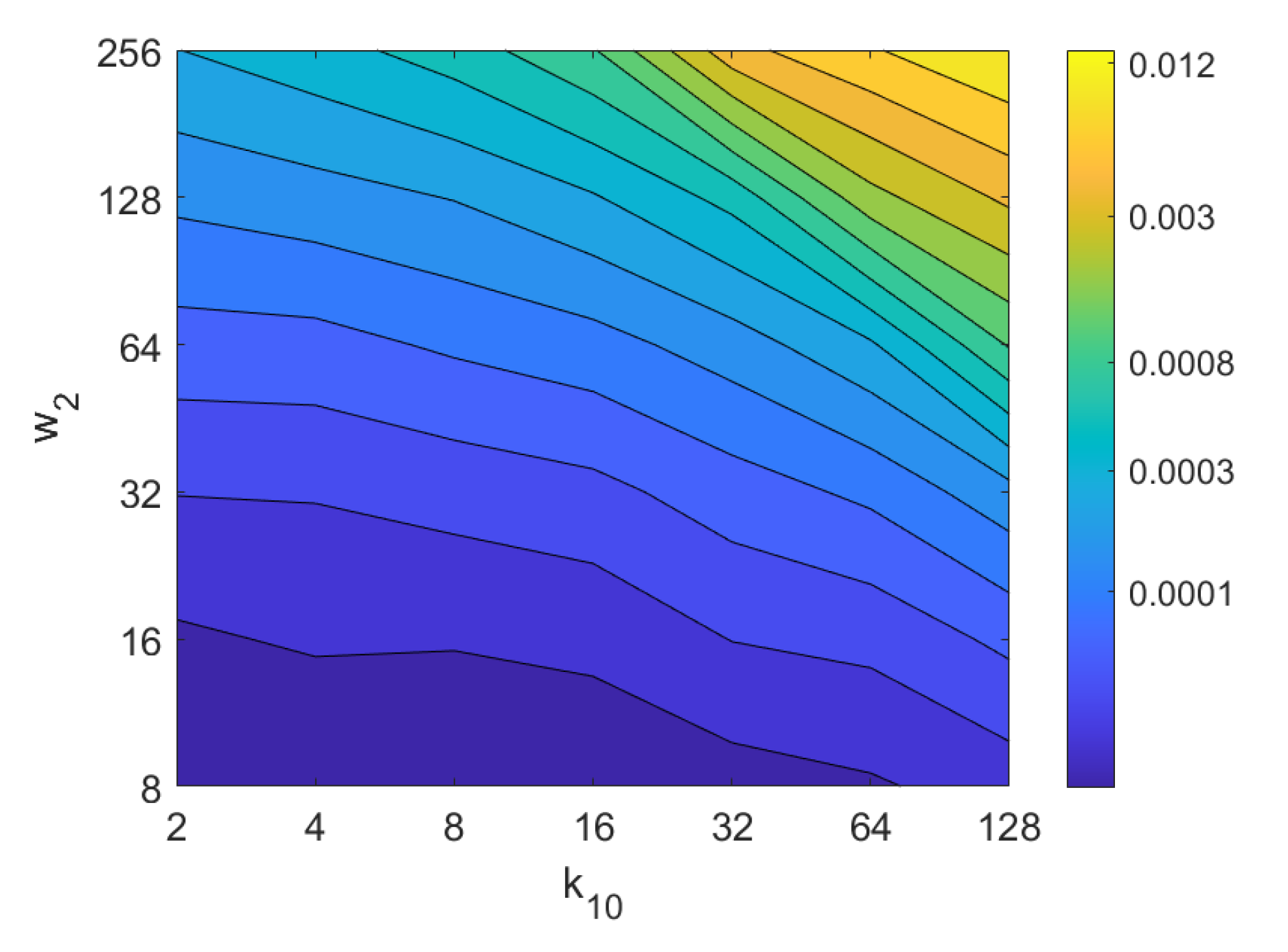
5.1. Image Retrieval Problem
- Weighted metric distance:If we consider , , the Minkowski distance is obtained. Two particular cases will be considered: (Manhattan distance), which is defined from the Minkowski distance with , and (Euclidean distance), doing .
