1. Introduction
Digital content has always been subject to copyright infringement due to its ease of duplication. Recently, as the market for real-time content services such as web-comics (also called webtoons) and video streaming services such as YouTube has grown very rapidly, the problem of copyright infringement is increasing. These services, unlike traditional paid services, offer free content and earn revenue by advertising to users. As a result, these services are more vulnerable to illegal copying because they are easier to access than services that are provided for a fee. In addition, these services are provided on Internet browsers or as smartphone applications, making it easier to replicate the content with the Internet browsers’ or applications’ downloading or capturing functions.
Watermarking techniques have emerged to reduce the loss caused by piracy. These techniques minimize loss through the insertion of invisible information in the content to enable tracking of illegal distribution routes and copyright authentication. As mentioned above, in real-time content provided by Internet browsers and applications, geometric distortion occurs very frequently due to capturing.
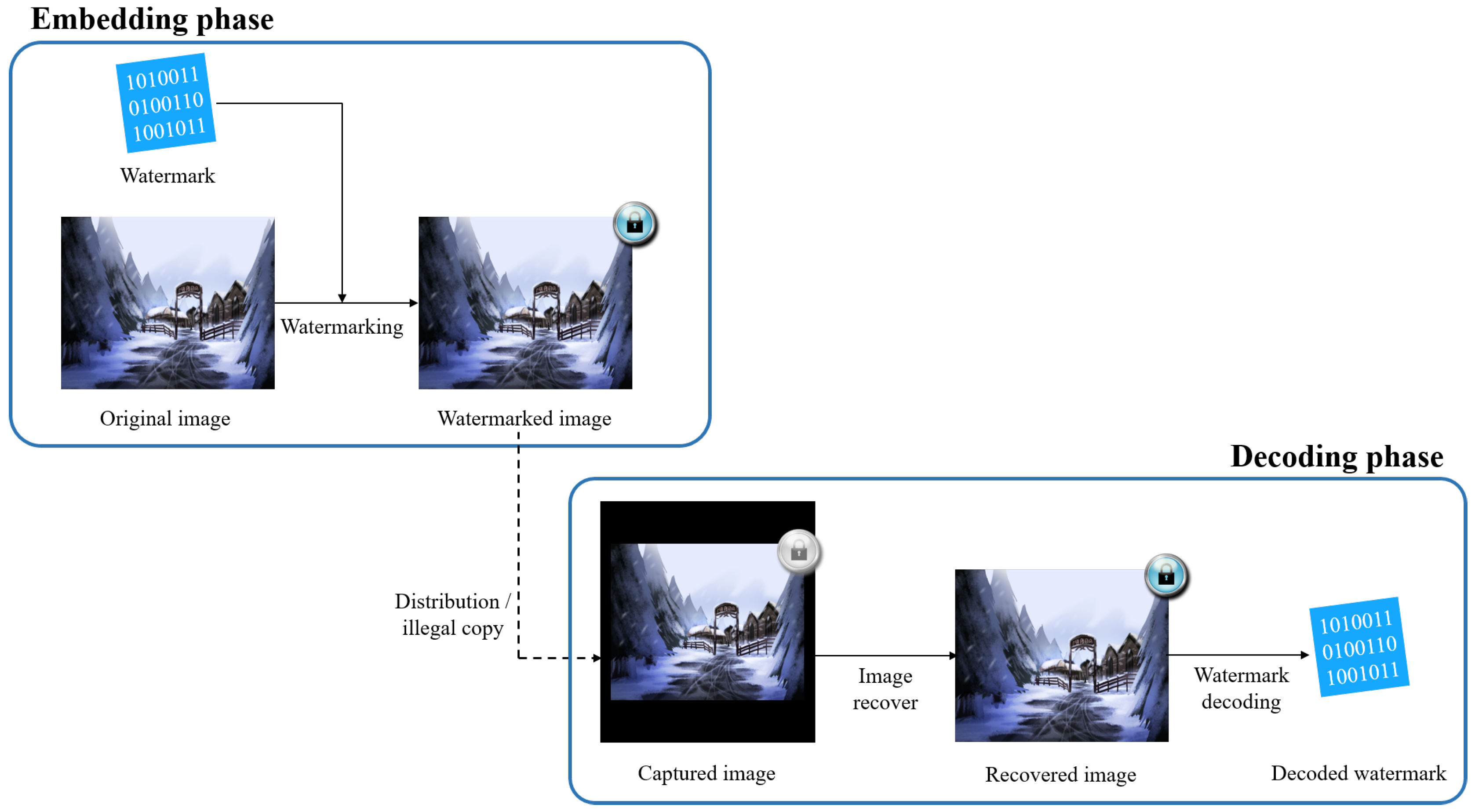
Figure 1 shows an illegal distribution scenario that occurs in a real-time content service and a watermark extraction process suitable for such a scenario. The piracy process, such as the capturing shown in this figure, makes it difficult to decode the watermark by breaking the synchronization of the watermark. Correction of the geometric distortion must be performed to extract the watermark accurately. Therefore, there is a need for a method that can effectively recover the image after such geometric distortion.
