3D Object Recognition Based on Point Clouds in Underwater Environment with Global Descriptors: A Survey


Abstract
:1. Introduction
- Inspection, maintenance and repairing of offshore structures, which are frequently carried out by the oil and gas industries [22].
- Subsea collision avoidance, by using systems to identify and locate a different obstacles [25], for example in the early assessment of accident sites.
- Detection and identification of marine wildlife, with the aim of studying their physical environment [26].
1.1. Objectives and Contributions
1.2. Structure of the Paper
2. Overview of Object Recognition from Point Clouds
2.1. Local Recognition Pipelines
2.2. Global Recognition Pipelines
2.3. Hybrid Recognition Pipelines
3. Global Descriptors
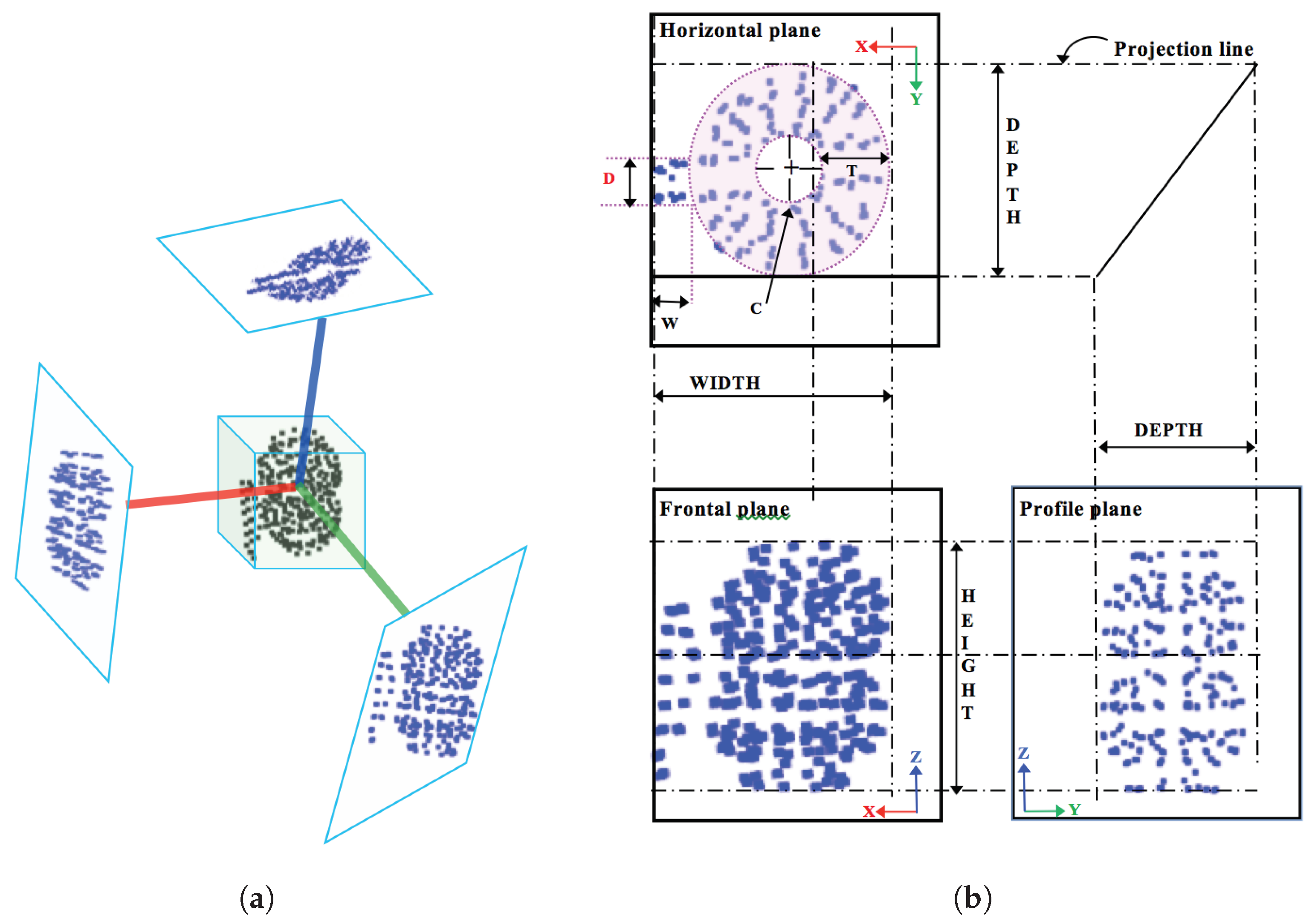
3.1. Global Orthographic Object Descriptor (GOOD)
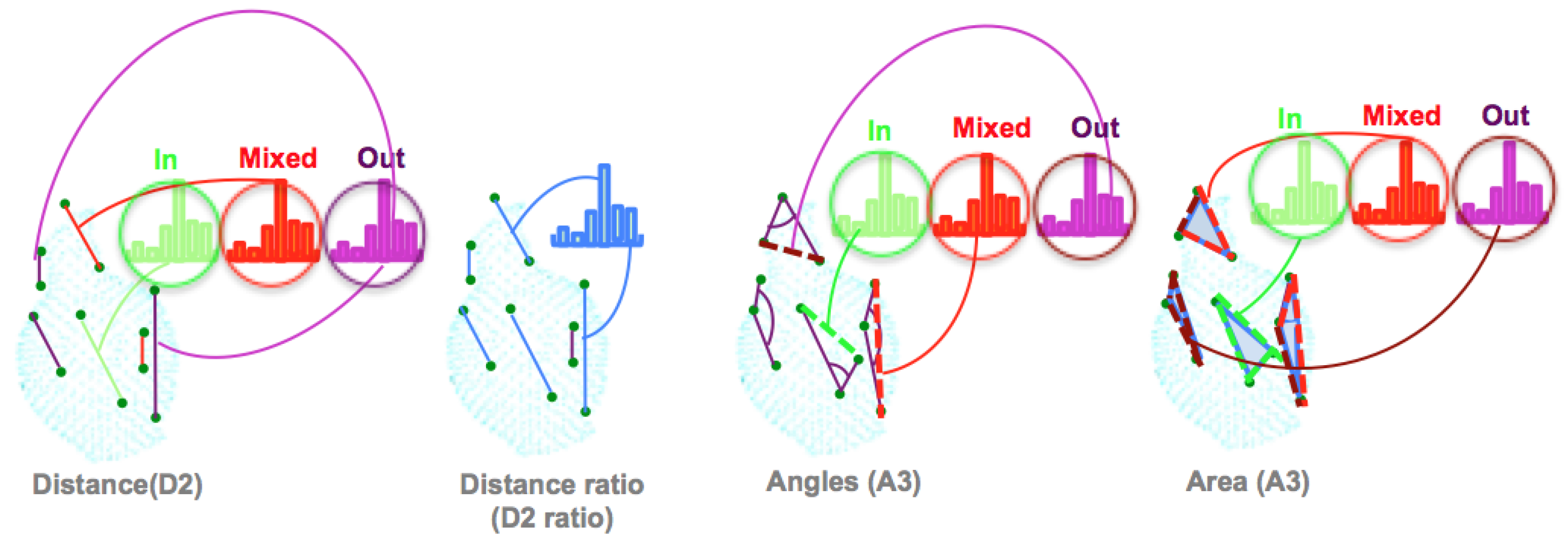
3.2. The Ensemble of Shape Functions (ESF)
- The distance D2: This is the distance calculated between two points, then classified into one of three categories based on whether the connection line falls in the surface, off the surface, or is mixed (with one part in and the other off the surface). To characterize the distribution of the voxels along the line, the authors added the ratio of line distance (D2 ratio). This ratio is equal to zero if the line falls off the surface, equal to one if inside, and equal to the numbers of the voxels, along with the connection, if the line is mixed.
- The angle A3: This is the angle computed between two lines, then the line opposite to this angle is classified in one of the three categories (in, out, or mixed).
- The area D3: This is the square root of the area formed by the three points, based on the Heron Formula (1).
3.3. Global Radius-Based Surface Descriptors (GRSD)
3.4. Global Descriptors Based on Fast Point Feature Histogram (FPFH)
3.4.1. Viewpoint Feature Histogram (VFH)
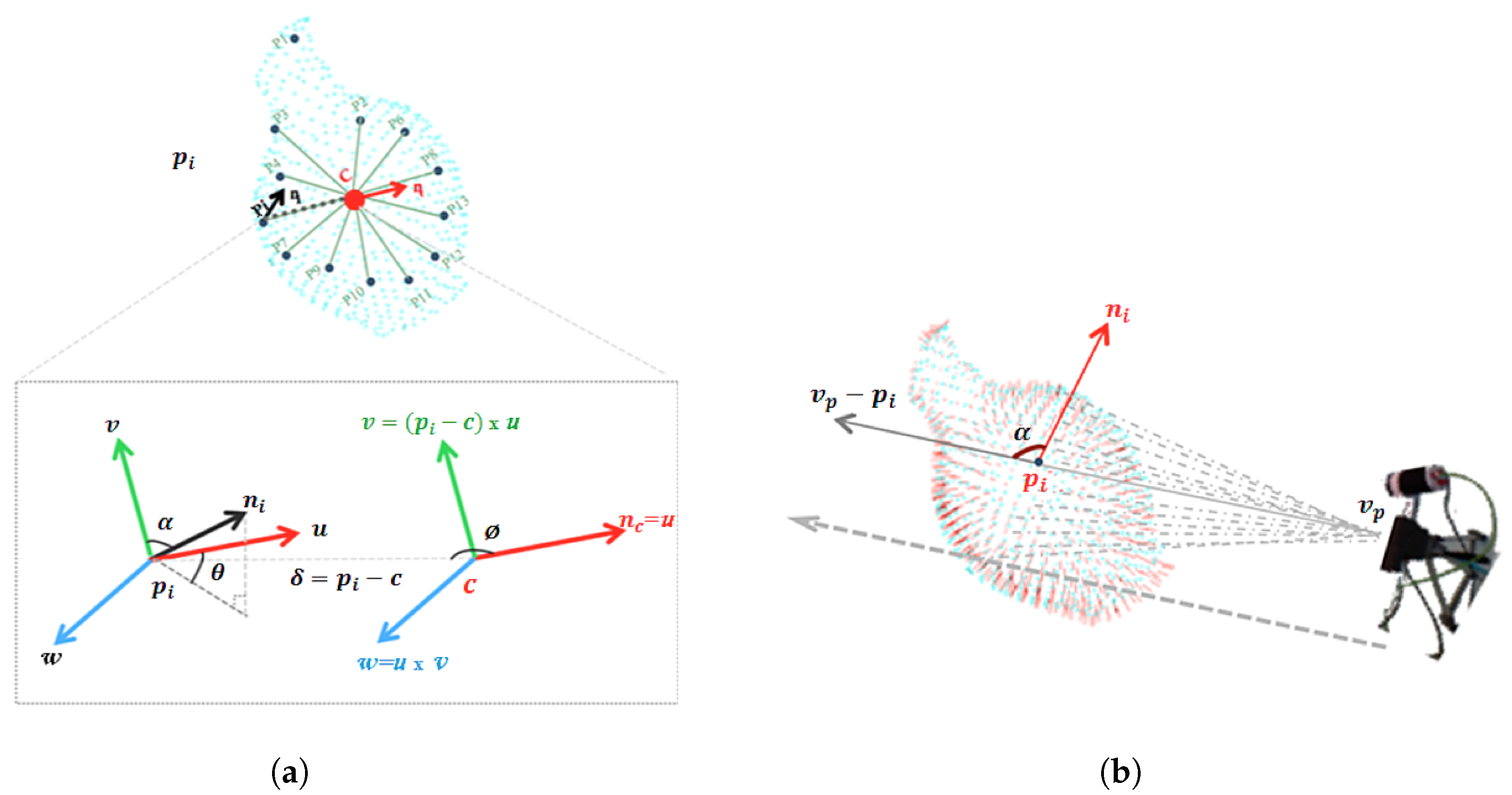
- The Extended Fast Point Feature Histogram (EFPFH). This is an extended version of the FPFH. The difference between EFPFH and its predecessors lies in the way the geometry characteristic of the features is computed. For each point inside the point cloud, instead of comparing each couple of points inside predefined radii, the EFPFH compares each point with the centroid of the point cloud. The histogram is computed using the following steps, where the object is assumed as being a single cluster of points.
- The centroid of the point cloud (c) is computed together with a normal ().
- For each point and its normal in the cluster, a reference frame is defined for each pair and c, with origin in c, where the 3 axes of the frame are , , and .
- As illustrated in Figure 3a. From c, , and , a set of features are computed from 3 angles (, , ) and the distance , as:
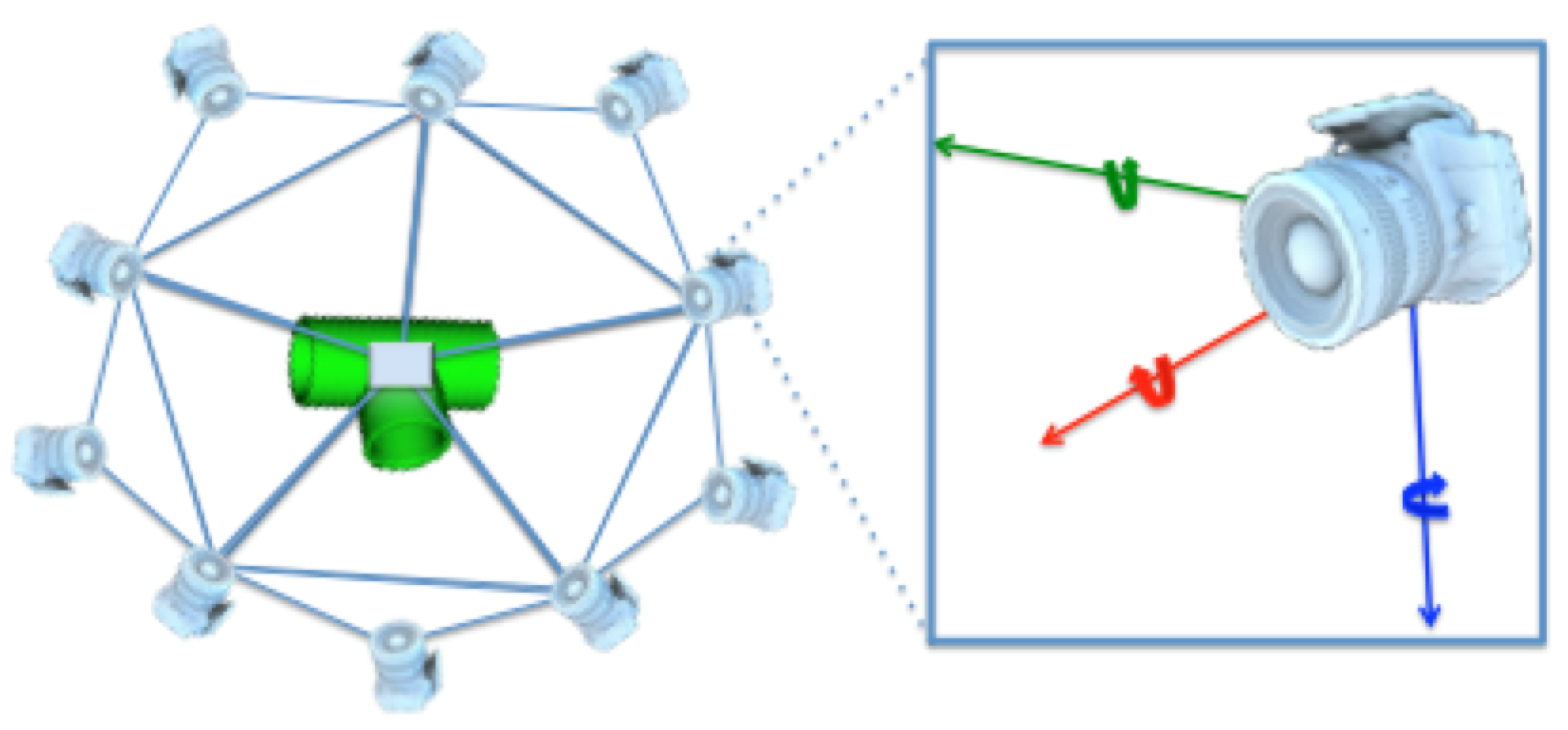
- The viewpoint histogram. It is a histogram of the angles between the two vectors as shown in Figure 3b; the vector formed from the point to the viewpoint , and the normal of the point .
