LiDAR Point Cloud Recognition and Visualization with Deep Learning for Overhead Contact Inspection

 , , , , , and
, , , , , and
Abstract
:1. Introduction
1.1. Background
1.2. Motivation
1.3. Our Contribution
2. Related Work
3. Proposed Methods
3.1. Point Cloud Recognition
3.2. Optimizing Model
3.3. Constructing Visualization Software for Point Cloud Recognition
| Algorithm 1 Visualization algorithm |
| Input: files that store point cloud data |
| Output: visualization results |
|
4. Experiments
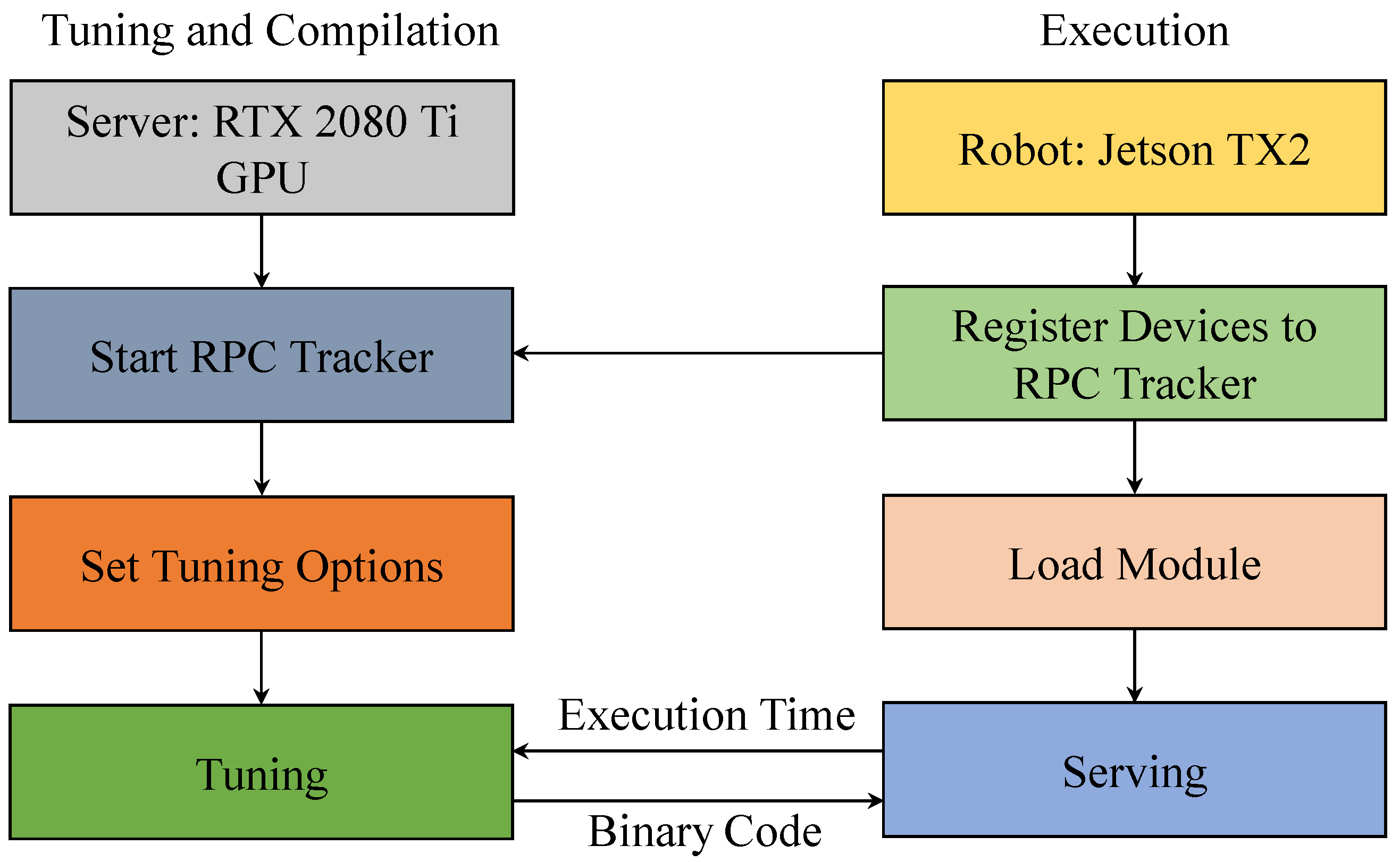
4.1. Experimental Environment
4.2. Datasets
4.3. Metrics
- ,
- ,
5. Results and Analysis
5.1. Comparison of the Point Cloud Recognition Results
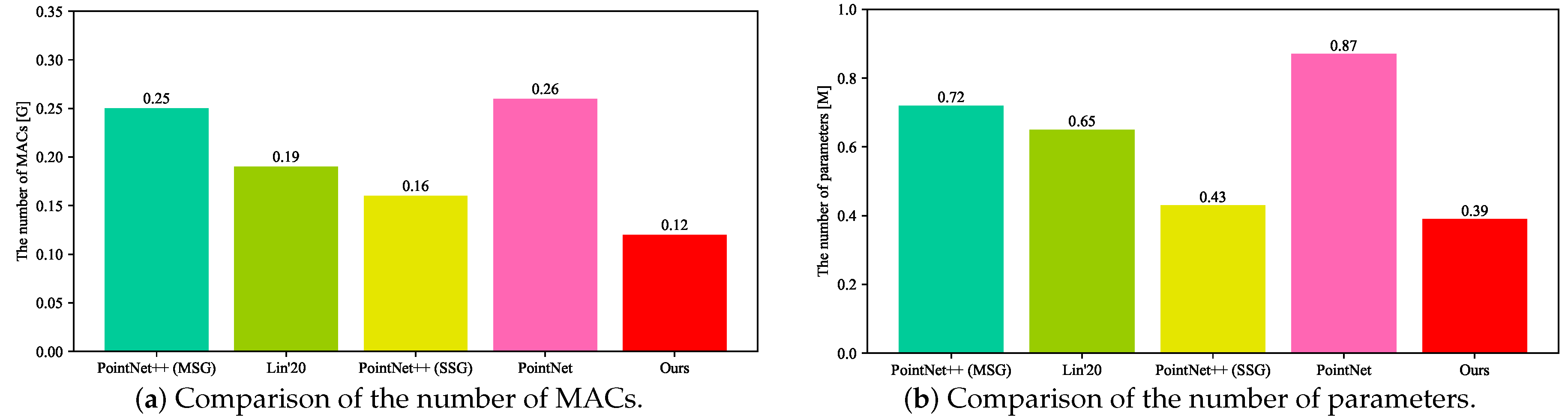
5.2. Comparison of the Number of MACs and Parameters
