1. Introduction
The natural gas pipelines network transports natural gas from the wellhead to the customers throughout the USA. Corrosion is a very severe and costly issue in natural gas pipelines. It is specified as the gradual reduction in the pipeline wall thickness that might lead to substantial environmental and economic consequences as a result of catastrophic events, including leaks and ruptures. Therefore, pipeline integrity management has become highly essential [
1]. Pipeline integrity management is composed of the pipelines’ inspection, repair, and maintenance with the scope of preventing failures and ensuring the safety of the pipelines during their lifecycles [
2].
We are living in the era where the Internet of Things (IoT) is taking control over many tasks previously thought complicated, including asset integrity management [
3]. The importance of pipeline integrity management leads to many investments and initiatives in implementing the IoT on the pipeline systems with the hope of reducing unnecessary costs and expenses. The immediate outcome of IoT implementation on the pipeline is an extensive monitoring system that can provide accurate, online information about various aspects and parameters of the pipeline. This accurate abundant data applies data-driven techniques for decision-making in gas pipeline integrity management [
4].
Integrity management is intrinsically a sequential decision-making problem in which decisions have persistent dynamic effects; i.e., maintenance decisions not only affect the current condition of the asset, but their traces remain throughout the rest of the asset’s life. Reinforcement Learning (RL) is an area of Artificial Intelligence (AI) concerned with data-driven modeling and solving sequential decision-making problems under uncertainty. It has three distinguishing characteristics that make it well suited to formulate the asset integrity management problem:
RL algorithms can learn from historical and online data [
5,
6]: as IoT monitoring and operating systems continue to grow, more data from the asset condition will be accessible which provides an unprecedented opportunity to generate tools that may learn optimal condition-based maintenance from the data.
RL can deal with delayed effects [
5,
6]: most maintenance actions have highly delayed indications of efficiency which makes the optimal integrity management a very hard problem to deal with. RL is to some extent capable of dealing with delayed consequences. Therefore, it gives us the proper tool to handle the delayed effects of actions.
RL algorithms are designed to interact and learn in a stochastic environment [
5], [
6]: oftentimes, the assets are exposed to unpredictable operating and environmental conditions that lead to high uncertainty in the effectiveness of the maintenance actions. RL is known to be capable of taking into account the high-uncertainty environment.
RL techniques for asset integrity management have been attracting more and more attention in recent years. Many studies have shown that an RL-based policy exhibits a superior performance than periodic or corrective policies. For example, in the manufacturing industry, Xanthopoulos et al. [
7] employed a policy-based Q-learning algorithm to find the optimal joint production/maintenance policy while minimizing the inventory level of a production/inventory system. Wei and Qi [
8] also applied a policy-based Q-learning algorithm to study the optimal actions including produce, idle, and maintenance, to maximize the average reward in a two machines-one buffer system. In addition to manufacturing systems, RL techniques were also applied to some large-scale and complex systems for operation and maintenance management. Aissani et al. [
9] proposed a dynamic scheduling of maintenance plans on an operating oil refinery by state-action-reward-state-action (Sarsa) algorithm to maximize the system availability and production efficiency. Barde et al. [
10] took multiple independent components in a military truck into account and found the optimal maintenance time for each component to minimize the system downtime by Monte Carlo RL. Compare et al. [
11] developed a framework by a Sarsa algorithm to find the best part flow management strategy of gas turbines consisting of repair and purchase actions in order to minimize the cost. In a more recent study, Bellani et al. [
12] proposed a Prognostics and Health Management (PHM) framework based on sequential decision-making and RL that, compared with the current practice of PHM, allows consideration of the maintenance and operation decisions’ influence on predicting the degradation.
The corrosion-related maintenance and operation of oil and gas pipelines in the United States account for a large portion, about 80%, of annual corrosion-related costs, which is estimated to be 7 billion US dollars according to the National Association of Corrosion Engineers (NACE) [
13]. This substantial economic trace of corrosion demands more investigations into minimizing the corrosion-related costs. Inspired by the abovementioned real-world applications of RL techniques on asset integrity management, this research aims at (a) demonstrating how to apply RL techniques to the maintenance scheduling of a dry natural gas pipeline subject to internal corrosion, and (b) investigating the possible reduction in the corrosion-related costs through the deployment of RL algorithms.
The great recent achievements of RL, or more particularly deep reinforcement learning, are to some extent owed to the notable opensource testbeds that became available to the RL research community, namely OpenAI Gym [
14] and the arcade learning environment [
15]. For example, Wang et al. [
16] proposed an algorithm that achieved a superhuman performance in 57 Atari games that is implemented and trained within the arcade learning environment. Despite all the great achievements of RL in video and Atari games, it has minimal success in safety-critical applications such as asset integrity management. One reason is the lack of a trustable test bench that could evaluate the performance of the AI approaches to real-world problems. In this research, we address this issue in pipeline maintenance management by proposing a test bench that could interact with any maintenance decision-maker, including RL algorithms.
Furthermore, we propose an autonomous maintenance scheduler based on RL techniques that interacts and communicates with the test bench to achieve an optimal maintenance policy. The proposed decision-maker integrates the health state data of a physical asset with a data-driven, model-free RL algorithm to ensure the asset’s integrity, as measured by the desired level of reliability, while minimizing the maintenance costs and extending the life of the asset. Therefore, the approach is condition-based because it leverages upon the asset’s health state condition information, and it is autonomous because it applies RL techniques and algorithms to come up with the optimal time and action of the maintenance. In summary, the motivations of this study are:
Investigating the capabilities of RL as a mathematical tool to digest the abundant data that are collected and stored from the pipelines over the years.
Filling the gap between the trending RL developments and pipeline maintenance decision-making by introducing a test bench for pipeline maintenance and an RL agent interaction. The test bench mimics the challenges of pipeline maintenance management; however, it intentionally reduces the problem complexity.
As there is limited research on using the RL technique for the maintenance optimization of corroded gas pipelines, this research can be regarded as a benchmark for interaction evaluation between a maintenance decision-maker and a corroded gas pipeline that could facilitate future research on the effectiveness of various RL techniques in condition-based corrosion maintenance management. The main contributions of this research are:
Proposing and implementing a test bench for interaction evaluations between a maintenance decision-maker and a corrosive pipeline in terms of the system reliability level and the cost effectiveness of the maintenance decisions.
Proposing and implementing a condition-based maintenance management regime that leverages RL techniques to achieve a superior performance (in the proposed test bench) compared to the existing maintenance management practices.
Implementing a corrosion prediction model for a gas pipeline that could adjust to include the influence of multiple concurrent maintenance actions.
The remainder of the paper is structured as follows. The next section elaborates on the design and implementation details of the proposed test bench. It first states the assumptions that are made in the test bench development, and then it goes through the details of the test bench components. Afterward, the proposed RL condition-based maintenance scheduler is presented in
Section 3.
Section 3 presents some RL preliminaries and then demonstrates the heart of the RL maintenance scheduler, which is a Q-learning-based algorithm. Following that,
Section 4 explains our evaluation methodology, which is how the RL maintenance scheduler’s performance is assessed and compared with the current widely used industry maintenance strategy, periodic maintenance practice. Then, the results of applying the proposed methodology to the pipeline corrosion maintenance management are shown in
Section 5—Results and Discussion. Finally, some concluding remarks and possible future work for improvement are provided in
Section 6—Conclusions.
2. The Test Bench
As stated in the introduction, the proposed condition-based maintenance scheduler is based on model-free RL. This class of RL algorithms is completely data-driven and does not need any knowledge about the system. In contrast with the model-based approaches, e.g., dynamic programing, model-free approaches do not require an accurate state transition function but still should be provided with observations and reward signals from the system. In this research, we propose and implement a test bench that is needful to evaluate the performance of any decision-making entity prior to performing direct interactions with a real pipeline system. This test bench:
Simulates the internal corrosion of the pipeline benefitting from a corrosion model that is adjustable to multiple concurrent maintenance actions and capable of simulating the corrosion with daily precision.
Simulates the pipeline environmental and operating parameters with daily precision.
Provides interaction protocols between the maintenance decision-maker and the pipeline’s corrosion simulator.
Approximates the cost associated to the maintenance actions and the pipe health state.
It is worth emphasizing that the decision-maker does not have access or knowledge about the internal behavior of the corrosion model and treats that as a black box.
Prior to getting into the details of the test bench, we will state the assumptions that are made in the test bench implementation.
The system is one section of the pipeline which is presumed to be new at time t = 0, and a corrosion defect gradually develops after that depending on the time-varying operating conditions.
It is assumed that the pipeline section suffers from only one corrosion defect at each time.
The pipeline section is assumed to corrode by two types of corrosion, namely pitting and uniform corrosions. To aggregate the two corrosion processes, a linear combination of the two is considered, as suggested by Wu and Castro [
17]. In this case, when the combined degradation reaches the threshold values, the pipeline system fails either due to leak or rupture.
Two types of maintenance are considered, namely, preventive maintenance and a replacement of the system. The preventive maintenance includes a batch corrosion inhibitor, internal coating, and pigging. The replacement renews the system completely.
Determining the in line inspection (ILI) interval is always a challenging problem to pipeline operators which depends on the conditions of the pipeline systems [
18]. In this paper, we simplify the problem and focus on the implementation of the RL techniques by assuming that an RL maintenance scheduler receives signals from the health state of the pipeline through monthly inspections. Then, it can decide either to do nothing, carry out one of the preventive maintenance actions or replace the corroded segment of the pipeline The scheduler’s maintenance order is disclosed to the system at the beginning of each month.
Inspection and maintenance times are neglected.
The following subsections describe the implementation details of the proposed test bench. First, an overview of various components of the test bench and their interactions is presented, then the details of each particular component is further elaborated.
