Using Vehicle Interior Noise Classification for Monitoring Urban Rail Transit Infrastructure


Abstract
:1. Introduction
- A smartphone-based onboard data collection framework for vehicle interior noise and dynamic responses of the car body was established.
- The theory of Shannon entropy was considered when selecting the optimal window size for segmenting the multi-source time-series signals.
- A multi-classification model for subway vehicle interior noise was established based on the XGBoost algorithm. The generation of a set of 45 features and performing feature selection based on different methods were also included.
- Case studies were conducted to extend the application scenario for the analysis of abnormal noise causes and evaluating the effect of rail grinding.
2. Research Methodology
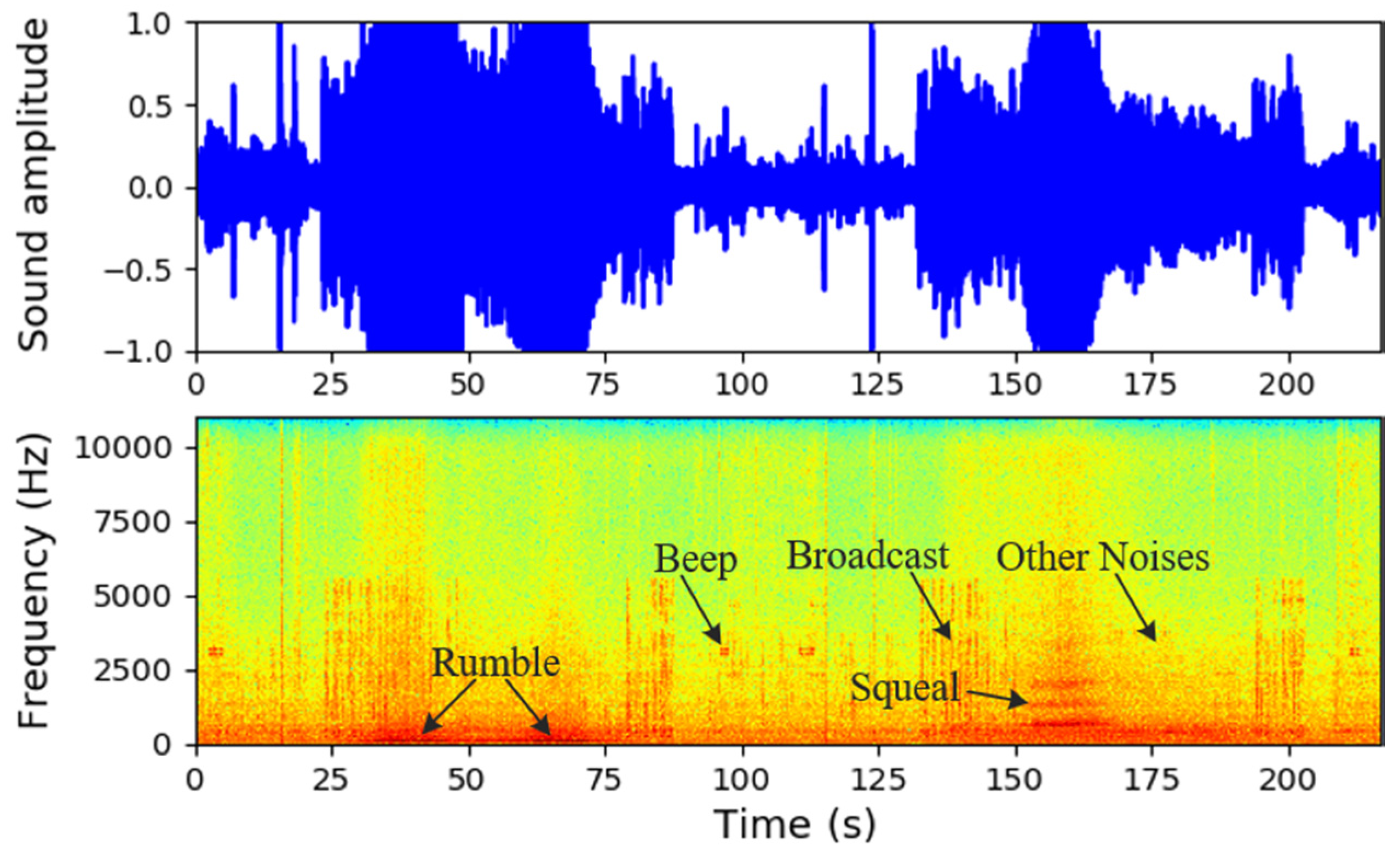
3. Data Collection and Description
4. Model Approach
4.1. Data Segmentation and Time Window
4.2. Data Balance Using the Synthetic Minority Oversampling Technique (SMOTE)
4.3. Features
4.4. Feature Selection Based on IG
4.5. Multi-Classification Model for Vehicle Interior Noise Based on XGBoost
5. Results and Discussions
5.1. Optimal Time Window Size and Data Balance
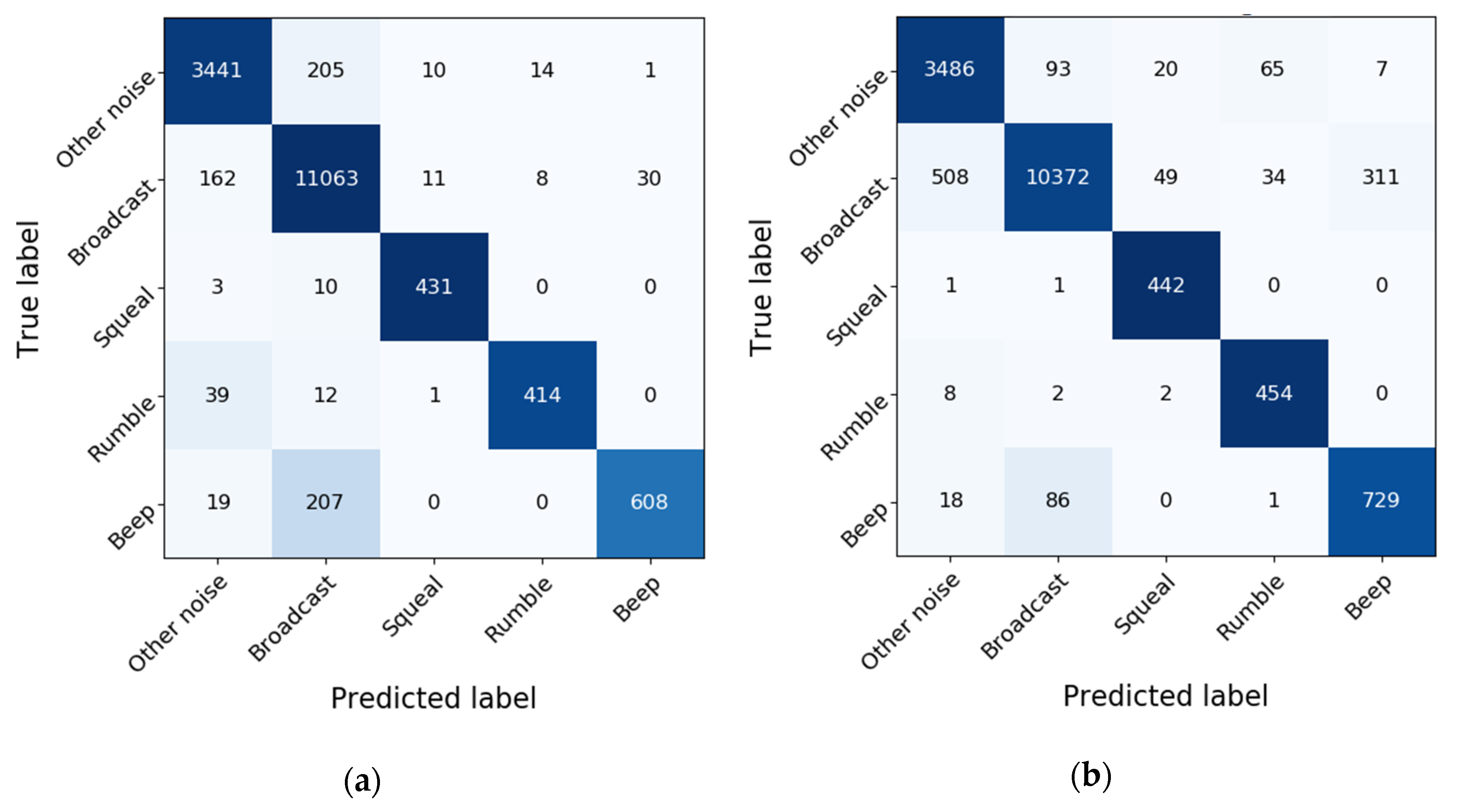
5.2. Feature Selection Based on the Importance Score
5.3. Comparisons with Other Methods
5.4. Case Studies to Extend the Model Application Scenarios
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- China Urban Rail Transit Association. Urban Rail Transit 2018 Annual Statistical Report; China Urban Rail Transit Association: Beijing, China, 2019. [Google Scholar]
- Atmaja, B.; Puabdillah, M.; Farid, M.; Asmoro, W. Prediction and simulation of internal train noise resulted by different speed and air conditioning unit. J. Phys. Conf. Ser. 2018, 1075, 012038. [Google Scholar] [CrossRef]
- Zhang, J.; Xiao, X.; Sheng, X.; Li, Z.; Jin, X. A Systematic Approach to Identify Sources of Abnormal Interior Noise for a High-Speed Train. Shock Vib. 2018, 2018. [Google Scholar] [CrossRef] [Green Version]
- Talotte, C. Aerodynamic noise: A critical survey. J. Sound Vib. 2000, 231, 549–562. [Google Scholar] [CrossRef]
