Ambulatory and Laboratory Stress Detection Based on Raw Electrocardiogram Signals Using a Convolutional Neural Network



Abstract
:1. Introduction
2. Material and Methods
2.1. Subjects and Data Acquisition
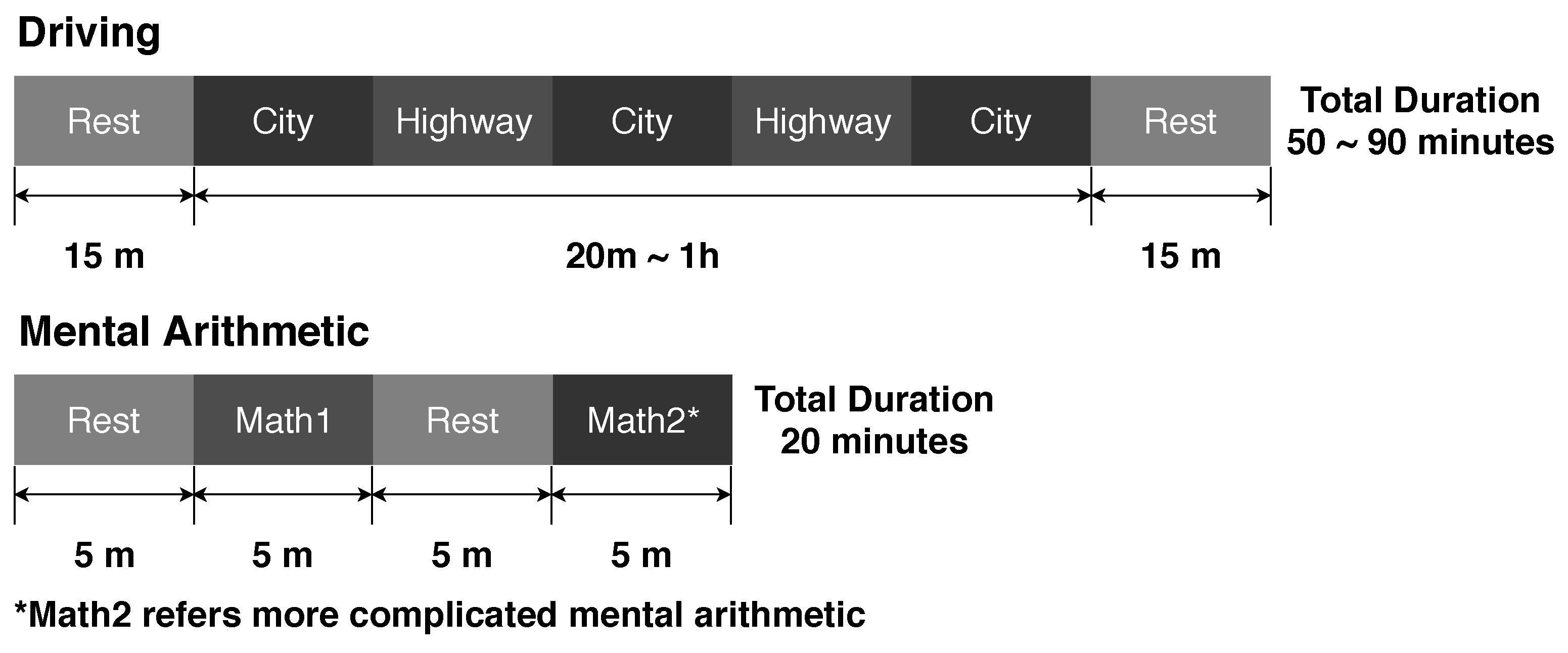
2.1.1. Driving Data Set
2.1.2. Mental Arithmetic Data Set
2.2. Data Preprocessing and Annotation Procedures
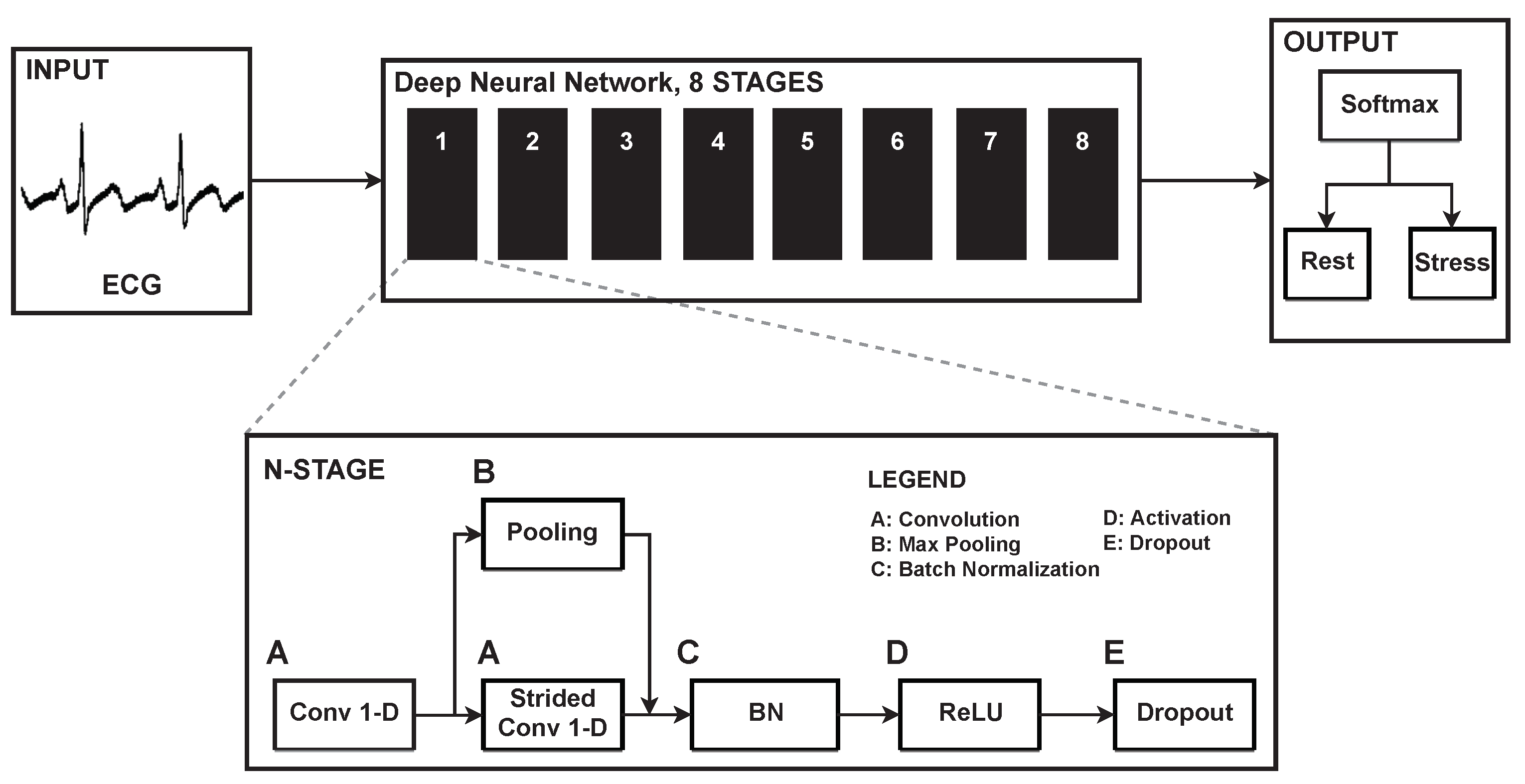
2.3. The Deep Neural Network
2.4. Training the Neural Network
2.4.1. Type I Training
2.4.2. Type II Training
2.4.3. Type III Training
2.5. Model Evaluation
2.5.1. Cross-Validation
2.5.2. Statistical Analysis
3. Results
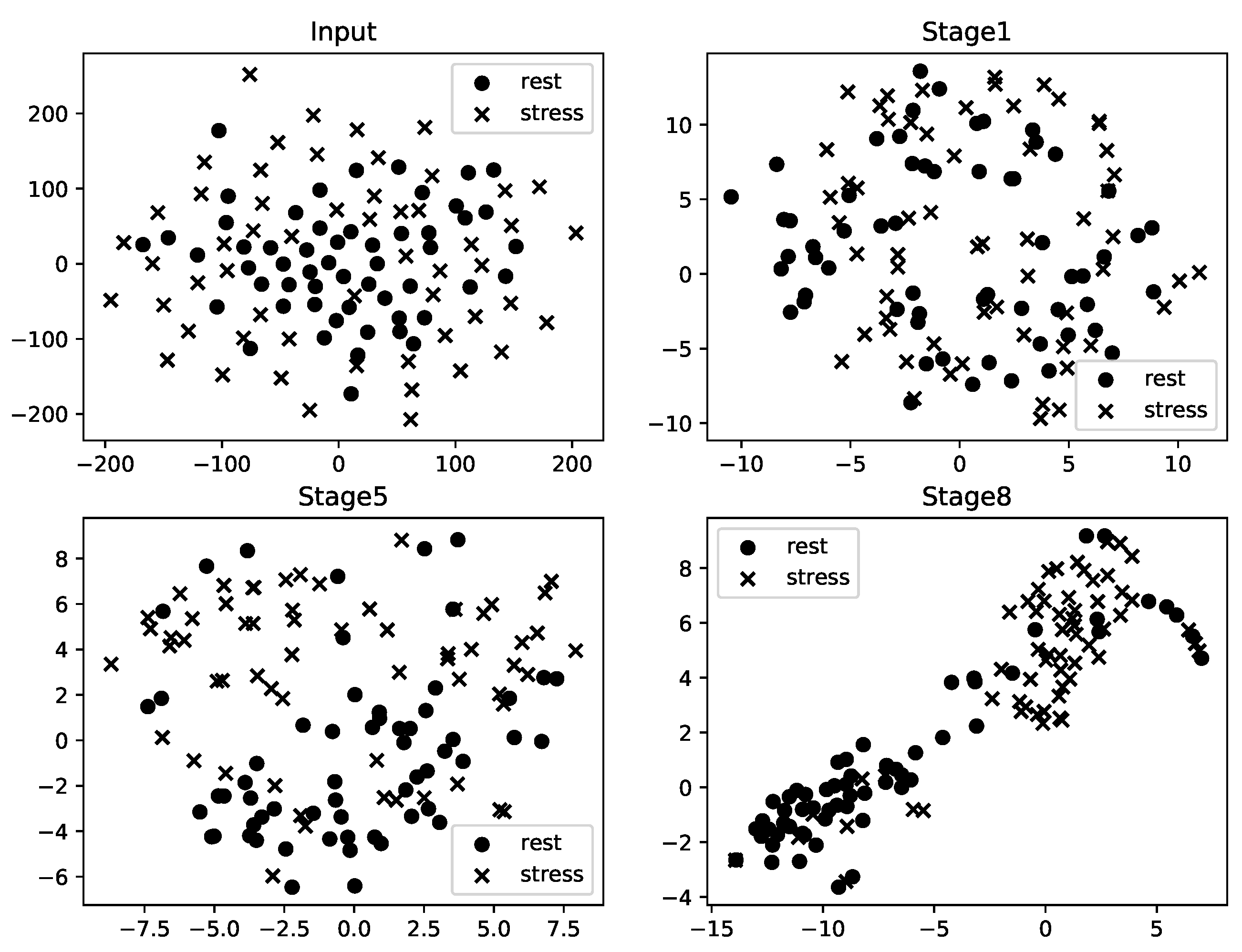
3.1. Feature Representation
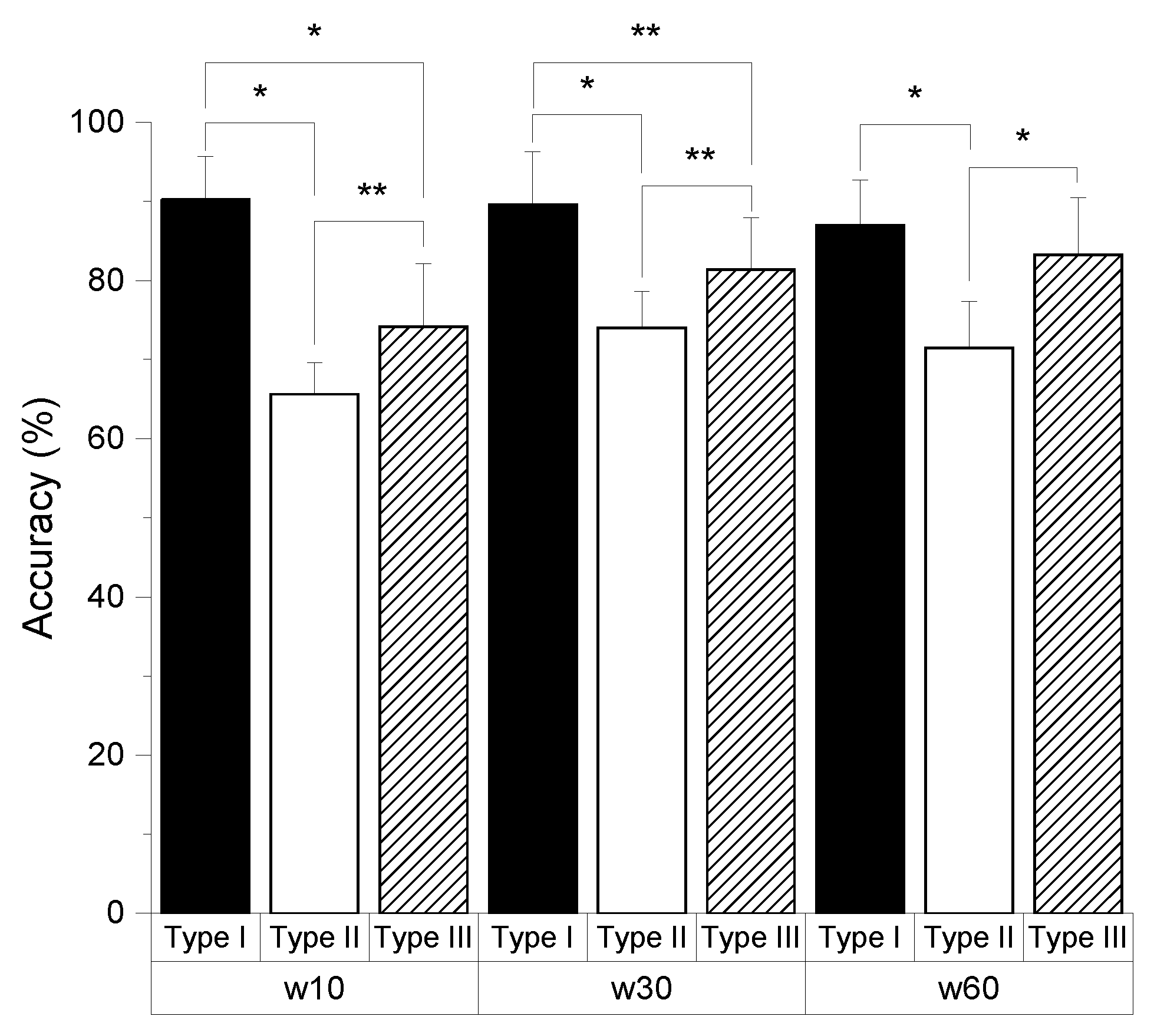
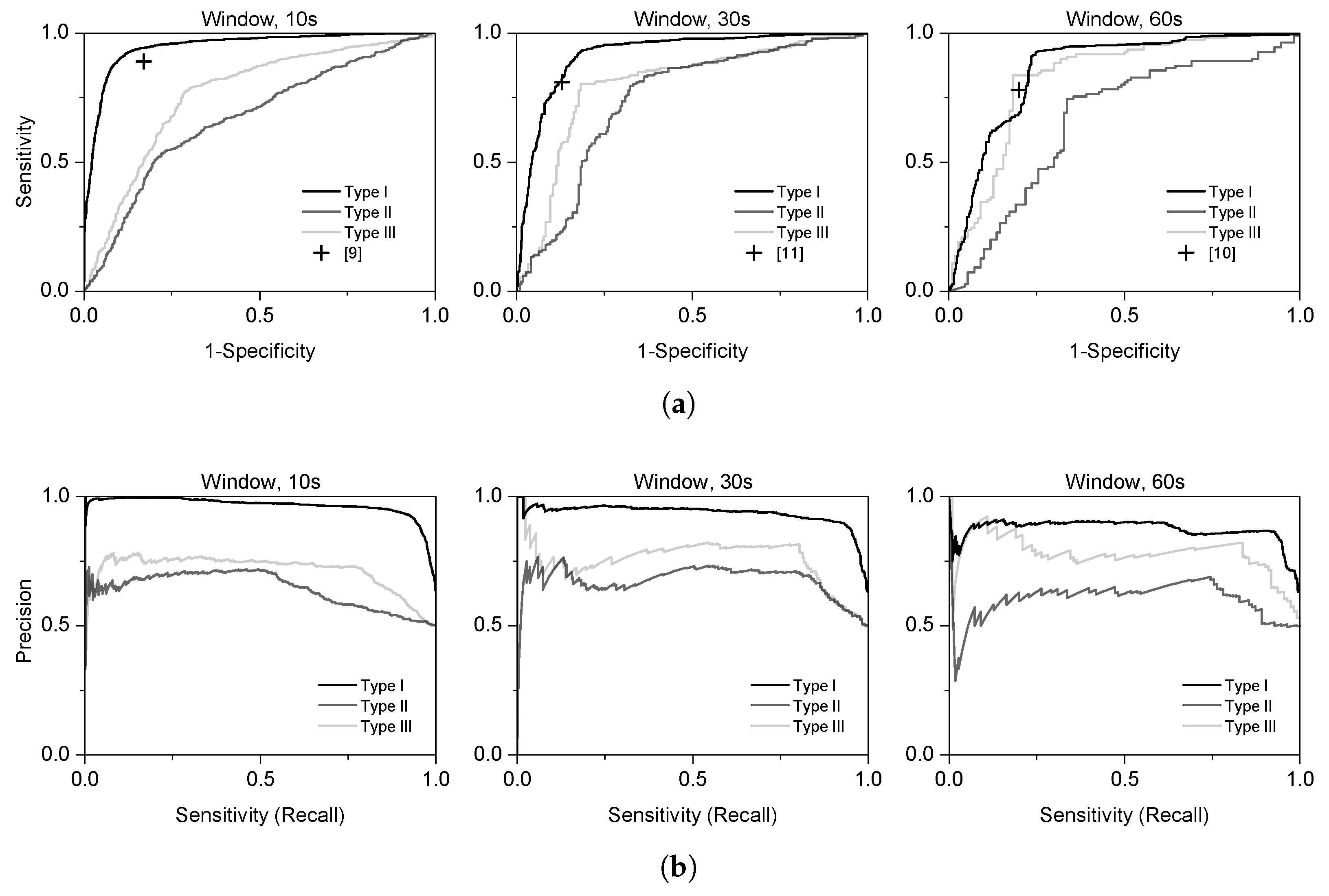
3.2. Performance of the End-to-End Model
3.3. Comparison with Different Models
4. Discussion and Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Order | Operation | Output | Stride | # of Parameters |
|---|---|---|---|---|
| 0 | input | (?, 2560, 1) | - | - |
| 1-1 | conv16-8 | (?, 2560, 8) | 1 | 128 |
| 1-2 | conv16-8 | (?, 1280, 8) | 2 | 1024 |
| 1-2 | maxpool16 | (?, 1280, 8) | 2 | - |
| 1-3 | concatenating | (?, 1280, 16) | - | - |
| 1-4 | batch normalization | (?, 1280, 16) | - | 32 |
| 1-5 | activation & dropout | (?, 1280, 16) | - | - |
| 2-1 | conv16-8 | (?, 1280, 8) | 1 | 2048 |
| 2-2 | conv16-8 | (?, 640, 8) | 2 | 1024 |
| 2-2 | maxpool16 | (?, 640, 8) | 2 | - |
| 2-3 | concatenating | (?, 640, 16) | - | - |
| 2-4 | batch normalization | (?, 640, 16) | - | 32 |
| 2-5 | activation & dropout | (?, 640, 16) | - | - |