2.1. Components of the Test Bench
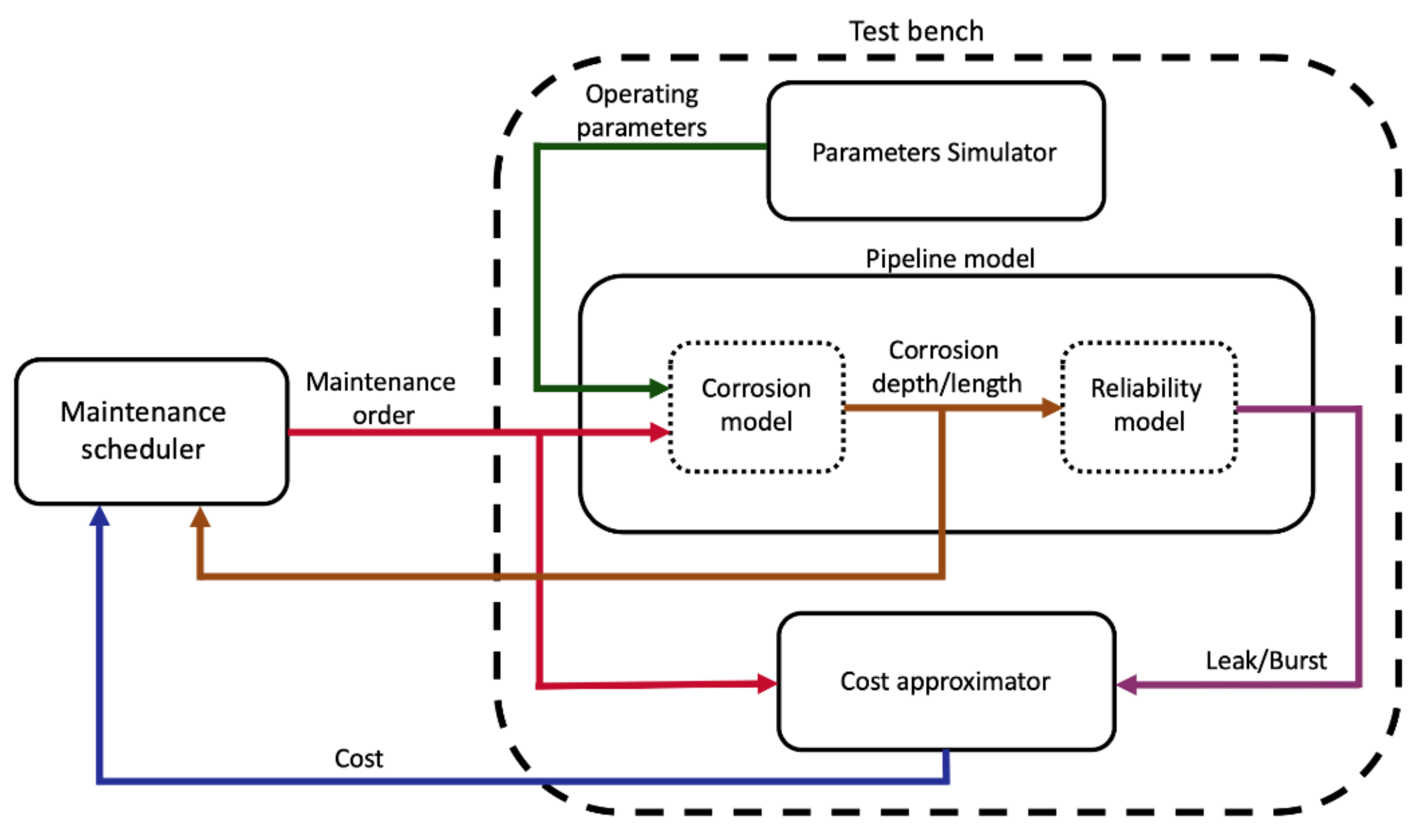
The test bench is composed of three components. First, a set of environmental and operational parameters are simulated that mimic the daily variation of a real pipeline’s environmental and operational parameters. Afterward, the parameters are fed into a pipeline model along with the order of the month’s maintenance action. Then, the pipeline corrosion model adjusts itself to the received maintenance order and then simulates the corrosion progress over a month-long period. At the end of the month, the total corrosion depth and length is inputted to the pipeline reliability model that simulates the failure events, namely leak and rupture. Eventually, a cost approximator estimates the month’s expenditure according to the existence of any failure as well as any maintenance actions.
Figure 1 shows an overview of the proposed test bench. It should be emphasized that the maintenance schedular is not part of the test bench. It is a separate entity that interacts with the test bench by reading the end of the month corrosion condition and the cost, and then instructing a maintenance order for the next month. The choice of the maintenance actions is limited to the set of actions that the corrosion model could adjust to them.
2.2. The Environmental and Operational Parameters Simulator
The complex operating condition of the pipeline system is simulated by modeling a variety of environmental parameters. Most common environmental parameters that are related to the pipeline corrosion include temperature (
Temp), total pressure (
P), partial pressure of CO
2 (
pCO2), partial pressure of H
2S (
pH2S), flow velocity (
V), pH value (
pH), chloride ion (
Cl−) concentration, and sulphate ion (
SO42−) concentration, and the presence of solids (
). The environmental parameters are stochastic in nature; therefore, in order to take temporal variability into account, we used a Poisson Square Wave Process (PSWP) [
19,
20] to model them and generate different time-varying environmental parameters. In a PSWP, the number of pulses (
) within a period of time (
follows a Poisson distribution with the probability mass function being:
where
is the mean occurrence rate per unit time (= 1 per day in this paper)
follows the exponential distribution with the mean duration to be
. The magnitude of each environmental parameter is described by a specified distribution such as uniform, normal, and lognormal distributions followed by a coefficient of variability (COV). The values are based on several studies [
21,
22] and the details are shown in
Table 1. The simulated environmental parameters are the inputs of the corrosion model to quantify the system degradation by internal corrosion, which will be introduced in the following subsection, on a daily granularity.
2.3. The Pipeline Model
The simulated system is a dry natural gas pipeline, which is 1.6 km in length, has an outer diameter of 509 mm, and inner diameter of 492 mm. The pipeline is considered to be used for transporting natural gas (i.e., CH4) with a small amount of corrosive gases (i.e., CO2 and H2S) and elements (i.e., Cl−). The degradation is the result of internal corrosion, including uniform and pitting corrosions. Degradation is a function of the operating conditions which are considered and simulated as time-varying parameters. When the linear combination of the two degradation processes reaches the threshold values, the pipeline fails either due to leak or rupture. In summary, the pipeline model takes the environmental parameters as inputs and outputs two Boolean signals representing whether the pipeline fails by either leak or rupture. The pipe model consists of a corrosion model and a reliability model, each of which will be described in the following subsections.
2.3.1. Corrosion Model
The pipeline system degrades as a result of internal corrosion including uniform and pitting corrosion. The corrosion defect is assumed to have rectangular-like shape as shown in
Figure 2 and can be described by corrosion depth (
) and corrosion length (
).
To simulate the overall degradation by a multiple degradation process (i.e., uniform and pitting corrosion), a linear combination method [
17] was adopted. The expression of the overall degradation is given by:
where
is the overall corrosion degradation over time in depth and length (with
;
and
are the weight factors of uniform and pitting corrosion, respectively (with
;
and
represent the corrosion degradation over time in the depth and length of uniform and pitting corrosion, respectively (with
,
).
Corrosion depths over time by uniform corrosion (
) and pitting corrosion (
) are regarded as the accumulation effect of the daily corrosion rate, which refers to the daily granularity assumption of environmental parameters; therefore, they can be calculated as:
where
is the uniform corrosion rate over time;
is the pitting corrosion rate over time;
is the number of days.
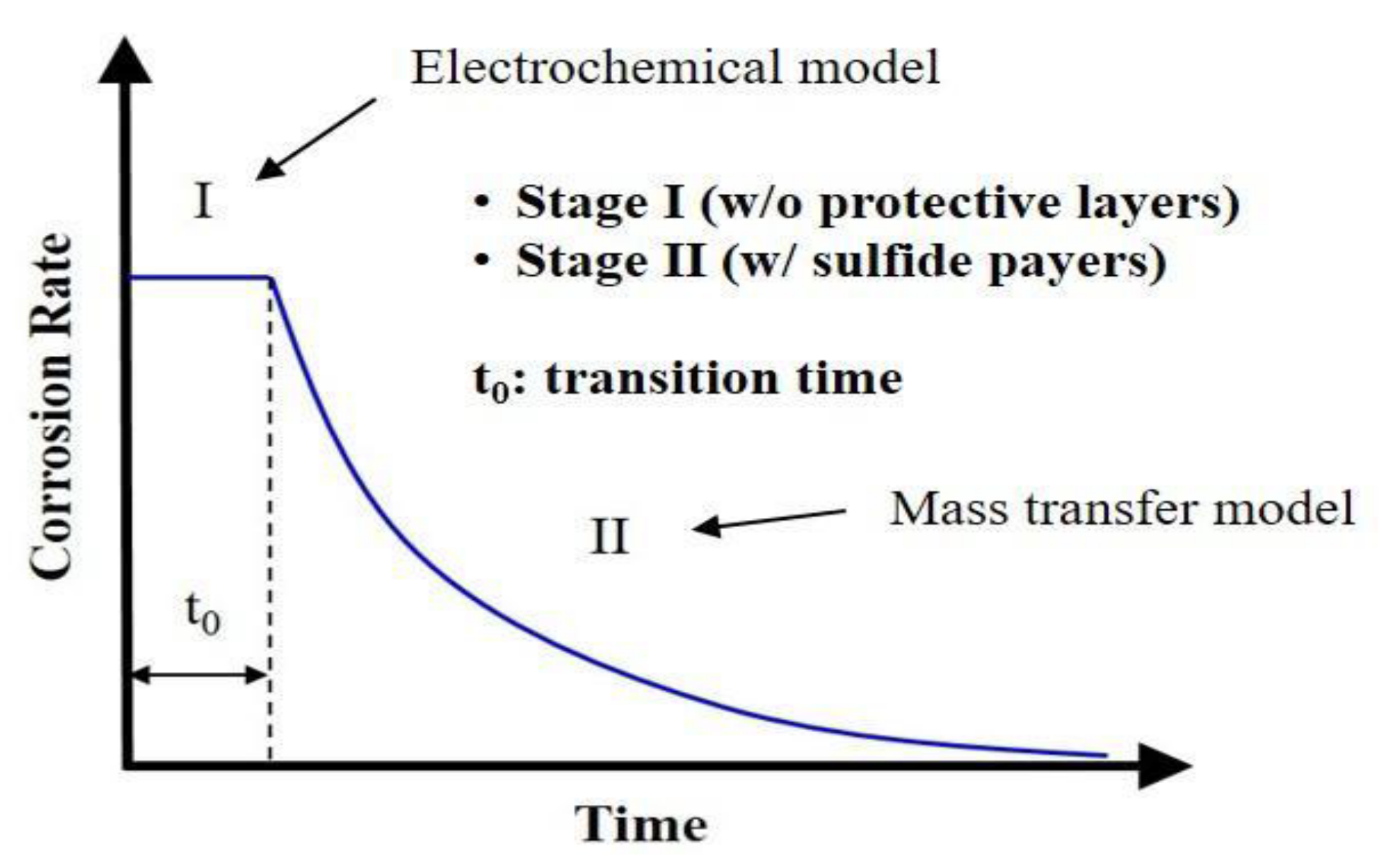
First of all, uniform corrosion rate is simulated by the two-stage model proposed by the authors of [
20]. As uniform corrosion usually follows by the formation of protective layers, this predictive model describes the corrosion behavior in a phenomenological sense in terms of two stages depending on the formation of corrosion-protective layers.