In this paper, we propose a convolutional neural network (CNN)-based template that can effectively correct geometric distortion. The proposed method divides the image into blocks of a specific size, inserts bit information into half of the blocks using the conventional watermarking technique, and inserts a CNN-based template to correct the geometric distortion in the other half. By inserting these block-based templates, it is possible to compensate for the disadvantages of geometric distortion while preserving the advantages of existing watermarking techniques except for the bit capacity.
The contributions of the proposed method are as follows:
- (1)
A learning-based template network that restores geometric distortion. Through learning, a robust template against various attacks can be designed.
- (2)
Block-unit template. This makes it easy to design a multi-bit watermarking system and does not interfere with the watermark signal because it can be inserted independently with the watermark.
- (3)
Due to the above two characteristics, the template can be easily applied to other watermarking techniques. This complements the vulnerability to geometric distortion of new forms of watermarks such as the DIBR watermarking method as well as existing watermarks.
The remainder of this paper is organized as follows.
Section 2 summarizes related works of robust watermarking and template-based watermarking.
Section 3 presents the main concept of the proposed method, and
Section 4 discusses the proposed method.
Section 5 presents experimental results and
Section 6 concludes the paper.
2. Related Work
To date, numerous watermarking techniques have been proposed to protect the copyright of content. Methods of inserting watermarks into various transform domains such as discrete cosine transform (DCT), discrete Fourier transform (DFT), radon transform, curvelet transform, Dual-tree complex wavelet transform (DT-CWT), and contourlet transform have been proposed [
1,
2,
3,
4,
5,
6]. Various insertion methods such as spread-spectrum, quantization index modulation (QIM), angle QIM, and absolute angle QIM have also been proposed [
7,
8,
9,
10]. However, these watermarking techniques often show weaknesses after geometric distortion. Because geometric distortion causes synchronization errors, it is not easy to ensure robustness of these watermarks to geometric attacks. In addition, the print-scan process, which is regarded as a watermark removal attack, is commonly used for image reproduction and distribution. Print-scan resilient data hiding provides an authentication method of an important document, which is becoming more significant issue because of the security problems [
11,
12,
13].
To reduce the vulnerability to geometric attacks, many studies have been carried out to identify the transform domain and insertion methods with invariant characteristics against geometric distortions [
14,
15,
16,
17]. However, these algorithms have drawbacks such as low invisibility, lack of bit capacity such as zero-bit watermarking, vulnerability to specific geometric distortion such as translation, or necessity of additional information.
Many template-based watermarking methods for decoding watermarks using template matching techniques have been proposed [
18,
19,
20,
21], but these methods also have a drawback in that it is difficult to insert sufficient copyright information because the bit capacity is low. In addition, since these templates are additionally inserted over the watermarked image in which the copyright information is embedded, the invisibility is further reduced, and the template and the watermark signal may interfere with each other.
These watermarking techniques robust to geometric attacks have many disadvantages compared to watermarking techniques that do not consider geometric attacks. In addition, if the synchronization problem is solved from the geometrically distorted image, the watermark can be normally decoded. For this reason, watermarking techniques that do not consider geometric attacks are used in many cases. If a geometric attack occurs, watermark decoding is performed after the image is recovered into the geometric characteristics of the original form. However, this approach requires a process for finding the original image information, comparing the original image with the geometrically distorted image, and then recovering the geometrical characteristics. This process is often inefficient because it is done manually or using heuristic search.
Conventional template-based watermarking techniques usually use whole image-unit transform rather than block-unit transform. This is because it is advantageous to use the image-unit transform when searching for invariant domains and insertion methods against rotation, scaling and translation (RST) attacks. When using the block-unit transform, it is necessary to solve the problem of correcting the block synchronization after geometrical distortion, which is difficult. However, the image-unit template has a problem in that the template cannot be inserted independently with the watermark containing copyright information unless they use the same transform domain. Therefore, there is a limitation that the template and watermark signal can interfere with each other. Also, it is difficult to design a multi-bit watermarking system in comparison with the block-unit method.
3. Main Concept of Proposed Method
The proposed method consists of a preparation step, insertion step, and decoding step as shown in
Figure 2. In the preparation step, a random binary code is generated using the key, and this code is used to generate a 2D binary template matrix
K of
size. This matrix determines whether each block is a template block or a watermark block in an image divided into blocks. It also serves as the ground truth for estimating the RST parameters in the template matching step.
