Appearance-Based Salient Regions Detection Using Side-Specific Dictionaries

Abstract
:1. Introduction
- The designed model is robust and easily handles the cluttered and noisy background which was a problem for dense appearance-based models. Also, the side-specific dictionaries of the proposed model are helpful in detecting the salient objects adjacent to the boundary.
- Sometimes the small segments from the background are extremely highlighted and affect the computed saliency. The averaging process of the proposed model is very helpful to overcome this issue by measuring the saliency of a superpixel as an average residual in this segment.
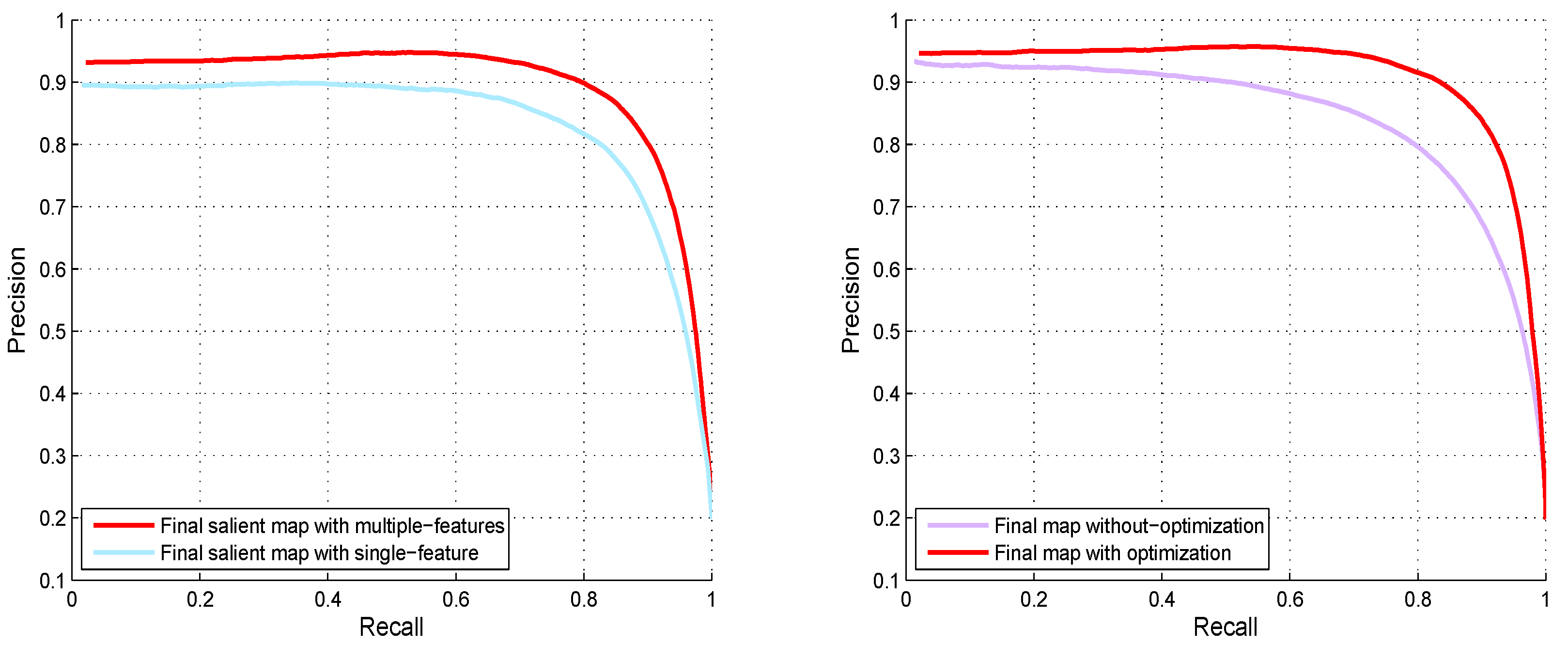
- To enhance the discrimination between the foreground and the background, we engage a multi-feature graph-learning procedure which incorporates the intrinsic weight of regions to implement the uniformity among the similar image patches by utilizing the prior information.
- Furthermore, we optimize the salient regions map by applying the guided filter, which removes the artifacts and further improves the qualitative as well as the quantitative results.