- Pearson correlation coefficient. It is a similitude coefficient that can be obtained as:where and , , . It takes values in the range . From this similitude coefficient, a distance measure can be defined as:
- Inner product: It is also a similitude coefficient that can be calculated as the scalar product between the two vectors to compare.As shown in the equation, and are usually normalized. In this case, this measure is known as cosine similitude and takes values in the range . The corresponding distance value is:
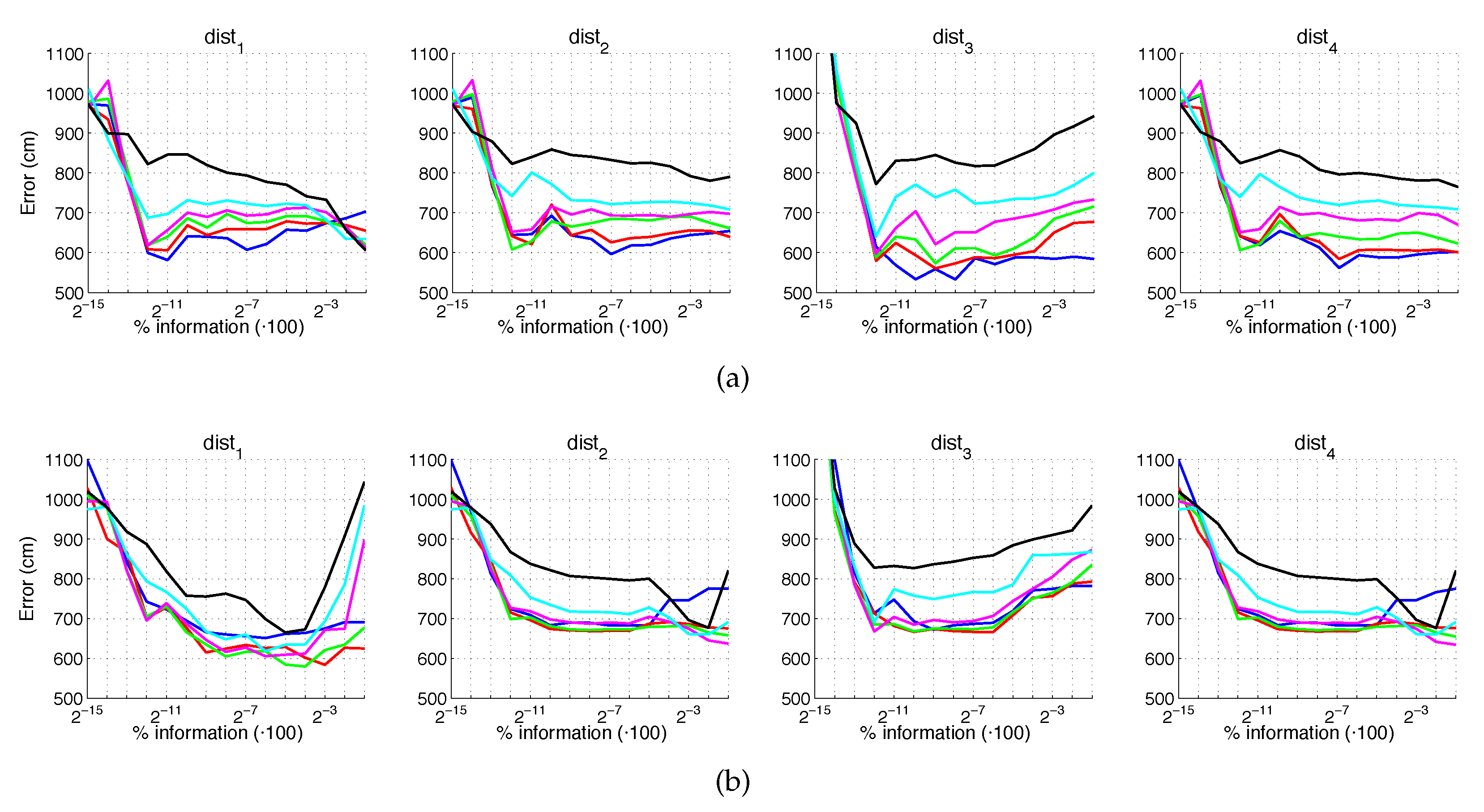
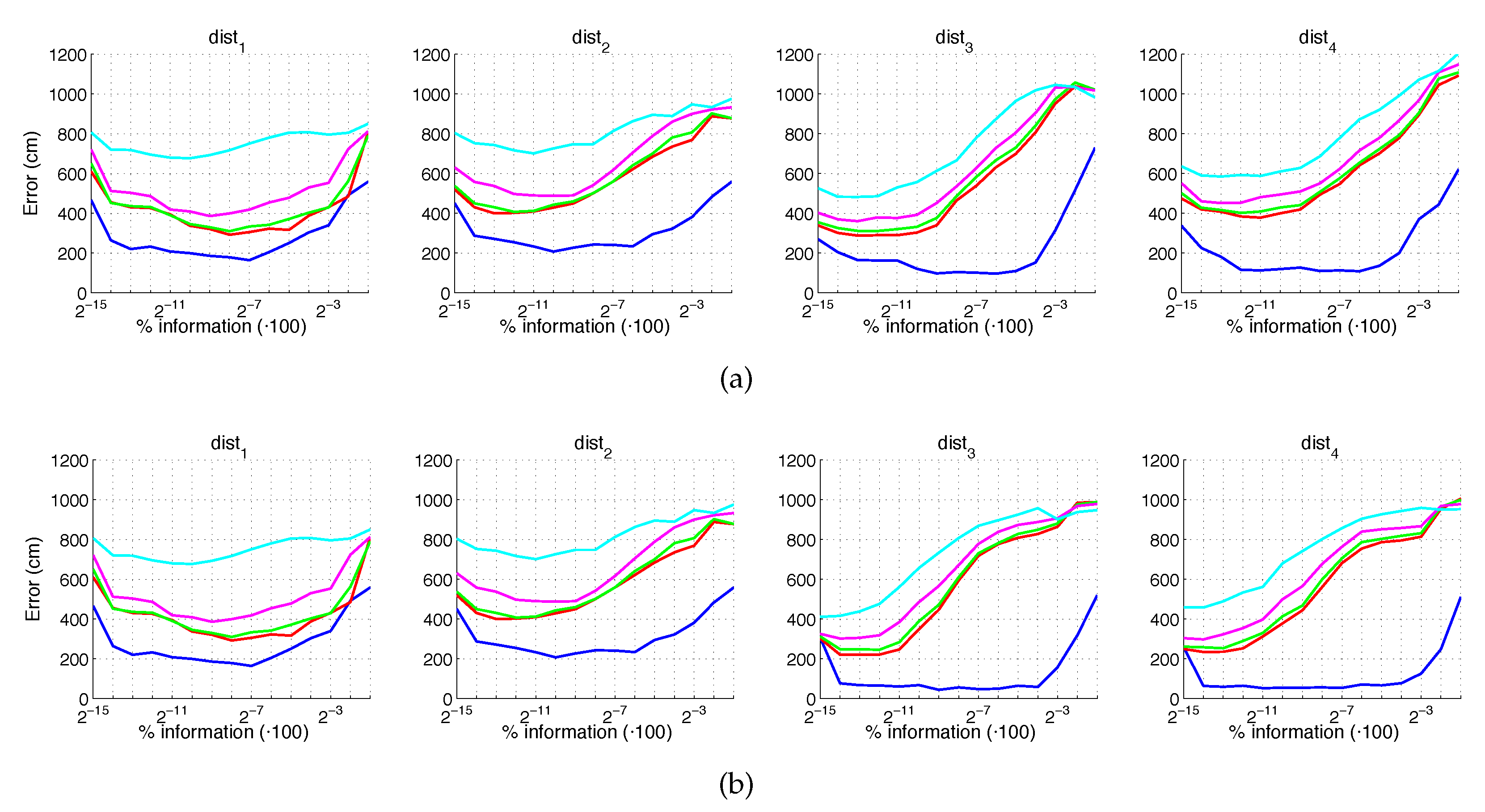
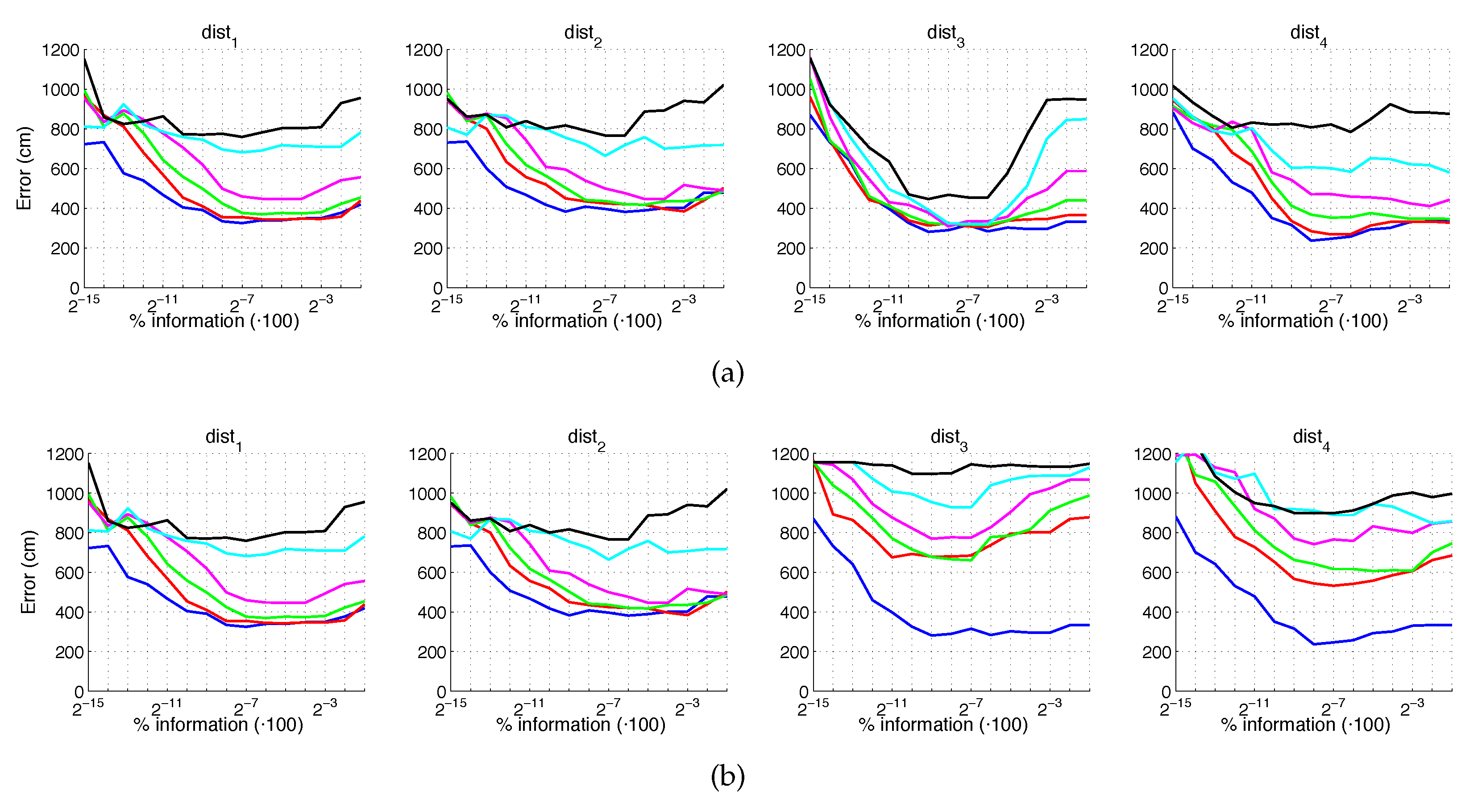
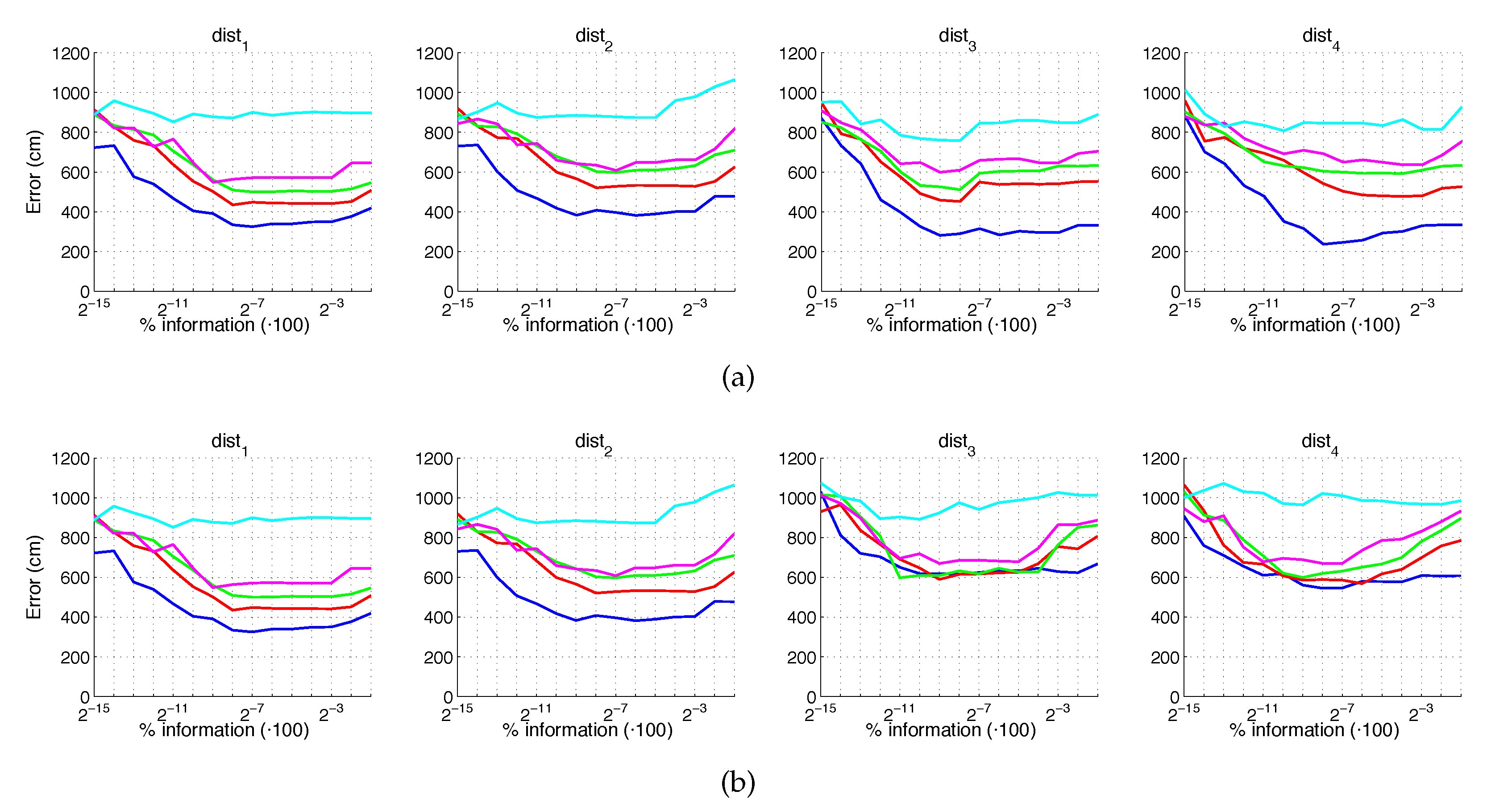
5.2. Estimation of the Position
5.3. Estimation of the Orientation
5.4. Evaluation with a Trajectory Dataset
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Reinoso, O.; Payá, L. Special Issue on Mobile Robots Navigation. Appl. Sci. 2020, 10, 1317. [Google Scholar] [CrossRef] [Green Version]
- Reinoso, O.; Payá, L. Special Issue on Visual Sensors. Sensors 2020, 20, 910. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Junior, J.M.; Tommaselli, A.; Moraes, M. Calibration of a catadioptric omnidirectional vision system with conic mirror. ISPRS J. Photogramm. Remote Sens. 2016, 113, 97–105. [Google Scholar] [CrossRef] [Green Version]
- Coors, B.; Paul Condurache, A.; Geiger, A. Spherenet: Learning spherical representations for detection and classification in omnidirectional images. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 518–533. [Google Scholar]
- Sun, C.; Hsiao, C.W.; Sun, M.; Chen, H.T. HorizonNet: Learning Room Layout With 1D Representation and Pano Stretch Data Augmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Pintore, G.; Agus, M.; Gobbetti, E. AtlantaNet: Inferring the 3D Indoor Layout from a Single 360 Image Beyond the Manhattan World Assumption. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 432–448. [Google Scholar]
- Xu, S.; Chou, W.; Dong, H. A Robust Indoor Localization System Integrating Visual Localization Aided by CNN-Based Image Retrieval with Monte Carlo Localization. Sensors 2019, 19, 249. [Google Scholar] [CrossRef] [Green Version]
- Leyva-Vallina, M.; Strisciuglio, N.; Lopez-Antequera, M.; Tylecek, R.; Blaich, M.; Petkov, N. TB-Places: A Data Set for Visual Place Recognition in Garden Environments. IEEE Access 2019, 7, 52277–52287. [Google Scholar] [CrossRef]
- Cebollada, S.; Payá, L.; Flores, M.; Peidró, A.; Reinoso, O. A state-of-the-art review on mobile robotics tasks using artificial intelligence and visual data. Expert Syst. Appl. 2020, 167, 114195. [Google Scholar] [CrossRef]