In the insertion step, the image is divided into blocks, and then watermark insertion and template insertion are performed. First, the image is spatially divided into
blocks. The set of generated blocks is defined as
B. The following rules distinguish the roles of the blocks.
where
x and
y are the horizontal and vertical coordinates of
B and
K, 0 ≤
x <
M, and 0 ≤
y <
N.
Then, a block-based watermark is inserted into all the watermark blocks through the watermark embedder. The watermark embedder consists of an image transform, watermark insertion, and inverse transform in the same manner as conventional watermarking techniques.
As the final step of the insertion, a template is inserted into the template blocks. Template insertion is completed by simply adding the sized noise output from the template generation network to the image, where w and h are the width and height of the image. The template generation network is responsible for generating a specific form of noise that can be detected in the template extraction network.
The decoding step consists of extracting the template, estimating the distorted geometric information of the image, recovering the image, and decoding the bits from the watermark. First, in the template extraction step, the extraction network finds the location where the template is inserted in the image. The template extraction network outputs a matrix ’ with a value of 1 where the template is inserted and 0 where the watermark is inserted. Inputting the ’ and the original template , which can be obtained from the key, into the template matching network yields estimated RST parameters. is simply a resize of K, which is used to increase the resolution of the template.
The geometrically distorted image is recovered using the estimated RST parameters. This step solves the problem of block synchronization, which is the biggest problem with block-based watermarking techniques. Therefore, the block-based watermark can be extracted blindly by using the block size and position information used in the watermark insertion step.
As the last step of decoding, the watermark extraction proceeds in the order of image transform and watermark extraction in the transformed domain as in conventional techniques.
The template generation network, template extraction network, and template matching network, which require a more detailed description, are described in
Section 4.1 and
Section 4.2, and the watermark embedder and decoder are described in
Section 4.3.
4. Proposed Method
In this section, the description of the template and the watermark are presented separately without considering the insertion and extraction order. The insertion and extraction order is detailed in
Section 3.
In each step of template insertion and extraction, a resized K is used. Resizing is performed with the nearest neighbor filter, and K resized into is defined as . For example, means that the K of size is resized to 64 × 64. The reason for resizing K is to increase the resolution of the template to increase the accuracy in the matching step.
4.1. Template Embedding and Extraction Network
Figure 3 presents a template insertion and extraction scheme. Template embedding is performed as a simple sum as,
where
is the template inserted image,
I is the original image, and
is the template noise generated from the template generation network.
In the template extraction step, a template is extracted from . The goal is to learn the template generation network and extraction network so that the extracted template becomes the same as the template used at the template insertion step.
The detailed template generation and extraction network structures are shown in
Figure 4. We set the kernel size of all convolutional layers in the network to (3, 3). The reason is to extract the local features of the image similar to discrete wavelet transform rather than global features similar to DFT. In order to estimate the RST parameters, the same geometric transformation as that occurring in the image must occur in the extracted template. If the template is perfectly invariant and the template is extracted without coordinate distortion, the RST parameters cannot be estimated. Thus, by exploiting local features, we induce the template to have semi-invariant properties. A semi-invariant template preserves its value from geometric distortion, but the coordinates are transformed according to the degree of geometric distortion.
The template generation network is an inverse process to the template extraction network. This template generation network generates a template noise (
) of size
from a template (
) of size
using a transposed convolutional layer. The process of expanding the dimension is similar to the insertion method for conventional watermarking techniques. In conventional watermarking techniques, when the watermark inserted in the middle frequency of the transformed domain passing through the inverse transform, the watermark signal spreads to the entire image of the spatial domain. The proposed template generation network also spreads the low-dimensional signal to the high-dimensional spatial domain similar to the conventional technique. At the end of the network, the generated template noise is masked so that the template noise does not interfere with the watermark block. The loss of the template generation network is defined as,
is the template noise generated from the generation network, i and j denote the horizontal and vertical coordinates of the generated template noise, respectively, U represents the width and height of the network output and is set to 512, i.e., since corresponds to the average energy of the template to be inserted, the generation network is trained so as to improve the template invisibility. is combined with the loss of the extraction network described below, and the generation network and the extraction network are trained together.
As in (
2), simply adding the template noise generated from the template generation network to the original image will complete the template embedding. The template embedded image is then sent to the template extraction network after RST distortion.
The template extraction network extracts 64 × 64 templates that are the same size as the input of the generation network from the attacked image. The loss of the template extraction network is defined as,
where
V is the size of the output of the extraction network and is set to 64.
denotes the output of the network, i.e., the extracted template, and
denotes the original template.
i and
j denote the horizontal and vertical coordinates of the template, respectively.
indicates a geometric transformation using the ground-truth parameters. Since the geometric distortion that occurs in the image occurs equally in the inserted template, we define the loss function so that the extracted template is also subjected to this geometric distortion. This loss,
, trains the extraction network to improve the extraction accuracy of the template.