Figure 3 shows the concept of this model for uniform corrosion as a function of time. Specifically, Stage I simulates the corrosion behavior in the absence of protective layers using the electrochemical model, which involves the calculation of corrosion current densities for all electrochemical reactions (i.e., iron dissolution, hydrogen ion reduction, direct carbonic acid reduction, direct hydrogen sulfide reduction, and direct water reduction) that may take place in the CO
2/H
2S aqueous environment inside the pipeline.
The uniform corrosion rate at Stage I (
) is represented as:
where
is the corrosion current density in A/m
2;
is the molar mass of iron (= 55.85 g/mol);
is the density of iron (= 7.86 g/cm
3);
is the Faraday constant (= 96,500 C/mol).
Stage II simulates the corrosion behavior in the presence of protective layers using the mass transfer model. Due to the formation of mackinawite sulfide layers on the steel surface, several reactions may take place in the corrosive environment including the diffusion of corrosive species such as HS
−, S
2−, HCO
32−, CO
32− from the bulk solution to the steel surface, release of dissolved iron sulfides such as Fe(HS)
+, HS
− from the protective layers to the bulk solution, and the release of Fe
2+ from the steel surface to the bulk solution. The corrosion rate is influenced by the fluxes of H
2S, CO
2, and H
+ in which the thickness of mackinawite sulfide layers has a critical role in the level of corrosion. The uniform corrosion rate at Stage II (
) is represented as:
where
,
, and
are the fluxes of H
2S, CO
2, and H
+ in mol/(m
2s). For more model details, readers are referred to [
20].
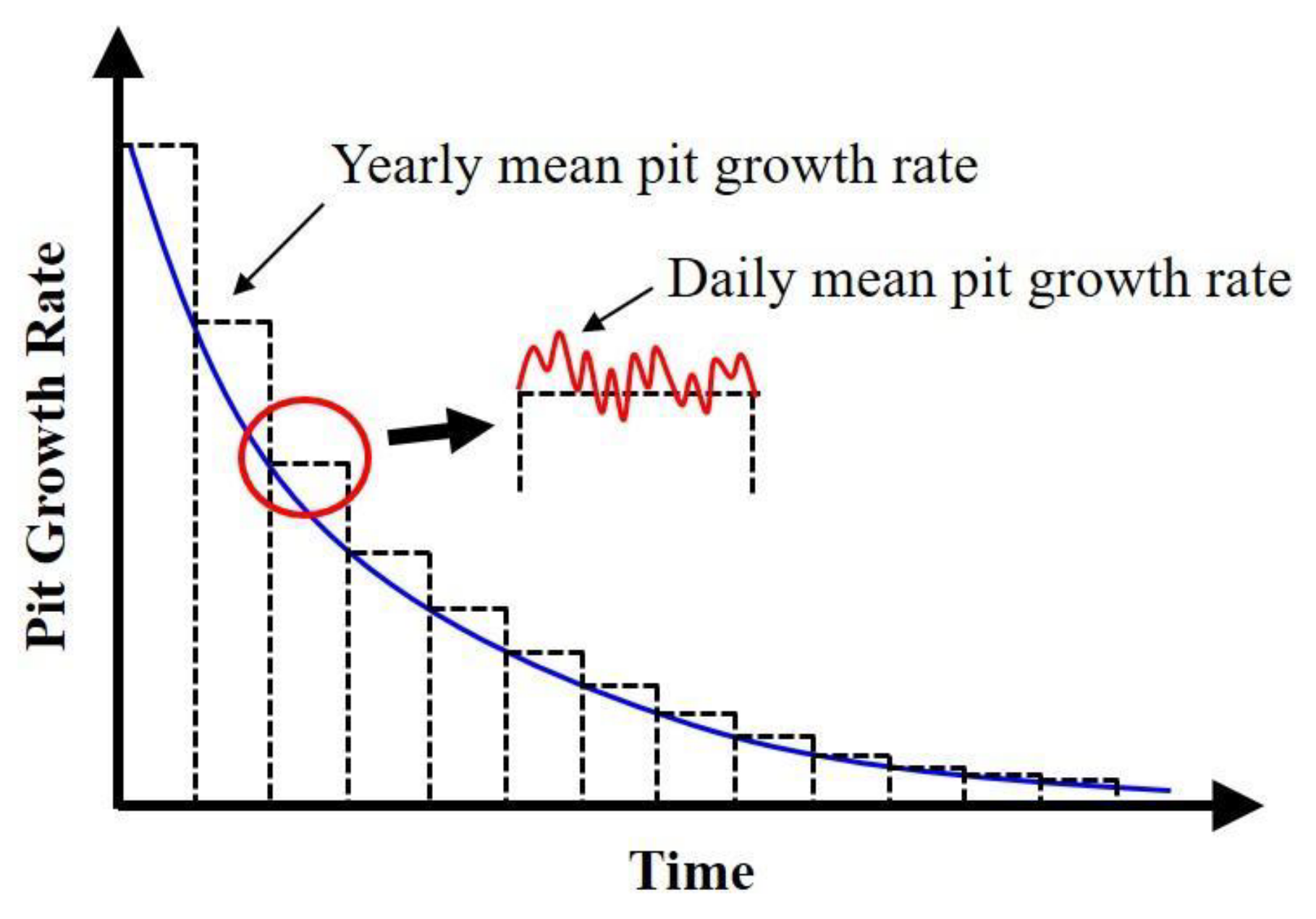
On the other hand, the pitting corrosion rate is simulated by the Papavinasam model [
23]. This model takes different environmental parameters and predicts the yearly mean pit growth rate given the constant operating condition. Each of these environmental parameters has its individual equation with respect to the pitting corrosion rate and they are integrated into a final corrosion rate equation:
where
θc is the contact angle of oil in a water environment in degree;
W% is the water production rate/(water + oil production rates) × 100;
Wss is the wall shear stress in Pa;
Rsolid is 1 if solids exist, otherwise it is 0;
Temp is the temperature in °C;
P is the total pressure in psi;
is the partial pressure of H
2S in psi;
is partial pressure of CO
2 in psi;
[SO42−] is the sulfate concentration in ppm;
[HCO3−] is the bicarbonate concentration in ppm;
[Cl−] is the chloride concentration in ppm;
PCRaddition is the mean pitting corrosion rate of these 11 individual pitting corrosion rates. Due to the consideration of daily-varying environmental parameters, this model is modified to a model that can predict the daily mean pit growth rate as a function of time. The schematic diagram of this model is shown in
Figure 4.
Unlike the modeling of corrosion depth that have been studied for a long time, to the best of the authors’ knowledge, there are no widely accepted model to calculate corrosion length [
24]. Therefore, we adopted the linear growth model [
25] with an arbitrarily assumed corrosion length growth rate (
) for corrosion length simulation given the assumption that
is the same for uniform and pitting corrosion. Consequently, the corrosion length over time by uniform (
) and (
) can be represented as:
The simulated overall corrosion depth and length are inputs to the reliability model, which will be introduced in the following subsection.
2.3.2. Reliability Model
When the corrosion degradation of the system exceeds the threshold values, the pipeline system fails either due to leak or rupture. We use a reliability model to determine whether the system fails. This reliability model is based on the load and strength interference technique by defining their limit state functions at a given corrosion defect. The limit state functions of leak (
) and rupture (
) can be written as:
where
is the corrosion allowance (i.e., 0.8 × wall thickness);
is the maximum defect depth;
is the burst pressure of the corroded pipeline;
is the operating pressure.
Limit state functions show that a leak happens when the maximum defect depth is larger than the corrosion allowance (), while a rupture happens when the operating pressure is larger than the burst pressure ().
The
of the pipeline is calculated by the ASME B31G standard [
26] because it requires relatively less information of the defect geometry (i.e., only corrosion length and depth) and, therefore, it is easier to implement. In addition, calculations by this model in terms of the probability of failure fall in the safe domain, implying that they are not too conservative in their calculation of the probability of rupture compared to the other existing standards or models [
27]. According to the ASME B31G standard,
can be represented as:
where
is hoop stress;
is the flow stress;
is the pipe’s wall thickness;
is the pipe’s outer diameter;
is the surface area of the corrosion defect;
is the original surface area of the pipe with
where
is the depth of a corrosion defect;
is the Folias factor defined as:
where
is the length of a corrosion defect.
Given the limit state functions, the probability of failure with respect to each of these two failure modes can be determined by a Monte Carlo simulation [
28]:
where
is the probability of failure (with
);
) is the limit state function (with
), and
is the number of simulations.
To simplify the problem as a first approximation, we assume that leaks and ruptures are independent; therefore, binomial distributions, where is the number of success event; is the number of Bernoulli trials; is the probability of success, which is used to determine whether the pipeline system fails. Specifically, two samples are driven from each Binomial distribution representing leak . and rupture , and if either one of the events happen, the pipeline is regarded as a fail.
2.3.3. Adjustment of the Corrosion Model to Maintenance Actions
Two types of maintenance, namely preventive maintenance and replacement, are considered. Preventive maintenance includes a batch corrosion inhibitor, internal coating, and pigging, all of which are common for the mitigation of internal corrosion in dry natural gas pipelines [
29]. It should be noted that although internal coating [
30] is usually applied during the manufacturing process, it is not uncommon for pipeline operators to do coating repair if the coating is damaged due to corrosion [
31]; therefore, internal coating is considered as one maintenance action here for comparison. Doing nothing is also an option to provide the agent with the flexibility of applying no maintenance action.
