Underwater Object Detection and Reconstruction Based on Active Single-Pixel Imaging and Super-Resolution Convolutional Neural Network


Abstract
:1. Introduction
- An optical imaging system based on SPI is developed for imaging objects in the underwater environment. Our experimental results validated that the recovered object by the underwater SPI system is affected by scattering and absorptions.
- Compressive sensing-based super-resolution convolutional neural network (CS-SRCNN) is implemented by combining the advantages of the SRCNN and SPI system. The newly introduced CS-SRCNN takes reconstructed underwater SPI images to train the network and to predict high-resolution images.
- We also demonstrate the effectiveness of our technique through simulation. In the simulation, the proposed method can restore objects with a low sampling rate and can produce more robust reconstructions. Our experimental results also validated that the recovered object by the underwater SPI system is affected by scattering and absorptions.
- We experimentally demonstrated reconstruction to get better results with a low sampling rate of only 30%.
2. Underwater Object Reconstruction
2.1. Theory
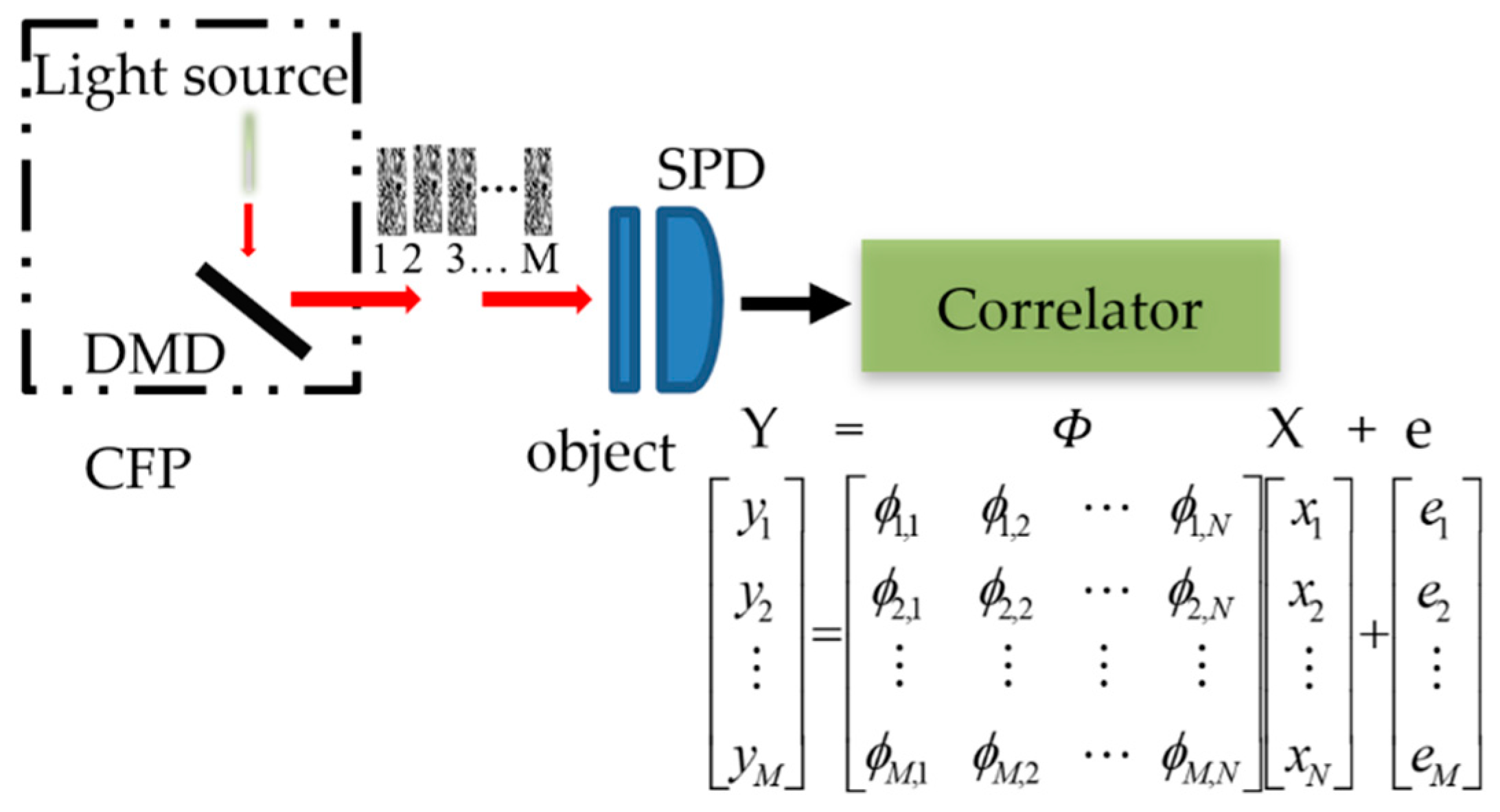
2.1.1. Compressive Sensing
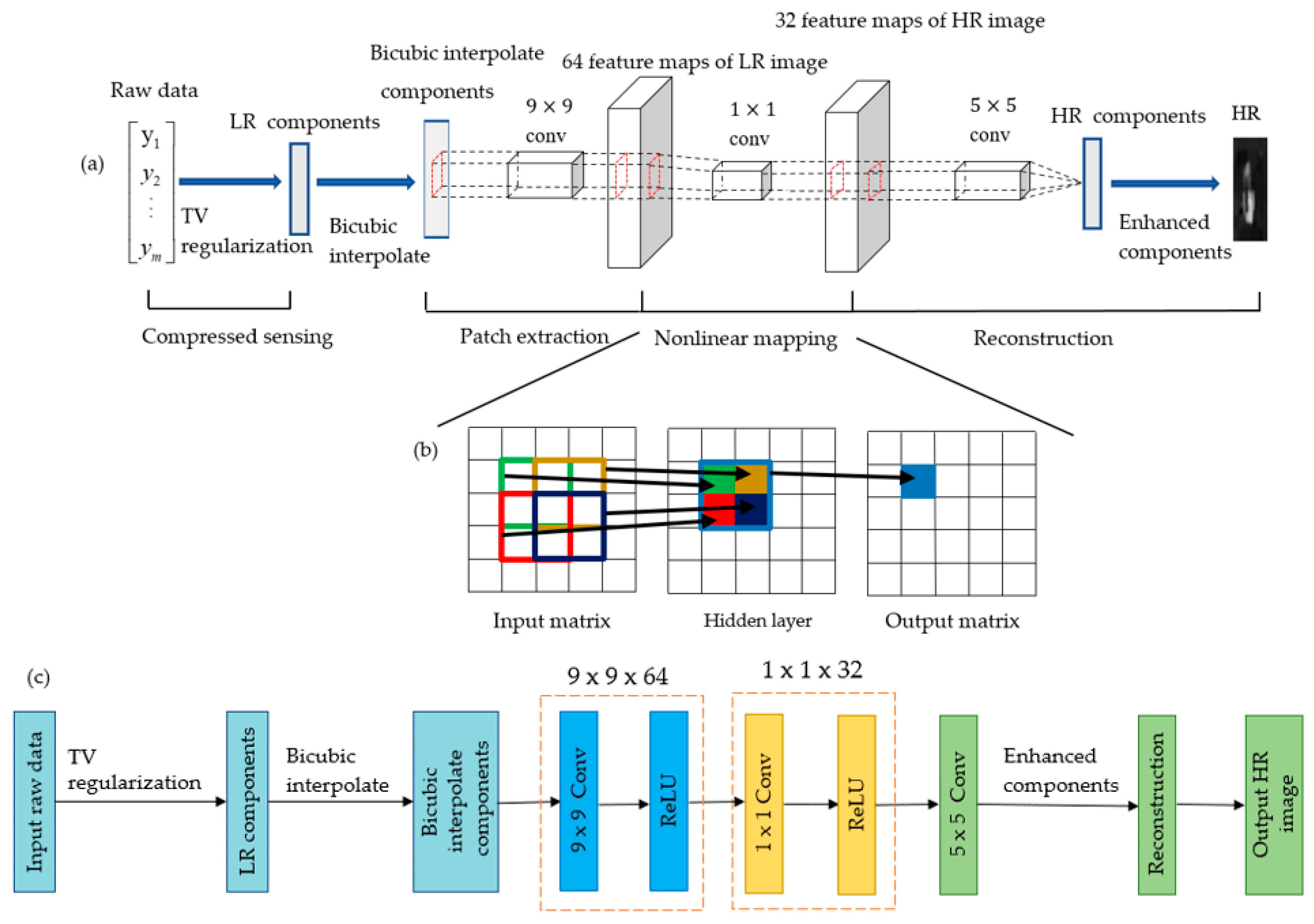
2.1.2. The Super-Resolution Convolutional Neural Network
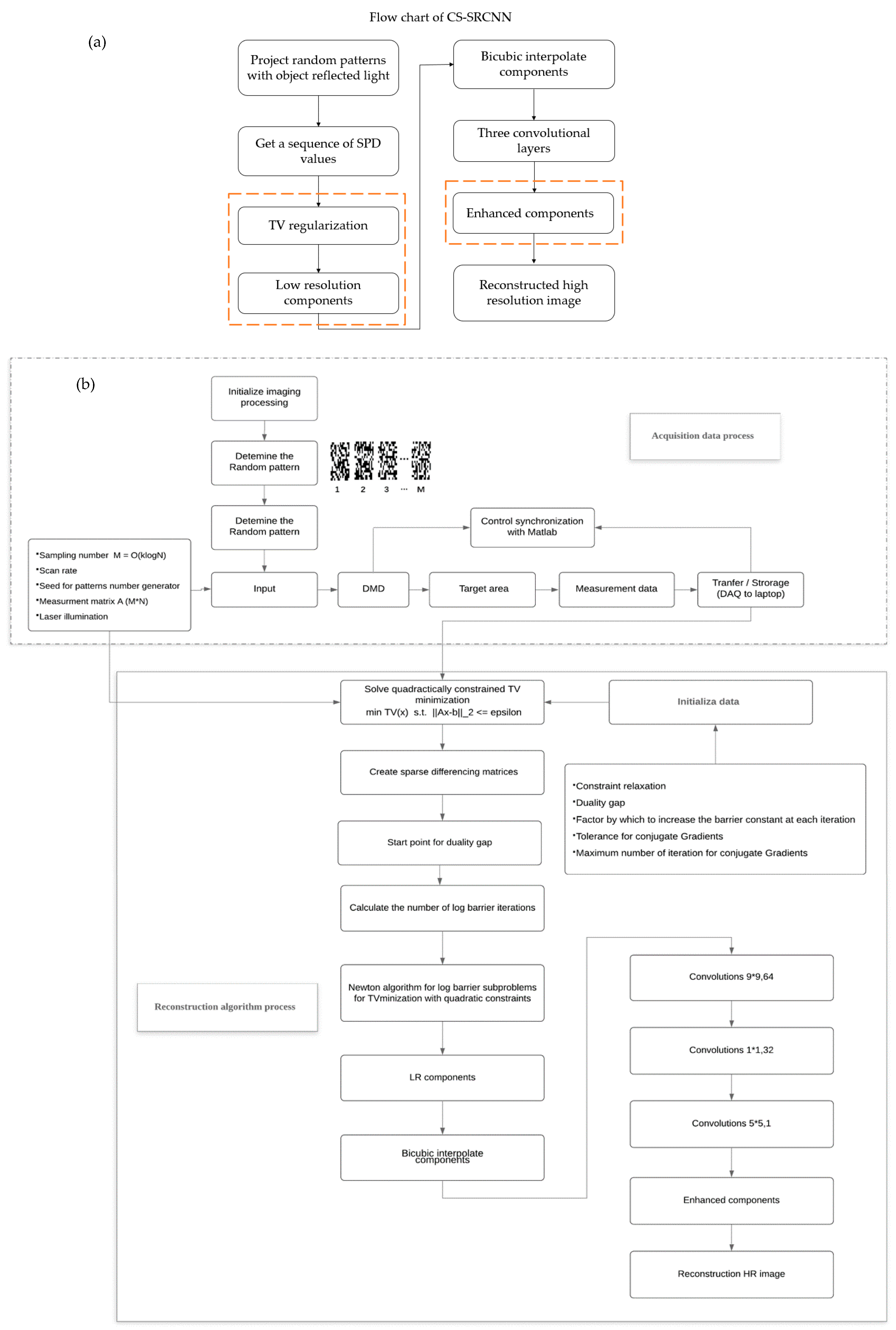
2.2. The Reconstruction of Underwater Single-Pixel Imaging based on Compressive Sensing and Super-Resolution Convolutional Neural Network
