We demonstrate the effectiveness of the proposed method through three different case studies: the first dedicated to analyzing the operators of the method in isolation to evaluate the influence of each one of them during the solution of JSSP instances; the second specialized in evaluating the capacity of the method to find optimal solutions to the problem addressed, being compared with different types of meta-heuristics that make up the state of the art; and the third dedicated to comparing our method with other GA-like techniques when solving the JSSP.
The proposed algorithm was coded using Matlab software and the tests were performed on a computer with 2.4 GHz Intel(R) Core i7 CPU and 16 GB of RAM. We emphasize that we only used the standard functions of the Matlab IDE to conduct the computational experiments and we do not use ready-made optimization software packages.
5.1. Case Study I: Analysis of Isolated Operators
In this case study, we evaluated different configurations of the method to investigate how each of the operators proposed in this work acts on our method. Specifically, we want to observe which operators most strongly influence the proposed method. For this, we evaluated different configurations of our technique in three LA [
17] instances. These configurations were stipulated so that we were able to analyze the influence of each of the operators separately. That is, we defined a configuration as a basic GA, another as a basic GA with the multi-crossover operator, another as a basic GA with a version of the proposed local search operator, and so on. For this, we will investigate the operation of the following configurations:
GA: Basic GA;
GA+mX: Basic GA with proposed multi-crossover operator from
Section 4.4;
GA+LS*: Basic GA with proposed local search operator from
Section 4.5 using
, i.e., performing local search on all offsprings that are generated at the crossover operator;
GA+LS**: Basic GA with proposed local search operator from
Section 4.5 using
, i.e., performing local search on
of all offsprings that are generated at the crossover operator;
GA+ELSA: Basic GA with simple mutation (just one use of
) and using proposed massive local search operator with
(elite local search of Reference [
6]);
GA+MLS: Basic GA with simple mutation (just one use of ) and using proposed massive local search operator with ;
GA+mX+LS**: Using our multi-crossover operator in GA+LS** previous configuration;
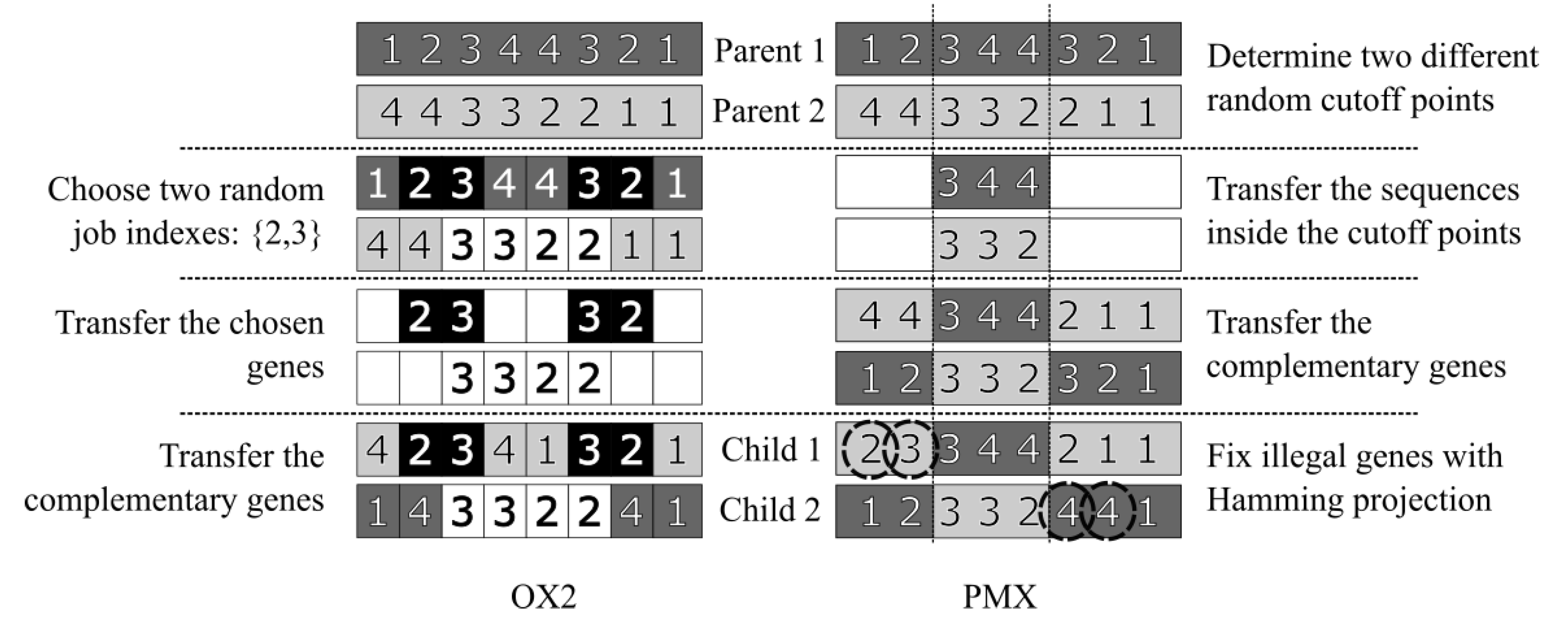
mXLSGA: Proposed method with all proposed operators (
Figure 4).