The corrosion model has daily granularity. However, the interaction of maintenance decision-maker and the environment happens on a monthly basis. On the first day of each month, the agent gets informed about the new state of the pipeline through monthly inspections and subsequently determines this month maintenance action and executes that action. Afterward, the pipeline model receives the action of the month and adapts itself accordingly. The details of the considered maintenance actions are shown in
Table 2.
For asset management problems, failure intensity is a common metric used for quantifying the effect of repair models. For example, Doyen and Gaudoin [
32] propose the reduction in intensity model to express the repair effect on the reduction in the system failure. Inspired by this paper, we propose a discount factor (
) ranging between zero and one to account for the influences of maintenance actions on the pipeline corrosion. The corrosion rate is multiplied by the discount factor to model the updated corrosion rate. Each maintenance action with a direct influence on the corrosion rate has a lifetime. The discount factor becomes 1 beyond the lifetime. The discount factors and the lifetime with respect to different maintenance actions are listed in
Table 3.
According to
Table 3, immediately following a batch corrosion inhibitor appliance, the corrosion rate would greatly lessen, and afterward gradually increase to its original value by an exponential function as stated in [
34]. In addition, the effect of the coating appliance and the pigging is to set the corrosion rate to zero but with different time scales. The coating effect is more permanent and remains for a longer period of time; therefore, the corrosion rate would be set to zero for five years. However, following a pigging action the corrosion rate would be set to zero only for two weeks.
2.4. Development of the Cost Approximator
Defining the costs is a critical task in any decision-making problem because the reward/cost is the only mean by which the decision-maker can know the aptness of its actions. The goal of the maintenance decision-maker in the corrosion maintenance scheduling problem is to:
Avoid catastrophic failures, namely leakage and rupture.
Extend the life of the asset.
Reduce the maintenance costs.
To include these three goals in the reward function, we define three types of rewards as follows. Here, we use cost to address the negative reward, and the total reward after each month is the algebraic summation of these three values:
Cost of failure: the cost that is associated with the situations where the system has failed. This cost will be non-zero only when the pipeline enters a failure state. Immediately upon arrival of the pipeline in a failed state, a large cost will be emitted to the decision-maker to penalize its decision-making policy. This cost should be considerably larger than the other types of costs because of the massive hazard the failures imposed on the life of people and the pipeline’s surrounding environment. Besides, failures cause an interruption in the service that might have large economic consequences.
Life extension reward: the reward of delaying the failure. At the end of each month that the pipeline is not in one of the terminal states, namely failure and replacement, the agent receives a positive reward for extending the life of the pipeline for that month. This value is small in comparison to other types of cost.
Cost of maintenance: the cost that is associated with each maintenance action. The cost of the month’s maintenance action is emitted to the agent at the end of each month along with the failure delaying reward and the failure cost.
One of the challenges in designing the test bench is assigning values to the reward function since the cost-sensitive decision-making mechanisms highly rely on the cost values. The approach taken in this research is to assign values to the maintenance cost from generic information appertaining to the gas pipeline maintenance and then specify the remaining reward values with respect to the maintenance costs. It should be noted that the values assigned here could be updated for different application scenarios. In addition, at this stage, the problem is simplified by considering only a segment of the pipeline, which is 1-mile long. By doing this, we are able to ignore the spatial effect on our studied system.
Table 4 lists the values of the three types of reward functions considered in this study. Regarding the maintenance cost, first of all, “Do nothing” costs USD 0 in general if the cost of the inspection is neglected for all the other maintenance actions. Second, “Pigging” operation starts from the inlet to the outlet; therefore, the cost is determined based on the distance between the launcher and the receiver. Based on the data from pipeline operators, the cost is roughly USD 35,000/mile [
35]. Third, “Batch-treatment of corrosion inhibitor” is to pump the corrosion inhibitors from the inlet, and the cost is determined by the volume of the pipeline. Here it is assumed that one-third of the tubing volume is needed for the inhibition efficiency to be over 90%, and the cost is estimated to be USD 130,000/mile [
33]. In addition, “Internal coating” is a costly option as it requires the pipeline excavation. The cost is approximately USD 800,000/mile according to [
36]. Finally, the cost of the replacement of a corroded pipeline varies on the basis of the pipeline size, which is hard to be accurately estimated, but in general it is more expensive than any rehabilitation actions. Here, we assign it to be USD 1,600,000/mile.
Two types of failure costs are considered in this research. The leak cost is assumed to be three times the replacement cost because a leaked pipeline needs to be replaced but the replacement follows with an unplanned interruption of the service. The rupture cost also includes the replacement cost but along with that, it has a significantly larger cost reflecting the highly catastrophic hazards it might lead to. The life extension reward per month is set to USD 70,000 based on the results of the sensitivity analysis that was performed on the value of the life extension reward in the evaluation section.
3. The RL Maintenance Scheduler
In this section, we first review the RL fundamentals in maintenance management, and then we present the methodology and the algorithm for the proposed RL-based maintenance decision-maker. Among various maintenance management strategies, this study focuses on the condition-based maintenance strategy that incorporates the costs into the decision-making process because they are shown to be more cost-effective over the pure risk-based and time-based strategies [
37,
38]. The goal of the scheduler is to find the best time and type of maintenance actions that optimize the maintenance-related costs while ensuring a high level of reliability in the pipeline.
3.1. Preliminaries
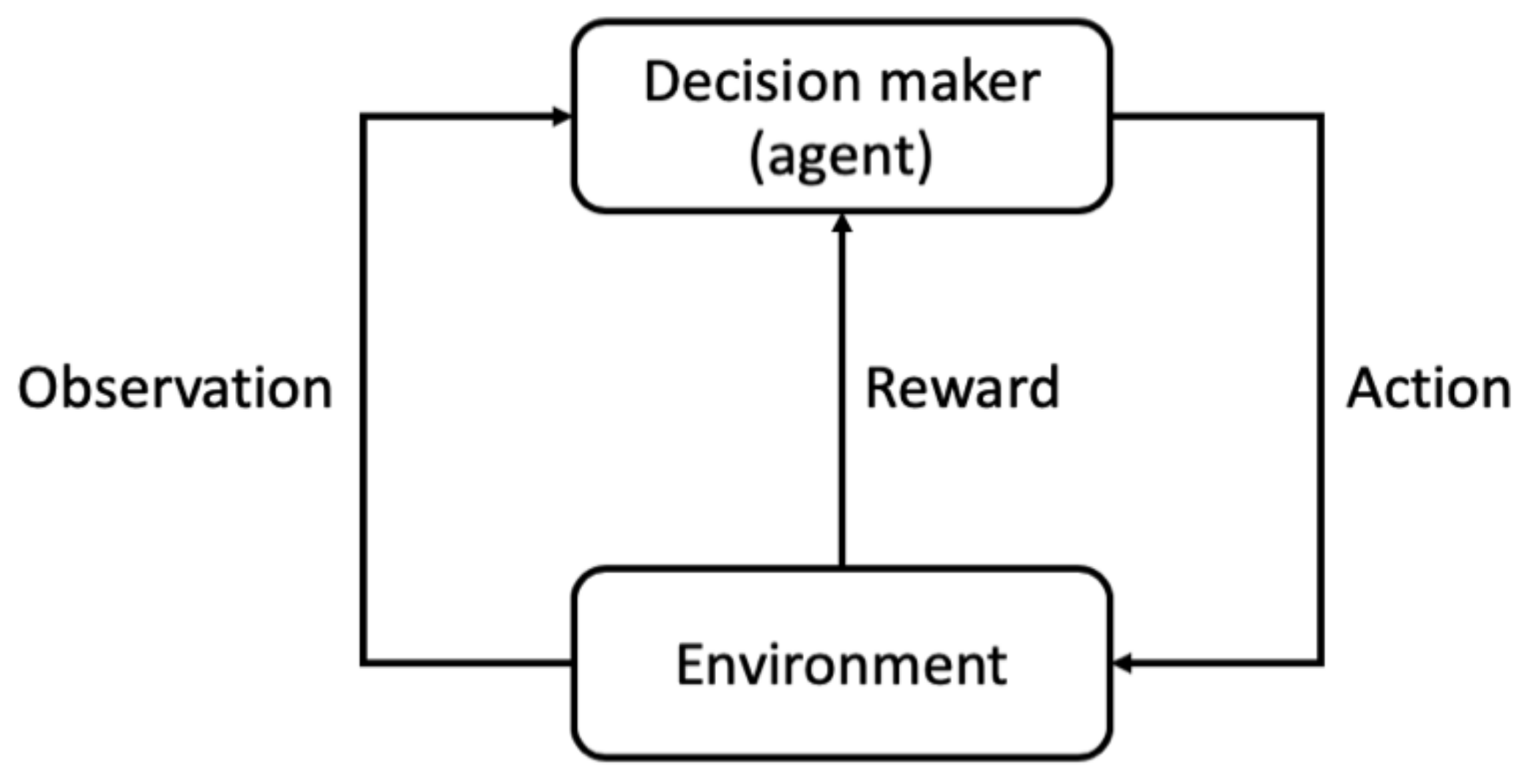
In the general RL setting, a decision-maker (often called as agent) interacts with an uncertain environment to achieve a goal. The environment is influenced by the agent’s actions, and the agent can observe the influence through some observation signals as well as a reward signal. The reward signal should reflect the aptness of the previous actions, and the agent learns to improve and optimize its decisions by learning from the previous rewards. The underlying assumption in all RL problems is that we can express the agent’s goal as the cumulative rewards throughout the agent–environment interaction. For example, if we consider the goal of the maintenance management to be the asset life extension, then we can reward the agent by a positive value for each year that the asset does not fail.
Figure 5 depicts the general framework of the RL agent and environment interaction.