The total loss using the losses of the template generation and extraction networks is defined as,
where
is the trade-off parameter between invisibility and template extraction accuracy. The larger the
, the higher the invisibility but the lower the extraction accuracy.
To use the middle frequency as the template noise similar to the existing watermarking technique, the template generation network is pre-trained before the whole network training. First, as in the spread-spectrum watermark [
1], we generate a middle frequency noise with a size of 512 × 512. This noise is generated by substituting a pseudo-random sequence from 1/4 to 3/4 of the zigzag-scanned DCT coefficients, and is defined as
. The pseudo-random sequence is set with an average value of 0 and a variance of 1. Then the template generation network is pre-trained until
is less than 0.1. The template extraction network is initialized by the Xavier uniform initializer [
22].
4.2. Template Matching Network
The template matching network shown in
Figure 5 compares the extracted template with the original template and estimates the RST parameters. First, the feature extraction network extracts features from the extracted template and the original template. The feature extraction network mimics domain transformation methods such as DFT. Domain transforms, such as DFT, are the sum of all pixels multiplied by different weights in the image. Similar to DFT, we use the kernel size as the template size to compute the global features of the template. We compute 256 global features and reshape it by 16 × 16. This is similar to calculating 16 × 16 DFT coefficients from an image. As we can estimate the translation degree from the phase of the DFT, these global features will facilitate RST parameter estimation.
The extracted features are then matched to estimate the RST parameters. These matching layers refer to the structure in [
23,
24,
25]. Feature extraction networks are Siamese networks that share weights with each other. After the feature extraction network, a concatenation layer, which is fast and has good matching accuracy, is used to combine features extracted from the feature extraction networks. Later layers are identical to the structure in [
25]. The final result is a five-dimensional matrix [
R,
,
,
,
], which indicates the rotation, scaling of
x and
y, and the translation of
x and
y parameters. The loss of the matching network is defined as,
where
d is the Euclidean distance between two points,
is the geometric transformation using the estimated RST parameters, and
is the geometric transformation using the ground-truth RST parameters.
and
correspond to the
S equally divided points of the image in the horizontal and vertical directions, respectively, and
S is set to 10, i.e.,
corresponds to the mean squared error between the estimated points and the true points. The reason for using the Euclidean distance as a loss without using the RST parameters directly is that each RST parameter has different weights of distortion on the image. For example, when a parameter of the same value is used, the distortion of rotation is larger than the distortion of translation.
Although the template matching network has been described separately here, the template generation and extraction network described above are attached to the template matching network, and then end-to-end learning is performed. End-to-end loss is defined as,
where
is the trade-off parameter between invisibility and matching accuracy. The template matching network also uses a Xavier uniform initializer to initialize the network. Since
includes training of the template extraction network, the template generation network, template extraction network, and template matching network are trained all at once by