- Lowe, D. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-Up Robust Features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Calonder, M.; Lepetit, V.; Strecha, C.; Fua, P. BRIEF: Binary robust independent elementary features. In Proceedings of the European Conference on Computer Vision, Heraklion, Greece, 5–11 September 2010; pp. 778–792. [Google Scholar]
- Leutenegger, S.; Chli, M.; Siegwart, R.Y. BRISK: Binary robust invariant scalable keypoints. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2548–2555. [Google Scholar]
- Rublee, E.; Rabud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 ICCV 2011: International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Alahi, A.; Ortiz, R.; Vandergheynst, P. FREAK: Fast Retina Keypoint. In Proceedings of the CVPR 2012: Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 510–517. [Google Scholar]
- Yang, X.; Cheng, K.T.T. Local difference binary for ultrafast and distinctive feature description. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 188–194. [Google Scholar] [CrossRef]
- Krose, B.; Bunschoten, R.; Hagen, S.; Terwijn, B.; Vlassis, N. Visual homing in enviroments with anisotropic landmark distrubution. Auton. Robot. 2007, 23, 231–245. [Google Scholar]
- Menegatti, E.; Maeda, T.; Ishiguro, H. Image-based memory for robot navigation using properties of omnidirectional images. Robot. Auton. Syst. 2004, 47, 251–267. [Google Scholar] [CrossRef] [Green Version]
- Oliva, A.; Torralba, A. Modeling the shape of the scene: A holistic representation of the spatial envelope. Int. J. Comput. Vis. 2001, 42, 145–175. [Google Scholar] [CrossRef]
- Ulrich, I.; Nourbakhsh, I. Appearance-based place recognition for topological localization. In Proceedings of the IEEE International Conference on Robotics and Automation, San Francisco, CA, USA, 24–28 April 2000; pp. 1023–1029. [Google Scholar]
- Amorós, F.; Payá, L.; Mayol-Cuevas, W.; Jiménez, L.M.; Reinoso, O. Holistic Descriptors of Omnidirectional Color Images and Their Performance in Estimation of Position and Orientation. IEEE Access 2020, 8, 81822–81848. [Google Scholar] [CrossRef]
- Milford, M. Visual Route Recognition with a Handful of Bits. In Proceedings of the Robotics: Science and Systems, Sydney, NSW, Australia, 9–13 July 2012. [Google Scholar]
- Berenguer, Y.; Payá, L.; Valiente, D.; Peidró, A.; Reinoso, O. Relative Altitude Estimation Using Omnidirectional Imaging and Holistic Descriptors. Remote Sens. 2019, 11, 323. [Google Scholar] [CrossRef] [Green Version]
