Indoor Positioning System Based on Fuzzy Logic and WLAN Infrastructure †

 , , and
, , and
Abstract
:1. Introduction
2. Localization in a WLAN Environment
2.1. Localization in the Environment of Buildings
- zone-level localization—the zone where a user is located and is identified; the zone can be defined as a room, more rooms, or part of a building, for example:
- room-level localization—the room where the user is located and identified;
- partial room-level localization—for large rooms, it is possible to determine, for example, the part where a user is located;
- localization on the basis of passage—the position of the user is determined as he/she passes through a control gate, which can be equipped by, e.g., doors with sensors;
- localization in reference to a point—the output of the localization is the position of a user in reference to a known point;
- precise localization—the position of the user is given by precise coordinates in a given area.
2.1.1. Localization Methods
- Time of Arrival (TOA) is a method that evaluates signal propagation times between a transmitter and a receiver. The time is calculated from a fixed time “0” (identical for both devices). Therefore, it is necessary to precisely synchronize the devices, i.e., the network element (Access Point, AP) and the localized device (smartphone, Wi-Fi adapter, etc.) A major disadvantage is the sensitivity to different times of signal propagation. Especially in the indoor areas of buildings, signal propagation is affected by obstacles. This causes the multipath propagation phenomenon, i.e., the signal can be received from different directions with different levels, but also with different delays. This method is therefore suitable for the outdoor environment where the signal does not interfere with so many objects. The position calculation itself is done with the help of the trilateration algorithm.
- Time Difference of Arrival (TDOA) is based on a similar principle; however, it is not necessary to synchronize the localization devices. The device to be localized sends information, which is received by all access points. The position of the device is calculated from the different times of message arrival to the respective APs and their known position. This method is also very sensitive to signal propagation time. The trilateration algorithm is used here as well.
- Angle of Arrival (AOA) is a method based on measuring the angle at which a signal is received with respect to a reference point. This method is barely usable for indoor localization, because the signal propagates in multiple directions. Therefore, the stability of direction from which the signal arrives cannot be guaranteed. The triangulation algorithm is used to calculate the position.
- Received Signal Strength Indicator (RSSI) is a method based on measuring the signal level at a given point in a building. Due to the fact that the signal level and distance change both naturally and due to the effects of the environment, the outputs of such measurements are the RSSI characteristics of the entire environment. This characteristic is different for each AP. The characteristic from the training phase can be compared with a specific measurement in the localization phase. There are more algorithms for the calculation of positions for this method. It can be the method of the nearest neighbor, an improved variant of the nearest neighbor (kNN). Neural networks, genetic algorithms, data clustering methods, and other algorithms, which can compare two different types of measurement methods and find possible similarities, may be used.
2.1.2. Fingerprinting Method
2.2. Related Work
2.3. Summary of IPS
3. Problems to Solve
3.1. The Variety of Wi-Fi Adapters
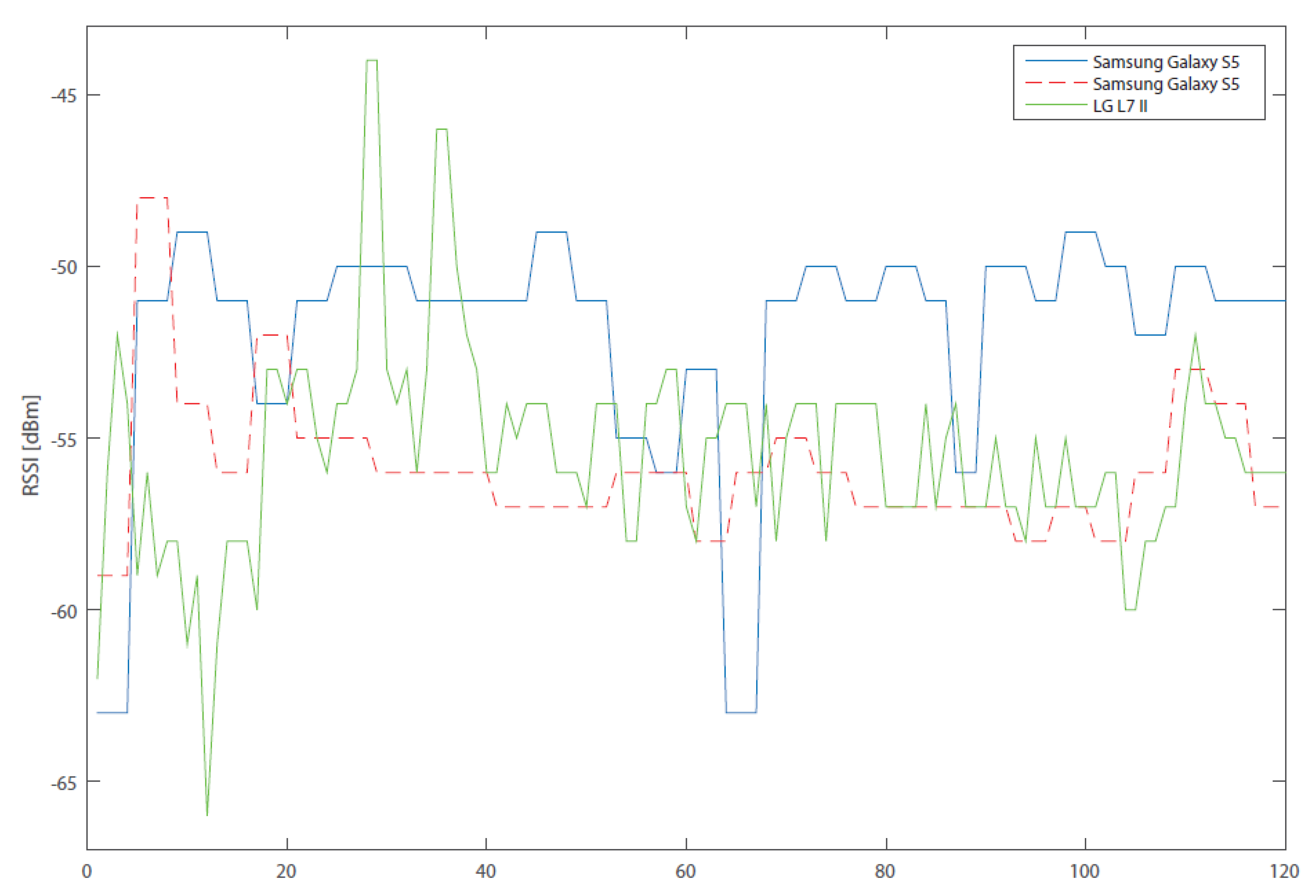
3.2. Signal Fluctuation
4. Fuzzy System Design
4.1. Training Set
4.2. Generating If–then Rules
- The first step is the creation of the training data set.