A Markov Decision Process (MDP) formally describes a framework for RL. The MDP is a mathematical abstraction that is defined by a tuple
in which
is a set of states,
is a set of actions,
is a reward function, and
is a transition probability function [
39]. In a general condition-based maintenance management setting, the state is the health condition of the asset. In each health state of the asset
, the decision-maker takes a maintenance action from the set of possible actions at that state a ϵ A
s. Upon taking action
, the asset health condition will change and over time reach a new state
, derived from the transition probability function
, and consequently the agent receives a reward
derived from the reward function
.
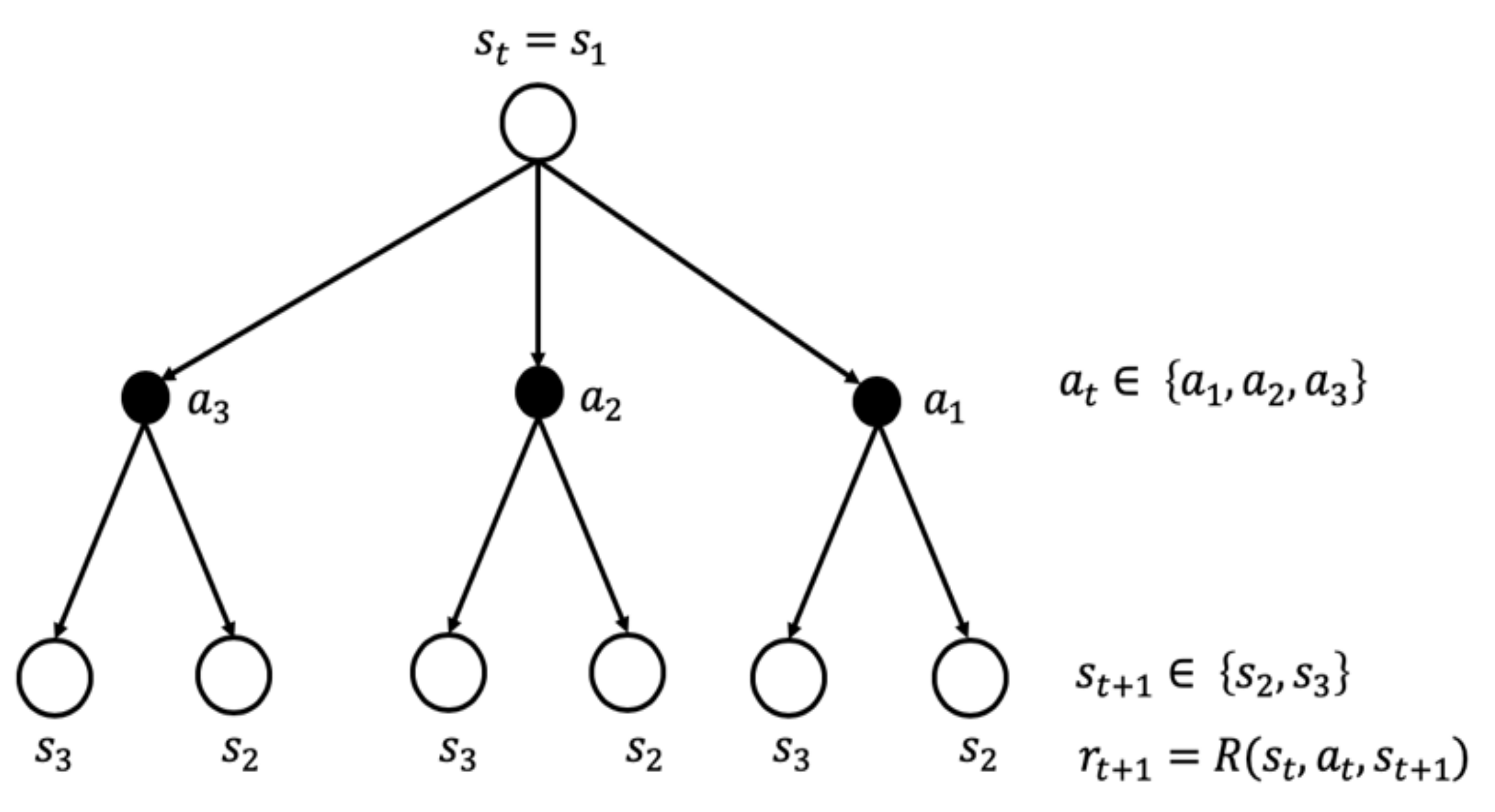
Figure 6 shows the transition in two consecutive time steps for a simple MDP. The agent starts at time t from state
and has three choice of actions
. Depending on the action it takes, the agent lands either on
or
according to the transition probability
and receives the reward
.
Often MDPs are used as discounted MDPs (DMDPs) for RL problems. A DMPD is defined with the same tuple except that it has one extra element which is a discount factor γ. By discounting future rewards with γ, we can determine the present value of future rewards. Without loss of generality, here we consider the asset to be an underground dry natural gas pipeline and the degradation mechanism to be the internal corrosion. However, we want to emphasize that the same approach is applicable to other assets under single or multiple co-existing degradations. We focus on one segment of the pipeline and we assume it is in operation under stochastic environmental and operational parameters. During the operation, the pipeline segment gradually builds up corrosion and degrades. In the absence of proper timely maintenance actions, the corroding pipeline can put the whole pipeline system at the risk of highly hazardous failures, namely leakage and rupture.
3.2. The RL Agent Development
This section discusses the development of the proposed decision-maker, which is responsible for maintenance scheduling. The heart of the maintenance scheduler is an RL algorithm, called the agent, that makes the maintenance decisions based on its experience from interacting with the corrosive pipeline. The first step to frame the pipeline’s corrosion maintenance as a sequential decision-making problem is to define it in an MDP format. As stated before, an MDP is the mathematical formulization of RL, and it consists of a state space, an action space, a reward function, and a state transition function. In the following, each one of these elements is described except for the transition function because the sequential decision-making technique employed in this research is model-free RL; i.e., it does not need explicit knowledge about the underlying pipe model that is used to simulate the degradation of the system and it only requires some signals from the state of the pipeline system.
3.2.1. State Space
The states in an MDP must be defined in a way that allows them to have the Markov property; i.e., the future state depends only on the current state and the current action. In other words, the state is a concise summary of the environment’s history that includes all the necessary information to predict the next state given the action. Because the scope of this research is the corrosion of the pipeline, the state definition should include all the essential information to predict the next corrosion status given the action. Therefore, we initially design the state definition to include the depth and length of the corrosion. However, instead of directly taking the value of the depth and length, the max-normalized version of them is considered to remove the agent’s dependency on the pipeline’s parameters. Equations (15) and (16) define the corrosion depth and length as utilized in the pipeline’s health state definition where the maximum corrosion depth is the wall thickness and the maximum corrosion length is estimated by running the model for 40 years without maintenance.
Representing the corrosion state with only the depth and length is not accurate because the next state of the corrosion is not predictable without knowing the rate of the corrosion degradation. Therefore, the corrosion rate is added to the state variables. We assume the agent’s access to the state variables is feasible only through monthly inspections of the corrosion depth and length and, therefore, the corrosion rate is derived by comparing the current month’s corrosion with the previous month’s corrosion. Since corrosion is a slow and gradual process, the agent does not need high precision in state representation. Thus, we discretize the state variables into 24 bins as shown in
Table 5. The corrosion rate is represented (
) as a binary variable with a value of 0 when there is no corrosion aggravation and 1 when the corrosion exacerbates. Equation (17) formulates the corrosion rate presence as the third state variable.
3.2.2. Action Space
The action space is defined by available actions that the maintenance scheduler can take in response of the system state. As presented in the maintenance actions section, the benchmark provides the scheduler with five actions. Therefore, a discrete action space of size 5 is considered for the agent as follows,
3.2.3. Reward Function
The reward is a feedback signal from the environment to the agent that reflects the aptness of the RL agent’s actions from the environment’s prospect. In real-world RL problems, the reward function is usually a handcrafted variable by an expert that is derived from the environment’s conditions. Assigning the reward function is a longtime challenge in RL [
40]. In this research, the test bench provides the agent with approximated cost values on a monthly basis. Therefore, the agent can use the negative cost as the reward signal. As stated in
Section 2, the total cost signal is the algebraic summation of the three types of costs, each of which reflects one of the expectations from the maintenance scheduler. Equation (19) formulates the reward signal. The bold italic terms are binary variables that represent the presence or absence of the term. For example, if pigging is the order of the maintenance in the past month, then the “
value is set to 1; otherwise, it is 0. “
” signifies the Boolean or.
3.2.4. The Learning Algorithm
Many RL algorithms have been proposed since the rise of RL in the early 1980s that can broadly be classified into two main categories: tabular solution methods and approximate solution methods [
6]. Tabular solution methods are applicable to problems with small action and state spaces while approximate solution methods are pertinent for much larger problems [
41]. The test bench presented in this research has finite action and state spaces that can be represented in arrays and tables. Accordingly, tabular solution methods are chosen over the approximate solution methods. Besides, the applied algorithms are model-free because the approach of this research is entirely data-driven; i.e., the agent treats the model as a black box that mimics a real pipeline and emits the required data for the learning process.
Temporal difference (TD) learning methods are the most common learning methods among the model-free, tabular RL solutions. The idea of TD learning is to update the current estimate of a variable toward a better estimate of that given the information gained in the current time step. Many algorithms are devised around the TD concept in RL but the most popular one is Q-learning [
42], which has been applied to a wide range of problems spanning from healthcare [
43] to financial markets [
44]. The popularity of Q-learning is due to its simplicity in formulation, implementation, and analysis as well as having reasonable computation and memory costs. In this research, we applied the Q-learning algorithm to the problem of pipeline optimal corrosion maintenance management.
Q-learning aims at learning the optimal action-value functions (also known as the Q-value) to derive the optimal maintenance management policy. As defined by [
6], the action-value function,
, is a function that estimates the worthiness of each action at each state and is defined as the cumulative discounted future rewards that can be expected if the agent starts from state
then performs action
and follows the policy
:
Patently, the optimal policy is to always choose the action that corresponds to maximum worthiness; i.e., maximum Q-values. It should be noted that any data-driven RL algorithm can only estimate the Q-values according to its experiences, and as it interacts more with the environment, it can arrive at a better estimate of the Q-values. Therefore, choosing the optimal action according to the current estimate of Q-values exploits the current knowledge about the actions’ worthiness. However, there might be other actions with higher actual value functions that are not chosen because the current estimates of the value functions are not accurate. Therefore, the agent needs to balance between exploiting the current knowledge about the best actions and exploring the other actions to gain more accurate estimates. This is known as the exploration–exploitation trade-off [
41].