| 3-1 | conv16-16 | (?, 640, 16) | 1 | 4096 |
| 3-2 | conv16-16 | (?, 320, 16) | 2 | 4096 |
| 3-2 | maxpool16 | (?, 320, 16) | 2 | - |
| 3-3 | concatenating | (?, 320, 32) | - | - |
| 3-4 | batch normalization | (?, 320, 32) | - | 64 |
| 3-5 | activation & dropout | (?, 320, 32) | - | - |
| 4-1 | conv16-16 | (?, 320, 16) | 1 | 8192 |
| 4-2 | conv16-16 | (?, 160, 16) | 2 | 4096 |
| 4-2 | maxpool16 | (?, 160, 16) | 2 | - |
| 4-3 | concatenating | (?, 160, 32) | - | - |
| 4-4 | batch normalization | (?, 160, 32) | - | 64 |
| 4-5 | activation & dropout | (?, 160, 32) | - | - |
| 5-1 | conv16-32 | (?, 160, 32) | 1 | 16,384 |
| 5-2 | conv16-32 | (?, 80, 32) | 2 | 16,384 |
| 5-2 | maxpool16 | (?, 80, 32) | 2 | - |
| 5-3 | concatenating | (?, 80, 64) | - | - |
| 5-4 | batch normalization | (?, 80, 64) | - | 128 |
| 5-5 | activation & dropout | (?, 80, 64) | - | - |
| 6-1 | conv16-32 | (?, 80, 32) | 1 | 32,768 |
| 6-2 | conv16-32 | (?, 40, 32) | 2 | 16,384 |
| 6-2 | maxpool16 | (?, 40, 32) | 2 | - |
| 6-3 | concatenating | (?, 40, 64) | - | - |
| 6-4 | batch normalization | (?, 40, 64) | - | 128 |
| 6-5 | activation & dropout | (?, 40, 64) | - | - |
| 7-1 | conv16-64 | (?, 40, 64) | 1 | 65,536 |
| 7-2 | conv16-64 | (?, 20, 64) | 2 | 65,536 |
| 7-2 | maxpool16 | (?, 20, 64) | 2 | - |
| 7-3 | concatenating | (?, 20, 128) | - | - |
| 7-4 | batch normalization | (?, 20, 128) | - | 256 |
| 7-5 | activation & dropout | (?, 20, 128) | - | - |
| 8-1 | conv16-64 | (?, 20, 64) | 1 | 131,072 |
| 8-2 | conv16-64 | (?, 10, 64) | 2 | 65,536 |