5.3. Comparison of Inference Runtime on Different Platforms
5.4. Effect of the Number of Optimizing Trials on Runtime
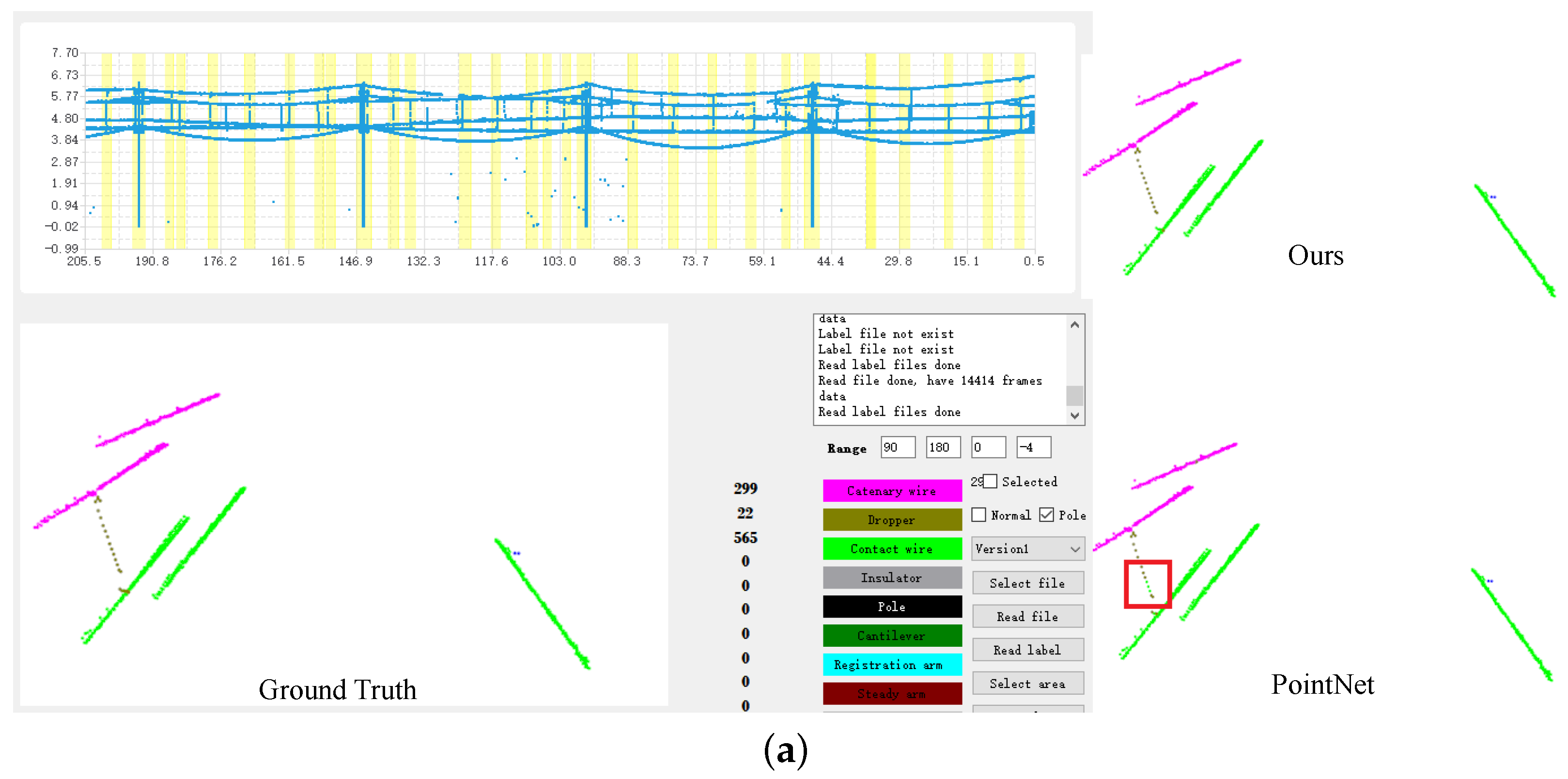
5.5. Comparison of the Visualized Results
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Owda, A.; Balsa-Barreiro, J.; Fritsch, D. Methodology for digital preservation of the cultural and patrimonial heritage: Generation of a 3D model of the Church St. Peter and Paul (Calw, Germany) by using laser scanning and digital photogrammetry. Sens. Rev. 2018, 38, 282–288. [Google Scholar] [CrossRef]
- Balsa-Barreiro, J.; Fritsch, D. Generation of visually aesthetic and detailed 3D models of historical cities by using laser scanning and digital photogrammetry. Digit. Appl. Archaeol. Cult. Herit. 2018, 8, 57–64. [Google Scholar] [CrossRef]
- Tang, Y.; Chen, M.; Lin, Y.; Huang, X.; Huang, K.; He, Y.; Li, L. Vision-Based Three-Dimensional Reconstruction and Monitoring of Large-Scale Steel Tubular Structures. Adv. Civ. Eng. 2020, 2020, 1236021. [Google Scholar] [CrossRef]
- Balsa-Barreiro, J.; Fritsch, D. Generation of 3D/4D Photorealistic Building Models. The Testbed Area for 4D Cultural Heritage World Project: The Historical Center of Calw (Germany). In International Symposium on Visual Computing (ISVC); Springer: Cham, Switzerland, 2015; pp. 361–372. [Google Scholar]
- Mueller, A.R. LiDAR and Image Point Cloud Comparison. Available online: https://calhoun.nps.edu/handle/10945/43960 (accessed on 14 September 2014).