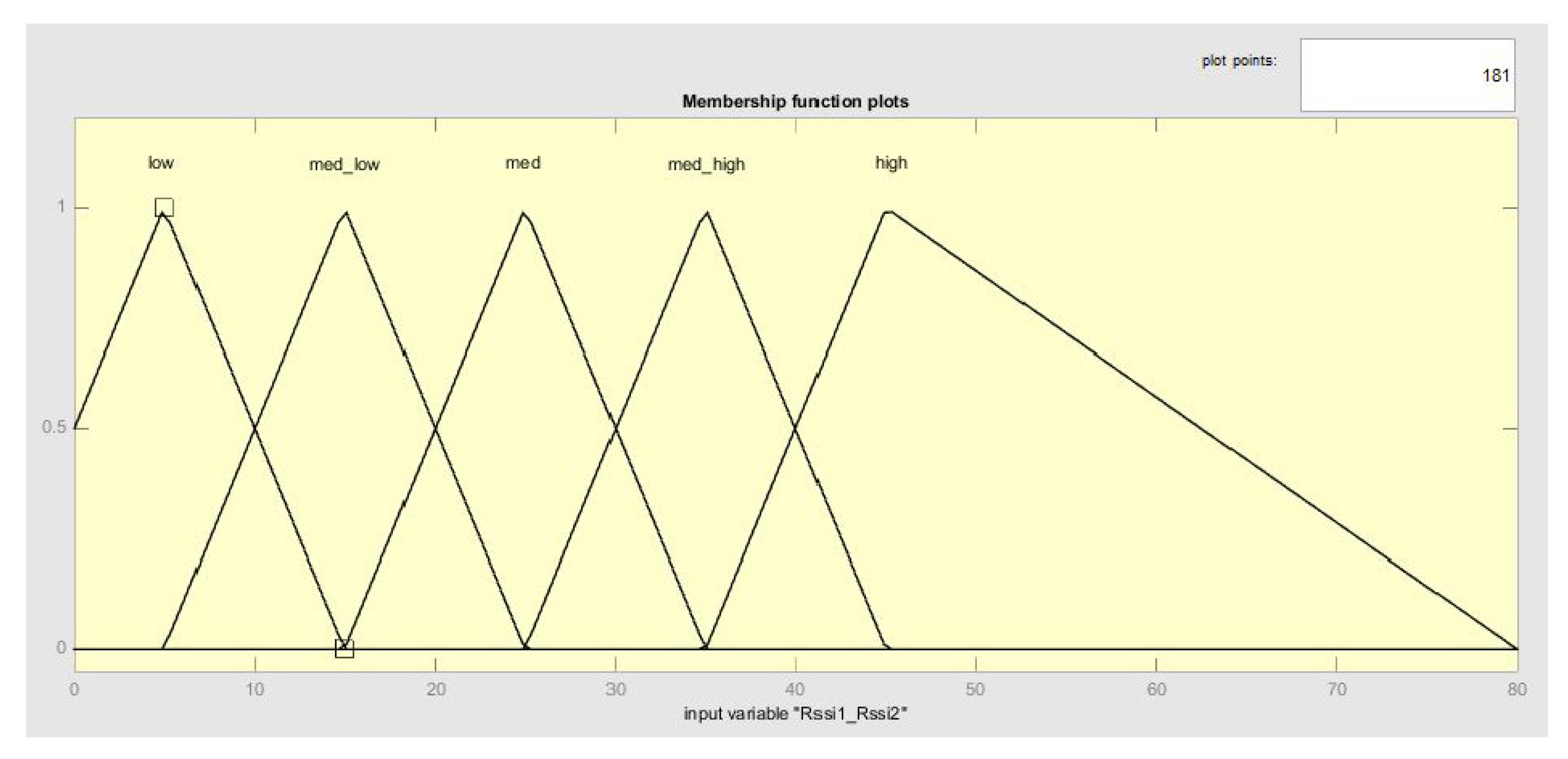
- As all inputs and outputs are known, it is necessary to define their fuzzy sets.