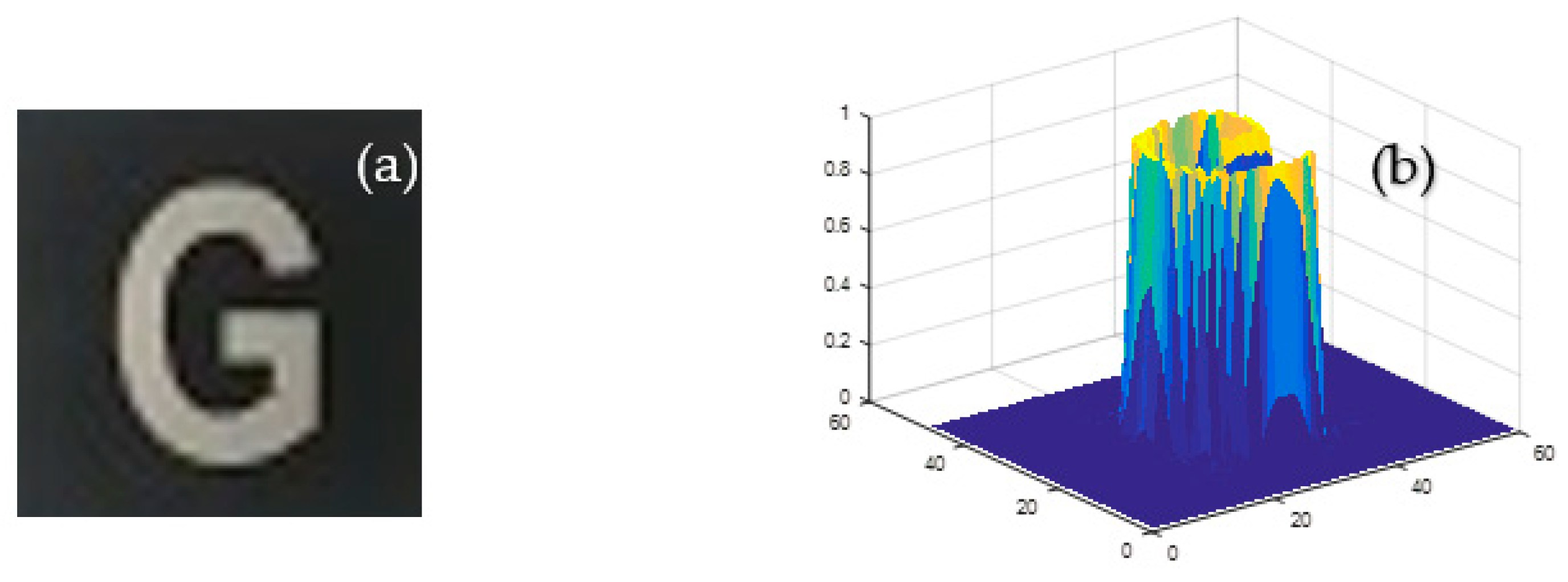
3. Simulation Results and Analysis
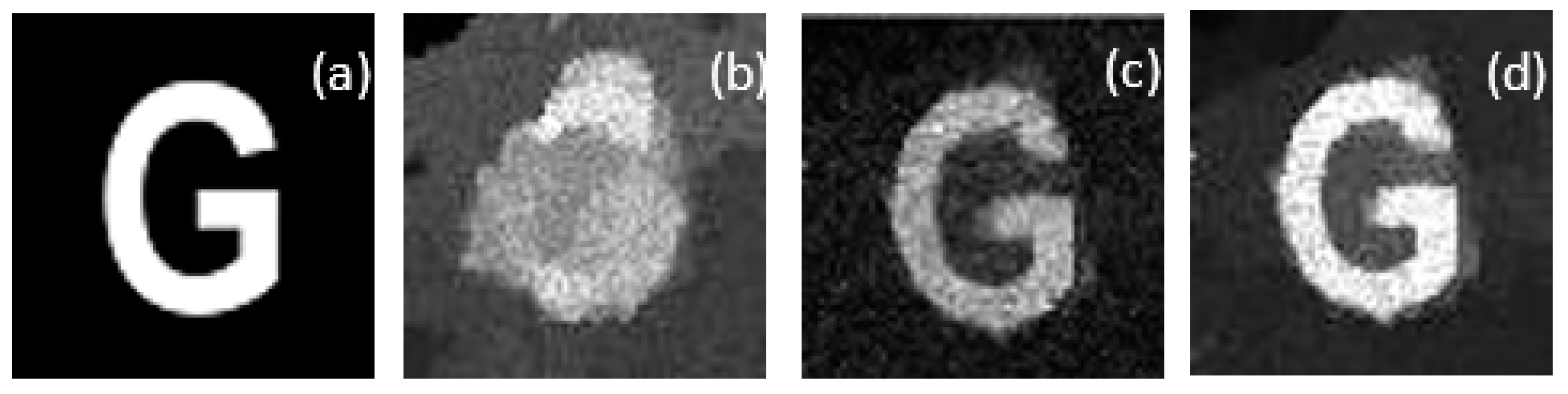
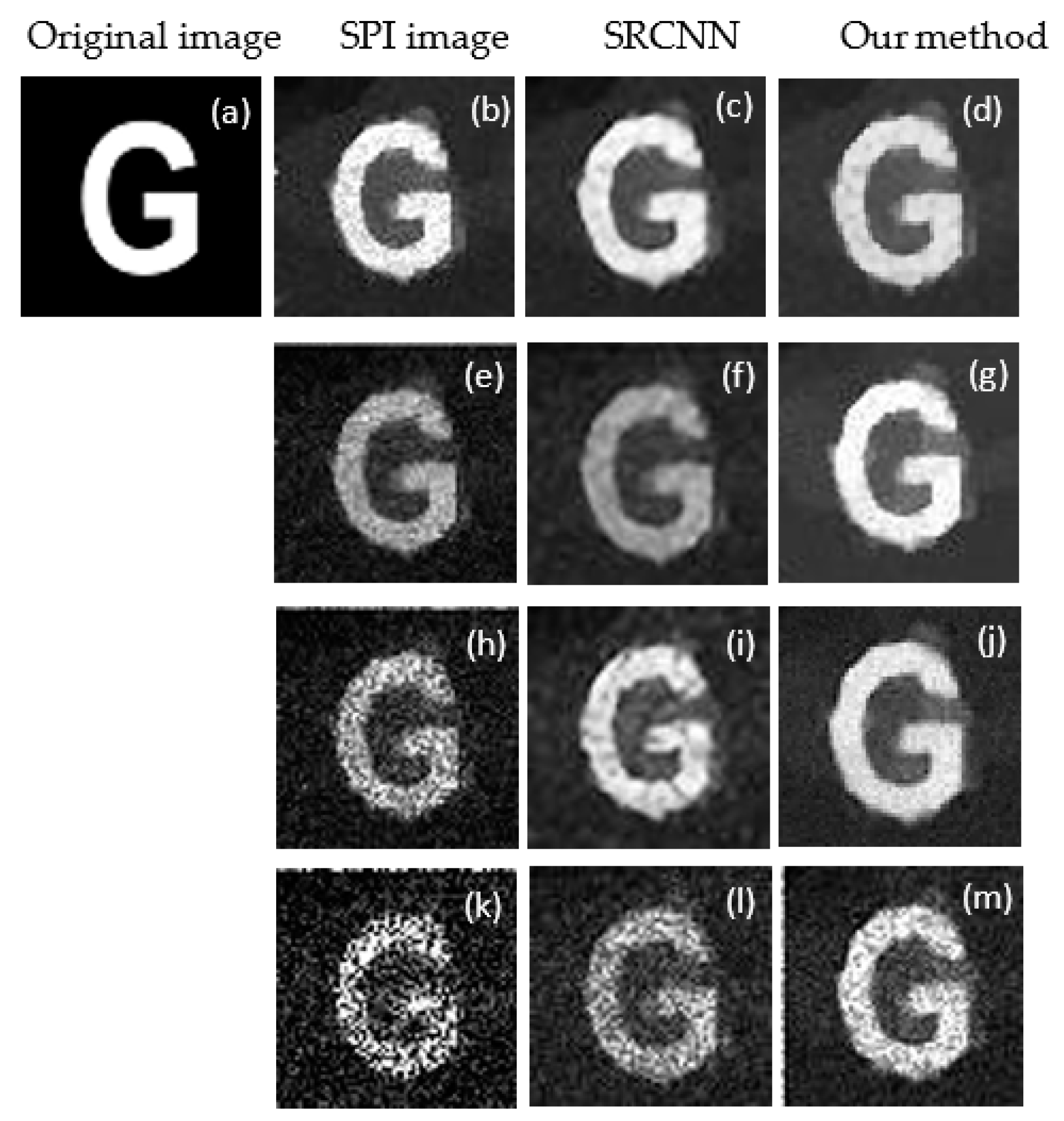
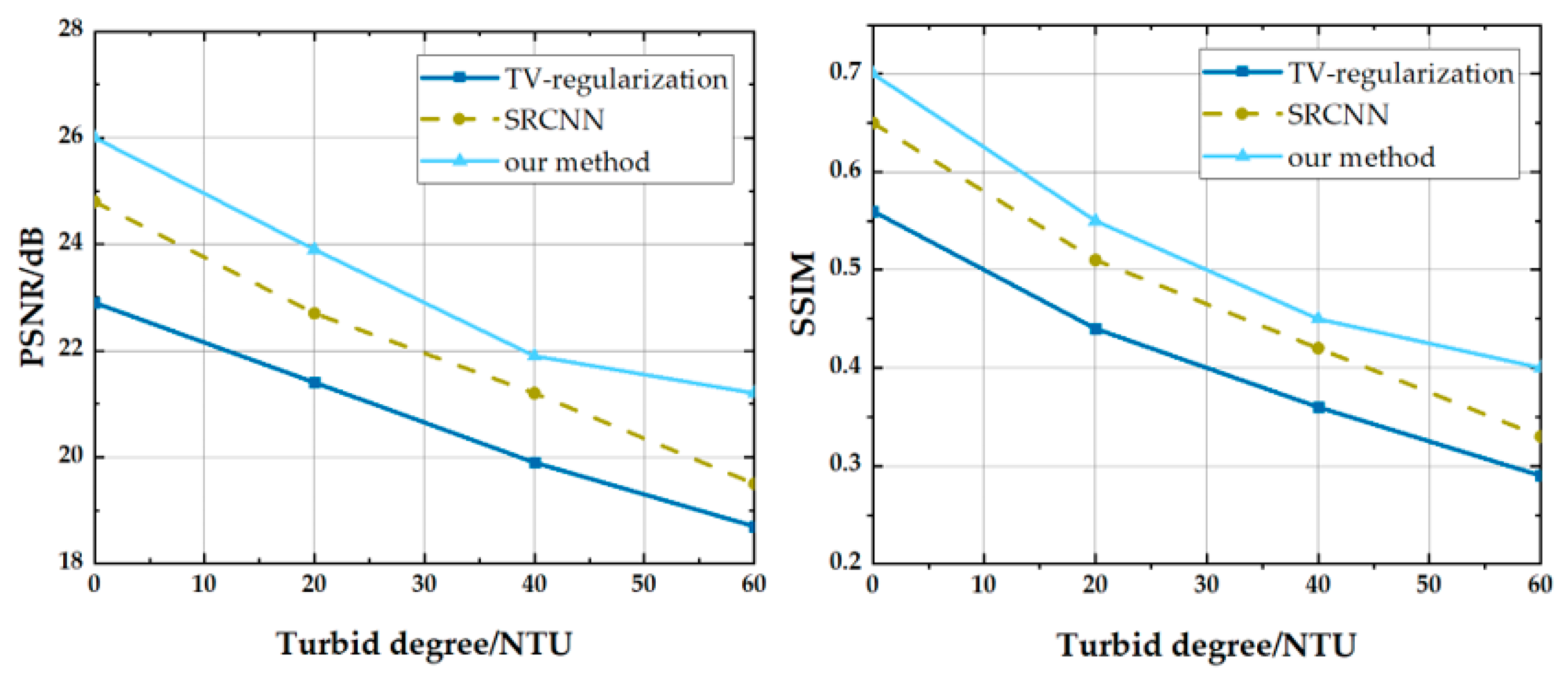
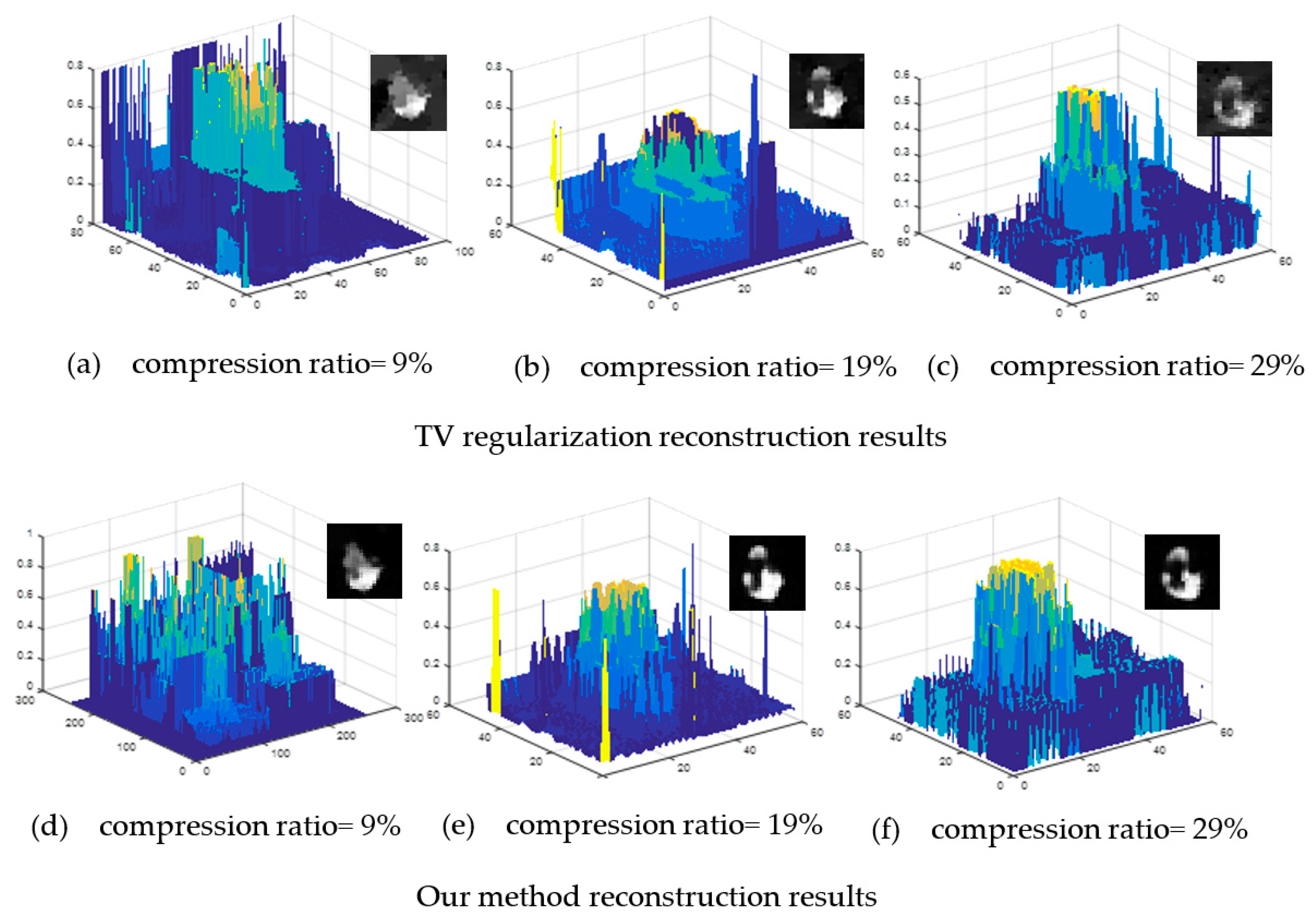
4. Experimental Results and Analysis
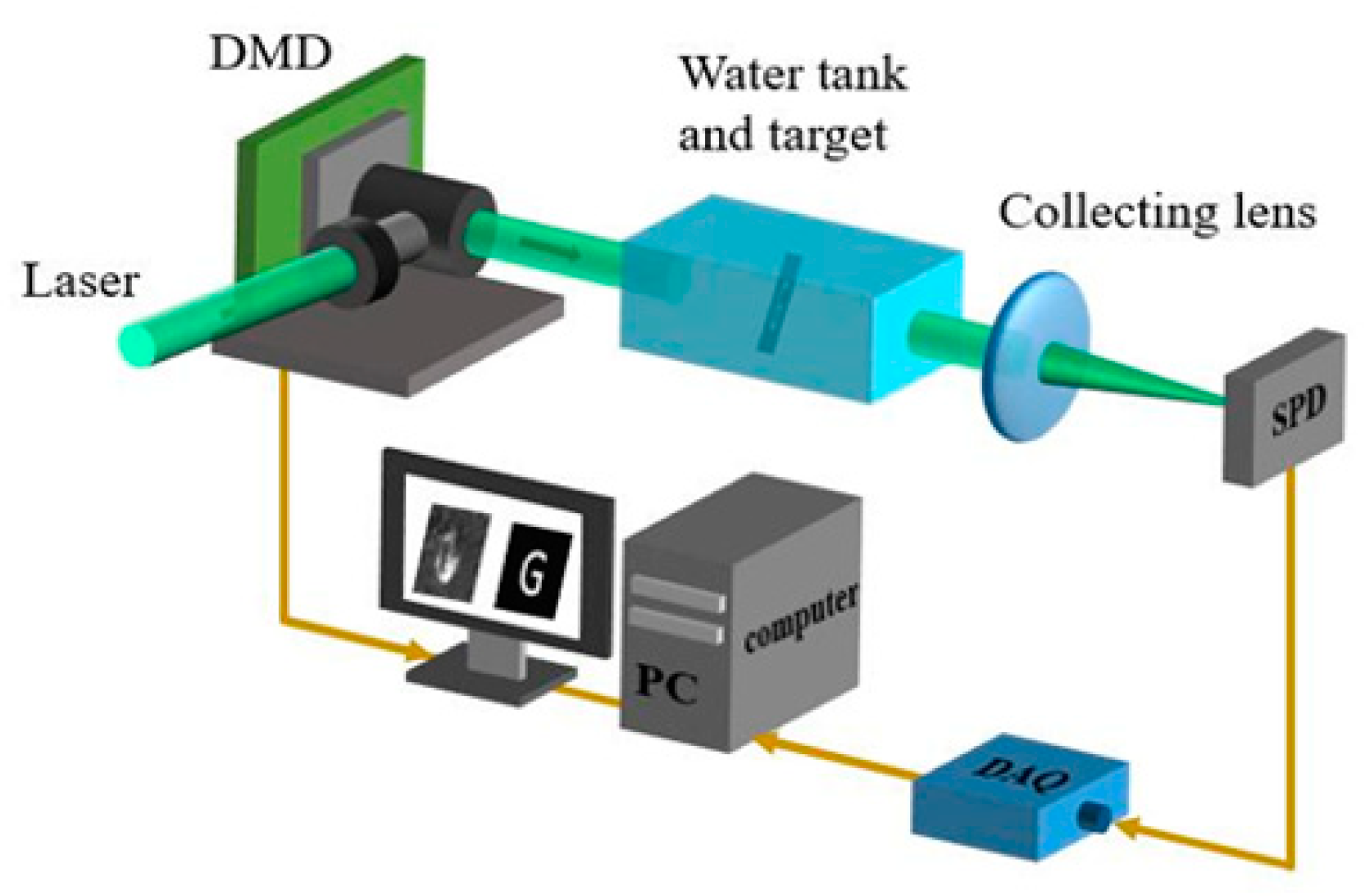
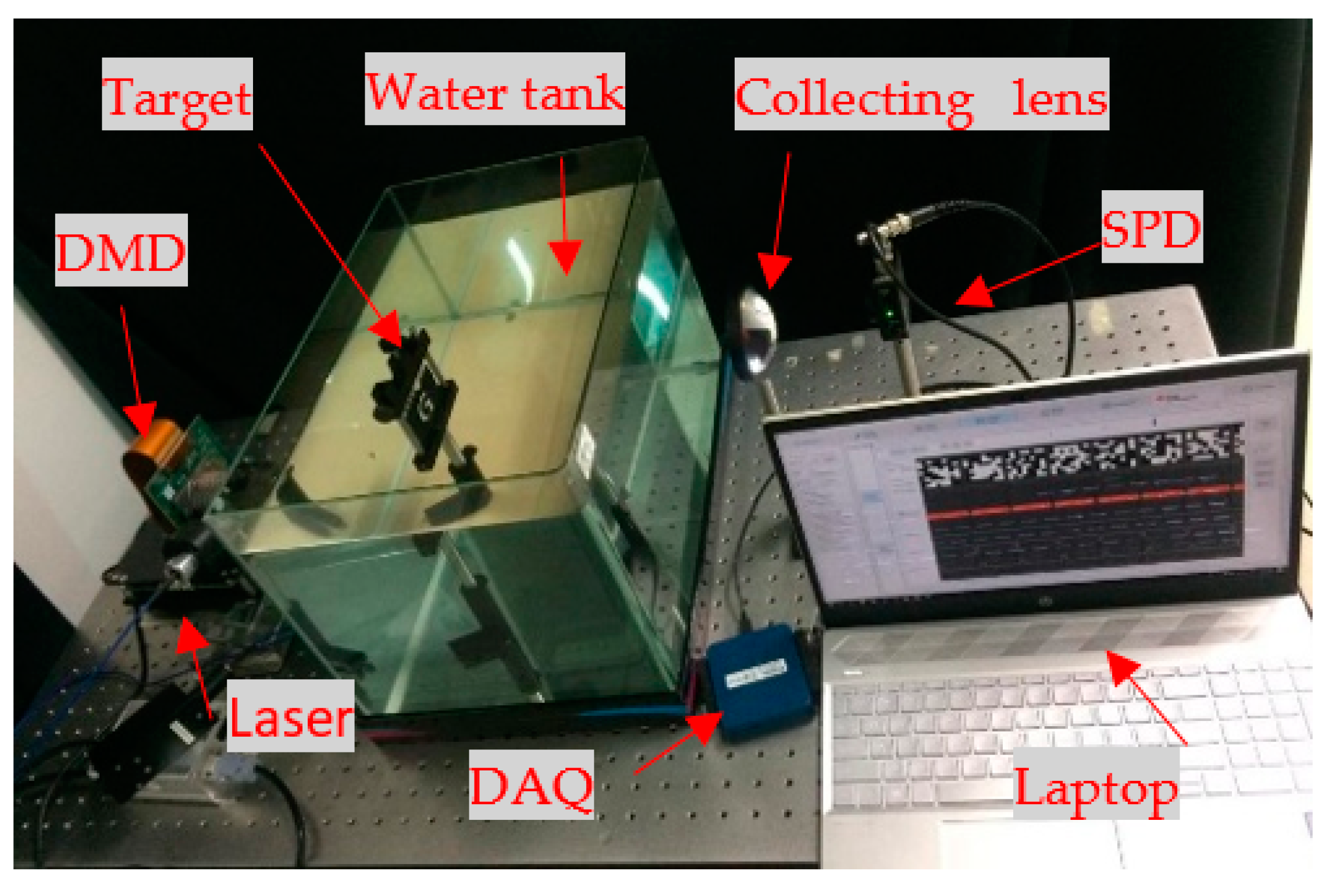
4.1. Experimental Setup
4.2. TV Regularization (Compressive Sensing) Reconstruction
4.3. Reconstruction Based on Compressive Sensing Super-resolution Convolutional Network (CS-SRCNN)
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lu, H.; Li, Y.; Uemura, T.; Kim, H.; Serikawa, S. Low illumination underwater light field images reconstruction using deep convolutional neural networks. Future Gener. Comput. Syst. 2018, 82, 142–148. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, W.; Wu, H.; Chen, Y.; Su, X.; Xiao, Y.; Wang, Z.; Gu, Y. High-visibility underwater ghost imaging in low illumination. Opt. Commun. 2019, 441, 45–48. [Google Scholar] [CrossRef]
- Amer, K.O.; Elbouz, M.; Alfalou, A.; Brosseau, C.; Hajjami, J. Enhancing underwater optical imaging by using a low-pass polarization filter. Opt. Express 2019, 27, 621–643. [Google Scholar] [CrossRef] [PubMed]
- Liu, F.; Wei, Y.; Han, P.; Yang, K.; Bai, L.; Shao, X. Polarization-based exploration for clear underwater vision in natural illumination. Opt. Express 2019, 27, 3629–3641. [Google Scholar] [CrossRef]
