SCENet: Secondary Domain Intercorrelation Enhanced Network for Alleviating Compressed Poisson Noises

Abstract
:1. Introduction with Preliminary Examination
2. Degradation Model
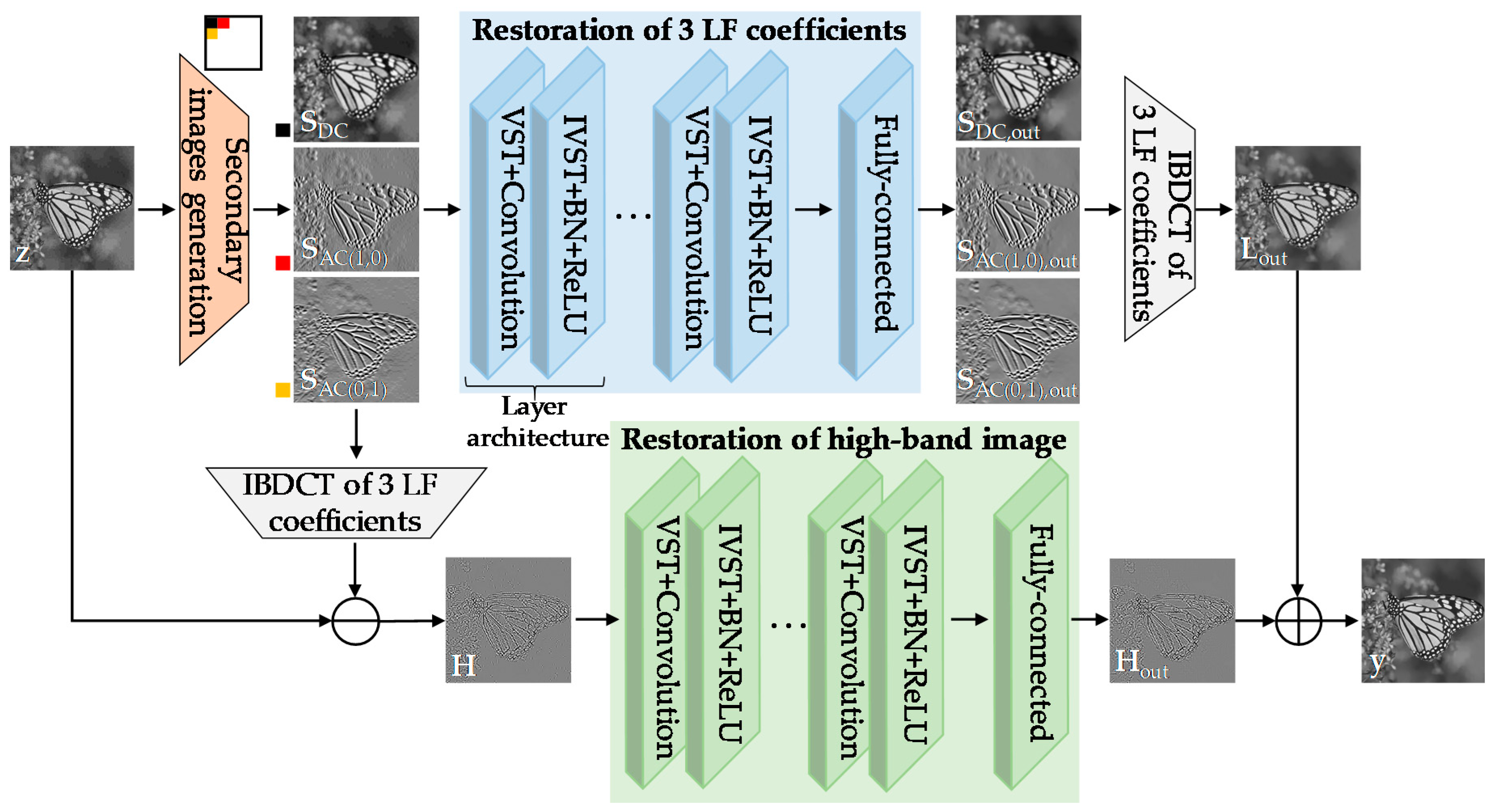
3. Secondary Domain Intercorrelation Enhanced Network
| Algorithm 1: Compressed Poisson noise reduction based on the SCENet |
| Input: degraded image z and trained parameters aL=1,...,20, F=1,2,3, bL=1,...,20 |
| Output: restored image y |
| 1: Compute DC, AC(1,0), AC(0,1) by T{z}. |
| 2: Obtain S = {SDC, SAC(1,0), SAC(0,1)} by merging the each coefficient. |
| 3: for L = 1, …, 20 do |
| 4: Stabilize using VST by f{S}. |
| 5: Apply convolution with trained parameters and then destabilize it by f −1{aL,F* f{S}}. |
| 6: Appy BN and ReLU by max(BN{f −1{aL,F* f{S}}}, 0). |
| 7: end for |
| 8: Obtain Sout = {SDC,out, SAC(1,0),out, SAC(0,1),out} by applying a fully-connected layer. |
| 9: Estimate Lout by T−1{Sout}. |
| 10: Obtain H by z −T−1{S}. |
| 11: Estimate Hout by running steps 3−8 above with H and bL=1,...,20 instead of S and aL,F. |
| 12: Estimate final restored image by y = Lout + Hout. |
4. Experiments
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Foi, A.; Trimeche, M.; Katkovnik, V.; Egiazarian, K. Practical Poissonian-Gaussian noise modeling and fitting for single-image raw-data. IEEE Trans. Image Process. 2008, 17, 1737–1754. [Google Scholar] [CrossRef] [PubMed]
- Dong, C.; Deng, Y.; Change, L.C.; Tang, X. Compression artifacts reduction by a deep convolutional network. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 576–584. [Google Scholar]
- Chen, Y.; Pock, T. Trainable nonlinear reaction diffusion: A flexible framework for fast and effective image restoration. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1256–1272. [Google Scholar] [CrossRef] [PubMed]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a Gaussian denoiser: Residual learning of deep CNN for image denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef] [PubMed]
- Liu, P.; Zhang, H.; Zhang, K.; Lin, L.; Zuo, W. Multi-level wavelet-CNN for image restoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 773–782. [Google Scholar]