- Next, it is necessary to create a set of possible rules which can become active rules. In practice, this means that a rule is created inside each record of a training data set according to a general formula in the form of an equation, for example. Here, it is important to note that the value of each input variable is always fuzzified into the respective language of expression according to the proposed membership functions (fuzzy sets).if ∆Rss1_Rssi2 is low AND … AND ∆Rss5_Rssi6 is high then zone is zone1,
- Duplicate rules are then removed from the created rule database.
- Then the so-called degree of importance is calculated for all rules. This is the transformation of the individual degrees of membership (e.g., µ∆Rss1_Rssi2 · µ∆Rss1_Rssi2 …) from the step of fuzzification into linguistic expressions. This classifies the rules in the sense that the higher the degree of importance, the better the rule is from the system point of view.
- In the last step, the generated rules are grouped according to the same conditional part of the rule. On the basis of the degree of importance, the rule with the highest value of this degree is chosen from each group. Other rules from the group are removed from the database. This step is important for the elimination of an erroneous derivation of the results, as the fuzzy system would not be able to derive a result from two identical conditions.
4.3. If–then Rule Optimization
- Steps 1–4 are identical to the previous ones.
- In the last step, groups are again generated according to identical condition parts. Every group contains several possible results for a given condition. The purpose of the SA algorithm is again the minimization with the help of the Mean Square Error (MSE) function according to relation (8). Now, however, there are not any specific membership function changes, but changes in the parameters of database functions. This means that a database of rules is created according to a number of groups, where each group is defined by a relevant condition. The results (which in this case are the parameters) of the rules, however, change according to what possible results for a given condition in the group are available. The SA algorithm, therefore, looks for such a combination of results for which the MSE function is minimized. After finding the best combination of results and the best database rules, the other unused results are removed.
4.4. Optimization of Fuzzy Sets
5. Proposed Localization System
5.1. System Functionality
- The creation of a mobile application FuzzyLoc Admin for the system administrator, which will be able to train a data set, as well as register the users and access points to the system.
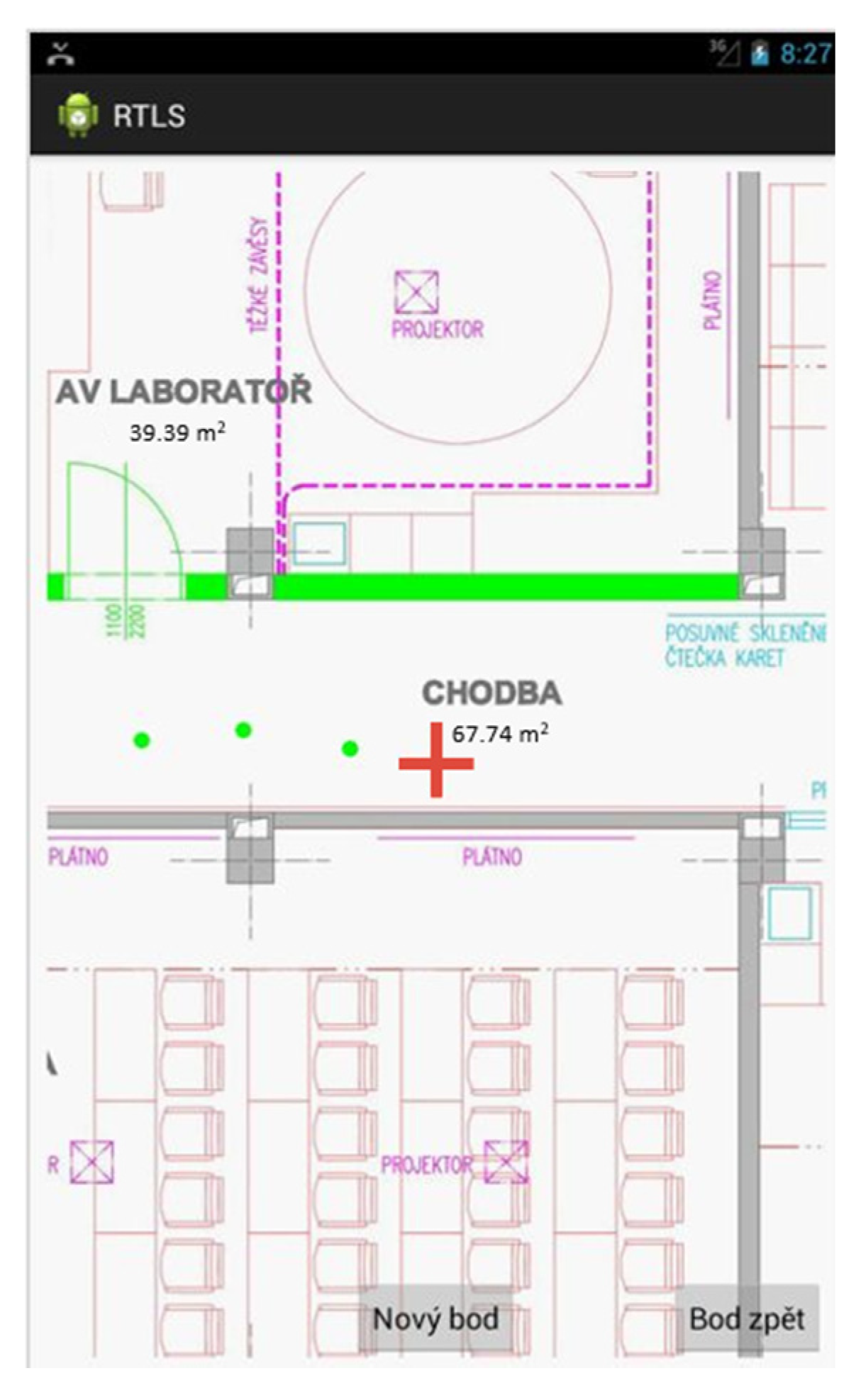
- The creation of a mobile application FuzzyLoc Client, which will scan the surrounding RSSIs; it will be able determine its position (zone) and then send the result to the server on the basis of the downloaded definition of the fuzzy derivation system.
