C2DAN: An Improved Deep Adaptation Network with Domain Confusion and Classifier Adaptation


Abstract
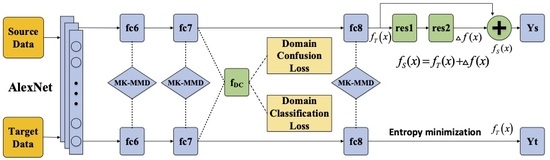
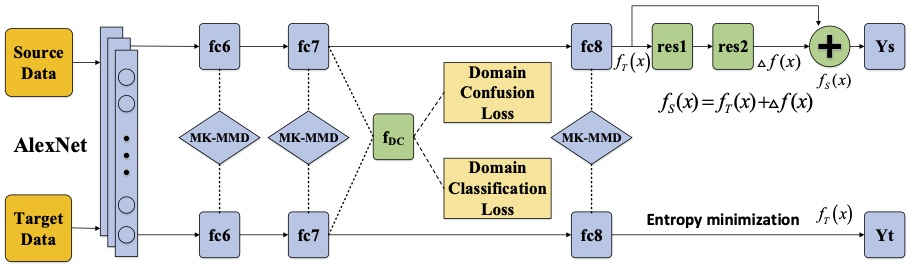
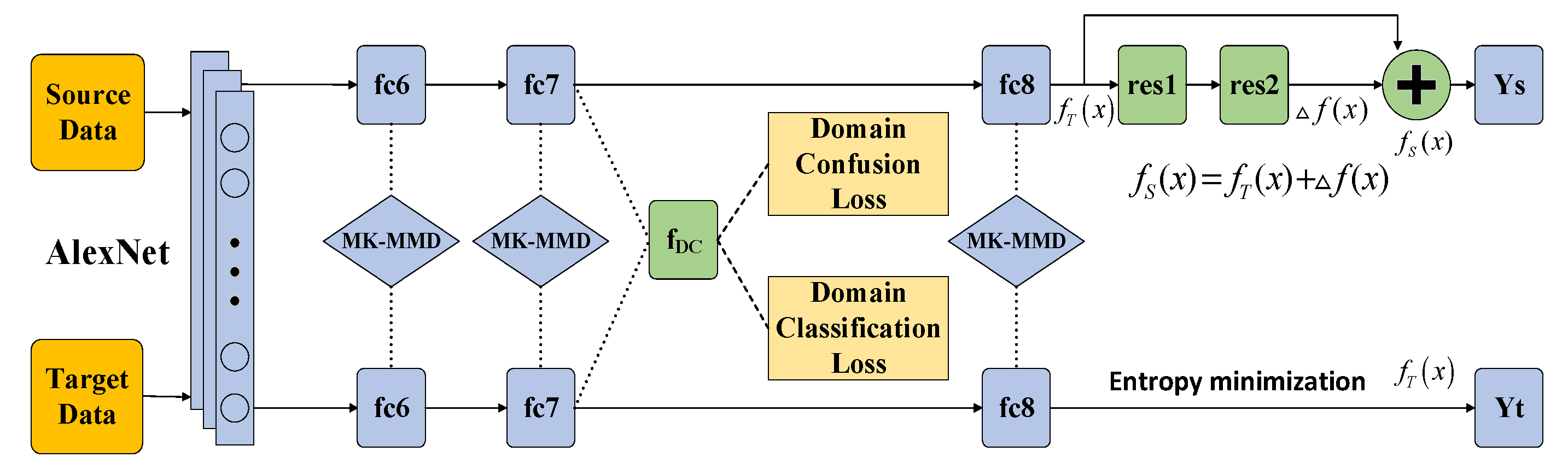
:
1. Introduction
- (1)
- We combine Domain Confusion (DC) with MK-MMD in DAN for both feature alignment and domain alignment, which makes the model more generalized in the target domain.
- (2)
- The model is extended by adding Classifier Adaptation (CA) to minimize the difference of source classifier and target classifier, the accuracy of the proposed method is further improved.
- (3)
- The best combination of MK-MMD, DC and CA in different scenarios is obtained through experiments on office-31 and CompCars dataset, the experimental results show that our improved method C2DAN surpass the performance of DAN.