- Lu, G.; Ouyang, W.; Xu, D.; Zhang, X.; Gao, Z.; Sun, M.T. Deep Kalman filtering network for video compression artifact reduction. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 568–584. [Google Scholar]
- Zhang, Y.; Sun, L.; Yan, C.; Ji, X.; Dai, Q. Adaptive residual networks for high-quality image restoration. IEEE Trans. Image Process. 2018, 27, 3150–3163. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Yang, W.; Hu, Y.; Liu, J. DMCNN: Dual-domain multi-scale convolutional neural network for compression artifacts removal. In Proceedings of the 25th IEEE International Conference on Image Processing, Athens, Greece, 7–10 October 2018; pp. 390–394. [Google Scholar]
- Zheng, B.; Chen, Y.; Tian, X.; Zhou, F.; Liu, X. Implicit dual-domain convolutional network for robust color image compression artifact reduction. arXiv 2018, arXiv:1810.08042. [Google Scholar]
- Zhang, X.; Lu, Y.; Liu, J.; Dong, B. Dynamically unfolding recurrent restorer: A moving endpoint control method for image restoration. arXiv 2018, arXiv:1805.07709. [Google Scholar]
- Zheng, B.; Sun, R.; Tian, X.; Chen, Y. S-Net: A scalable convolutional neural network for JPEG compression artifact reduction. J. Electron. Imaging 2018, 27, Art. No. 043037. [Google Scholar]
- Yoo, J.; Lee, S.H.; Kwak, N. Image restoration by estimating frequency distribution of local patches. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6684–6692. [Google Scholar]
- Galteri, L.; Seidenari, L.; Bertini, M.; Bimbo, A.D. Deep universal generative adversarial compression artifact removal. IEEE Trans. Multimedia 2019, in press. [Google Scholar] [CrossRef]
- Chen, H.; He, X.; An, C.; Nguyen, T.Q. Deep wide-activated residual network based joint blocking and color bleeding artifacts reduction for 4: 2: 0 JPEG-compressed images. IEEE Signal Process. Lett. 2019, 26, 79–83. [Google Scholar] [CrossRef]
- Markku, M.; Foi, A. Optimal inversion of the Anscombe transformation in low-count Poisson image denoising. IEEE Trans. Image Process. 2011, 20, 99–109. [Google Scholar]
- Lim, K.W.; Chun, K.W.; Ra, J.B. Improvements on image transform coding by reducing interblock correlation. IEEE Trans. Image Process. 1995, 4, 1146–1150. [Google Scholar] [PubMed]
- Yoo, S.B.; Choi, K.; Ra, J.B. Post-processing for blocking artifact reduction based on inter-block correlation. IEEE Trans. Multimedia 2014, 16, 1536–1548. [Google Scholar] [CrossRef]