2. Related Work
2.1. Dictionary Learning-Based SRD
2.2. Sparse Representation-Based SRD
2.3. Global or Local Measures-Based SRD
2.4. Multiple Feature-Based SRD
2.5. Foreground or Background-Based SRD
2.6. Deep Convolutional Neural Networks-Based SRD
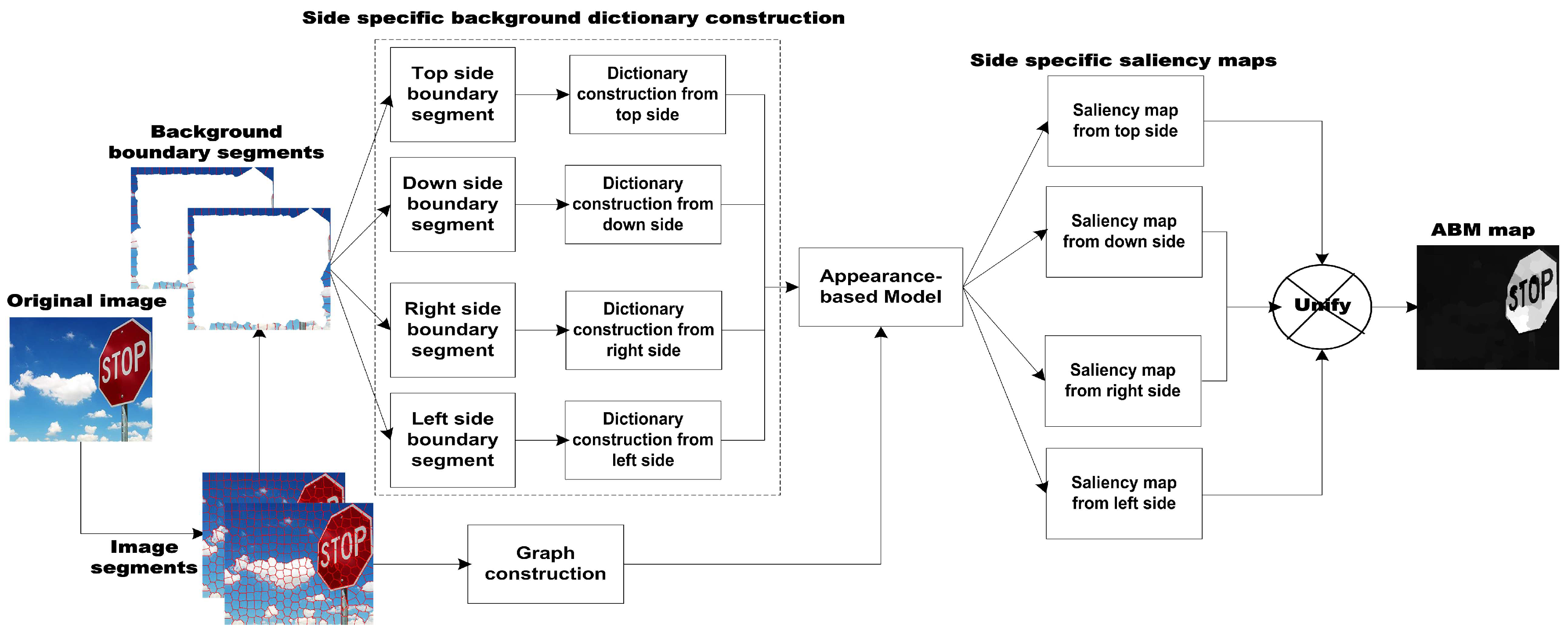
3. The Proposed Salient Regions Detection Approach
3.1. The Visual Feature Extraction
3.2. Heuristic Background Dictionary
3.3. Appearance-Based Salient Region Detection
3.4. Saliency Enhancement through a Regression-Based Model
4. Experimental Results
4.1. Benchmark Datasets
4.2. Preceding Methods Selected for Comparison
4.3. Evaluation Metrics
4.3.1. Precision-Recall
4.3.2. F-Score
4.3.3. Receiver Operating Characteristics
4.3.4. Mean Absolute Error
4.4. Implementation and Analysis
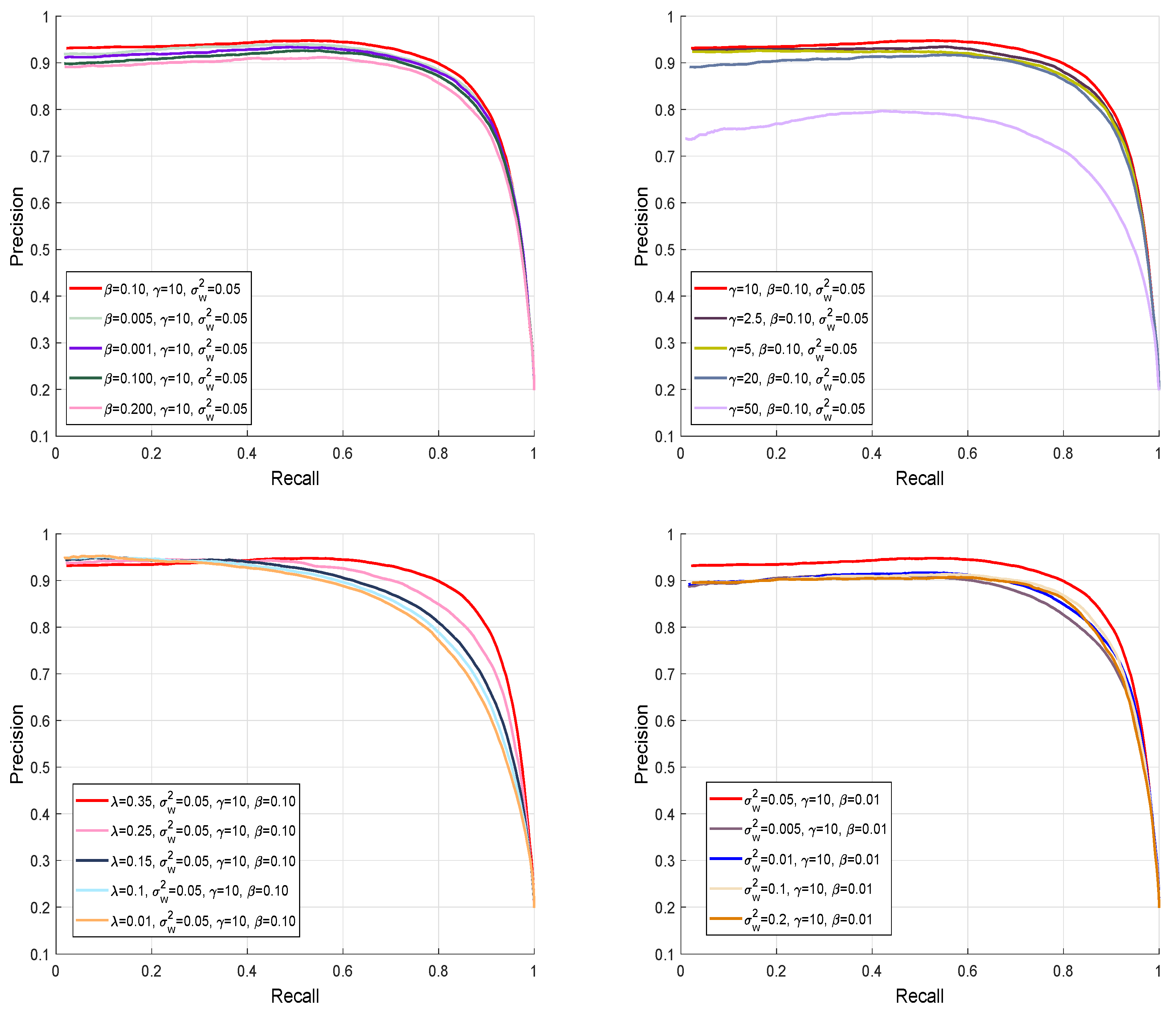
4.4.1. Parameter Settings
4.4.2. Evaluation of Our Algorithm
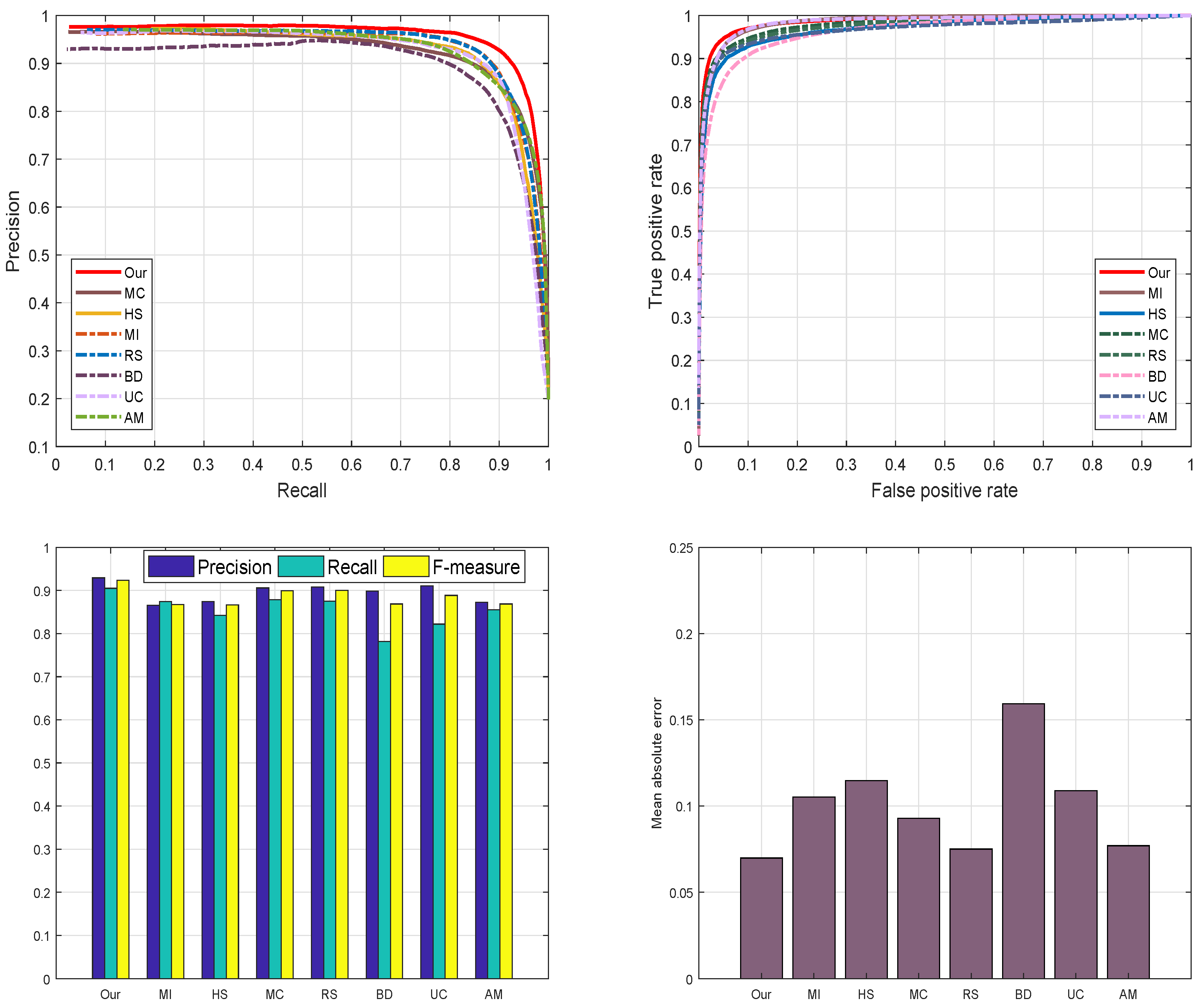
4.4.3. ASD Database
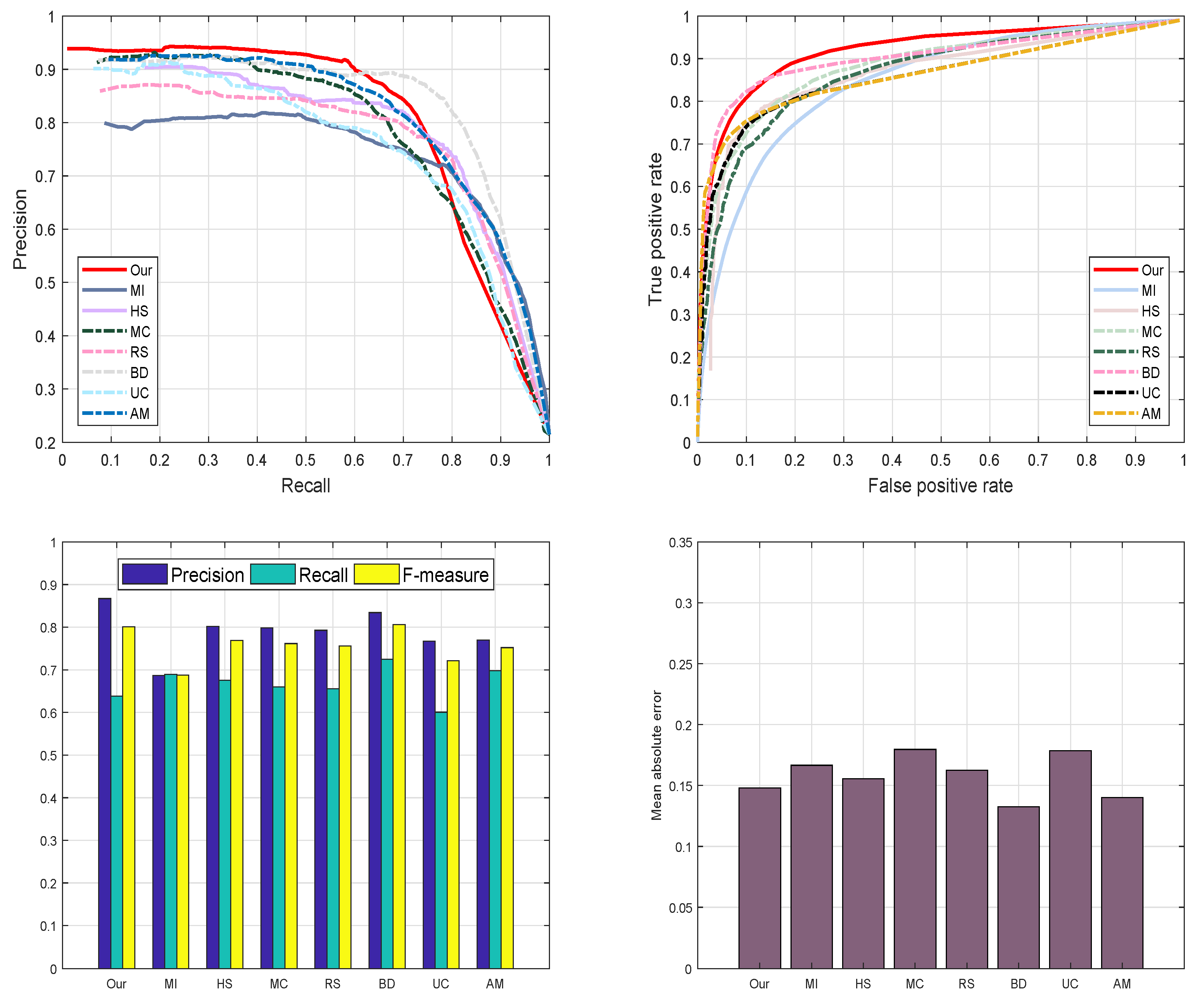
4.4.4. DUT-OMRON Database
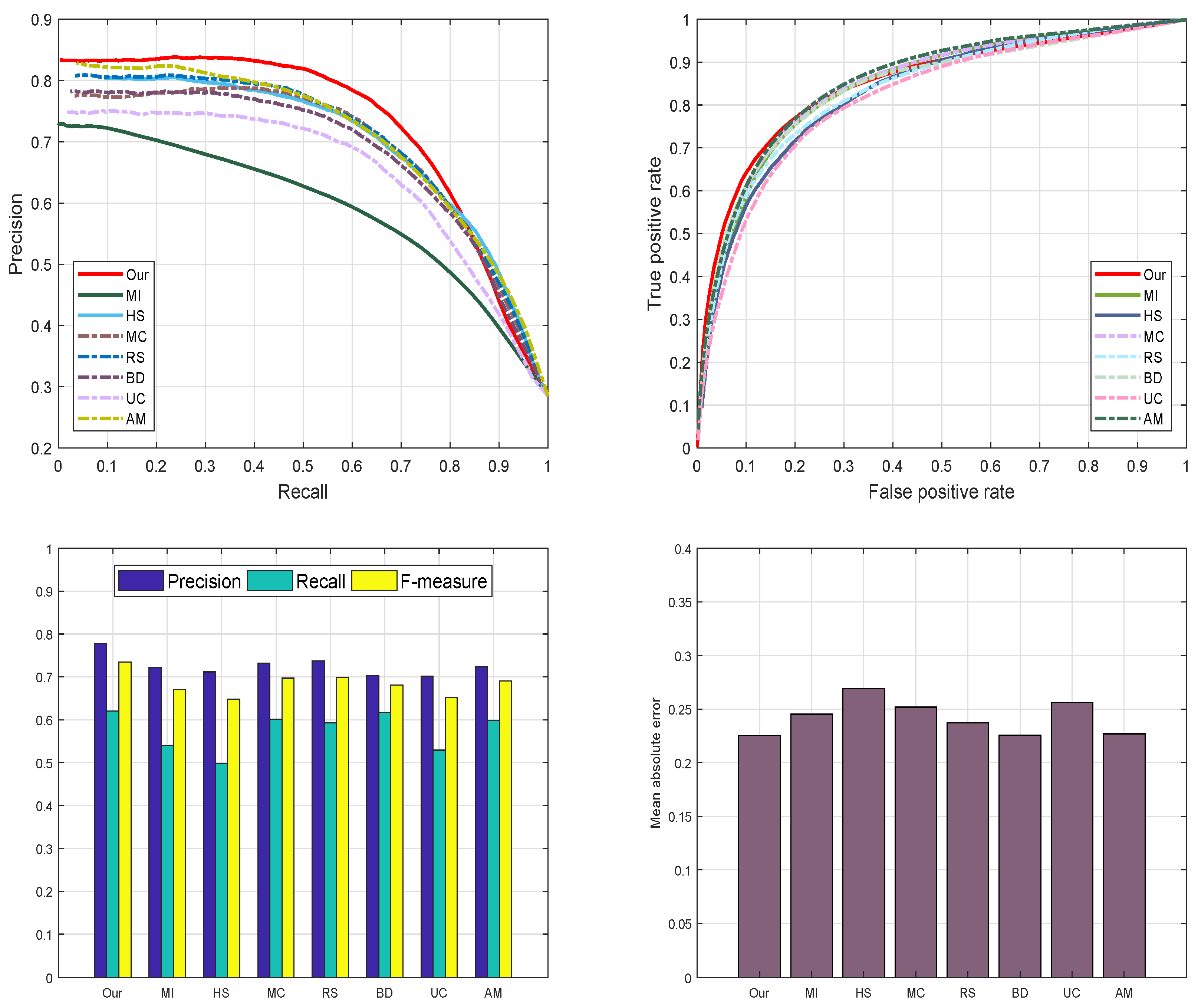
4.4.5. ECSSD Database
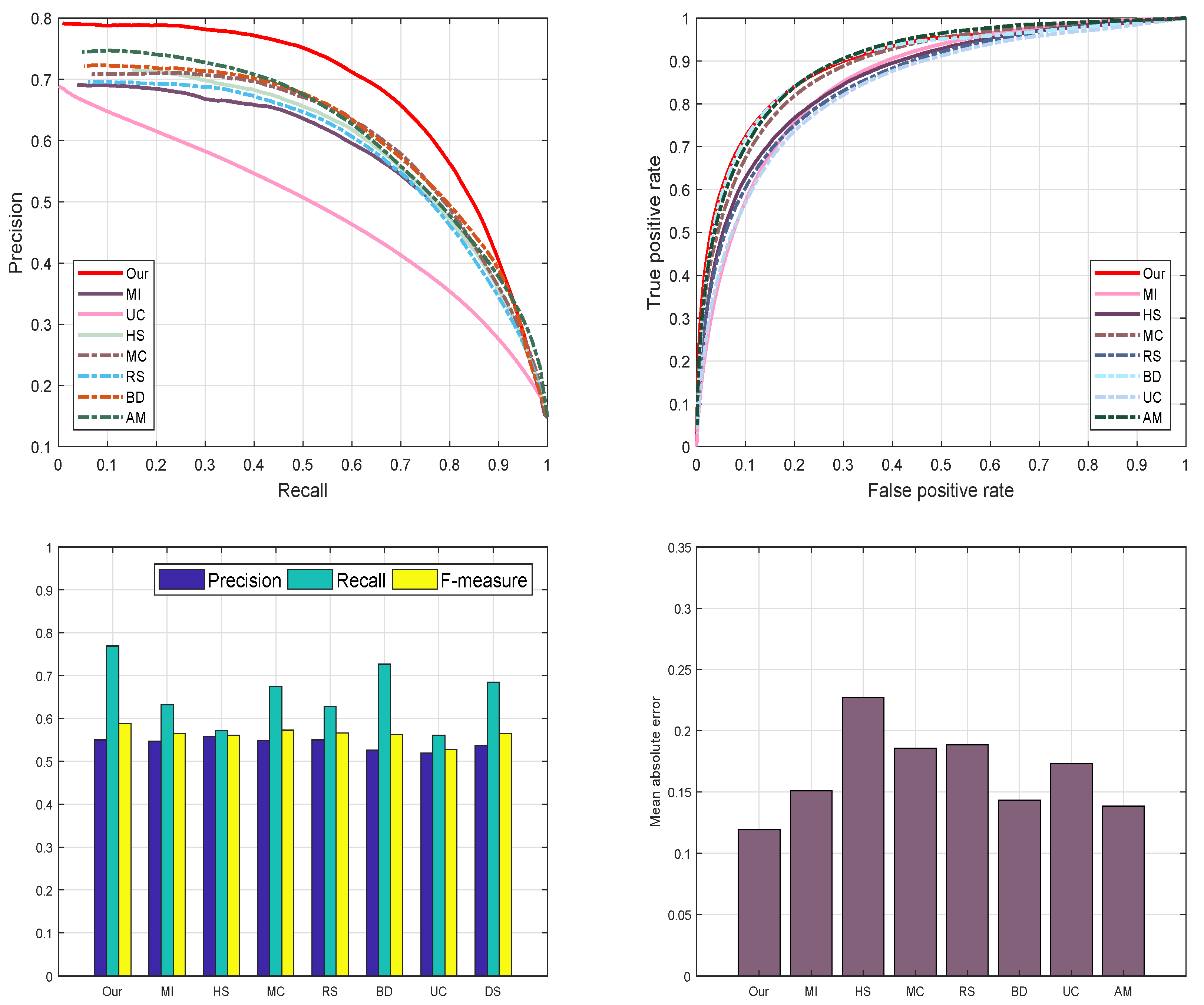
4.4.6. SED2 Data-Set
4.4.7. Limitations
4.4.8. Execution Time
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Han, B.; Zhu, H.; Ding, Y. Bottom-up saliency based on weighted sparse coding residual. In Proceedings of the ACM International Conference on Multimedia, Scottsdale, AZ, USA, 28 November–1 December 2011; pp. 1117–1120. [Google Scholar]
- Yang, J.; Yang, M.-H. Top-down visual saliency via joint CRF and dictionary learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2296–2303. [Google Scholar]