- Han, J.; Xiao, X.; Wu, Y.; Wen, Z.; Zhao, G. Effect of rail corrugation on metro interior noise and its control. Appl. Acoust. 2018, 130, 63–70. [Google Scholar] [CrossRef]
- Wu, B.; Chen, G.; Lv, J.; Zhu, Q.; Kang, X. Generation mechanism and remedy method of rail corrugation at a sharp curved metro track with Vanguard fasteners. J. Low Freq. Noise Vib. Act. Control. 2019. [Google Scholar] [CrossRef]
- Li, L.; Thompson, D.; Xie, Y.; Zhu, Q.; Luo, Y.; Lei, Z. Influence of rail fastener stiffness on railway vehicle interior noise. Appl. Acoust. 2019, 145, 69–81. [Google Scholar] [CrossRef] [Green Version]
- Meehan, P.A.; Liu, X. Modelling and mitigation of wheel squeal noise amplitude. J. Sound Vib. 2018, 413, 144–158. [Google Scholar] [CrossRef]
- Zhang, J.; Han, G.; Xiao, X.; Wang, R.; Zhao, Y.; Jin, X. Influence of Wheel Polygonal Wear on Interior Noise of High-Speed Trains. In China’s High-Speed Rail Technology; Springer: Berlin/Heidelberg, Germany, 2018; pp. 373–401. [Google Scholar]
- Fink, O.; Zio, E.; Weidmann, U. Predicting time series of railway speed restrictions with time-dependent machine learning techniques. Expert Syst. Appl. 2013, 40, 6033–6040. [Google Scholar] [CrossRef] [Green Version]
- Sun, Y.; Zhao, Y. Characteristics of Interior Noise in MonoRail and Noise Control. In INTER-NOISE and NOISE-CON Congress and Conference Proceedings; Institute of Noise Control Engineering: Chicago, IL, USA, 2018; Volume 258, pp. 1461–1467. [Google Scholar]
- Hu, K.; Wang, Y.; Guo, H.; Chen, H. Sound quality evaluation and optimization for interior noise of rail vehicle. Adv. Mech. Eng. 2014, 6, 820875. [Google Scholar] [CrossRef]
- Kurzweil, L.G. Prediction and control of noise from railway bridges and tracked transit elevated structures. J. Sound Vib. 1977, 51, 419–439. [Google Scholar] [CrossRef]
- Zhang, J.; Xiao, X.; Sheng, X.; Li, Z. Sound Source Localisation for a High-Speed Train and Its Transfer Path to Interior Noise. Chin. J. Mech. Eng. 2019, 32, 59. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Xiao, X.; Sheng, X.; Zhang, C.; Wang, R.; Jin, X. SEA and contribution analysis for interior noise of a high speed train. Appl. Acoust. 2016, 112, 158–170. [Google Scholar] [CrossRef]
