Semantic Segmentation of Intralobular and Extralobular Tissue from Liver Scaffold H&E Images

 ,
,  , , , , , , , , , and
, , , , , , , , , and
Abstract
:1. Introduction
- 1
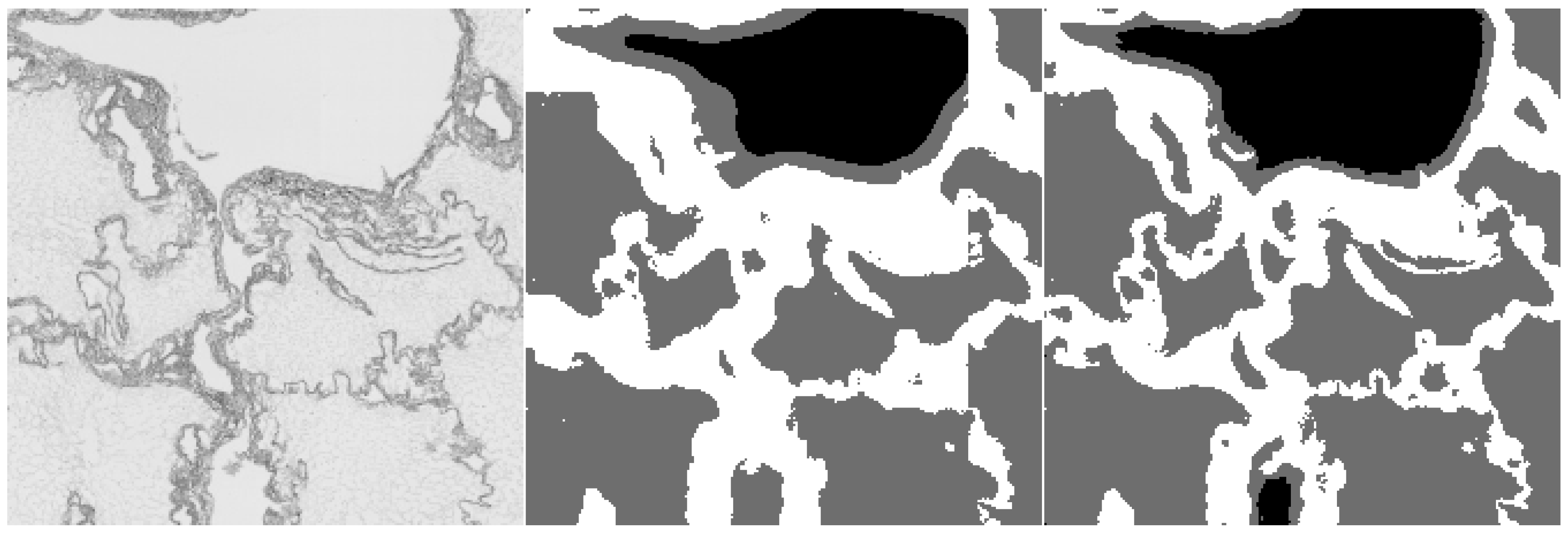
- We introduce a two-stage method for semantic segmentation of liver scaffold hematoxylin-eosin (H&E) stained section images. In the first stage, we train the Naive Bayes classifier on simple texture descriptors. In the second stage, we utilize the classifier’s outputs as training data for U-Net-based convolutional neural network.
- 2
- We compare the single-stage approach with the two-stage method on a small subset of manually annotated data with the two-stage method reaching superior results.
