An Audification and Visualization System (AVS) of an Autonomous Vehicle for Blind and Deaf People Based on Deep Learning

Abstract
:1. Introduction
2. Related Works
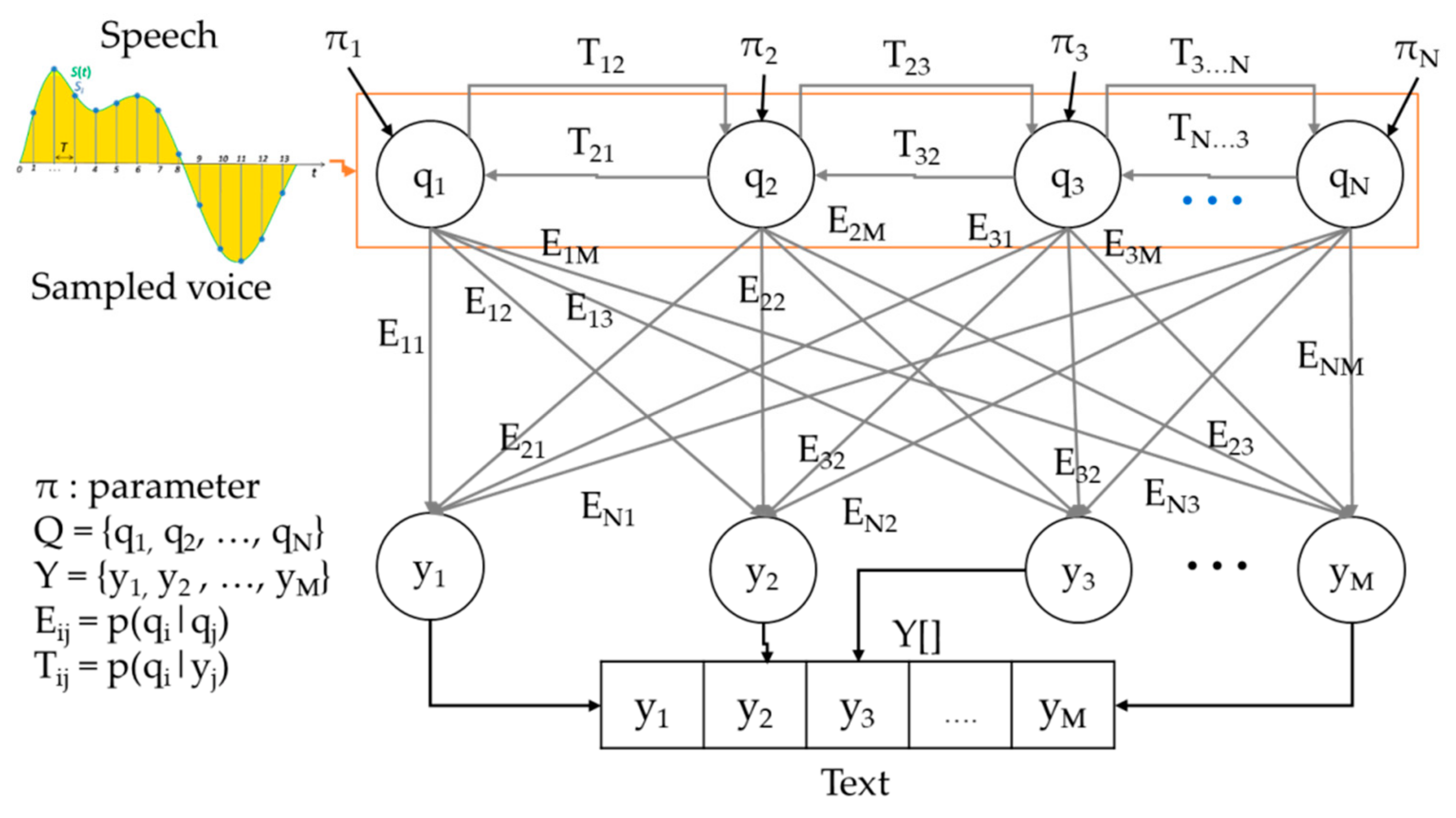
2.1. Hidden Markov Model
2.2. Vehicle for Disabilities
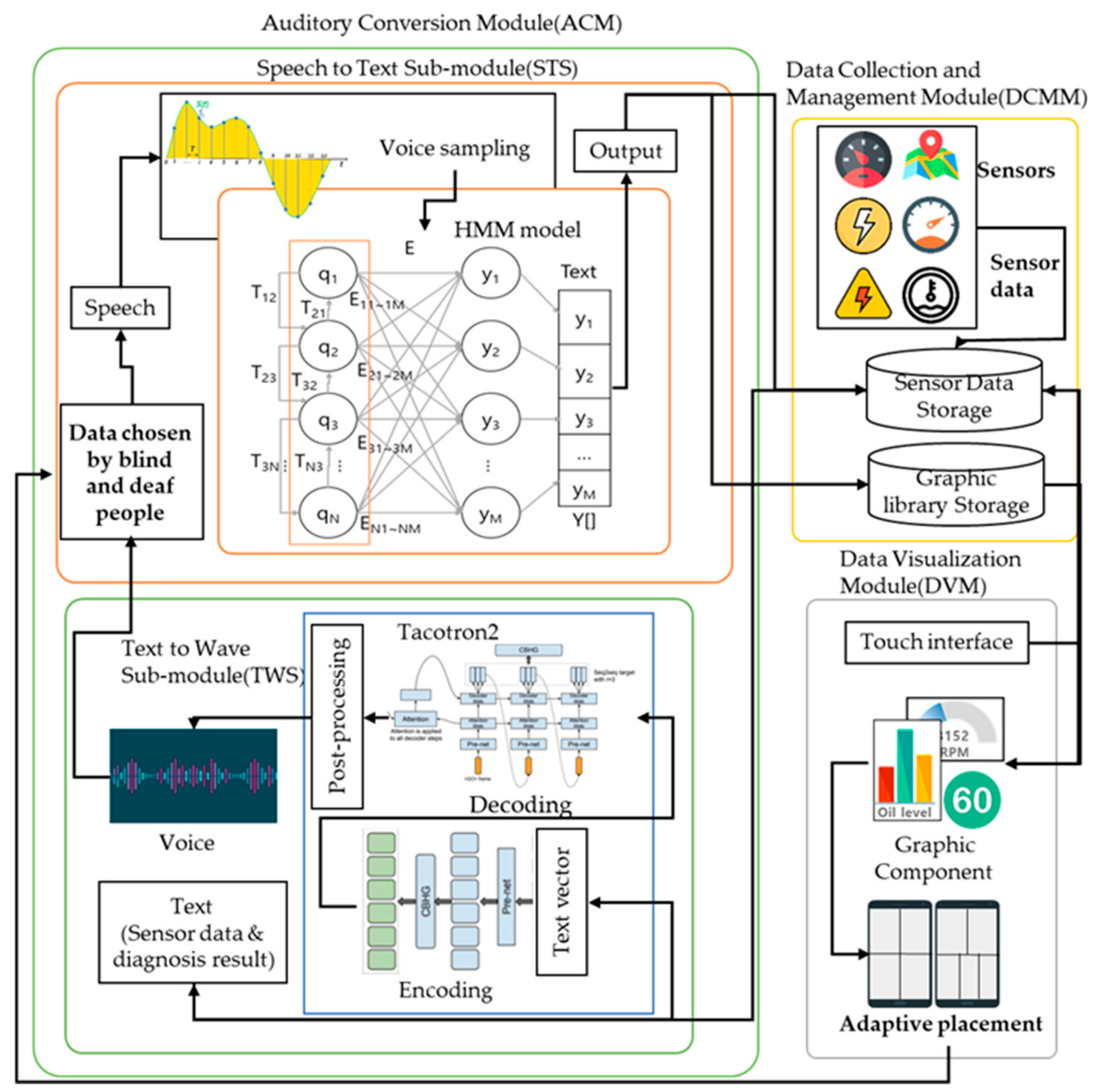
3. Proposed Method
3.1. Overview
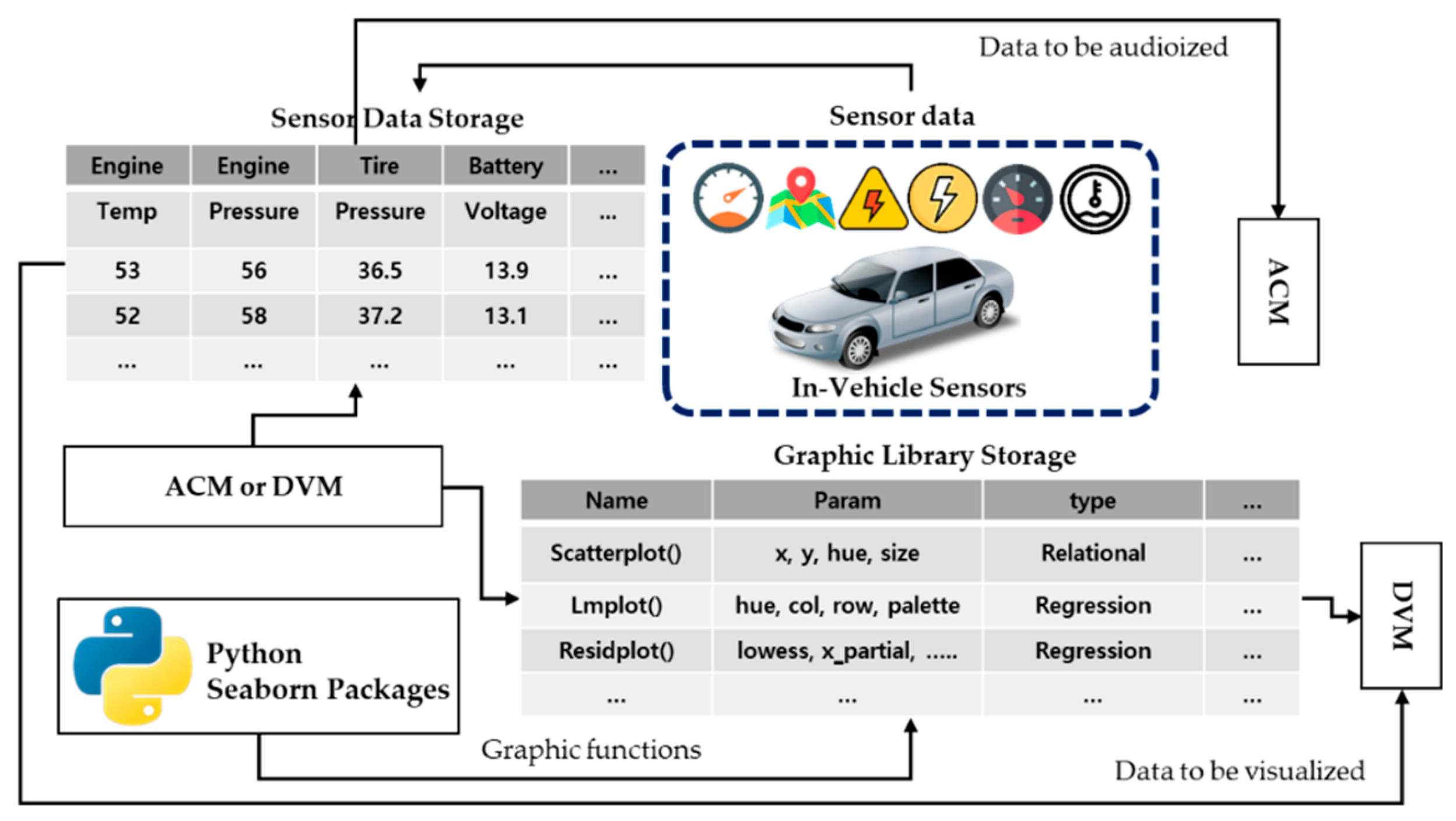
3.2. Design of a Data Collection and Management Module
3.3. Design of an Auditory Conversion Module
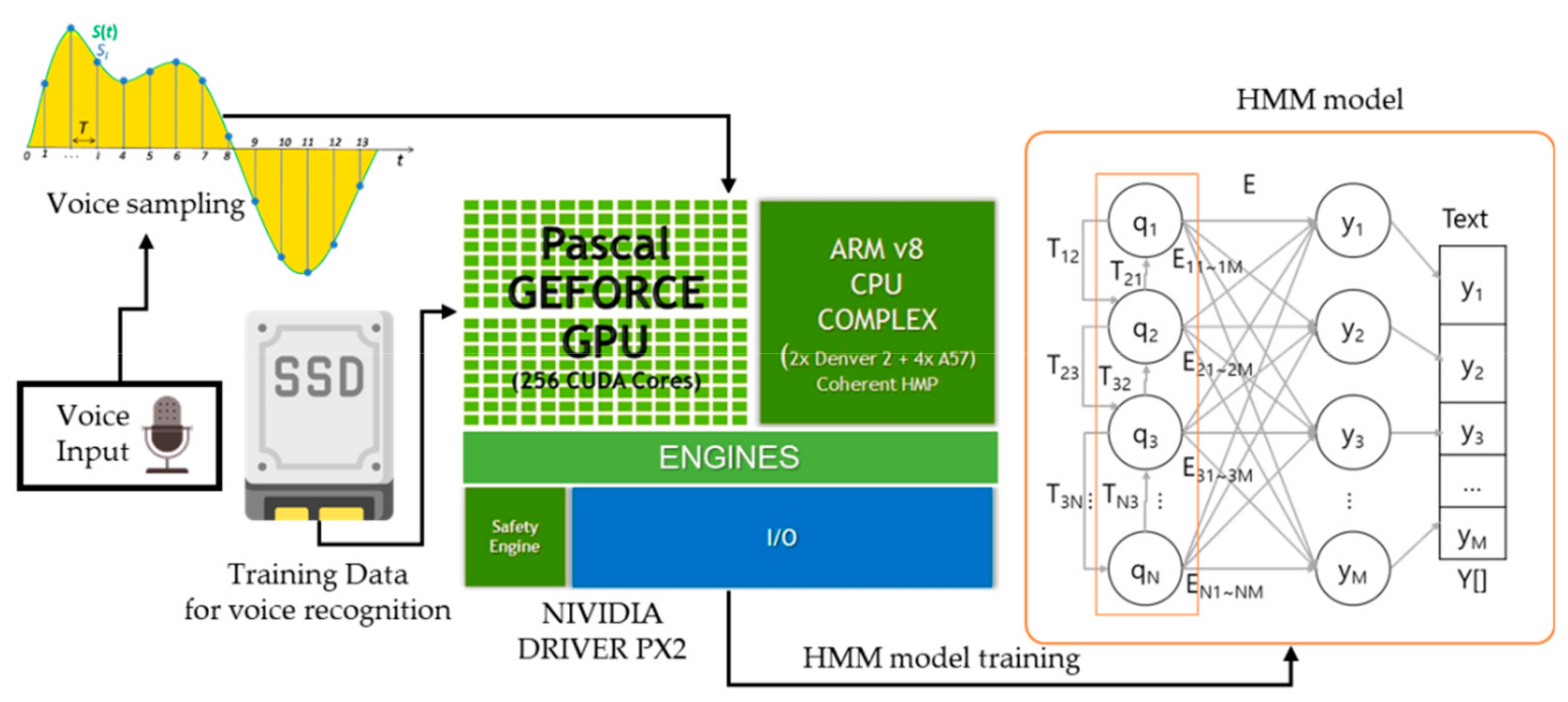
3.3.1. Speech-to-Text Submodule (STS)