- Franzoni, L.; Rouse, J.; Duvall, T. A broadband energy-based boundary element method for predicting vehicle interior noise. J. Acoust. Soc. Am. 2004, 115, 2538. [Google Scholar] [CrossRef]
- Wu, D.; Ge, J.M. Analysis of the Influence of Racks on High Speed Train Interior Noise Using Finite Element Method. Appl. Mech. Mater. 2014, 675, 257–260. [Google Scholar] [CrossRef]
- Ghofrani, F.; He, Q.; Goverde, R.M.; Liu, X. Recent applications of big data analytics in railway transportation systems: A survey. Transp. Res. Part. C Emerg. Technol. 2018, 90, 226–246. [Google Scholar] [CrossRef]
- Toque, F.; Come, E.; Oukhellou, L.; Trepanier, M. Short-Term Multi-Step Ahead Forecasting of Railway Passenger Flows During Special Events With Machine Learning Methods. In Proceedings of the CASPT 2018, Conference on Advanced Systems in Public Transport and TransitData 2018, Brisbane, Australia, 23–25 July 2018; p. 15. [Google Scholar]
- Cui, Y.; Martin, U.; Zhao, W. Calibration of disturbance parameters in railway operational simulation based on reinforcement learning. J. Rail Transp. Plan. Manag. 2016, 6, 1–12. [Google Scholar] [CrossRef]
- Ghofrani, F.; Pathak, A.; Mohammadi, R.; Aref, A.; He, Q. Predicting rail defect frequency: An integrated approach using fatigue modeling and data analytics. Comput. Aided Civ. Infrastruct. Eng. 2020, 35, 101–115. [Google Scholar] [CrossRef]
- Mohammadi, R.; He, Q.; Ghofrani, F.; Pathak, A.; Aref, A. Exploring the impact of foot-by-foot track geometry on the occurrence of rail defects. Transp. Res. Part C Emerg. Technol. 2019, 102, 153–172. [Google Scholar] [CrossRef]
- Ghofrani, F.; He, Q.; Mohammadi, R.; Pathak, A.; Aref, A. Bayesian Survival Approach to Analyzing the Risk of Recurrent Rail Defects. Transp. Res. Rec. 2019, 2673, 281–293. [Google Scholar] [CrossRef]
- Li, H.; Parikh, D.; He, Q.; Qian, B.; Li, Z.; Fang, D.; Hampapur, A. Improving rail network velocity: A machine learning approach to predictive maintenance. Transp. Res. Part C Emerg. Technol. 2014, 45, 17–26. [Google Scholar] [CrossRef]
- He, Q.; Li, H.; Bhattacharjya, D.; Parikh, D.P.; Hampapur, A. Track geometry defect rectification based on track deterioration modelling and derailment risk assessment. J. Oper. Res. Soc. 2015, 66, 392–404. [Google Scholar] [CrossRef]