| 8-2 | maxpool16 | (?, 10, 64) | 2 | - |
| 8-3 | concatenating | (?, 10, 128) | - | - |
| 8-4 | batch normalization | (?, 10, 128) | - | 256 |
| 8-5 | activation & dropout | (?, 10, 128) | - | - |
| Total | 435K |
References
- Cohen, S.; Janicki-Deverts, D.; Miller, G.E. Psychological stress and disease. JAMA 2007, 298, 1685–1687. [Google Scholar] [CrossRef] [PubMed]
- Smets, E.; De Raedt, W.; Van Hoof, C. Into the Wild: The Challenges of Physiological Stress Detection in Laboratory and Ambulatory Settings. IEEE J. Biomed. Health Inform. 2018, 23, 463–473. [Google Scholar] [CrossRef] [PubMed]
- Sztajzel, J. Heart rate variability: A noninvasive electrocardiographic method to measure the autonomic nervous system. Swiss Med. Wkly. 2004, 134, 514–522. [Google Scholar] [PubMed]
- Shaffer, F.; Ginsberg, J. An overview of heart rate variability metrics and norms. Front. Public Health 2017, 5, 258. [Google Scholar] [CrossRef] [PubMed]
- McCraty, R.; Atkinson, M.; Tiller, W.A.; Rein, G.; Watkins, A.D. The effects of emotions on short-term power spectrum analysis of heart rate variability. Am. J. Cardiol. 1995, 76, 1089–1093. [Google Scholar] [CrossRef]
- Appelhans, B.M.; Luecken, L.J. Heart rate variability as an index of regulated emotional responding. Rev. Gen. Psychol. 2006, 10, 229–240. [Google Scholar] [CrossRef]
- Camm, A.; Malik, M.; Bigger, J.; Breithardt, G.; Cerutti, S.; Cohen, R.; Coumel, P.; Fallen, E.; Kennedy, H.; Kleiger, R.; et al. Heart rate variability: Standards of measurement, physiological interpretation and clinical use. Task Force of the European Society of Cardiology and the North American Society of Pacing and Electrophysiology. Circulation 1996, 93, 1043–1065. [Google Scholar]