2. Related Work
3. C2DAN: Improved Deep Adaptive Network
3.1. MK-MMD
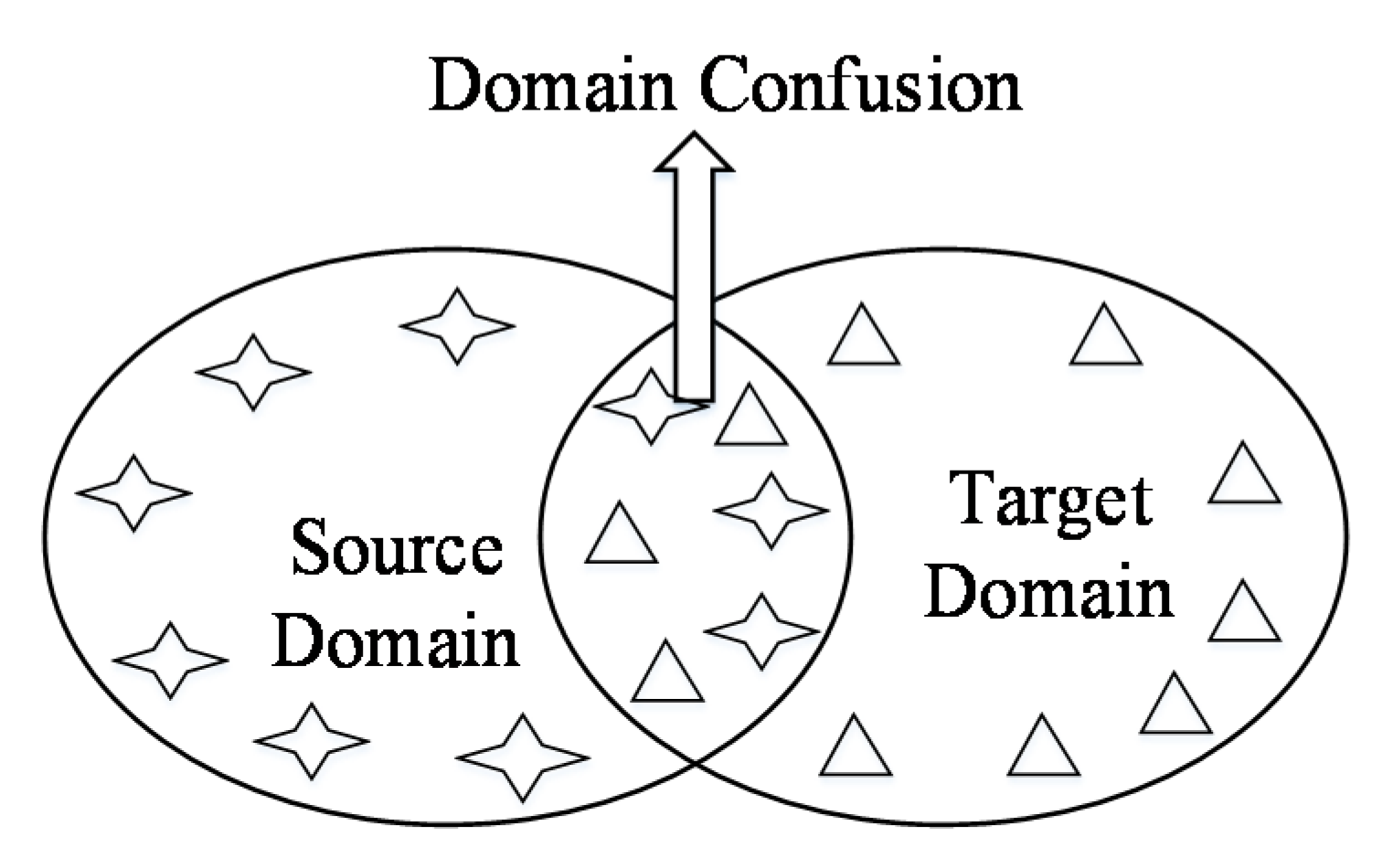
3.2. Domain Confusion
3.3. Classifier Adaptation
3.4. Loss Function
4. Experiment Results and Analysis
4.1. Data Set
4.2. Experiment Procedure
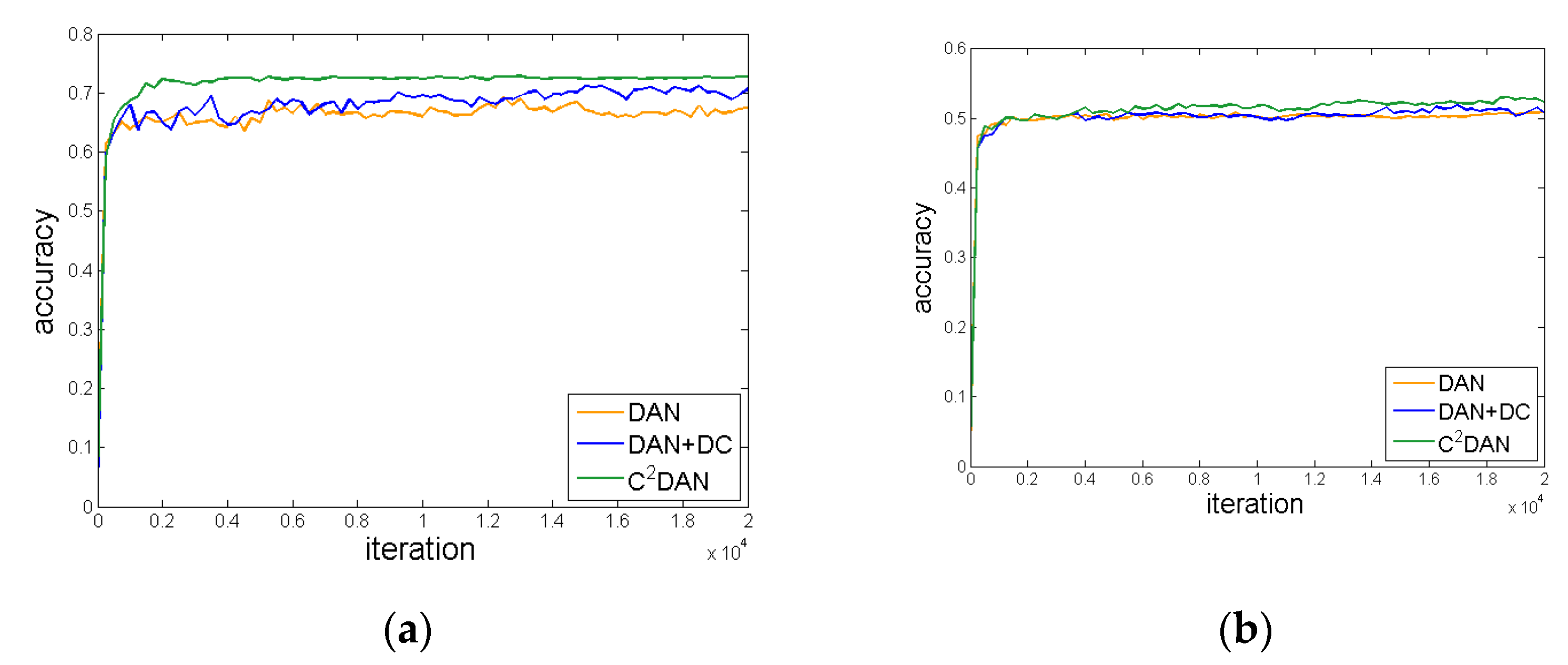
4.3. Experiment Results and Analysis
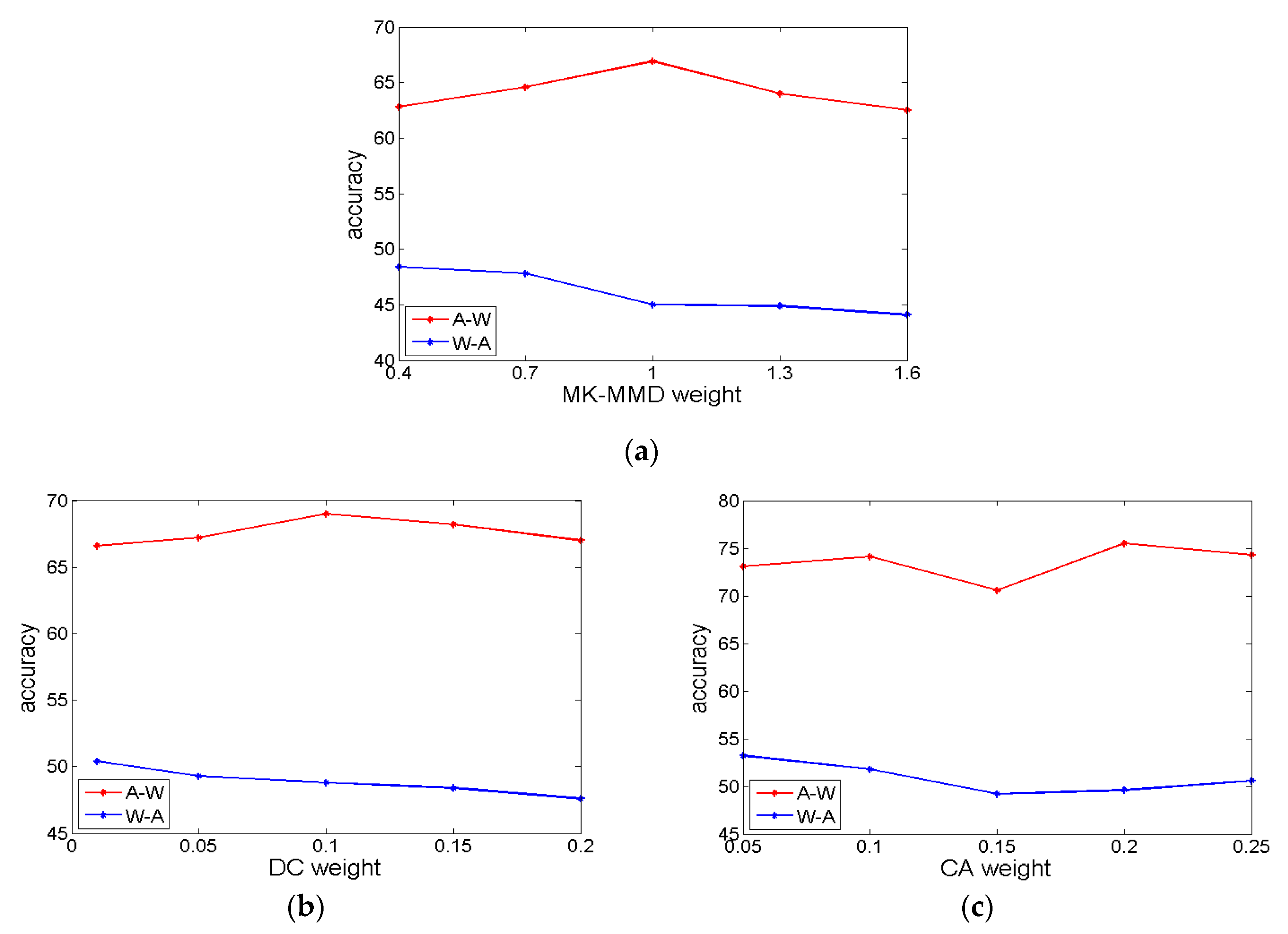
4.4. Analysis of Weights
5. Application on Vehicle Classification
5.1. The Introduction of the Dataset
5.2. Experiments Details and the Result
5.3. Accuracy and Analysis of Various Categories
- (1)
- It can be seen that the classification accuracy of 17 types of vehicles has been improved after using the proposed DAN+DC or C2DAN methods. Compared with that of the DAN method, only one type has decreased, the data in the table show that the difference is little and the decline is not serious. The accuracy of 85% vehicle types have been improved, which proves that the proposed method is reasonable and effective.
- (2)
- For vehicle types with less data, such as the Besturn and Dongfengfengdu cars, in which type the number of samples in source domain and target domain are both less than 2% of the total number of datasets, the proposed method improves the accuracy of vehicle classification by 28.5% and 5.5% respectively compared with the DAN method, and improves by 38.7% and 13.1% compared with the method using only CNN. It proves that the proposed method’s superiority is obvious. The feature extracted by the model in a limited number of samples greatly improves the representation ability in the target domain. By enhancing the feature invariance, the distribution difference between the source domain and the target domain is further reduced.
- (3)
- For the performance degradation of some classes, the main reason is that MK-MMD is an active acquisition while domain confusion is a passive verification for domain invariant feature. Besides, when the domain invariant property of the feature extracted by MK-MMD has reached the optimum level, the improvable space is very limited and the balance training of two kinds of loss may sacrifice the ability of domain adaptation in some categories. However, the sacrifice degree of this part is not too large. It is within the acceptable range and the accuracy of most categories has been improved.