- Tang, Y.; Li, L.; Wang, C.; Chen, M.; Feng, W.; Zou, X.; Huang, K. Real-time detection of surface deformation and strain in recycled aggregate concrete-filled steel tubular columns via four-ocular vision. Robot. Comput. Integr. Manuf. 2019, 59, 36–46. [Google Scholar] [CrossRef]
- Chen, M.; Tang, Y.; Zou, X.; Huang, K.; Li, L.; He, Y. High-accuracy multi-camera reconstruction enhanced by adaptive point cloud correction algorithm. Opt. Lasers Eng. 2019, 122, 170–183. [Google Scholar] [CrossRef]
- Duan, M.; Li, K.; Liao, X.; Li, K. A Parallel Multiclassification Algorithm for Big Data Using an Extreme Learning Machine. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 2337–2351. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Li, K.; Tang, Z.; Bilal, K.; Yu, S.; Weng, C.; Li, K. A Parallel Random Forest Algorithm for Big Data in a Spark Cloud Computing Environment. IEEE Trans. Parallel Distrib. Syst. 2017, 28, 919–933. [Google Scholar] [CrossRef] [Green Version]
- Chen, C.; Li, K.; Ouyang, A.; Li, K. FlinkCL: An OpenCL-Based In-Memory Computing Architecture on Heterogeneous CPU-GPU Clusters for Big Data. IEEE Trans. Comput. 2018, 67, 1765–1779. [Google Scholar] [CrossRef]
- Chen, L.; Xu, C.; Lin, S.; Li, S.; Tu, X. A Deep Learning-Based Method for Overhead Contact System Component Recognition Using Mobile 2D LiDAR. Sensors 2020, 20, 2224. [Google Scholar] [CrossRef] [Green Version]
- Kang, G.; Gao, S.; Yu, L.; Zhang, D.; Wei, X.; Zhan, D. Contact Wire Support Defect Detection Using Deep Bayesian Segmentation Neural Networks and Prior Geometric Knowledge. IEEE Access 2019, 7, 173366–173376. [Google Scholar] [CrossRef]
- Lin, S.; Xu, C.; Chen, L.; Li, S.; Tu, X. LiDAR Point Cloud Recognition of Overhead Catenary System with Deep Learning. Sensors 2020, 20, 2212. [Google Scholar] [CrossRef] [Green Version]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 77–85. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5099–5108. [Google Scholar]
- Xie, G.; Zeng, G.; Jiang, J.; Fan, C.; Li, R.; Li, K. Energy management for multiple real-time workflows on cyber—Physical cloud systems. Future Gener. Comput. Syst. 2020, 105, 916–931. [Google Scholar] [CrossRef]
- Tu, X.; Xu, C.; Liu, S.; Li, R.; Xie, G.; Huang, J.; Yang, L. Efficient monocular depth estimation for edge devices in internet of things. IEEE Trans. Ind. Informat. 2020, 1–12. [Google Scholar] [CrossRef]
- Chen, W.; Xie, G.; Li, R.; Bai, Y.; Fan, C.; Li, K. Efficient task scheduling for budget constrained parallel applications on heterogeneous cloud computing systems. Future Gener. Comput. Syst. 2017, 74, 1–11. [Google Scholar] [CrossRef]