- Mehmood, I.; Sajjad, M.; Ejaz, W.; Baik, S.W. Saliency-directed prioritization of visual data in wireless surveillance networks. Inf. Fusion 2015, 24, 16–30. [Google Scholar] [CrossRef]
- Sajjad, M.; Ullah, A.; Ahmad, J.; Abbas, N.; Rho, S.; WookBaik, S. Integrating salient colors with rotational invariant texture features for image representation in retrieval system. Multimed. Tools Appl. 2018, 77, 4769–4789. [Google Scholar] [CrossRef]
- Sajjad, M.; Ullah, A.; Ahmad, J.; Abbas, N.; Rho, S.; WookBaik, S. Saliency-weighted graphs for efficient visual content description and their applications in real-time image retrieval systems. J. Real-Time Image Process. 2017, 13, 431–447. [Google Scholar]
- Borji, A.; Itti, L. Exploiting local and global patch rarities for saliency detection. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 478–485. [Google Scholar]
- Duan, L.; Wu, C.; Miao, J.; Qing, L.; Fu, Y. Visual saliency detection by spatially weighted dissimilarity. In Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011; pp. 473–480. [Google Scholar]
- Lu, H.; Li, X.; Zhang, L.; Ruan, X.; Yang, M.H. Dense and Sparse Reconstruction Error Based Saliency Descriptor. IEEE Trans. Image Process. 2016, 25, 1592–1603. [Google Scholar] [CrossRef] [PubMed]
- Huo, L.; Yang, S.; Jiao, L.; Wang, S.; Shi, J. Local graph regularized coding for salient object detection. Infrared Phys. Technol. 2016, 77, 124–131. [Google Scholar] [CrossRef]
- Huo, L.; Yang, S.; Jiao, L.; Wang, S.; Wang, S. Local graph regularized sparse reconstruction for salient object detection. Neurocomputing 2016, 194, 348–359. [Google Scholar] [CrossRef]