- Martin, D.; Fowlkes, C.; Tal, D.; Malik, J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In Proceedings of the IEEE International Conference on Computer Vision, Vancouver, BC, Canada, 7–14 July 2001; pp. 416–423. [Google Scholar]
- Agustsson, E.; Timofte, R. Ntire 2017 challenge on single image super-resolution: Dataset and study. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 126–135. [Google Scholar]
- Kingma, D.P.; Adam, B.J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- LIVE Image Quality Assessment Database Release 2. Available online: http://live.ece.utexas.edu/research/quality (accessed on 15 March 2019).
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K. Image denoising by sparse 3-D transform-domain collaborative filtering. IEEE Trans. Image Process. 2007, 16, 2080–2095. [Google Scholar] [CrossRef] [PubMed]
- Zhao, C.; Zhang, J.; Ma, S.; Fan, X.; Zhang, Y.; Gao, W. Reducing image compression artifacts by structural sparse representation and quantization constraint prior. IEEE Trans. Circuits Sys. Video Technol. 2017, 27, 2057–2071. [Google Scholar] [CrossRef]
- SCENet Program. Available online: https://github.com/seokbongyoo/SCENet (accessed on 15 March 2019).
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Smartphone Image Denoising Dataset. Available online: https://www.eecs.yorku.ca/~kamel/sidd/index.php (accessed on 5 April 2019).
- Mittal, A.; Moorthy, A.K.; Bovik, A.C. No-reference image quality assessment in the spatial domain. IEEE Trans. Image Process. 2012, 21, 4695–4708. [Google Scholar] [CrossRef] [PubMed]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Noise Level | Metric | Camera Man | Barbara | Bird | Butter Fly | Hall Monitor | Lena | Mobile | Peppers |
|---|---|---|---|---|---|---|---|---|---|---|
| Degraded | q = 10, peak = 200 | PSNR | 25.85 | 25.13 | 30.86 | 27.90 | 27.91 | 29.89 | 21.85 | 29.39 |
| SSIM | 0.737 | 0.753 | 0.805 | 0.836 | 0.771 | 0.777 | 0.750 | 0.754 | ||
| q = 20, peak = 400 | PSNR | 27.67 | 27.46 | 32.84 | 30.17 | 30.28 | 31.82 | 24.16 | 31.15 | |
| SSIM | 0.776 | 0.827 | 0.827 | 0.873 | 0.815 | 0.819 | 0.822 | 0.797 | ||