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.S.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
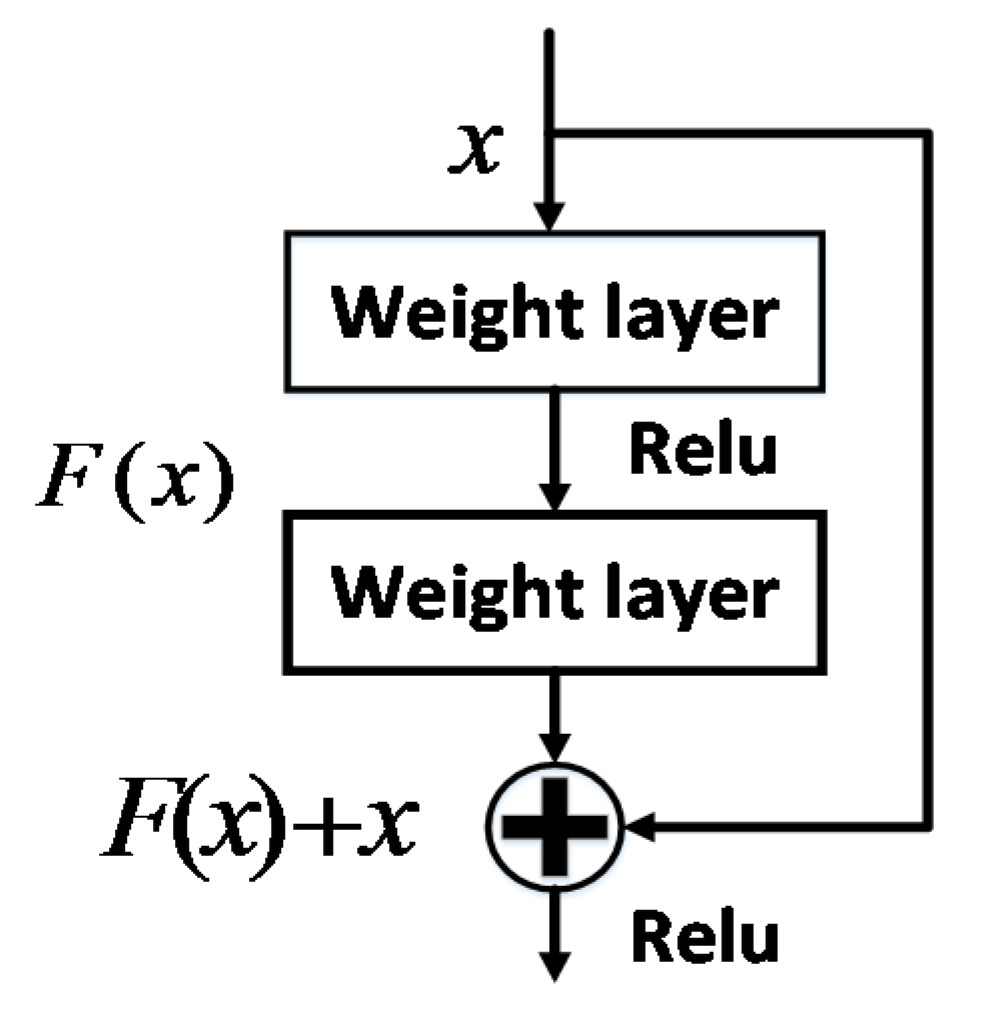
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), LasVegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Cheng, X.; Ren, Y.; Cheng, K.; Cao, J.; Hao, Q. Method for Training Convolutional Neural Networks for In Situ Plankton Image Recognition and Classification Based on the Mechanisms of the Human Eye. Sensors 2020, 20, 2592. [Google Scholar] [CrossRef] [PubMed]
- Everingham, M.; Eslami, S.M.A.; Gool, L.V.; Williams, C.K.I.; Winn, J.M.; Zisserman, A. The Pascal Visual Object Classes Challenge: A Retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Khaki, S.; Pham, H.; Han, Y.; Kuhl, A.; Kent, W.; Wang, L. Convolutional Neural Networks for Image-Based Corn Kernel Detection and Counting. Sensors 2020, 20, 2721. [Google Scholar] [CrossRef] [PubMed]
- Krause, J.; Stark, M.; Deng, J.; Li, F. 3D Object Representations for Fine-Grained Categorization. In Proceedings of the 2013 IEEE International Conference on Computer Vision Workshops, Sydney, Australia, 1–8 December 2013; pp. 554–561. [Google Scholar] [CrossRef]
- Gebru, T.; Hoffman, J.; Li, F. Fine-Grained Recognition in the Wild: A Multi-task Domain Adaptation Approach. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1358–1367. [Google Scholar] [CrossRef] [Green Version]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar] [CrossRef] [Green Version]
- Ansari, R.A.; Malhotra, R.; Buddhiraju, K.M. Identifying Informal Settlements Using Contourlet Assisted Deep Learning. Sensors 2020, 20, 2733. [Google Scholar] [CrossRef] [PubMed]
- Patel, V.M.; Gopalan, R.; Li, R.; Chellappa, R. Visual Domain Adaptation: A survey of recent advances. IEEE Signal Process. Mag. 2015, 32, 53–69. [Google Scholar] [CrossRef]
- Ghifary, M.; Kleijn, W.B.; Zhang, M. Domain Adaptive Neural Networks for Object Recognition. In PRICAI 2014: Trends in Artificial Intelligence, Proceedings of the 13th Pacific Rim International Conference on Artificial Intelligence, Gold Coast, QLD, Australia, 1–5 December 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 898–904. [Google Scholar] [CrossRef] [Green Version]
- Long, M.; Cao, Y.; Wang, J.; Jordan, M.I. Learning Transferable Features with Deep Adaptation Networks. In Proceedings of the 32nd International Conference on Machine Learning, ICML 2015, Lille, France, 6–11 July 2015; pp. 97–105. [Google Scholar]
- Long, M.; Zhu, H.; Wang, J.; Jordan, M.I. Deep Transfer Learning with Joint Adaptation Networks. In Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6–11 August 2017; pp. 2208–2217. [Google Scholar]
- Long, M.; Zhu, H.; Wang, J.; Jordan, M.I. Unsupervised Domain Adaptation with Residual Transfer Networks. In Advances in Neural Information Processing Systems 29, Proceedings of the 30th International Conference on Neural Information Processing, Barcelona, Spain, 2016; Lee, D.D., Sugiyama, M., Eds.; Curran Associates, Inc.: New York, NY, USA, 2016; pp. 136–144. [Google Scholar]
- Zhang, X.; Yu, F.X.; Chang, S.; Wang, S. Deep Transfer Network: Unsupervised Domain Adaptation. arXiv 2015, arXiv:1503.00591. [Google Scholar]
