Improved Classification Method Based on the Diverse Density and Sparse Representation Model for a Hyperspectral Image

Abstract
:1. Introduction
2. Methodology
2.1. Dictionary Learning Based on DD Algorithm
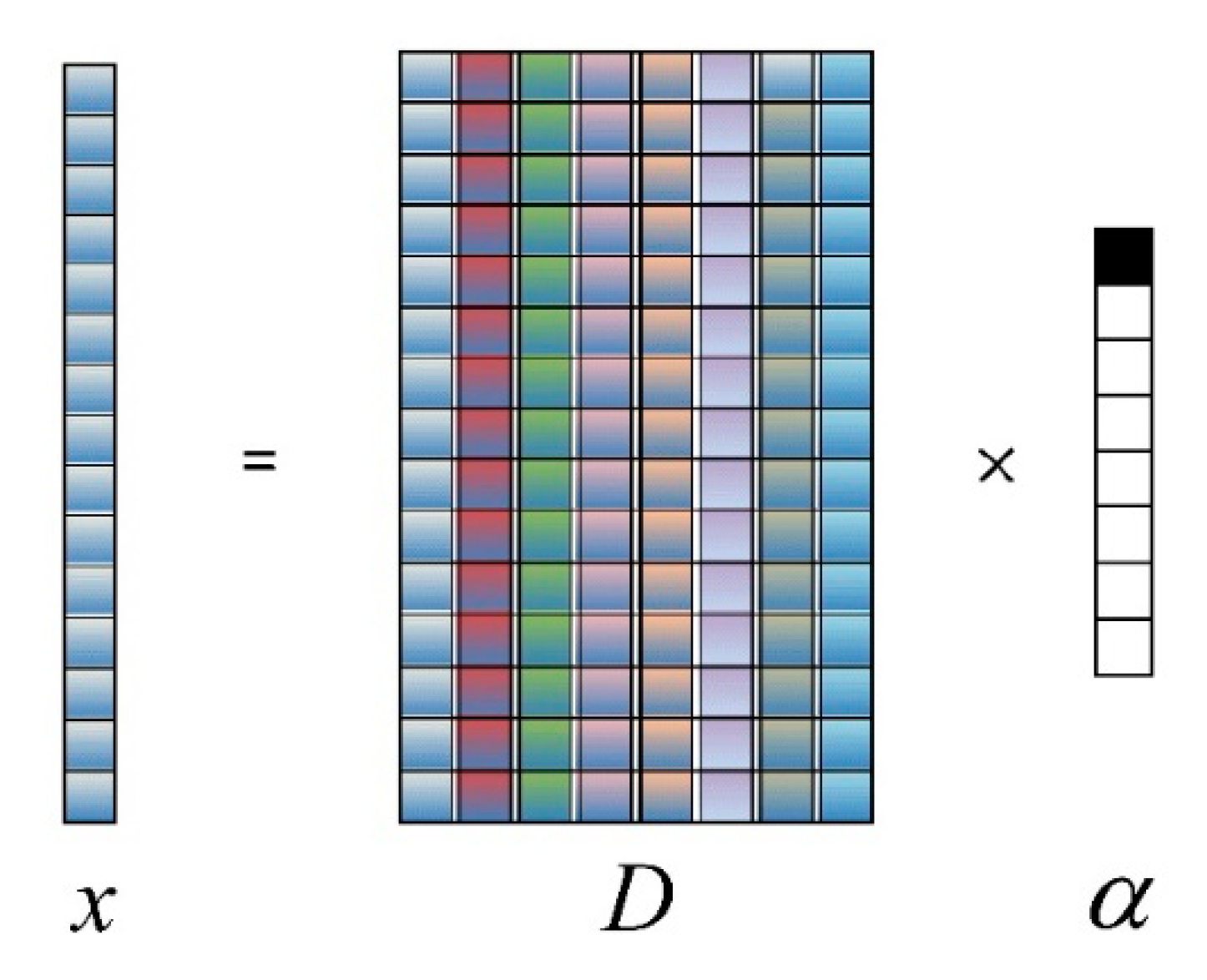
2.2. Constraint-Based Sparse Representation
2.3. NCM_DDSR Algorithm
| Algorithm 1 Novel classification method based on diverse density and sparse representation |
| Inputs: Positive bag and negative bag for hyperspectral images; Pi is the number of the i-th training sample bags; i = {1, …, N} is the number of bags; j = {1, …, Pi} is the number of instances; b = {1, …, P} is the number of training samples; x is a pixel to be sparse represented; is an atom in the dictionary D; Rx is the current residual Step 1 Diverse Density. for b = 1, …, P for j = 1, …, N for i = 1, …, Pi Judge the sample package based on (2), (3) end for Calculate the tmax based on (1) end for Compare to find the largest tmax end for Step 2 Use the Diverse Density algorithm to obtain labels and feature vectors to build a dictionary D. Step 3 Sparse representation. do {Select which maximizes ||} while ( is positive) do {Calculate the atomic coefficients based on (11)} while (The sum of the atomic coefficients is equal to 1) Step 4 Determine the class label of every test pixel. Outputs: The classification map. |
3. Experiment
3.1. PHI Image
3.2. AVIRIS Image
4. Discussion
4.1. PHI Image
4.2. AVIRIS Image
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Kumar, S.; Ghosh, J.; Crawford, M.M. Best-bases feature extraction algorithms for classification of hyperspectral data. IEEE Trans. Geosci. Remote Sens. 2001, 39, 1368–1379. [Google Scholar] [CrossRef] [Green Version]
- Prasad, S.; Bruce, L.M. Hyperspectral feature space partitioning via mutual information for data fusion. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Barcelona, Spain, 23–28 July 2007. [Google Scholar]
- Melgani, F.; Bruzzone, L.; Crawford, M.M. Classification of hyperspectral remote sensing images with support vector machines. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1778–1790. [Google Scholar] [CrossRef] [Green Version]
- Li, S.; Zhang, X.; Jia, X.; Wu, H. Fusion multiscale super-pixel features for classification of hyperspectral images. In Proceedings of the 8th Workshop on Hyperspectral Image and Signal Processing: Evolution in Remote Sensing, Los Angeles, CA, USA, 21–24 August 2016. [Google Scholar]
- Chen, Y.; Li, R.; Yang, G.; Sun, L.; Wang, J. Deep feature extraction and classification of hyperspectral images based on convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef] [Green Version]