- Pan, J.; Tompkins, W.J. A real-time QRS detection algorithm. IEEE Trans. Biomed. Eng. 1985, 32, 230–236. [Google Scholar] [CrossRef]
- Rigas, G.; Goletsis, Y.; Fotiadis, D.I. Real-time driver’s stress event detection. IEEE Trans. Intell. Transp. Syst. 2012, 13, 221–234. [Google Scholar] [CrossRef]
- Castaldo, R.; Xu, W.; Melillo, P.; Pecchia, L.; Santamaria, L.; James, C. Detection of mental stress due to oral academic examination via ultra-short-term HRV analysis. In Proceedings of the 2016 38th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Orlando, FL, USA, 16–20 August 2016; pp. 3805–3808. [Google Scholar]
- Smets, E.; Casale, P.; Großekathöfer, U.; Lamichhane, B.; De Raedt, W.; Bogaerts, K.; Van Diest, I.; Van Hoof, C. Comparison of machine learning techniques for psychophysiological stress detection. In Proceedings of the International Symposium on Pervasive Computing Paradigms for Mental Health, Milan, Italy, 24–25 September 2015; Springer: Cham, Switzerland, 2015; pp. 13–22. [Google Scholar]
- Hwang, B.; You, J.; Vaessen, T.; Myin-Germeys, I.; Park, C.; Zhang, B.T. Deep ECGNet: An Optimal Deep Learning Framework for Monitoring Mental Stress Using Ultra Short-Term ECG Signals. Telemed. e-Health 2018, 24, 753–772. [Google Scholar] [CrossRef] [PubMed]
- Saeed, A.; Ozcelebi, T.; Lukkien, J.; van Erp, J.; Trajanovski, S. Model Adaptation and Personalization for Physiological Stress Detection. In Proceedings of the 2018 IEEE 5th International Conference on Data Science and Advanced Analytics (DSAA), Turin, Italy, 1–4 October 2018; pp. 209–216. [Google Scholar]
