2.2. Construction of Base Station Almanac
The BSA is the core dataset of telecom operators, which is crucial to the network operation. It describes the basic parameters of all the base stations and cells in a network. Generally, it includes base station name, cell name, base station latitude and longitude, cell identity, type of base station, azimuth of sector, downtilt of sector, base station height, coverage scenario and so on. Among them, the cell identity is a group of parameters, which are different for different network standards. For example, a cell in the global system for mobile communications (GSM), wideband code division multiple access (WCDMA) or time division–synchronous code division multiple access (TD-SCDMA) network is uniquely identified by two parameters, i.e., location area code (LAC) and cell identity (cellID). On the other hand, for long term evolution (LTE) networks, a cell is uniquely identified by three parameters, that is, the tracking area code (TAC), the base station identity (eNodeBID), and the cellID. The type of base station refers to whether the base station to which the cell belongs to is an omnidirectional station (usually only one cell) or a sectorized station (usually, one base station includes multiple cells, also called sectors). Coverage scenario refers to the types of scenes covered by the base station, such as schools, residential areas, commercial areas, rural areas and so on.
Generally, the BSA information is manually collected and reported by the network operation and maintenance department of the local branches of telecom operator. The disadvantages of this approach are obvious:
(1) Erroneous data: Usually it requires a lot of manual participation, which may result in many errors during the process.
(2) Delay: Since the data are reported through many managerial levels up to headquarters, there is always a big delay between the two ends. In this case, the data in the BSA table cannot be fully consistent with the actual situation in the network.
As we know, that BSA is mainly employed by telecom operators for routine network maintenance. With the popularization of smartphones and in view of the various types of location-based services (LBS) being increasingly accepted by the users, BSA is of great value to such applications. It is crucial to network-aided positioning for various LBS services [
3], since it can provide precise location information of the base stations. However, considering that BSA is a highly confidential and core data asset belonging to the operator, it is not open to the public. Therefore, the Internet service providers attempt to acquire the key information in BSA by means of network parameter scanning with the terminals. Many methods have been proposed to identify the BSA information, especially the location of BS.
In the early stage of digital mobile communications, a common way to estimate cell tower positions is through wardriving [
18]. In wardriving, a vehicle drives within the target area, recording signals radiated from nearby cell towers (or WiFi access points) and the locations these signals were received at. Using this dataset, one can estimate the locations of cell towers with algorithms such as weighted centroid [
18] or strongest received signal strength (strongest RSS) [
19].
Strongest RSS assumes that the measurement with the strongest observed RSS within a cell, also is the measurement closest to the cell tower. The RSS can potentially be affected by many factors, such as obstacles, other types of radio waves, or the signal receiver in the mobile device. Therefore, this method is simple, yet inaccurate.
Weighted centroid is a simple and effective algorithm for estimating cell tower locations for omnidirectional cells. It estimates the cell tower location to be the geometric center of the measurements belonging to the cell. However, for sectorized cells with a 120° cell span, the correct location of the cell tower is not the geometric center of the measurements.
On top of the strongest RSS and weighted centroid, Yang et al. [
20] proposed a cell combining optimization method (CCO). It mainly consists of two steps: RSS thresholding and tower-based regrouping. RSS Thresholding is to filter out all cells whose strongest RSS is lower than a certain cutoff threshold (−60 dBm in this paper). This is to eliminate as many outside cells (i.e., cells fall outside of wardriving area) as possible, since the location estimation of these cells is too poor. Tower-based regrouping technique merges the wardriving traces of cells that share a common cell tower into a single trace and estimating the position of the cell tower itself can improve localization results significantly. It combines the sectors with non-homogeneous coverage into a BS with homogeneous coverage. After applying the cell combining optimization, both the strongest RSS and weighted centroid are improved significantly. Weighted centroid benefits more from the optimization.
With the popularity of smart phones, new cell tower positioning methods have been proposed by employing crowdsourcing data.