The pseudocode of the implemented Q-learning algorithm for optimal pipeline corrosion maintenance management is shown in
Figure 7. This algorithm is mainly borrowed from [
6] and adopted to the pipeline’s corrosion maintenance problem. It consists of one main loop over each episode. In the pipeline corrosion environment, a full episode is defined as the agent that starts with an intact new pipeline and performs a sequence of actions until it either reaches the end of the simulation scope or the pipeline is replaced by taking a replacement action, or a leakage or a rupture failure happens. The exploration–exploitation dilemma is addressed at line (10) by means of an ε-greedy policy; i.e., the agent picks the next action to be the current best action (
) with probability
and with
probability randomly choosing among suboptimal actions.
The problem with the basic ε-greedy policy is that it lacks the ability to adapt as the agent state of knowledge about the actions and the environment improves. Therefore, it always explores the action space with the same rate. If the value of the ε is chosen to be small, the agent does not explore enough and usually sticks to a suboptimal policy; e.g., performs coating when there is small corrosion in the pipeline. If the value of ε is large, the agent keeps exploring even when it is mature, and it should be confident about the best policy. Thus, the decaying ε-greedy policy is implemented as a remedy for this issue. In decaying ε-greedy, the agent starts with a large exploration rate and reduces the ε with each learning iteration. Consequently, the agent leans more towards exploring the actions at the beginning of the learning, and as the learning progresses and the agent get more mature, it favors exploiting its current knowledge about the actions [
45]. The decaying rule implemented in this study is given in Equation (21), where
is the maximum exploration rate,
is the minimum allowable exploration rate, and
is the exploration decay rate.
4. Evaluation Methodology
In this section, we describe how to quantitatively evaluate the performance of the proposed RL maintenance scheduler in achieving its three goals. First, a set of performance metrics are proposed, and then, to acquire a baseline for performance comparison, a periodic maintenance scheduler is introduced. Later in the results and discussion section, the performance of the RL condition-based scheduler is compared with the periodic scheduler based on the proposed metrics. Finally, the results of the sensitivity analysis are discussed to study the influence of the model parameters.
4.1. The Maintenance Scheduler Performance Evaluation