| Algorithm 1. Computation of observed values and array of states. |
| Input: initial probabilities π, transition probabilities T, emission probabilities E, number of states N, observation Y = ; Forward(π, T, E, Y){ for(j=1; jN; j++){ } for(t=2; t<=T, t++){ for(j=1; j<=N; j++){ } } p(Y|π, T, E) = return p(Y|π, T, E) } Viterbi(π, T, E, Y){ for(j=1; j<=N; j++){ } for(t = 2; t<=T, t++){ for(j=1; j<=N; j++){ S[t] = } } return S[] } |
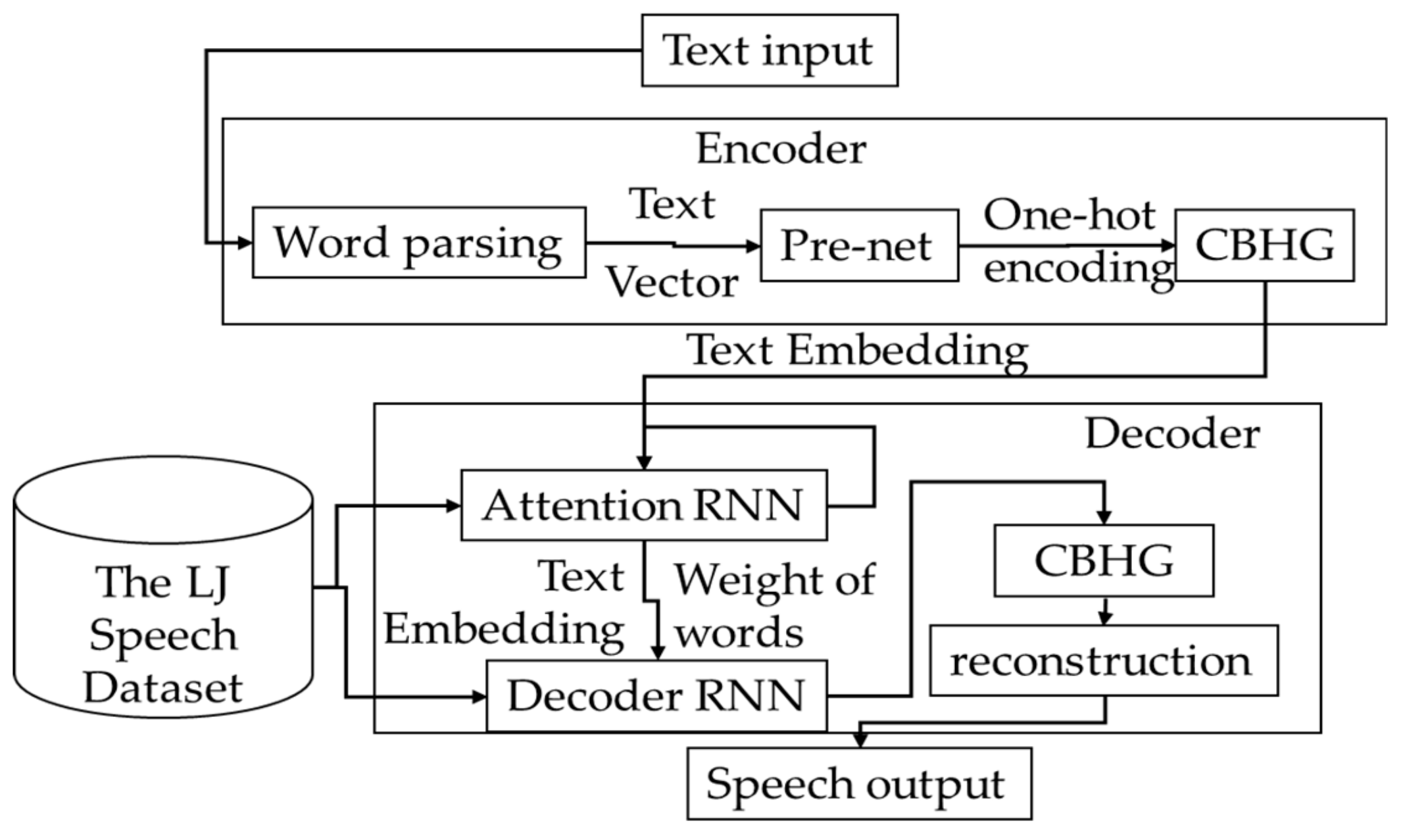
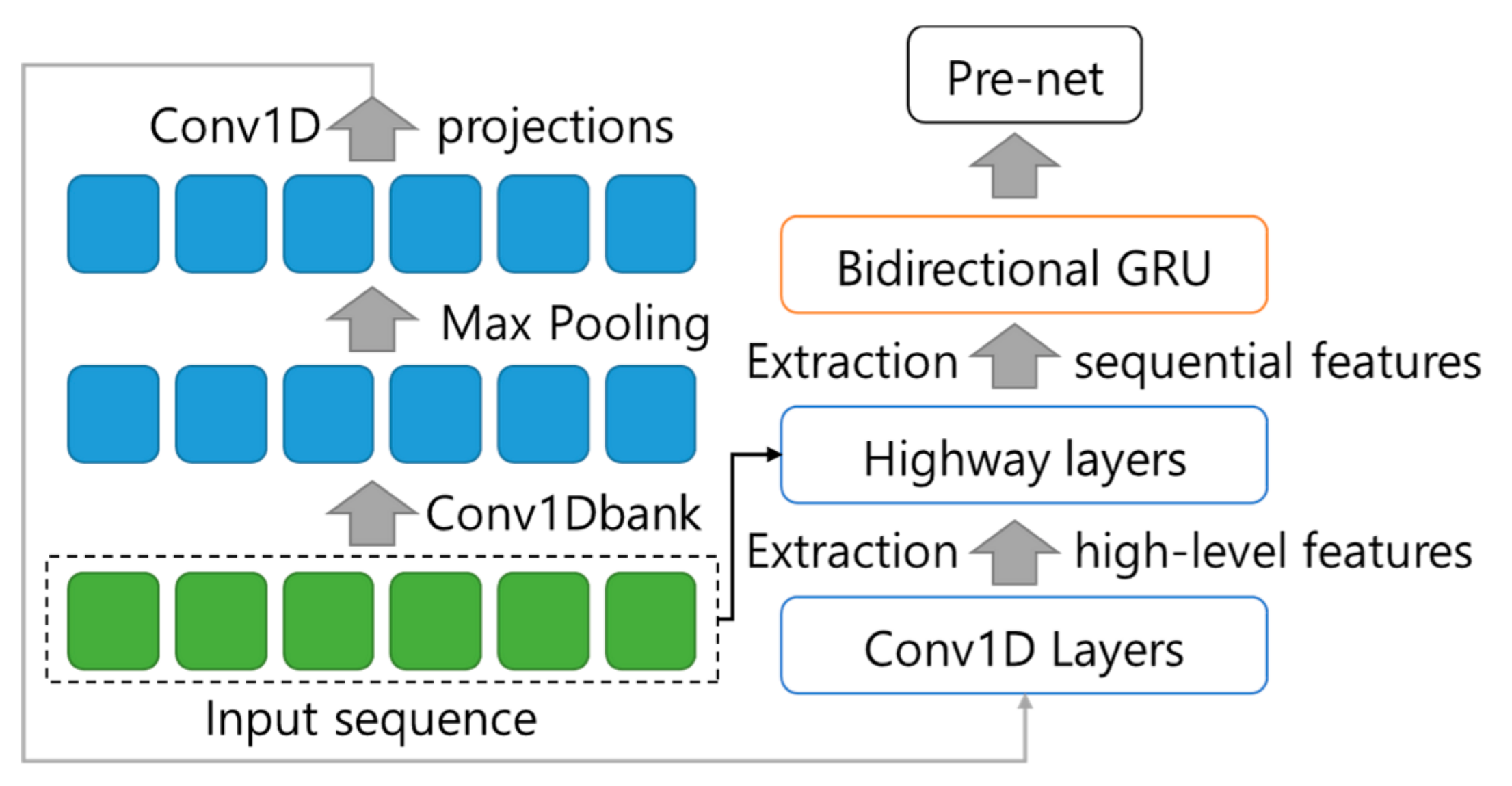