- Yang, C.; Zhang, L.; Lu, H. Graph Regularized Saliency Detection With Convex-Hull-Based Center Prior. IEEE Signal Process. Lett. 2013, 20, 637–640. [Google Scholar] [CrossRef]
- Hou, X.; Zhang, L. Dynamic visual attention: Searching for coding length increments. Advances in Neural Information Processing Systems 21. In Proceedings of the 22nd Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–11 December 2008; pp. 681–688. [Google Scholar]
- Shen, X.; Wu, Y. A unified approach to salient object detection via low rank matrix recovery. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 853–860. [Google Scholar]
- Li, Y.; Zhou, Y.; Xu, L.; Yang, X.; Yang, J. Incremental sparse SRD. In Proceedings of the IEEE International Conference on Image Processing, Cairo, Egypt, 7–10 November 2009; pp. 3093–3096. [Google Scholar]
- Sajjad, M.; Mehmood, I.; Baik, S.W. Image super-resolution using sparse coding over redundant dictionary based on effective image representations. J. Vis. Commun. Image Represent. 2015, 26, 50–65. [Google Scholar] [CrossRef]
- Zhang, L.; Zhao, S.; Liu, W.; Lu, H. SRD via sparse reconstruction and joint label inference in multiple features. Neurocomputing 2015, 155, 1–11. [Google Scholar] [CrossRef]
- Jia, C.; Qi, J.; Li, X.; Lu, H. Saliency detection via a unified generative and discriminative model. Neurocomputing 2015, 173, 406–417. [Google Scholar] [CrossRef]
- Harel, J.J.; Koch, C.; Perona, P. Graph-based visual saliency. Advances in Neural Information Processing Systems 19. In Proceedings of the Twentieth Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 4–7 December 2006; pp. 545–552. [Google Scholar]
