A Critical Evaluation of Privacy and Security Threats in Federated Learning


Abstract
:1. Introduction
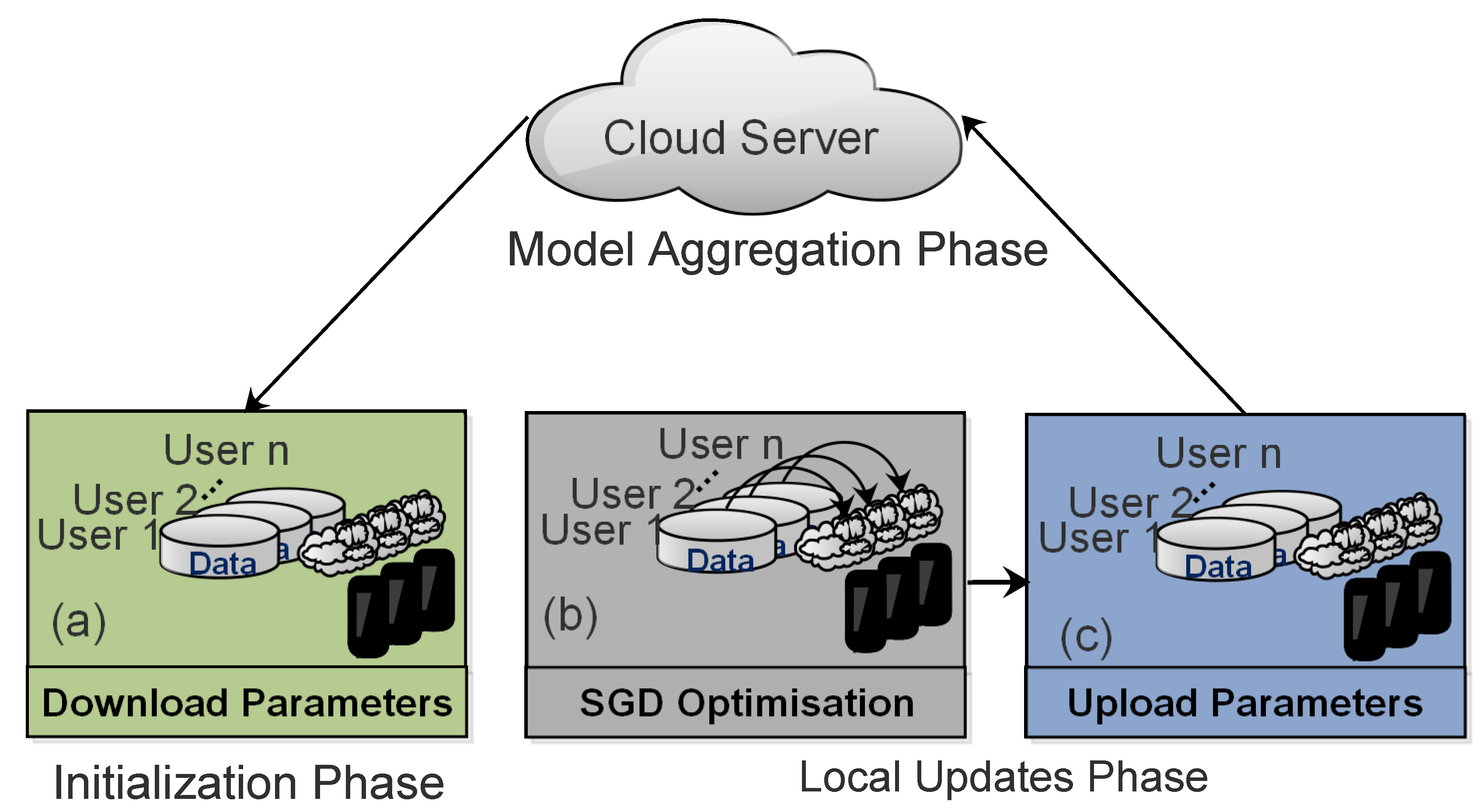
2. Overview of Federated Learning
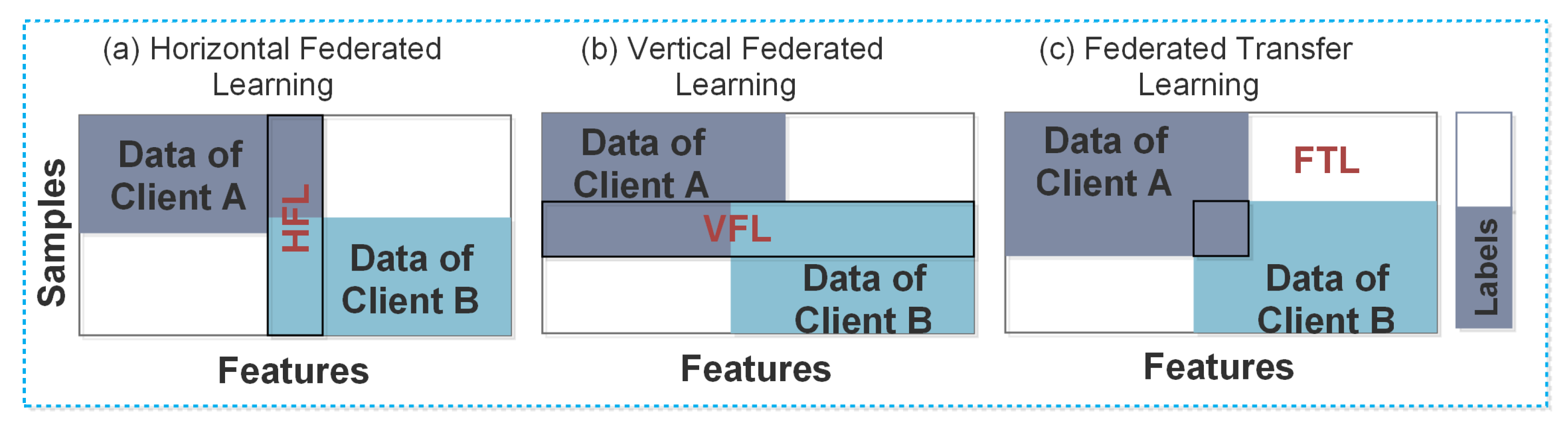
- Horizontal Federated Learning (HFL): the HFL is also known as sample-based FL. It is usually applied to the scenarios, where the datasets share the same feature space, but different space in samples. In HFL systems, an attack is usually assumed from the untrusted and curious cloud server, whereas the clients in HFL are considered honest.