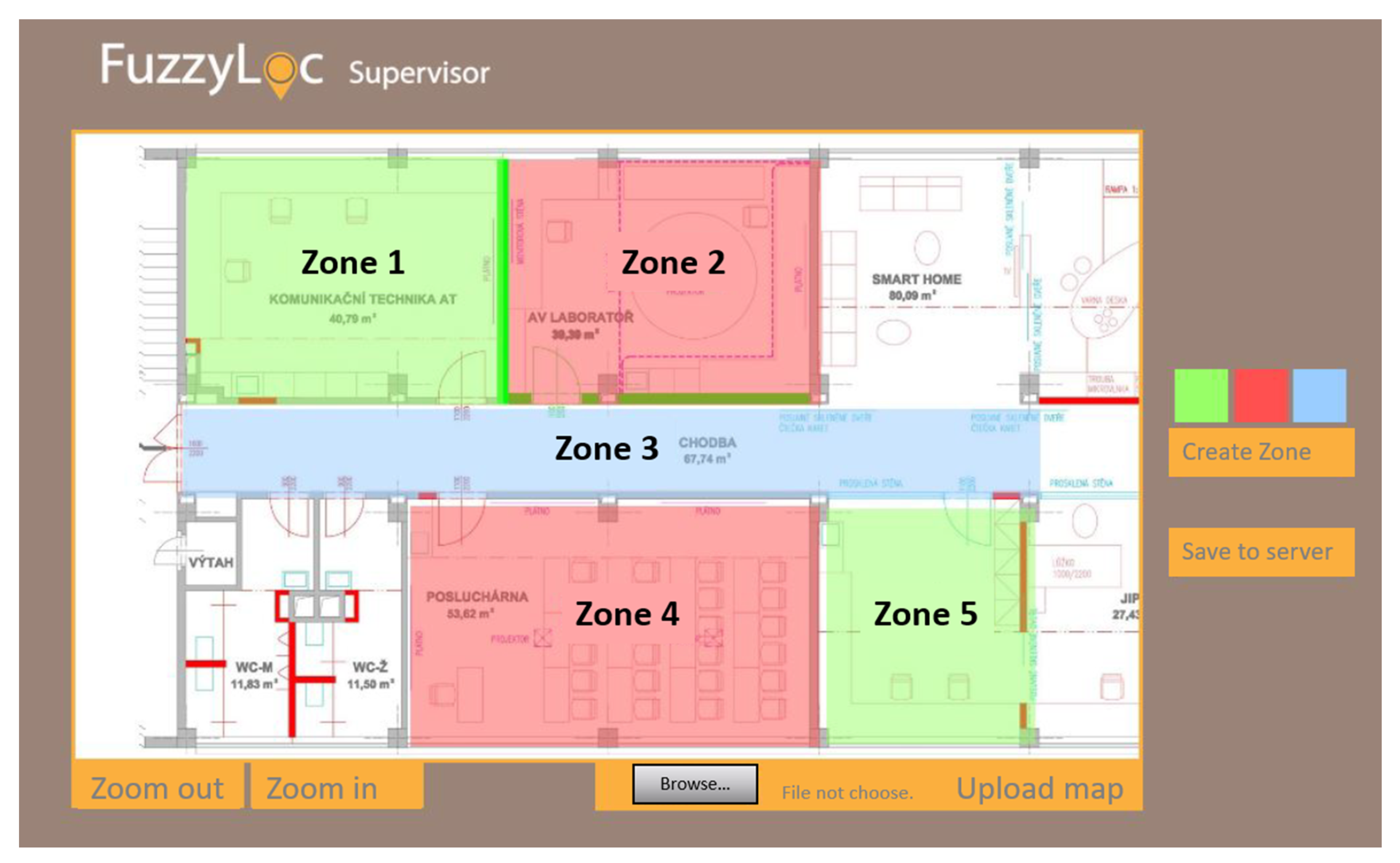
- The creation of a simple web interface FuzzyLoc Supervisor meant for displaying the results of localization and zone definitions, according to which it will identify the resulting zone.
- The creation of the web server FuzzyLoc Server, which will be able to communicate with the abovementioned elements; it will contain a MySQL database for storing all necessary data; its deployment in the production environment will be simple.
- The creation of the program FuzzyLoc Engine for generating definitions, according to which each device will be localized.
- The system configuration starts with step 1; a map of the area, where localization will take place, is uploaded through a web interface. The map is uploaded directly onto the server; it is accessible to all devices that will access the surveillance web environment. The maximum allowed map size is 8 MB.