Apple Inc. has proposed a positioning algorithm for wireless communication network access point (AP) devices and mobile devices based on the location information of the mobile devices [
1]. In this method, the server may receive location information from the mobile devices (e.g., a device with GPS module) of a known location located within the coverage of the wireless AP. Therefore, the position of AP device can be estimated by calculating the geographical average using the received position information of the mobile devices, and when a mobile device is connected to an access point, its location can then be determined based on the position information of the serving AP and the neighboring APs.
Qualcomm has proposed a weighted centroid method of utilizing the crowdsourced information to improve the base station location information in the BSA database [
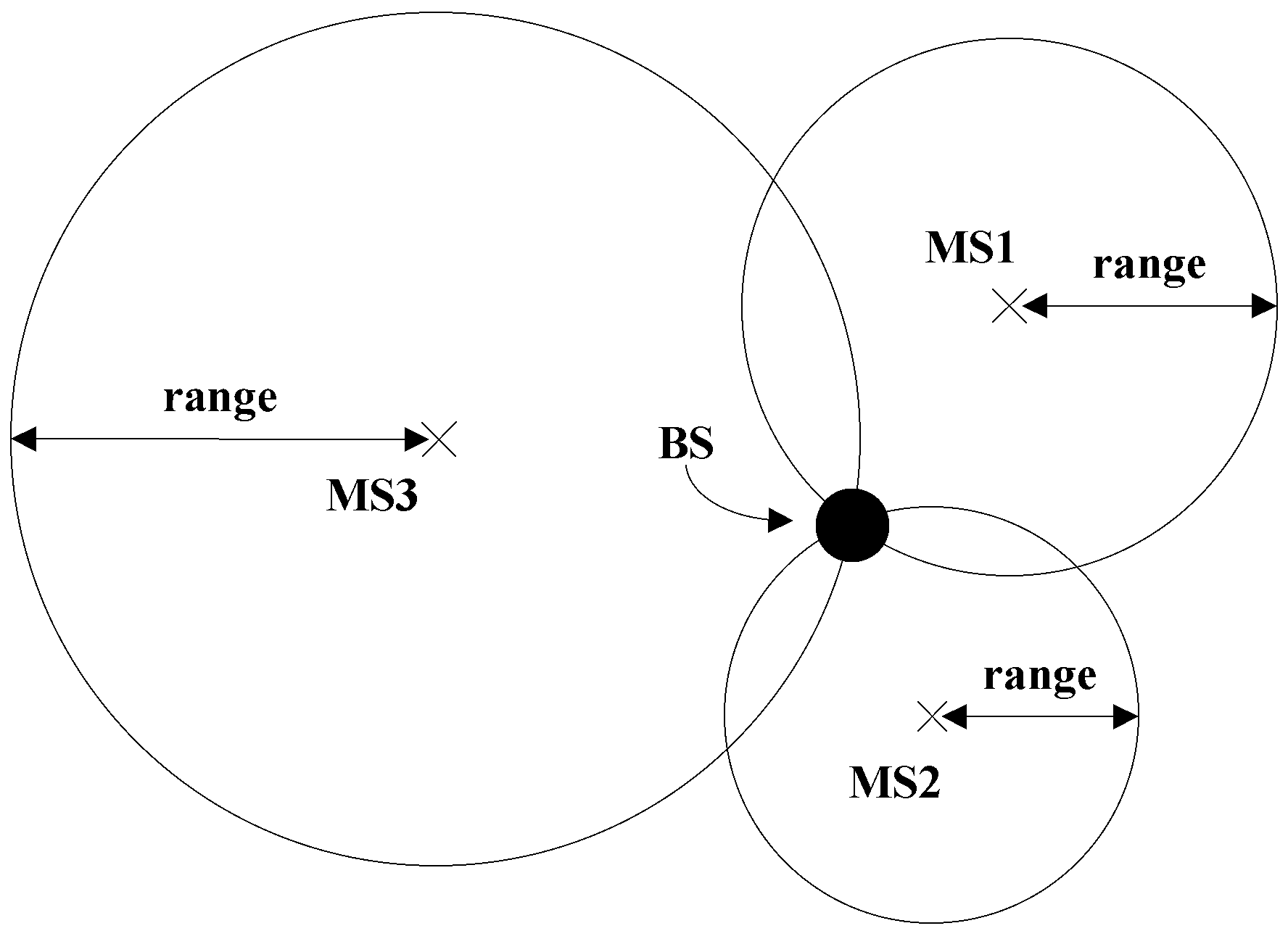
3]. As shown in
Figure 2, the base station estimates the approximate distance (i.e., range in the figure) between itself and the terminals MS1~MS3 by using the collected coverage information (including RSS, Time of Arrival (TOA), etc.) of the serving cell. Taking the position of MS1~MS3 as the center, and the approximate distance between BS and MS1~MS3 as radius, we can draw three circles. Then, the position of the BS can be defined roughly as the intersection position of the circles. Alternatively, the terminal reports its current GPS position if available. The BS aggregates the accurate GPS position of the terminals belonging to the same BS, i.e., taking its clustering center (geometric center) as the BS position and updating in the BSA.