- Vertical Federated Learning (VFL): the VFL is also known as feature-based FL. It is usually applied to the scenario where two datasets need to share identical sample IDs, but different feature spaces. In VFL systems, it is assumed that an adversary between two non-colluding parties can compromise a client’s privacy. The adversary learns the data from the corrupted party, while the data of the other party remains secure.
- Federated Transfer Learning (FTL): the FTL is usually applied to the scenario where two datasets are different in feature space and samples. The security concerns in FTL systems are the same as in VFL systems, because it also involves two non-colluding parties.
3. Preliminaries
3.1. Privacy and Security
3.2. Poisoning Attacks and Inference Attacks
4. Summary of Existing Studies
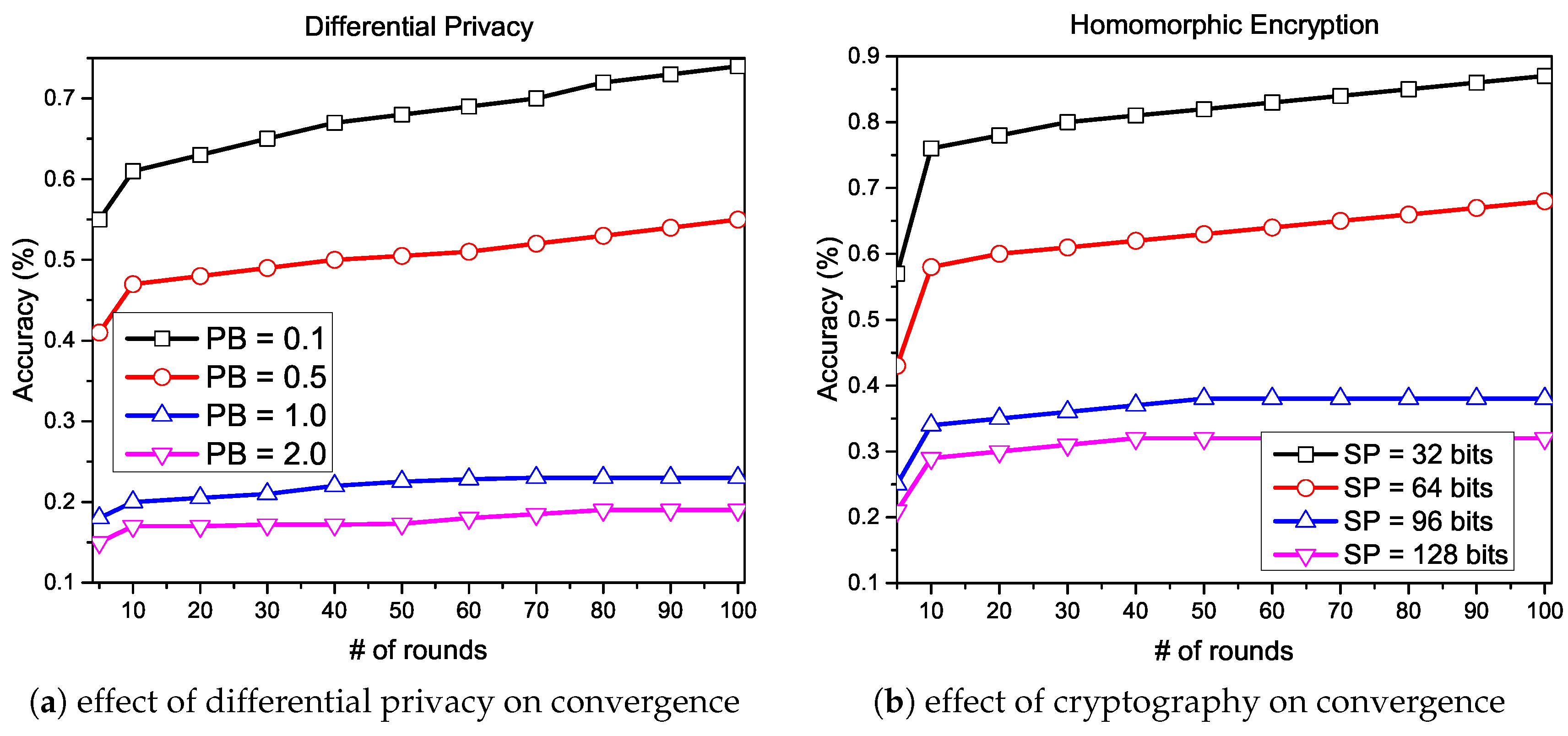
- Differential Privacy (DP): the differential privacy (DP) adds the random calibrated noises to the data or the model parameters to guarantee that the output function does not influence a single record. In Table 1, several existing studies adopt DP for privacy protection, where the adversaries cannot get the knowledge, whether the record has participated in the learning. The random calibrated noises provide statistical privacy guarantees to the individual’s record and prevents the model from inference attacks. However, the noises in the learning process tend to produce less accurate models, because the accuracy is inversely proportional to the added noises.