- Yuan, X.; Martínez-Ortega, J.F.; Fernández, J.A.S.; Eckert, M. AEKF-SLAM: A new algorithm for robotic underwater navigation. Sensors 2017, 17, 1174. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Luthardt, S.; Willert, V.; Adamy, J. LLama-SLAM: Learning high-quality visual landmarks for long-term mapping and localization. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 2645–2652. [Google Scholar]
- Cao, L.; Ling, J.; Xiao, X. Study on the Influence of Image Noise on Monocular Feature-Based Visual SLAM Based on FFDNet. Sensors 2020, 20, 4922. [Google Scholar] [CrossRef] [PubMed]
- Shamsfakhr, F.; Bigham, B.S.; Mohammadi, A. Indoor mobile robot localization in dynamic and cluttered environments using artificial landmarks. Eng. Comput. 2019, 36, 400–419. [Google Scholar] [CrossRef]
- Lin, J.; Peng, J.; Hu, Z.; Xie, X.; Peng, R. ORB-SLAM, IMU and Wheel Odometry Fusion for Indoor Mobile Robot Localization and Navigation. Acad. J. Comput. Inf. Sci. 2020, 3. [Google Scholar] [CrossRef]
- Gil, A.; Mozos, O.M.; Ballesta, M.; Reinoso, O. A comparative evaluation of interest point detectors and local descriptors for visual SLAM. Mach. Vis. Appl. 2010, 21, 905–920. [Google Scholar] [CrossRef] [Green Version]
- Dong, X.; Dong, X.; Dong, J.; Zhou, H. Monocular Visual-IMU Odometry: A Comparative Evaluation of Detector–Descriptor-Based Methods. IEEE Trans. Intell. Transp. Syst. 2019, 21, 2471–2484. [Google Scholar] [CrossRef]
- Menegatti, E.; Zocaratto, M.; Pagello, E.; Ishiguro, H. Image-based Monte Carlo Localisation with Omnidirectional Images. Robot. Auton. Syst. 2004, 48, 17–30. [Google Scholar] [CrossRef] [Green Version]
- Murillo, A.; Guerrero, J.; Sagües, C.; Filliat, D. Surf features for efficient robot localization with omnidirectional images. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Rome, Italy, 10–14 April 2007; pp. 3901–3907. [Google Scholar]
- Siagian, C.; Itti, L. Biologically Inspired Mobile Robot Vision Localization. IEEE Trans. Robot. 2009, 25, 861–873. [Google Scholar] [CrossRef] [Green Version]
- Payá, L.; Amorós, F.; Fernández, L.; Reinoso, O. Performance of Global-Appearance Descriptors in Map Building and Localization Using Omnidirectional Vision. Sensors 2014, 14, 3033–3064. [Google Scholar] [CrossRef]
- Khaliq, A.; Ehsan, S.; Chen, Z.; Milford, M.; McDonald-Maier, K. A holistic visual place recognition approach using lightweight cnns for significant viewpoint and appearance changes. IEEE Trans. Robot. 2019, 36, 561–569. [Google Scholar] [CrossRef] [Green Version]
- Román, V.; Payá, L.; Cebollada, S.; Reinoso, Ó. Creating Incremental Models of Indoor Environments through Omnidirectional Imaging. Appl. Sci. 2020, 10, 6480. [Google Scholar] [CrossRef]