In summary, the abovementioned methods have the following limitations:
(1) Limited application scenarios: As these methods are proposed mainly for the positioning purpose, it detects and updates only those location-relevant parameters of the almanac, that is, the cell ID and the corresponding latitude and longitude of the base station site. It does not tackle other key attributes such as the type of base station, sector azimuth and downtilt of sectors, etc., which are crucial to mobile network operation.
(2) The performance of the Qualcomm method depends heavily on the availability of the coverage parameters of the base station and the GPS positioning of the terminal. It is usually difficult for commercial handset to obtain the coverage information of the neighboring cells and TOA of the serving cell due to its limited access right to low-level database of the handset. In addition, as the signal strength always fluctuates significantly due to the variation of the propagation environment, estimating the position using only these parameters can bring about very large errors.
In addition, although the positioning accuracy of GPS is very high, the actual amount of data available is too small to be effectively utilized. Due to issues like power saving, generally the GPS module is turned on only in case the navigation App starts. Instead, large number of positioning demands are fulfilled through network-aided positioning. Although the accuracy is lower than that of the GPS positioning, the available samples are very rich and can still meet the needs of many application scenarios through a suitable learning algorithm.
(3) The weighted centroid methods apply for the omni-directional stations only. It does not deal with the sectorized base station cases, whereas almost all the outdoor stations in urban and suburban areas are sectorized ones. In this case, the non-homogeneity of measurements around the sectorized cell has a big adverse effect. That is, the centroid of the samples does not indicate the cell location.
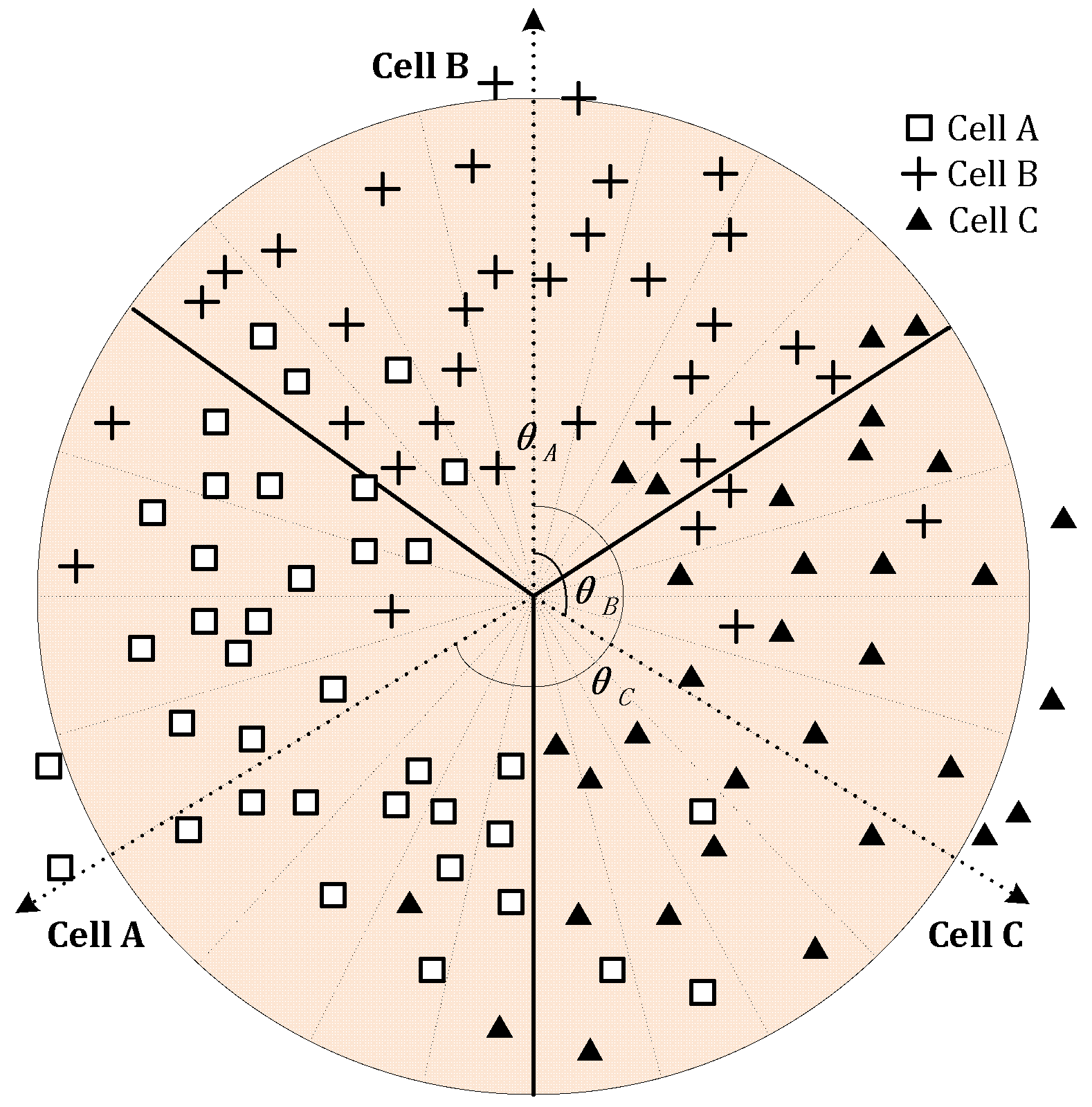