- Cryptography Techniques (CT): the cryptography techniques, such as homomorphic encryption and secure multi-party computation (SMC), are widely used in the existing literature of privacy-preserving FL algorithms. In particular, each client encrypts the update before uploading it to the cloud server, where the cloud server decrypts these updates in order to obtain a new global model. However, these techniques are vulnerable to inference attacks, because each client has to share the gradients accessible to the adversaries. Applying cryptography techniques to the FL systems can also result in major computation overhead, due to the extra operations of encryption and decryption.
5. Critical Evaluation of FL
5.1. Experimental Setup
5.2. Initialization Phase: A Privacy Threat
5.2.1. Experiment
5.2.2. Solution
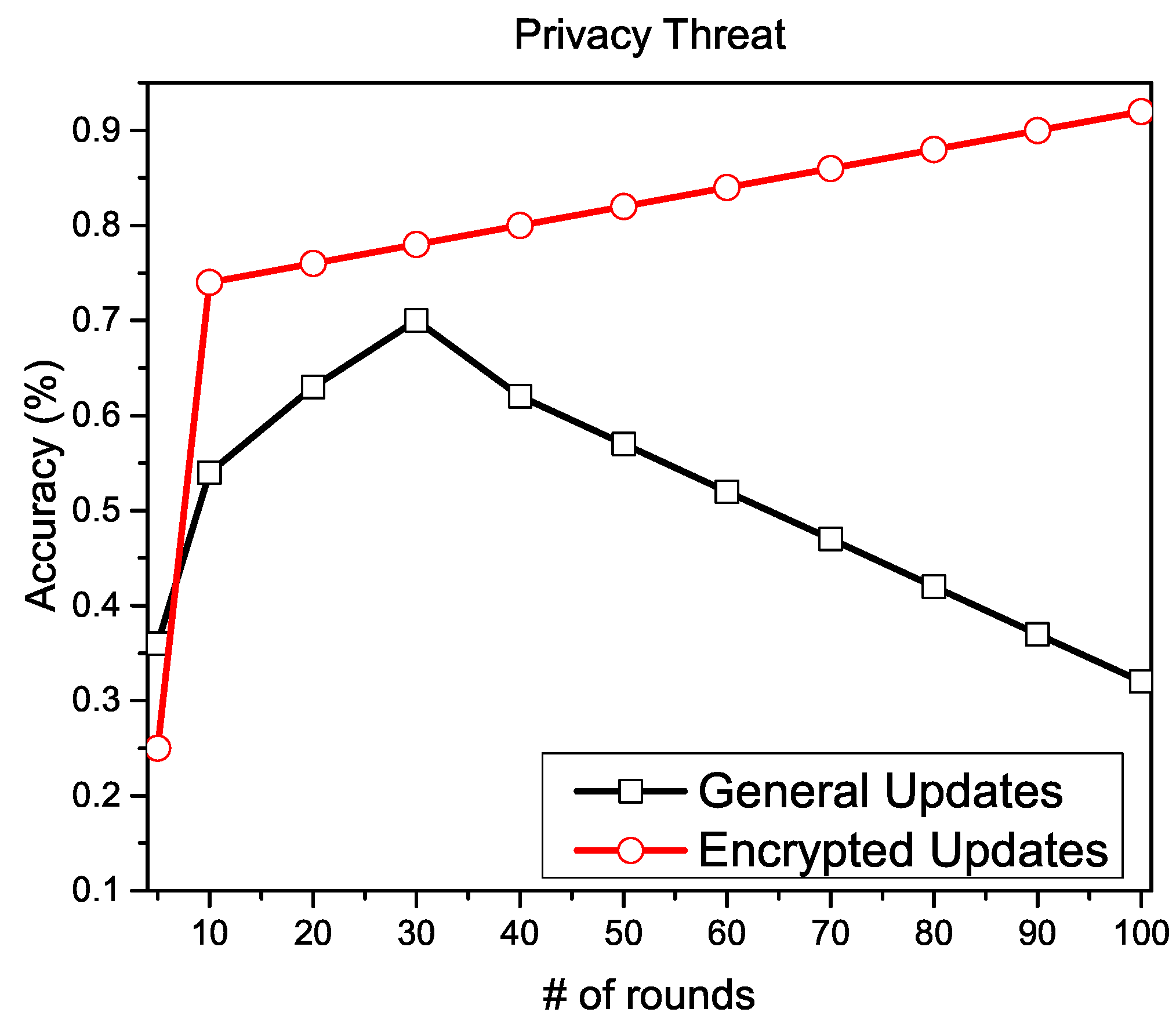
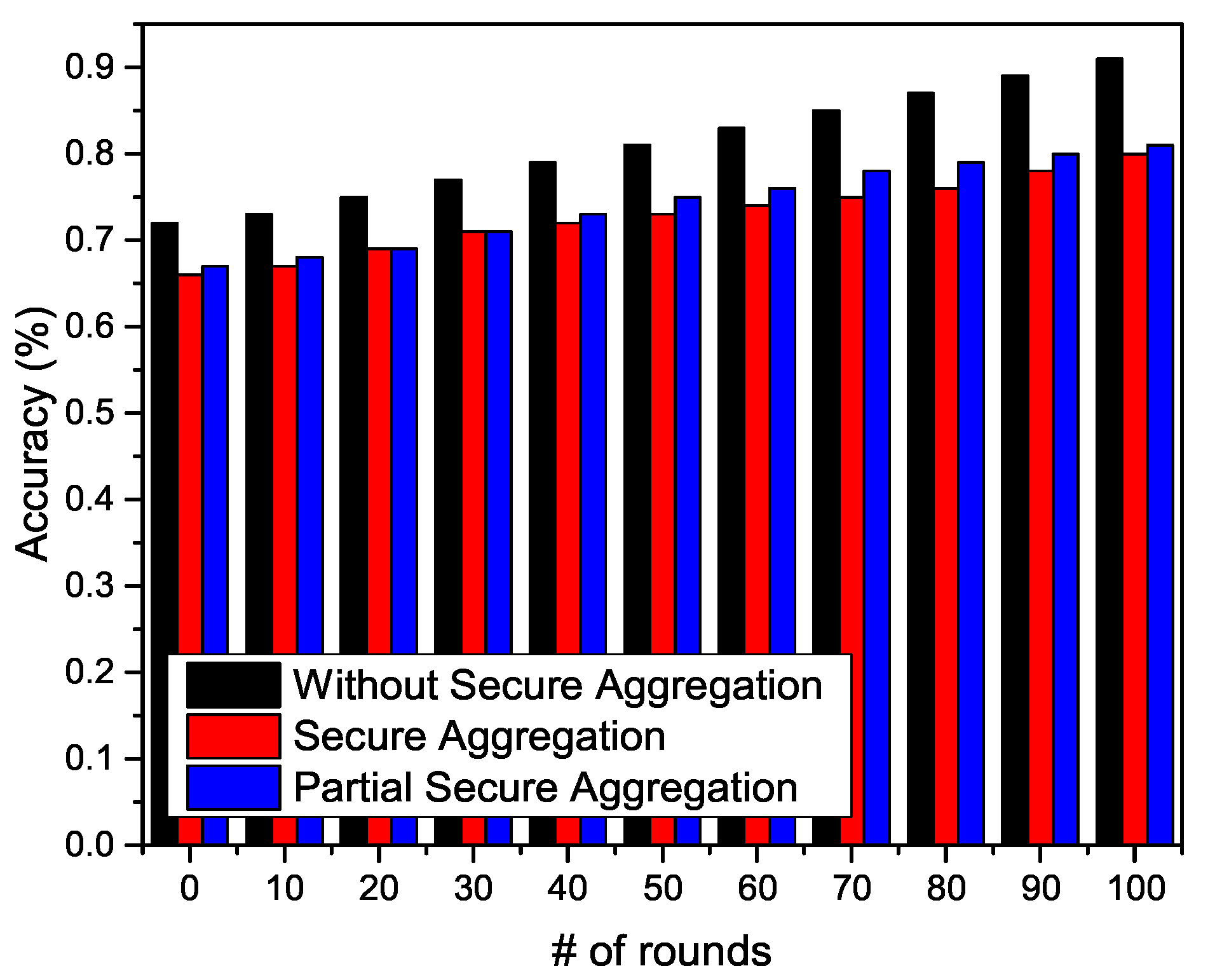
5.3. Local Updates Phase: A Privacy and Security Threat
5.3.1. Experiment
5.3.2. Solution
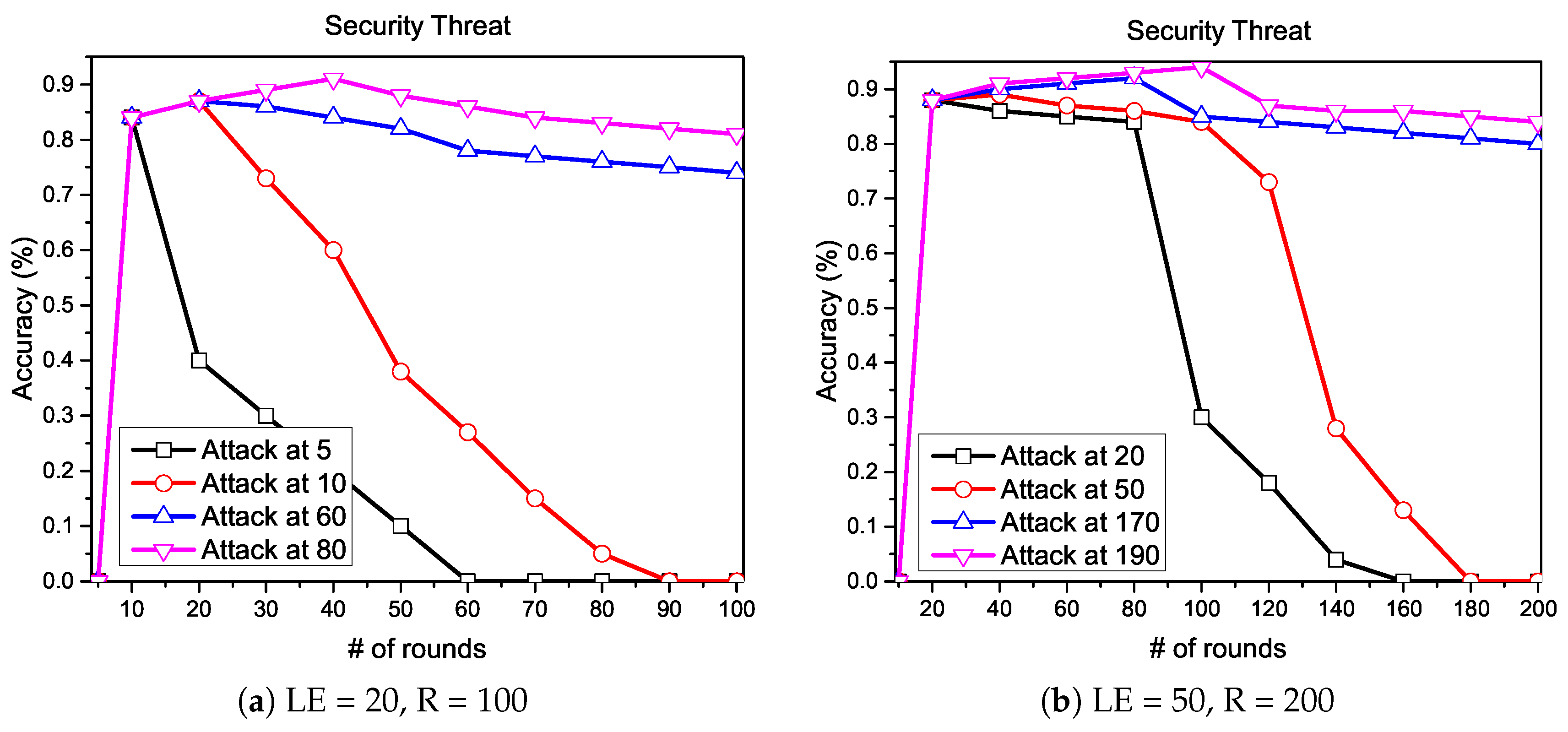
5.4. Model Aggregation Phase: A Security Threat
5.4.1. Experiment
5.4.2. Solution
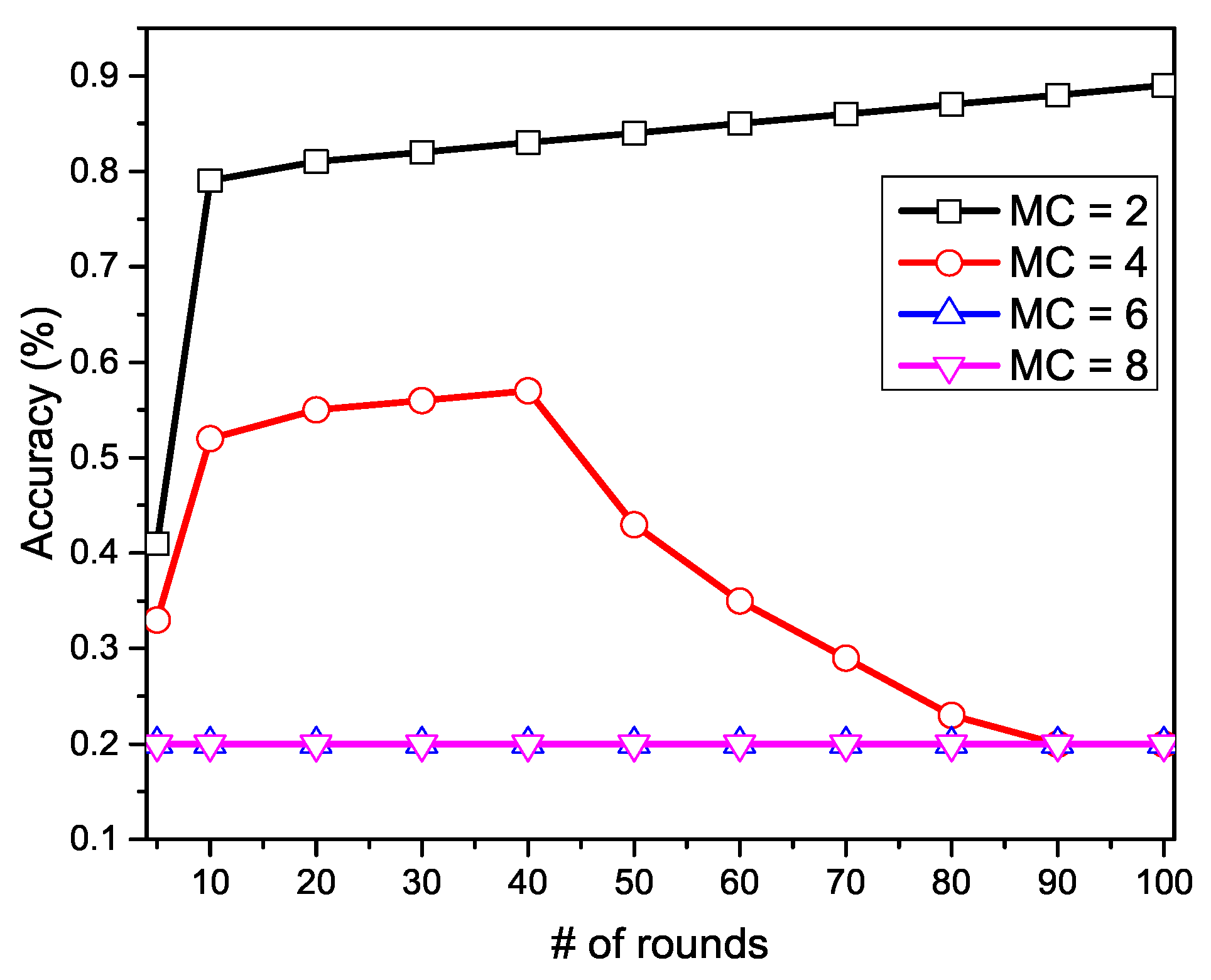
5.5. Convergence: Affected by Privacy Threat
5.5.1. Experiment
5.5.2. Solution
6. Discussion Future Directions
- Incremental Federated Learning: training on available datasets is limited to standard machine learning techniques. However, in most real applications, the datasets are not fixed, and the clients do not participate in training due to personalized datasets. Therefore, it is important to investigate the incremental learning, where the clients can train the same model on their own dataset. Additionally, efficient convergence on such models is another open challenge that will help FL to be implemented widely.