- Marinho, L.B.; Almeida, J.S.; Souza, J.W.M.; Albuquerque, V.H.C.; Rebouças Filho, P.P. A novel mobile robot localization approach based on topological maps using classification with reject option in omnidirectional images. Expert Syst. Appl. 2017, 72, 1–17. [Google Scholar] [CrossRef]
- Ma, J.; Zhao, J. Robust topological navigation via convolutional neural network feature and sharpness measure. IEEE Access 2017, 5, 20707–20715. [Google Scholar] [CrossRef]
- Paya, L.; Reinoso, O.; Berenguer, Y.; Ubeda, D. Using omnidirectional vision to create a model of the environment: A comparative evaluation of global appearance descriptors. J. Sens. 2016, 2016, 1–21. [Google Scholar] [CrossRef] [Green Version]
- Arroyo, R.; Alcantarilla, P.F.; Bergasa, L.M.; Yebes, J.J.; Bronte, S. Fast and effective visual place recognition using binary codes and disparity information. In Proceedings of the 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems, Chicago, IL, USA, 14–18 September 2014; pp. 3089–3094. [Google Scholar]
- Berenguer, Y.; Payá, L.; Peidró, A.; Gil, A.; Reinoso, O. Nearest Position Estimation Using Omnidirectional Images and Global Appearance Descriptors. In Robot 2015: Second Iberian Robotics Conference; Springer: Cham, Switzerland, 2016; pp. 517–529. [Google Scholar]
- Ishiguro, H.; Tsuji, S. Image-based memory of environment. In Proceedings of the 1996 IEEE/RSJ International Conference on Intelligent Robots and Systems ’96 (IROS 96), Osaka, Japan, 4–8 November 1996; Volume 2, pp. 634–639. [Google Scholar] [CrossRef]
- Sturzl, W.; Mallot, H. Efficient visual homing based on Fourier transformed panoramic images. Robot. Auton. Syst. 2006, 54, 300–313. [Google Scholar] [CrossRef]
- Horst, M.; Möller, R. Visual place recognition for autonomous mobile robots. Robotics 2017, 6, 9. [Google Scholar] [CrossRef] [Green Version]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients fot Human Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; Volume II, pp. 886–893. [Google Scholar]
- Zhu, Q.; Avidan, S.; Yeh, M.C.; Cheng, K.T. Fast Human Detection Using a Cascade of Histograms of Oriented Gradients. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; Volume 2, pp. 1491–1498. [Google Scholar] [CrossRef]
- Hofmeister, M.; Liebsch, M.; Zell, A. Visual self-localization for small mobile robots with weighted gradient orientation histograms. In Proceedings of the 40th International Symposium on Robotics, Barcelona, Spain, 10–13 March 2009; IFR: Frankfurt am Main, Germany, 2009; pp. 87–91. [Google Scholar]