3.4.2. Global Fast Point Feature Histogram (GFPFH)
3.4.3. Clustered Viewpoint Feature Histogram (CVFH)
3.4.4. Oriented, Unique and Repeatable CVFH (OUR-CVFH)
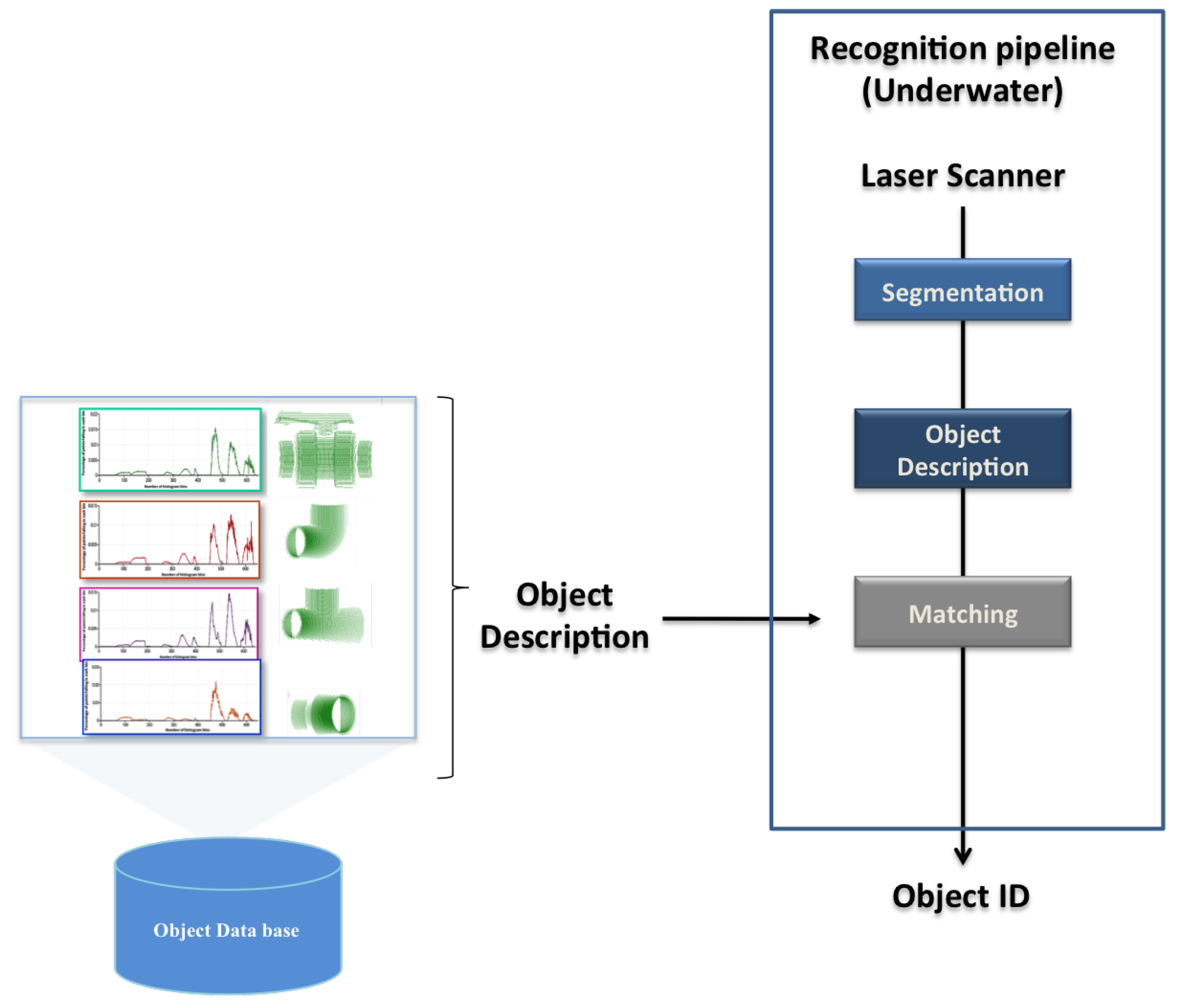
4. Object Recognition Pipeline
- Segmentation: Real scans pass through a segmentation phase, to remove any point not belonging to the object view. For instance, if the object is lying on the bottom of a water tank, removing the principal plane (the bottom) is enough to correctly segment it. This is actually how it was implemented for the real experiments reported in Section 7. This step is skipped in the simulated results. The proposed 3D recognition pipeline requires a segmentation step, which aims to separate the 3D points belonging to the objects of interest from the rest of the scene. It consists of regrouping the points representing the object into one homogeneous group based on similar characteristics following the approach proposed in [71].
- Description: This block uses the global descriptors, presented in the previous section, to encode the segmented object (input scan) in a compact way. The global object descriptors are also used to encode the object views stored in the database (object model). In this way the segmented input scan can be matched against the object model views in the database.
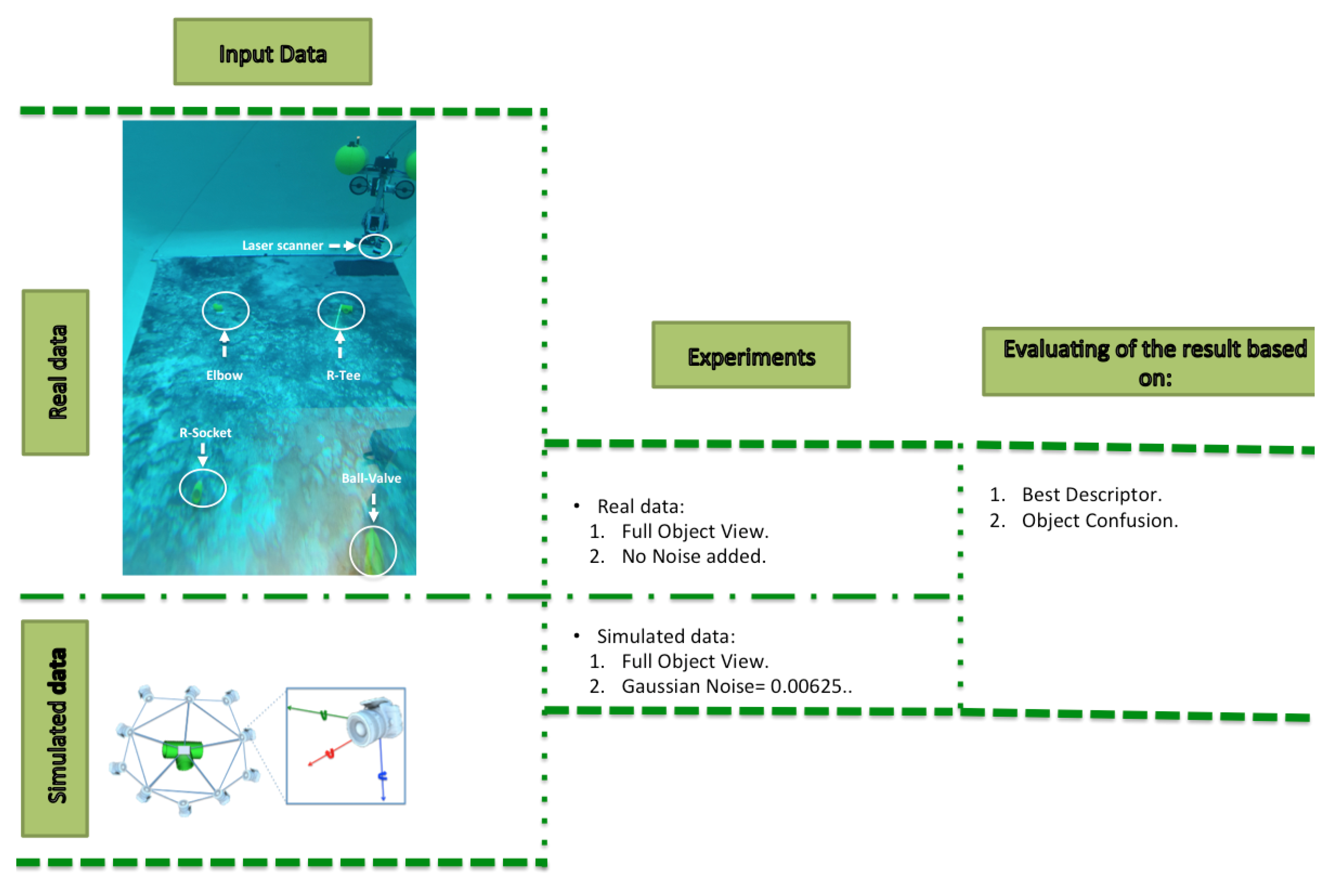
5. Experimental Setup
- The use of full vs.partial views.
- The point cloud resolution.
- The presence of noise.
- Simulated Experiments, which involved the use of a virtual camera to generate a simulated point cloud of the object, grabbed from a random point of view. The virtual scan was characterized with all the descriptors being used to recognize the object. For each <object, resolution, noise, full/partial view> combination, Montecarlo runs of the experiment were performed, computing the average object recognition, and the confusion matrix.
- Real Experiments involved the use of a laser scanner mounted on the GIRONA 500 AUV operating in a water tank scenario. Four objects were placed on the bottom of the water tank. The GIRONA500 vehicle was tele-operated to follow an approximated square trajectory, starting from a position where the reducing socket was within the field of view of the laser scanner. The trajectory ended with the robot on the ball valve, after passing over the elbow and reducing tee. The vehicle performed 3 complete loops, allowing it to acquire multiple views of the same object, each time it passed above it. The laser scanner was mounted looking towards the bottom providing full views of the objects.
5.1. Object Database
5.2. Virtual Scan
- Full Object Views using a level of tessellation fixed to 1, resulting in an icosahedron composed of 20 triangles and in 12 corners. The virtual camera was placed at each corner, at 0.5 m distance looking towards the origin, resulting in 12 full object views (Figure 6). These are the type of views used to represent the object in the database.
- Partial Object Views using a random vertex of the icosahedron to place the camera. The camera-to-object distance is randomly selected within the 0.2 to 1 m interval which is representative of the typical range for manipulation operations. The camera is also rotated around the three axes with a random angle of up to ±10°.
5.3. Resolution
6. Results on Simulated Data
- Full View Same Resolution Experiment (FVSR).
- Full View Different Resolution Experiment (FVDR).
- Partial View Same Resolution Experiment (PVSR).
- Partial View Different Resolution Experiment (PVDR).
6.1. Difference of Resolution Between the Scan and the Object Model in the Database
6.2. Scan Resolution
6.3. Full vs. Partial Object View
6.4. Best Descriptor
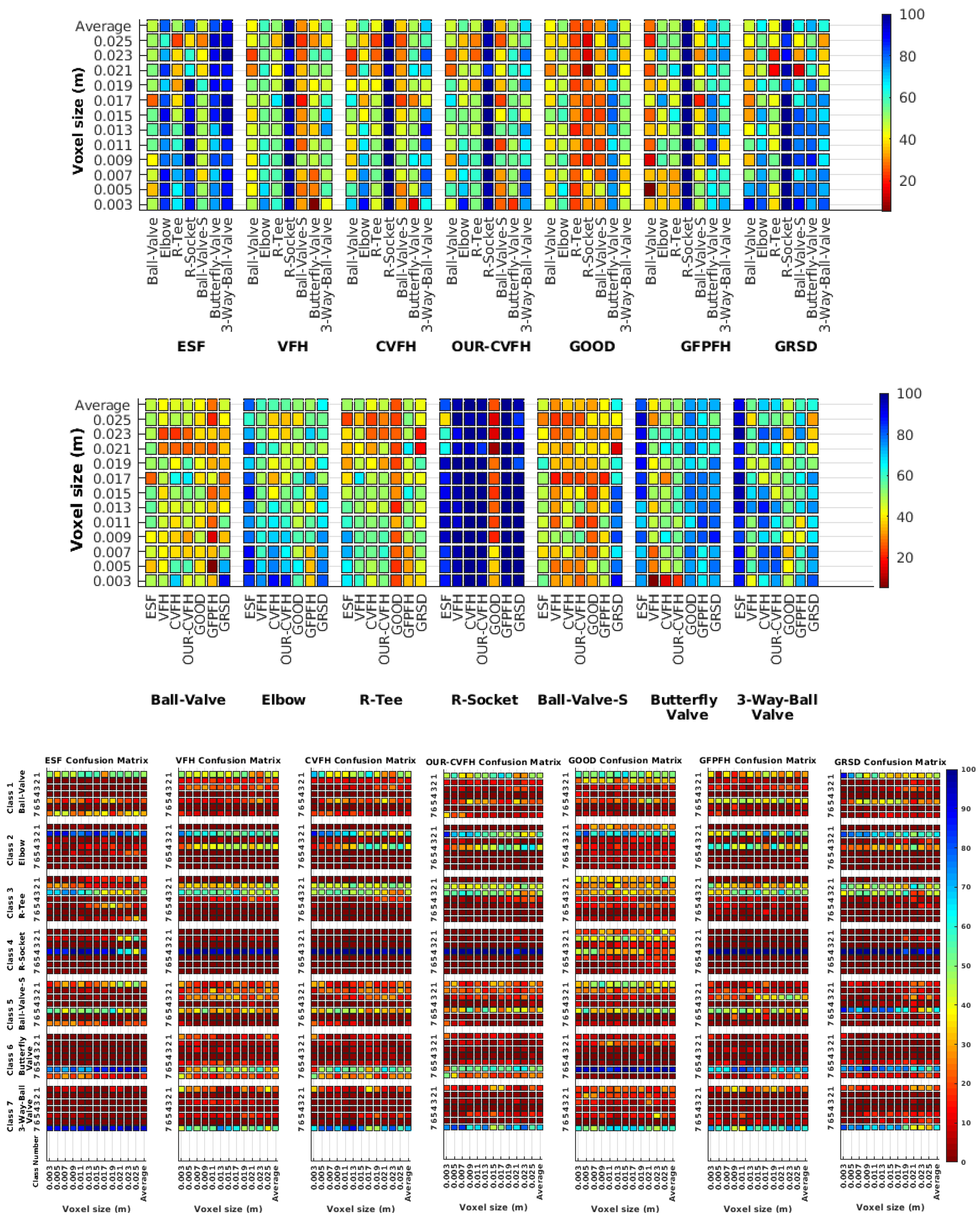
6.5. Object Confusion
- The lower the resolution the higher the confusion. This can be appreciated in Table 4 since the recognition rate decreases with the resolution.