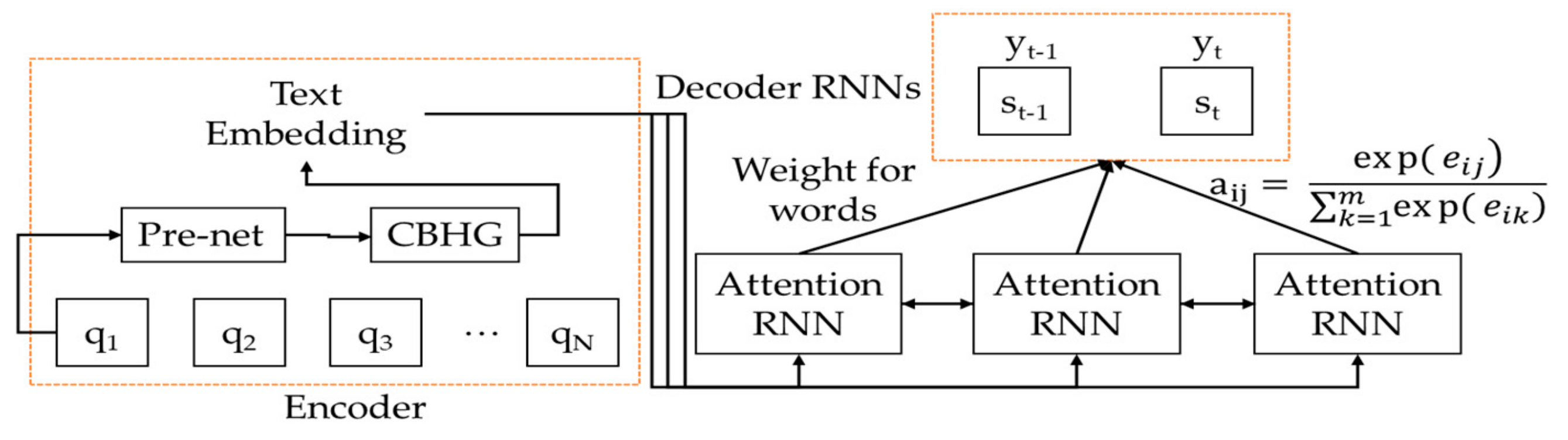
3.3.2. Text-to-Wave Submodule
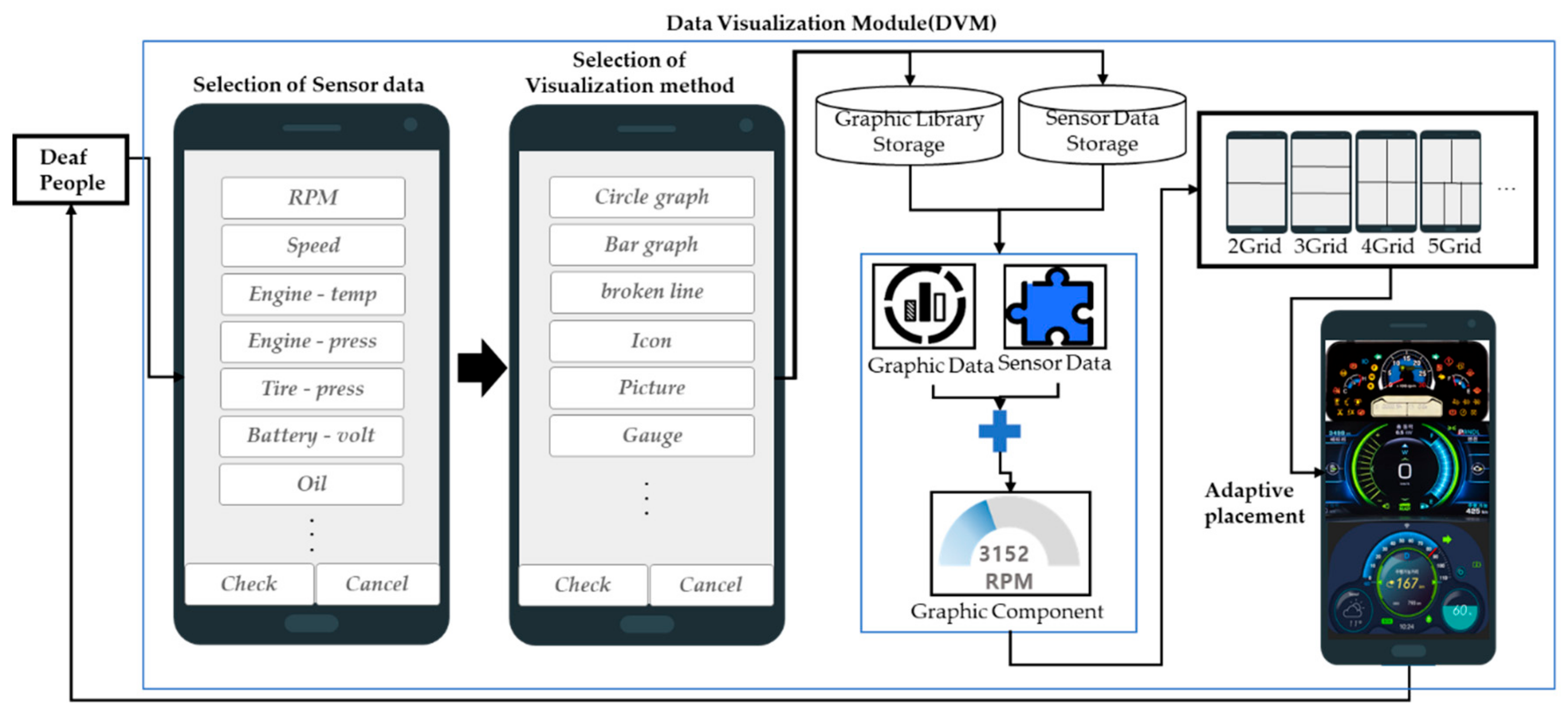
3.4. Design of a Data Visualization Module
| Algorithm 2. Data visualization algorithm. |
| input: int number_kind, list data_value[], String data_name[], String graph_name; init: Button check_sensors[number_kind]; List graph[]; List param_data[]; int k=0; for(int i = 0; i<kind; i++){ check_sensors[i]=data_value[data_name[i]]; check_sensors.enable; } if(ClickEvent(data_name) && ClickEvent(graph_name)){ check_sensors[data_name].disable; param[k].input(key : data_value[data_name],value : graph[graph_name],); } if(ClickEvent(send)){ send(param[]); } if(ClickEvent(cancel)){ check_sensors[data_name].enable; param[k].delete(key : data_value[data_name],value : graph[graph_name],); } |
| Algorithm 3. Adaptive component placement. |
| SetComponent(Object[] component[], int compNumber, int compX[], int compY[]){ int i = 0; Rect grid[] = GridPartition(compNumber, vertical, 1.5); for(i = 0; i<= compNumber; i++){ if(compNumber == 1) displayComponent(component[i], grid[i]); else{ if((compX[i]<compY[i]) && (grid[i].x<grid[i].y)){ displayComponent(component[i], grid[i]); } elseif((compX[i]>compY[i]] && (grid[i].y<grid[i].x)){ displayComponent(component[i], grid[i]); } elsief((compX[i]<compY[i]] && (grid[i].y<grid[i].x) && (component[i].type == digit)){ component[i] = ReplaceXandY(component[i]); displayComponent(component[i], grid[i]); } else if((compX[i]<compY[i]) && (grid[i].y<grid[i].x) && (component[i].type != digit)){ grid[i] = ReplaceGrid(horizontal, 1.5); displayComponent(component[i], grid[i]); }}}} |
4. Performance Analysis
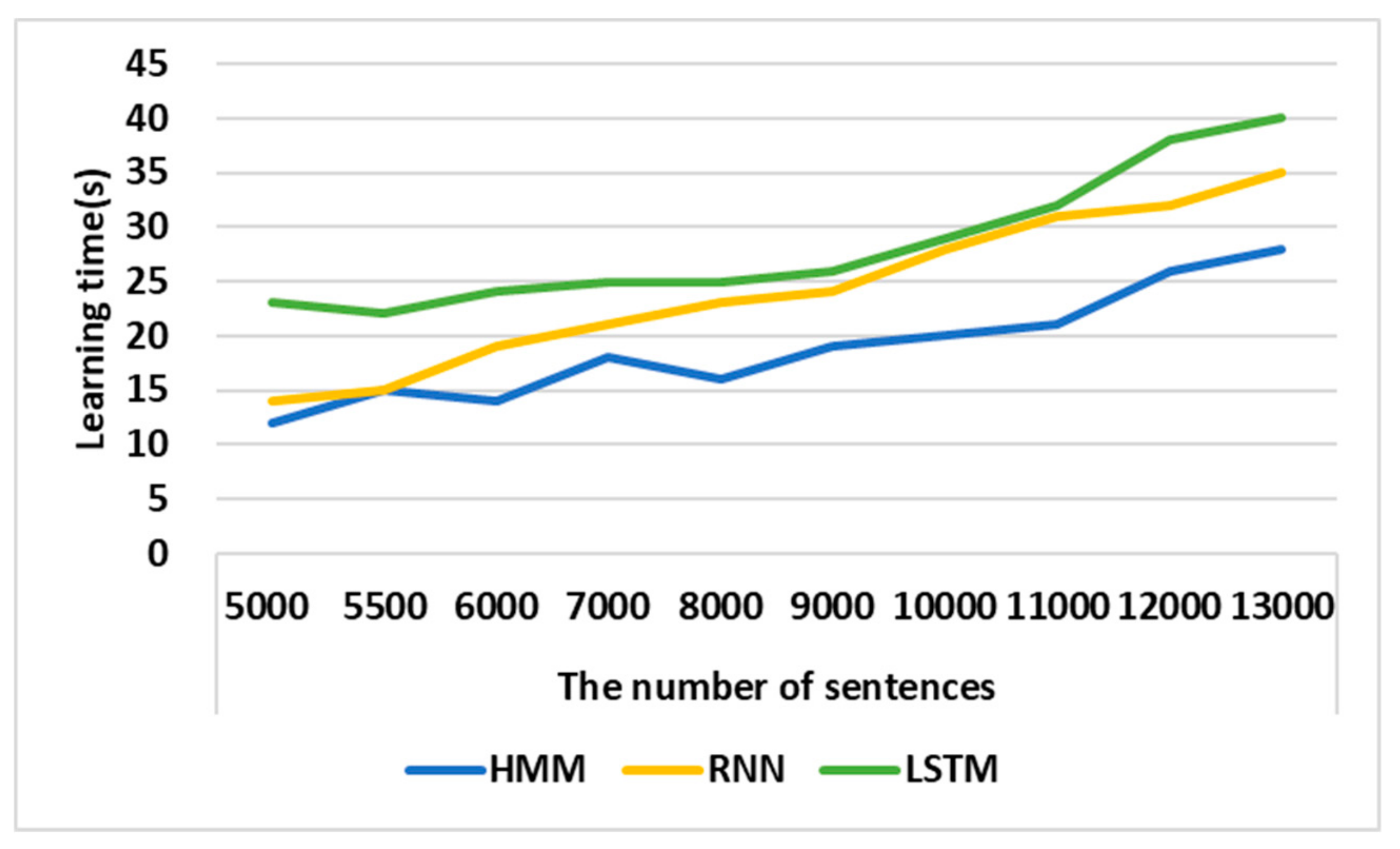
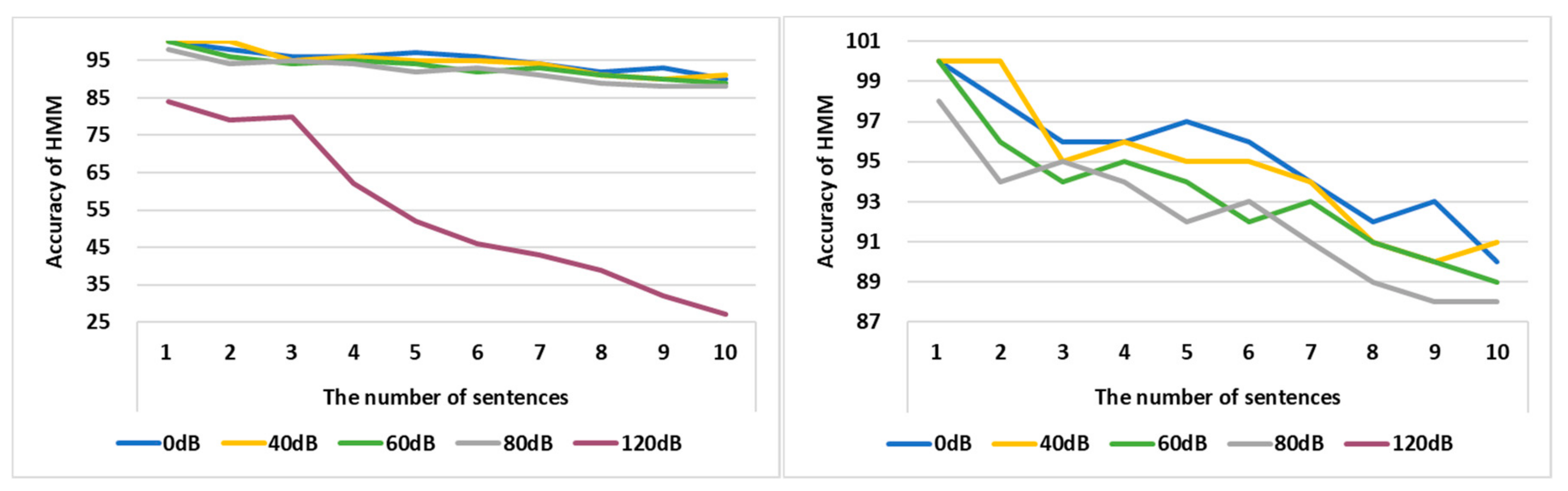
4.1. Performance Analysis of HMM Learning
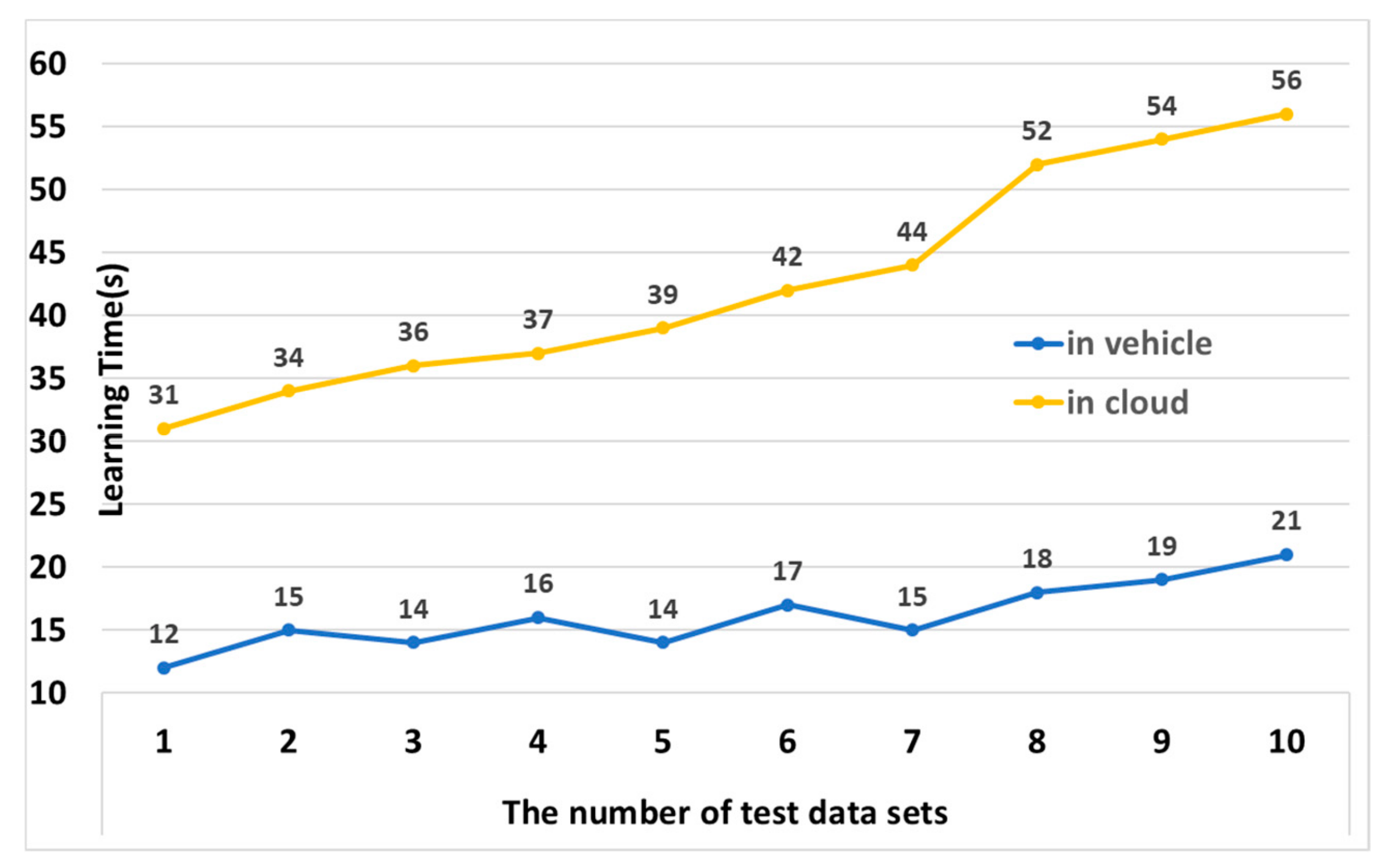
4.2. Performance Analysis of STS
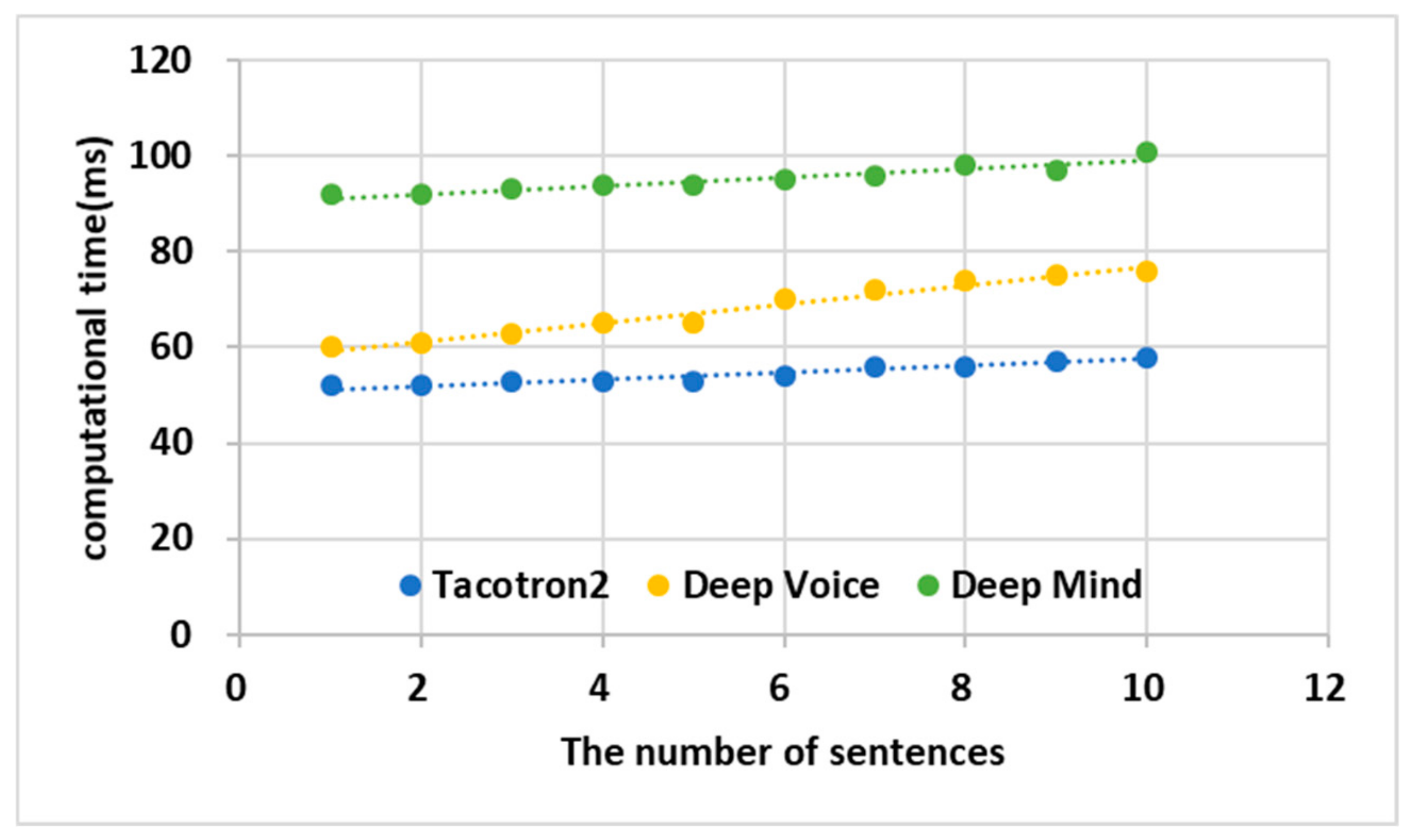
4.3. Performance Analysis of TWS
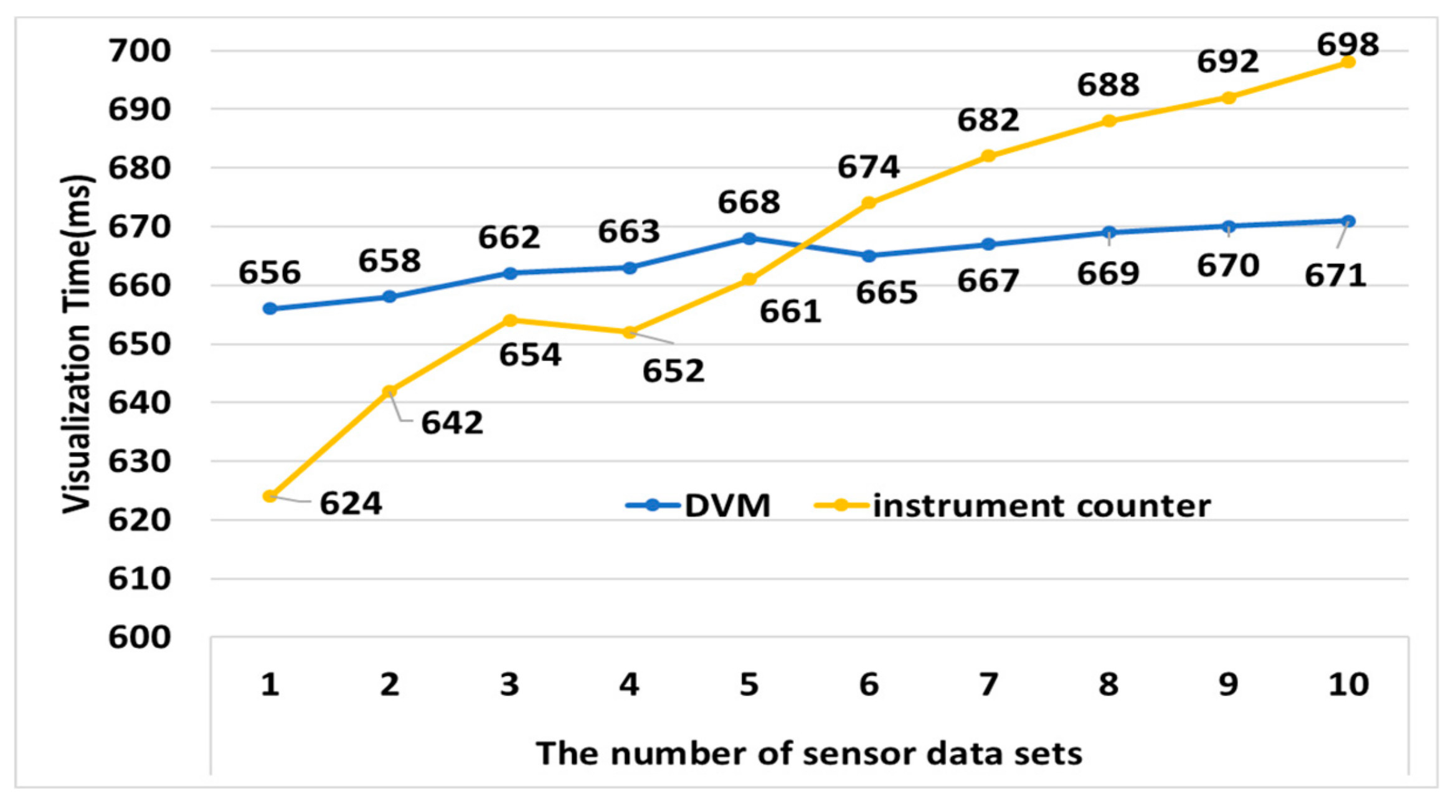
4.4. Performance Analysis of DVM
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- SAE International(www.sae.org). Levels of Driving Automation. Available online: https://www.sae.org/news/press-room/2018/12/sae-international-releases-updated-visual-chart-for-its-%E2%80%9Clevels-of-driving-automation%E2%80%9D-standard-for-self-driving-vehicles (accessed on 12 September 2019).
- Lee, D. Google Self-Driving Car Hits a Bus. Available online: https://www.bbc.com/news/technology-35692845 (accessed on 5 November 2019).
- Bevilacqua, M. Cyclist Killed by Tesla Car with Self-Driving Features. Available online: https://www.bicycling.com/news/a20034037/cyclist-killed-by-tesla-car-with-self-driving-features/ (accessed on 5 November 2019).