.
4.3. Watermark Embedder and Decoder
The watermark has the role of inserting and decoding bit information. Similar to conventional techniques, the watermark is inserted/decoded in the transformed domain, and the curvelet is used as the transform domain. The reason for using this domain is that it is easy to insert multiple bits into one block through parameter adjustment while the watermark in this domain remains invisible and robust.
The curvelet transform is a multi-scale decomposition-like wavelet transform, and the curvelet represents the curve shape for various directions in the spatial domain [
26,
27,
28,
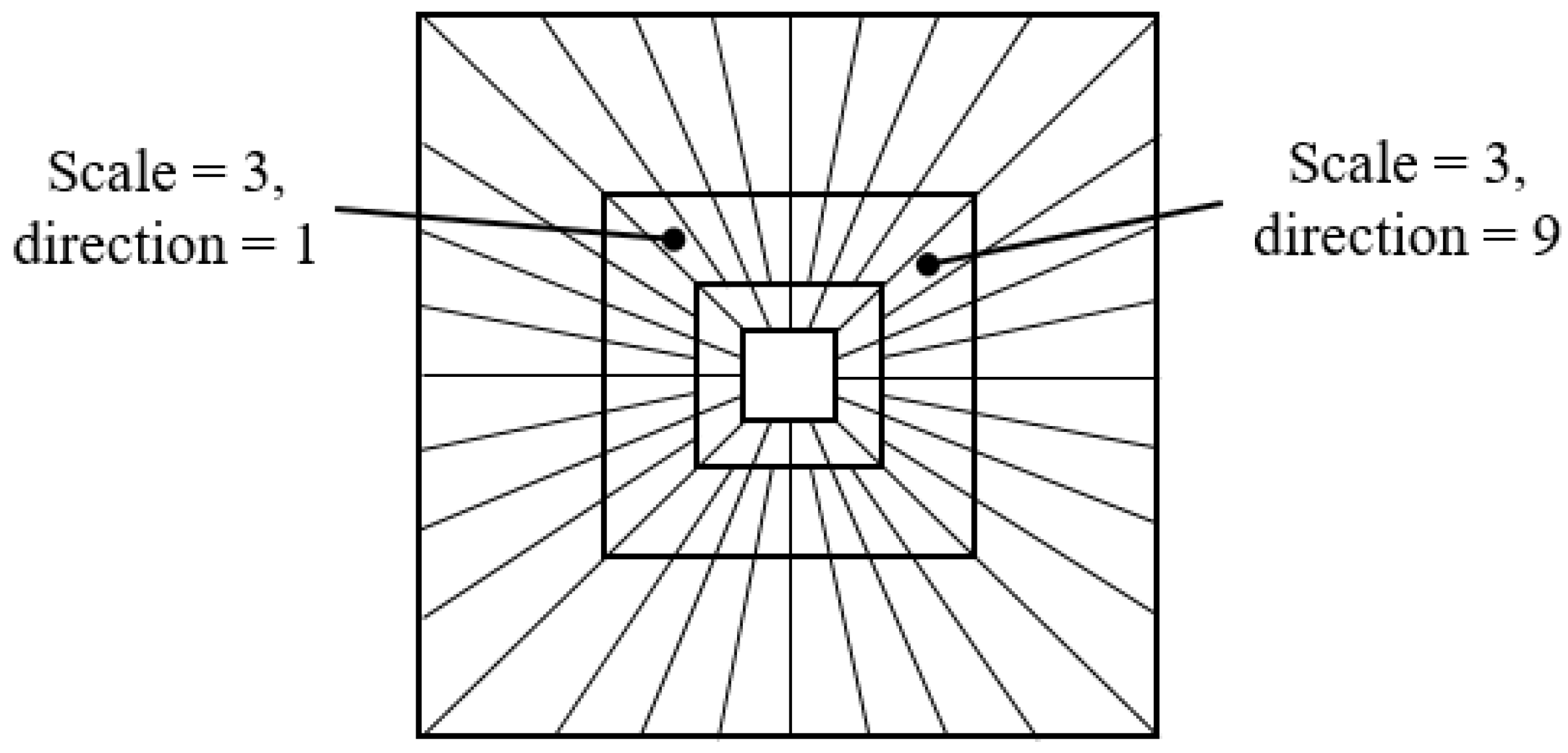
29]. In the image, the frequency domains are decomposed into various scales and directions by the curvelet transform as shown in
Figure 6, and the curvelet coefficients are expressed as
, where
s means scale and
l means direction.
i and
j represent the horizontal and vertical coordinates of the coefficients in each scale and direction, respectively.
In this paper, we divide the watermark block into 5 scales and 8 directions in total. The watermark is inserted using the QIM method as in Algorithm 1 on a scale of 3 levels.
| Algorithm 1 QIM-based watermark embedding procedure. |
- 1:
Input: curvelet coefficients over scale s and direction l - 2:
Output: modified curvelet coefficients - 3:
q: quantization step - 4:
b: bit to be inserted - 5:
- 6:
- 7:
if mod[round( = b then - 8:
- 9:
else - 10:
if mod( then - 11:
- 12:
else if mod( then - 13:
- 14:
end if - 15:
end if - 16:
- 17:
|
In Algorithm 1, m and n denote the horizontal and vertical sizes of the curvelet coeffcient, respectively, and i and j denote the horizontal and vertical coordinates of the curvelet coefficient. Q is a quantization operation, q is a quantization step, and b is the bit to be inserted. This algorithm is the same as in other QIM techniques and is designed to find the nearest quantization level corresponding to the bit to be inserted.
Because the curvelet coefficient expresses a curved shape with directionality, it is related to the surrounding coefficients. As a result, when one coefficient is modified, the modification spreads to the surrounding coefficients [
30]. Therefore, when quantization is performed, the entire
should be adjusted by a multiplication operation as,
where
denotes the modified curvelet coefficients.
is adjusted by applying (
8) to all coefficients.
The curvelet has a symmetry property similar to DFT. Therefore, the same modification should be applied in opposite directions. Since scale 3 has a total of 16 directions, a total of 8 bits can be inserted into one block considering the symmetry property. If this process is applied to all watermark blocks, the total bit capacity becomes the number of ‘watermark blocks’ × 8.
The watermark decode proceeds as shown in Algorithm 2.
denotes the curvelet coefficient of the image to be decoded, and
denotes the decoded bit. This process is repeated for all watermark blocks to decode all the bits.
| Algorithm 2 Watermark decoding procedure. |
- 1:
Input: watermarked curvelet coefficients - 2:
Output: decoded bit pattern - 3:
= - 4:
= mod[round(/q),2]
|
4.4. Application Method for Images of Various Sizes
Because the input size is fixed in CNN, all descriptions are based on 512 × 512 images according to the network input size. In the real world, however, there are images of various sizes, so all images must be resized to 512 × 512 to insert and extract the template and watermark. However, if the image is resized for watermark and template insertion, image quality degradation caused by the resizing cannot be avoided.