- Chen, W.; An, J.; Li, R.; Fu, L.; Xie, G.; Bhuiyan, M.Z.A.; Li, K. A novel fuzzy deep-learning approach to traffic flow prediction with uncertain spatial—Temporal data features. Future Gener. Comput. Syst. 2018, 89, 78–88. [Google Scholar] [CrossRef]
- Nai, K.; Xiao, D.; Li, Z.; Jiang, S.; Gu, Y. Multi-pattern correlation tracking. Knowl. Based Syst. 2019, 181, 104789. [Google Scholar] [CrossRef]
- Li, G.; Peng, M.; Nai, K.; Li, Z.; Li, K. Reliable correlation tracking via dual-memory selection model. Inf. Sci. 2020, 518, 238–255. [Google Scholar] [CrossRef]
- Xie, G.; Zeng, G.; Xiao, X.; Li, R.; Li, K. Energy-Efficient Scheduling Algorithms for Real-Time Parallel Applications on Heterogeneous Distributed Embedded Systems. IEEE Trans. Parallel Distrib. Syst. 2017, 28, 3426–3442. [Google Scholar] [CrossRef]
- Huang, J.; Li, R.; An, J.; Ntalasha, D.; Yang, F.; Li, K. Energy-Efficient Resource Utilization for Heterogeneous Embedded Computing Systems. IEEE Trans. Comput. 2017, 66, 1518–1531. [Google Scholar] [CrossRef]
- Chen, T.; Moreau, T.; Jiang, Z.; Zheng, L.; Yan, E.; Cowan, M.; Shen, H.; Wang, L.; Hu, Y.; Ceze, L.; et al. TVM: An Automated End-to-End Optimizing Compiler for Deep Learning. In Proceedings of the 13th USENIX Conference on Operating Systems Design and Implementation, Carlsbad, CA, USA, 8–10 October 2018; pp. 579–594. [Google Scholar]
- Zhou, J.; Han, Z.; Wang, L. A Steady Arm Slope Detection Method Based on 3D Point Cloud Segmentation. In Proceedings of the IEEE 3rd International Conference on Image, Vision and Computing (ICIVC), Chongqing, China, 27–29 June 2018; pp. 278–282. [Google Scholar]
- Han, Z.; Yang, C.; Liu, Z. Cantilever Structure Segmentation and Parameters Detection Based on Concavity and Convexity of 3D Point Clouds. IEEE Trans. Instrum. Meas. 2019. [Google Scholar] [CrossRef]
- Guo, B.; Yu, Z.; Zhang, N.; Zhu, L.; Gao, C. 3D point cloud segmentation, classification and recognition algorithm of railway scene. Chin. J. Sci. Instrum. 2017, 38, 2103–2111. [Google Scholar]
- Verdoja, F.; Thomas, D.; Sugimoto, A. Fast 3D point cloud segmentation using supervoxels with geometry and color for 3D scene understanding. In Proceedings of the IEEE International Conference on Multimedia and Expo (ICME), Hong Kong, China, 10–14 July 2017; pp. 1285–1290. [Google Scholar]
- Liu, Z.; Zhong, J.; Lyu, Y.; Liu, K.; Han, Y.; Wang, L.; Liu, W. Location and fault detection of catenary support components based on deep learning. In Proceedings of the IEEE International Instrumentation and Measurement Technology Conference (I2MTC), Houston, TX, USA, 14–17 May 2018; pp. 1–6. [Google Scholar]