- The next step is the creation of zones on the basis of the uploaded map. The individual zones are created by defining two corners (upper left and bottom right) of the zone; it is only possible to create zones in the shape of a rectangle. Each zone must be given a unique name according to the needs of the administrator. These zone parameters are then saved on the server.
- The created zone definitions are then downloaded to FuzzyLoc Admin; on their basis, the training data set is created. Of course, measurements must be done in such a way that the correct zone is chosen from the list, the one where the training data are currently being measured. The data file is then uploaded to the server.
- The administrator then has to register users (to be localized) and access points (to be used in the localization process —at least six of them) from the mobile application.
- The administrator then initiates the prepared script/home/user/FuzzyLocEngine/generateFis.sh and, depending on the amount of data, it creates the file fis.fcl.
- Then the administrator must generate certificates for individual devices to be localized. This step is currently not available due to an error in a specific library in Android OS, so it is temporarily necessary to install only the root certificate FuzzyLoc CA into the client’s device or to utilize one’s own certification resources. The root certificate also needs to be installed onto the PC from which the FuzzyLoc Supervisor will be accessed.
- Now the localization of the device may start. When a user runs FuzzyLoc for the first time, he/she is prompted to consent to the downloading of fis.fcl from the server. The application will also ask for the SSID and IP server. The user will then only run the localization of the device and the application will switch to background mode. It will send the localization results to the server.
- The final step is to enter the URL of the https://IP-server on the PC with the root certificate installed. After signing in, the monitoring environment is displayed.
5.2. Key System Components
5.2.1. FuzzyLoc Server
5.2.2. FuzzyLoc Client
5.2.3. FuzzyLoc Admin
5.2.4. FuzzyLoc Supervisor
6. Methodology and Performed Testing
6.1. The First Test Environment
6.2. The Second Test Environment
6.3. Results and Discussion
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Hrad, J.; Vojtech, L.; Cihlar, M.; Stasa, P.; Neruda, M.; Svub, J.; Benes, F. Fuzzy Logic Based Indoor Localization Using WLAN Infrastructure. In Proceedings of the IEEE Eurasia Conference on Biomedical Engineering, Healthcare and Sustainability (ECBIOS), Tainan, Taiwan, 29–31 May 2020. [Google Scholar]
- Konecny, J.; Urbanczyk, T.; Benes, F.; Stasa, P. Framework AutoId Healthcare; Centre for Applied Cybernetics: Ostrava, Czech Republic, 2019. [Google Scholar]