To avoid image degradation due to resizing, the embedding process is performed as shown in
Figure 7. First, the image is resized to 512 × 512 and a template and watermark are inserted into the resized image to create a stego image. Subtracting the 512 × 512 image before the embedding step will leave only the stego signal, which contains the template and watermark signals. By resizing the stego signal into the original image size and adding it to the original image, the template and watermark can be inserted into the image without image quality degradation.
5. Experimental Results
This section reports the performance of the proposed method in terms of invisibility and robustness. A comparison experiment is also conducted using the method described by Zhang [
4], which uses the same domain and insertion method as the proposed method. Unlike the proposed watermarking method, Zhang’s method transforms the whole image into a curvelet domain to insert a watermark. Whereas Zhang’s method inserts multi-bits by dividing the curvelet directions, the proposed watermarking method inserts multi-bits by dividing the image into spatial blocks.
We also experimented with the proposed template for the new type of DIBR watermarking [
31]. This DIBR watermarking method exploits the DT-CWT domain, which is robust against DIBR attacks and signal distortions, but vulnerable to geometric distortion. By comparing the performance before and after applying the template to the DIBR watermarking method, we show that the proposed template can compensate the vulnerability of the geometric distortion for the new watermarking method.
5.1. Experiment Setting
BOSSBase [
32], Middlebury [
33,
34], and Microsoft Research 3D Video [
35] datasets with 5000 images with resolutions ranging from 512 × 512 to 1800 × 1500 were used for the experiment. A total of 3500 images were used for training, and the remaining 1500 images were used for performance testing. For network learning, 70,000 images were synthesized from the 3500 images with geometric and signal distortions. The geometric distortion used random parameters of 0 to 90-degree rotation, 0.7 to 1.5 times scaling, and 0 to 30% translation. The signal distortion also randomly applied a Gaussian noise of 0 to 200 variance and a JPEG compression factor of 30 to 100 to the geometrically distorted image.
The proposed method was implemented with a tensorflow library [
36] and Python. The network was trained using the adam optimizer [
37], with a learning rate of
, epsilon of
, batch size of 32, and
in (
7) of 0.2. Until convergence occurred, the end-to-end network was trained and convergence typically occurred after 15 epochs. The training took about an hour per epoch using the Nvidia GTX 1080 single GPU.
For fair comparison, all experiments were performed on a gray channel. The bit capacity for Zhang’s method and the proposed watermarking method were set to 256 bits. For the proposed watermarking method, the image was divided by 8 × 8 to create 64 blocks. Among these, 32 blocks were used to insert bit information and the remaining blocks were used for the template. The proposed watermark was inserted on scale 3 in the curvelet domain divided by scale 5 and direction 8. Zhang’s method inserts the watermark on scales 3 and 4 in the curvelet domain divided by scale 5 and direction 128. The quantization step q for the proposed method and Zhang’s method was set to 3.
In the experiment with the DIBR watermarking method [
31], all other parameter values were set to default, and only the block size was adjusted. In the DIBR watermarking method with the template, the image was divided by 8 × 8 to create 64 blocks. Among these, 32 blocks were used to insert bit information and the rest were used for the template. In the method without a template, the image was divided by 5 × 6 to create a total of 30 blocks, and all 30 blocks were inserted with bit information. With this block size adjustment, the bit capacity of the DT-CWT method with a template and the DT-CWT method without a template were set to a similar level.
5.2. Image Quality
Figure 8 shows the original image and the template/watermark-embedded image. As can be seen, the degradation of quality due to the proposed watermark and template insertion is hardly noticeable. We also measured the peak signal-to-noise ratio (PSNR) and structural similarity (SSIM) [
38] for more objective image quality measurements. As can be seen from
Table 1, the ‘proposed template + proposed watermark’ shows a similar image quality to that obtained using Zhang’s method.
The watermarking method using DT-CWT shows a lower visual quality than other methods because the DT-CWT watermarking method greatly modifies the image to have robustness to DIBR. ‘DT-CWT + proposed template’ has a slightly better visual quality than the DT-CWT only method because it uses half the image area as a template, which has relatively lower energy than the DIBR watermark.