- Hierarchical Federated Learning: decomposition of FL tasks into a hierarchy of subtasks, so that higher-level parent-task invokes the lower-level child-task to perform primitive actions can bring robustness in overall performance of FL. The local epochs can further decompose in sub-local epochs to make a hierarchy and perform the FL tasks hierarchically for vigorous training. The privacy and security threats in hierarchical FL will be more exciting to investigate. The computation cost should also need to be considered while implementing hierarchical FL, as the decomposition might overload the clients.
- Mobile Federated Learning: generally, the clients in FL training are assumed to be stable with their constant geographic location. However, in the real world, this assumption may not be applied as the latest IoT smart devices are easy to move, and the clients have kept those devices with them. Thus, training on those devices with constant geographic location is impractical. Therefore, mobile federated learning should be considered for practical implementations.
- Decentralized Federated Learning: in the traditional FL settings, an untrusted cloud server is required for system initialization and global model aggregation. However, it would be an interesting study to eliminate this third party, and the clients elect themselves as a cloud server in a round-robin schedule. This technique will minimize the threats from the third party. However, malicious clients may have more chances to access the individual’s private information, especially when the malicious client acted as a server in the most recent round. Therefore, the privacy-preserving technique of decentralized FL should also be investigated.
- Adaptive Clustering: the work-load of individual clients can be divided into multiple clients through clustering, which can bring robustness in FL’s communication efficiency. In this system, one client can become a cluster-head and be responsible for communicating with the cloud server. In contrast, the other clients in the same cluster should only communicate and forward their local updates to their cluster-head. The selection mechanism of such clients can be done based on their previous updates and their available resources. The energy consumption of individual clients can be greatly reduced by forwarding the local updates at a minimum distance. However, sharing local updates in the cluster can bring higher privacy risks, as the malicious clients can be available at any cluster and so leak the individual’s private information.
- Clients Heterogeneity: in the general architecture of FL, the clients are considered to be homogeneous, which hinders FL from being implemented in many real applications. In real scenarios, the clients can be different from each other in many ways, such as: federation capacity, privacy requirements, reliability, and accessibility. Therefore, it is important to consider these practical scenarios in FL. Additionally, in real-applications, the number of clients may not be fixed, and training participation could be unstable. Thus, such a system should also support dynamic scheduling, which can adjust the learning strategy in the case of participation instability.
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Chang, C.; Srirama, S.N.; Buyya, R. Internet of Things (IoT) and new computing paradigms. Fog Edge Comput. Princ. Paradig. 2019, 6, 1–23. [Google Scholar]
- Konečný, J.; McMahan, H.B.; Ramage, D.; Richtárik, P. Federated optimization: Distributed machine learning for on-device intelligence. arXiv 2016, arXiv:1610.02527. [Google Scholar]
- Riedl, M.O. Human-centered artificial intelligence and machine learning. Hum. Behav. Emerg. Technol. 2019, 1, 33–36. [Google Scholar] [CrossRef] [Green Version]
- Feldstein, S. The road to digital unfreedom: How artificial intelligence is reshaping repression. J. Democr. 2019, 30, 40–52. [Google Scholar] [CrossRef]
- Cui, H.; Radosavljevic, V.; Chou, F.C.; Lin, T.H.; Nguyen, T.; Huang, T.K.; Schneider, J.; Djuric, N. Multimodal trajectory predictions for autonomous driving using deep convolutional networks. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 2090–2096. [Google Scholar]
- Eljawad, L.; Aljamaeen, R.; Alsmadi, M.K.; Al-Marashdeh, I.; Abouelmagd, H.; Alsmadi, S.; Haddad, F.; Alkhasawneh, R.A.; Alzughoul, M.; Alazzam, M.B. Arabic Voice Recognition Using Fuzzy Logic and Neural Network. Int. J. Appl. Eng. Res. 2019, 14, 651–662. [Google Scholar]
- Rønn, K.V.; Søe, S.O. Is social media intelligence private? Privacy in public and the nature of social media intelligence. Intell. Natl. Secur. 2019, 34, 362–378. [Google Scholar] [CrossRef]
- Nayak, S.K.; Ojha, A.C. Data Leakage Detection and Prevention: Review and Research Directions. In Machine Learning and Information Processing; Springer: Singapore, 2020; pp. 203–212. [Google Scholar]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics (AISTATS), Fort Lauderdale, FL, USA, 20–22 April 2017; Volume 54, pp. 1273–1282. [Google Scholar]