- The recognition rate is higher than the mis-recognition (The addition of all the confusion percentages) only when the same resolution is used. Using the same resolution leads to less confusion (60.3% average recognition rate), while using different resolutions leads to significantly higher confusion (27% average recognition rate).
- The use of full views also leads to less confusion (49.4 average recognition rate) than using partial views (37.9 average recognition rate).
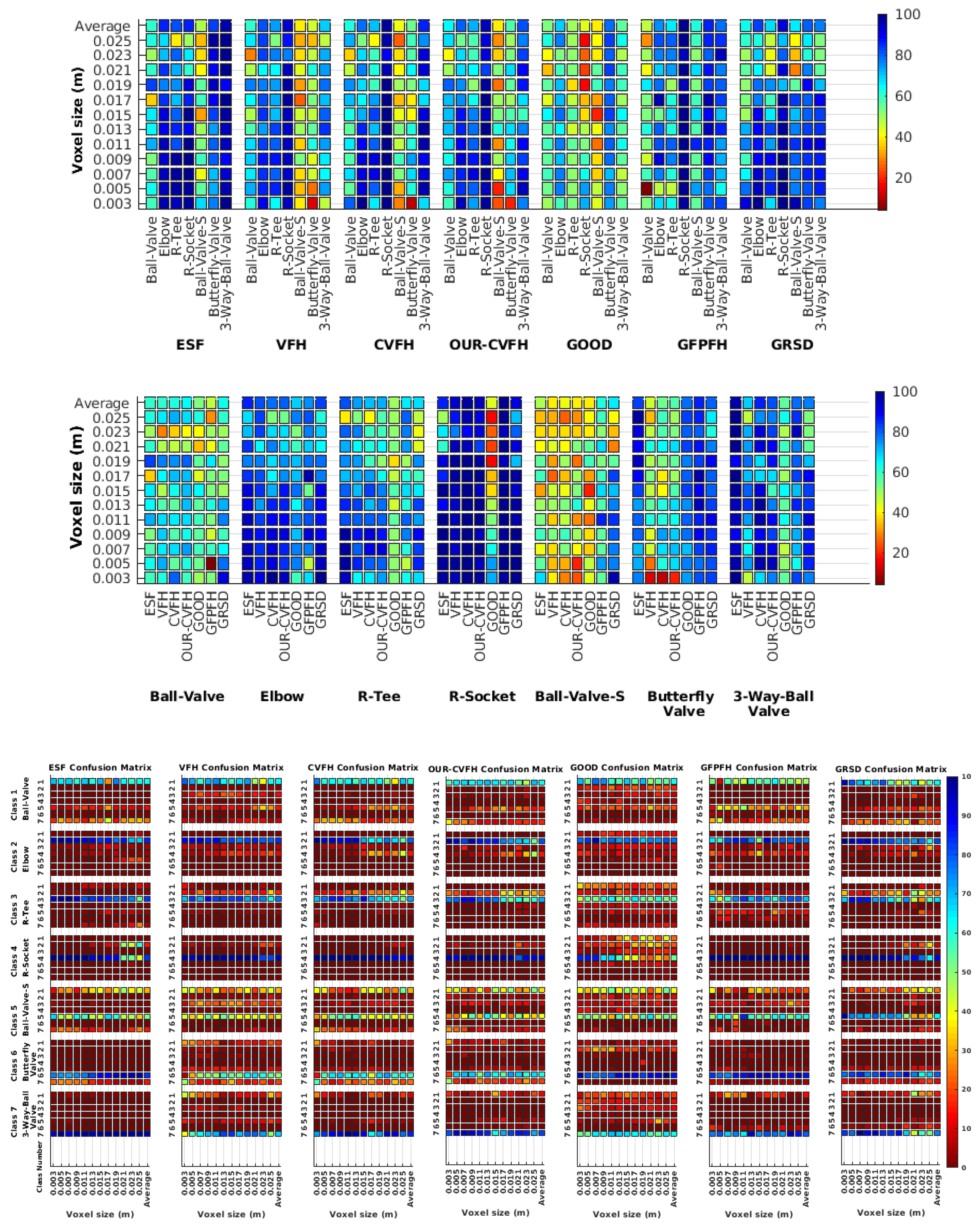
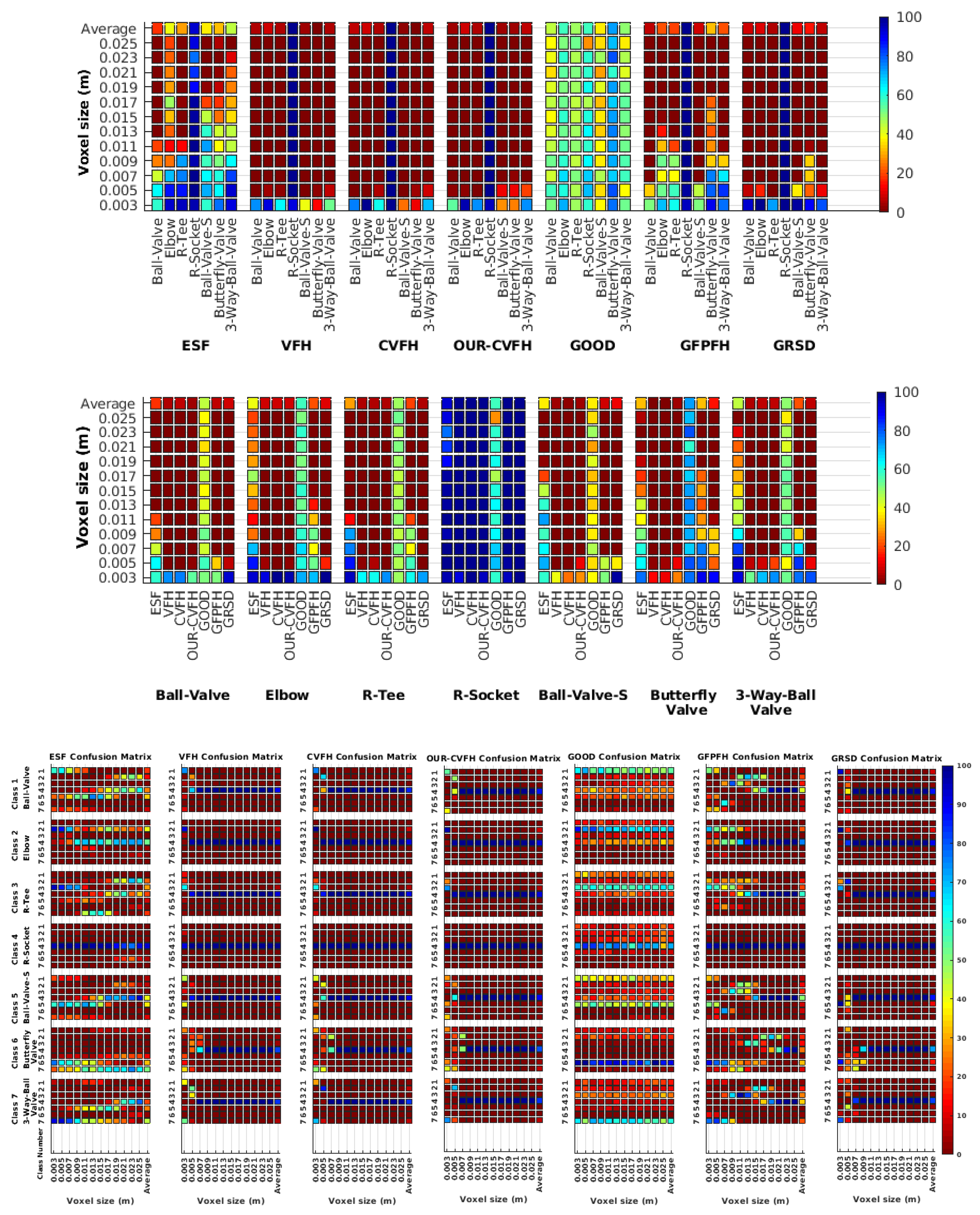
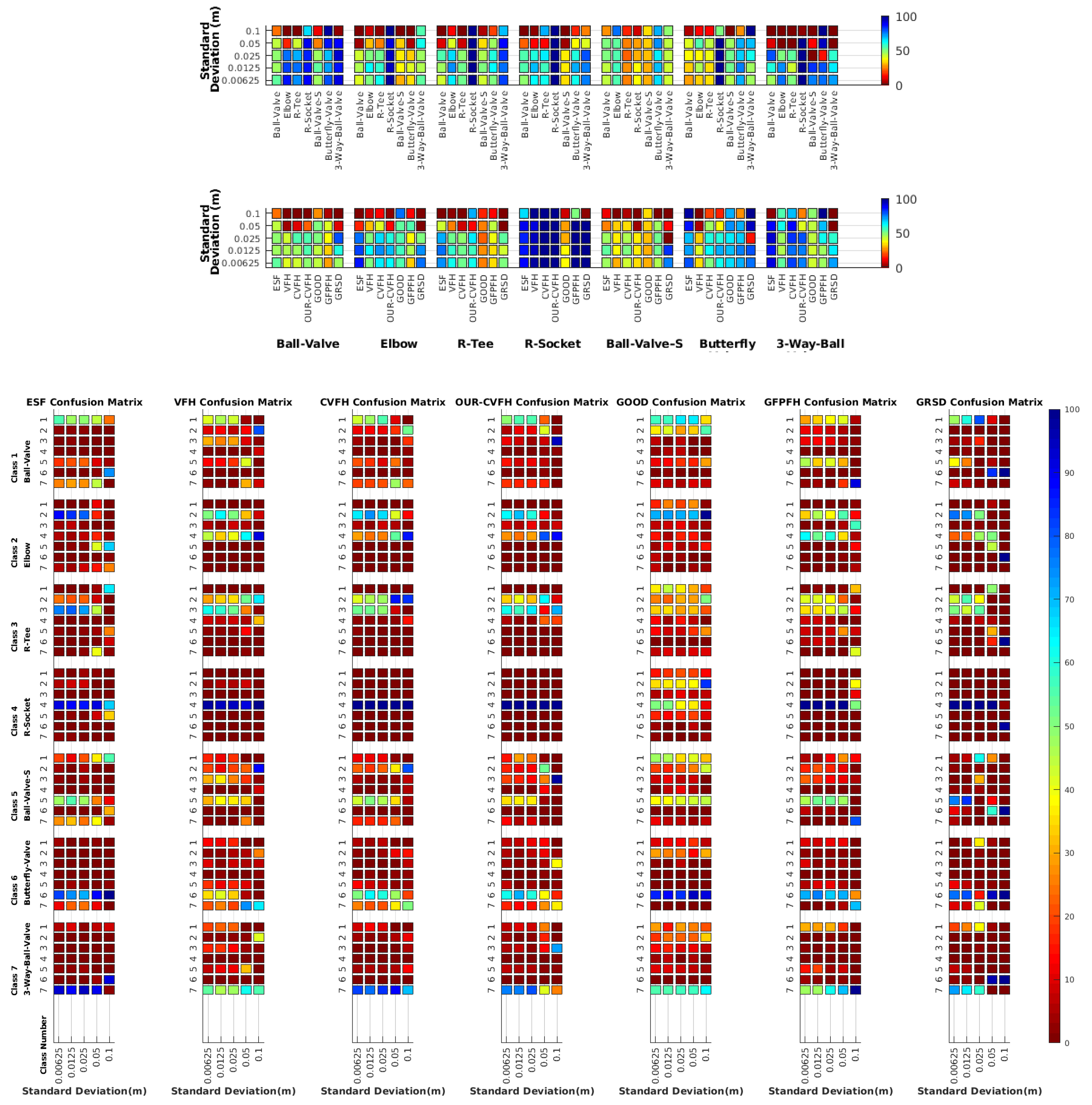
- Which is the descriptor provoking most confusion? Let us focus on the results when using the same resolution which we consider the most interesting ones. In this case, see Table 5, the descriptor with the lowest recognition rate is GOOD, being hence the one leading to higher confusion. This can be confirmed looking at its confusion matrices in Figure 8 and Figure 10. On the other side of the spectrum we find ESF and GRSD which have good recognition rates (72.5% and 69.4% respectively), leading to less confusion as can be appreciated in Figure 8 and Figure 10.