The maintenance scheduler has three objectives, namely avoiding catastrophic failures, extending the asset’s life, and reducing the maintenance cost. A metric of performance is introduced for each one of the objectives to evaluate the agent’s performance in accomplishing its goals quantitatively.
Number of failures in full episodes runs of the test bench.
Average life length in the unit of month over full episodes runs of the test bench.
Average monthly cost (excluding the life extension reward) over full episodes runs of the test bench.
The performance metrics are average values in multiple runs to address the randomness of the test bench due to the stochasticity in the corrosion model’s input variables; e.g., environmental and operating parameters. In this study, we choose . Therefore, 20 full pipeline life episodes are simulated by the test bench while the maintenance decision-maker instructs the monthly maintenance orders. A full episode is defined by starting from a new pipeline and simulating until either reaching the maximum number of steps or entering the terminal state (i.e., the replacement of the pipeline or the occurrence of leakage or rupture).
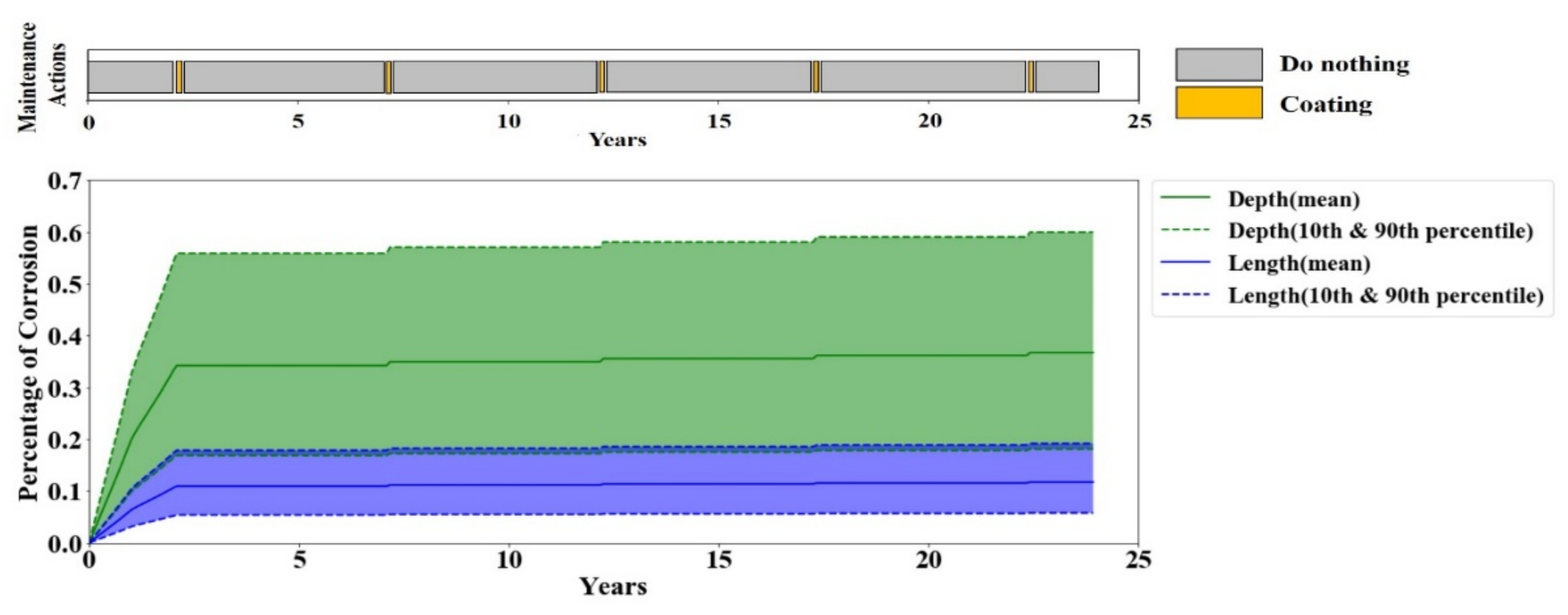
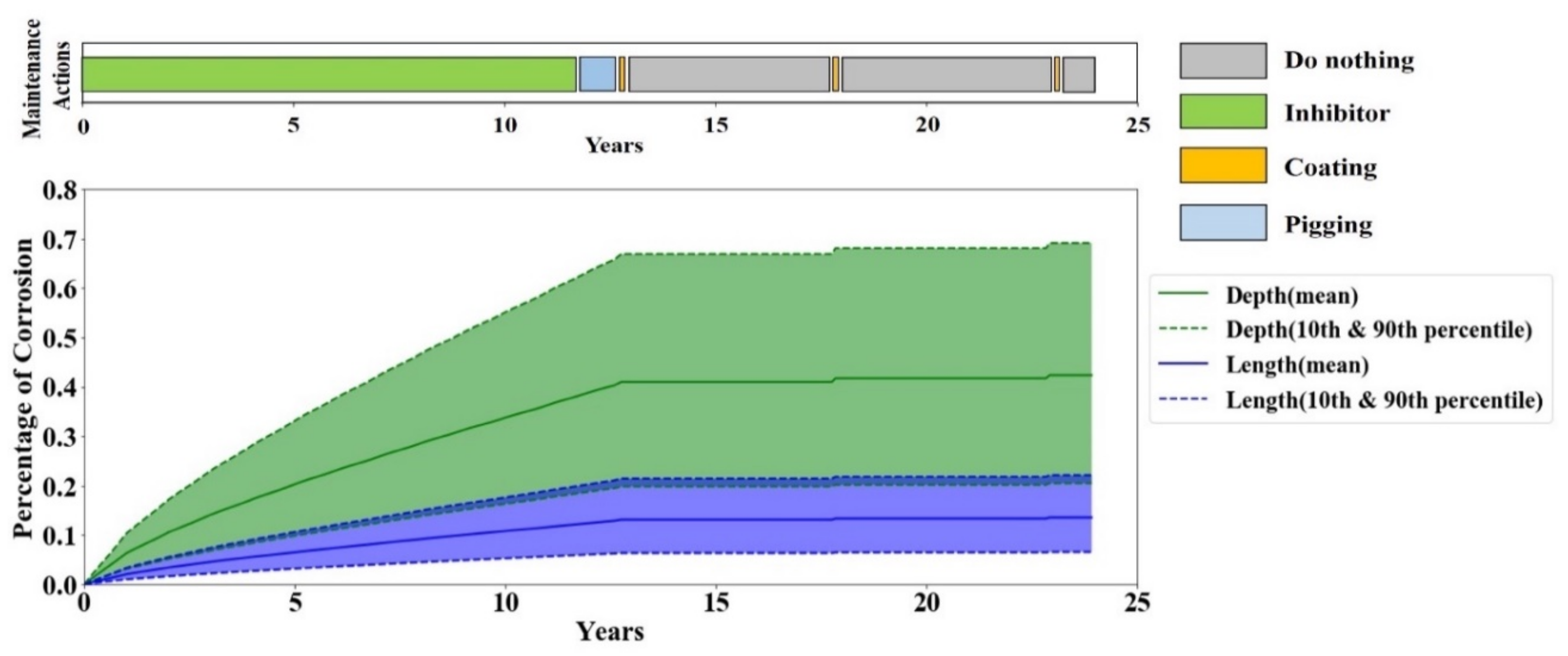
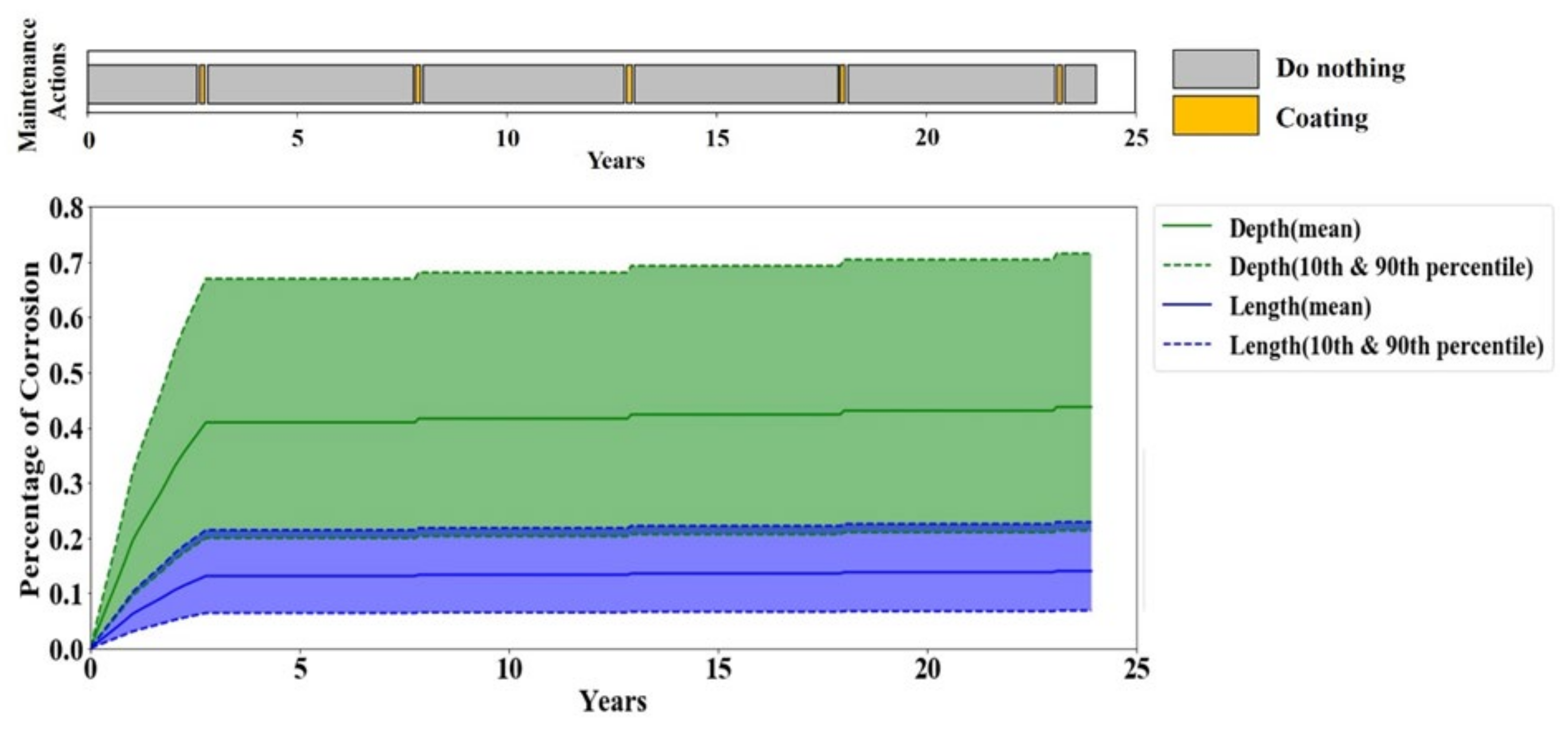
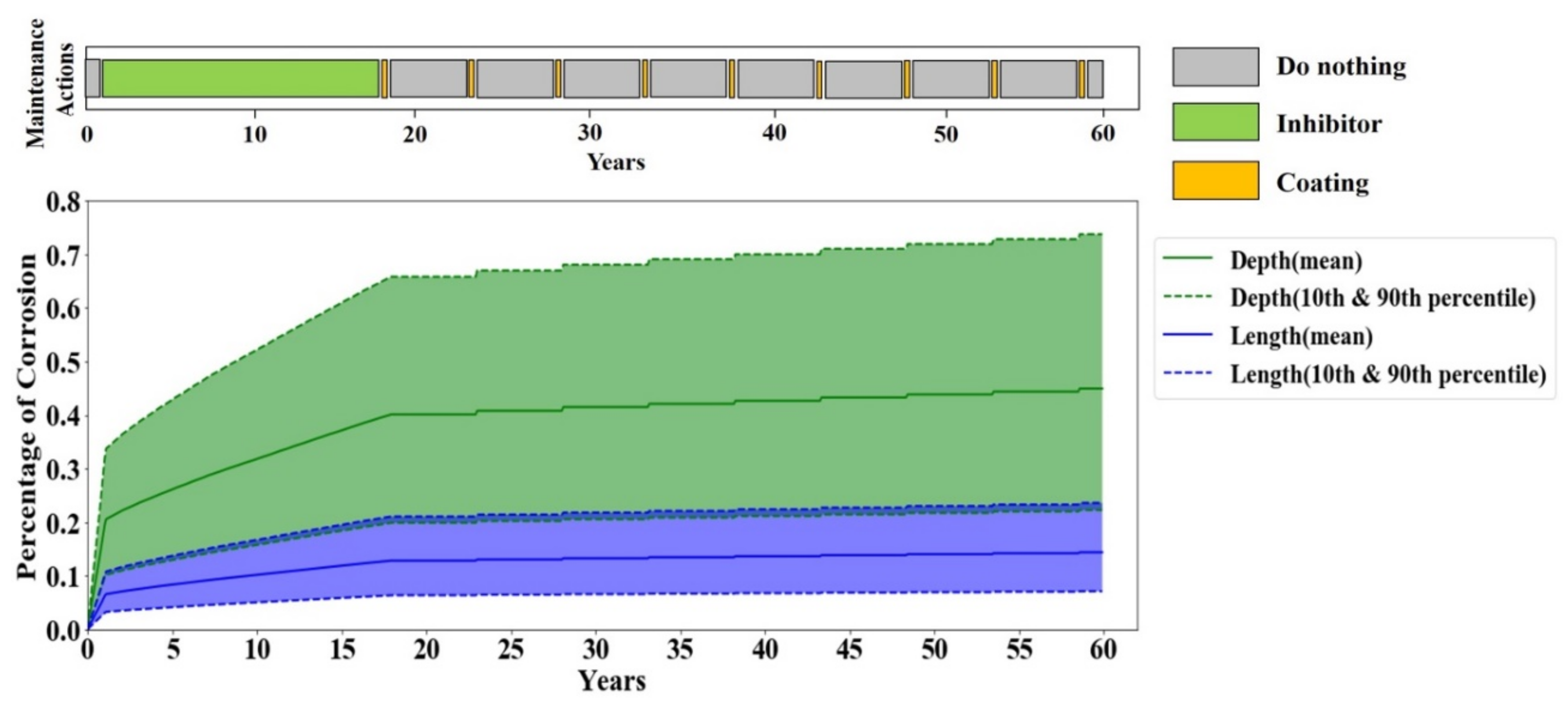
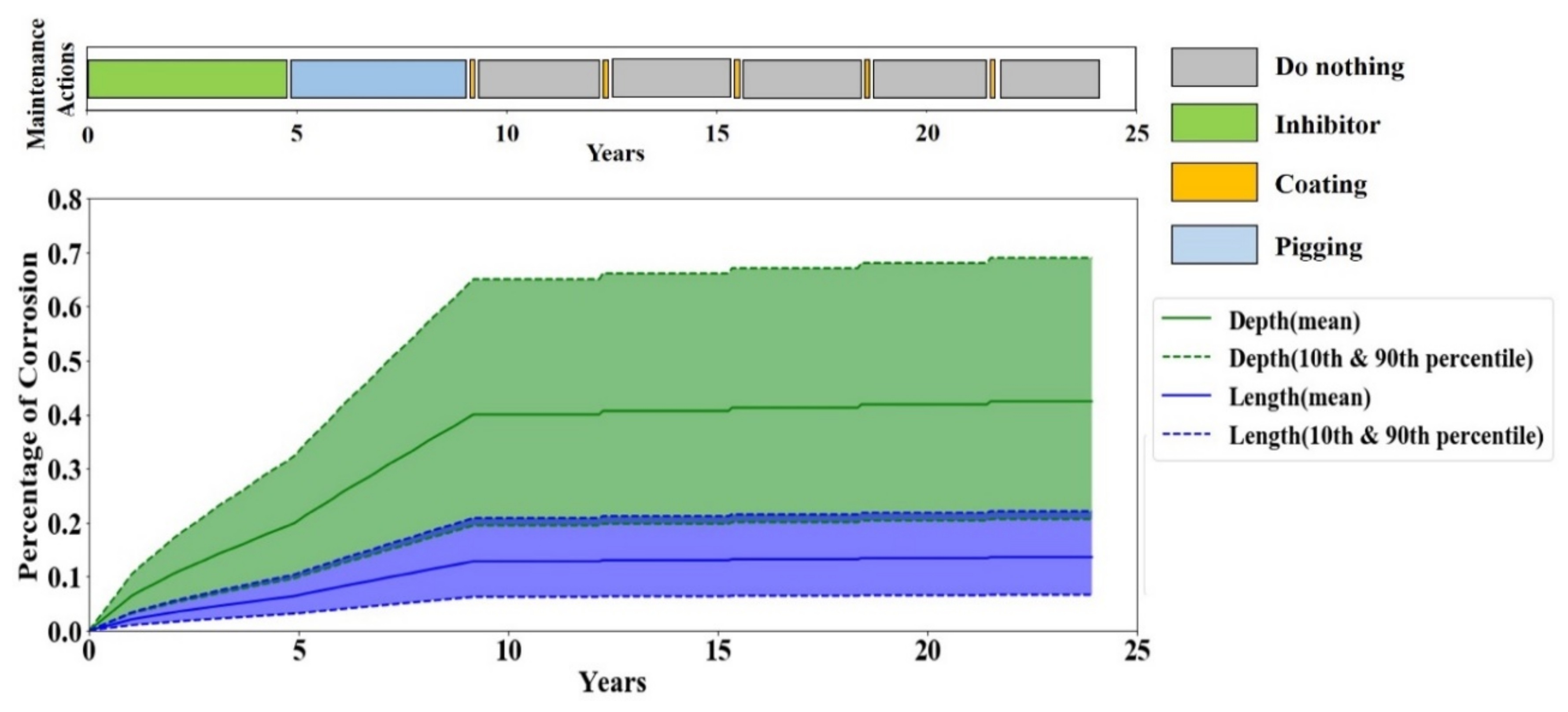
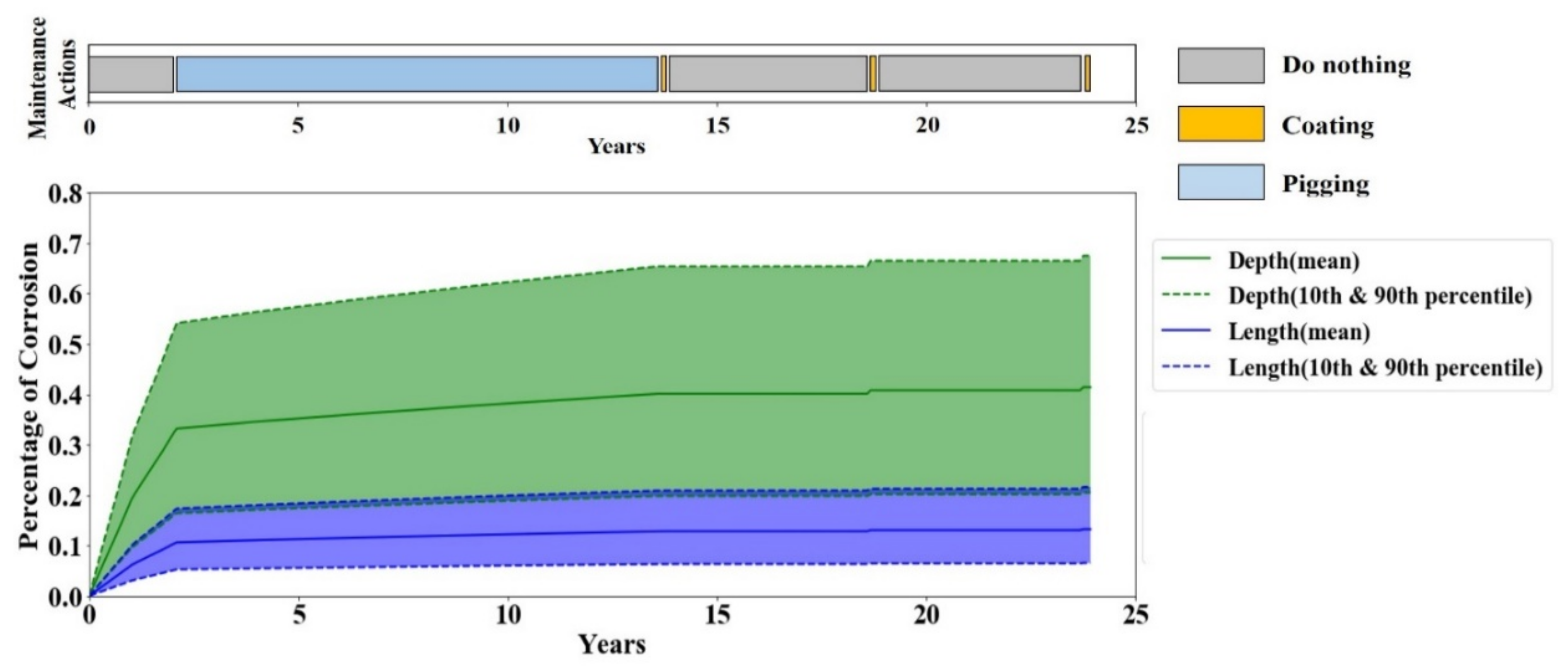
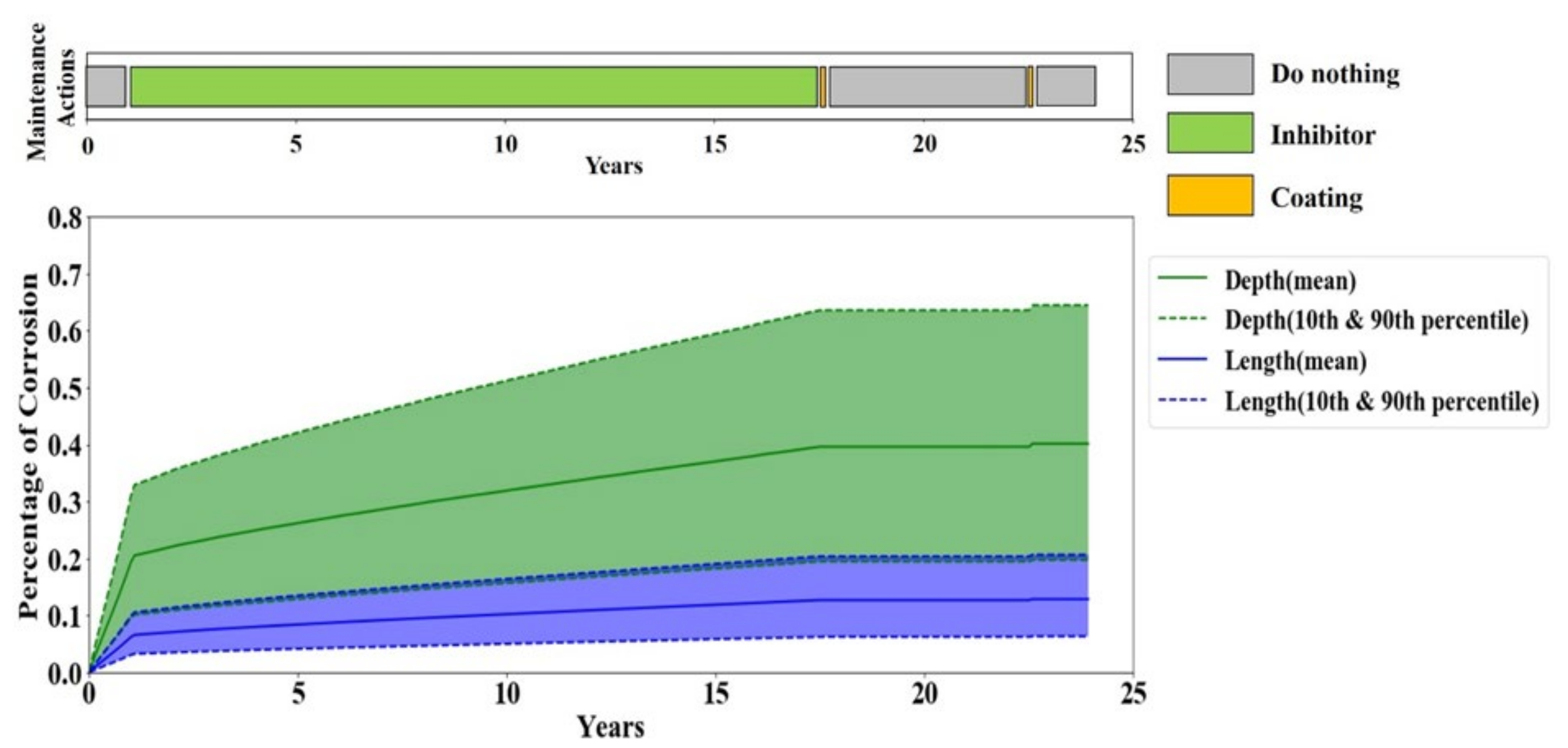
A periodic maintenance policy is the most common maintenance practice in the oil and gas industry. Therefore, the performance of the periodic maintenance policy serves as the baseline performance for evaluating the RL agent’s performance. A periodic maintenance strategy carries out the maintenance actions in fixed periods. To account for the variations of the periodic maintenance policy given that each pipeline operator has their preference on the period of each maintenance action, multiple evaluations by the periodic maintenance policy with different scenarios are performed. The considered scenarios are listed in
Table 6.
4.2. Sensitivity Analysis
The test bench presented in this paper is a valuable tool for when the pipeline operators and decision-makers want to assess their maintenance policy, and the learning algorithm of
Section 3.2.4 is beneficial when they want to consult an AI technique for making an optimal maintenance management strategy. However, it is crucial to tune the test bench and adjust the models’ parameters to each specific pipeline system. Hence, in this section, we introduce sensitivity scenarios to study the influence of some of the test bench’s parameters, namely, the maintenance actions’ effective life and the life extension reward, on the RL agent’s performance.