The details of the configuration of each of the evaluated algorithms are shown in
Table 2.
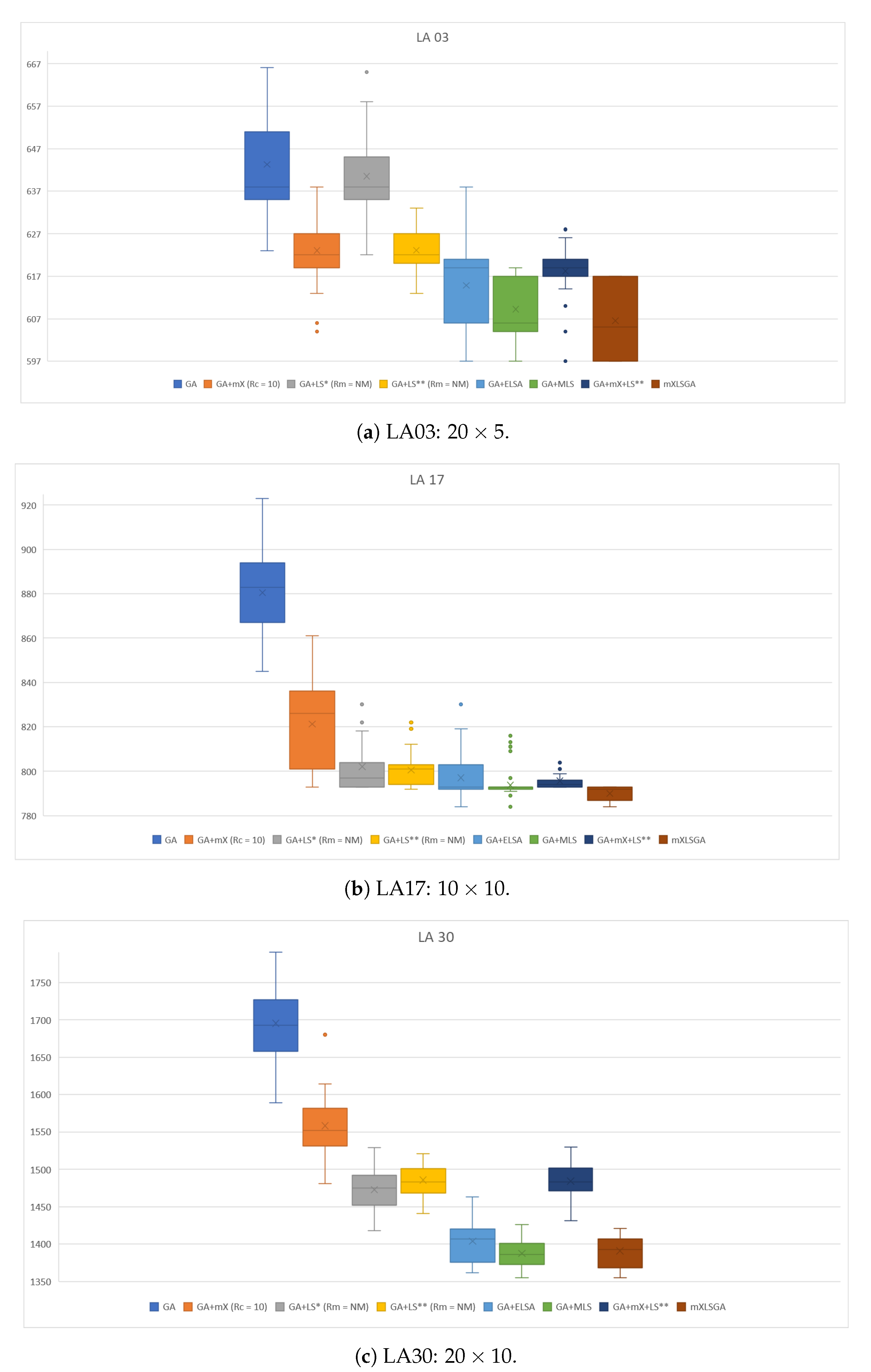
Each of the configurations presented in this case study was executed 35 times in three LA instances of different sizes: LA 03, with a dimension of
, considered easy level; LA 17, of size
, of medium level; and LA 30, with a size of
, of difficult level. These instances were defined so that at least one instance of each of the three main groups of dimensions was considered to verify the efficiency of the algorithm and its behavior in instances of varying dimensions, from the simpler to the most complex. The fitness values for each configuration were used to make the box plots in
Figure 5.