- Mariani, P.; Quincoces, I.; Haugholt, K.; Chardard, Y.; Visser, A.; Yates, C.; Piccinno, G.; Reali, G.; Risholm, P.; Thielemann, J. Range-gated imaging system for underwater monitoring in ocean environment. Sustainability 2019, 11, 162. [Google Scholar] [CrossRef] [Green Version]
- Chang, A.; Jung, J.; Um, D.; Yeom, J.; Hanselmann, F. Cost-effective Framework for Rapid Underwater Mapping with Digital Camera and Color Correction Method. KSCE J. Civ. Eng. 2019, 23, 1776–1785. [Google Scholar] [CrossRef]
- Lu, J.; Li, N.; Zhang, S.; Yu, Z.; Zheng, H.; Zheng, B. Multi-scale adversarial network for underwater image restoration. Opt. Laser Technol. 2019, 110, 105–113. [Google Scholar] [CrossRef]
- Tang, C.; Von Lukas, U.F.; Vahl, M.; Wang, S.; Wang, Y.; Tan, M. Efficient underwater image and video enhancement based on Retinex. Signal, Image Video Process. 2019, 13, 1011–1018. [Google Scholar] [CrossRef]
- Çelebi, A.T.; Ertürk, S. Visual enhancement of underwater images using empirical mode decomposition. Expert Syst. Appl. 2012, 39, 800–805. [Google Scholar]
- Li, M.; Mathai, A.; Yandi, L.; Chen, Q.; Wang, X.; Xu, X. A brief review on 2D and 3D image reconstruction using single-pixel imaging. Laser Phys. 2020, 30, 095204. [Google Scholar] [CrossRef]
- Mathai, A.; Guo, N.; Liu, D.; Wang, X. 3D Transparent Object Detection and Reconstruction Based on Passive Mode Single-Pixel Imaging. Sensors 2020, 20, 4211. [Google Scholar] [CrossRef] [PubMed]
- Mathai, A.; Wang, X.; Chua, S.Y. Transparent Object Detection Using Single-Pixel Imaging and Compressive Sensing. In Proceedings of the 2019 13th International Conference on Sensing Technology (ICST), Sydney, Australia, 2–4 December 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–6. [Google Scholar]