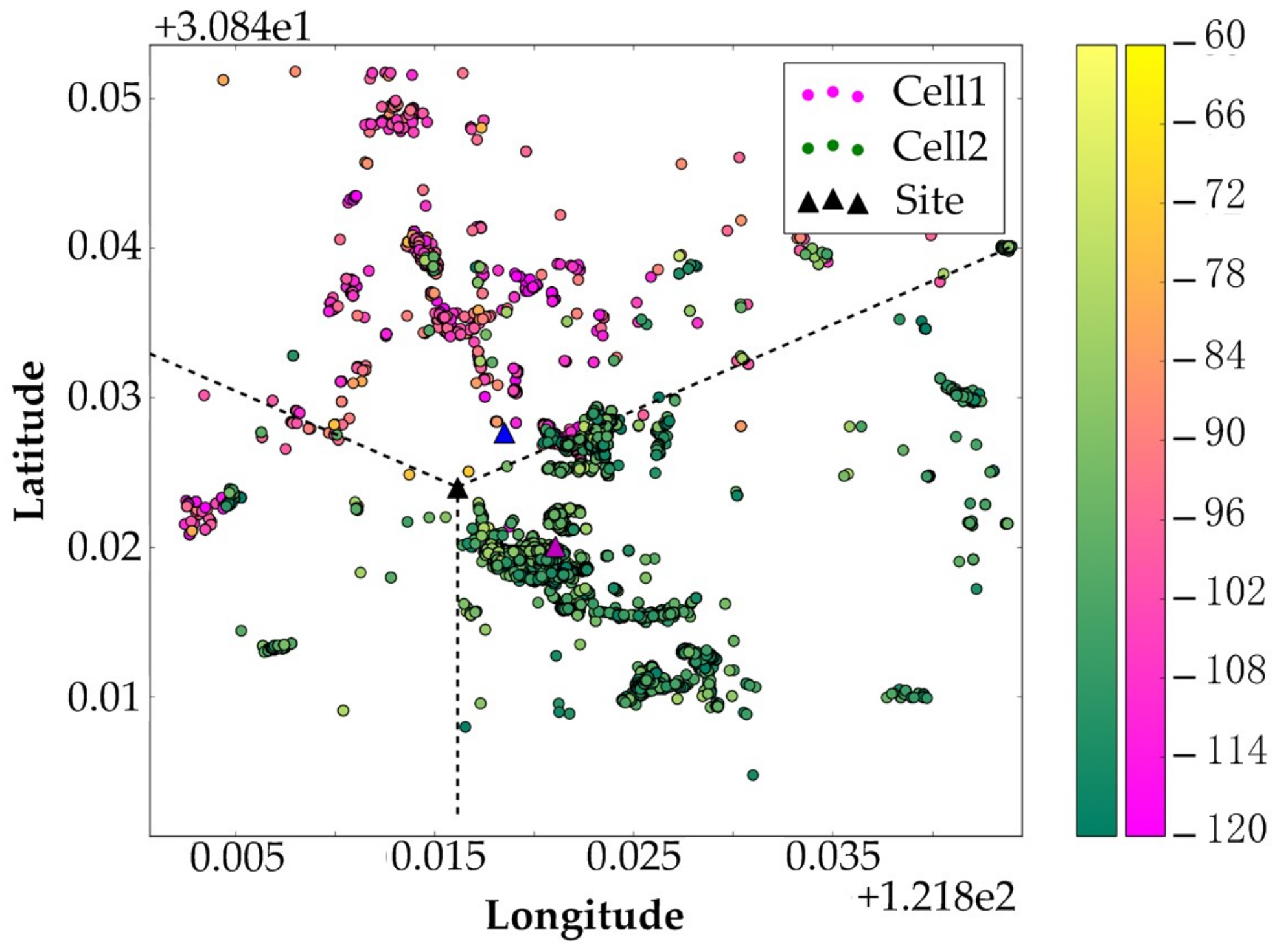
(4) Although the CCO method is applicable for the sectorized cells, by eliminating the non-homogeneity raised by sectorized cells, it requires the distribution of samples among the sectors of one BS to be balanced, and the sectors of a BS shall be rotational symmetric. When the number of samples in each sector of the same BS varies greatly, the clustering center would shift to a sector with a much larger number of samples, and it possibly results in a larger positioning error. For BS with rational asymmetric sectors, as illustrated in
Figure 3 for example, positioning error occurs.
2.3. Data Acquisition with Mobile Crowdsensing
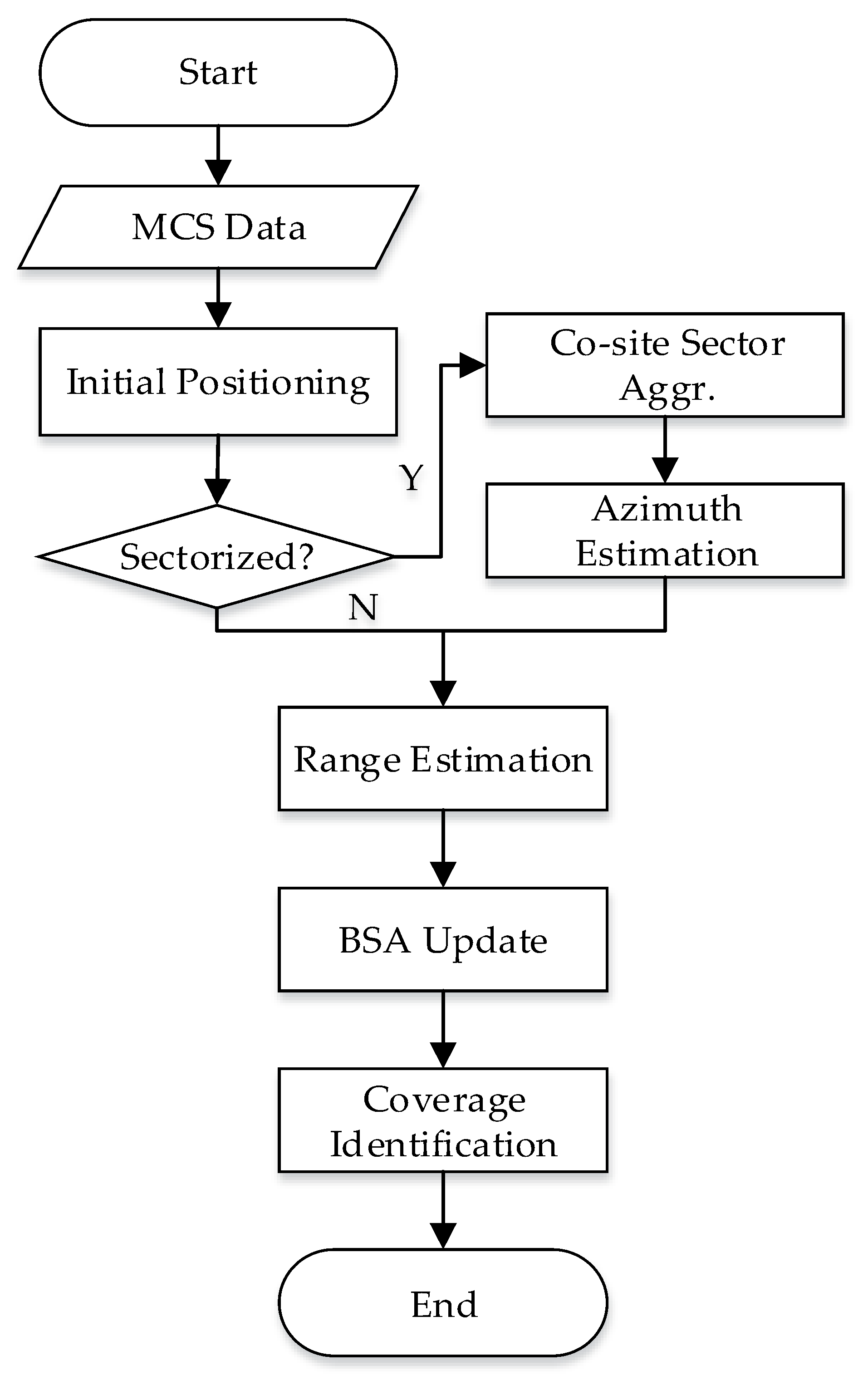
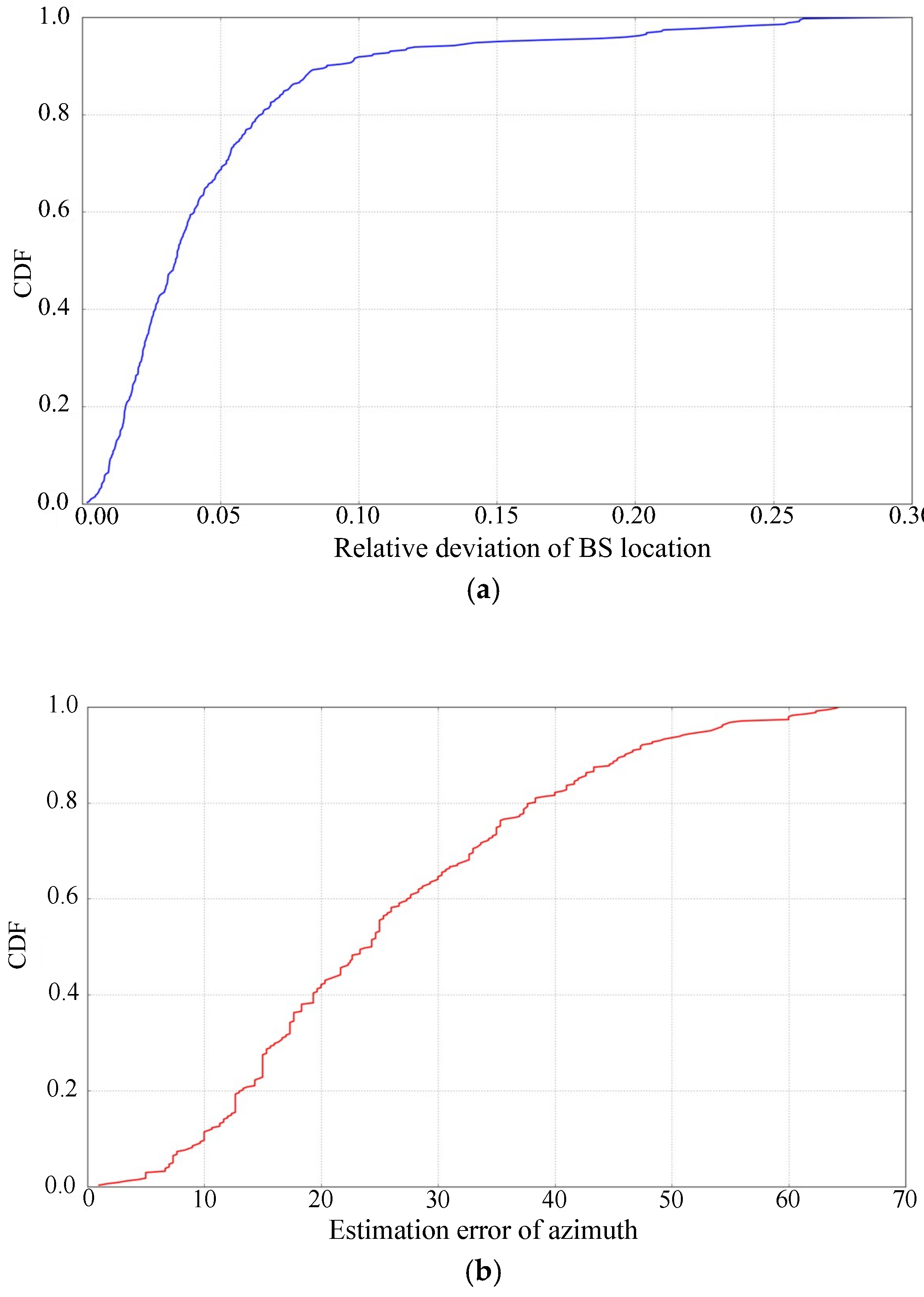
Aiming at the shortcomings of the above methods, this paper makes further efforts on the detection and optimization of BSA and proposes a new method. The proposed method is based on the data obtained through a crowdsourcing-based user perception (CUP) system. It is commercially deployed by cooperating with the operator.