Looking at the box plots shown in
Figure 5, we can see that the addition of any of the operators proposed in GA was very beneficial. However, some operators have greater influence in certain cases. For example, the multi-crossover operator has greater influence on less complex bases, since in
Figure 5a it works as well as or even better than the GA+LS* and GA+LS** configurations, while on more complex bases (
Figure 5b,c) the GA+mX configuration presents results statistically inferior to the results of GA+LS* and GA+LS**.
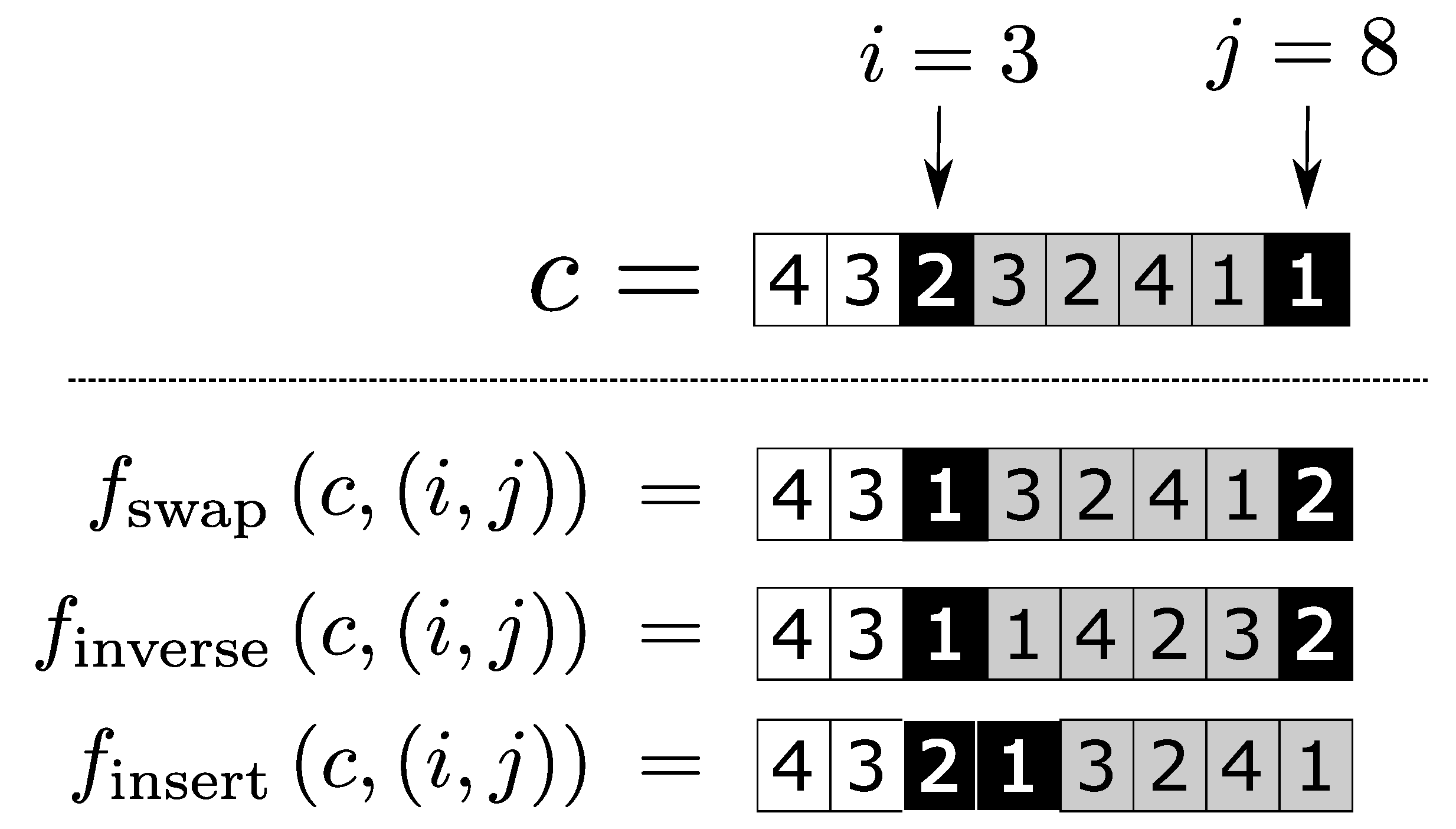
Concerning mutation operators that use local search strategies, we noticed that as the complexity of the analyzed instance increases, the performance of GA+LS* improves in relation to the GA+LS** configuration. This is because, the greater the complexity of the instance, the use of local search strategies becomes more advantageous than the genetic variability guaranteed by the operator with the use of
. However, we can see in
Figure 5a that, in instances of less complexity, the GA+LS** configuration presents much better and more stable results than those presented by GA+LS*. Thus, it is a good strategy to use a value between
and 1 for
in the next case studies.
We can also observe that the massive local search operator is the operator that present better quality and greater stability in the results. The addition of massive local search operators in basic GA results in better fitness values compared to the addition of two distinct operators, as is the case with the GA+mX+LS** configuration, which results in lower fitness values than GA+ELSA and GA+MLS configurations in the box plots of
Figure 5a,c. Also, the use of more than one disturbance function in
has resulted in GA+MLS presenting better and more stable results than the results of GA+ELSA, which uses only the
function in
, in all evaluated cases. Thus, we can conclude that the operator with the greatest influence is the massive local search operator.
The use of two local search operators in GA + mX + LS** made this configuration more stable than the simplest configurations that use only one operator, in this case the configurations GA + mX, GA + LS* and GA + LS**. In addition, also compared to these configurations, GA + mX + LS** presents better fitness values in the instances LA03 (
Figure 5a) and LA30 (
Figure 5c).
Finally, the configuration of the proposed methodology that corresponds to the joint use of all the operators discussed is the mXLSGA method, which presents the best results in all evaluated cases, with greater accent in the LA03 instances (