- Ma, Y.; Li, R.; Yang, G.; Sun, L.; Wang, J. A Research on the Combination Strategies of Multiple Features for Hyperspectral Remote Sensing Image Classification. J. Sens. 2018, 1–14. [Google Scholar] [CrossRef]
- Kishore, M.; Kulkarni, S.B. Approaches and challenges in classification for hyperspectral data: A review. In Proceedings of the International Conference on Electrical, Electronics, and Optimization Techniques, Chennai, India, 3–5 March 2016. [Google Scholar]
- Zhang, C.; Wang, J.; Zhang, Y. Small-sample classification of hyperspectral data in a graph-based semi-supervision framework. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Fort Worth, TX, USA, 23–28 July 2017. [Google Scholar]
- Prasad, S.; Bruce, L.M. Overcoming the small sample size problem in hyperspectral classification and detection tasks. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Boston, MA, USA, 8–11 July 2008. [Google Scholar]
- Pan, B.; Shi, Z.; Xu, X. MugNet: Deep learning for hyperspectral image classification using limited samples. ISPRS J. Photogramm. Remote Sens. 2018, 145, 108–119. [Google Scholar] [CrossRef]
- Groves, P. Methodology for hyperspectral band selection. Photogram. Eng. Remote Sens. 2004, 70, 793–802. [Google Scholar]
- Wang, J.; Zhang, R.; Wu, Q. Hyperspectral image classification based on PCA network. In Proceedings of the 8th Workshop on Hyperspectral Image and Signal Processing: Evolution in Remote Sensing, Los Angeles, CA, USA, 21–24 August 2016. [Google Scholar]
- Guo, X.; Huang, L.; Zhang, L.; Plaza, A.; Benediktsson, J.A. Support tensor machines for classification of hyperspectral remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2016, 54, 3248–3264. [Google Scholar] [CrossRef]
- Chi, M.; Bruzzone, L. Semisupervised classification of hyperspectral images by SVMs optimized in the primal. IEEE Trans. Geosci. Remote Sens. 2007, 45, 1870–1880. [Google Scholar] [CrossRef]
- Gu, Y.; Wang, C.; You, D.; Tran, T.D. Representative multiple kernel learning for classification in hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2012, 50, 2852–2865. [Google Scholar] [CrossRef]
- Zhao, C.; Li, W.; Qi, B. Representative multiple kernel learning for classification in hyperspectral imagery. Optik 2015, 126, 5633–5640. [Google Scholar]
- Tu, B.; Zhang, X.; Kang, X.; Zhang, G.; Wang, J.; Wu, J. Hyperspectral image classification via fusing correlation coefficient and joint sparse representation. IEEE Geosci. Remote Sens. Lett. 2018, 15, 340–344. [Google Scholar] [CrossRef]