- Li, M.; Mathai, A.; Xu, X.; Wang, X. Non-line-of-sight object detection based on the orthogonal matching pursuit compressive sensing reconstruction. In Optics Frontier Online 2020: Optics Imaging and Display; International Society for Optics and Photonics: Bellingham, WA, USA, 2020; p. 115710G. [Google Scholar]
- Ouyang, B.; Dalgleish, F.R.; Caimi, F.M.; Giddings, T.E.; Shirron, J.J.; Vuorenkoski, A.K.; Nootz, G.; Britton, W.; Ramos, B. Underwater laser serial imaging using compressive sensing and digital mirror device. In Laser Radar Technology and Applications XVI; International Society for Optics and Photonics: Bellingham, WA, USA, 2011; p. 803707. [Google Scholar]
- Chen, Q.; Mathai, A.; Xu, X.; Wang, X. A study into the effects of factors influencing an underwater, single-pixel imaging system’s performance. In Photonics; Multidisciplinary Digital Publishing Institute: Bazel, Switzerland, 2019; p. 123. [Google Scholar]
- Chen, Q.; Chamoli, S.K.; Yin, P.; Wang, X.; Xu, X. Active Mode Single Pixel Imaging in the Highly Turbid Water Environment Using Compressive Sensing. IEEE Access 2019, 7, 159390–159401. [Google Scholar] [CrossRef]
- Chen, Q.; Yam, J.W.; Chua, S.Y.; Guo, N.; Wang, X. Characterizing the performance impacts of target surface on underwater pulse laser ranging system. J. Quant. Spectrosc. Radiat. Transf. 2020, 255, 107267. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436. [Google Scholar] [CrossRef] [PubMed]