Figure 5a) and LA17 (
Figure 5b). This confirms that the use of all operators concurrently is the best configuration for the methodology since it is in this configuration that the best results are obtained.
Table 3 shows the average time required considering 35 independent executions for all the proposed method configurations to solve the JSSP instances in this case study. As we can see, basic GA is the fastest technique of all compared. However, we note that the addition of the multi-crossover operator (GA + mX) does not radically compromise the computational time, but, as shown in the box-plots of
Figure 5a–c, this addition considerably improves the performance of the method in obtaining good results. In the case of versions that use only massive local search operators (GA + ELSA and GA + MLS), it is clear that the performance is improved and that, in smaller instances such as LA03 and LA17, the computational time is not drastically increased. However, that is not the case of the LA30 instance. This is due to the quadratic behavior of these operators, since, as we can see in their formulation in Algorithm 3, in each iteration of the method occurs
perturbations in the chromosomes from
. Something similar occurs with configurations that only use local search strategies in the mutation operator (GA + LS* and GA + LS**). Specifically, we can see that these are the most expensive isolated operators in time cost in the case of smaller instances (LA03 and LA17) and this cost increases proportionally according to the complexity and size of the instance. These facts are reflected in the GA + mX + LS** configuration, whose average time in all instances is approximately the sum of the times of the GA + mX and GA + LS** configurations. In all instances, the configuration that obtains the best performance (mXLSGA) is also the most costly in computational time, but this is an expected result since this technique uses all the operators described in this work. Thus, in the following case studies, we will direct our analysis and comparisons to our mXLSGA.
5.2. Case Study II: Mxlsga for JSSP and Comparison with Other Algorithms
In this case study, we will evaluate the capacity of the proposed methodology to find optimal solutions in the search space. For this, we intend to demonstrate the effectiveness of the method when applied in JSSP instances present in the specialized literature.