- Ma, Y.-F.; Zhang, H.-G. Contrast-based image attention analysis by using fuzzy growing. In Proceedings of the Eleventh ACM International Conference on Multimedia (MULTIMEDIA ’03), Berkeley, CA, USA, 2–8 November 2003; ACM: New York, NY, USA, 2003; pp. 374–381. [Google Scholar]
- Lin, M.; Zhang, C.; Chen, Z. Global feature integration based salient region detection. Neurocomputing 2015, 159, 1–8. [Google Scholar] [CrossRef]
- Cheng, M.-M.; Zhang, G.-X.; Mitra, N.J.; Huang, X.; Hu, S.-M. Global contrast based salient region detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; pp. 409–416. [Google Scholar]
- Cheng, M.; Mitra, N.J.; Huang, X.; Torr, P.H.S.; Hu, S. Global Contrast Based Salient Region Detection. IEEE Transa. Pattern Anal. Mach. Intell. 2015, 37, 569–582. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Q.; Zhu, G.; Yuan, Y. Multi-spectral dataset and its application in saliency detection. Comput. Vis. Image Understand. 2013, 117, 1748–1754. [Google Scholar] [CrossRef]
- Lin, M.; Zhang, C.; Chen, Z. Predicting salient object via multi-level features. Neurocomputing 2016, 205, 301–310. [Google Scholar] [CrossRef]
- Wang, H.; Dai, L.; Cai, Y.; Sun, X.; Chen, L. Salient object detection based on multi-scale contrast. Neural Netw. 2018, 101, 47–56. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Lu, H.; Lin, Z.; Shen, X.; Price, B. Adaptive Metric Learning for SRD. IEEE Trans. Image Process. 2015, 24, 3321–3331. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Lu, H.; Lin, Z.; Shen, X.; Price, B. Inner and Inter Label Propagation: Salient Object Detection in the Wild. IEEE Trans. Image Process. 