- Hassannejad, H.; Matrella, G.; Ciampolini, P.; De Munari, I.; Mordonini, M.; Cagnoni, S. Food image recognition using very deep convolutional networks. In Proceedings of the 2nd International Workshop on Multimedia Assisted Dietary Management, Amsterdam, The Netherlands, 16 October 2016; ACM: New York, NY, USA, 2016; pp. 41–49. [Google Scholar]
- Caramazza, P.; Boccolini, A.; Buschek, D.; Hullin, M.; Higham, C.F.; Henderson, R.; Murray-Smith, R.; Faccio, D. Neural network identification of people hidden from view with a single-pixel, single-photon detector. Sci. Rep. 2018, 8, 11945. [Google Scholar] [CrossRef] [Green Version]
- Han, J.; Zhang, D.; Cheng, G.; Liu, N.; Xu, D. Advanced deep-learning techniques for salient and category-specific object detection: A survey. IEEE Signal. Process. Mag. 2018, 35, 84–100. [Google Scholar] [CrossRef]
- Guan, C.-Z. Realtime Multi-Person 2D Pose Estimation using ShuffleNet. In Proceedings of the 2019 14th International Conference on Computer Science & Education (ICCSE), Toronto, ON, Canada, 19–21 August 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 17–21. [Google Scholar]
- Higham, C.F.; Murray-Smith, R.; Padgett, M.J.; Edgar, M.P. Deep learning for real-time single-pixel video. Sci. Rep. 2018, 8, 2369. [Google Scholar] [CrossRef] [Green Version]
- Rizvi, S.; Cao, J.; Zhang, K.; Hao, Q. Improving Imaging Quality of Real-time Fourier Single-pixel Imaging via Deep Learning. Sensors 2019, 19, 4190. [Google Scholar] [CrossRef] [Green Version]
