SNS-CF: Siamese Network with Spatially Semantic Correlation Features for Object Tracking



Abstract
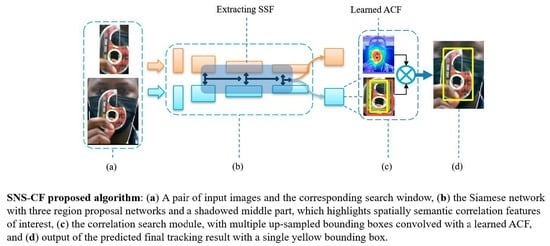
:
1. Introduction
- We extract spatially semantic correlation features (SSF) from the Siamese network.
- We learn adaptive correlation filters (ACF) at every convolutional layer output and calculate their weighted sum in the end.
2. Related Works
2.1. Deep Siamese Tracking
2.2. Correlation Filter Tracking
3. Proposed Method
3.1. Siamese Net
3.2. Region Proposal Network (RPN)
3.3. Extracting SSF
3.4. Convolutional Features
3.5. Correlation Filters
3.6. Learned ACF
4. Implementation Details
5. Experimental Results
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Zhang, Z.; Peng, H. Deeper and wider siamese networks for real-time visual tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 4591–4600. [Google Scholar]
- Li, B.; Wu, W.; Wang, Q.; Zhang, F.; Xing, J.; Yan, J. Siamrpn++: Evolution of siamese visual tracking with very deep networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 4282–4291. [Google Scholar]
- Ma, C.; Huang, J.B.; Yang, X.; Yang, M.H. Hierarchical convolutional features for visual tracking. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3074–3082. [Google Scholar]
- Bertsimas, D.; Dunn, J.; Pawlowski, C.; Zhuo, Y.D. Robust classification. INFORMS J. Optim. 2018, 1, 2–34. [Google Scholar] [CrossRef] [Green Version]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H. Fully-convolutional siamese networks for object tracking. In Proceedings of the European Conference on computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switzerland, 2016; pp. 850–865. [Google Scholar]
- Li, B.; Yan, J.; Wu, W.; Zhu, Z.; Hu, X. High performance visual tracking with siamese region proposal network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8971–8980. [Google Scholar]
- Thierry, N.; Park, H.; Kim, Y.; Paik, J. SSReF-Spatial_Semantic Residual Features for Object Tracking. Inst. Electron. Inf. Eng. 2019, 11, 651–654. [Google Scholar]
- Wang, Q.; Zhang, L.; Bertinetto, L.; Hu, W.; Torr, P.H. Fast online object tracking and segmentation: A unifying approach. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 1328–1338. [Google Scholar]
- Moudgil, A.; Gandhi, V. Long-term visual object tracking benchmark. In Proceedings of the Asian Conference on Computer Vision, Perth, Australia, 2–6 December 2018; Springer: Cham, Switzerland, 2018; pp. 629–645. [Google Scholar]
- Wu, Y.; Lim, J.; Yang, M.H. Object tracking benchmark. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1834–1848. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gray, R.M. Toeplitz and Circulant Matrices: A Review; Now Publishers Inc.: Hanover, MA, USA, 2006. [Google Scholar]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. High-speed tracking with kernelized correlation filters. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 583–596. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Gundogdu, E.; Alatan, A. Good features to correlate for visual tracking. IEEE Trans. Image Process. 2018, 27, 2526–2540. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shen, J.; Tang, X.; Dong, X.; Shao, L. Visual object tracking by hierarchical attention siamese network. IEEE Trans. Cybern. 2019, 50, 3068–3080. [Google Scholar] [CrossRef] [PubMed]
- Hariharan, B.; Arbeláez, P.; Girshick, R.; Malik, J. Hypercolumns for object segmentation and fine-grained localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 447–456. [Google Scholar]
- Danelljan, M.; Bhat, G.; Shahbaz Khan, F.; Felsberg, M. Eco: Efficient convolution operators for tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6638–6646. [Google Scholar]
- Li, F.; Tian, C.; Zuo, W.; Zhang, L.; Yang, M.H. Learning spatial-temporal regularized correlation filters for visual tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4904–4913. [Google Scholar]
- Van Rossum, G.; Drake, F.L. Python 3 Reference Manual; PythonLabs: Scotts Valley, CA, USA, 2009. [Google Scholar]
- MATLAB. version 9.8.0.1417392 (R2020a) Update 4; MATLAB: Natick, MA, USA, 2020. [Google Scholar]
- Fan, H.; Lin, L.; Yang, F.; Chu, P.; Deng, G.; Yu, S.; Bai, H.; Xu, Y.; Liao, C.; Ling, H. Lasot: A high-quality benchmark for large-scale single object tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 5374–5383. [Google Scholar]
- Moore, G.; Noyuce, R.O.; (Intel Corporation, Santa Clara, CA, USA). Personal communication, 1968.