2015, 24, 3176–3186. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, C.; Zhang, L.; Lu, H.; Ruan, X.; Yang, M.-H. SRD via Graph-Based Manifold Ranking. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 3166–3173. [Google Scholar]
- Zhang, P.; Wang, D.; Lu, H.; Wang, H.; Ruan, X. Amulet: Aggregating Multi-level Convolutional Features for Salient Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 202–211. [Google Scholar]
- Huang, F.; Qi, J.; Lu, H.; Zhang, L.; Ruan, X. Salient Object Detection via Multiple Instance Learning. IEEE Trans. Image Process. 2017, 26, 1911–1922. [Google Scholar] [CrossRef] [PubMed]
- Zhang, P.; Wang, D.; Lu, H.; Wang, H.; Yin, B. Learning Uncertain Convolutional Features for Accurate Saliency Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 212–221. [Google Scholar]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Susstrunk, S. SLIC superpixels compared to state-of-the-art superpixel methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef] [PubMed]
- Borji, A.; Cheng, Mi.; Jiang, H.; Li, J. Salient Object Detection: A Survey. arXiv, 2014; arXiv:1411.5878. [Google Scholar]
- Borji, A.; Cheng, M.-M.; Jiang, H.; Li, J. Salient Object Detection: A Benchmark. IEEE Trans. Image Process. 2015, 24, 5706–5722. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jiang, H.; Wang, J.; Yuan, Z.; Wu, Y.; Zheng, N.; Li, S. Salient object detection: A discriminative regional feature integration approach. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2083–2090. [Google Scholar]