- Asad, M.; Moustafa, A.; Ito, T.; Aslam, M. Evaluating the Communication Efficiency in Federated Learning Algorithms. arXiv 2020, arXiv:2004.02738. [Google Scholar]
- Lu, Y.; Huang, X.; Dai, Y.; Maharjan, S.; Zhang, Y. Blockchain and federated learning for privacy-preserved data sharing in industrial IoT. IEEE Trans. Ind. Inform. 2019, 16, 4177–4186. [Google Scholar] [CrossRef]
- Dwork, C.; McSherry, F.; Nissim, K.; Smith, A. Calibrating noise to sensitivity in private data analysis. In Theory of Cryptography Conference; Springer: Berlin/Heidelberg, Germany, 2006; pp. 265–284. [Google Scholar]
- Papernot, N.; Abadi, M.; Erlingsson, U.; Goodfellow, I.; Talwar, K. Semi-supervised knowledge transfer for deep learning from private training data. arXiv 2016, arXiv:1610.05755. [Google Scholar]
- Aono, Y.; Hayashi, T.; Wang, L.; Moriai, S. Privacy-preserving deep learning via additively homomorphic encryption. IEEE Trans. Inf. Forensics Secur. 2017, 13, 1333–1345. [Google Scholar]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated machine learning: Concept and applications. ACM Trans. Intell. Syst. Technol. (TIST) 2019, 10, 1–19. [Google Scholar] [CrossRef]
- Wang, Z.; Song, M.; Zhang, Z.; Song, Y.; Wang, Q.; Qi, H. Beyond inferring class representatives: User-level privacy leakage from federated learning. In Proceedings of the IEEE INFOCOM 2019—IEEE Conference on Computer Communications, Paris, France, 29 April–2 May 2019; pp. 2512–2520. [Google Scholar]
- Li, Q.; Wen, Z.; He, B. Federated learning systems: Vision, hype and reality for data privacy and protection. arXiv 2019, arXiv:1907.09693. [Google Scholar]
- Bae, H.; Jang, J.; Jung, D.; Jang, H.; Ha, H.; Yoon, S. Security and privacy issues in deep learning. arXiv 2018, arXiv:1807.11655. [Google Scholar]
- Nishio, T.; Yonetani, R. Client selection for federated learning with heterogeneous resources in mobile edge. In Proceedings of the ICC 2019—2019 IEEE International Conference on Communications (ICC), Shanghai, China, 21–23 May 2019; pp. 1–7. [Google Scholar]
- Kim, H.; Park, J.; Bennis, M.; Kim, S.L. On-device federated learning via blockchain and its latency analysis. arXiv 2018, arXiv:1808.03949. [Google Scholar]
- Zhao, L.; Ni, L.; Hu, S.; Chen, Y.; Zhou, P.; Xiao, F.; Wu, L. Inprivate digging: Enabling tree-based distributed data mining with differential privacy. In Proceedings of the IEEE INFOCOM 2018—IEEE Conference on Computer Communications, Honolulu, HI, USA, 15–19 April 2018; pp. 2087–2095. [Google Scholar]
- Bhagoji, A.N.; Chakraborty, S.; Mittal, P.; Calo, S. Analyzing federated learning through an adversarial lens. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 634–643. [Google Scholar]
- Segal, A.; Marcedone, A.; Kreuter, B.; Ramage, D.; McMahan, H.B.; Seth, K.; Patel, S.; Bonawitz, K.; Ivanov, V. Practical secure aggregation for privacy-preserving machine learning. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017. [Google Scholar]
- Liu, Y.; Ma, Z.; Liu, X.; Ma, S.; Nepal, S.; Deng, R. Boosting privately: Privacy-preserving federated extreme boosting for mobile crowdsensing. arXiv 2019, arXiv:1907.10218. [Google Scholar]
- Cheng, K.; Fan, T.; Jin, Y.; Liu, Y.; Chen, T.; Yang, Q. Secureboost: A lossless federated learning framework. arXiv 2019, arXiv:1901.08755. [Google Scholar]
- Li, T.; Sanjabi, M.; Beirami, A.; Smith, V. Fair resource allocation in federated learning. arXiv 2019, arXiv:1905.10497. [Google Scholar]
- Asad, M.; Moustafa, A.; Ito, T. FedOpt: Towards Communication Efficiency and Privacy Preservation in Federated Learning. Appl. Sci. 2020, 10, 2864. [Google Scholar] [CrossRef] [Green Version]
- Fang, M.; Cao, X.; Jia, J.; Gong, N. Local model poisoning attacks to Byzantine-robust federated learning. In Proceedings of the 29th USENIX Security Symposium (USENIX Security 20), Boston, MA, USA, 12–14 August 2020; pp. 1605–1622. [Google Scholar]
- Bhowmick, A.; Duchi, J.; Freudiger, J.; Kapoor, G.; Rogers, R. Protection against reconstruction and its applications in private federated learning. arXiv 2018, arXiv:1812.00984. [Google Scholar]
- Xie, C.; Huang, K.; Chen, P.Y.; Li, B. DBA: Distributed Backdoor Attacks against Federated Learning. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Li, Q.; Wen, Z.; He, B. Practical Federated Gradient Boosting Decision Trees. In Proceedings of the AAAI, New York, NY, USA, 7–12 February 2020; pp. 4642–4649. [Google Scholar]
- Sahu, A.K.; Li, T.; Sanjabi, M.; Zaheer, M.; Talwalkar, A.; Smith, V. On the convergence of federated optimization in heterogeneous networks. arXiv 2018, arXiv:1812.06127, 3. [Google Scholar]
- Kang, J.; Xiong, Z.; Niyato, D.; Xie, S.; Zhang, J. Incentive mechanism for reliable federated learning: A joint optimization approach to combining reputation and contract theory. IEEE Internet Things J. 2019, 6, 10700–10714. [Google Scholar] [CrossRef]
- Truex, S.; Baracaldo, N.; Anwar, A.; Steinke, T.; Ludwig, H.; Zhang, R.; Zhou, Y. A hybrid approach to privacy-preserving federated learning. In Proceedings of the 12th ACM Workshop on Artificial Intelligence and Security, London, UK, 11–15 November 2019; pp. 1–11. [Google Scholar]