- Hofmeister, M.; Vorst, P.; Zell, A. A comparison of Efficient Global Image Features for Localizing Small Mobile Robots. In Proceedings of the 41st International Symposium on Robotics, Munich, Germany, 7–9 June 2010; pp. 143–150. [Google Scholar]
- Aslan, M.F.; Durdu, A.; Sabanci, K.; Mutluer, M.A. CNN and HOG based comparison study for complete occlusion handling in human tracking. Measurement 2020, 158, 107704. [Google Scholar] [CrossRef]
- Neumann, D.; Langner, T.; Ulbrich, F.; Spitta, D.; Goehring, D. Online vehicle detection using Haar-like, LBP and HOG feature based image classifiers with stereo vision preselection. In Proceedings of the 2017 IEEE Intelligent Vehicles Symposium (IV), Los Angeles, CA, USA, 11–14 June 2017; pp. 773–778. [Google Scholar]
- Payá, L.; Fernández, L.; Gil, A.; Reinoso, O. Map Building and Monte Carlo Localization Using Global Appearance of Omnidirectional Images. Sensors 2010, 10, 11468–11497. [Google Scholar] [CrossRef]
- Oliva, A.; Torralba, A. Building the gist of ascene: The role of global image features in recognition. Prog. Brain Res. Spec. Issue Vis. Percept. 2006, 155, 23–36. [Google Scholar]
- Torralba, A. Contextual priming for object detection. Int. J. Comput. Vis. 2003, 53, 169–191. [Google Scholar] [CrossRef]
- Siagian, C.; Itti, L. Rapid Biologically-Inspired Scene Classification Using Features Shared with Visual Attention. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 300–312. [Google Scholar] [CrossRef]
- Chang, C.K.; Siagian, C.; Itti, L. Mobile robot vision navigation and localization using Gist and Saliency. In Proceedings of the 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Taipei, Taiwan, 18–22 October 2010; pp. 4147–4154. [Google Scholar] [CrossRef] [Green Version]
- Murillo, A.; Singh, G.; Kosecka, J.; Guerrero, J. Localization in Urban Environments Using a Panoramic Gist Descriptor. IEEE Trans. Robot. 2013, 29, 146–160. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, H. Visual loop closure detection with a compact image descriptor. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligen Robots and Systems (IROS), Vilamoura-Algarve, Portugal, 7–12 October 2012; pp. 1051–1056. [Google Scholar]
- Su, Z.; Zhou, X.; Cheng, T.; Zhang, H.; Xu, B.; Chen, W. Global localization of a mobile robot using lidar and visual features. In Proceedings of the 2017 IEEE International Conference on Robotics and Biomimetics (ROBIO), Macau, Macao, 5–8 December 2017; pp. 2377–2383. [Google Scholar]
- Andreasson, H.; Treptow, A.; Duckett, T. Localization for mobile robots using panoramic vision, local features and particle filter. In Proceedings of the 2005 IEEE International Conference on Robotics and Automation, Barcelona, Spain, 18–22 April 2005; pp. 3348–3353. [Google Scholar]