| q = 30, peak = 600 | PSNR | 28.97 | 29.17 | 34.02 | 31.41 | 31.56 | 32.84 | 25.73 | 32.04 | |
| SSIM | 0.814 | 0.864 | 0.850 | 0.888 | 0.839 | 0.841 | 0.859 | 0.819 | ||
| BM3D [22] | q = 10, peak = 200 | PSNR | 27.22 | 27.18 | 33.13 | 29.97 | 29.89 | 31.29 | 22.83 | 31.53 |
| SSIM | 0.809 | 0.805 | 0.901 | 0.913 | 0.858 | 0.802 | 0.782 | 0.825 | ||
| q = 20, peak = 400 | PSNR | 29.16 | 29.69 | 35.70 | 32.38 | 32.20 | 33.08 | 25.43 | 32.93 | |
| SSIM | 0.846 | 0.880 | 0.920 | 0.932 | 0.899 | 0.840 | 0.876 | 0.842 | ||
| q = 30, peak = 600 | PSNR | 30.47 | 31.21 | 37.14 | 33.59 | 33.75 | 34.29 | 26.95 | 33.27 | |
| SSIM | 0.871 | 0.902 | 0.921 | 0.931 | 0.902 | 0.858 | 0.897 | 0.844 | ||
| SSRQC [23] | q = 10, peak = 200 | PSNR | 27.32 | 27.31 | 33.14 | 30.53 | 29.73 | 31.27 | 23.05 | 31.49 |
| SSIM | 0.814 | 0.821 | 0.891 | 0.913 | 0.853 | 0.805 | 0.794 | 0.818 | ||
| q = 20, peak = 400 | PSNR | 28.97 | 29.32 | 35.28 | 32.65 | 32.20 | 32.94 | 25.29 | 32.91 | |
| SSIM | 0.844 | 0.872 | 0.905 | 0.930 | 0.880 | 0.835 | 0.864 | 0.836 | ||
| q = 30, peak = 600 | PSNR | 30.18 | 30.91 | 36.38 | 33.63 | 33.36 | 34.27 | 26.74 | 33.61 | |
| SSIM | 0.868 | 0.898 | 0.915 | 0.936 | 0.891 | 0.850 | 0.892 | 0.847 | ||
| ARCNN [2] | q = 10, peak = 200 | PSNR | 27.34 | 26.63 | 33.33 | 31.04 | 30.01 | 31.88 | 23.22 | 31.27 |
| SSIM | 0.819 | 0.811 | 0.901 | 0.918 | 0.880 | 0.847 | 0.807 | 0.827 | ||
| q = 20, peak = 400 | PSNR | 28.86 | 29.18 | 35.11 | 33.22 | 32.49 | 33.56 | 25.70 | 32.57 | |
| SSIM | 0.838 | 0.873 | 0.906 | 0.931 | 0.898 | 0.872 | 0.868 | 0.848 | ||
| q = 30, peak = 600 | PSNR | 30.15 | 30.85 | 36.26 | 34.37 | 33.76 | 34.43 | 27.22 | 33.38 | |
| SSIM | 0.860 | 0.902 | 0.912 | 0.937 | 0.907 | 0.885 | 0.897 | 0.860 | ||
| DnCNN [4] | q = 10, peak = 200 | PSNR | 27.81 | 27.15 | 33.50 | 31.17 | 30.52 | 31.92 | 23.60 | 31.55 |
| SSIM | 0.833 | 0.817 | 0.903 | 0.919 | 0.886 | 0.844 | 0.809 | 0.823 | ||
| q = 20, peak = 400 | PSNR | 29.58 | 29.63 | 35.33 | 33.52 | 32.94 | 33.63 | 26.22 | 32.95 | |
| SSIM | 0.852 | 0.873 | 0.909 | 0.934 | 0.901 | 0.867 | 0.875 | 0.839 | ||
| q = 30, peak = 600 | PSNR | 30.75 | 31.18 | 36.35 | 34.62 | 33.95 | 34.44 | 27.86 | 33.61 | |
| SSIM | 0.870 | 0.897 | 0.913 | 0.938 | 0.905 | 0.877 | 0.906 | 0.847 | ||