- Li, Z.; He, Q. Prediction of railcar remaining useful life by multiple data source fusion. IEEE Trans. Intell. Transp. Syst. 2015, 16, 2226–2235. [Google Scholar] [CrossRef]
- Verhaegh, W.; Verhaegh, W.; Aarts, E.; Korst, J. Algorithms in Ambient Intelligence; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2004; Volume 2. [Google Scholar]
- Mato-Méndez, F.J.; Sobreira-Seoane, M.A. Blind separation to improve classification of traffic noise. Appl. Acoust. 2011, 72, 590–598. [Google Scholar] [CrossRef]
- Sobreira-Seoane, M.A.; Rodriguez Molares, A.; Alba Castro, J.L. Automatic classification of traffic noise. J. Acoust. Soc. Am. 2008, 123, 3823. [Google Scholar] [CrossRef]
- Paulraj, P.; Melvin, A.A.; Sazali, Y. Car Cabin Interior Noise Classification Using Temporal Composite Features and Probabilistic Neural Network Model. Appl. Mech. Mater. 2014, 471, 64–68. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, P.; Wang, X.; Liu, X. Position synchronization for track geometry inspection data via big-data fusion and incremental learning. Transp. Res. Part C Emerg. Technol. 2018, 93, 544–565. [Google Scholar] [CrossRef]
- Cho, C.J.; Park, Y.; Ku, B.; Ko, H. An implementation of environment recognition for enhancement of advanced video based railway inspection car detection modules. Sci. Adv. Mater. 2018, 10, 496–500. [Google Scholar] [CrossRef]
- Yin, J.; Zhao, W. Fault diagnosis network design for vehicle on-board equipments of high-speed railway: A deep learning approach. Eng. Appl. Artif. Intell. 2016, 56, 250–259. [Google Scholar] [CrossRef]
- Li, C.; Luo, S.; Cole, C.; Spiryagin, M. An overview: Modern techniques for railway vehicle on-board health monitoring systems. Veh. Syst. Dyn. 2017, 55, 1045–1070. [Google Scholar] [CrossRef]
- Tsunashima, H.; Naganuma, Y.; Matsumoto, A.; Mizuma, T.; Mori, H. Condition monitoring of railway track using in-service vehicle. Reliab. Saf. Railw. 2012, 12, 334–356. [Google Scholar]
- Wang, P.; Wang, Y.; Wang, L.; Chen, R.; Xiao, J. Measurement of Carbody Vibration in Urban Rail Transit Using Smartphones. In Proceedings of the Transportation Research Board 96th Annual Meeting, Washington, DC, USA, 8–12 January 2017. [Google Scholar]