- Chen, Y.; Nasrabadi, N.M.; Tran, T.D. Hyperspectral Image Classification Using Dictionary-Based Sparse Representation. IEEE Trans. Geosci. Remote Sens. 2011, 49, 3973–3985. [Google Scholar] [CrossRef]
- Zhao, Y.; Yang, J. Hyperspectral Image Denoising via Sparse Representation and Low-Rank Constraint. IEEE Trans. Geosci. Remote Sens. 2015, 53, 296–308. [Google Scholar] [CrossRef]
- Fu, Y.; Lam, A.; Sato, I.; Sato, Y. Adaptive Spatial-Spectral Dictionary Learning for Hyperspectral Image Denoising. In Proceedings of the International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Zhang, L.; Wei, W.; Zhang, Y.; Shen, C.; van den Hengel, A.; Shi, Q. Cluster Sparsity Field: An Internal Hyperspectral Imagery Prior for Reconstruction. Int. J. Comput. Vis. 2018, 126, 797–821. [Google Scholar] [CrossRef]
- Fang, L.; Zhuo, H.; Li, S. Super-resolution of hyperspectral image via superpixel-based sparse representation. Neurocomputing 2018, 273, 171–177. [Google Scholar] [CrossRef]
- Qin, Z.; Fan, J.; Liu, Y.; Gao, J.; Li, G.Y. Sparse representation for wireless communications: A compressive sensing approach. IEEE Signal Process. Mag. 2018, 35, 40–58. [Google Scholar] [CrossRef] [Green Version]
- Liu, S.; Liu, M.; Li, P.; Zhao, J.; Zhu, Z.; Wang, X. SAR image denoising via sparse representation in shearlet domain based on continuous cycle spinning. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2985–2992. [Google Scholar] [CrossRef]
- Vladimir, V.; Kozoderov, E.; Dmitriev, V. Testing different classification methods in airborne hyperspectral imagery processing. Opt. Express 2016, 24, A956–A965. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | PCA_MinD | SVM | NCM_DDSR |
|---|---|---|---|
| Water (%) | 92.83 ± 1.76 | 85.00 ± 1.73 | 89.33 ± 4.54 |
| Paddy (%) | 75.00 ± 0.00 | 58.50 ± 0.00 | 99.50 ± 0.00 |
| Caraway (%) | 100.0 ± 0.00 | 86.67 ± 23.0 | 100.0 ± 0.00 |
| Wild-grass (%) | 89.67 ± 4.62 | 94.67 ± 1.15 | 90.67 ± 1.53 |
| Pachyrhizus (%) | 80.00 ± 1.73 | 77.67 ± 1.15 | 83.00 ± 5.20 |
| Tea (%) | 97.67 ± 1.53 | 98.33 ± 2.89 | 100.0 ± 0.00 |
| Bamboo (%) | 75.33 ± 8.14 | 87.67 ± 8.50 | 73.00 ± 6.08 |
| Overall accuracy (%) | 86.48 ± 1.67 | 81.33 ± 1.86 | 91.59 ± 1.77 |
| Kappa coefficient | 0.840 ± 0.02 | 0.779 ± 0.02 | 0.897 ± 0.02 |
| Method | Overall Accuracy (%) | Kappa Coefficient |
|---|---|---|
| PCA_MinD | 68.16 ± 7.19 | 0.61 ± 0.09 |
| SVM | 60.50 ± 1.48 | 0.52 ± 0.02 |
| NCM_DDSR | 92.83 ± 1.02 | 0.91 ± 0.01 |
| Category | PCA_MinD | SVM | NCM_DDSR |
|---|---|---|---|
| Water (%) | 93.67 ± 0.76 | 84.83 ± 1.44 | 95.1 ± 0.29 |
| Paddy (%) | 83.33 ± 4.04 | 81.50 ± 0.50 | 99.33 ± 0.58 |
| Caraway (%) | 100.0 ± 0.00 | 98.67 ± 2.31 | 100.0 ± 0.00 |