- Malik, A. RTLS for Dummies, 1st ed.; Wiley & Sons: New York, NY, USA, 2009. [Google Scholar]
- Montaser, A.; Moselhi, O. RFID indoor location identification for construction projects. Autom. Constr. 2014, 39, 167–179. [Google Scholar] [CrossRef]
- Gu, Y.; Lo, A.; Niemegeers, I. A survey of indoor positioning systems for wireless personal networks. IEEE Commun. Surv. Tutor. 2009, 11, 13–32. [Google Scholar] [CrossRef] [Green Version]
- Ding, G.; Zhang, J.; Zhang, L.; Tan, Z. Overview of Received Signal Strength Based Fingerprinting Localization in Indoor Wireless LAN Environments. In Proceedings of the 5th IEEE International Symposium on Microwave, Antenna, Propagation and EMC Technologies for Wireless Communications (MAPE), Chengdu, China, 29–31 October 2013; pp. 160–164. [Google Scholar] [CrossRef]
- Chen, Y.; Crespi, N.; Lv, L.; Li, M.; Ortiz, A.M.; Shu, L. Locating using prior information: Wireless indoor localization algorithm. Comput. Commun. Rev. 2013, 43, 463–464. [Google Scholar] [CrossRef]
- Wu, C.; Yang, Z.; Liu, Y.; Xi, W. WILL: Wireless Indoor Localization without Site Survey. In Proceedings of the IEEE International Conference on Computer Communications (INFOCOM), Orlando, FL, USA, 25–30 March 2012; pp. 64–72. [Google Scholar] [CrossRef] [Green Version]
- Yang, S.; Dessai, P.; Verma, M.; Gerla, M. FreeLoc: Calibration-Free Crowdsourced Indoor Localization. In Proceedings of the IEEE International Conference on Computer Communications (INFOCOM), Turin, Italy, 14–19 April 2013; pp. 2481–2489. [Google Scholar] [CrossRef]
- Farshad, A.; Li, J.; Marina, M.K.; Garcia, F.J. A Microscopic Look at Wi-Fi Fingerprinting for Indoor Mobile Phone Localization in Diverse Environments. In Proceedings of the 2013 International Conference on Indoor Positioning and Indoor Navigation (IPIN), Montbeliard-Belfort, France, 28–31 October 2013. [Google Scholar] [CrossRef]
- Torres-Sospedra, J.; Jiménez, A.R.; Moreira, A.; Lungenstrass, T.; Lu, W.-C.; Knauth, S.; Mendoza-Silva, G.M.; Seco, F.; Pérez-Navarro, A.; Nicolau, M.J.; et al. Off-Line Evaluation of Mobile-Centric Indoor Positioning Systems: The Experiences from the 2017 IPIN Competition. Sensors 2018, 18, 487. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ferreira, A.G.; Fernandes, D.; Catarino, A.P.; Monteiro, J. Performance Analysis of ToA-Based Positioning Algorithms for Static and Dynamic Targets with Low Ranging Measurements. Sensors 2017, 17, 1915. [Google Scholar] [CrossRef] [PubMed]
- Honkavirta, V.; Perälä, T.; Ali-Löytty, S.; Piché, R.A. Comparative Survey of WLAN Location Fingerprinting Methods. In Proceedings of the 6th Workshop on Positioning, Navigation and Communication (WPNC), Hannover, Germany, 19 March 2009; pp. 243–251. [Google Scholar] [CrossRef] [Green Version]