- Ghose, A.; Biswas, P.; Bhaumik, C.; Sharma, M.; Pal, A.; Jha, A. Road condition monitoring and alert application: Using in-vehicle Smartphone as Internet-connected sensor. In Proceedings of the 2012 IEEE International Conference on Pervasive Computing and Communications Workshops, Lugano, Switzerland, 19–23 March 2012; pp. 489–491. [Google Scholar]
- Han, W.; Chan, C.F.; Choy, C.S.; Pun, K.P. An efficient MFCC extraction method in speech recognition. In Proceedings of the 2006 IEEE International Symposium on Circuits and Systems, Island of Kos, Greece, 21–24 May 2006. [Google Scholar]
- Banos, O.; Galvez, J.-M.; Damas, M.; Pomares, H.; Rojas, I. Window Size Impact in Human Activity Recognition. Sensors 2014, 14, 6474–6499. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Feng, N.; Wang, Y.; Shen, Y. Acoustic emission detection of rail defect based on wavelet transform and Shannon entropy. J. Sound Vib. 2015, 339, 419–432. [Google Scholar] [CrossRef]
- Sun, Y.; Wong, A.K.; Kamel, M.S. Classification of imbalanced data: A review. Int. J. Pattern Recognit. Artif. Intell. 2009, 23, 687–719. [Google Scholar] [CrossRef]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer Science + Business Media: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Martinez, J.; Perez, H.; Escamilla, E.; Suzuki, M.M. Speaker recognition using Mel frequency Cepstral Coefficients (MFCC) and Vector quantization (VQ) techniques. In Proceedings of the CONIELECOMP 2012, 22nd International Conference on Electrical Communications and Computers, Puebla, Mexico, 27–29 February 2012; pp. 248–251. [Google Scholar]
- Lei, S. A feature selection method based on information gain and genetic algorithm. In Proceedings of the 2012 International Conference on Computer Science and Electronics Engineering, Hangzhou, China, 23–25 March 2012; Volume 2, pp. 355–358. [Google Scholar]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; ACM: New York, NY, USA, 2016; pp. 785–794. [Google Scholar]
- Omar, K. XGBoost and LGBM for Porto Seguro’s Kaggle Challenge: A Comparison. 2018. Available online: https://pub.tik.ee.ethz.ch/students/2017-HS/SA-2017-98.pdf (accessed on 7 July 2019).