2. Materials and Methods
2.1. Scaffold Sample Preparation
2.2. Histological Staining and Imaging
2.3. Image Processing
2.4. Preprocessing and Data Annotation
2.5. Handcrafted Texture Feature Segmentation (HCTFS)
2.6. Fully-Convolutional Neural Network
3. Experiments and Results
3.1. Handcrafted Texture Feature Segmentation
3.2. Semantic Segmentation via CNN
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| CNN | Convolutional Neural Network |
| H&E | Hematoxylin-eosin-staining |
| WSS | Whole Slide Scan |
| HCTFS | Handcrafted Texture Feature Segmentation |
References
- Hussey, G.S.; Dziki, J.L.; Badylak, S.F. Extracellular matrix-based materials for regenerative medicine. Nat. Rev. Mater. 2018, 3, 159–173. [Google Scholar] [CrossRef]
- Porzionato, A.; Stocco, E.; Barbon, S.; Grandi, F.; Macchi, V.; De Caro, R. Tissue-engineered grafts from human decellularized extracellular matrices: A systematic review and future perspectives. Int. J. Mol. Sci. 2018, 19, 4117. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mazza, G.; Al-Akkad, W.; Rombouts, K.; Pinzani, M. Liver tissue engineering: From implantable tissue to whole organ engineering. Hepatol. Commun. 2018, 2, 131–141. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, Q.; Johnson, J.A.; Dunne, L.W.; Chen, Y.; Iyyanki, T.; Wu, Y.; Chang, E.I.; Branch-Brooks, C.D.; Robb, G.L.; Butler, C.E. Decellularized skin/adipose tissue flap matrix for engineering vascularized composite soft tissue flaps. Acta Biomater. 2016, 35, 166–184. [Google Scholar] [CrossRef] [Green Version]
- Atala, A.; Kurtis Kasper, F.; Mikos, A.G. Engineering complex tissues. Sci. Transl. Med. 2012, 4, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Wuensch, A.; Baehr, A.; Bongoni, A.K.; Kemter, E.; Blutke, A.; Baars, W.; Haertle, S.; Zakhartchenko, V.; Kurome, M.; Kessler, B.; et al. Regulatory Sequences of the Porcine THBD Gene Facilitate Endothelial-Specific Expression of Bioactive Human Thrombomodulin in Single- and Multitransgenic Pigs. Transplantation 2014, 97, 138–147. [Google Scholar] [CrossRef] [Green Version]
- Poornejad, N.; Momtahan, N.; Salehi, A.S.; Scott, D.R.; Fronk, C.A.; Roeder, B.L.; Reynolds, P.R.; Bundy, B.C.; Cook, A.D. Efficient decellularization of whole porcine kidneys improves reseeded cell behavior. Biomed. Mater. 2016, 11, 025003. [Google Scholar] [CrossRef]
- Moulisová, V.; Jiřík, M.; Schindler, C.; Červenková, L.; Pálek, R.; Rosendorf, J.; Arlt, J.; Bolek, L.; Šůsová, S.; Nietzsche, S.; et al. Novel morphological multi-scale evaluation system for quality assessment of decellularized liver scaffolds. J. Tissue Eng. 2020, 11. [Google Scholar] [CrossRef]
- Crapo, P.M.; Gilbert, T.W.; Badylak, S.F. An overview of tissue and whole organ decellularization processes. Biomaterials 2011, 32, 3233–3243. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Nicolas, C.T.; Chen, H.S.; Ross, J.J.; De Lorenzo, S.B.; Nyberg, S.L. Recent Advances in Decellularization and Recellularization for Tissue-Engineered Liver Grafts. Cells Tissues Organs 2017, 204, 125–136. [Google Scholar] [CrossRef]
- Amin, A.; Mahmoud-Ghoneim, D. Texture analysis of liver fibrosis microscopic images: A study on the effect of biomarkers. Acta Biochim. Biophys. Sin. 2011, 43, 193–203. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Haralick, R.M. Statistical and structural approaches to texture. Proc. IEEE 1979, 67, 786–804. [Google Scholar] [CrossRef]
- Kang, H.K.; Kim, K.H.; Ahn, J.S.; Kim, H.B.; Yi, J.H.; Kim, H.S. A simple segmentation and quantification method for numerical quantitative analysis of cells and tissues. Technol. Health Care 2020, 28, S401–S410. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Vu, Q.D.; Graham, S.; Kurc, T.; To, M.N.N.; Shaban, M.; Qaiser, T.; Koohbanani, N.A.; Khurram, S.A.; Kalpathy-Cramer, J.; Zhao, T.; et al. Methods for segmentation and classification of digital microscopy tissue images. Front. Bioeng. Biotechnol. 2019, 7, 53. [Google Scholar] [CrossRef]
- John, G.H.; Langley, P. Estimating Continuous Distributions in Bayesian Classifiers. In Proceedings of the Eleventh Conference on Uncertainty in Artificial Intelligence; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1995; pp. 338–345. [Google Scholar]
- Blinchikoff, H.J.; Zverev, A.I. Filtering in the Time and Frequency Domains; Wiley: New York, NY, USA, 1976; p. 12. [Google Scholar]
- Duda, R.O.; Hart, P.E. Pattern Classification and Scene Analysis; Wiley: New York, NY, USA, 1973; Volume 3. [Google Scholar]
- Lee, E.P.; Lee, E.P.; Lozeille, J.; Soldán, P.; Daire, S.E.; Dyke, J.M.; Wright, T.G. An empirical study of the naive Bayes classifier. Phys. Chem. Chem. Phys. 2001, 3, 4863–4869. [Google Scholar] [CrossRef]
- Zhang, H. Exploring conditions for the optimality of naïve bayes. Int. J. Pattern Recognit. Artif. Intell. 2005, 19, 183–198. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1520–1528. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland; pp. 234–241.