- Agrawal, M.; Konolige, K.; Blas, M.R. Censure: Center surround extremas for realtime feature detection and matching. In Proceedings of the European Conference on Computer Vision, Marseille, France, 12–18 October 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 102–115. [Google Scholar]
- Badino, H.; Huber, D.; Kanade, T. Real-time topometric localization. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, Saint Paul, MN, USA, 14–18 May 2012; pp. 1635–1642. [Google Scholar]
- Zhang, M.; Han, S.; Wang, S.; Liu, X.; Hu, M.; Zhao, J. Stereo Visual Inertial Mapping Algorithm for Autonomous Mobile Robot. In Proceedings of the 2020 3rd International Conference on Intelligent Robotic and Control Engineering (IRCE), Oxford, UK, 10–12 August 2020; pp. 97–104. [Google Scholar]
- Aladem, M.; Rawashdeh, S.A. Lightweight visual odometry for autonomous mobile robots. Sensors 2018, 18, 2837. [Google Scholar]
- Sünderhauf, N.; Protzel, P. Brief-gist-closing the loop by simple means. In Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Francisco, CA, USA, 25–30 September 2011; pp. 1234–1241. [Google Scholar]
- Radon, J. 1.1 über die bestimmung von funktionen durch ihre integralwerte längs gewisser mannigfaltigkeiten. Class. Pap. Mod. Diagn. Radiol. 2005, 5, 21. [Google Scholar]
- Hoang, T.V.; Tabbone, S. A geometric invariant shape descriptor based on the Radon, Fourier, and Mellin transforms. In Proceedings of the 2010 20th International Conference on Pattern Recognition (ICPR), Istanbul, Turkey, 23–26 August 2010; pp. 2085–2088. [Google Scholar]
- Hasegawa, M.; Tabbone, S. A shape descriptor combining logarithmic-scale histogram of radon transform and phase-only correlation function. In Proceedings of the 2011 International Conference on Document Analysis and Recognition, Beijing, China, 18–21 September 2011; pp. 182–186. [Google Scholar]
- Berenguer, Y.; Payá, L.; Ballesta, M.; Reinoso, O. Position estimation and local mapping using omnidirectional images and global appearance descriptors. Sensors 2015, 15, 26368–26395. [Google Scholar] [PubMed] [Green Version]
- Juliá, M.; Gil, A.; Reinoso, O. A comparison of path planning strategies for autonomous exploration and mapping of unknown environments. Auton. Robot. 2012, 33, 427–444. [Google Scholar] [CrossRef]