- Healey, J.A.; Picard, R.W. Detecting stress during real-world driving tasks using physiological sensors. IEEE Trans. Intell. Transp. Syst. 2005, 6, 156–166. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; Curran Associates Inc.: Red Hook, NY, USA, 2012; pp. 1097–1105. [Google Scholar]
- Hannun, A.Y.; Rajpurkar, P.; Haghpanahi, M.; Tison, G.H.; Bourn, C.; Turakhia, M.P.; Ng, A.Y. Cardiologist-level arrhythmia detection and classification in ambulatory electrocardiograms using a deep neural network. Nat. Med. 2019, 25, 65. [Google Scholar] [CrossRef] [PubMed]
- Manawadu, U.E.; Kawano, T.; Murata, S.; Kamezaki, M.; Muramatsu, J.; Sugano, S. Multiclass Classification of Driver Perceived Workload Using Long Short-Term Memory based Recurrent Neural Network. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 September 2018; pp. 1–6. [Google Scholar]
- Xu, S.S.; Mak, M.W.; Cheung, C.C. Towards end-to-end ECG classification with raw signal extraction and deep neural networks. IEEE J. Biomed. Health Inform. 2018, 23, 1574–1584. [Google Scholar] [CrossRef] [PubMed]
- Acharya, U.R.; Fujita, H.; Lih, O.S.; Hagiwara, Y.; Tan, J.H.; Adam, M. Automated detection of arrhythmias using different intervals of tachycardia ECG segments with convolutional neural network. Inf. Sci. 2017, 405, 81–90. [Google Scholar] [CrossRef]