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Bureš, L.; Gruber, I.; Neduchal, P.; Hlaváč, M.; Hrúz, M. Semantic text segmentation from synthetic images of full-text documents. SPIIRAS Proc. 2019, 18, 1381–1406. [Google Scholar] [CrossRef]
- Tokui, S.; Oono, K.; Hido, S.; Clayton, J. Chainer: A next-generation open source framework for deep learning. In Proceedings of the Workshop on Machine Learning Systems (LearningSys) in the Twenty-Ninth Annual Conference on Neural Information Processing Systems (NIPS), Montreal, Canada, 11–12 December 2015; Volume 5, pp. 1–6. [Google Scholar]
- Akiba, T.; Fukuda, K.; Suzuki, S. ChainerMN: Scalable distributed deep learning framework. arXiv 2017, arXiv:1710.11351. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Maghsoudlou, P.; Georgiades, F.; Smith, H.; Milan, A.; Shangaris, P.; Urbani, L.; Loukogeorgakis, S.P.; Lombardi, B.; Mazza, G.; Hagen, C.; et al. Optimization of Liver Decellularization Maintains Extracellular Matrix Micro-Architecture and Composition Predisposing to Effective Cell Seeding. PLoS ONE 2016, 11, e0155324. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mirmalek-Sani, S.H.; Sullivan, D.C.; Zimmerman, C.; Shupe, T.D.; Petersen, B.E. Immunogenicity of decellularized porcine liver for bioengineered hepatic tissue. Am. J. Pathol. 2013, 183, 558–565. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Struecker, B.; Hillebrandt, K.H.; Voitl, R.; Butter, A.; Schmuck, R.B.; Reutzel-Selke, A.; Geisel, D.; Joehrens, K.; Pickerodt, P.A.; Raschzok, N.; et al. Porcine liver decellularization under oscillating pressure conditions: A technical refinement to improve the homogeneity of the decellularization process. Tissue Eng. Part C Methods 2015, 21, 303–313. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Dev Set | Test Set |
|---|---|---|
| HCTFS | 86.47% | 86.51% |
| UNet-Mini | 90.87% | 90.67% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jirik, M.; Gruber, I.; Moulisova, V.; Schindler, C.; Cervenkova, L.; Palek, R.; Rosendorf, J.; Arlt, J.; Bolek, L.; Dejmek, J.; et al. Semantic Segmentation of Intralobular and Extralobular Tissue from Liver Scaffold H&E Images. Sensors 2020, 20, 7063. https://doi.org/10.3390/s20247063
Jirik M, Gruber I, Moulisova V, Schindler C, Cervenkova L, Palek R, Rosendorf J, Arlt J, Bolek L, Dejmek J, et al. Semantic Segmentation of Intralobular and Extralobular Tissue from Liver Scaffold H&E Images. Sensors. 2020; 20(24):7063. https://doi.org/10.3390/s20247063
Chicago/Turabian StyleJirik, Miroslav, Ivan Gruber, Vladimira Moulisova, Claudia Schindler, Lenka Cervenkova, Richard Palek, Jachym Rosendorf, Janine Arlt, Lukas Bolek, Jiri Dejmek, and et al. 2020. "Semantic Segmentation of Intralobular and Extralobular Tissue from Liver Scaffold H&E Images" Sensors 20, no. 24: 7063. https://doi.org/10.3390/s20247063