- Han, D.; Jung, S.; Lee, M.; Yoon, G. Building a Practical Wi-Fi-Based Indoor Navigation System. IEEE Pervasive Comput. 2014, 13, 72–79. [Google Scholar] [CrossRef]
- Ferreira, A.G.; Fernandes, D.; Catarino, A.; Rocha, A.M.; Monteiro, J.L. A Loose-Coupled Fusion of Inertial and UWB Assisted by a Decision-Making Algorithm for Localization of Emergency Responders. Electronics 2019, 8, 1463. [Google Scholar] [CrossRef] [Green Version]
- Niu, J.; Gu, Y.; Lu, B.; Cheng, L.; Jun, J.H. Wi-Fi Fingerprint Localization in Open Space. Lang. Cognit. Neurosci. 2013, 2013, 1–4. [Google Scholar]
- He, S.; Chan, S.-H.G. Wi-Fi fingerprint-based indoor positioning: Recent advances and comparisons. IEEE Commun. Surv. Tutor. 2015, 18, 466–490. [Google Scholar] [CrossRef]
- Fuchs, C.; Aschenbruck, N.; Martini, P.; Wieneke, M. Indoor tracking for mission critical scenarios: A survey. Pervasive Mob. Comput. 2011, 7, 1–15. [Google Scholar] [CrossRef]
- Fischer, C.; Gellersen, H. Location and Navigation Support for Emergency Responders: A Survey. IEEE Pervasive Comput. 2009, 9, 38–47. [Google Scholar] [CrossRef] [Green Version]
- Ferreira, A.G.; Fernandes, D.; Catarino, A.; Monteiro, J. Localization and Positioning Systems for Emergency Responders: A Survey. IEEE Commun. Surv. Tutor. 2017, 19, 2836–2870. [Google Scholar] [CrossRef]
- Cihlář, M. Analýza Pokrytí Zadaného území Signálem pro Technologii RTLS v pásmu 2,45 GHz. Bachelor’s Thesis, Czech Technical University, Prague, Czech Republic, 2014. [Google Scholar]
- Hossain, A.K.M.; Jin, Y.; Soh, W.-S.; Van, H.N. SSD: A Robust RF Location Fingerprint Addressing Mobile Devices’ Heterogeneity. IEEE Trans. Mob. Comput. 2011, 12, 65–77. [Google Scholar] [CrossRef]
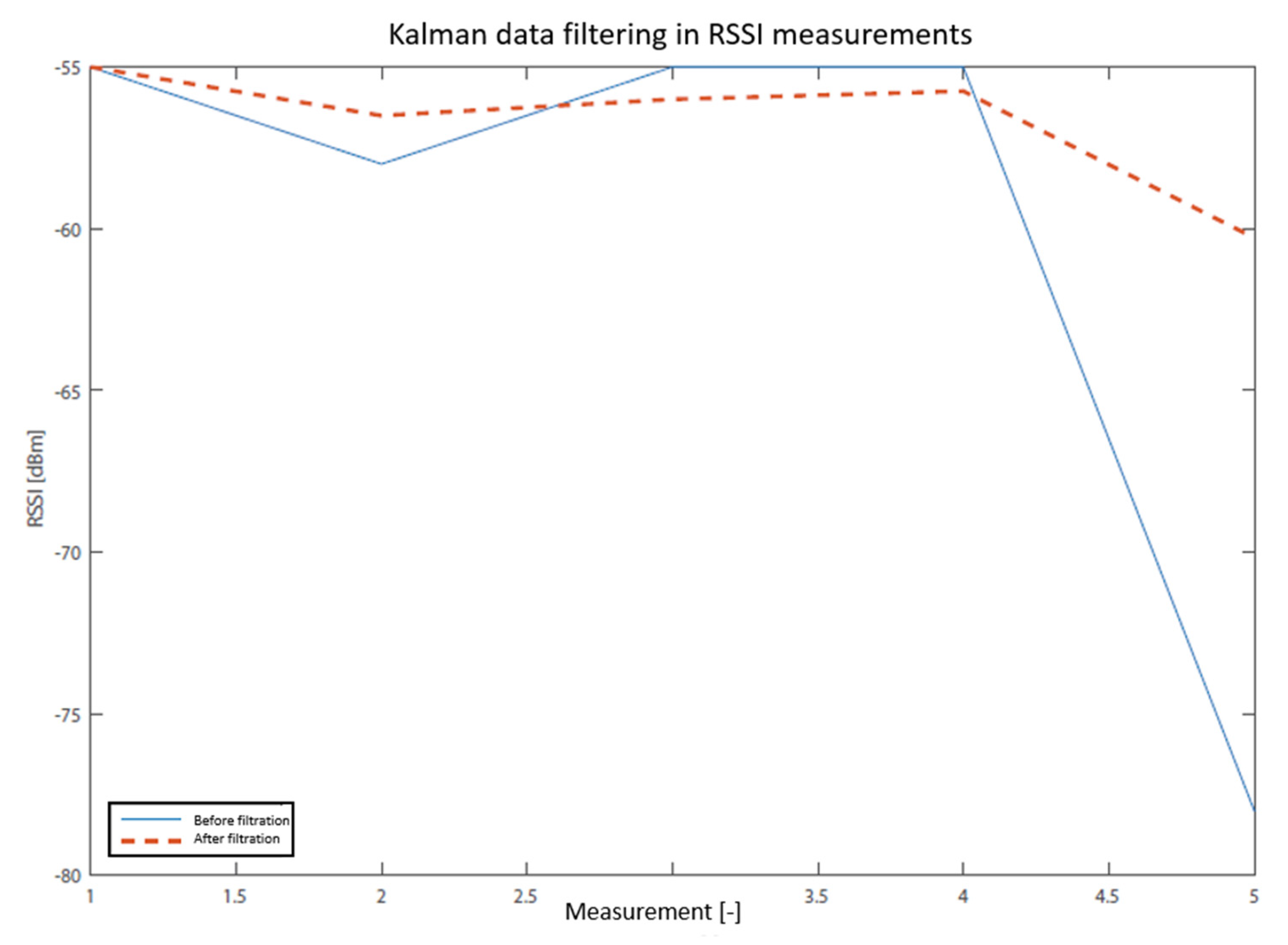
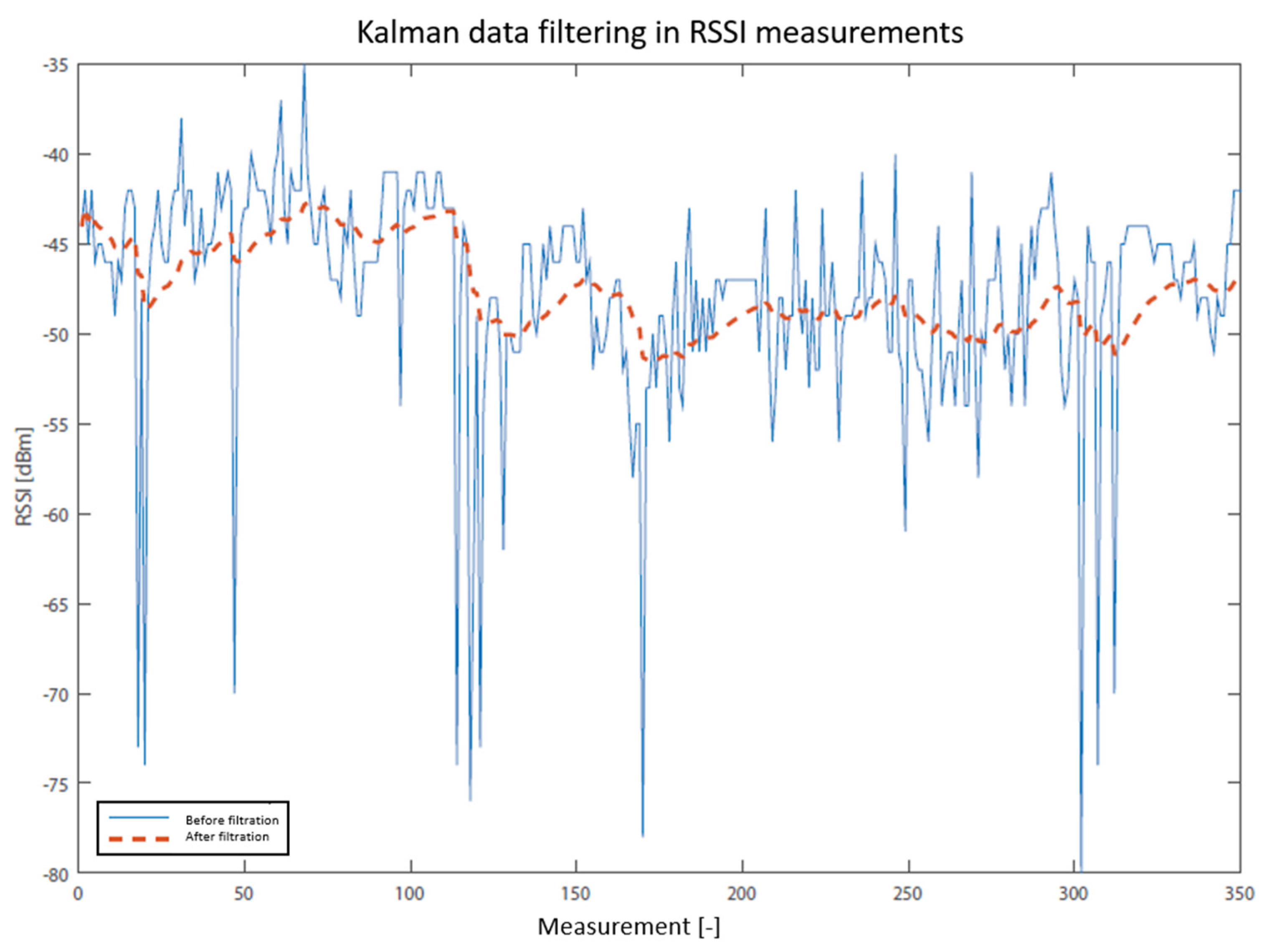
- Welch, G.; Bishop, G. An Introduction to the Kalman Filter; University of North Carolina: Chapel Hill, NC, USA, 1995. [Google Scholar]
- Wang, L.-X.; Mendel, J.M. Generating fuzzy rules by learning from examples. IEEE Trans. Syst. Man Cybern. 1992, 22, 1414–1427. [Google Scholar] [CrossRef] [Green Version]
- Casillas, J.; Cordón, O.; Herrera, F. COR: A methodology to improve ad hoc data-driven linguistic rule learning methods by inducing cooperation among rules. IEEE Trans. Syst. Man Cybern. Part B 2002, 32, 526–537. [Google Scholar] [CrossRef] [PubMed]
- Yanar, T.A.; Akyürek, Z. Fuzzy model tuning using simulated annealing. Expert Syst. Appl. 2011, 38, 8159–8169. [Google Scholar] [CrossRef]
- Liu, G.; Yang, W. Learning and Tuning of Fuzzy Membership Functions by Simulated Annealing Algorithm. In Proceedings of the IEEE Asia-Pacific Conference on Circuits and Systems: Electronic Communication Systems, Tianjin, China, 4–6 December 2000; pp. 367–370. [Google Scholar]