- Kiranyaz, S.; Ince, T.; Gabbouj, M. Real-time patient-specific ECG classification by 1-D convolutional neural networks. IEEE Trans. Biomed. Eng. 2016, 63, 664–675. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing And Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Goldberger, A.L.; Amaral, L.A.; Glass, L.; Hausdorff, J.M.; Ivanov, P.C.; Mark, R.G.; Mietus, J.E.; Moody, G.B.; Peng, C.K.; Stanley, H.E. PhysioBank, PhysioToolkit, and PhysioNet: Components of a new research resource for complex physiologic signals. Circulation 2000, 101, e215–e220. [Google Scholar] [CrossRef]
- Bradley, M.M.; Lang, P.J. Measuring emotion: The self-assessment manikin and the semantic differential. J. Behav. Therapy Exp. Psychiatry 1994, 25, 49–59. [Google Scholar] [CrossRef]
- Jacobsen, P.B.; Donovan, K.A.; Trask, P.C.; Fleishman, S.B.; Zabora, J.; Baker, F.; Holland, J.C. Screening for psychologic distress in ambulatory cancer patients: A multicenter evaluation of the distress thermometer. Cancer 2005, 103, 1494–1502. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Saito, T.; Rehmsmeier, M. The precision-recall plot is more informative than the ROC plot when evaluating binary classifiers on imbalanced datasets. PLoS ONE 2015, 10, e0118432. [Google Scholar] [CrossRef]
- Lee, M.; Park, D.; Dong, S.Y.; Youn, I. A Novel R Peak Detection Method for Mobile Environments. IEEE Access 2018, 6, 51227–51237. [Google Scholar] [CrossRef]





| Ref | # of Subjects | Signal | Window Length (s) | Classifier | Performance (%) | Stressor |
|---|---|---|---|---|---|---|
| [9] | 13 | ECG, SC, Respiration | 10 | BN | 84 | Driving |
| [10] | 42 | ECG | 180 | AB | 80 | Verbal examination |