- Yang, M.; Zhang, L.; Yang, J.; Zhang, D. Metaface learning for sparse representation based face recognition. In Proceedings of the 2010 IEEE International Conference on Image Processing, Hong Kong, China, 26–29 September 2010; pp. 1601–1604. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Guided Image Filtering. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1397–1409. [Google Scholar] [CrossRef]
- Achanta, R.; Hemami, S.; Estrada, F.; Susstrunk, S. Frequency-tuned salient region detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1597–1604. [Google Scholar]
- Yan, Q.; Xu, L.; Shi, J.; Jia, J. Hierarchical saliency detection. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 1155–1162. [Google Scholar]
- Alpert, S.; Galun, M.; Basri, R.; Brandt, A. Image Segmentation by Probabilistic Bottom-Up Aggregation and Cue Integration. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007. [Google Scholar]
- Liu, T.; Sun, J.; Zheng, N.-N.; Tang, X.; Shum, H.-Y. Learning to detect a salient object. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Wang, Z.; Xiang, D.; Hou, S.; Wu, F. Background-Driven Salient Object Detection. IEEE Trans. Multimedia 2017, 19, 750–762. [Google Scholar] [CrossRef]
- Zhang, L.; Yang, C.; Lu, H.; Ruan, X.; Yang, M. Ranking Saliency. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1892–1904. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Ai, J.; Jiang, B.; Lu, H.; Li, X. Saliency Detection via Absorbing Markov Chain with Learnt Transition Probability. IEEE Trans. Image Process. 2018, 27, 987–998. [Google Scholar] [CrossRef]