- Yan, H.; Ding, Y.; Li, P.; Wang, Q.; Xu, Y.; Zuo, W. Mind the Class Weight Bias: Weighted Maximum Mean Discrepancy for Unsupervised Domain Adaptation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 22–25 July 2017; pp. 945–954. [Google Scholar] [CrossRef] [Green Version]
- Borgwardt, K.M.; Gretton, A.; Rasch, M.J.; Kriegel, H.; Sch¨olkopf, B.; Smola, A.J. Integrating structured biological data by Kernel Maximum Mean Discrepancy. ISMB. Bioinformatics 2006, 22, 49–57. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sun, B.; Feng, J.; Saenko, K. Return of Frustratingly Easy Domain Adaptation. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, Arizona, USA, 12–17 February 2016; pp. 2058–2065. [Google Scholar]
- Sun, B.; Saenko, K. Deep CORAL: Correlation Alignment for Deep Domain Adaptation. In Computer Version-ECCV 2016 Workshops, Proceedings of the 14th European Conference on Computer Version, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; Volume 9915, pp. 443–450. [Google Scholar] [CrossRef] [Green Version]
- Zhuang, F.; Cheng, X.; Luo, P.; Pan, S.J.; He, Q. Supervised Representation Learning: Transfer Learning with Deep Autoencoders. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence (IJCAI 2015), Buenos Aires, Argentina, 25–31 July 2015; pp. 4119–4125. [Google Scholar]
- Hoffman, J.; Tzeng, E.; Darrell, T.; Saenko, K. Simultaneous Deep Transfer Across Domains and Tasks. In Domain Adaptation in Computer Vision Applications; Springer: Berlin/Heidelberg, Germany, 2017; pp. 173–187. [Google Scholar] [CrossRef] [Green Version]
- Ganin, Y.; Lempitsky, V.S. Unsupervised Domain Adaptation by Backpropagation. In JMLR Workshop and Conference Proceedings, Proceedings of The 31st International Conference on Machine Learning, Beijing, China, on 21–26 June 2014; Microtome Publishing: Brookline, MA, USA; pp. 1180–1189.
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V.S. Domain-Adversarial Training of Neural Networks. J. Mach. Learn. Res. 2016, 17, 1–35. [Google Scholar]
- Tzeng, E.; Devin, C.; Hoffman, J.; Finn, C.; Abbeel, P.; Levine, S.; Saenko, K.; Darrell, T. Adapting Deep Visuomotor Representations with Weak Pairwise Constraints. WAFR. Springer Proceedings in Advanced Robotics; Springer: Berlin/Heidelberg, Germany, 2016; Volume 13, pp. 688–703. [Google Scholar] [CrossRef]
- Tzeng, E.; Hoffman, J.; Saenko, K.; Darrell, T. Adversarial Discriminative Domain Adaptation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 22–25 July 2017; pp. 2962–2971. [Google Scholar] [CrossRef] [Green Version]
- Wang, L.; Sindagi, V.; Patel, V.M. High-Quality Facial Photo-Sketch Synthesis Using Multi-Adversarial Networks. In Proceedings of the 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; pp. 83–90. [Google Scholar] [CrossRef] [Green Version]
- Cao, Z.; Long, M.; Wang, J.; Jordan, M.I. Partial Transfer Learning With Selective Adversarial Networks. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 2724–2732. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Ding, Z.; Li, W.; Ogunbona, P. Importance Weighted Adversarial Nets for Partial Domain Adaptation. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 8156–8164. [Google Scholar] [CrossRef] [Green Version]