- Wang, Y.; Cong, J.; Tang, H.; Liu, X.; Gao, T.; Wang, P. A Data Fusion Approach for Speed Estimation and Location Calibration of a Metro Train. in Underground Environment Based on Low-Cost Sensors in Smartphones. In Proceedings of the Transportation Research Board 98th Annual Meeting, Washington, DC, USA, 13–17 January 2019. [Google Scholar]












{kind=link}
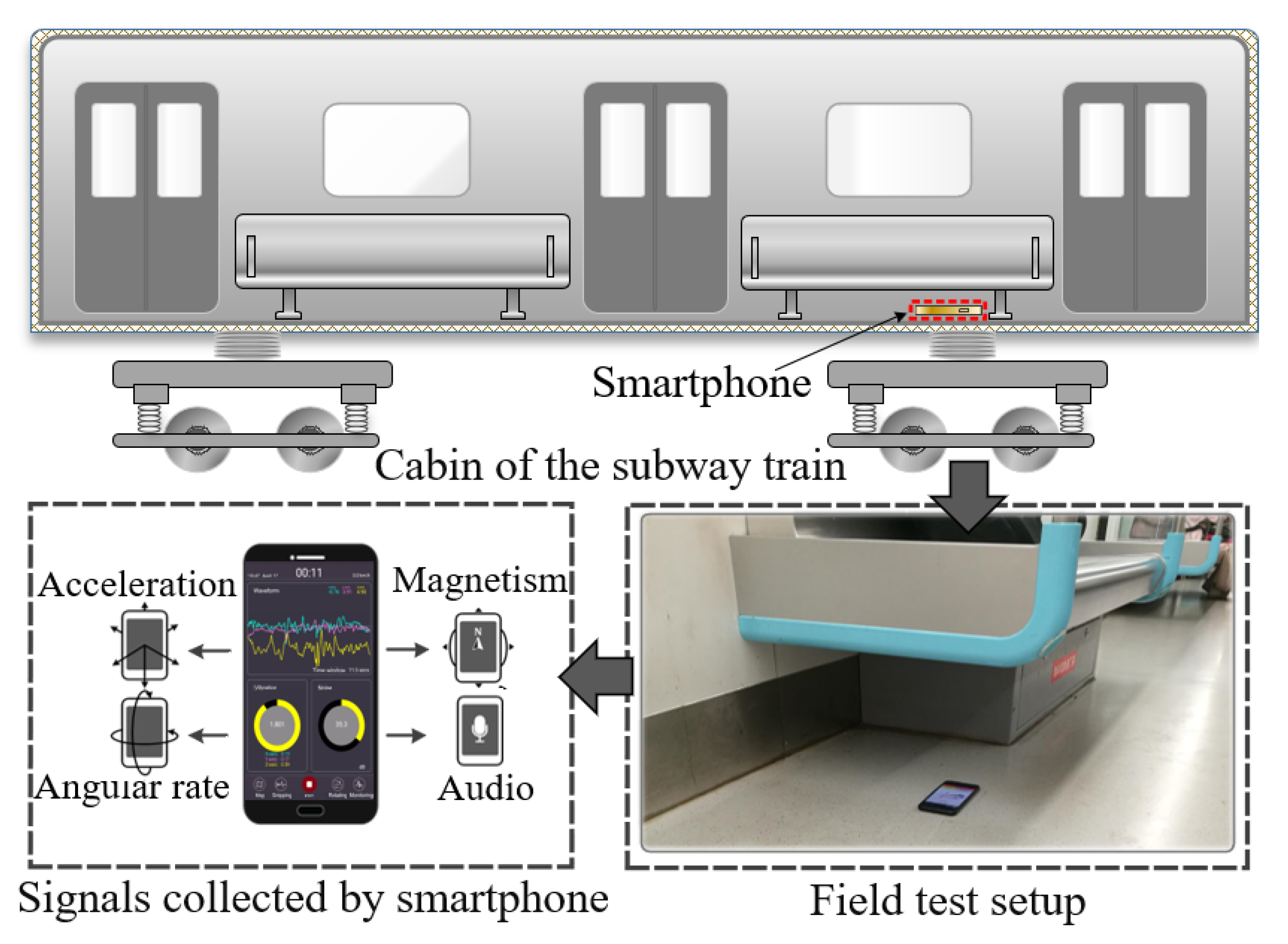{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Feature | Definition | |
|---|---|---|---|
| Time-domain | f1 | Segment energy | |
| f2 | Root mean square (RMS) of the segment | ||
| f3 | Zero cross rate | ||
| Frequency-domain | f4 | Spectral centroid | |
| f5 | Spectral bandwidth | [29] | |
| f6 | Spectral roll-off | ||
| f7 | Spectral bandwidth to energy ratio | ||
| f8 | Spectral entropy | ||
| f9 | Energy to spectral entropy ratio | ||
| f10–f21 | First 12 MFCCs | ||
| f22–f33 | First-order derivatives of f10–f21 | ||
| f34–f45 | Second-order derivatives of f10–f21 | ||
| The Model Trained with Unbalanced Data | The Model Trained with Balanced Training Data | ||||||
|---|---|---|---|---|---|---|---|
| Classes | Precision | Recall | F1 score | Precision | Recall | F1 score | Support |
| Other noises | 0.94 | 0.94 | 0.94 | 0.87 | 0.95 | 0.91 | 3671 |