A client–server architecture is employed for the CUP system, as illustrated in
Figure 4 [
7].
The system mainly consists of two parts: the data acquisition agent in the terminal and the data processing platform at the cloud side. The data acquisition agent, either as a stand-alone APP or a software development kit (SDK) plug-in bundled with other APPs, is deployed in massive number of commercial terminals. Under certain conditions, the agent is then triggered to collect the terminal’s instantaneous wireless parameters periodically by visiting the APIs of the operating system. The sampling period can be configured from the server side. Similar to the energy-saving strategy of PCS [
16], the agent is triggered only in case the screen is waked up and user launches the APPs that the agent SDK is bundled with. And a maximum number of samples in one day is configured by the server, so as to further save the energy consumption. The information is transferred to the data processing platform on the cloud side under the pre-defined triggering conditions (e.g., when the terminal is connected to WiFi) through radio access network (RAN), core network (CN), and the Internet, as indicated in
Figure 4 with red dotted line.
The sampling dataset of an LTE network includes mainly the followings: date, time, network mode, ID of the serving cell, the positioning information of the terminal, signal strength (RSRP), and signal quality (RSRQ).
The positioning information includes current location (longitude and latitude), the positioning method and precision. In case the GPS module is enabled by the user, the GPS longitude and latitude are collected by the agent. Otherwise, the agent will acquire current location with the third-party network augmented positioning APIs like Baidu or Google positioning. The network augmented positioning is less accurate (normally with errors of several tens of meters in urban area) and consumes less battery than GPS positioning. The agent does not trigger the GPS positioning initiatively, to avoid interference to users and save battery energy.