| MWCNN [5] | q = 10, peak = 200 | PSNR | 28.09 | 27.71 | 33.23 | 31.10 | 30.62 | 31.91 | 23.69 | 31.53 |
| SSIM | 0.830 | 0.820 | 0.894 | 0.918 | 0.880 | 0.845 | 0.809 | 0.821 | ||
| q = 20, peak = 400 | PSNR | 29.68 | 29.92 | 34.85 | 33.26 | 32.74 | 33.35 | 26.15 | 32.72 | |
| SSIM | 0.839 | 0.871 | 0.889 | 0.927 | 0.886 | 0.856 | 0.871 | 0.828 | ||
| q = 30, peak = 600 | PSNR | 30.98 | 31.55 | 36.07 | 34.54 | 34.00 | 34.32 | 27.74 | 33.49 | |
| SSIM | 0.864 | 0.898 | 0.900 | 0.931 | 0.897 | 0.870 | 0.900 | 0.841 | ||
| SCENet | q = 10, peak = 200 | PSNR | 28.24 | 27.67 | 34.08 | 31.72 | 31.13 | 32.37 | 23.90 | 32.12 |
| SSIM | 0.846 | 0.825 | 0.916 | 0.932 | 0.905 | 0.851 | 0.822 | 0.835 | ||
| q = 20, peak = 400 | PSNR | 30.20 | 30.32 | 36.41 | 34.21 | 33.85 | 34.25 | 26.54 | 33.68 | |
| SSIM | 0.880 | 0.887 | 0.935 | 0.951 | 0.930 | 0.879 | 0.893 | 0.856 | ||
| q = 30, peak = 600 | PSNR | 31.36 | 31.84 | 37.58 | 35.37 | 35.10 | 35.18 | 28.17 | 34.43 | |
| SSIM | 0.894 | 0.910 | 0.939 | 0.955 | 0.936 | 0.891 | 0.920 | 0.866 |
| Noise Level | Metric | Degraded | BM3D [22] | SSRQC [23] | ARCNN [2] | DnCNN [4] | MWCNN [5] | SCENet |
|---|---|---|---|---|---|---|---|---|
| q = 10, peak = 200 | PSNR | 27.01 | 27.85 | 28.03 | 28.16 | 28.60 | 28.64 | 28.97 |
| SSIM | 0.730 | 0.761 | 0.762 | 0.774 | 0.797 | 0.795 | 0.805 | |
| q = 20, peak = 400 | PSNR | 28.99 | 30.15 | 29.88 | 30.22 | 30.60 | 30.47 | 31.08 |
| SSIM | 0.794 | 0.833 | 0.835 | 0.843 | 0.850 | 0.841 | 0.863 | |
| q = 30, peak = 600 | PSNR | 30.18 | 31.38 | 31.30 | 31.35 | 31.58 | 31.63 | 32.34 |
| SSIM | 0.827 | 0.861 | 0.859 | 0.868 | 0.873 | 0.871 | 0.890 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yoo, S.B.; Han, M. SCENet: Secondary Domain Intercorrelation Enhanced Network for Alleviating Compressed Poisson Noises. Sensors 2019, 19, 1939. https://doi.org/10.3390/s19081939
Yoo SB, Han M. SCENet: Secondary Domain Intercorrelation Enhanced Network for Alleviating Compressed Poisson Noises. Sensors. 2019; 19(8):1939. https://doi.org/10.3390/s19081939
Chicago/Turabian StyleYoo, Seok Bong, and Mikyong Han. 2019. "SCENet: Secondary Domain Intercorrelation Enhanced Network for Alleviating Compressed Poisson Noises" Sensors 19, no. 8: 1939. https://doi.org/10.3390/s19081939