- Huang, J.; Priem, C.; Malachowsky, C.; (NVIDIA, Santa Clara, CA, USA). Personal communication, 1993.
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Xu, N.; Yang, L.; Fan, Y.; Yang, J.; Yue, D.; Liang, Y.; Price, B.; Cohen, S.; Huang, T. Youtube-vos: Sequence-to- sequence video object segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 585–601. [Google Scholar]
- Zou, W.; Zhu, S.; Yu, K.; Ng, A.Y. Deep learning of invariant features via simulated fixations in video. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, Harrahs and Harveys, NV, USA, 3–8 December 2012; pp. 3202–3211. [Google Scholar]
- Zhang, K.; Zhang, L.; Liu, Q.; Zhang, D.; Yang, M.H. Fast visual tracking via dense spatio-temporal context learning. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 127–141. [Google Scholar]
- Hare, S.; Golodetz, S.; Saffari, A.; Vineet, V.; Cheng, M.M.; Hicks, S.L.; Torr, P.H. Struck: Structured output tracking with kernels. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 2096–2109. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhong, W.; Lu, H.; Yang, M.H. Robust object tracking via sparse collaborative appearance model. IEEE Trans. Image Process. 2014, 23, 2356–2368. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, K.; Zhang, L.; Yang, M.H. Fast compressive tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 2002–2015. [Google Scholar] [CrossRef] [PubMed]
- Babenko, B.; Yang, M.H.; Belongie, S. Robust object tracking with online multiple instance learning. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 1619–1632. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kalal, Z.; Mikolajczyk, K.; Matas, J. Tracking-learning-detection. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 1409–1422. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. Exploiting the circulant structure of tracking-by-detection with kernels. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 702–715. [Google Scholar]
- Sauer, A.; Aljalbout, E.; Haddadin, S. Tracking Holistic Object Representations. arXiv 2019, arXiv:1907.12920. [Google Scholar]
- Sun, C.; Wang, D.; Lu, H.; Yang, M.H. Learning spatial-aware regressions for visual tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8962–8970. [Google Scholar]
- Zhu, Z.; Wang, Q.; Li, B.; Wu, W.; Yan, J.; Hu, W. Distractor-aware siamese networks for visual object tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 101–117. [Google Scholar]
- Xu, T.; Feng, Z.H.; Wu, X.J.; Kittler, J. Learning adaptive discriminative correlation filters via temporal consistency preserving spatial feature selection for robust visual object tracking. IEEE Trans. Image Process. 2019, 28, 5596–5609. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bai, S.; He, Z.; Dong, Y.; Bai, H. Multi-hierarchical independent correlation filters for visual tracking. In Proceedings of the 2020 IEEE International Conference on Multimedia and Expo (ICME), London, UK, 6–10 July 2020; pp. 1–6. [Google Scholar]
- Bhat, G.; Johnander, J.; Danelljan, M.; Shahbaz Khan, F.; Felsberg, M. Unveiling the power of deep tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 483–498. [Google Scholar]