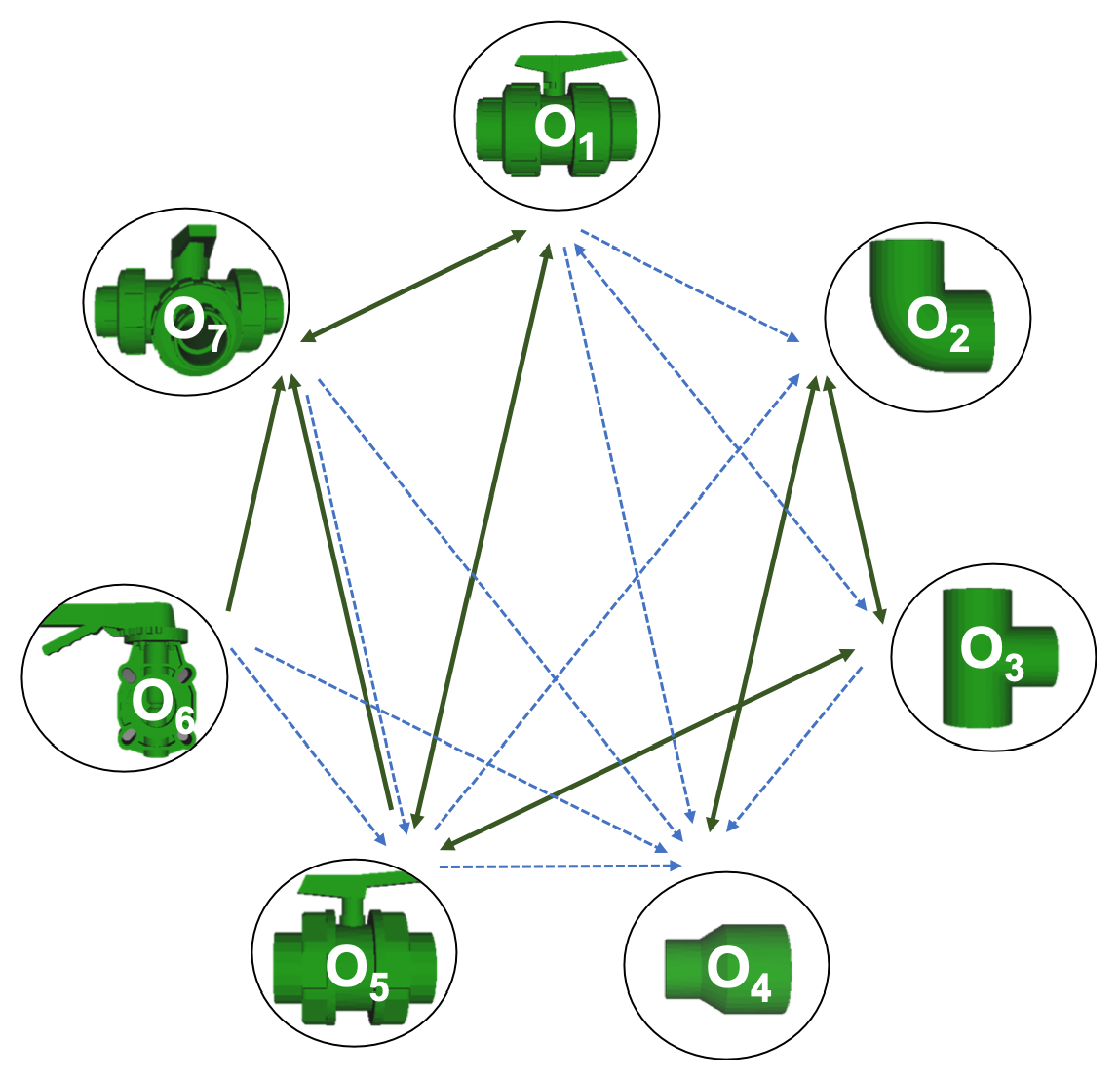
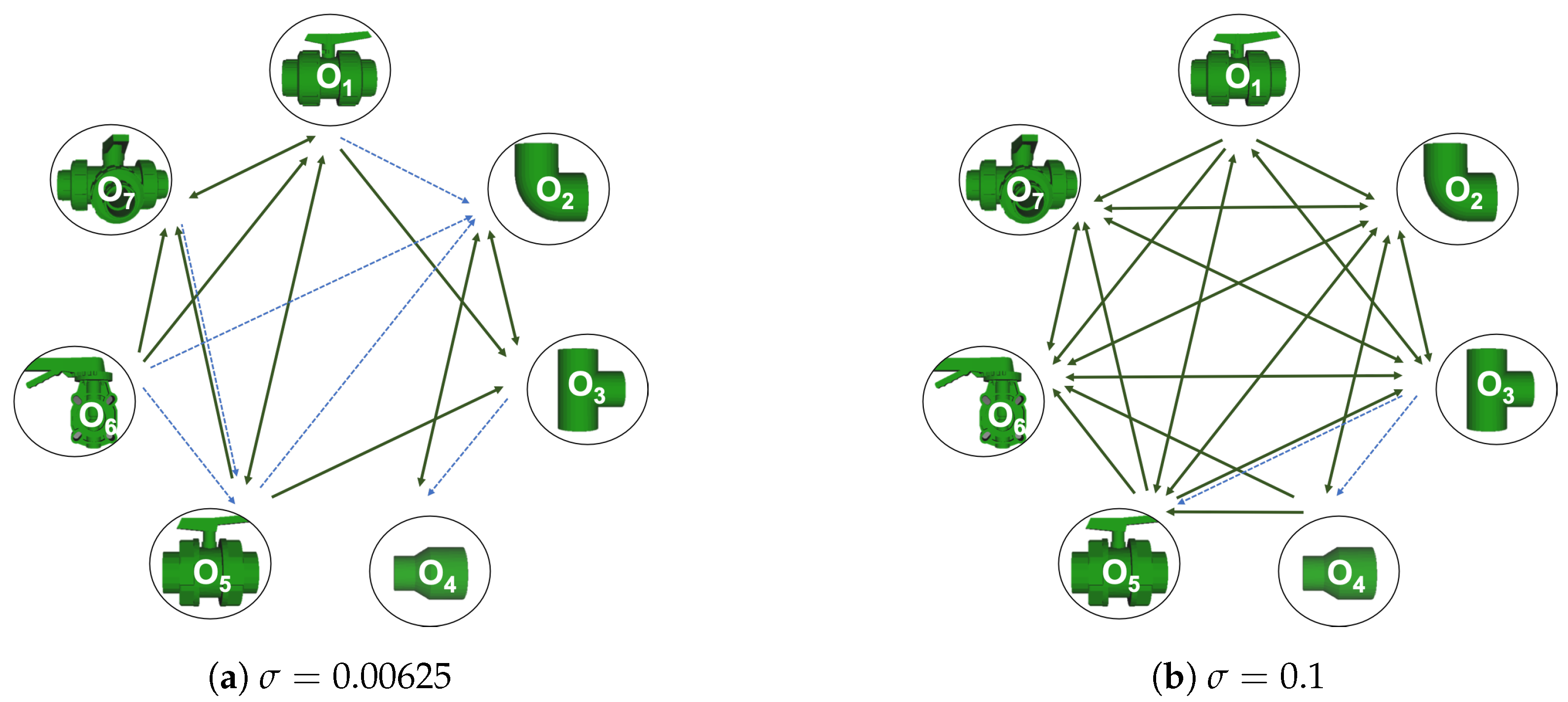
- When confusion arises, which are the objects more prone to be confused? As stated above, the two most interesting scenarios are the ones corresponding to the same resolution, FVSR and PVSR. Figure 12 shows how objects are confused in those scenarios. The green arrows correspond to the confusions appearing (those whose percentages is higher than 5%) when using full views. In this case, most of the confusion appears either among the valves () or among the Elbow, R-Tee and the R-Socket objects. Moreover The R-Tee is also confused with Ball-Valve-S (). When partial views are used instead, the blue arrows add on top of the green ones showing new confusions (The black ones still exist with partial views), making the object identification more challenging. The graph shows clearly how the use of partial views leads to more confusion.
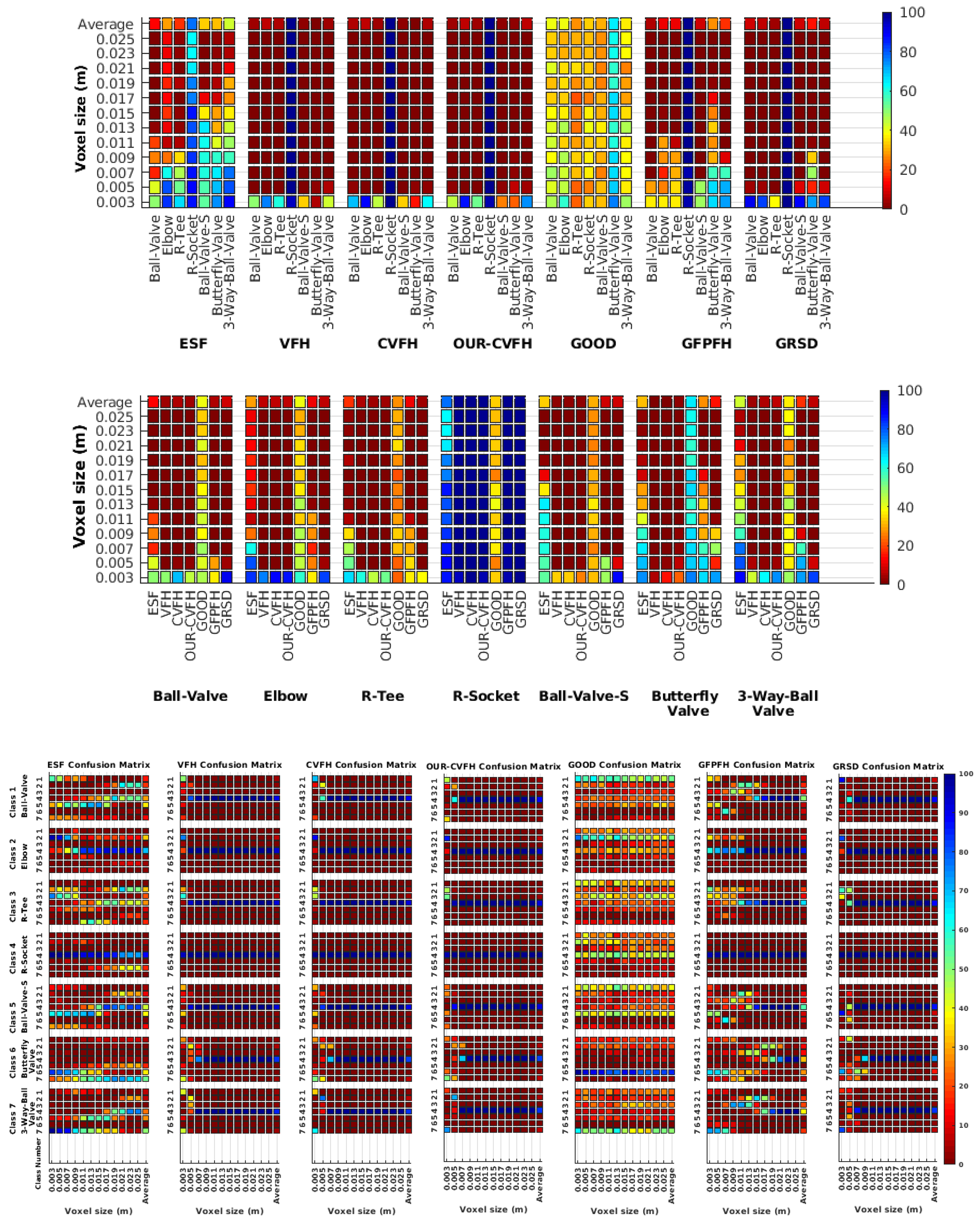
6.6. Gaussian Noise
- Noisy Full View Same Resolution Experiment (NFVSR).
- Noisy Partial View Same Resolution Experiment (NPVSR).
6.6.1. Scan Resolution
6.6.2. Full vs. Partial Object View
6.6.3. Best Descriptor
6.6.4. Object Confusion
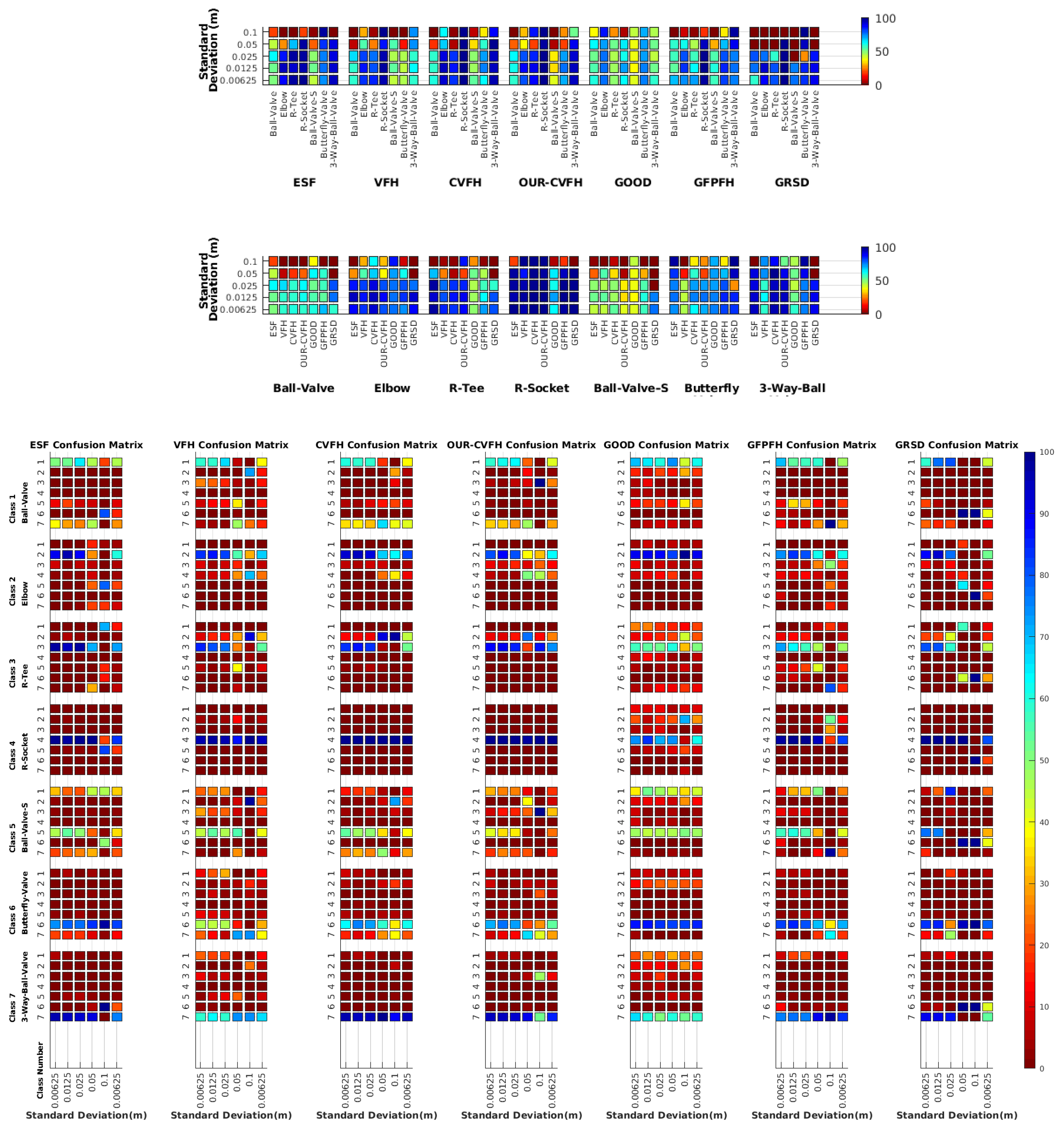
7. Results on Underwater Testing
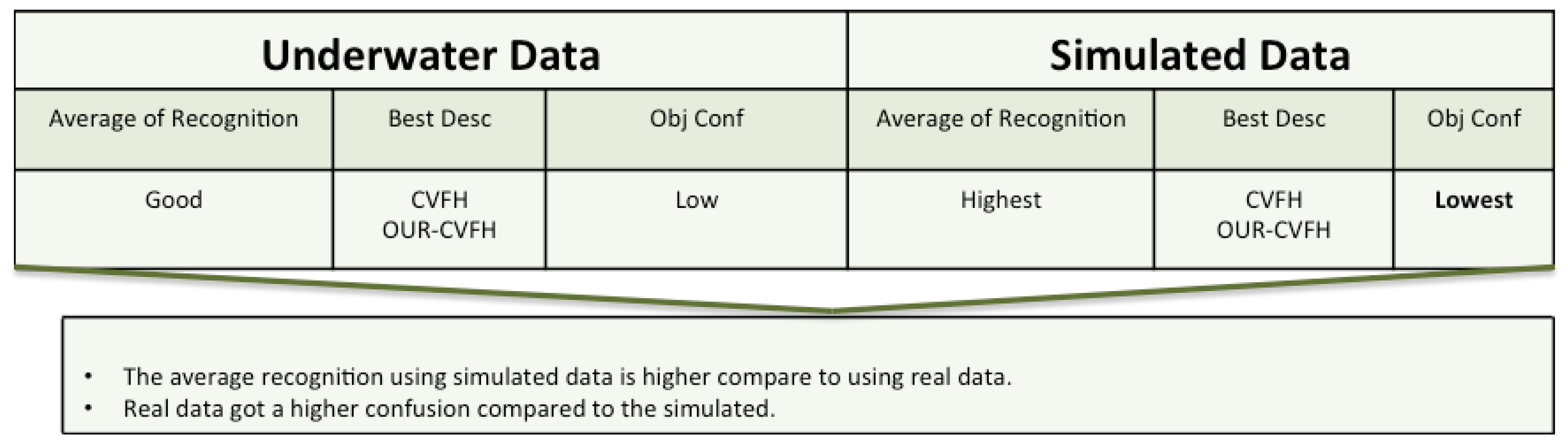
7.1. Real vs. Simulated Rresults
7.1.1. Best Descriptor
7.1.2. Object Confusion
8. Interpretation of Results
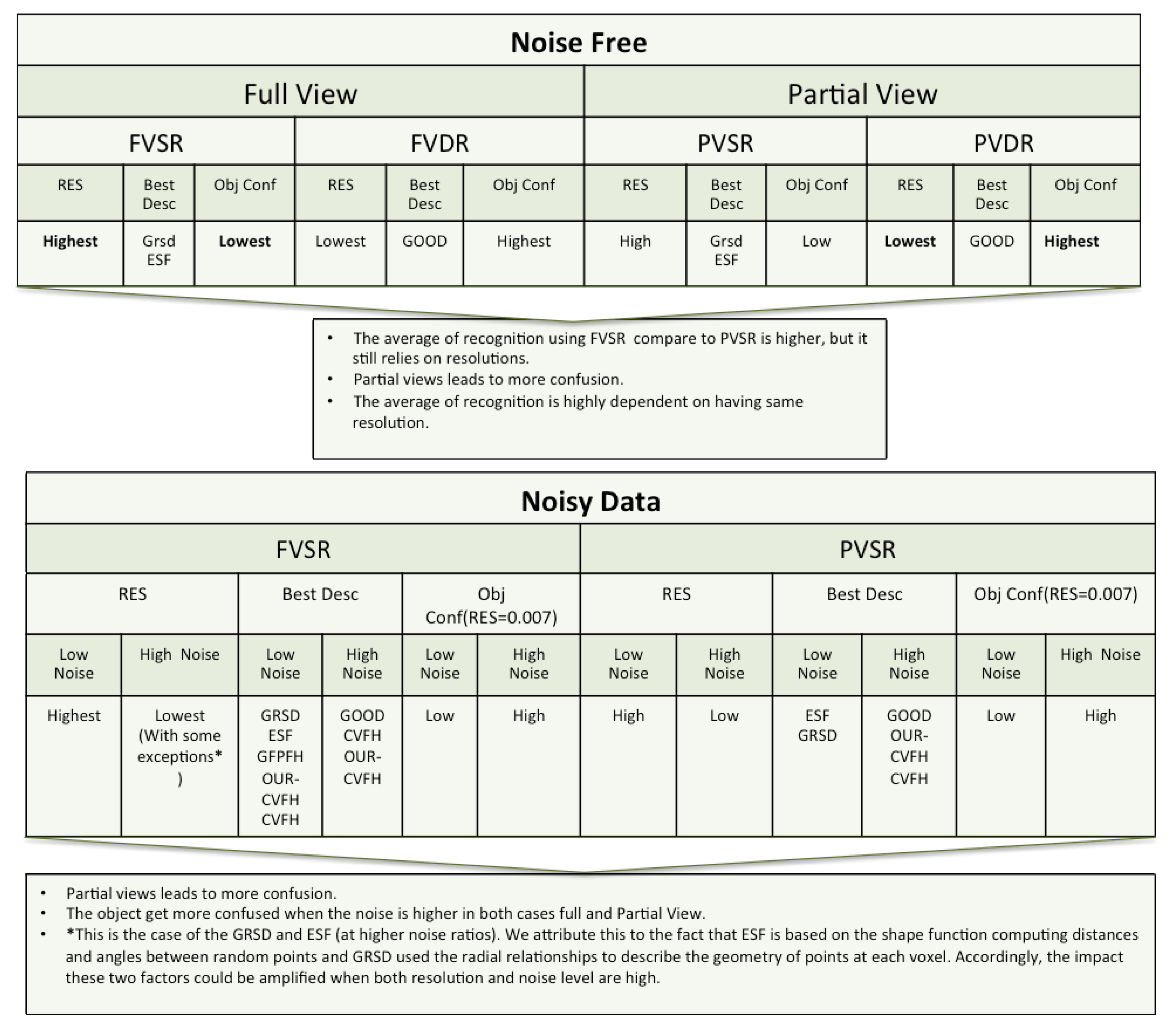
8.1. Simulated Data
- Full View Same Resolution and Partial View Same Resolution ExperimentThe best performance in both cases was achieved using ESF and GRSD. The average of recognition is slightly better using the full view than the partial one, where the trend of the recognition accuracy with respect to the descriptors was monotonic in both cases.