- Bi, Y.; Xu, X.; Chua, S.Y.; Chow, E.M.T.; Wang, X. Underwater Turbulence Detection Using Gated Wavefront Sensing Technique. Sensors 2018, 18, 798. [Google Scholar] [CrossRef] [Green Version]
- Dutta, R.; Manzanera, S.; Gambín-Regadera, A.; Irles, E.; Tajahuerce, E.; Lancis, J.; Artal, P. Single-pixel imaging of the retina through scattering media. Biomed. Opt. Express 2019, 10, 4159–4167. [Google Scholar] [CrossRef]
- Jauregui-Sánchez, Y.; Clemente, P.; Lancis, J.; Tajahuerce, E. Single-pixel imaging with Fourier filtering: Application to vision through scattering media. Opt. Lett. 2019, 44, 679–682. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Donoho, D.L. Compressed sensing. IEEE Trans. Inf. Theory 2006, 52, 1289–1306. [Google Scholar] [CrossRef]
- Li, C. An Efficient Algorithm for Total Variation Regularization with Applications to the Single Pixel Camera and Compressive Sensing. Ph.D. Thesis, Rice University, Houston, TX, USA, 2010. [Google Scholar]
- Yu, W.-K.; Yao, X.-R.; Liu, X.-F.; Li, L.-Z.; Zhai, G.-J. Three-dimensional single-pixel compressive reflectivity imaging based on complementary modulation. Appl. Optics. 2015, 54, 363–367. [Google Scholar] [CrossRef]
- Candès, E.J. Compressive sampling. In Proceedings of the International Congress of Mathematicians, 2006, Madrid, Spain, 22–30 August 2006; pp. 1433–1452. [Google Scholar]
- Umehara, K.; Ota, J.; Ishida, T. Super-resolution imaging of mammograms based on the super-resolution convolutional neural network. Open J. Med. Imaging 2017, 7, 180. [Google Scholar] [CrossRef] [Green Version]