| Broadcast | 0.96 | 0.98 | 0.97 | 0.98 | 0.92 | 0.95 | 11,274 |
| Squeal | 0.95 | 0.97 | 0.96 | 0.86 | 1.00 | 0.92 | 444 |
| Rumble | 0.95 | 0.89 | 0.92 | 0.82 | 0.97 | 0.89 | 466 |
| Beep | 0.95 | 0.73 | 0.83 | 0.70 | 0.87 | 0.78 | 834 |
| Classifier | Accuracy | Precision | Running Time (s) | |
|---|---|---|---|---|
| XGBoost | 0.923 | 0.96 | 0.95 | 15.06 |
| K-nearest Neighbours | 0.704 | 0.84 | 0.72 | 2.51 |
| Decision Trees | 0.851 | 0.91 | 0.92 | 3.12 |
| Random Forest | 0.923 | 0.96 | 0.94 | 77.88 |
| Gradient Boost | 0.925 | 0.96 | 0.94 | 340.31 |
| AdaBoost | 0.651 | 0.77 | 0.64 | 67.70 |
| ANN | 0.880 | 0.93 | 0.94 | 173.22 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Wang, P.; Wang, Q.; Chen, Z.; He, Q. Using Vehicle Interior Noise Classification for Monitoring Urban Rail Transit Infrastructure. Sensors 2020, 20, 1112. https://doi.org/10.3390/s20041112
Wang Y, Wang P, Wang Q, Chen Z, He Q. Using Vehicle Interior Noise Classification for Monitoring Urban Rail Transit Infrastructure. Sensors. 2020; 20(4):1112. https://doi.org/10.3390/s20041112
Chicago/Turabian StyleWang, Yifeng, Ping Wang, Qihang Wang, Zhengxing Chen, and Qing He. 2020. "Using Vehicle Interior Noise Classification for Monitoring Urban Rail Transit Infrastructure" Sensors 20, no. 4: 1112. https://doi.org/10.3390/s20041112