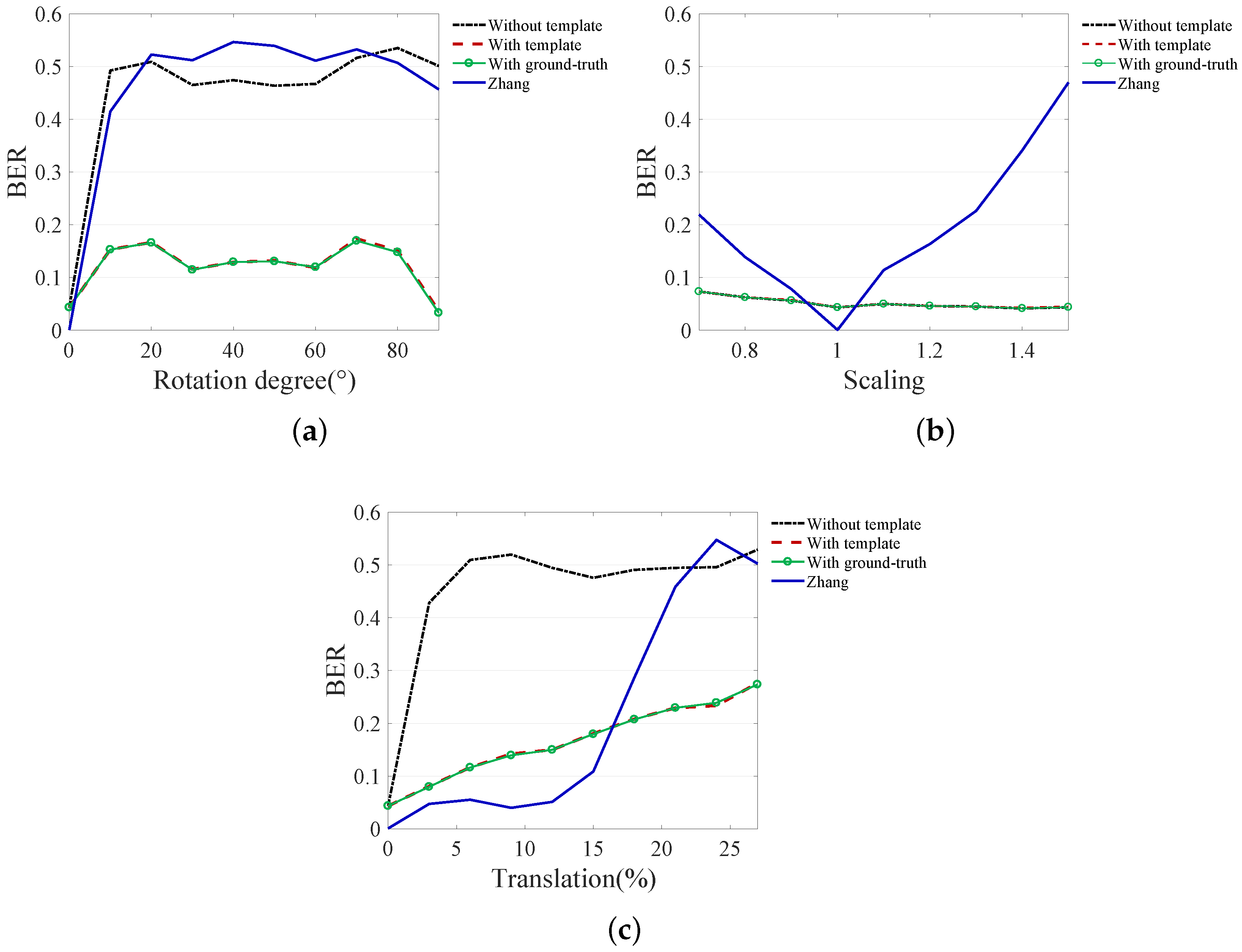
5.3. Robustness Test for RST Attack
Figure 9 shows the robustness test results for rotation, scaling, and translation. The following four methods were tested for robustness: (1) proposed watermarking method without recovery, (2) proposed watermarking method with proposed template recovery, (3) proposed watermarking method with ground-truth recovery and (4) Zhang’s method. The robustness performance was measured based on the bit-error-rate (BER).
Zhang’s method shows good robustness to low-level geometric distortion. This is because the absolute values of curvelet coefficients do not have a large variation in weak geometric distortions. Especially, this method shows low BER for weak scaling and translation. However, it shows a relative weakness in rotation.
The proposed watermarking method without recovery showed lower performance despite using a similar insertion method in the same domain as Zhang’s method. This is because the watermark is inserted with block-units unlike with Zhang’s method. Since block synchronization is broken due to geometric distortion, block-based watermarking is not effective without correction for geometric distortion. On the other hand, low BER is obtained for scaling even without recovery because the proposed watermarking method uses resized images in fixed sizes of 512 × 512 for the watermark insertion/decoding process to fit the image size to the network size.
If an image is recovered using the proposed template, the proposed watermark shows a low error even for strong geometric distortion. This result shows that the robustness is almost identical to the results of recovery with ground-truth, which means that the template almost completely recovers the image from the geometric distortion. The error that occurs even when the image is completely recovered is because the watermark information is cropped together with the image information. Except for the cropped part, the watermark is normally decoded.