- Yang, W.; Zhang, X.; Tian, Y.; Wang, W.; Xue, J.-H.; Liao, Q. Deep learning for single image super-resolution: A brief review. IEEE Trans. Multimed. 2019, 21, 3106–3121. [Google Scholar] [CrossRef] [Green Version]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef] [Green Version]
- Luo, Z.; Yurt, A.; Stahl, R.; Lambrechts, A.; Reumers, V.; Braeken, D.; Lagae, L. Pixel super-resolution for lens-free holographic microscopy using deep learning neural networks. Opt. Express 2019, 27, 13581–13595. [Google Scholar] [CrossRef]
- Le, M.; Wang, G.; Zheng, H.; Liu, J.; Zhou, Y.; Xu, Z. Underwater computational ghost imaging. Opt. Express 2017, 25, 22859–22868. [Google Scholar] [CrossRef]
- Li, F.; Zhao, M.; Tian, Z.; Willomitzer, F.; Cossairt, O. Compressive ghost imaging through scattering media with deep learning. Opt. Express 2020, 28, 17395–17408. [Google Scholar] [CrossRef]
- Ward, C.M.; Harguess, J.; Crabb, B.; Parameswaran, S. Image quality assessment for determining efficacy and limitations of Super-Resolution Convolutional Neural Network (SRCNN). In Applications of Digital Image Processing XL; International Society for Optics and Photonics: Bellingham, WA, USA, 2017; p. 1039605. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| “Lena” | “Cameraman” | |||||||
|---|---|---|---|---|---|---|---|---|
| SRCNN | CS | Li | Our | SRCNN | CS | Li | Our | |
| PSNR | 21.92 | 18.83 | 20.47 | 24.03 | 21.83 | 18.48 | 20.30 | 23.57 |