Five scenarios of sensitivity analysis are designed and applied to the proposed methodology. The Q-learning agent is trained for each sensitivity scenario separately, and afterward, the resulting policy is evaluated by the same approach as explained in the previous subsection. The parameters of each scenario are listed in
Table 7. The value of the life extension reward and the effective lifetime of maintenance actions are changed one at a time. Therefore, the results reflect the influence of each variable independent from the others. The scenario that holds the former life extension reward and maintenances’ lifetimes parameters, presented in
Table 3 and
Table 4, is addressed as the reference for the sensitivity scenarios.
6. Conclusions
This paper presented a test bench and a methodology for addressing the problem of optimizing maintenance management of a dry gas pipeline by RL decision-making approaches. Despite the great recent achievements of RL and its promising capabilities to improve asset integrity management by leveraging the enormous amount of IoT data, its application to pipeline integrity management is very limited. The proposed test bench is an effort to fill this gap via facilitating the development of RL methodologies in pipeline integrity management without risking the real system. The test bench is a physics-based corrosion degradation model that could interact with a decision-maker agent and adjust itself to the maintenance orders conducted by the decision-maker. Accordingly, it provides a testbed for assessing various corrosion maintenance policies including but not limited to any RL-based maintenance policy, condition-based maintenance policy, periodic maintenance policy and corrective maintenance policy.
Furthermore, this paper proposed a data-driven, model-free RL algorithm that performs condition-based maintenance management. The proposed algorithm is trained and tested through the test bench, and the results showed a 58% reduction in maintenance costs while improving the reliability of the pipeline compared to the periodic maintenance regime; i.e., no failure happened under the proposed condition-based maintenance policy. These promising results encourage further investigations into applying data-driven RL approaches to pipeline integrity management. In continuation of this research, the authors are working on advancing the RL agent to overcome the limitations of the current agent, such as finite and discreet state and action spaces. More specifically, the authors are working on development of a data-efficient and trustable deep RL solution that would be a competent decision-maker to deal with real pipeline systems. Accordingly, we have been in continuous consultation with a number of major oil and gas companies on modeling aspects and assumptions of operational parameters and maintenance strategies.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}