- Full View Different Resolution and Partial View different Resolution ExperimentOnly the GOOD descriptor provided significantly valid results. The change of resolution did not affect the performance of the descriptor in either of the scenarios (FVSR and PVSR). This invariance of the performance regarding the resolution was reported in the original work of the authors in [68].
- Same resolution versus different Resolution ExperimentFrom the cases of FVDR and PVDR, changing the resolution in the database and test led to poor recognition. Conversely, the cases of FVSR and PVSR, show that having the same resolution in both the database and test leads to higher recognition rates.
- Full Views versus Partial ViewsPredictably, using full object views instead of just a partial view, leads to better results. This behaviour is somehow expectable, given the global nature of the methods tested, and the fact that the descriptors in the database were always computed from full views. Additionally, from the confusion matrices, the objects that are prone to confusion when using partial views are a superset of the ones for the case of using full views.
- Noisy Full View versus Noisy Partial ViewIn these experiments only the case where the resolution of the database and test are similar were taking into account. As general assessment, the results of NFVSR versus NPVSR follow the same trend as discussed in the noise-free experiment, where the performance of the descriptor decreases with lower resolution and higher noise ratio, except for GRSD and ESF where the performance of the descriptors decreased for high resolution and noise. We attribute this difference to the fact that ESF is based on the shape function computing distances and angles between random points, while GRSD used the radial relationships to describe the geometry of points at each voxel. Accordingly, the impact of these two factors could be amplified when both resolution and noise level are high.As a specific assessment, the confusion matrix for the , which is the resolution of the laser scan used in the real experiment, was computed at a different noise level. The results showed that the object got more confusion at a high noise level compared to a low level.
8.2. Underwater Data
- Real data inevitably suffers from noise generated from the changes of the position of the laser during the acquisition of the point cloud, causing a distortion of the object shape and leading to a different descriptor representation. These motion distortions were present in real but not in simulated data.
- Most of the object descriptors used in this study are based on use of a surface normals. Noise causes a modification in the surface which causes a change in the normal for each point.
9. Conclusions
10. Future Work
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| MP | Motion Primitive |
| BoF | Bag-of-Features |
| CVFH | Clustered Viewpoint Feature Histogram |
| CSHOT | Colored Signature of Histogram of Orientation |
| CAD | Computer aided design model |
| CRF | Conditional Random Field model |
| ECSAD | Equivalent circumference surface angle descriptor |
| EFPFH | Extended Fast Point Feature Histograms |
| FPFH | Fast Point Feature Histograms |
| GFPFH | Global Fast Point Feature Histogram |
| GOOD | Global Orthographic Object Descriptor |
| GRSD | Global Radius-based Surface Descriptors |
| GPCSD | Global Principal Curvature Shape Descriptor |
| IMR | Inspection Maintenance and repair |
| RSD | Radius-based Surface Descriptors |
| OUR-CVFH | Oriented, Unique and Repeatable |
| PVC | Polyvinylchloride pressure pipes |
| PCL | Point Cloud Library |
| PCA | Principal Component Analysis |
| RCS | Rotational Contour Signatures |
| RoPS | Rotational Projection Statistics |
| ROVs | Remotely Operated Vehicles |
| SDC | Shape Distribution Component |
| SLAM | Simultaneous Localization And Mapping |
| SHOT | Signature of Histogram of Orientation |
| SI | Spin Image |
| VFH | Viewpoint Feature Histogram |
| FVSR | Full View Same Resolution Experiment |
| PVSR | Partial View Same Resolution Experiment |
| FVDR | Full View Different Resolution Experiment |
| PVDR | Partial View Different Resolution Experiment |
| NFVSR | Noisy Full View Same Resolution Experiment |
| NPVSR | Noisy Partial View Same Resolution Experiment |
| IK | Inverse Kinematics |
| UVMS | Underwater Vehicle Manipulator System |
| I-AUV | Intervention Autonomous Underwater Vehicle |
| AUV | Autonomous Underwater Vehicle |
| ROV | Remotely Operated Vehicle |
| DoF | Degrees of Freedom |
| DVL | Doppler Velocity Log |
| FOV | Field Of View |
| LIDAR | Light Detection and Ranging |
References
- Rusu, R.B.; Marton, Z.C.; Blodow, N.; Dolha, M.; Beetz, M. Towards 3D point cloud based object maps for household environments. Robot. Auton. Syst. 2008, 56, 927–941. [Google Scholar] [CrossRef]
- Rusu, R.B.; Gerkey, B.; Beetz, M. Robots in the kitchen: Exploiting ubiquitous sensing and actuation. Robot. Auton. Syst. 2008, 56, 844–856. [Google Scholar] [CrossRef]
- Blodow, N.; Goron, L.C.; Marton, Z.C.; Pangercic, D.; Rühr, T.; Tenorth, M.; Beetz, M. Autonomous semantic mapping for robots performing everyday manipulation tasks in kitchen environments. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, San Francisco, CA, USA, 25–30 September 2011; pp. 4263–4270. [Google Scholar]
- Houser, K. A Robot Is Learning to Cook and Clean in an Ikea Kitchen. 2019. Available online: https://futurism.com/the-byte/robots-cook-clean-ikea-kitchen (accessed on 9 May 2019).
- Saxena, A.; Wong, L.; Quigley, M.; Ng, A.Y. A vision-based system for grasping novel objects in cluttered environments. In Robotics Research; Springer: Berlin/Heidelberg, Germany, 2010; pp. 337–348. [Google Scholar]
- Zhu, M.; Derpanis, K.G.; Yang, Y.; Brahmbhatt, S.; Zhang, M.; Phillips, C.; Lecce, M.; Daniilidis, K. Single image 3D object detection and pose estimation for grasping. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 3936–3943. [Google Scholar]
- Farahmand, F.; Pourazad, M.T.; Moussavi, Z. An intelligent assistive robotic manipulator. In Proceedings of the IEEE Engineering in Medicine and Biology 27th Annual Conference, Shanghai, China, 17–18 January 2006; pp. 5028–5031. [Google Scholar]
- Boronat Roselló, E. ROSAPL: Towards a Heterogeneous Multi-Robot System and Human Interaction Framework. Master’s Thesis, Universitat Politècnica de Catalunya, Barcelona, Spain, 2014. [Google Scholar]
- Vargas, J.A.C.; Garcia, A.G.; Oprea, S.; Escolano, S.O.; Rodriguez, J.G. Detecting and manipulating objects with a social robot: An ambient assisted living approach. In ROBOT 2017: Third Iberian Robotics Conference; Springer: Cham, Switzerland, 2017; pp. 613–624. [Google Scholar]
- Vargas, J.A.C.; Garcia, A.G.; Oprea, S.; Escolano, S.O.; Rodriguez, J.G. Object recognition pipeline: Grasping in domestic environments. In Rapid Automation: Concepts, Methodologies, Tools, and Applications; IGI Global: Hershey, PA, USA, 2019; pp. 456–468. [Google Scholar]
- Bontsema, J.; Hemming, J.; Pekkeriet, E. CROPS: High tech agricultural robots. In Proceedings of the International Conference of Agricultural Engineering AgEng 2014, Zurih, Switzerland, 6–10 July 2014. [Google Scholar]
- Tao, Y.; Zhou, J. Automatic apple recognition based on the fusion of color and 3D feature for robotic fruit picking. Comput. Electr. Agric. 2017, 142, 388–396. [Google Scholar] [CrossRef]
- Huang, J.; You, S. Detecting objects in scene point cloud: A combinational approach. In Proceedings of the International Conference on 3D Vision, 3DV ’13 2013, Seattle, WA, USA, 29 June–1 July 2013; pp. 175–182. [Google Scholar] [CrossRef]
- Holz, D.; Behnke, S. Fast edge-based detection and localization of transport boxes and pallets in rgb-d images for mobile robot bin picking. In Proceedings of the ISR 2016: 47st International Symposium on Robotics, VDE, Munich, Germany, 21–22 June 2016; pp. 1–8. [Google Scholar]
- Geronimo, D.; Lopez, A.M.; Sappa, A.D.; Graf, T. Survey of pedestrian detection for advanced driver assistance systems. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1239–1258. [Google Scholar] [CrossRef]
- Fu, M.Y.; Huang, Y.S. A survey of traffic sign recognition. In Proceedings of the International Conference on Wavelet Analysis and Pattern Recognition, Qingdao, China, 11–14 July 2010; pp. 119–124. [Google Scholar]
- Fan, Y.; Zhang, W. Traffic sign detection and classification for Advanced Driver Assistant Systems. In Proceedings of the 12th International Conference on Fuzzy Systems and Knowledge Discovery (FSKD), Zhangjiajie, China, 15–17 August 2015; pp. 1335–1339. [Google Scholar]
- Markiewicz, P.; Długosz, M.; Skruch, P. Review of tracking and object detection systems for advanced driver assistance and autonomous driving applications with focus on vulnerable road users sensing. In Polish Control Conference; Springer: Cham, Switzerland, 2017; pp. 224–237. [Google Scholar]
- Foresti, G.L.; Gentili, S. A hierarchical classification system for object recognition in underwater environments. IEEE J. Ocean. Eng. 2002, 27, 66–78. [Google Scholar] [CrossRef]
- Bagnitsky, A.; Inzartsev, A.; Pavin, A.; Melman, S.; Morozov, M. Side scan sonar using for underwater cables & pipelines tracking by means of AUV. In Proceedings of the IEEE Symposium on Underwater Technology and Workshop on Scientific Use of Submarine Cables and Related Technologies, Tokyo, Japan, 5–8 April 2011; pp. 1–10. [Google Scholar]
- Yu, S.C.; Kim, T.W.; Asada, A.; Weatherwax, S.; Collins, B.; Yuh, J. Development of high-resolution acoustic camera based real-time object recognition system by using autonomous underwater vehicles. In Proceedings of the OCEANS 2006, Boston, MA, USA, 18–21 September 2006. [Google Scholar]
- Hegde, J.; Utne, I.B.; Schjølberg, I. Applicability of current remotely operated vehicle standards and guidelines to autonomous subsea IMR operations. In Proceedings of the ASME 34th International Conference on Ocean, Offshore and Arctic Engineering, St. John’s, NL, Canada, 31 May–5 June 2015; American Society of Mechanical Engineers: New York, NY, USA, 2015. [Google Scholar] [CrossRef]