- Černý, V. Thermodynamical approach to the traveling salesman problem: An efficient simulation algorithm. J. Optim. Theory Appl. 1985, 45, 41–51. [Google Scholar] [CrossRef]
- Kirkpatrick, S.; Gelatt, C.D., Jr.; Vecchi, M.P. Optimization by Simulated Annealing. Science 1983, 220, 671–680. [Google Scholar] [CrossRef] [PubMed]
- Jorgensen, W.L. Perspective on Equation of state calculations by fast computing machines. Theor. Chem. Acc. 2000, 103, 225–227. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Technology | Network Throughput | Frequency Band | Range | Security |
|---|---|---|---|---|
| Bluetooth | 2 Mbps | 2.4 GHz | 800 m | 255bit AES |
| RFID (NFC) | 106–424 kbps | 13.56 MHz | 20 cm | TIP |
| RFID (UHF) | 40 kbps | 860–960 MHz | 12 m | none |
| Wi-Fi | 1–300 Mbps | 2.4 and 5 GHz | 50 m | SSID |
| IrDA | 14.4 kbps | 850–900 nm | 0–1 m | IRFM |
| UWB | 53–480 Mbps | 3.1–10.6 GHz | 0–10 m | High |
| ZigBee | 20–250 kbps | 868 Mbps–2.4 Gbps | 10–75 m | 128bit AES |
| RTLS Technology | Gu et al. [5] |
|---|---|
| RFID | 2–3 m |
| GPS | 15 m |
| UWB | 0.15 m |
| Visual analysis | - |
| WLAN | 4 m (2D) |
| Ultrasonic | 0.03 m |
| IR | 3 mm |
| Positioning Point No. | Testing Environment 1 | Testing Environment 2 |
|---|---|---|
| 1 | 65 | 100 |
| 2 | 40 | 100 |
| 3 | 75 | 90 |
| 4 | 80 | 95 |
| 5 | 65 | 95 |
| 6 | 50 | 80 |
| 7 | 75 | 85 |
| 8 | 50 | 90 |
| 9 | 80 | 90 |
| 10 | 90 | 75 |
| 11 | 55 | 45 |
| Positioning Point No. | “WkNN” Localization | Fuzzy Logic-Based Localization | ||
|---|---|---|---|---|
| Success Rate [%] | Average Distance Error [m] | Success Rate [%] | Average Distance Error [m] | |
| 1 | - | - | 100 | 2.12 |
| 2 | - | - | 100 | 2.03 |
| 3 | 80 | 2.77 | 90 | 2.42 |
| 4 | - | - | 95 | 2.17 |
| 5 | 70 | 2.49 | 95 | 2.19 |
| 6 | - | - | 80 | 2.61 |
| 7 | 82.5 | 2.11 | 85 | 2.41 |
| 8 | 80 | 3.24 | 90 | 2.34 |
| 9 | - | - | 90 | 2.77 |
| 10 | - | - | 75 | 2.82 |
| 11 | - | - | 45 | 2.86 |
| 78.1 | 2.65 | 85.9 | 2.43 | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hrad, J.; Vojtech, L.; Cihlar, M.; Stasa, P.; Neruda, M.; Benes, F.; Svub, J. Indoor Positioning System Based on Fuzzy Logic and WLAN Infrastructure. Sensors 2020, 20, 4490. https://doi.org/10.3390/s20164490
Hrad J, Vojtech L, Cihlar M, Stasa P, Neruda M, Benes F, Svub J. Indoor Positioning System Based on Fuzzy Logic and WLAN Infrastructure. Sensors. 2020; 20(16):4490. https://doi.org/10.3390/s20164490
Chicago/Turabian StyleHrad, Jaromir, Lukas Vojtech, Martin Cihlar, Pavel Stasa, Marek Neruda, Filip Benes, and Jiri Svub. 2020. "Indoor Positioning System Based on Fuzzy Logic and WLAN Infrastructure" Sensors 20, no. 16: 4490. https://doi.org/10.3390/s20164490