In details, to evaluate the proposed approach, experiments were performed in 58 JSSP instance scenarios, 3 FT instances [
16], 40 LA instances [
17], 10 ORB instances [
18] and 5 ABZ instances [
19]. The results obtained in the execution of the tests were compared with papers from the specific literature. The articles determined for each comparison were selected because they are relevant works in the literature, which deal with the JSSP with the same specific instances and, when existing, papers published in the last three years were adopted. The papers selected for comparison of results were as follows: SSS [
61], GA-CPG-GT [
14], DWPA [
15], GWO [
11], HGWO [
12], MA [
9], IPB-GA [
8] and aLSGA [
6].
The configuration of parameters for the mXLSGA was established through tests and also taking into consideration, when possible, a closer parameterization of the works that were used for comparison. In this way, the parameters were defined as shown in
Table 4.
The proposed mXLSGA method was executed 10 times for each JSSP instance and the best value obtained was used for comparison with other papers. In most of the comparative works, the authors do not mention the processing time of their techniques and only present the best result. We proceed in the same way for this case study, reserving a more detailed analysis using time and other statistical measures for the next case study, in which we programmed a version of other compared techniques and, therefore, we were able to observe such measures.
Table 5 shows the results derived from the LA [
17], FT [
16], ORB [
18] and ABZ [
19] instance tests. The columns indicate, respectively, the instance that was tested, the instance size (number of Jobs × number of Machines), the optimal solution of each instance, the results achieved by each method (best solution found and error percentage (Equation (
8)), and the mean of the error for each benchmark (MErr).
where “E%” is the relative error, “BKS” is the best known Solution and “Best” is the best value obtained by executing the algorithm for each instance.
As shown in
Table 5, mXLSGA found the best known solution in
of FT instances,
of LA instances,
of ORB instances, and
of ABZ instances.
The mXLSGA proposal reached in 28 LA instances the best known solution and obtained a mean relative error (MErr) of . The SSS and HGWO methods obtained a lower average error than our mXLSGA, assuming and , respectively, but they did not test all the LA instances. If we only consider the instances that have been tested by SSS, our mXLSGA proposal would obtain a MErr of . If we only consider the instances tested by HGWO, our method would get from MErr. Specifically, in FT instances, the mXLSGA reached in 3 instances the best known solution and obtained a MErr of . In ORB instances, the mXLSGA reached in 3 instances the best known solution and obtained a MErr , it is the method with the lowest MErr of all compared algorithms. In ABZ instances, the mXLSGA reached in 2 instances the best known solution and obtained a MErr of . The method that achieved a minor error was GA-CPG-GT, but this work did not test in all ABZ instances, and if we compare only the instances that GA-CPG-GT was tested, mXLSGA would have gotten relative mean error, that is, the mXLSGA achieved the best known solution in the first 2 ORB instances.
In particular, our method surpassed the technique on which it was based, which in this case is aLSGA. In LA instances, our method got 6 BKS more than aLSGA.The aLSGA obtained in the LA instances a MErr of and mXLSGA obtained a MErr of , but aLSGA was tested only in the first 35 LA instances, if we consider the MErr only for the 35 LA instances, mXLSGA would get a MErr of , which is less than half the value obtained by aLSGA. For ORB instances, mXLSGA obtained a MErr less than one third of the one obtained by aLSGA. The improvement achieved by mXLSGA is certainly due to the insertion of the multi-crossover operator and the enhancements employed in local search techniques.
Analyzing the data presented in
Table 5, we can see that in the tested JSSP instances, the proposed mXLSGA results better or equal to the compared state-of-the-art algorithms.
5.3. Case Study III: Statistical Analysis of Ga-Like Methods
This case study was designed and executed to verify the effectiveness of the mXLSGA method when compared to the main GA-like methods that build the specialized literature: the basic GA, GSA [
22], LSGA [
4], aLSGA [
6]. We compared mXLSGA with such techniques because they were the basis of inspiration for its modeling and because they still represent the state of the art in GA-based metaheuristics to solve the JSSP. The effectiveness must be guaranteed through the analysis of different statistical measures and the time of each method. Indeed, we implemented all the compared techniques to perform the analyzes. So that all the methods were coded as faithfully as possible to the descriptions present in their respective articles, however, we emphasize that the coding may differ from the original coding for several reasons, such as: different programming techniques; parameterization of the method, for example, the number of executions for the method; some detail of the method that is not present in the text of the original work or that we have interpreted differently; and so forth.
We try to follow the parameterization as faithful as possible to the original parameterization of each technique, however, we use 100 individuals and 100 iterations in all the considered methods. In details, the configuration used is presented in
Table 6.