| [11] | 20 | ECG, SC, Respiration, ST | 30 | BN | 84.6 | SCWT, math, counting |
| [12] | 20, 30 | Raw ECG | 10 | CNN+RNN | 87.39, 73.96 | MA, interview, SCWT, visual stimuli, cold pressor |
| [13] | 10 | HR, SC | - | MT-CNN | 0.918 (AUC) | Driving [14] |
| Stressor | Window Length (s) | Number of Samples | Total | |
|---|---|---|---|---|
| Rest | Stress | |||
| Driving | 10 | 2161 | 3731 | 5892 |
| 30 | 712 | 1227 | 1939 | |
| 60 | 349 | 598 | 947 | |
| Mental arithmetic | 10 | 1020 | 1020 | 2040 |
| 30 | 340 | 340 | 680 | |
| 60 | 170 | 170 | 340 | |
| Order | Operation | Filter Width | Number of Filters | Stride |
|---|---|---|---|---|
| 1 | Conv 1-D | 16 | 1 | |
| 2 | Conv 1-D | 16 | 2 | |
| Pooling | 16 | - | 2 | |
| 3 | Concat | Concatenating | ||
| 4 | BN | Batch normalization | ||
| 5 | Activation | ReLU | ||
| 6 | Dropout | Drop rate: 0.3 | ||
| Task | SAM | DT |
|---|---|---|
| Math1 | 0.37 | |
| Math2 | 0.89 |
| Stressor | Classifier | Window Length (s) | ||
|---|---|---|---|---|
| 10 | 30 | 60 | ||
| MA | DT | 0.539 (0.050) | 0.517 (0.062) | 0.490 (0.066) |
| kNN | 0.497 (0.030) | 0.511 (0.040) | 0.535 (0.058) | |
| LR | 0.493 (0.029) | 0.537 (0.076) | 0.508 (0.055) | |
| RF | 0.512 (0.075) | 0.505 (0.062) | 0.515 (0.041) | |
| SVM | 0.483 (0.025) | 0.516 (0.071) | 0.520 (0.082) | |
| Driving | DT | 0.487 (0.210) | 0.457 (0.234) | 0.512 (0.208) |
| kNN | 0.361 (0.051) | 0.423 (0.150) | 0.451 (0.208) | |
| LR | 0.447 (0.188) | 0.443 (0.235) | 0.434 (0.225) | |
| RF | 0.528 (0.187) | 0.486 (0.215) | 0.523 (0.193) | |