- So, J.; Guler, B.; Avestimehr, A.S. Byzantine-resilient secure federated learning. arXiv 2020, arXiv:2007.11115. [Google Scholar]
- Liu, Y.; Kang, Y.; Zhang, X.; Li, L.; Cheng, Y.; Chen, T.; Hong, M.; Yang, Q. A communication efficient vertical federated learning framework. arXiv 2019, arXiv:1912.11187. [Google Scholar]
- McMahan, H.B.; Ramage, D.; Talwar, K.; Zhang, L. Learning differentially private recurrent language models. arXiv 2017, arXiv:1710.06963. [Google Scholar]
- Liu, Y.; Liu, Y.; Liu, Z.; Liang, Y.; Meng, C.; Zhang, J.; Zheng, Y. Federated forest. IEEE Trans. Big Data 2020. [Google Scholar] [CrossRef]
- Hardy, S.; Henecka, W.; Ivey-Law, H.; Nock, R.; Patrini, G.; Smith, G.; Thorne, B. Private federated learning on vertically partitioned data via entity resolution and additively homomorphic encryption. arXiv 2017, arXiv:1711.10677. [Google Scholar]
- Sanil, A.P.; Karr, A.F.; Lin, X.; Reiter, J.P. Privacy preserving regression modelling via distributed computation. In Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 22–25 August 2004; pp. 677–682. [Google Scholar]
- Chen, Y.R.; Rezapour, A.; Tzeng, W.G. Privacy-preserving ridge regression on distributed data. Inf. Sci. 2018, 451, 34–49. [Google Scholar] [CrossRef]
- Nikolaenko, V.; Weinsberg, U.; Ioannidis, S.; Joye, M.; Boneh, D.; Taft, N. Privacy-preserving ridge regression on hundreds of millions of records. In Proceedings of the 2013 IEEE Symposium on Security and Privacy, Berkeley, CA, USA, 19–22 May 2013; pp. 334–348. [Google Scholar]
- Bagdasaryan, E.; Veit, A.; Hua, Y.; Estrin, D.; Shmatikov, V. How to backdoor federated learning. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Palermo, Italy, 3–5 June 2020; pp. 2938–2948. [Google Scholar]
- Ma, C.; Li, J.; Ding, M.; Yang, H.H.; Shu, F.; Quek, T.Q.; Poor, H.V. On Safeguarding Privacy and Security in the Framework of Federated Learning. IEEE Netw. 2020, 34, 242–248. [Google Scholar] [CrossRef] [Green Version]
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Bhagoji, A.N.; Bonawitz, K.; Charles, Z.; Cormode, G.; d’Oliveira, R.G.; et al. Advances and open problems in federated learning. arXiv 2019, arXiv:1912.04977. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Existing Literature | FL Classification | Model Used | Network Architecture | Privacy Mechanism |
|---|---|---|---|---|
| FedCS [19] | HFL | NN | centralized | general |
| BlockFL [20] | HFL | LM | centralized | general |
| Tree-based FL [21] | HFL | DT | distributed | DP |
| Adversarial Lens [22] | HFL | NN | centralized | general |
| Secure Aggregation [23] | HFL | NN | centralized | CT |
| FedXGB [24] | HFL | DT | centralized | CT |
| SecureBoost [25] | VFL | DT | centralized | CT |
| q-FedAvg [26] | HFL | NN, LM | centralized | general |
| FedOpt [27] | HFL | NN, LM | centralized | DP, CT |
| Byzantine-Robust FL [28] | HFL | NN | Centralized | None |
| Local DPFL [29] | HFL | NN, LM | centralized | DP |
| Distributed Backdoor [30] | HFL | NN | centralized | general |
| SimFL [31] | HFL | DT | distributed | hashing |
| FedProx [32] | HFL | general | centralized | general |
| Reputation FL [33] | HFL | LM | centralized | general |
| Hybrid FL [34] | HFL | NN, LM | centralized | DP, CT |
| BREA [35] | HFL | NN | centralized | SA |
| FedBCD [36] | VFL | NN | centralized | general |
| FL-LSTM [37] | HFL | NN | centralized | DP |
| FedForest [38] | HFL | DT | centralized | CT |
| Logistic Regression FL [39] | HFL | LM | centralized | CT |
| Linear Regression FL [40] | VFL | LM | centralized | CT |
| PPRR [41] | HFL | LM | centralized | CT |
| Ridge Regression FL [42] | HFL | LM | centralized | CT |
| Backdoor FL [43] | HFL | NN | centralized | general |
| Sr # | FL Phase | Issue | Target | Attacks | Attacker | ||
|---|---|---|---|---|---|---|---|
| Model | Training Data | Participant | Server | ||||
| 1 | Initialization | Privacy | No | Yes | Inference Attacks | Yes | Yes |
| 2 | Local Updates | Security | Yes | No | |||
| 3 | Model Aggregation | Security | Yes | No | Poisoning Attacks | No | Yes |
| 4 | Convergence | Privacy | Yes | No | |||
| Parameter | Value |
|---|---|
| Network Size | |
| Global rounds | 100 |
| Local epochs | 20 |
| Learning rate | |
| Non-IID degree | |
| Client transmission power | 200 mW |
| Local update size | 20,000 nats |
| Mini-batch size | 32 |
| Type of Layer | Layer Size |
|---|---|
| Convolution + ReLu layer 1 | |
| Max pooling layer 1 | |
| Convolution + ReLu layer 2 | |
| Max pooling layer 2 | |
| Fully connected + ReLu layer | 220 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Asad, M.; Moustafa, A.; Yu, C. A Critical Evaluation of Privacy and Security Threats in Federated Learning. Sensors 2020, 20, 7182. https://doi.org/10.3390/s20247182
Asad M, Moustafa A, Yu C. A Critical Evaluation of Privacy and Security Threats in Federated Learning. Sensors. 2020; 20(24):7182. https://doi.org/10.3390/s20247182
Chicago/Turabian StyleAsad, Muhammad, Ahmed Moustafa, and Chao Yu. 2020. "A Critical Evaluation of Privacy and Security Threats in Federated Learning" Sensors 20, no. 24: 7182. https://doi.org/10.3390/s20247182