- Zhang, Y.Y.; Zhang, S.; Zhang, P.; Zhang, X. Saliency detection via background and foreground null space learning. Signal Process. Image Commun. 2019, 70, 271–281. [Google Scholar] [CrossRef]
- Ji, Y.; Zhang, H.; Tseng, K.-K.; Chow, T.W.S.; Wu, Q.M.J. Graph model-based salient object detection using objectness and multiple saliency cues. Neurocomputing 2019, 323, 188–202. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | ECSSD | SED2 | DUT-OMRON | ASD | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| NS | MSC | Our | NS | MSC | Our | NS | MSC | Our | NS | MSC | Our | |
| F-score | 0.710 | 0.713 | 0.73 | 0.775 | 0.791 | 0.802 | 0.616 | 0.60 | 0.699 | 0.870 | 0.92 | 0.93 |
| AUC | 0.90 | 0.89 | 0.907 | 0.85 | 0.859 | 0.861 | 0.887 | 0.883 | 0.895 | 0.935 | 0.952 | 0.953 |
| MAE | 0.245 | 0.229 | 0.222 | 0.182 | 0.155 | 0.145 | 0.149 | 0.126 | 0.125 | 0.095 | 0.080 | 0.070 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fareed, M.M.S.; Chun, Q.; Ahmed, G.; Murtaza, A.; Asif, M.R.; Fareed, M.Z. Appearance-Based Salient Regions Detection Using Side-Specific Dictionaries. Sensors 2019, 19, 421. https://doi.org/10.3390/s19020421
Fareed MMS, Chun Q, Ahmed G, Murtaza A, Asif MR, Fareed MZ. Appearance-Based Salient Regions Detection Using Side-Specific Dictionaries. Sensors. 2019; 19(2):421. https://doi.org/10.3390/s19020421
Chicago/Turabian StyleFareed, Mian Muhammad Sadiq, Qi Chun, Gulnaz Ahmed, Adil Murtaza, Muhammad Rizwan Asif, and Muhammad Zeeshan Fareed. 2019. "Appearance-Based Salient Regions Detection Using Side-Specific Dictionaries" Sensors 19, no. 2: 421. https://doi.org/10.3390/s19020421