- Bousmalis, K.; Silberman, N.; Dohan, D.; Erhan, D.; Krishnan, D. Unsupervised Pixel-Level Domain Adaptation with Generative Adversarial Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 22–25 July 2017; pp. 95–104. [Google Scholar] [CrossRef] [Green Version]
- Chadha, A.; Andreopoulos, Y. Improved Techniques for Adversarial Discriminative Domain Adaptation. IEEE Trans. Image Process. 2020, 29, 2622–2637. [Google Scholar] [CrossRef] [PubMed]
- Saenko, K.; Kulis, B.; Fritz, M.; Darrell, T. Adapting Visual Category Models to New Domains. In Computer Vision-ECCV 2010, Proceedings of the 11th European Conference On Computer Vision, Heraklion, Crete, Greece, 5–11 September 2010; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6314, pp. 213–226. [Google Scholar] [CrossRef]
- Yang, L.; Luo, P.; Loy, C.C.; Tang, X. A large-scale car dataset for fine-grained categorization and verification. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3973–3981. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; WardeFarley, D.; Ozair, S.; Courville, A.C.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the 28th Annual Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Isola, P.; Zhu, J.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 22–25 July 2017; pp. 5967–5976. [Google Scholar] [CrossRef] [Green Version]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. arXiv 2014, arXiv:1411.1784v1. [Google Scholar]
- Liu, M.; Tuzel, O. Coupled Generative Adversarial Networks. In Advances in Neural Information Processing Systems 29, Proceedings of the 30th International Conference on Neural Information Processing, Barcelona, Spain, 2016; Lee, D.D., Sugiyama, M., Eds.; Curran Associates, Inc.: New York, NY, USA, 2016; pp. 469–477. [Google Scholar]
- Zhu, J.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using CycleConsistent Adversarial Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar] [CrossRef] [Green Version]
- Yi, Z.; Zhang, H.R.; Tan, P.; Gong, M. DualGAN: Unsupervised Dual Learning for Image-to-Image Translation. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2868–2876. [Google Scholar] [CrossRef] [Green Version]
- Kim, T.; Cha, M.; Kim, H.; Lee, J.K.; Kim, J. Learning to Discover Cross-Domain Relations with Generative Adversarial Networks. In Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6–11 August 2017; pp. 1857–1865. [Google Scholar]
- Shen, J.; Qu, Y.; Zhang, W.; Yu, Y. Wasserstein Distance Guided Representation Learning for Domain Adaptation. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence (AAAI 2018), New Orleans, LA, USA, 2–7 February 2018; pp. 4058–4065. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein Generative Adversarial Networks. Available online: http://proceedings.mlr.press/v70/arjovsky17a.html (accessed on 25 June 2020).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| A-W | D-W | W-D | A-D | D-A | W-A | Average | |
|---|---|---|---|---|---|---|---|
| Baseline | 60.6(~0.6) | 95.0(~0.5) | 99.1(~0.2) | 59.0(~0.7) | 49.7(~0.3) | 46.2(~0.5) | 68.2 |
| DAN [12] RTN [14] | 66.9(~0.6) 70.0(~0.4) | 96.3(~0.4) 96.8(~0.2) | 99.3(~0.2) 99.6(~0.1) | 66.3(~0.5) 69.8(~0.2) | 52.2(~0.3) 50.2(~0.4) | 49.4(~0.4) 50.0(~0.6) | 71.6 72.7 |
| DAN+DC (fc6) | 67.3(~0.6) | 96.0(~0.3) | 99.1(~0.2) | 66.0(~0.7 | 51.5(~0.3) | 49.6(~0.5) | 71.5 |