It shall be noted that, highly sensitive information, such as user ID, phone number, and contents of APPs are not acquired. Thus, there is no violation to user’s privacy. The raw data arrived at the data processing platform are firstly pre-processed, mainly to eliminate invalid data.
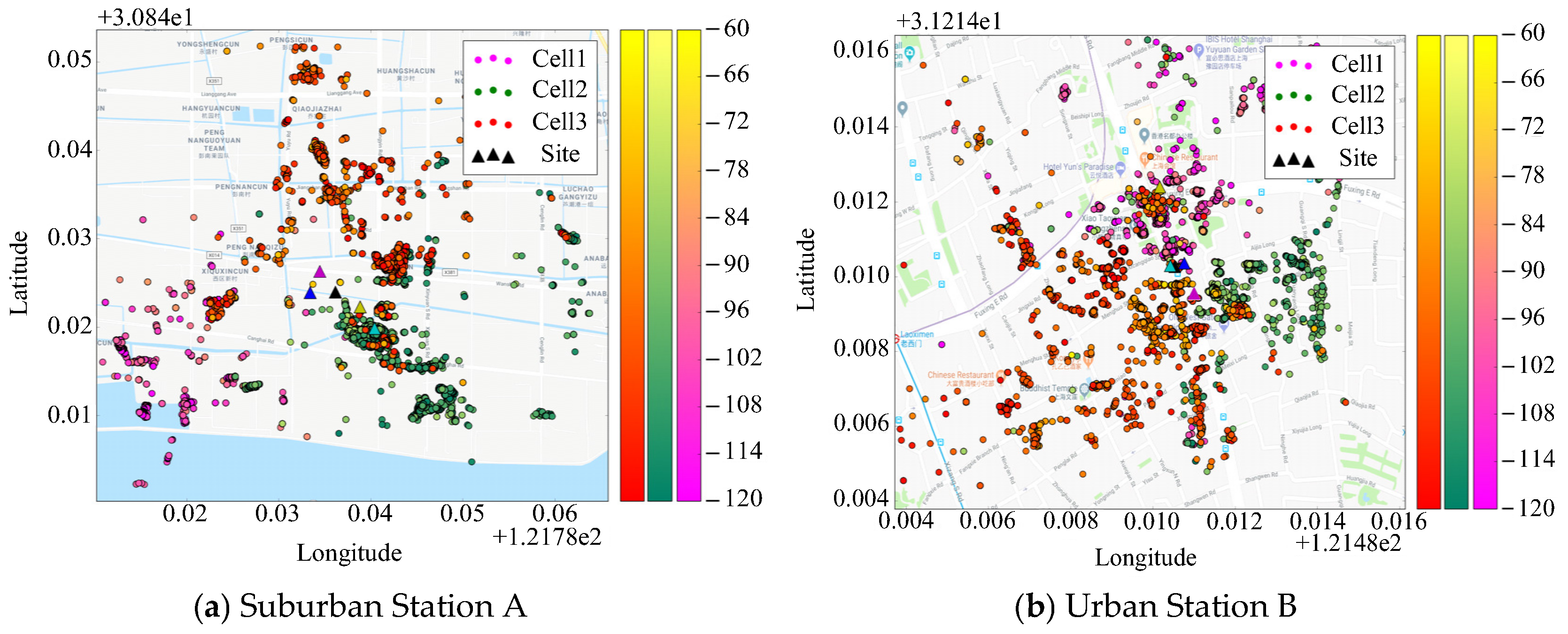
One big advantage of the MCS data is spatial homogeneity. As we know, that the samples of wardriving concentrate only on the main roads around the cell. The non-homogeneous spatial distribution of samples always leads to serious deviation of cell location estimation from the actual location. In our data acquisition scenario; however, since the data are acquired from massive number of users throughout the network, the distribution of samples are more homogeneous.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}