- Halsey, A., III; Laris, M. Blind Man Sets Out Alone in Google’s Driverless Car. Available online: https://www.washingtonpost.com/local/trafficandcommuting/blind-man-sets-out-alone-in-googles-driverless-car/2016/12/13/f523ef42-c13d-11e6-8422-eac61c0ef74d_story.html (accessed on 24 September 2019).
- Li, K.; Wang, X.; Xu, Y.; Wang, J. Lane changing intention recognition based on speech recognition models. Transp. Res. Part C Emerg. Technol. 2016, 69, 497–514. [Google Scholar] [CrossRef]
- Stamp, M. A Revealing Introduction to Hidden Markov Models; San Jose State University: San Jose, CA, USA, 2018; pp. 1–21. [Google Scholar]
- Liang, J.; Ma, M.; Sadiq, M.; Yeung, K.-H. A filter model for intrusion detection system in Vehicle Ad Hoc Networks: A hidden Markov methodology. Knowl.-Based Syst. 2019, 163, 611–623. [Google Scholar] [CrossRef]
- Saini, R.; Roy, P.P.; Dogra, D.P. A segmental HMM based trajectory classification using genetic algorithm. Expert Syst. Appl. 2018, 93, 169–181. [Google Scholar] [CrossRef]
- Siddique, C.; Ban, X. (Jeff) State-dependent self-adaptive sampling (SAS) method for vehicle trajectory data. Transp. Res. Part C Emerg. Technol. 2019, 100, 224–237. [Google Scholar] [CrossRef]
- Liu, P.; Kurt, A.; Ozguner, U. Synthesis of a behavior-guided controller for lead vehicles in automated vehicle convoys. Mechatronics 2018, 50, 366–376. [Google Scholar] [CrossRef]
- Mingote, V.; Miguel, A.; Ortega, A.; Lleida, E. Supervector Extraction for Encoding Speaker and Phrase Information with Neural Networks for Text-Dependent Speaker Verification †. Appl. Sci. 2019, 9, 3295. [Google Scholar] [CrossRef]
- Wang, X.; Cong, Z.; Fang, L. Determination of Real-time Vehicle Driving Status Using HMM. Acta Autom. Sin. 2014, 39, 2131–2142. [Google Scholar] [CrossRef]
- Kato, J.; Watanabe, T.; Joga, S.; Liu, Y.; Hase, H. An HMM/MRF-Based Stochastic Framework for Robust Vehicle Tracking. IEEE Trans. Intell. Transp. Syst. 2004, 5, 142–154. [Google Scholar] [CrossRef]
- Xiong, X.; Chen, L.; Liang, J. A New Framework of Vehicle Collision Prediction by Combining SVM and HMM. IEEE Trans. Intell. Transp. Syst. 2018, 19, 699–710. [Google Scholar] [CrossRef]
- Jazayeri, A.; Cai, H.; Zheng, J.Y.; Tuceryan, M. Vehicle Detection and Tracking in Car Video Based on Motion Model. IEEE Trans. Intell. Transp. Syst. 2011, 12, 583–595. [Google Scholar] [CrossRef]
- Choromański, W.; Grabarek, I. Driver with Varied Disability Level—Vehicle System: New Design Concept, Construction and Standardization of Interfaces. Procedia Manuf. 2015, 3, 3078–3084. [Google Scholar] [CrossRef]
- Bennett, R.; Vijaygopal, R.; Kottasz, R. Attitudes towards autonomous vehicles among people with physical disabilities. Transp. Res. Part A Policy Pract. 2019, 127, 1–17. [Google Scholar] [CrossRef]
- Bennett, R.; Vijaygopal, R.; Kottasz, R. Willingness of people with mental health disabilities to travel in driverless vehicles. J. Transp. Health 2019, 12, 1–12. [Google Scholar] [CrossRef]
- Xu, X.W.; He, J.Y. Design of Intelligent Guide Vehicle for Blind People. Appl. Mech. Mater. 2013, 268, 1490–1493. [Google Scholar] [CrossRef]
- Jeong, Y.; Son, S.; Lee, B. The Lightweight Autonomous Vehicle Self-Diagnosis (LAVS) Using Machine Learning Based on Sensors and Multi-Protocol IoT Gateway. Sensors 2019, 19, 2534. [Google Scholar] [CrossRef] [PubMed]
- Jeong, Y.; Son, S.; Jeong, E.; Lee, B. An Integrated Self-Diagnosis System for an Autonomous Vehicle Based on an IoT Gateway and Deep Learning. Appl. Sci. 2018, 8, 1164. [Google Scholar] [CrossRef] [Green Version]
- Kenneth, H.C. Lagrange Multipliers for Quadratic Forms with Linear Constraints. Available online: https://www.ece.k-state.edu/people/faculty/carpenter/document/lagrange.pdf (accessed on 5 October 2005).
- Wang, Y.; Skerry-Ryan, R.J.; Stanton, D.; Wu, Y.; Weiss, R.J.; Jaitly, N.; Yang, Z.; Xiao, Y.; Chen, Z.; Bengio, S.; et al. Tacotron: Towards End-to-End Speech Synthesis. arXiv 2017, arXiv:1703.10135. [Google Scholar]
- Ito, K. The LJ Speech Dataset. Available online: https://keithito.com/LJ-Speech-Dataset/ (accessed on 3 September 2019).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Set Name | Set Contents | Meaning |
|---|---|---|
| Q | {q1, q2, …, qN} | Set of hidden states |
| Y | {y1, y2, …, yM} | Set of observed values in a hidden state |
| π | { π1, π2, …, πN|RN} | Set of initial probabilities p(qi) with the probability of initial state qi |
| T | {T12, T21, …., TNM, TMN|RNxN} | Set of transition probabilities p (qj|qi) indicating the probability of moving from qi to qj |
| E | {E11, E12, …, ENM|RNxM} | Set of assignment probabilities p(yj|qi) indicating the probability that yj will occur in qi |
| θ | {π, T, E} | HMM parameter |
| Observed Value | Data Name | Observed Value | Data Name |
|---|---|---|---|
| y1 | Speed | y7 | Driving distance |
| y2 | RPM | y8 | Timing belt |
| y3 | Tire | y9 | Spark plug |
| y4 | Steering wheel | y10 | Air conditioner |
| y5 | Engine oil | y11 | Brake pad |
| y6 | Coolant |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Son, S.; Jeong, Y.; Lee, B. An Audification and Visualization System (AVS) of an Autonomous Vehicle for Blind and Deaf People Based on Deep Learning. Sensors 2019, 19, 5035. https://doi.org/10.3390/s19225035
Son S, Jeong Y, Lee B. An Audification and Visualization System (AVS) of an Autonomous Vehicle for Blind and Deaf People Based on Deep Learning. Sensors. 2019; 19(22):5035. https://doi.org/10.3390/s19225035
Chicago/Turabian StyleSon, Surak, YiNa Jeong, and Byungkwan Lee. 2019. "An Audification and Visualization System (AVS) of an Autonomous Vehicle for Blind and Deaf People Based on Deep Learning" Sensors 19, no. 22: 5035. https://doi.org/10.3390/s19225035