| DAN+DC (fc7) RTN+DC C2DAN | 69.0(~0.7) 73.0(~0.7) 74.0(~0.6) | 96.2(~0.4) 97.3(~0.5) 96.6(~0.7) | 99.5(~0.2) 99.6(~0.1) 99.6(~0.1) | 67.0(~0.6) 70.8(~0.2) 71.5(~0.3) | 52.5(~0.5) 50.4(~0.4) 53.0(~0.6) | 50.2(~0.5) 51.8(~0.6) 52.2(~0.4) | 72.5 73.8 74.4 |
| A-C | W-C | D-C | C-A | C-W | C-D | Average | |
|---|---|---|---|---|---|---|---|
| Baseline | 82.6(~0.3) | 75.8(~0.3) | 77.1(~0.5) | 90.5(0.1) | 79.6(0.2) | 83.5(0.5) | 81.5 |
| DAN [12] RTN [14] | 86.0(~0.5) 88.1(~0.2) | 81.5(~0.2) 85.6(~0.1) | 81.8(~0.3) 84.1(~0.2) | 92.0(~0.5) 93.0(~0.1) | 90.6(~0.5) 96.3(~0.3) | 90.2(~0.3) 94.2(~0.2) | 87.0 90.2 |
| DAN+DC (fc6) | 85.0(~0.1) | 80.4(~0.3) | 80.0(~0.3) | 91.7(~0.3) | 85.6(~0.2) | 88.6(~0.2) | 85.2 |
| DAN+DC (fc7) RTN+DC C2DAN | 86.4(~0.2) 88.4(~0.4) 88.7(~0.3) | 82.2(~0.5) 86.5(~0.2) 86.3(~0.5) | 82.5(~0.1) 85.3(~0.3) 85.0(~0.5) | 92.8(~0.3) 93.7(~0.3) 93.5(~0.2) | 92.3(~0.5) 96.3(~0.1) 97.0(~0.3) | 91.3(~0.5) 95.0(~0.2) 95.6(~0.1) | 87.9 90.8 91.0 |
| Acura | Benz | Besturn | BYD | Changan | |
|---|---|---|---|---|---|
| data | 157 | 570 | 72 | 356 | 405 |
| sv_data | 370 | 155 | 68 | 395 | 465 |
| Dongfengfengdu | Geely | Haima | Honda | Hyundai | |
| data | 46 | 426 | 69 | 360 | 645 |
| sv_data | 92 | 576 | 203 | 380 | 572 |
| Jeep | Lexus | MAZDA | Mitsubishi | Nissan | |
| data | 200 | 283 | 314 | 275 | 431 |
| sv_data | 304 | 188 | 371 | 281 | 462 |
| Shuanglong | Toyota | Volkswagen | Volvo | Zhonghua | |
| data | 190 | 511 | 553 | 370 | 193 |
| sv_data | 264 | 572 | 533 | 598 | 111 |
| Method | Accuracy |
|---|---|
| CNN (Baseline) | 0.351 |
| DAN [12] | 0.449 |
| RTN [14] | 0.443 |
| DAN+DC | 0.476 |
| RTN+DC | 0.456 |
| C2DAN (DAN+DC+CA) | 0.507 |
| CNN (Baseline) | DAN | DAN + DC | C2DAN | |
|---|---|---|---|---|
| Acura | 0.511 | 0.600 | 0.614 | 0.608 |
| Benz | 0.265 | 0.696 | 0.587 | 0.781 |
| Besturn | 0.118 | 0.220 | 0.505 | 0.206 |
| BYD | 0.083 | 0.387 | 0.332 | 0.504 |
| Changan | 0.606 | 0.326 | 0.328 | 0.338 |
| Dongfengfengdu | 0.054 | 0.130 | 0.185 | 0.054 |
| Geely | 0.474 | 0.534 | 0.520 | 0.641 |
| Haima | 0.000 | 0.039 | 0.060 | 0.014 |
| Honda | 0.431 | 0.281 | 0.389 | 0.409 |
| Hyundai | 0.271 | 0.470 | 0.472 | 0.530 |
| Jeep | 0.740 | 0.815 | 0.803 | 0.869 |
| Lexus | 0.617 | 0.399 | 0.479 | 0.724 |
| MAZDA | 0.218 | 0.498 | 0.496 | 0.517 |
| Mitsubishi | 0.238 | 0.476 | 0.605 | 0.514 |
| Nissan | 0.530 | 0.510 | 0.574 | 0.500 |
| Shuanglong | 0.273 | 0.401 | 0.409 | 0.391 |
| Toyota | 0.196 | 0.222 | 0.234 | 0.195 |
| Volkswagen | 0.580 | 0.656 | 0.658 | 0.714 |
| Volvo | 0.582 | 0.698 | 0.652 | 0.679 |
| Zhonghua | 0.234 | 0.612 | 0.622 | 0.712 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, H.; Chen, X.; Wang, L.; Liang, D.; Liu, N.; Zhou, H. C2DAN: An Improved Deep Adaptation Network with Domain Confusion and Classifier Adaptation. Sensors 2020, 20, 3606. https://doi.org/10.3390/s20123606
Sun H, Chen X, Wang L, Liang D, Liu N, Zhou H. C2DAN: An Improved Deep Adaptation Network with Domain Confusion and Classifier Adaptation. Sensors. 2020; 20(12):3606. https://doi.org/10.3390/s20123606
Chicago/Turabian StyleSun, Han, Xinyi Chen, Ling Wang, Dong Liang, Ningzhong Liu, and Huiyu Zhou. 2020. "C2DAN: An Improved Deep Adaptation Network with Domain Confusion and Classifier Adaptation" Sensors 20, no. 12: 3606. https://doi.org/10.3390/s20123606