- Barat, C.; Rendas, M.J. A robust visual attention system for detecting manufactured objects in underwater video. In Proceedings of the OCEANS 2006, Boston, MA, USA, 18–21 September 2006. [Google Scholar]
- Gordan, M.; Dancea, O.; Stoian, I.; Georgakis, A.; Tsatos, O. A new SVM-based architecture for object recognition in color underwater images with classification refinement by shape descriptors. In Proceedings of the IEEE International Conference on Automation, Quality and Testing, Robotics, Cluj-Napoca, Romania, 25–28 May 2006; Volume 2, pp. 327–332. [Google Scholar]
- Sivčev, S.; Rossi, M.; Coleman, J.; Omerdić, E.; Dooly, G.; Toal, D. Collision detection for underwater ROV manipulator systems. Sensors 2018, 18, 1117. [Google Scholar] [CrossRef]
- Gobi, A.F. Towards generalized benthic species recognition and quantification using computer vision. In Proceedings of the Fourth Pacific-Rim Symposium on Image and Video Technology, Singapore, 14–17 November 2010; pp. 94–100. [Google Scholar]
- Rusu, R.B.; Cousins, S. 3D is here: Point cloud library (PCL). In Proceedings of the IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 1–4. [Google Scholar]
- Palomer, A.; Ridao, P.; Ribas, D.; Forest, J. Underwater 3D laser scanners: The deformation of the plane. In Lecture Notes in Control and Information Sciences; Fossen, T.I., Pettersen, K.Y., Nijmeijer, H., Eds.; Springer: Cham, Switzerland, 2017; Volume 474, pp. 73–88. [Google Scholar] [CrossRef]
- Pang, G.; Qiu, R.; Huang, J.; You, S.; Neumann, U. Automatic 3D industrial point cloud modeling and recognition. In Proceedings of the 14th IAPR international conference on machine vision applications (MVA), Tokyo, Japan, 18–22 May 2015; pp. 22–25. [Google Scholar]
- Kumar, G.; Patil, A.; Patil, R.; Park, S.; Chai, Y. A LiDAR and IMU integrated indoor navigation system for UAVs and its application in real-time pipeline classification. Sensors 2017, 17, 1268. [Google Scholar] [CrossRef]
- Alexandre, L.A. 3D descriptors for object and category recognition: a comparative evaluation. In Proceedings of the Workshop on Color-Depth Camera Fusion in Robotics at the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vilamoura, Portugal, 7–12 October 2012; Volume 1, p. 7. [Google Scholar]
- Johnson, A.E.; Hebert, M. Using spin images for efficient object recognition in cluttered 3D scenes. IEEE Trans. Pattern Anal. Mach. Intell. 1999, 21, 433–449. [Google Scholar] [CrossRef] [Green Version]
- Rusu, R.B.; Holzbach, A.; Beetz, M.; Bradski, G. Detecting and segmenting objects for mobile manipulation. In Proceedings of the IEEE 12th International Conference on Computer Vision Workshops, ICCV Workshops, Kyoto, Japan, 27 September–4 October 2009; pp. 47–54. [Google Scholar]
- Aldoma, A.; Vincze, M.; Blodow, N.; Gossow, D.; Gedikli, S.; Rusu, R.B.; Bradski, G. CAD-model recognition and 6DOF pose estimation using 3D cues. In Proceedings of the IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Barcelona, Spain, 6–13 November 2011; pp. 585–592. [Google Scholar]
- Lai, K.; Bo, L.; Ren, X.; Fox, D. A large-scale hierarchical multi-view rgb-d object dataset. In Proceedings of the IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 1817–1824. [Google Scholar]
- Tombari, F.; Salti, S.; Di Stefano, L. A combined texture-shape descriptor for enhanced 3D feature matching. In Proceedings of the 18th IEEE International Conference on Image Processing, Brussels, Belgium, 11–14 September 2011; pp. 809–812. [Google Scholar]
- Guo, Y.; Bennamoun, M.; Sohel, F.; Lu, M.; Wan, J. 3D object recognition in cluttered scenes with local surface features: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 2270–2287. [Google Scholar]
- Guo, Y.; Bennamoun, M.; Sohel, F.; Lu, M.; Wan, J.; Kwok, N.M. A comprehensive performance evaluation of 3D local feature descriptors. Int. J. Comput. Vis. 2016, 116, 66–89. [Google Scholar] [CrossRef]
- Tombari, F.; Salti, S.; Di Stefano, L. Unique shape context for 3D data description. In Proceedings of the ACM Workshop on 3D Object Retrieval, Firenze, Italy, 25 October 2010; ACM: New York, NY, USA, 2010; pp. 57–62. [Google Scholar]
- Mian, A.S.; Bennamoun, M.; Owens, R. Three-dimensional model-based object recognition and segmentation in cluttered scenes. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1584–1601. [Google Scholar] [CrossRef] [PubMed]
- Taati, B.; Greenspan, M. Local shape descriptor selection for object recognition in range data. Comput. Vis. Image Underst. 2011, 115, 681–694. [Google Scholar] [CrossRef]
- Rodolà, E.; Albarelli, A.; Bergamasco, F.; Torsello, A. A scale independent selection process for 3d object recognition in cluttered scenes. Int. J. Comput. Vis. 2013, 102, 129–145. [Google Scholar] [CrossRef]
- Jørgensen, T.B.; Buch, A.G.; Kraft, D. Geometric edge description and classification in point cloud data with application to 3D object recognition. In Proceedings of the 10th International Conference on Computer Vision Theory and Applications International Conference on Computer Vision Theory and Applications. Institute for Systems and Technologies of Information, Control and Communication, Berlin, Germany, 11–14 March 2015; pp. 333–340. [Google Scholar]
- Yang, J.; Zhang, Q.; Xian, K.; Xiao, Y.; Cao, Z. Rotational contour signatures for robust local surface description. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3598–3602. [Google Scholar]
- Malassiotis, S.; Strintzis, M.G. Snapshots: A novel local surface descriptor and matching algorithm for robust 3D surface alignment. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1285–1290. [Google Scholar] [CrossRef] [PubMed]
- Rusu, R.B.; Blodow, N.; Beetz, M. Fast point feature histograms (FPFH) for 3D registration. In Proceedings of the IEEE International Conference on Robotics and Automation, ICRA’09, Kobe, Japan, 12–17 May 2009; pp. 3212–3217. [Google Scholar]
- Salti, S.; Tombari, F.; Di Stefano, L. SHOT: Unique signatures of histograms for surface and texture description. Comput. Vis. Image Underst. 2014, 125, 251–264. [Google Scholar] [CrossRef]
- Guo, Y.; Sohel, F.; Bennamoun, M.; Lu, M.; Wan, J. Rotational projection statistics for 3D local surface description and object recognition. Int. J. Comput. Vis. 2013, 105, 63–86. [Google Scholar] [CrossRef]
- Shi, Z.; Kang, Z.; Lin, Y.; Liu, Y.; Chen, W. Automatic recognition of pole-like objects from mobile laser scanning point clouds. Remote Sens. 2018, 10, 1891. [Google Scholar] [CrossRef]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Wold, S.; Esbensen, K.; Geladi, P. Principal component analysis. Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]
- Chen, F.; Selvaggio, M.; Caldwell, D.G. Dexterous grasping by manipulability selection for mobile manipulator with visual guidance. IEEE Trans. Ind. Inform. 2019, 15, 1202–1210. [Google Scholar] [CrossRef]
- Rusu, R.B.; Bradski, G.; Thibaux, R.; Hsu, J. Fast 3D recognition and pose using the viewpoint feature histogram. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Taipei, Taiwan, 18–22 October 2010; pp. 2155–2162. [Google Scholar]
- Marton, Z.C.; Pangercic, D.; Rusu, R.B.; Holzbach, A.; Beetz, M. Hierarchical object geometric categorization and appearance classification for mobile manipulation. In Proceedings of the 10th IEEE-RAS International Conference on Humanoid Robots (Humanoids), Nashville, TN, USA, 6–8 December 2010; pp. 365–370. [Google Scholar]
- Marton, Z.C.; Pangercic, D.; Blodow, N.; Kleinehellefort, J.; Beetz, M. General 3D modelling of novel objects from a single view. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Taipei, Taiwan, 18–22 October 2010; pp. 3700–3705. [Google Scholar]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-up robust features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Gunji, N.; Niigaki, H.; Tsutsuguchi, K.; Kurozumi, T.; Kinebuchi, T. 3D object recognition from large-scale point clouds with global descriptor and sliding window. In Proceedings of the 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 721–726. [Google Scholar]
- Tombari, F.; Di Stefano, L. Object recognition in 3D scenes with occlusions and clutter by hough voting. In Proceedings of the Fourth Pacific-Rim Symposium on Image and Video Technology, Singapore, 14–17 November 2010; pp. 349–355. [Google Scholar]
- Garstka, J. Learning Strategies to Select Point Cloud Descriptors for Large-Scale 3-D Object Classification. Ph.D. Thesis, University of Hagen, Hagen, Germany, 2016. [Google Scholar]
- Jain, S.; Argall, B. Estimation of Surface Geometries in Point Clouds for the Manipulation of Novel Household Objects. In Proceedings of the RSS 2017 Workshop on Spatial-Semantic Representations in Robotics, Cambridge, MA, USA, 16 July 2017. [Google Scholar]
- Aldoma, A.; Tombari, F.; Prankl, J.; Richtsfeld, A.; Di Stefano, L.; Vincze, M. Multimodal cue integration through hypotheses verification for rgb-d object recognition and 6dof pose estimation. In Proceedings of the IEEE International Conference on Robotics and Automation, Karlsruhe, Germany, 6–10 May 2013; pp. 2104–2111. [Google Scholar]
- Aldoma, A.; Tombari, F.; Rusu, R.B.; Vincze, M. OUR-CVFH–oriented, unique and repeatable clustered viewpoint feature histogram for object recognition and 6DOF pose estimation. In Joint DAGM (German Association for Pattern Recognition) and OAGM Symposium; Springer: Berlin/Heidelberg, Germany, 2012; pp. 113–122. [Google Scholar]
- Alhamzi, K.; Elmogy, M.; Barakat, S. 3d object recognition based on local and global features using point cloud library. Int. J. Adv. Comput. Technol. 2015, 7, 43. [Google Scholar]
- Wohlkinger, W.; Vincze, M. Ensemble of shape functions for 3d object classification. In Proceedings of the IEEE International Conference on Robotics and Biomimetics (ROBIO), Karon Beach, Phuket, Thailand, 7–11 December 2011; pp. 2987–2992. [Google Scholar]
- Rusu, R.B.; Marton, Z.C.; Blodow, N.; Beetz, M. Persistent point feature histograms for 3D point clouds. In Proceedings of the 10th International Conference on Intel Autonomous System (IAS-10), Baden-Baden, Germany, 2008; pp. 119–128. [Google Scholar]
- Aldoma, A.; Fäulhammer, T.; Vincze, M. Automation of “ground truth” annotation for multi-view RGB-D object instance recognition datasets. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Chicago, IL, USA, 14–18 September 2014; pp. 5016–5023. [Google Scholar]