| SSIM | 0.56 | 0.32 | 0.37 | 0.68 | 0.57 | 0.30 | 0.31 | 0.59 |
| M = 100 | M = 200 | M = 300 | |
|---|---|---|---|
| PSNR | 9.02 | 10.17 | 11.59 |
| SSIM | 0.10 | 0.13 | 0.26 |
| V | 0.24 | 0.27 | 0.29 |
| M = 100 | M = 200 | M = 300 | |
|---|---|---|---|
| PSNR | 10.25 | 11.58 | 12.78 |
| SSIM | 0.23 | 0.31 | 0.42 |
| V | 0.27 | 0.29 | 0.31 |
| SPI Image | SRCNN Image | Our Method Image | |
|---|---|---|---|
| PSNR | 11.59 | 12.07 | 15.67 |
| SSIM | 0.26 | 0.32 | 0.45 |
| V | 0.29 | 0.30 | 0.33 |
| SPI Image | SRCNN Image | Our Method Image | |
|---|---|---|---|
| PSNR | 12.89 | 13.21 | 15.32 |
| SSIM | 0.23 | 0.25 | 0.36 |
| V | 0.31 | 0.31 | 0.33 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, M.; Mathai, A.; Lau, S.L.H.; Yam, J.W.; Xu, X.; Wang, X. Underwater Object Detection and Reconstruction Based on Active Single-Pixel Imaging and Super-Resolution Convolutional Neural Network. Sensors 2021, 21, 313. https://doi.org/10.3390/s21010313
Li M, Mathai A, Lau SLH, Yam JW, Xu X, Wang X. Underwater Object Detection and Reconstruction Based on Active Single-Pixel Imaging and Super-Resolution Convolutional Neural Network. Sensors. 2021; 21(1):313. https://doi.org/10.3390/s21010313
Chicago/Turabian StyleLi, Mengdi, Anumol Mathai, Stephen L. H. Lau, Jian Wei Yam, Xiping Xu, and Xin Wang. 2021. "Underwater Object Detection and Reconstruction Based on Active Single-Pixel Imaging and Super-Resolution Convolutional Neural Network" Sensors 21, no. 1: 313. https://doi.org/10.3390/s21010313