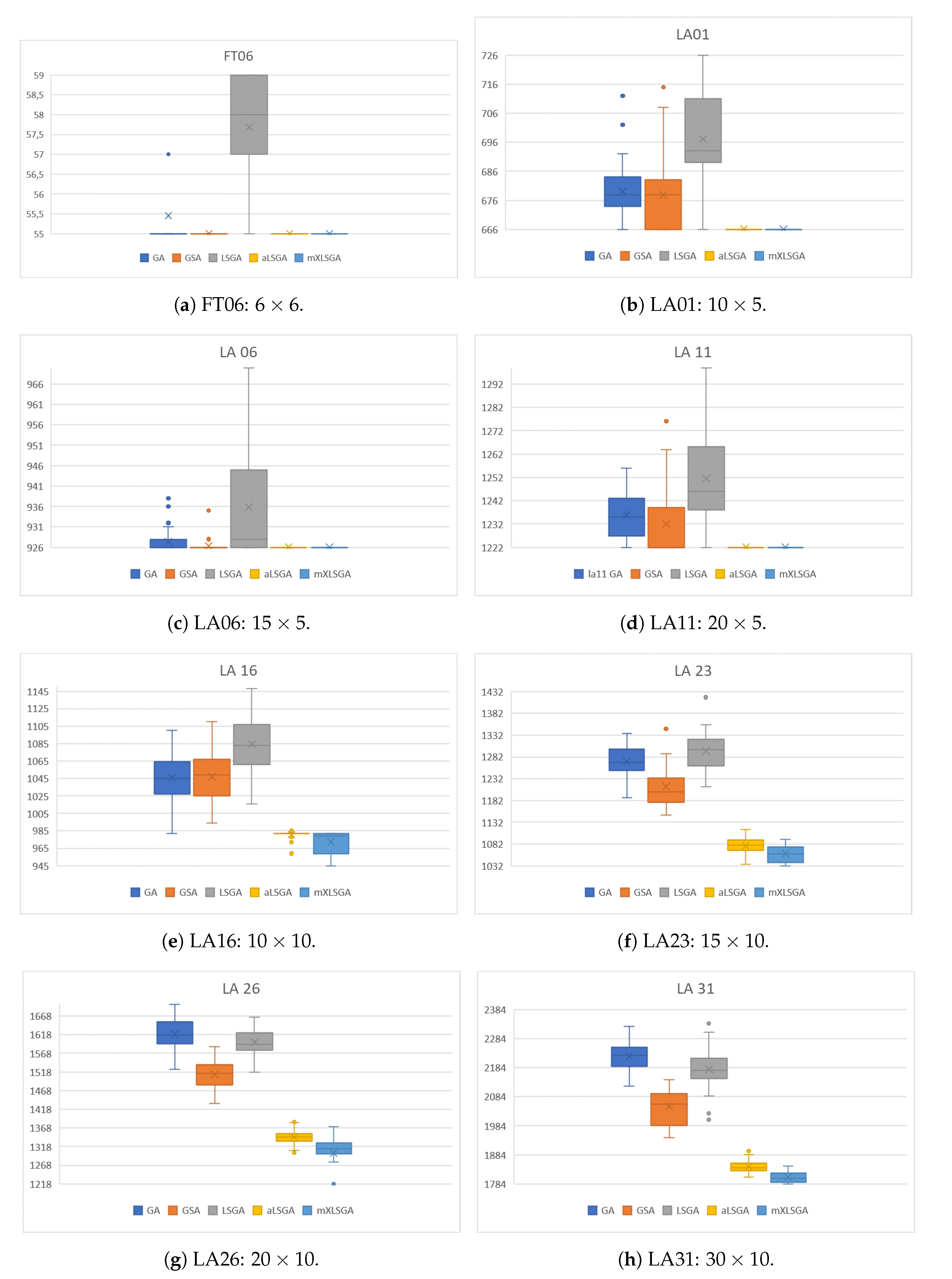
The compared techniques were executed 35 times on instances of different dimensions in which our method can find the optimal value of makespan considering case study II (
Section 5.2). In
Table 7, we can see some statistical information about these executions, namely: the best fitness value achieved by the technique (Best); the worst fitness value achieved (Worst); the average of the fitness values of the executions of each technique (Average); the standard deviation of these values (SD); the number of times the method has reached the optimal value (Number opt); the number of iterations (Number it) needed to reach the optimum value; and the average time (AT) in seconds that the technique takes to perform 100 iterations.