- Sels, S.; Ribbens, B.; Bogaerts, B.; Peeters, J.; Vanlanduit, S. 3D model assisted fully automated scanning laser Doppler vibrometer measurements. Opt. Lasers Eng. 2017, 99, 23–30. [Google Scholar] [CrossRef]
- Kasaei, S.H.; Lopes, L.S.; Tomé, A.M.; Oliveira, M. An orthographic descriptor for 3D object learning and recognition. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; pp. 4158–4163. [Google Scholar]
- Osada, R.; Funkhouser, T.; Chazelle, B.; Dobkin, D. Matching 3D models with shape distributions. In Proceedings of the SMI 2001 International Conference On Shape Modeling and Applications, Genova, Italy, 7–11 May 2001; pp. 154–166. [Google Scholar]
- McCallum, A. Efficiently inducing features of conditional random fields. In Proceedings of the Nineteenth conference on Uncertainty in Artificial Intelligence, Acapulco, Mexico, 7–10 August 2003; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2003; pp. 403–410. [Google Scholar]
- Rusu, R.B.; Blodow, N.; Marton, Z.C.; Beetz, M. Close-range scene segmentation and reconstruction of 3D point cloud maps for mobile manipulation in domestic environments. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, IROS 2009, St. Louis, MO, USA, 10–15 October 2009; pp. 1–6. [Google Scholar]
- Hetzel, G.; Leibe, B.; Levi, P.; Schiele, B. 3D object recognition from range images using local feature histograms. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2001, Kauai, HI, USA, 8–14 December 2001; Volume 2, p. II. [Google Scholar]
- Himri, K.; Ridao, P.; Gracias, N.; Palomer, A.; Palomeras, N.; Pi, R. Semantic SLAM for an AUV using object recognition from point clouds. IFAC PapersOnLine 2018, 51, 360–365. [Google Scholar] [CrossRef]
- Ribas, D.; Palomeras, N.; Ridao, P.; Carreras, M.; Mallios, A. Girona 500 AUV: From survey to intervention. IEEE/ASME Trans. Mechatron. 2012, 17, 46–53. [Google Scholar] [CrossRef]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Descriptor | Main Characteristics | ||
|---|---|---|---|
| Based on | Use of Normals | Descriptor Size | |
| Global Orthographic Object Descriptor (GOOD)-2016—[68] | - | No | 75 |
| The Ensemble of shape functions (ESF)-2011—[64] | Shape function [69] | No | 640 |
| Global Radius-based Surface Descriptors (GRSD)-2010—[54] | RSD [55] | Yes | 21 |
| Viewpoint Feature Histogram (VFH)-2010—[53] | Fast Point Feature Histogram (FPFH) [46] | Yes | 308 |
| Global Fast Point Feature Histogram (GFPFH)-2009—[33] | Fast Point Feature Histogram (FPFH) [46] | Yes | 16 |
| Clustered Viewpoint Feature Histogram (CVFH)-2011—[34] | VFH [53] | Yes | 308 |
| Oriented, Unique and Repeatable CVFH (OUR-CVFH)-2012—[62] | CVFH [34] | Yes | 308 |
| PVC Objects | Id Name | Size (mm3) | PVC Objects Views (12) |
|---|---|---|---|
 | 1-Ball-Valve |  | |
 | 2- Elbow |  | |
 | 3- R-Tee |  | |
 | 4- R-Socket |  | |
 | 5- Ball-Valve-S |  | |
 | 6- Butterfly-Valve |  | |
 | 7- 3-Way-Ball-Valve |  |
| VX (m) | 0.003 | 0.005 | 0.007 | 0.009 | 0.011 | 0.0013 | 0.015 | 0.017 | 0.019 | 0.021 | 0.023 | 0.025 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (m) | |||||||||||||
| 0 |  | ||||||||||||
| 0.00625 |  | ||||||||||||
| 0.0125 |  | ||||||||||||
| 0.025 |  | ||||||||||||
| 0.05 |  | ||||||||||||
| 0.1 |  | ||||||||||||
| Full Object View | Partial Object View | |
|---|---|---|
| Same Resolution |  |  |
| Different Resolution |  |  |
| Experiment | View | Resolution | Descriptors | Average Over Descriptors | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ESF | VFH | CVFH | OURCVFH | GOOD | GFPFH | GRSD | ||||
| FVSR | Full | Same | 77.4 | 65.3 | 69.5 | 69.3 | 55.1 | 72.8 | 75.0 | 69.2 |
| FVDR | Different | 41.8 | 18.1 | 18.3 | 18.7 | 51.9 | 29.3 | 22.3 | 28.6 | |
| PVSR | Partial | Same | 67.6 | 52.8 | 56.7 | 56.8 | 41.9 | 56.5 | 63.8 | 56.6 |
| PVDR | Different | 34.3 | 17.2 | 17.8 | 17.8 | 38.3 | 25.3 | 21.0 | 24.5 | |
| FVSR/FVDR | Average Over | Full View | 59.6 | 41.7 | 43.9 | 44.0 | 53.5 | 51.0 | 48.6 | 48.9 |
| PVSR/PVDR | Partial View | 50.9 | 35.0 | 37.3 | 37.3 | 40.1 | 40.9 | 42.4 | 40.5 | |
| FVSR/PVSR | Same Res | 72.5 | 59.1 | 63.1 | 63.0 | 48.5 | 64.6 | 69.4 | 62.9 | |
| FVDR/PVDR | Diff Res | 38.0 | 17.6 | 18.1 | 18.2 | 45.1 | 27.3 | 21.6 | 26.6 | |
| FVSR/FVDR/ PVSR/PVDR | Full Average | 55.3 | 38.4 | 40.6 | 40.6 | 46.8 | 46.0 | 45.5 | 44.7 | |
| Experiment | View | Resolution | Objects | |||||||||||||||||||||||||||
| Ball Valve | Elbow | R-Tee | R-Socket | |||||||||||||||||||||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |||
| FVSR | Full | Same | 58,8 | 2,8 | 4,3 | 0,7 | 16,7 | 0,5 | 16,3 | 1,6 | 78,8 | 6,8 | 10,7 | 1,4 | 0,6 | 0,1 | 4,6 | 15,6 | 69,6 | 1,6 | 5,3 | 0,9 | 2,3 | 2,8 | 8,3 | 1,3 | 86,3 | 1,0 | 0,1 | 0,2 |
| FVDR | Different | 13,5 | 7,5 | 3,8 | 62,3 | 8,0 | 1,1 | 3,8 | 1,7 | 22,0 | 1,5 | 73,3 | 0,8 | 0,6 | 0,1 | 3,1 | 8,6 | 17,0 | 64,3 | 2,3 | 1,0 | 3,8 | 1,5 | 2,1 | 1,7 | 92,7 | 1,0 | 0,8 | 0,2 | |
| PVSR | Partial | Same | 36,6 | 9,9 | 8,7 | 13,5 | 19,8 | 1,1 | 10,4 | 3,0 | 51,5 | 3,2 | 39,0 | 2,0 | 0,7 | 0,7 | 5,6 | 28,5 | 38,6 | 18,6 | 5,7 | 0,7 | 2,2 | 2,7 | 7,8 | 1,2 | 85,4 | 1,6 | 0,7 | 0,6 |
| PVDR | Different | 11,3 | 7,9 | 3,3 | 63,7 | 8,5 | 1,5 | 3,7 | 2,9 | 15,5 | 1,4 | 77,2 | 1,4 | 0,9 | 0,8 | 3,9 | 11,1 | 10,6 | 66,8 | 3,3 | 1,1 | 3,2 | 2,6 | 4,1 | 1,9 | 87,0 | 1,2 | 2,5 | 0,6 | |
| FVSR/ FVDR | Average Over | Full View | 36,1 | 5,2 | 4,0 | 31,5 | 12,4 | 0,8 | 10,0 | 1,6 | 50,4 | 4,1 | 42,0 | 1,1 | 0,6 | 0,1 | 3,9 | 12,1 | 43,3 | 32,9 | 3,8 | 1,0 | 3,1 | 2,1 | 5,2 | 1,5 | 89,5 | 1,0 | 0,4 | 0,2 |
| PVSR/ PVDR | Partial View | 24,0 | 8,9 | 6,0 | 38,6 | 14,2 | 1,3 | 7,1 | 2,9 | 33,5 | 2,3 | 58,1 | 1,7 | 0,8 | 0,7 | 4,7 | 19,8 | 24,6 | 42,7 | 4,5 | 0,9 | 2,7 | 2,7 | 6,0 | 1,6 | 86,2 | 1,4 | 1,6 | 0,6 | |
| FVSR/ PVSR | Same Res | 47,7 | 6,3 | 6,5 | 7,1 | 18,3 | 0,8 | 13,3 | 2,3 | 65,2 | 5,0 | 24,8 | 1,7 | 0,7 | 0,4 | 5,1 | 22,1 | 54,1 | 10,1 | 5,5 | 0,8 | 2,3 | 2,8 | 8,1 | 1,3 | 85,9 | 1,3 | 0,4 | 0,4 | |
| FVDR/ PVDR | Diff Res | 12,4 | 7,7 | 3,5 | 63,0 | 8,3 | 1,3 | 3,8 | 2,3 | 18,8 | 1,4 | 75,2 | 1,1 | 0,7 | 0,5 | 3,5 | 9,9 | 13,8 | 65,5 | 2,8 | 1,1 | 3,5 | 2,0 | 3,1 | 1,8 | 89,9 | 1,1 | 1,7 | 0,4 | |
| FVSR/ FVDR/ PVSR/ PVDR | Full Average | 30,1 | 7,0 | 5,0 | 35,0 | 13,3 | 1,1 | 8,5 | 2,3 | 42,0 | 3,2 | 50,0 | 1,4 | 0,7 | 0,4 | 4,3 | 16,0 | 34,0 | 37,8 | 4,1 | 0,9 | 2,9 | 2,4 | 5,6 | 1,5 | 87,9 | 1,2 | 1,0 | 0,4 | |
| Experiment | View | Resolution | Objects | Average Recognition for All Objects | ||||||||||||||||||||||||||
| Ball Valve-S | Butterfly Valve | 3-Way Valve | ||||||||||||||||||||||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | ||||||||||
| FVSR | Full | Same | 29,4 | 3,4 | 9,4 | 0,7 | 47,8 | 0,8 | 8,6 | 6,2 | 3,8 | 1,3 | 0,4 | 4,8 | 70,1 | 13,6 | 12,4 | 1,7 | 2,1 | 0,2 | 4,3 | 2,4 | 76,8 | 69,8 | ||||||
| FVDR | Different | 6,9 | 4,9 | 3,7 | 65,4 | 14,6 | 1,5 | 2,9 | 4,0 | 6,6 | 2,8 | 49,0 | 2,6 | 22,5 | 12,4 | 4,1 | 6,3 | 7,2 | 55,9 | 5,2 | 1,0 | 20,4 | 29,0 | |||||||
| PVSR | Partial | Same | 18,5 | 14,1 | 13,0 | 14,0 | 33,1 | 1,4 | 6,0 | 7,0 | 4,5 | 2,7 | 11,3 | 5,2 | 54,3 | 14,9 | 14,5 | 3,0 | 4,0 | 12,2 | 8,2 | 1,6 | 56,5 | 50,9 | ||||||
| PVDR | Different | 6,1 | 5,8 | 3,4 | 66,6 | 12,6 | 1,9 | 3,5 | 5,2 | 6,1 | 3,1 | 51,0 | 3,0 | 20,4 | 11,3 | 5,1 | 7,3 | 6,3 | 57,4 | 5,7 | 0,9 | 17,2 | 24,9 | |||||||
| FVSR/ FVDR | Average Over | Full View | 18,1 | 4,2 | 6,5 | 33,0 | 31,2 | 1,2 | 5,8 | 5,1 | 5,2 | 2,0 | 24,7 | 3,7 | 46,3 | 13,0 | 8,3 | 4,0 | 4,7 | 28,0 | 4,7 | 1,7 | 48,6 | 49,4 | ||||||
| PVSR/ PVDR | Partial View | 12,3 | 10,0 | 8,2 | 40,3 | 22,8 | 1,6 | 4,8 | 6,1 | 5,3 | 2,9 | 31,1 | 4,1 | 37,4 | 13,1 | 9,8 | 5,2 | 5,2 | 34,8 | 6,9 | 1,3 | 36,8 | 37,9 | |||||||
| FVSR/ PVSR | Same Res | 23,9 | 8,8 | 11,2 | 7,3 | 40,5 | 1,1 | 7,3 | 6,6 | 4,2 | 2,0 | 5,9 | 5,0 | 62,2 | 14,2 | 13,5 | 2,3 | 3,0 | 6,2 | 6,3 | 2,0 | 66,6 | 60,3 | |||||||
| FVDR/ PVDR | Diff Res | 6,5 | 5,4 | 3,5 | 66,0 | 13,6 | 1,7 | 3,2 | 4,6 | 6,4 | 2,9 | 50,0 | 2,8 | 21,5 | 11,8 | 4,6 | 6,8 | 6,8 | 56,6 | 5,4 | 0,9 | 18,8 | 27,0 | |||||||
| FVSR/ FVDR/ PVSR/ PVDR | Full Average | 15,2 | 7,1 | 7,4 | 36,7 | 27,0 | 1,4 | 5,3 | 5,6 | 5,3 | 2,5 | 27,9 | 3,9 | 41,8 | 13,0 | 9,1 | 4,6 | 4,9 | 31,4 | 5,8 | 1,5 | 42,7 | 43,6 | |||||||
| Different Standard Deviation () | |||
|---|---|---|---|
| =0 | =0.00625 | =0.0125 | |
| Full Object View |  |  |  |
| =0.025 | =0.05 | =0.1 | |
| Full Object View |  |  |  |
| =0 | =0.00625 | =0.0125 | |
| Partial Object View |  |  |  |
| =0.025 | =0.05 | =0.1 | |
| Partial Object View |  |  |  |
| Noise Std | Experiment | View | Resolution | Descriptors | Average Over Descriptors | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| ESF | VFH | CVFH | OURCVFH | GOOD | GFPFH | GRSD | |||||
| FVSR | Full | Same | 80,7 | 65,9 | 77,7 | 77,0 | 61,9 | 71,1 | 85,6 | 74,3 | |
| PVSR | Partial | 69,7 | 52,3 | 63,9 | 61,4 | 41,7 | 53,4 | 70,4 | 59,0 | ||
| FVSR | Full | Same | 78,4 | 67,4 | 78,6 | 76,4 | 61,0 | 75,4 | 82,6 | 74,3 | |
| PVSR | Partial | 74,6 | 52,9 | 62,4 | 63,6 | 43,7 | 51,7 | 71,7 | 60,1 | ||
| FVSR | Full | Same | 80,0 | 69,1 | 79,6 | 78,0 | 60,3 | 74,7 | 86,1 | 75,4 | |
| PVSR | Partial | 72,3 | 55,3 | 66,7 | 66,3 | 44,4 | 55,9 | 72,3 | 61,9 | ||
| FVSR | Full | Same | 80,4 | 67,4 | 78,3 | 75,9 | 56,4 | 72,1 | 61,4 | 70,3 | |
| PVSR | Partial | 70,4 | 51,4 | 65,9 | 65,6 | 42,9 | 56,7 | 51,3 | 57,7 | ||
| FVSR | Full | Same | 62,4 | 45,7 | 54,7 | 41,9 | 59,7 | 64,6 | 27,7 | 51,0 | |
| PVSR | Partial | 56,0 | 36,1 | 36,1 | 33,4 | 44,3 | 61,4 | 31,1 | 42,7 | ||
| FVSR | Full | Same | 20,0 | 29,7 | 42,6 | 42,4 | 45,7 | 23,3 | 14,3 | 31,1 | |
| PVSR | Partial | 28,9 | 23,7 | 30,0 | 30,7 | 40,7 | 30,3 | 14,7 | 28,4 | ||
| Average | FVSR/PVSR | Average | Same | 64,5 | 51,4 | 61,4 | 59,4 | 50,2 | 57,6 | 55,8 | 57,2 |
| Full Object View | Partial Object View | |
|---|---|---|
| Same Resolution |  |  |
| Experiment | View | Resolution | Objects | |||||||||||||||||||||||||||||
| Ball Valve | Elbow | R-Tee | R-Socket | |||||||||||||||||||||||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |||||