- Kang, G.; Gao, S.; Yu, L.; Zhang, D. Deep Architecture for High-Speed Railway Insulator Surface Defect Detection: Denoising Autoencoder With Multitask Learning. IEEE Trans. Instrum. Meas. 2019, 68, 2679–2690. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Balsa-Barreiro, J.; Lerma, J.L. Empirical study of variation in lidar point density over different land covers. Int. J. Remote Sens. 2014, 35, 3372–3383. [Google Scholar] [CrossRef]
- Tang, Y.; Li, L.; Feng, W.; Liu, F.; Zou, X.; Chen, M. Binocular vision measurement and its application in full-field convex deformation of concrete-filled steel tubular columns. Measurement 2018, 130, 372–383. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
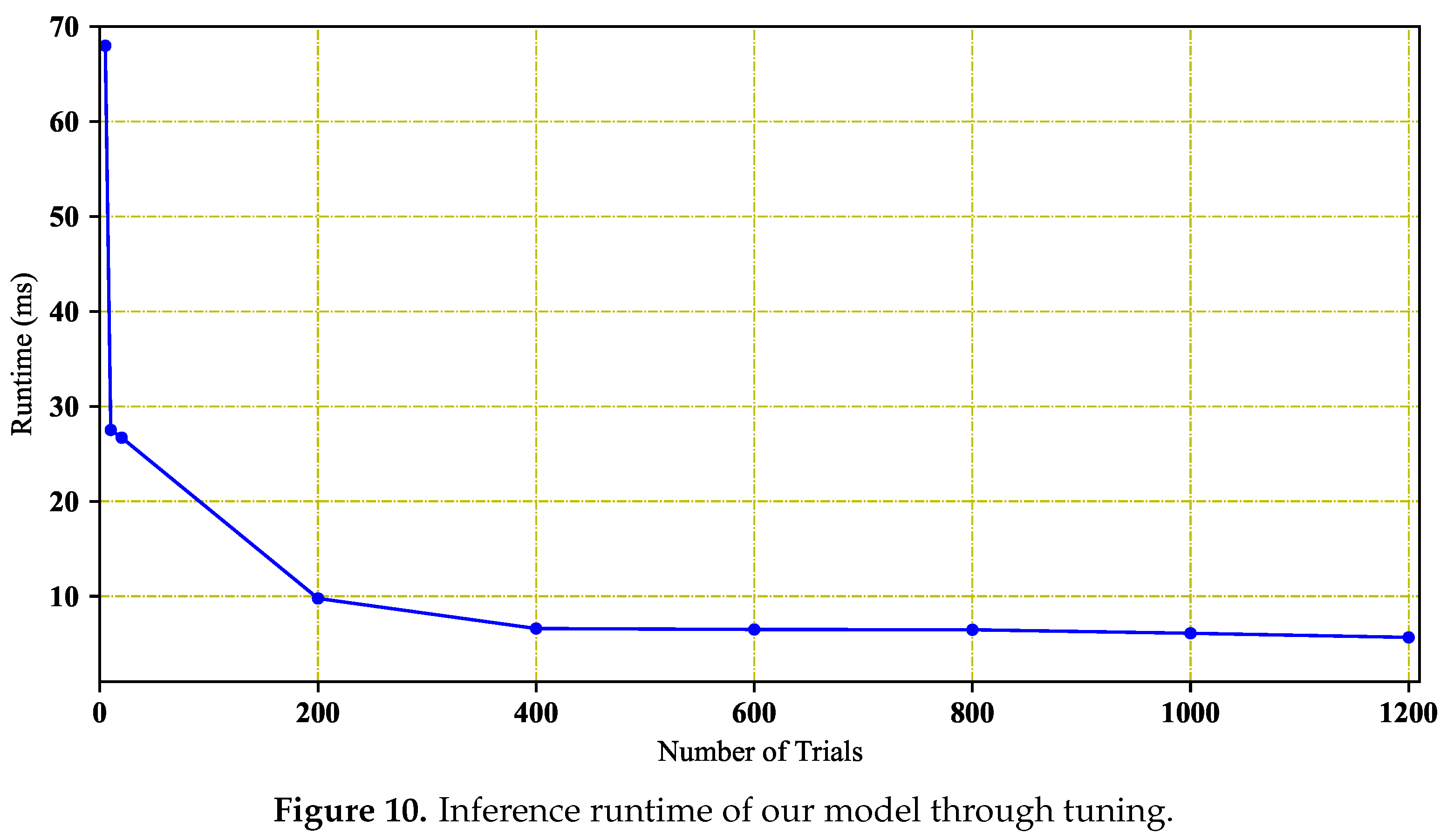{kind=link}
{kind=link}
{kind=link}
| Point Cloud Category | Ours | PointNet++ (SSG) | Lin et al. [13] | PointNet++ (MSG) | PointNet | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Precision | IoU | Precision | IoU | Precision | IoU | Precision | IoU | Precision | IoU | |
| Contact wire | 99.89 | 99.75 | 99.37 | 98.28 | 99.79 | 99.60 | 99.51 | 98.47 | 99.14 | 98.74 |
| Dropper | 97.16 | 93.68 | 97.22 | 93.15 | 96.39 | 91.91 | 96.96 | 93.72 | 89.67 | 76.84 |
| Steady arm | 95.97 | 85.68 | 91.12 | 83.33 | 95.27 | 86.44 | 90.80 | 84.51 | 92.02 | 82.23 |
| Registration arm | 94.70 | 91.38 | 95.42 | 89.83 | 95.23 | 92.11 | 95.39 | 90.61 | 93.59 | 88.64 |
| Catenary wire | 99.65 | 99.51 | 98.57 | 97.93 | 99.45 | 99.16 | 98.61 | 98.06 | 98.99 | 98.12 |
| Pole | 99.91 | 99.76 | 99.85 | 99.65 | 99.80 | 99.64 | 99.86 | 99.64 | 99.73 | 99.34 |
| Cantilever | 93.87 | 88.68 | 92.60 | 87.88 | 92.81 | 87.23 | 93.38 | 87.75 | 87.03 | 77.87 |
| Insulator | 97.18 | 94.12 | 97.26 | 94.45 | 97.36 | 93.59 | 97.10 | 94.21 | 96.03 | 91.68 |
| Mean accuracy | 97.17 | 94.07 | 96.42 | 93.06 | 97.01 | 93.71 | 96.45 | 93.37 | 94.52 | 89.18 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tu, X.; Xu, C.; Liu, S.; Lin, S.; Chen, L.; Xie, G.; Li, R. LiDAR Point Cloud Recognition and Visualization with Deep Learning for Overhead Contact Inspection. Sensors 2020, 20, 6387. https://doi.org/10.3390/s20216387
Tu X, Xu C, Liu S, Lin S, Chen L, Xie G, Li R. LiDAR Point Cloud Recognition and Visualization with Deep Learning for Overhead Contact Inspection. Sensors. 2020; 20(21):6387. https://doi.org/10.3390/s20216387
Chicago/Turabian StyleTu, Xiaohan, Cheng Xu, Siping Liu, Shuai Lin, Lipei Chen, Guoqi Xie, and Renfa Li. 2020. "LiDAR Point Cloud Recognition and Visualization with Deep Learning for Overhead Contact Inspection" Sensors 20, no. 21: 6387. https://doi.org/10.3390/s20216387