| SVM | 0.514 (0.155) | 0.533 (0.177) | 0.498 (0.205) | |
| Type | Window Length (s) | Evaluation Metrics | |||
|---|---|---|---|---|---|
| AUC | Score | Sensitivity | Specificity | ||
| I | 10 | 0.938 (0.053) | 0.922 (0.044) | 0.930 (0.035) | 0.854 (0.094) |
| II | 0.701 (0.069) | 0.602 (0.094) | 0.552 (0.186) | 0.759 (0.173) | |
| III | 0.761 (0.088) | 0.752 (0.079) | 0.787 (0.117) | 0.696 (0.144) | |
| I | 30 | 0.924 (0.072) | 0.922 (0.050) | 0.949 (0.039) | 0.788 (0.161) |
| II | 0.766 (0.049) | 0.755 (0.050) | 0.815 (0.143) | 0.665 (0.165) | |
| III | 0.807 (0.131) | 0.815 (0.063) | 0.830 (0.130) | 0.797 (0.170) | |
| I | 60 | 0.857 (0.141) | 0.901 (0.036) | 0.923 (0.044) | 0.755 (0.214) |
| II | 0.679 (0.113) | 0.717 (0.078) | 0.760 (0.227) | 0.670 (0.258) | |
| III | 0.835 (0.095) | 0.826 (0.089) | 0.820 (0.162) | 0.845 (0.161) | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cho, H.-M.; Park, H.; Dong, S.-Y.; Youn, I. Ambulatory and Laboratory Stress Detection Based on Raw Electrocardiogram Signals Using a Convolutional Neural Network. Sensors 2019, 19, 4408. https://doi.org/10.3390/s19204408
Cho H-M, Park H, Dong S-Y, Youn I. Ambulatory and Laboratory Stress Detection Based on Raw Electrocardiogram Signals Using a Convolutional Neural Network. Sensors. 2019; 19(20):4408. https://doi.org/10.3390/s19204408
Chicago/Turabian StyleCho, Hyun-Myung, Heesu Park, Suh-Yeon Dong, and Inchan Youn. 2019. "Ambulatory and Laboratory Stress Detection Based on Raw Electrocardiogram Signals Using a Convolutional Neural Network" Sensors 19, no. 20: 4408. https://doi.org/10.3390/s19204408