| Wild-grass (%) | 89.67 ± 4.73 | 96.33 ± 1.15 | 85.33 ± 6.35 |
| Pachyrhizus (%) | 82.00 ± 2.65 | 85.00 ± 5.29 | 97.00 ± 0.00 |
| Tea (%) | 95.33 ± 1.53 | 94.67 ± 4.16 | 94.33 ± 4.04 |
| Bamboo (%) | 69.00 ± 5.20 | 86.00 ± 8.19 | 61.33 ± 13.2 |
| Overall accuracy (%) | 87.78 ± 1.25 | 88.14 ± 0.74 | 91.88 ± 1.54 |
| Kappa coefficient | 0.850 ± 0.02 | 0.858 ± 0.01 | 0.900 ± 0.02 |
| Category | PCA_MinD | SVM | NCM_DDSR |
|---|---|---|---|
| Water (%) | 93.00 ± 0.00 | 84.00 ± 0.00 | 93.67 ± 2.36 |
| Paddy (%) | 91.50 ± 6.93 | 98.17 ± 1.15 | 98.50 ± 0.87 |
| Caraway (%) | 100.0 ± 0.00 | 100.0 ± 0.00 | 100.0 ± 0.00 |
| Wild-grass (%) | 87.00 ± 1.00 | 96.33 ± 0.58 | 86.67 ± 5.86 |
| Pachyrhizus (%) | 84.33 ± 2.08 | 87.33 ± 3.79 | 89.67 ± 6.03 |
| Tea (%) | 95.33 ± 2.31 | 98.67 ± 1.15 | 98.67 ± 1.15 |
| Bamboo (%) | 76.33 ± 1.53 | 85.33 ± 6.66 | 68.67 ± 6.43 |
| Overall accuracy (%) | 90.22 ± 1.75 | 92.44 ± 0.70 | 92.00 ± 1.61 |
| Kappa coefficient | 0.880 ± 0.02 | 0.903 ± 0.01 | 0.902 ± 0.02 |
| Ratio of Sample to Band Number | 0.5 | 1 | 1.5 | |||
|---|---|---|---|---|---|---|
| Accuracy Evaluation Index | Overall Accuracy | Κ Coefficient | Overall Accuracy | Κ Coefficient | Overall Accuracy | Κ Coefficient |
| PCA_MinD | 86.48% | 0.840 | 87.78% | 0.850 | 90.22% | 0.880 |
| SVM | 81.33% | 0.779 | 88.14% | 0.858 | 92.44% | 0.903 |
| NCM_DDSR | 91.59% | 0.897 | 91.88% | 0.900 | 92% | 0.902 |
| Ratio of Sample to Band Number | 0.5 | 1 | 1.5 | |||
|---|---|---|---|---|---|---|
| Accuracy Evaluation Index | Overall Accuracy | Κ Coefficient | Overall Accuracy | Κ Coefficient | Overall Accuracy | Κ Coefficient |
| PCA_MinD | 68.16% | 0.61 | 84.05% | 0.81 | 87.88% | 0.85 |
| SVM | 60.50% | 0.52 | 72.11% | 0.66 | 79.94% | 0.75 |
| NCM_DDSR | 92.83% | 0.91 | 92.94% | 0.91 | 92.50% | 0.90 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, N.; Wang, R.; Zhao, H.; Wang, M.; Deng, K.; Wei, W. Improved Classification Method Based on the Diverse Density and Sparse Representation Model for a Hyperspectral Image. Sensors 2019, 19, 5559. https://doi.org/10.3390/s19245559
Li N, Wang R, Zhao H, Wang M, Deng K, Wei W. Improved Classification Method Based on the Diverse Density and Sparse Representation Model for a Hyperspectral Image. Sensors. 2019; 19(24):5559. https://doi.org/10.3390/s19245559
Chicago/Turabian StyleLi, Na, Ruihao Wang, Huijie Zhao, Mingcong Wang, Kewang Deng, and Wei Wei. 2019. "Improved Classification Method Based on the Diverse Density and Sparse Representation Model for a Hyperspectral Image" Sensors 19, no. 24: 5559. https://doi.org/10.3390/s19245559