| FVSR | Full | Same | 59,9 | 2,9 | 23,6 | 0,6 | 13,7 | 0,4 | 17,4 | 0,7 | 84,7 | 7,0 | 7,0 | 0,1 | 0,4 | 0,0 | 3,9 | 15,3 | 71,9 | 1,7 | 3,9 | 2,0 | 1,4 | 0,9 | 2,3 | 0,3 | 95,9 | 0,7 | 0,0 | 0,0 | ||
| PVSR | Partial | 45,7 | 9,0 | 7,9 | 0,4 | 21,1 | 0,3 | 15,6 | 3,6 | 66,0 | 5,3 | 22,6 | 1,1 | 0,6 | 0,9 | 3,9 | 31,0 | 54,7 | 5,1 | 3,9 | 0,6 | 0,9 | 2,1 | 6,1 | 0,9 | 88,6 | 1,3 | 0,3 | 0,7 | |||
| FVSR/ PVSR | Average | 52,8 | 5,9 | 15,7 | 0,5 | 17,4 | 0,4 | 16,5 | 2,1 | 75,4 | 6,1 | 14,8 | 0,6 | 0,5 | 0,4 | 3,9 | 23,1 | 63,3 | 3,4 | 3,9 | 1,3 | 1,1 | 1,5 | 4,2 | 0,6 | 92,2 | 1,0 | 0,1 | 0,4 | |||
| FVSR | Full | Same | 57,9 | 3,0 | 6,1 | 0,7 | 11,9 | 1,0 | 19,4 | 0,4 | 81,1 | 8,6 | 8,3 | 0,1 | 1,3 | 0,1 | 3,4 | 14,3 | 75,7 | 2,0 | 3,0 | 0,9 | 0,7 | 1,4 | 3,7 | 0,7 | 93,7 | 0,4 | 0,0 | 0,0 | ||
| PVSR | Partial | 45,6 | 9,1 | 8,7 | 0,3 | 21,4 | 0,3 | 14,6 | 1,9 | 64,4 | 4,9 | 26,1 | 0,4 | 0,9 | 1,4 | 4,1 | 30,3 | 55,4 | 5,1 | 3,4 | 0,9 | 0,7 | 2,1 | 5,0 | 0,6 | 89,3 | 2,0 | 0,4 | 0,6 | |||
| FVSR/ PVSR | Average | 51,7 | 6,1 | 7,4 | 0,5 | 16,6 | 0,6 | 17,0 | 1,1 | 72,8 | 6,7 | 17,2 | 0,3 | 1,1 | 0,8 | 3,8 | 22,3 | 65,6 | 3,6 | 3,2 | 0,9 | 0,7 | 1,8 | 4,4 | 0,6 | 91,5 | 1,2 | 0,2 | 0,3 | |||
| FVSR | Full | Same | 58,9 | 2,7 | 6,0 | 0,7 | 14,6 | 0,7 | 16,4 | 1,0 | 85,9 | 4,4 | 7,9 | 0,1 | 0,4 | 0,3 | 3,4 | 16,7 | 72,9 | 2,3 | 2,6 | 1,3 | 0,9 | 1,3 | 1,7 | 0,9 | 95,0 | 1,1 | 0,0 | 0,0 | ||
| PVSR | Partial | 48,9 | 10,4 | 7,6 | 1,0 | 17,4 | 0,7 | 14,0 | 2,9 | 69,1 | 4,6 | 20,7 | 1,6 | 0,4 | 0,7 | 5,3 | 32,1 | 54,7 | 3,0 | 2,3 | 1,3 | 1,3 | 2,1 | 6,3 | 1,0 | 88,3 | 1,7 | 0,3 | 0,3 | |||
| FVSR/ PVSR | Average | 53,9 | 6,6 | 6,8 | 0,9 | 16,0 | 0,7 | 15,2 | 1,9 | 77,5 | 4,5 | 14,3 | 0,9 | 0,4 | 0,5 | 4,4 | 24,4 | 63,8 | 2,6 | 2,4 | 1,3 | 1,1 | 1,7 | 4,0 | 0,9 | 91,6 | 1,4 | 0,1 | 0,1 | |||
| FVSR | Full | Same | 62,0 | 4,3 | 3,6 | 0,6 | 12,9 | 0,3 | 16,4 | 0,3 | 79,1 | 8,7 | 11,1 | 0,1 | 0,1 | 0,4 | 3,0 | 18,7 | 69,0 | 1,7 | 5,1 | 0,7 | 1,7 | 1,4 | 2,7 | 1,3 | 93,6 | 1,0 | 0,0 | 0,0 | ||
| PVSR | Partial | 54,3 | 7,4 | 10,0 | 0,9 | 15,1 | 0,0 | 12,3 | 2,3 | 59,7 | 6,7 | 28,3 | 1,0 | 0,6 | 1,4 | 4,4 | 31,6 | 53,6 | 5,1 | 3,1 | 1,0 | 1,1 | 3,0 | 6,1 | 1,3 | 87,0 | 2,0 | 0,4 | 0,1 | |||
| FVSR/ PVSR | Average | 58,1 | 5,9 | 6,8 | 0,7 | 14,0 | 0,1 | 14,4 | 1,3 | 69,4 | 7,7 | 19,7 | 0,6 | 0,4 | 0,9 | 3,7 | 25,1 | 61,3 | 3,4 | 4,1 | 0,9 | 1,4 | 2,2 | 4,4 | 1,3 | 90,3 | 1,5 | 0,2 | 0,1 | |||
| FVSR | Full | Same | 30,7 | 7,9 | 2,4 | 0,4 | 13,1 | 15,0 | 30,4 | 5,9 | 42,4 | 9,9 | 26,0 | 12,7 | 0,4 | 2,7 | 11,4 | 28,7 | 30,7 | 3,6 | 12,3 | 6,3 | 7,0 | 0,7 | 5,3 | 0,4 | 91,9 | 1,7 | 0,0 | 0,0 | ||
| PVSR | Partial | 25,4 | 12,4 | 5,2 | 0,3 | 21,1 | 12,8 | 22,9 | 5,3 | 30,9 | 4,0 | 43,7 | 13,0 | 0,6 | 2,6 | 11,3 | 32,9 | 25,9 | 5,3 | 14,5 | 2,6 | 7,5 | 2,4 | 6,7 | 1,0 | 85,9 | 3,3 | 0,7 | 0,0 | |||
| FVSR/ PVSR | Average | 28,0 | 10,1 | 3,8 | 0,4 | 17,1 | 13,9 | 26,7 | 5,6 | 36,6 | 6,9 | 34,9 | 12,9 | 0,5 | 2,6 | 11,4 | 30,8 | 28,3 | 4,4 | 13,4 | 4,4 | 7,3 | 1,6 | 6,0 | 0,7 | 88,9 | 2,5 | 0,4 | 0,0 | |||
| FVSR | Full | Same | 8,3 | 18,7 | 15,9 | 0,3 | 7,3 | 25,7 | 23,9 | 1,1 | 27,6 | 8,9 | 27,9 | 15,0 | 14,4 | 5,1 | 14,1 | 34,0 | 15,3 | 3,3 | 3,3 | 16,3 | 13,7 | 1,3 | 16,4 | 4,1 | 49,0 | 14,0 | 14,3 | 0,9 | ||
| PVSR | Partial | 8,1 | 25,1 | 17,7 | 1,4 | 4,4 | 24,7 | 18,4 | 0,7 | 20,7 | 11,7 | 33,7 | 13,3 | 14,9 | 5,0 | 15,9 | 29,1 | 17,1 | 6,9 | 7,9 | 15,6 | 7,6 | 1,4 | 14,7 | 2,3 | 61,3 | 5,9 | 13,9 | 0,6 | |||
| FVSR/ PVSR | Average | 8,2 | 21,9 | 16,8 | 0,9 | 5,9 | 25,2 | 21,1 | 0,9 | 24,1 | 10,3 | 30,8 | 14,1 | 14,6 | 5,1 | 15,0 | 31,6 | 16,2 | 5,1 | 5,6 | 15,9 | 10,6 | 1,4 | 15,6 | 3,2 | 55,1 | 9,9 | 14,1 | 0,7 | |||
| Objects | ||||||||||||||||||||||||||||||||
| Experiment | View | Resolution | Ball Valve-S | Butterfly Valve | 3-Way Valve | Average Confusion | Recogn-ition | |||||||||||||||||||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |||||
| FVSR | Full | Same | 23,6 | 5,0 | 10,4 | 1,0 | 48,3 | 0,6 | 11,1 | 6,9 | 7,7 | 3,0 | 0,0 | 5,7 | 65,9 | 10,9 | 12,3 | 2,4 | 2,9 | 0,7 | 3,1 | 0,7 | 77,9 | 8,0 | 5,9 | 7,9 | 1,8 | 4,5 | 0,7 | 6,8 | 72,0 | |
| PVSR | Partial | 20,6 | 14,1 | 10.9 | 1,1 | 42,1 | 1,4 | 9,7 | 6,9 | 5,7 | 4,3 | 0,6 | 6,7 | 61,4 | 14,4 | 15,6 | 3,9 | 4,1 | 1,0 | 5,0 | 0,6 | 69,9 | 8,8 | 11,6 | 5,5 | 5,1 | 6,5 | 0,6 | 7,0 | 61,2 | ||
| FVSR/ PVSR | Average | 22,1 | 9,6 | 10,6 | 1,1 | 45,2 | 1,0 | 10,4 | 6,9 | 6,7 | 3,6 | 0,3 | 6,2 | 63,6 | 12,6 | 13,9 | 3,1 | 3,5 | 0,9 | 4,1 | 0,6 | 73,9 | 8,4 | 8,8 | 6,7 | 3,5 | 5,5 | 0,7 | 6,9 | 66,6 | ||
| FVSR | Full | Same | 19,1 | 4,6 | 10,4 | 1,0 | 50,7 | 1,7 | 12,4 | 6,3 | 4,1 | 1,9 | 0,1 | 4,3 | 69,3 | 14,0 | 9,9 | 2,1 | 3,9 | 0,4 | 2,1 | 3,0 | 78,6 | 6,8 | 5,3 | 5,3 | 2,1 | 3,6 | 1,3 | 7,8 | 72,4 | |
| PVSR | Partial | 18,0 | 11,3 | 11,1 | 0,9 | 44,7 | 2,7 | 11,3 | 6,6 | 5,6 | 3,9 | 0,4 | 7,4 | 64,9 | 11,3 | 15,9 | 2,9 | 4,3 | 0,4 | 6,3 | 1,1 | 69,1 | 8,1 | 10,7 | 5,6 | 5,5 | 6,8 | 1,0 | 6,6 | 61,9 | ||
| FVSR/ PVSR | Average | 18,6 | 7,9 | 10,8 | 0,9 | 47,7 | 2,2 | 11,9 | 6,4 | 4,9 | 2,9 | 0,3 | 5,9 | 67,1 | 12,6 | 12,9 | 2,5 | 4,1 | 0,4 | 4,2 | 2,1 | 73,9 | 7,4 | 8,0 | 5,4 | 3,8 | 5,2 | 1,2 | 7,2 | 67,2 | ||
| FVSR | Full | Same | 27,7 | 3,6 | 6,6 | 0,4 | 52,3 | 0,4 | 9,0 | 7,4 | 4,0 | 2,4 | 0,4 | 2,9 | 73,4 | 9,4 | 12,4 | 1,7 | 2,6 | 0,6 | 3,3 | 1,6 | 77,9 | 8,9 | 5,1 | 3,8 | 2,0 | 4,1 | 0,7 | 6,0 | 73,7 | |
| PVSR | Partial | 15,3 | 9,4 | 11,9 | 1,4 | 49,1 | 1,3 | 11,6 | 5,9 | 3,7 | 1,1 | 1,1 | 6,4 | 68,9 | 12,9 | 16,9 | 3,4 | 4,6 | 0,7 | 7,7 | 0,9 | 65,9 | 8,0 | 10,9 | 5,1 | 4,7 | 6,2 | 0,8 | 6,8 | 63,6 | ||
| FVSR/ PVSR | Average | 21,5 | 6,5 | 9,2 | 0,9 | 50,7 | 0,9 | 10,3 | 6,6 | 3,9 | 1,8 | 0,8 | 4,6 | 71,1 | 11,1 | 14,6 | 2,6 | 3,6 | 0,6 | 5,5 | 1,2 | 71,9 | 8,5 | 8,0 | 4,5 | 3,4 | 5,1 | 0,8 | 6,4 | 68,6 | ||
| FVSR | Full | Same | 35,7 | 5,3 | 8,9 | 0,9 | 39,7 | 0,3 | 9,3 | 11,1 | 5,6 | 1,9 | 0,4 | 3,7 | 62,4 | 14,9 | 13,1 | 2,0 | 3,9 | 0,9 | 3,7 | 0,6 | 75,9 | 10,8 | 6,4 | 4,7 | 2,6 | 4,4 | 0,3 | 7,1 | 68,8 | |
| PVSR | Partial | 25,3 | 12,1 | 14,0 | 1,9 | 35,9 | 1,1 | 9,7 | 12,7 | 5,3 | 3,3 | 0,4 | 6,0 | 54,9 | 17,4 | 18,9 | 3,4 | 4,0 | 0,0 | 4,3 | 0,3 | 69,1 | 11,1 | 11,0 | 6,5 | 6,1 | 5,3 | 0,6 | 7,0 | 59,2 | ||
| FVSR/ PVSR | Average | 30,5 | 8,7 | 11,4 | 1,4 | 37,8 | 0,7 | 9,5 | 11,9 | 5,4 | 2,6 | 0,4 | 4,9 | 58,6 | 16,1 | 16,0 | 2,7 | 3,9 | 0,4 | 4,0 | 0,4 | 72,5 | 10,9 | 8,7 | 5,6 | 4,3 | 4,8 | 0,5 | 7,1 | 64,0 | ||
| FVSR | Full | Same | 20,3 | 11,0 | 7,0 | 2,6 | 26,9 | 14,1 | 18,1 | 4,1 | 6,7 | 2,0 | 0,4 | 2,6 | 61,7 | 22,4 | 8,6 | 3,6 | 3,0 | 0,0 | 5,1 | 15,7 | 64,0 | 8,5 | 10,5 | 4,1 | 5,5 | 7,9 | 8,6 | 13,5 | 49,8 | |
| PVSR | Partial | 18,4 | 17,2 | 11,6 | 1,9 | 27,1 | 8,6 | 15,2 | 5,5 | 4,5 | 2,6 | 0,5 | 4,4 | 52,0 | 30,5 | 9,2 | 4,4 | 3,8 | 0,6 | 11,4 | 14,9 | 55,7 | 8,7 | 13,0 | 4,7 | 8,7 | 11,3 | 6,7 | 13,1 | 43,3 | ||
| FVSR/ PVSR | Average | 19,3 | 14,1 | 9,3 | 2,3 | 27,0 | 11,4 | 16,7 | 4,8 | 5,6 | 2,3 | 0,5 | 3,5 | 56,9 | 26,5 | 8,9 | 4,0 | 3,4 | 0,3 | 8,3 | 15,3 | 59,9 | 8,6 | 11,8 | 4,4 | 7,1 | 9,6 | 7,6 | 13,3 | 46,5 | ||
| FVSR | Full | Same | 11,1 | 27,9 | 15,3 | 0,3 | 7,7 | 21,3 | 16,4 | 1,3 | 8,1 | 6,6 | 1,3 | 1,0 | 50,9 | 30,9 | 3,1 | 8,0 | 11,1 | 0,1 | 1,4 | 28,6 | 47,6 | 5,4 | 18,9 | 10,3 | 5,5 | 7,0 | 20,1 | 15,1 | 29,5 | |
| PVSR | Partial | 13,3 | 29,3 | 16,4 | 1,9 | 7,6 | 18,6 | 13,0 | 0,9 | 10,0 | 5,0 | 1,3 | 1,3 | 49,1 | 32,4 | 3,6 | 11,4 | 8,6 | 0,1 | 2,4 | 27,1 | 46,7 | 6,0 | 20,0 | 10,3 | 7,5 | 5,9 | 19,1 | 12,8 | 30,1 | ||
| FVSR/ PVSR | Average | 12,2 | 28,6 | 15,9 | 1,1 | 7,6 | 19,9 | 14,7 | 1,1 | 9,1 | 5,8 | 1,3 | 1,1 | 50,0 | 31,6 | 3,4 | 9,7 | 9,9 | 0,1 | 1,9 | 27,9 | 47,1 | 5,7 | 19,4 | 10,3 | 6,5 | 6,4 | 19,6 | 14,0 | 29,8 | ||
| Average | 8,2 | 10,8 | 6,2 | 4,8 | 6,1 | 5,1 | 9,1 | |||||||||||||||||||||||||
| Objects | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Descriptors | Experiment | Ball Valve | Elbow | R-Tee | R-Socket | Average of Recognition | |||||||||||||
| 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 | Real | Synth-etic | ||
| ESF | Real | 100 | 0 | 0 | 0 | 0 | 76 | 24 | 0 | 8 | 0 | 92 | 0 | 21 | 2 | 0 | 77 | 86,2 | |
| Synthetic | 100 | 0 | 0 | 0 | 1 | 99 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 100 | 99,8 | ||
| VFH | Real | 100 | 0 | 0 | 0 | 31 | 41 | 21 | 7 | 4 | 6 | 90 | 0 | 19 | 2 | 0 | 60 | 72,8 | |
| Synthetic | 100 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 48 | 0 | 52 | 88,0 | ||
| CVFH | Real | 100 | 0 | 0 | 0 | 0 | 93 | 3 | 3 | 0 | 4 | 95 | 0 | 0 | 6 | 0 | 94 | 95,4 | |
| Synthetic | 100 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 100 | 100 | ||
| OURCVFH | Real | 100 | 0 | 0 | 0 | 0 | 83 | 0 | 17 | 0 | 0 | 96 | 4 | 0 | 13 | 0 | 88 | 91,5 | |
| Synthetic | 100 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 100 | 100 | ||
| GOOD | Real | 100 | 0 | 0 | 0 | 34 | 66 | 0 | 0 | 100 | 0 | 0 | 0 | 33 | 0 | 0 | 67 | 58,0 | |
| Synthetic | 100 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 75,0 | ||
| GFPFH | Real | 60 | 0 | 0 | 40 | 0 | 48 | 0 | 52 | 4 | 73 | 23 | 0 | 0 | 15 | 0 | 85 | 54,1 | |
| Synthetic | 100 | 0 | 0 | 0 | 0 | 88 | 12 | 0 | 1 | 0 | 99 | 0 | 0 | 0 | 0 | 100 | 96,8 | ||
| GRSD | Real | 88 | 0 | 12 | 0 | 0 | 76 | 0 | 24 | 0 | 33 | 67 | 0 | 0 | 2 | 0 | 98 | 82,1 | |
| Synthetic | 100 | 0 | 0 | 0 | 0 | 98 | 2 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 100 | 99,5 | ||
| Average Real | 92,6 | 0,0 | 1,7 | 5,7 | 9,3 | 69,0 | 6,9 | 14,8 | 16,7 | 16,6 | 65,9 | 0,6 | 10,4 | 5,6 | 0,0 | 81,2 | |||
| Scanned/(Miss-)Recognized/Correct View | Histogram of the Descriptor | |
|---|---|---|
| ESF |  |  |
| GFPFH |  |  |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Himri, K.; Ridao, P.; Gracias, N. 3D Object Recognition Based on Point Clouds in Underwater Environment with Global Descriptors: A Survey. Sensors 2019, 19, 4451. https://doi.org/10.3390/s19204451
Himri K, Ridao P, Gracias N. 3D Object Recognition Based on Point Clouds in Underwater Environment with Global Descriptors: A Survey. Sensors. 2019; 19(20):4451. https://doi.org/10.3390/s19204451
Chicago/Turabian StyleHimri, Khadidja, Pere Ridao, and Nuno Gracias. 2019. "3D Object Recognition Based on Point Clouds in Underwater Environment with Global Descriptors: A Survey" Sensors 19, no. 20: 4451. https://doi.org/10.3390/s19204451