- Liu, S.; Li, S.; Pang, L.; Hu, J.; Chen, H.; Zhang, X. Autonomous Exploration and Map Construction of a Mobile Robot Based on the TGHM Algorithm. Sensors 2020, 20, 490. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- ARVC. Automation, Robotics and Computer Vision Research Group. Miguel Hernández University. Spain. Quorum 5 Set of Images. Available online: http://arvc.umh.es/db/images/quorumv/ (accessed on 29 December 2020).
- Pronobis, A.; Caputo, B. COLD: COsy Localization Database. Int. J. Robot. Res. (IJRR) 2009, 28, 588–594. [Google Scholar] [CrossRef] [Green Version]














































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Descriptor | Parameters |
|---|---|
| FS | number of rows, position descriptor number of columns, position descriptor number of rows, orientation descriptor number of columns, orientation descriptor |
| HOG | number of bins per histogram, position descriptor number of horizontal cells, position descriptor number of bins per histogram, orientation descriptor width of vertical cells, orientation descriptor distance between vertical cells, orientation descriptor number of vertical cells, orientation descriptor |
| Gist | number of orientations (Gabor filters), position descriptor number of horizontal blocks, position descriptor number of orientations (Gabor filters), orientation descriptor width of vertical blocks, orientation descriptor distance between vertical blocks, orientation descriptor number of vertical blocks, orientation descriptor |
| WS | number of windows per cell, descriptor number of horizontal blocks, descriptor horizontal space between windows, descriptor |
| BG | number of windows per cell, descriptor number of horizontal blocks, descriptor |
| RT | degrees between lines where Radon is calculated, matrix r number of columns, position descriptor number of columns, orientation descriptor omnidirectional images’ size is |
| Descriptor | Localization | Orientation |
|---|---|---|
| FS | ||
| HOG | ||
| Gist | ||
| WS | ||
| BG | ||
| RT–F | ||
| RT–POC | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Román, V.; Payá, L.; Peidró, A.; Ballesta, M.; Reinoso, O. The Role of Global Appearance of Omnidirectional Images in Relative Distance and Orientation Retrieval. Sensors 2021, 21, 3327. https://doi.org/10.3390/s21103327
Román V, Payá L, Peidró A, Ballesta M, Reinoso O. The Role of Global Appearance of Omnidirectional Images in Relative Distance and Orientation Retrieval. Sensors. 2021; 21(10):3327. https://doi.org/10.3390/s21103327
Chicago/Turabian StyleRomán, Vicente, Luis Payá, Adrián Peidró, Mónica Ballesta, and Oscar Reinoso. 2021. "The Role of Global Appearance of Omnidirectional Images in Relative Distance and Orientation Retrieval" Sensors 21, no. 10: 3327. https://doi.org/10.3390/s21103327