As shown in
Table 7, it is noteworthy that mXLSGA found the optimal fitness value in all instances analyzed, and in instances FT 06, LA 01, LA 06 and LA 11, the proposed method found the optimal value in all executions. The mXLSGA presented the lowest worst value and the lowest average in all instances. In the instance LA 16, LA 23, and LA 26, mXLSGA did not obtain the lowest standard deviation value, however, it was the only method that found the optimal value in all these instances. Our method was the method that required the longest average execution time, but as it will be better explained in the following paragraphs, this is not in any way a deficiency in our method, as it does not need all 100 generations to converge.
To visualize the statistical performance of each method, we made the box plots of the fitness values achieved in this case study, which are shown in
Figure 6. As highlighted in the case study I (
Section 5.2), box plots make it clear how the presence of a massive local search operator makes the method much more robust compared to the others, since in all the instances the aLSGA and mXLSGA methods are the most stable and have the best fitness values. This difference is even accentuated as the complexity of the instance increases. Also, the graphs reflect the values presented in
Table 7, since mXLSGA is the box below the other boxes in all evaluations. We also noticed some details, such as why the mXLSGA standard deviation is the largest when executed in the LA 26 instance since this is because the technique finds the optimum value 6 times as a discrepancy. It is also clear from the graph that, statistically, our method is the method that most finds the best makespan settings.
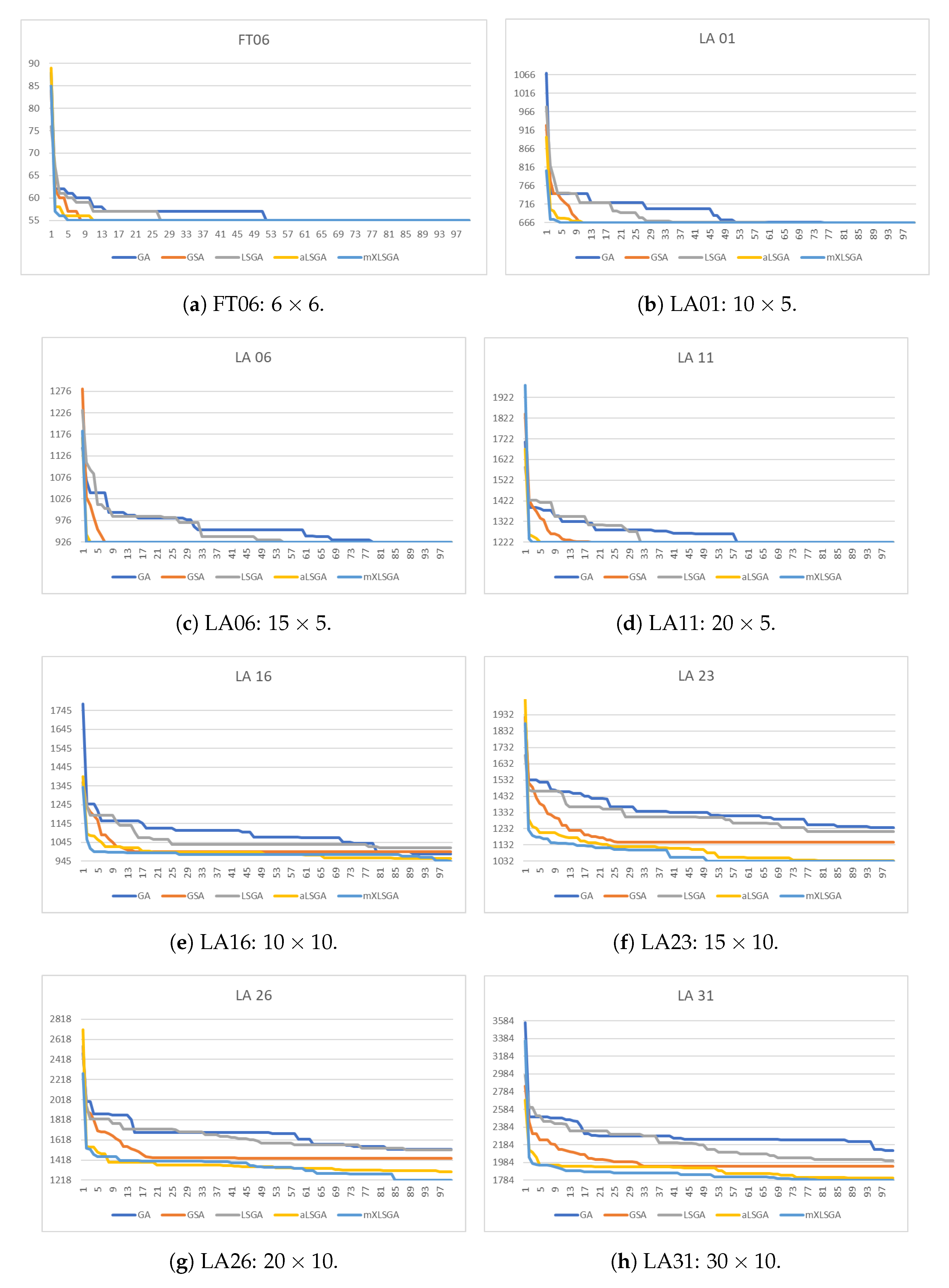
In
Figure 7, we highlight the convergence curves of the fitness value of the best individual of the 35 executions of each method in each instance during the 100 generations. It is clear that, as the complexity of the assessed instance increases, the number of iterations that each method needs to achieve the best value also increases. However, in none of the situations did our method requires all the 100 generations to find the best value. Indeed, mXLSGA finds the optimal value of makespan, or very close to optimum, with approximately 50 generations in more difficult instances. Whereas, in the case of simpler instances, such as FT 06 (
Figure 7a), LA 01 (
Figure 7b), LA 06 (
Figure 7c) and LA 11 (
Figure 7d), we realize that our method achieves optimal fitness before the 5th iteration. This fact does not occur with the other evaluated techniques, which need more iterations to reach the optimal value or, with the configuration used, they were not able to reach any of the optimum points, as was the case with all techniques with exception of mXLSGA in instances LA 16 (