5.4. Robustness Test for Simultaneous Attack
To test the robustness of the template for signal distortion, we measured the BER when signal distortion and RST distortion occurred simultaneously. We compared the BER when recovering an image with the proposed template and ground-truth.
Table 2,
Table 3 and
Table 4 show the results of BER when Gaussian noise and RST distortion occur simultaneously. As can be seen from these tables, the larger the noise variance, the greater the error in the method with a template compared to the method with ground-truth. At 200 noise variance, the BER is very high in the method with a template. This is because the noise has corrupted the template as well as the watermark signal, and the image has not been correctly recovered. However, considering that the variance of the inserted template noise is less than 10, the noise variance of 200 is very strong, and in practice, such a large amount of noise barely occurs. In addition, there is little difference between the template-recovered method and the ground-truth-recovered method for scaling. This is because the watermark is inserted/decoded at a fixed image size of 512 × 512 as mentioned above.
5.5. Application of Proposed Template to DIBR Watermarking Method
We tested the robustness of the DIBR watermarking method against RST when the proposed template is applied. The experiment was conducted in three ways: (1) DT-CWT with template recovery, (2) DT-CWT with ground-truth recovery, and (3) Only DT-CWT method. All experiments used the right-view image rendered by DIBR. In other words, we measured the BER of images with DIBR distortion and RST distortion simultaneously. DIBR parameters used in this test were the recommended values in [
39].
As shown in
Figure 10, the DT-CWT-based DIBR watermarking method has a low BER for weak geometric distortions, similar to curvelet watermarking methods. However, as the degree of geometric distortion increases, the BER increases sharply.
On the other hand, if the image is recovered using a template with the DT-CWT method, the watermark can be decoded well after the geometric distortion. The DT-CWT method recovered with a template has a slightly higher BER than that recovered with ground-truth because the template is disturbed by DIBR. However, since the error increase rate is insignificant, the proposed template can be considered robust to the new type of distortion, DIBR. These results show that the proposed template can give robustness against geometric attacks to newly proposed watermarking techniques.
6. Discussion and Conclusions
Conventional template-based watermarking techniques usually use whole image-unit transform rather than block-unit transform. However, the image-unit template has a problem in that the template cannot be inserted independently with the watermark containing copyright information unless they use the same transform domain. Therefore, there is a limitation that the template and watermark signal can interfere with each other. Also, it is difficult to design a multi-bit watermarking system in comparison with the block-unit method. On the other hand, since the proposed template is a block-unit method and can be separated spatially, it does not cause interference with the watermark. Moreover, because it is a learning-based method, it has the advantage of being able to respond quickly to new types of distortion. Due to these advantages, the proposed template can be applied not only to conventional watermarking methods but also to newly proposed watermarking methods for various purposes.
For example, the proposed template can be applied to a new form of watermarks such as the recently proposed depth-image-based rendering (DIBR) watermarking technique. DIBR is a rendering method to give a stereoscopic effect to images [
40,
41], but it cannot be protected by conventional watermarks and templates because it causes horizontal non-linear distortion. To cope with this, various DIBR watermarking techniques have been proposed [
31,
42,
43,
44], but they show weaknesses in geometric distortion since there have been few studies on the topic. The proposed learning-based and block-based template can easily solve the problem of geometric distortion for the DIBR watermark.
However, the proposed template-based watermarking system also has an inherent problem. Instead of acquiring robustness, there is an increase in computational cost for matching the embedded template. For example, compared to the case of applying only the curvelet transform, the watermark detection time increases by about 0.6 s on average when the proposed template is used. In the case of watermark, about 0.6 s of CPU time comes out when decoding a 512 × 512 video (based on Intel 6700 K). The proposed method uses only half of the image area, resulting in around 0.3 s of CPU time. In the case of the template, it takes around 0.25 s of GPU time to decode (based on GTX 1080). This can be a weakness when processing large-scale image data (e.g., web-scale image database) and improvement in template processing time will be needed in future studies. In terms of cost-efficiency, model simplification of the deep neural network [
45,
46] should be helpful to improve the performance.
Recently, Webcomic companies and content providers of IPTV have started actively using these techniques to track and punish illegal distribution. Watermarking techniques and templates based on CNN are still in the early stage for these applications. Further research is needed to improve watermark performance such as masking techniques that will increase invisibility and security enhancement. As the market for real-time content services such as web-comics (also called webtoons) and video streaming services such as YouTube has grown very rapidly, the demands of the watermarking framework have to be not only user friendly but also requires computing efficiency. There are some potential implementation of the proposed method based on the other machine learning techniques including graphical models, and different CNN architectures such as dilated convolution [
47]. Also, we will extend the scope of our research into video content watermarking using CNN.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}