- He, A.; Luo, C.; Tian, X.; Zeng, W. A twofold siamese network for real-time object tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 4834–4843. [Google Scholar]
- Sun, C.; Wang, D.; Lu, H.; Yang, M.H. Correlation tracking via joint discrimination and reliability learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 489–497. [Google Scholar]
- Nam, H.; Han, B. Learning multi-domain convolutional neural networks for visual tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4293–4302. [Google Scholar]
- Song, Y.; Ma, C.; Wu, X.; Gong, L.; Bao, L.; Zuo, W.; Shen, C.; Lau, R.W.; Yang, M.H. Vital: Visual tracking via adversarial learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8990–8999. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metrics | Ours (SNS-CF) | CF2 [3] | KCF [12] | Struck [29] | DLT [27] | STC [28] | TLD [33] | MIL [32] | CT [31] |
|---|---|---|---|---|---|---|---|---|---|
| DP rate ↑ (%) | 84.0 | 83.7 | 69.2 | 63.5 | 52.6 | 50.7 | 59.2 | 43.9 | 35.9 |
| OS rate ↑ | 65.7 | 65.5 | 54.8 | 51.6 | 43.0 | 31.4 | 49.7 | 33.1 | 27.8 |
| CLE ↓ (pixel) | 20.2 | 22.8 | 45.0 | 47.1 | 66.5 | 86.2 | 60.0 | 72.1 | 80.1 |
| Speed ↑ (FPS) | 35.1 | 10.4 | 243 | 9.84 | 8.43 | 653 | 23.3 | 28.0 | 44.4 |
| Metrics | Ours (SNS-CF) | SiamRPN++ [2] | LADCF [38] | MFT [39] | SiamRPN [6] | UPDT [40] | SA_Siam_R [41] | DRT [42] |
|---|---|---|---|---|---|---|---|---|
| EAO ↑ | 0.423 | 0.414 | 0.389 | 0.385 | 0.383 | 0.378 | 0.337 | 0.356 |
| Accuracy ↑ | 0.587 | 0.600 | 0.503 | 0.505 | 0.586 | 0.536 | 0.566 | 0.519 |
| Robustness ↓ | 0.223 | 0.234 | 0.159 | 0.140 | 0.276 | 0.184 | 0.258 | 0.201 |
| AO ↑ | 0.487 | 0.498 | 0.421 | 0.393 | 0.472 | 0.454 | 0.429 | 0.426 |
| Metrics | Ours (SNS-CF) | Correlation Filter [3] (Baseline) | Siamese Network [2] (Baseline) | Both (Without SSF and ACF) |
|---|---|---|---|---|
| DP rate ↑ (%) | 84.0 | 83.7 | - | 83.3 |
| OS rate ↑ (%) | 65.7 | 65.5 | - | 65.0 |
| CLE ↓ (pixel) | 20.2 | 22.8 | - | 21.3 |
| EAO ↑ | 0.423 | - | 0.414 | 0.420 |
| Accuracy ↑ | 0.587 | - | 6.00 | 0.557 |
| Robustness ↓ | 0.223 | - | 0.234 | 0.228 |
| Speed ↑ (FPS) | 35.1 | 10.4 | - | 34.2 |
| AO ↑ | 0.487 | - | 0.489 | 0.393 |
| Scenarios | Ours (SNS-CF) | Correlation Filter [3] (Baseline) | Siamese Network [2] (Baseline) |
|---|---|---|---|
| Background clutter | 0.228 | 0.225 | 0.230 |
| Intra-class variations | 0.198 | 0.302 | 0.227 |
| Occlusions | 0.312 | 0.226 | 0.232 |
| Illumination variations | 0.154 | 0.159 | 0.247 |
| Average Robustness ↓ | 0.223 | 0.228 | 0.234 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ntwari, T.; Park, H.; Shin, J.; Paik, J. SNS-CF: Siamese Network with Spatially Semantic Correlation Features for Object Tracking. Sensors 2020, 20, 4881. https://doi.org/10.3390/s20174881
Ntwari T, Park H, Shin J, Paik J. SNS-CF: Siamese Network with Spatially Semantic Correlation Features for Object Tracking. Sensors. 2020; 20(17):4881. https://doi.org/10.3390/s20174881
Chicago/Turabian StyleNtwari, Thierry, Hasil Park, Joongchol Shin, and Joonki Paik. 2020. "SNS-CF: Siamese Network with Spatially Semantic Correlation Features for Object Tracking" Sensors 20, no. 17: 4881. https://doi.org/10.3390/s20174881