Figure 7e), LA 23 (
Figure 7f), LA 26 (
Figure 7g) and LA 31 (
Figure 7h). In this way, time is no longer a major concern for our method, since it requires only
of the iterations used to achieve good results in larger instances, which reduces the time spent in half, or it only needs
of iterations to achieve the optimum in simpler instances.
In the sequence, still concerning the computational time analysis, we will evaluate the following situation: in each instance considered in this case study we will execute all the techniques taking as a stopping criterion the computational time instead of the maximum number of iterations. That is, all techniques will be performed for the same amount of time. In this way, for each instance, we will take as a time limit for all techniques the time it took the most time-consuming method to complete 100 iterations with respect to that instance according to the
Table 7. For example, for this experiment, all methods have
seconds to search for the optimal value of the instance FT-06, since this amount of time is the same amount that the GSA technique, which is the most time-consuming method in this instance, takes to perform 100 iterations on this JSSP instance. All techniques were performed independently 35 times following the strategy described. The results are summarized in
Table 8.
In
Table 8, we can see that there was some improvement in all the techniques that had more time to be performed. A clear example is basic GA, which showed a performance improvement in practically all measures considering all instances. However, the complexity of the evaluated instance remains a predominant factor with respect to the performance of the technique in this experiment, since in the case of a less complex instance such as FT06, all the evaluated methods were able to find the optimal value 55 in all the 35 executions. In the case of more complex instances such as instances LA16, LA23, LA26, and LA31 only the proposed method was able to find the optimal value, even with all techniques being able to be executed with the same amount of time. In addition, also in these instances, our method presented without a tie the best statistical measures of best fitness value, worst fitness value, and average fitness. In other words, our methodology presented the best performance in more complex instances and tied these measures in simpler instances in this experiment. This serves as an indication that the methodology proposed in this work provides better searchability for the technique, making it more efficient and surpassing other GA-like algorithms present in the literature.












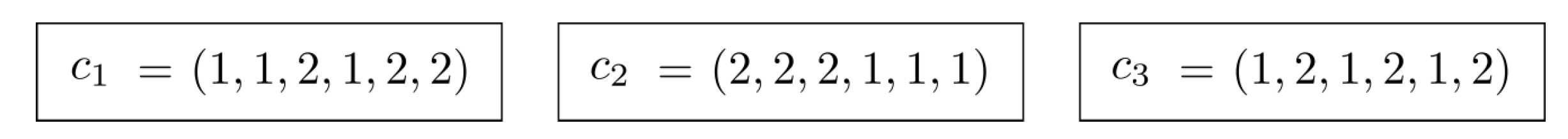{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}